Целью проекта Cassandra является обработка больших объемов данных на нескольких узлах без единой точки отказа. Cassandra имеет одноранговую распределенную систему по своим узлам, и данные распределяются по всем узлам в кластере.
-
Все узлы в кластере играют одинаковую роль. Каждый узел независим и одновременно связан с другими узлами.
-
Каждый узел в кластере может принимать запросы на чтение и запись независимо от того, где данные фактически находятся в кластере.
-
Когда узел выходит из строя, запросы на чтение / запись могут обслуживаться другими узлами в сети.
Все узлы в кластере играют одинаковую роль. Каждый узел независим и одновременно связан с другими узлами.
Каждый узел в кластере может принимать запросы на чтение и запись независимо от того, где данные фактически находятся в кластере.
Когда узел выходит из строя, запросы на чтение / запись могут обслуживаться другими узлами в сети.
Репликация данных в Кассандре
В Cassandra один или несколько узлов в кластере действуют как реплики для данного фрагмента данных. Если будет обнаружено, что некоторые узлы ответили устаревшим значением, Cassandra вернет самое последнее значение клиенту. После возврата самого последнего значения Cassandra выполняет восстановление в фоновом режиме, чтобы обновить устаревшие значения.
На следующем рисунке показано схематическое представление того, как Cassandra использует репликацию данных между узлами в кластере, чтобы гарантировать отсутствие единой точки отказа.
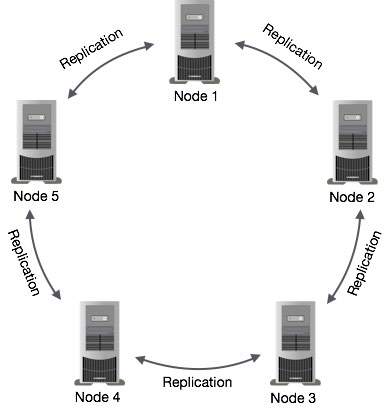
Примечание. Cassandra использует протокол Gossip в фоновом режиме, чтобы узлы могли обмениваться данными друг с другом и обнаруживать любые неисправные узлы в кластере.
Компоненты Кассандры
Ключевые компоненты Кассандры следующие:
-
Узел — это место, где хранятся данные.
-
Центр обработки данных — это совокупность связанных узлов.
-
Кластер . Кластер — это компонент, содержащий один или несколько центров обработки данных.
-
Журнал фиксации — Журнал фиксации — это механизм восстановления после сбоя в Cassandra. Каждая операция записи записывается в журнал фиксации.
-
Mem-таблица — Mem-таблица — это структура данных, хранящаяся в памяти. После фиксации, данные будут записаны в mem-таблицу. Иногда для семейства с одним столбцом может быть несколько таблиц памяти.
-
SSTable — это файл на диске, в который данные сбрасываются из таблицы памяти, когда его содержимое достигает порогового значения.
-
Фильтр Блума — это не более чем быстрые, недетерминированные алгоритмы для проверки того, является ли элемент членом набора. Это особый вид кеша. Фильтры Блума доступны после каждого запроса.
Узел — это место, где хранятся данные.
Центр обработки данных — это совокупность связанных узлов.
Кластер . Кластер — это компонент, содержащий один или несколько центров обработки данных.
Журнал фиксации — Журнал фиксации — это механизм восстановления после сбоя в Cassandra. Каждая операция записи записывается в журнал фиксации.
Mem-таблица — Mem-таблица — это структура данных, хранящаяся в памяти. После фиксации, данные будут записаны в mem-таблицу. Иногда для семейства с одним столбцом может быть несколько таблиц памяти.
SSTable — это файл на диске, в который данные сбрасываются из таблицы памяти, когда его содержимое достигает порогового значения.
Фильтр Блума — это не более чем быстрые, недетерминированные алгоритмы для проверки того, является ли элемент членом набора. Это особый вид кеша. Фильтры Блума доступны после каждого запроса.
Кассандра Query Language
Пользователи могут получить доступ к Cassandra через его узлы, используя Cassandra Query Language (CQL). CQL рассматривает базу данных (Keyspace) как контейнер таблиц. Программисты используют cqlsh: приглашение работать с CQL или отдельными драйверами языка приложения.
Клиенты обращаются к любому из узлов за своими операциями чтения-записи. Этот узел (координатор) воспроизводит прокси между клиентом и узлами, содержащими данные.
Операции записи
Каждая операция записи узлов фиксируется журналами фиксации, записанными в узлах. Позже данные будут записаны и сохранены в mem-таблице. Когда таблица mem заполнена, данные записываются в файл данных SStable . Все записи автоматически распределяются и реплицируются по всему кластеру. Кассандра периодически объединяет SSTables, отбрасывая ненужные данные.
Операции чтения
Во время операций чтения Cassandra получает значения из mem-таблицы и проверяет фильтр Блума, чтобы найти соответствующий SSTable, который содержит необходимые данные.