В этой главе мы поговорим о том, как интегрировать Apache Kafka с Spark Streaming API.
О Спарк
Spark Streaming API обеспечивает масштабируемую высокопроизводительную отказоустойчивую обработку потоков потоков данных. Данные могут поступать из многих источников, таких как Kafka, Flume, Twitter и т. Д., И могут обрабатываться с использованием сложных алгоритмов, таких как высокоуровневые функции, такие как map, Reduce, Join и Window. Наконец, обработанные данные можно отправить в файловые системы, базы данных и живые панели мониторинга. Эластичные распределенные наборы данных (RDD) — это фундаментальная структура данных Spark. Это неизменяемая распределенная коллекция объектов. Каждый набор данных в RDD разделен на логические разделы, которые могут быть вычислены на разных узлах кластера.
Интеграция с Spark
Kafka — это потенциальная платформа обмена сообщениями и интеграции для потоковой передачи Spark. Kafka выступает в качестве центрального узла для потоков данных в реальном времени и обрабатывается с использованием сложных алгоритмов в Spark Streaming. После обработки данных Spark Streaming может публиковать результаты в еще одной теме Kafka или хранить в HDFS, базах данных или информационных панелях. Следующая диаграмма изображает концептуальный поток.
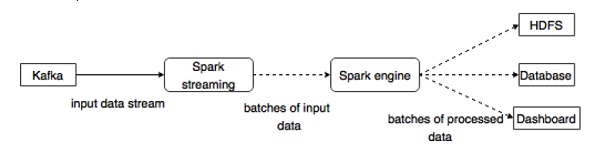
Теперь давайте подробно рассмотрим API Kafka-Spark.
SparkConf API
Он представляет конфигурацию для приложения Spark. Используется для установки различных параметров Spark в виде пар ключ-значение.
Класс SparkConf
имеет следующие методы —
-
set (строковый ключ, строковое значение) — установить переменную конфигурации.
-
удалить (строковый ключ) — удалить ключ из конфигурации.
-
setAppName (string name) — установить имя приложения для вашего приложения.
-
get (string key) — получить ключ
set (строковый ключ, строковое значение) — установить переменную конфигурации.
удалить (строковый ключ) — удалить ключ из конфигурации.
setAppName (string name) — установить имя приложения для вашего приложения.
get (string key) — получить ключ
StreamingContext API
Это основная точка входа для функциональности Spark. SparkContext представляет соединение с кластером Spark и может использоваться для создания RDD, аккумуляторов и широковещательных переменных в кластере. Подпись определяется так, как показано ниже.
public StreamingContext(String master, String appName, Duration batchDuration, String sparkHome, scala.collection.Seq<String> jars, scala.collection.Map<String,String> environment)
-
master — кластерный URL для подключения (например, mesos: // host: port, spark: // host: port, local [4]).
-
appName — имя вашей работы, отображаемое в веб-интерфейсе кластера.
-
batchDuration — интервал времени, в течение которого потоковые данные будут разделены на пакеты
master — кластерный URL для подключения (например, mesos: // host: port, spark: // host: port, local [4]).
appName — имя вашей работы, отображаемое в веб-интерфейсе кластера.
batchDuration — интервал времени, в течение которого потоковые данные будут разделены на пакеты
public StreamingContext(SparkConf conf, Duration batchDuration)
Создайте StreamingContext, предоставив конфигурацию, необходимую для нового SparkContext.
-
conf — параметры искры
-
batchDuration — интервал времени, в течение которого потоковые данные будут разделены на пакеты
conf — параметры искры
batchDuration — интервал времени, в течение которого потоковые данные будут разделены на пакеты
API KafkaUtils
API KafkaUtils используется для подключения кластера Kafka к потоковой передаче Spark. Этот API имеет подпись createStream
существенного метода, определенную как ниже.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream( StreamingContext ssc, String zkQuorum, String groupId, scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)
Показанный выше метод используется для создания входного потока, который извлекает сообщения от Kafka Brokers.
-
ssc — объект StreamingContext.
-
zkQuorum — Кворум Зоопарка .
-
groupId — идентификатор группы для этого потребителя.
-
themes — вернуть карту тем для потребления.
-
storageLevel — уровень хранилища, используемый для хранения полученных объектов.
ssc — объект StreamingContext.
zkQuorum — Кворум Зоопарка .
groupId — идентификатор группы для этого потребителя.
themes — вернуть карту тем для потребления.
storageLevel — уровень хранилища, используемый для хранения полученных объектов.
В API KafkaUtils есть еще один метод createDirectStream, который используется для создания входного потока, который напрямую извлекает сообщения из брокеров Kafka без использования какого-либо получателя. Этот поток может гарантировать, что каждое сообщение от Kafka будет включено в преобразования ровно один раз.
Пример приложения сделан в Scala. Чтобы скомпилировать приложение, пожалуйста, скачайте и установите sbt
, инструмент сборки scala (похож на maven). Основной код приложения представлен ниже.
import java.util.HashMap import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord} import org.apache.spark.SparkConf import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka._ object KafkaWordCount { def main(args: Array[String]) { if (args.length < 4) { System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>") System.exit(1) } val Array(zkQuorum, group, topics, numThreads) = args val sparkConf = new SparkConf().setAppName("KafkaWordCount") val ssc = new StreamingContext(sparkConf, Seconds(2)) ssc.checkpoint("checkpoint") val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2) val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1L)) .reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2) wordCounts.print() ssc.start() ssc.awaitTermination() } }
Сценарий сборки
Интеграция искра-кафка зависит от банки с искрой, потоковой искрой и искрой Kafka. Создайте новый файл build.sbt
и укажите детали приложения и его зависимость. Sbt
загрузит необходимый jar при компиляции и упаковке приложения.
name := "Spark Kafka Project" version := "1.0" scalaVersion := "2.10.5" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"
Компиляция / Упаковка
Выполните следующую команду, чтобы скомпилировать и упаковать файл jar приложения. Нам нужно отправить файл jar в консоль spark для запуска приложения.
sbt package
Отправка в Spark
Запустите интерфейс командной строки Kafka Producer (описанный в предыдущей главе), создайте новую тему под названием my-first-topic
и предоставьте несколько примеров сообщений, как показано ниже.
Another spark test message
Выполните следующую команду, чтобы отправить приложение в консоль spark.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming -kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark -kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>
Пример вывода этого приложения показан ниже.