С 1970 года RDBMS является решением проблем хранения и обслуживания данных. После появления больших данных компании осознали преимущества обработки больших данных и стали выбирать такие решения, как Hadoop.
Hadoop использует распределенную файловую систему для хранения больших данных и MapReduce для их обработки. Hadoop отлично справляется с хранением и обработкой огромных данных различных форматов, таких как произвольные, полу- или даже неструктурированные.
Ограничения Hadoop
Hadoop может выполнять только пакетную обработку, а доступ к данным будет осуществляться только последовательно. Это означает, что нужно искать весь набор данных даже для самых простых заданий.
Огромный набор данных при обработке приводит к другому огромному набору данных, который также должен обрабатываться последовательно. На этом этапе требуется новое решение для доступа к любой точке данных за одну единицу времени (произвольный доступ).
Базы данных Hadoop с произвольным доступом
Такие приложения, как HBase, Cassandra, couchDB, Dynamo и MongoDB, являются одними из баз данных, которые хранят огромные объемы данных и осуществляют случайный доступ к данным.
Что такое HBase?
HBase — это распределенная столбцово-ориентированная база данных, построенная на основе файловой системы Hadoop. Это проект с открытым исходным кодом, который можно масштабировать по горизонтали.
HBase — это модель данных, похожая на большую таблицу Google, разработанную для обеспечения быстрого произвольного доступа к огромным объемам структурированных данных. Он использует отказоустойчивость, обеспечиваемую файловой системой Hadoop (HDFS).
Он является частью экосистемы Hadoop, которая обеспечивает случайный доступ в режиме реального времени для чтения / записи данных в файловой системе Hadoop.
Можно хранить данные в HDFS либо напрямую, либо через HBase. Потребитель данных читает / получает доступ к данным в HDFS случайным образом, используя HBase. HBase находится поверх файловой системы Hadoop и обеспечивает доступ для чтения и записи.
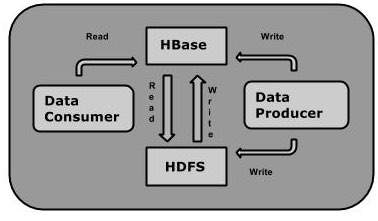
HBase и HDFS
| HDFS | HBase |
|---|---|
| HDFS — это распределенная файловая система, подходящая для хранения больших файлов. | HBase — это база данных, построенная на основе HDFS. |
| HDFS не поддерживает быстрый поиск отдельных записей. | HBase обеспечивает быстрый поиск для больших таблиц. |
| Это обеспечивает высокую задержку пакетной обработки; нет концепции пакетной обработки. | Он обеспечивает доступ с низкой задержкой к отдельным строкам из миллиардов записей (произвольный доступ). |
| Это обеспечивает только последовательный доступ к данным. | HBase внутренне использует хэш-таблицы и обеспечивает произвольный доступ, а также сохраняет данные в индексированных файлах HDFS для более быстрого поиска. |
Механизм хранения в HBase
HBase является базой данных, ориентированной на столбцы, и таблицы в ней сортируются по строкам. Схема таблицы определяет только семейства столбцов, которые являются парами ключ-значение. Таблица имеет несколько семейств столбцов, и каждое семейство столбцов может иметь любое количество столбцов. Последующие значения столбцов хранятся непрерывно на диске. Каждое значение ячейки таблицы имеет временную метку. Короче говоря, в HBase:
- Таблица представляет собой набор строк.
- Row — это коллекция семейств столбцов.
- Семейство столбцов — это коллекция столбцов.
- Столбец — это коллекция пар ключ-значение.
Ниже приведен пример схемы таблицы в HBase.
| RowId | Семейство колонн | Семейство колонн | Семейство колонн | Семейство колонн | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
Ориентированные на столбцы и ориентированные на строки
Базы данных, ориентированные на столбцы, — это базы данных, которые хранят таблицы данных как разделы столбцов данных, а не как строки данных. Вскоре у них будут семейства столбцов.
| Рядно-ориентированная база данных | Колонно-ориентированная база данных |
|---|---|
| Подходит для процесса онлайн-транзакций (OLTP). | Подходит для онлайн аналитической обработки (OLAP). |
| Такие базы данных рассчитаны на небольшое количество строк и столбцов. | Колонно-ориентированные базы данных предназначены для огромных таблиц. |
На следующем рисунке показаны семейства столбцов в базе данных, ориентированной на столбцы:
Apache HBase используется для произвольного доступа в режиме реального времени для чтения / записи больших данных.
Он размещает очень большие таблицы поверх кластеров товарного оборудования.
Apache HBase — это нереляционная база данных, созданная по образцу Google Bigtable. Bigtable работает в файловой системе Google, также Apache HBase работает поверх Hadoop и HDFS.