HBase — Обзор
С 1970 года RDBMS является решением проблем хранения и обслуживания данных. После появления больших данных компании осознали преимущества обработки больших данных и стали выбирать такие решения, как Hadoop.
Hadoop использует распределенную файловую систему для хранения больших данных и MapReduce для их обработки. Hadoop отлично справляется с хранением и обработкой огромных данных различных форматов, таких как произвольные, полу- или даже неструктурированные.
Ограничения Hadoop
Hadoop может выполнять только пакетную обработку, а доступ к данным будет осуществляться только последовательно. Это означает, что нужно искать весь набор данных даже для самых простых заданий.
Огромный набор данных при обработке приводит к другому огромному набору данных, который также должен обрабатываться последовательно. На этом этапе требуется новое решение для доступа к любой точке данных за одну единицу времени (произвольный доступ).
Базы данных Hadoop с произвольным доступом
Такие приложения, как HBase, Cassandra, couchDB, Dynamo и MongoDB, являются одними из баз данных, которые хранят огромные объемы данных и осуществляют случайный доступ к данным.
Что такое HBase?
HBase — это распределенная столбцово-ориентированная база данных, построенная на основе файловой системы Hadoop. Это проект с открытым исходным кодом, который можно масштабировать по горизонтали.
HBase — это модель данных, похожая на большую таблицу Google, разработанную для обеспечения быстрого произвольного доступа к огромным объемам структурированных данных. Он использует отказоустойчивость, обеспечиваемую файловой системой Hadoop (HDFS).
Он является частью экосистемы Hadoop, которая обеспечивает случайный доступ в режиме реального времени для чтения / записи данных в файловой системе Hadoop.
Можно хранить данные в HDFS либо напрямую, либо через HBase. Потребитель данных читает / получает доступ к данным в HDFS случайным образом, используя HBase. HBase находится поверх файловой системы Hadoop и обеспечивает доступ для чтения и записи.
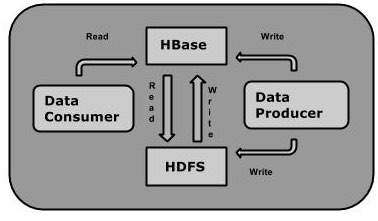
HBase и HDFS
| HDFS | HBase |
|---|---|
| HDFS — это распределенная файловая система, подходящая для хранения больших файлов. | HBase — это база данных, построенная на основе HDFS. |
| HDFS не поддерживает быстрый поиск отдельных записей. | HBase обеспечивает быстрый поиск для больших таблиц. |
| Это обеспечивает высокую задержку пакетной обработки; нет концепции пакетной обработки. | Он обеспечивает доступ с низкой задержкой к отдельным строкам из миллиардов записей (произвольный доступ). |
| Это обеспечивает только последовательный доступ к данным. | HBase внутренне использует хэш-таблицы и обеспечивает произвольный доступ, а также сохраняет данные в индексированных файлах HDFS для более быстрого поиска. |
Механизм хранения в HBase
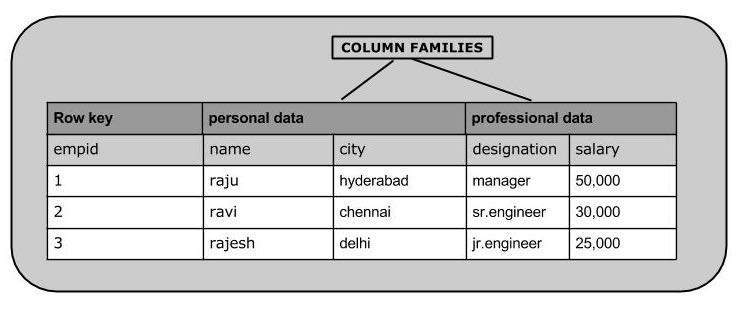
HBase является базой данных, ориентированной на столбцы, и таблицы в ней сортируются по строкам. Схема таблицы определяет только семейства столбцов, которые являются парами ключ-значение. Таблица имеет несколько семейств столбцов, и каждое семейство столбцов может иметь любое количество столбцов. Последующие значения столбцов хранятся непрерывно на диске. Каждое значение ячейки таблицы имеет временную метку. Короче говоря, в HBase:
- Таблица представляет собой набор строк.
- Row — это коллекция семейств столбцов.
- Семейство столбцов — это коллекция столбцов.
- Столбец — это коллекция пар ключ-значение.
Ниже приведен пример схемы таблицы в HBase.
| RowId | Семейство колонн | Семейство колонн | Семейство колонн | Семейство колонн | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
Ориентированные на столбцы и ориентированные на строки
Базы данных, ориентированные на столбцы, — это базы данных, которые хранят таблицы данных как разделы столбцов данных, а не как строки данных. Вскоре у них будут семейства столбцов.
| Рядно-ориентированная база данных | Колонно-ориентированная база данных |
|---|---|
| Подходит для процесса онлайн-транзакций (OLTP). | Подходит для онлайн аналитической обработки (OLAP). |
| Такие базы данных рассчитаны на небольшое количество строк и столбцов. | Колонно-ориентированные базы данных предназначены для огромных таблиц. |
На следующем рисунке показаны семейства столбцов в базе данных, ориентированной на столбцы:
HBase и RDBMS
| HBase | RDBMS |
|---|---|
| HBase не содержит схемы, не имеет понятия схемы с фиксированными столбцами; определяет только семейства столбцов. | СУБД регулируется своей схемой, которая описывает всю структуру таблиц. |
| Он построен для широких столов. HBase является горизонтально масштабируемым. | Это тонкий и построен для небольших столов. Трудно масштабировать. |
| В HBase нет транзакций. | СУБД является транзакционной. |
| Денормализованные данные. | Это будет иметь нормализованные данные. |
| Это хорошо для полуструктурированных, а также структурированных данных. | Это хорошо для структурированных данных. |
Особенности HBase
- HBase линейно масштабируется.
- Имеет автоматическую поддержку при сбоях.
- Это обеспечивает последовательное чтение и запись.
- Он интегрируется с Hadoop как в качестве источника, так и в качестве пункта назначения.
- У этого есть легкий API Java для клиента.
- Он обеспечивает репликацию данных по кластерам.
Где использовать HBase
-
Apache HBase используется для произвольного доступа в режиме реального времени для чтения / записи больших данных.
-
Он размещает очень большие таблицы поверх кластеров товарного оборудования.
-
Apache HBase — это нереляционная база данных, созданная по образцу Google Bigtable. Bigtable работает в файловой системе Google, также Apache HBase работает поверх Hadoop и HDFS.
Apache HBase используется для произвольного доступа в режиме реального времени для чтения / записи больших данных.
Он размещает очень большие таблицы поверх кластеров товарного оборудования.
Apache HBase — это нереляционная база данных, созданная по образцу Google Bigtable. Bigtable работает в файловой системе Google, также Apache HBase работает поверх Hadoop и HDFS.
Приложения HBase
- Он используется всякий раз, когда есть необходимость писать тяжелые приложения.
- HBase используется всякий раз, когда нам нужно обеспечить быстрый произвольный доступ к доступным данным.
- Такие компании, как Facebook, Twitter, Yahoo и Adobe, используют HBase для внутреннего использования.
История HBase
| Год | Событие |
|---|---|
| Ноя 2006 | Google выпустил статью на BigTable. |
| Февраль 2007 | Первоначальный прототип HBase был создан как вклад Hadoop. |
| Окт 2007 | Первый пригодный для использования HBase вместе с Hadoop 0.15.0 был выпущен. |
| Янв 2008 | HBase стал суб-проектом Hadoop. |
| Окт 2008 | HBase 0.18.1 был выпущен. |
| Янв 2009 | HBase 0.19.0 был выпущен. |
| Сентябрь 2009 | HBase 0.20.0 был выпущен. |
| Май 2010 | HBase стал проектом верхнего уровня Apache. |
HBase — Архитектура
В HBase таблицы разбиты на регионы и обслуживаются серверами регионов. Регионы разделены по столбцам по вертикали на «Магазины». Магазины сохраняются в виде файлов в HDFS. Ниже показана архитектура HBase.
Примечание . Термин «хранилище» используется для обозначения регионов для описания структуры хранилища.
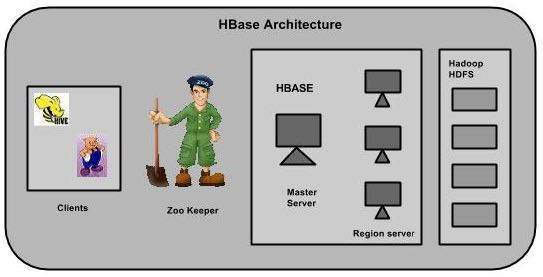
HBase состоит из трех основных компонентов: клиентской библиотеки, главного сервера и серверов региона. Региональные серверы могут быть добавлены или удалены в соответствии с требованием.
MasterServer
Главный сервер —
-
Назначает регионы на серверы регионов и использует Apache ZooKeeper для этой задачи.
-
Управляет балансировкой нагрузки регионов на серверах регионов. Он выгружает занятые серверы и перемещает регионы на менее занятые серверы.
-
Поддерживает состояние кластера путем согласования распределения нагрузки.
-
Отвечает за изменения схемы и другие операции с метаданными, такие как создание таблиц и семейств столбцов.
Назначает регионы на серверы регионов и использует Apache ZooKeeper для этой задачи.
Управляет балансировкой нагрузки регионов на серверах регионов. Он выгружает занятые серверы и перемещает регионы на менее занятые серверы.
Поддерживает состояние кластера путем согласования распределения нагрузки.
Отвечает за изменения схемы и другие операции с метаданными, такие как создание таблиц и семейств столбцов.
районы
Регионы — это не что иное, как таблицы, которые разбиты и распределены по серверам регионов.
Региональный сервер
Региональные серверы имеют регионы, которые —
- Общайтесь с клиентом и выполняйте операции, связанные с данными.
- Обрабатывать запросы на чтение и запись для всех регионов, находящихся под ним.
- Определите размер региона, следуя пороговым значениям размера региона.
Когда мы более подробно рассмотрим сервер регионов, он содержит регионы и хранилища, как показано ниже:
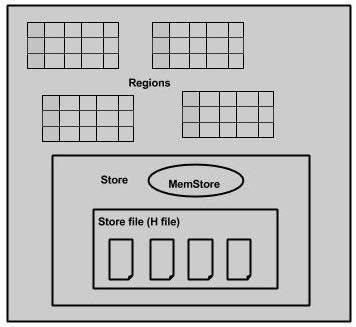
Магазин содержит память и память HFiles. Memstore — это как кеш-память. Все, что введено в HBase, изначально хранится здесь. Позже данные передаются и сохраняются в Hfiles в виде блоков, а хранилище метаданных сбрасывается.
Работник зоопарка
-
Zookeeper — это проект с открытым исходным кодом, который предоставляет такие услуги, как поддержка информации о конфигурации, присвоение имен, обеспечение распределенной синхронизации и т. Д.
-
Zookeeper имеет эфемерные узлы, представляющие разные региональные серверы. Главные серверы используют эти узлы для обнаружения доступных серверов.
-
В дополнение к доступности, узлы также используются для отслеживания сбоев сервера или сетевых разделов.
-
Клиенты общаются с региональными серверами через zookeeper.
-
В псевдо и автономных режимах HBase сам позаботится о зоопарке.
Zookeeper — это проект с открытым исходным кодом, который предоставляет такие услуги, как поддержка информации о конфигурации, присвоение имен, обеспечение распределенной синхронизации и т. Д.
Zookeeper имеет эфемерные узлы, представляющие разные региональные серверы. Главные серверы используют эти узлы для обнаружения доступных серверов.
В дополнение к доступности, узлы также используются для отслеживания сбоев сервера или сетевых разделов.
Клиенты общаются с региональными серверами через zookeeper.
В псевдо и автономных режимах HBase сам позаботится о зоопарке.
HBase — Установка
Эта глава объясняет, как HBase установлен и изначально настроен. Java и Hadoop необходимы для продолжения работы с HBase, поэтому вам необходимо загрузить и установить java и Hadoop в вашей системе.
Настройка перед установкой
Перед установкой Hadoop в среду Linux нам нужно настроить Linux с помощью ssh (Secure Shell). Следуйте приведенным ниже инструкциям для настройки среды Linux.
Создание пользователя
Прежде всего, рекомендуется создать отдельного пользователя для Hadoop, чтобы изолировать файловую систему Hadoop от файловой системы Unix. Следуйте инструкциям ниже, чтобы создать пользователя.
- Откройте корень с помощью команды «su».
- Создайте пользователя из учетной записи root с помощью команды «useradd username».
- Теперь вы можете открыть существующую учетную запись пользователя с помощью команды «su username».
Откройте терминал Linux и введите следующие команды, чтобы создать пользователя.
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
Настройка SSH и генерация ключей
Настройка SSH требуется для выполнения различных операций в кластере, таких как запуск, остановка и операции распределенной оболочки демона. Для аутентификации разных пользователей Hadoop требуется предоставить пару открытого / закрытого ключа для пользователя Hadoop и поделиться ею с разными пользователями.
Следующие команды используются для генерации пары ключ-значение с использованием SSH. Скопируйте открытые ключи из формы id_rsa.pub в author_keys и предоставьте владелец, права на чтение и запись в файл authorized_keys соответственно.
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
Проверьте SSH
ssh localhost
Установка Java
Java является основной предпосылкой для Hadoop и HBase. Прежде всего, вы должны проверить существование java в вашей системе, используя «java -version». Синтаксис команды версии Java приведен ниже.
$ java -version
Если все работает нормально, вы получите следующий вывод.
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если java не установлен в вашей системе, следуйте приведенным ниже инструкциям для установки java.
Шаг 1
Загрузите Java (JDK <последняя версия> — X64.tar.gz), перейдя по следующей ссылке Oracle Java .
Затем jdk-7u71-linux-x64.tar.gz будет загружен в вашу систему.
Шаг 2
Обычно вы найдете загруженный файл Java в папке Downloads. Проверьте его и извлеките файл jdk-7u71-linux-x64.gz, используя следующие команды.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Шаг 3
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Откройте root и введите следующие команды.
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
Шаг 4
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл ~ / .bashrc .
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH= $PATH:$JAVA_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 5
Используйте следующие команды для настройки альтернатив Java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
Теперь проверьте команду java -version из терминала, как описано выше.
Загрузка Hadoop
После установки Java вы должны установить Hadoop. Прежде всего, проверьте наличие Hadoop с помощью команды «Hadoop version», как показано ниже.
hadoop version
Если все работает нормально, вы получите следующий вывод.
Hadoop 2.6.0 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
Если ваша система не может найти Hadoop, загрузите Hadoop в свою систему. Следуйте приведенным ниже командам, чтобы сделать это.
Загрузите и извлеките hadoop-2.6.0 из Apache Software Foundation, используя следующие команды.
$ su password: # cd /usr/local # wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop- 2.6.0/hadoop-2.6.0-src.tar.gz # tar xzf hadoop-2.6.0-src.tar.gz # mv hadoop-2.6.0/* hadoop/ # exit
Установка Hadoop
Установите Hadoop в любом необходимом режиме. Здесь мы демонстрируем функциональность HBase в псевдораспределенном режиме, поэтому установите Hadoop в псевдораспределенном режиме.
Следующие шаги используются для установки Hadoop 2.4.1 .
Шаг 1 — Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc .
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 2 — Настройка Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Вам необходимо внести изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Чтобы разрабатывать программы Hadoop на языке java, необходимо сбросить переменную среды java в файле hadoop-env.sh , заменив значение JAVA_HOME местоположением java в вашей системе.
export JAVA_HOME=/usr/local/jdk1.7.0_71
Вам нужно будет отредактировать следующие файлы для настройки Hadoop.
ядро-site.xml
Файл core-site.xml содержит такую информацию, как номер порта, используемый для экземпляра Hadoop, память, выделенная для файловой системы, лимит памяти для хранения данных и размер буферов чтения / записи.
Откройте core-site.xml и добавьте следующие свойства между тегами <configuration> и </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
HDFS-site.xml
Файл hdfs-site.xml содержит такую информацию, как значение данных репликации, путь namenode и путь datanode ваших локальных файловых систем, где вы хотите хранить инфраструктуру Hadoop.
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства между тегами <configuration>, </ configuration>.
<configuration> <property> <name>dfs.replication</name > <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value> </property> </configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующее свойство между <configuration $ gt ;, </ configuration $ gt; теги в этом файле.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml
Этот файл используется, чтобы указать, какую платформу MapReduce мы используем. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего, необходимо скопировать файл из mapred-site.xml.template в файл mapred-site.xml с помощью следующей команды.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства между тегами <configuration> и </ configuration>.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1 — Настройка узла имени
Настройте namenode с помощью команды «hdfs namenode -format» следующим образом.
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Шаг 2 — Проверка Hadoop dfs
Следующая команда используется для запуска dfs. Выполнение этой команды запустит вашу файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий.
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Шаг 3 — Проверка скрипта пряжи
Следующая команда используется для запуска скрипта пряжи. Выполнение этой команды запустит ваши демоны пряжи.
$ start-yarn.sh
Ожидаемый результат следующий.
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Шаг 4 — Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop — 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в вашем браузере.
http://localhost:50070
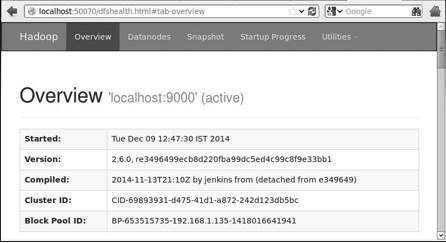
Шаг 5 — Проверьте все приложения кластера
Номер порта по умолчанию для доступа ко всем приложениям кластера — 8088. Используйте следующий URL для посещения этой службы.
http://localhost:8088/
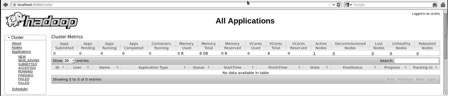
Установка HBase
Мы можем установить HBase в любом из трех режимов: автономный режим, псевдораспределенный режим и полностью распределенный режим.
Установка HBase в автономном режиме
Загрузите последнюю стабильную версию формы HBase http://www.interior-dsgn.com/apache/hbase/stable/ с помощью команды «wget» и извлеките ее с помощью команды tar «zxvf». Смотрите следующую команду.
$cd usr/local/ $wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8- hadoop2-bin.tar.gz $tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gz
Перейдите в режим суперпользователя и переместите папку HBase в / usr / local, как показано ниже.
$su $password: enter your password here mv hbase-0.99.1/* Hbase/
Настройка HBase в автономном режиме
Прежде чем продолжить работу с HBase, вы должны отредактировать следующие файлы и настроить HBase.
hbase-env.sh
Установите java Home для HBase и откройте файл hbase-env.sh из папки conf. Отредактируйте переменную среды JAVA_HOME и измените существующий путь на текущую переменную JAVA_HOME, как показано ниже.
cd /usr/local/Hbase/conf gedit hbase-env.sh
Это откроет файл env.sh HBase. Теперь замените существующее значение JAVA_HOME текущим значением, как показано ниже.
export JAVA_HOME=/usr/lib/jvm/java-1.7.0
HBase-site.xml
Это основной файл конфигурации HBase. Установите каталог данных в соответствующем месте, открыв домашнюю папку HBase в / usr / local / HBase. Внутри папки conf вы найдете несколько файлов, откройте файл hbase-site.xml, как показано ниже.
#cd /usr/local/HBase/ #cd conf # gedit hbase-site.xml
Внутри файла hbase-site.xml вы найдете теги <configuration> и </ configuration>. Внутри них установите каталог HBase под ключом свойства с именем «hbase.rootdir», как показано ниже.
<configuration> //Here you have to set the path where you want HBase to store its files. <property> <name>hbase.rootdir</name> <value>file:/home/hadoop/HBase/HFiles</value> </property> //Here you have to set the path where you want HBase to store its built in zookeeper files. <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/zookeeper</value> </property> </configuration>
На этом установка и настройка HBase успешно завершена. Мы можем запустить HBase, используя скрипт start-hbase.sh, который находится в папке bin HBase. Для этого откройте домашнюю папку HBase и запустите скрипт запуска HBase, как показано ниже.
$cd /usr/local/HBase/bin $./start-hbase.sh
Если все идет хорошо, при попытке запустить скрипт запуска HBase вам будет выдано сообщение о том, что HBase запущен.
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.out
Установка HBase в псевдораспределенном режиме
Давайте теперь проверим, как HBase установлен в псевдораспределенном режиме.
Конфигурирование HBase
Прежде чем продолжить работу с HBase, настройте Hadoop и HDFS в локальной или удаленной системе и убедитесь, что они работают. Остановите HBase, если он работает.
HBase-site.xml
Отредактируйте файл hbase-site.xml, чтобы добавить следующие свойства.
<property> <name>hbase.cluster.distributed</name> <value>true</value> </property>
Там будет указано, в каком режиме должен работать HBase. В том же файле из локальной файловой системы измените hbase.rootdir, ваш адрес экземпляра HDFS, используя синтаксис hdfs: //// URI. Мы запускаем HDFS на локальном хосте через порт 8030.
<property> <name>hbase.rootdir</name> <value>hdfs://localhost:8030/hbase</value> </property>
Запуск HBase
После завершения настройки перейдите в домашнюю папку HBase и запустите HBase с помощью следующей команды.
$cd /usr/local/HBase $bin/start-hbase.sh
Примечание. Перед запуском HBase убедитесь, что Hadoop запущен.
Проверка каталога HBase в HDFS
HBase создает свой каталог в HDFS. Чтобы увидеть созданный каталог, перейдите к Hadoop bin и введите следующую команду.
$ ./bin/hadoop fs -ls /hbase
Если все пойдет хорошо, вы получите следующий результат.
Found 7 items drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data -rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id -rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALs
Запуск и остановка мастера
Используя «local-master-backup.sh», вы можете запустить до 10 серверов. Откройте домашнюю папку HBase, master и выполните следующую команду, чтобы запустить ее.
$ ./bin/local-master-backup.sh 2 4
Чтобы уничтожить мастер резервного копирования, вам нужен его идентификатор процесса, который будет храниться в файле с именем «/tmp/hbase-USER-X-master.pid». Вы можете уничтожить мастер резервного копирования с помощью следующей команды.
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9
Запуск и остановка RegionServers
Вы можете запустить несколько серверов региона из одной системы, используя следующую команду.
$ .bin/local-regionservers.sh start 2 3
Чтобы остановить сервер региона, используйте следующую команду.
$ .bin/local-regionservers.sh stop 3
Запуск HBaseShell
После успешной установки HBase вы можете запустить HBase Shell. Ниже приведена последовательность шагов, которые необходимо выполнить для запуска оболочки HBase. Откройте терминал и войдите в систему как суперпользователь.
Запустить файловую систему Hadoop
Просмотрите домашнюю папку Hadoop sbin и запустите файловую систему Hadoop, как показано ниже.
$cd $HADOOP_HOME/sbin $start-all.sh
Запустить HBase
Просмотрите папку bin корневого каталога HBase и запустите HBase.
$cd /usr/local/HBase $./bin/start-hbase.sh
Запустите главный сервер HBase
Это будет тот же каталог. Запустите его, как показано ниже.
$./bin/local-master-backup.sh start 2 (number signifies specific server.)
Начальный регион
Запустите сервер региона, как показано ниже.
$./bin/./local-regionservers.sh start 3
Запустите HBase Shell
Вы можете запустить оболочку HBase, используя следующую команду.
$cd bin $./hbase shell
Это даст вам подсказку HBase Shell, как показано ниже.
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14 18:26:29 PST 2014 hbase(main):001:0>
Веб-интерфейс HBase
Чтобы получить доступ к веб-интерфейсу HBase, введите следующий URL-адрес в браузере.
http://localhost:60010
В этом интерфейсе отображаются текущие запущенные серверы регионов, мастера резервного копирования и таблицы HBase.
Серверы HBase Region и мастера резервного копирования
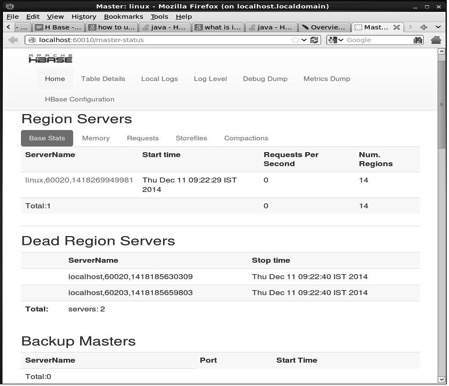
Таблицы HBase
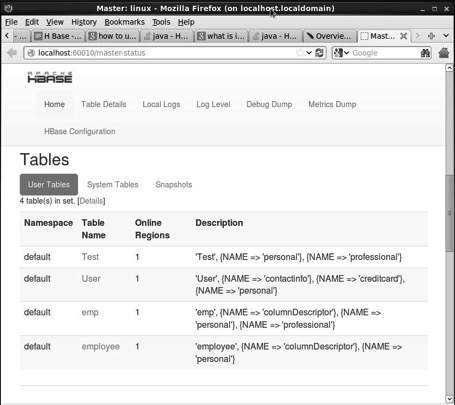
Настройка среды Java
Мы также можем связываться с HBase с помощью библиотек Java, но перед тем, как обращаться к HBase с помощью Java API, вам нужно установить classpath для этих библиотек.
Установка пути к классам
Прежде чем приступить к программированию, установите для classpath библиотеки HBase в файле .bashrc . Откройте .bashrc в любом из редакторов, как показано ниже.
$ gedit ~/.bashrc
Установите classpath для библиотек HBase (папка lib в HBase), как показано ниже.
export CLASSPATH = $CLASSPATH://home/hadoop/hbase/lib/*
Это сделано для предотвращения исключения «класс не найден» при доступе к HBase с использованием API Java.
HBase — Shell
В этой главе объясняется, как запустить интерактивную оболочку HBase, которая поставляется вместе с HBase.
HBase Shell
HBase содержит оболочку, с помощью которой вы можете общаться с HBase. HBase использует файловую систему Hadoop для хранения своих данных. Он будет иметь главный сервер и региональные серверы. Хранение данных будет в виде регионов (таблиц). Эти регионы будут разделены и сохранены на региональных серверах.
Главный сервер управляет этими серверами региона, и все эти задачи выполняются в HDFS. Ниже приведены некоторые команды, поддерживаемые HBase Shell.
Общие команды
-
status — Предоставляет статус HBase, например, количество серверов.
-
версия — Предоставляет версию используемого HBase.
-
table_help — Предоставляет справку для команд ссылки на таблицу.
-
whoami — предоставляет информацию о пользователе.
status — Предоставляет статус HBase, например, количество серверов.
версия — Предоставляет версию используемого HBase.
table_help — Предоставляет справку для команд ссылки на таблицу.
whoami — предоставляет информацию о пользователе.
Язык определения данных
Это команды, которые работают с таблицами в HBase.
-
создать — создает таблицу.
-
list — перечисляет все таблицы в HBase.
-
отключить — отключение таблицы.
-
is_disabled — проверяет, отключена ли таблица.
-
enable — включает таблицу.
-
is_enabled — проверяет, включена ли таблица.
-
Описание — Предоставляет описание таблицы.
-
alter — изменяет таблицу.
-
существующие — проверяет, существует ли таблица.
-
drop — Удаляет стол из HBase.
-
drop_all — удаляет таблицы, соответствующие ‘regex’, указанному в команде.
-
Java Admin API — Прежде чем все вышеперечисленные команды, Java предоставляет Admin API для достижения функциональных возможностей DDL посредством программирования. В пакете org.apache.hadoop.hbase.client HBaseAdmin и HTableDescriptor являются двумя важными классами в этом пакете, которые предоставляют функциональные возможности DDL.
создать — создает таблицу.
list — перечисляет все таблицы в HBase.
отключить — отключение таблицы.
is_disabled — проверяет, отключена ли таблица.
enable — включает таблицу.
is_enabled — проверяет, включена ли таблица.
Описание — Предоставляет описание таблицы.
alter — изменяет таблицу.
существующие — проверяет, существует ли таблица.
drop — Удаляет стол из HBase.
drop_all — удаляет таблицы, соответствующие ‘regex’, указанному в команде.
Java Admin API — Прежде чем все вышеперечисленные команды, Java предоставляет Admin API для достижения функциональных возможностей DDL посредством программирования. В пакете org.apache.hadoop.hbase.client HBaseAdmin и HTableDescriptor являются двумя важными классами в этом пакете, которые предоставляют функциональные возможности DDL.
Язык манипулирования данными
-
put — помещает значение ячейки в указанный столбец в указанной строке в определенной таблице.
-
get — извлекает содержимое строки или ячейки
-
delete — удаляет значение ячейки в таблице.
-
deleteall — удаляет все ячейки в данной строке.
-
scan — сканирует и возвращает данные таблицы.
-
count — считает и возвращает количество строк в таблице.
-
truncate — отключает, удаляет и воссоздает указанную таблицу.
-
Клиентский API-интерфейс Java. Перед всеми вышеупомянутыми командами Java предоставляет клиентский API-интерфейс для реализации функций DML, операций CRUD (Create Retrieve Update Delete) и многого другого посредством программирования в пакете org.apache.hadoop.hbase.client. HTable Put и Get являются важными классами в этом пакете.
put — помещает значение ячейки в указанный столбец в указанной строке в определенной таблице.
get — извлекает содержимое строки или ячейки
delete — удаляет значение ячейки в таблице.
deleteall — удаляет все ячейки в данной строке.
scan — сканирует и возвращает данные таблицы.
count — считает и возвращает количество строк в таблице.
truncate — отключает, удаляет и воссоздает указанную таблицу.
Клиентский API-интерфейс Java. Перед всеми вышеупомянутыми командами Java предоставляет клиентский API-интерфейс для реализации функций DML, операций CRUD (Create Retrieve Update Delete) и многого другого посредством программирования в пакете org.apache.hadoop.hbase.client. HTable Put и Get являются важными классами в этом пакете.
Запуск HBase Shell
Чтобы получить доступ к оболочке HBase, вы должны перейти в домашнюю папку HBase.
cd /usr/localhost/ cd Hbase
Вы можете запустить интерактивную оболочку HBase, используя команду «hbase shell», как показано ниже.
./bin/hbase shell
Если вы успешно установили HBase в своей системе, он выдаст подсказку оболочки HBase, как показано ниже.
HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.94.23, rf42302b28aceaab773b15f234aa8718fff7eea3c, Wed Aug 27 00:54:09 UTC 2014 hbase(main):001:0>
Чтобы выйти из интерактивной команды оболочки в любой момент, введите exit или используйте <ctrl + c>. Проверьте работу оболочки, прежде чем продолжить. Используйте команду list для этой цели. Список — это команда, используемая для получения списка всех таблиц в HBase. Прежде всего, проверьте установку и настройку HBase в вашей системе, используя эту команду, как показано ниже.
hbase(main):001:0> list
Когда вы вводите эту команду, она дает вам следующий вывод.
hbase(main):001:0> list TABLE
HBase — Общие команды
Основными командами в HBase являются status, version, table_help и whoami. Эта глава объясняет эти команды.
статус
Эта команда возвращает состояние системы, включая сведения о серверах, работающих в системе. Его синтаксис выглядит следующим образом:
hbase(main):009:0> status
Если вы выполните эту команду, она вернет следующий вывод.
hbase(main):009:0> status 3 servers, 0 dead, 1.3333 average load
версия
Эта команда возвращает версию HBase, используемую в вашей системе. Его синтаксис выглядит следующим образом:
hbase(main):010:0> version
Если вы выполните эту команду, она вернет следующий вывод.
hbase(main):009:0> version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14 18:26:29 PST 2014
table_help
Эта команда покажет вам, как и как использовать команды, на которые ссылаются таблицы. Ниже приведен синтаксис для использования этой команды.
hbase(main):02:0> table_help
При использовании этой команды отображаются разделы справки для команд, связанных с таблицами. Ниже приведен частичный вывод этой команды.
hbase(main):002:0> table_help Help for table-reference commands. You can either create a table via 'create' and then manipulate the table via commands like 'put', 'get', etc. See the standard help information for how to use each of these commands. However, as of 0.96, you can also get a reference to a table, on which you can invoke commands. For instance, you can get create a table and keep around a reference to it via: hbase> t = create 't', 'cf'…...
кто я
Эта команда возвращает пользовательские данные HBase. Если вы выполните эту команду, возвращает текущего пользователя HBase, как показано ниже.
hbase(main):008:0> whoami hadoop (auth:SIMPLE) groups: hadoop
HBase — Admin API
HBase написан на Java, поэтому он предоставляет API Java для связи с HBase. Java API — это самый быстрый способ связи с HBase. Ниже приведен API-интерфейс Java, на который ссылаются, который охватывает задачи, используемые для управления таблицами.
Класс HBaseAdmin
HBaseAdmin — это класс, представляющий администратора. Этот класс принадлежит пакету org.apache.hadoop.hbase.client . Используя этот класс, вы можете выполнять задачи администратора. Вы можете получить экземпляр Admin, используя метод Connection.getAdmin () .
Методы и описание
| S.No. | Методы и описание |
|---|---|
| 1 |
void createTable (HTableDescriptor desc) Создает новую таблицу. |
| 2 |
void createTable (HTableDescriptor desc, byte [] [] splitKeys) Создает новую таблицу с начальным набором пустых областей, определенных указанными разделенными ключами. |
| 3 |
void deleteColumn (byte [] tableName, String columnName) Удаляет столбец из таблицы. |
| 4 |
void deleteColumn (String tableName, String columnName) Удалить столбец из таблицы. |
| 5 |
void deleteTable (String tableName) Удаляет таблицу. |
void createTable (HTableDescriptor desc)
Создает новую таблицу.
void createTable (HTableDescriptor desc, byte [] [] splitKeys)
Создает новую таблицу с начальным набором пустых областей, определенных указанными разделенными ключами.
void deleteColumn (byte [] tableName, String columnName)
Удаляет столбец из таблицы.
void deleteColumn (String tableName, String columnName)
Удалить столбец из таблицы.
void deleteTable (String tableName)
Удаляет таблицу.
Дескриптор класса
Этот класс содержит сведения о таблице HBase, такие как:
- дескрипторы всех семейств столбцов,
- если таблица является каталожной таблицей,
- если таблица только для чтения,
- максимальный размер магазина mem,
- когда должен произойти раскол региона,
- сопроцессоры, связанные с ним и т. д.
Конструкторы
| S.No. | Конструктор и резюме |
|---|---|
| 1 |
HTableDescriptor (имя таблицы) Создает дескриптор таблицы, определяющий объект TableName. |
HTableDescriptor (имя таблицы)
Методы и описание
| S.No. | Методы и описание |
|---|---|
| 1 |
HTableDescriptor addFamily (семейство HColumnDescriptor) Добавляет семейство столбцов к данному дескриптору |
HTableDescriptor addFamily (семейство HColumnDescriptor)
Добавляет семейство столбцов к данному дескриптору
HBase — Создать таблицу
Создание таблицы с использованием HBase Shell
Вы можете создать таблицу с помощью команды create , здесь вы должны указать имя таблицы и имя семейства столбцов. Синтаксис для создания таблицы в оболочке HBase показан ниже.
create ‘<table name>’,’<column family>’
пример
Ниже приведен пример схемы таблицы с именем emp. Он имеет два семейства столбцов: «персональные данные» и «профессиональные данные».
| Ключ строки | личные данные | профессиональные данные |
|---|---|---|
Вы можете создать эту таблицу в оболочке HBase, как показано ниже.
hbase(main):002:0> create 'emp', 'personal data', 'professional data'
И это даст вам следующий вывод.
0 row(s) in 1.1300 seconds => Hbase::Table - emp
верификация
Вы можете проверить, создана ли таблица, используя команду list, как показано ниже. Здесь вы можете увидеть созданную таблицу emp.
hbase(main):002:0> list TABLE emp 2 row(s) in 0.0340 seconds
Создание таблицы с использованием API Java
Вы можете создать таблицу в HBase, используя метод createTable () класса HBaseAdmin . Этот класс принадлежит пакету org.apache.hadoop.hbase.client . Ниже приведены шаги по созданию таблицы в HBase с использованием API Java.
Шаг 1: создание HBaseAdmin
Этот класс требует объект конфигурации в качестве параметра, поэтому сначала создайте экземпляр класса конфигурации и передайте этот экземпляр HBaseAdmin.
Configuration conf = HBaseConfiguration.create(); HBaseAdmin admin = new HBaseAdmin(conf);
Шаг 2: Создать TableDescriptor
HTableDescriptor — это класс, который принадлежит классу org.apache.hadoop.hbase . Этот класс похож на контейнер имен таблиц и семейств столбцов.
//creating table descriptor
HTableDescriptor table = new HTableDescriptor(toBytes("Table name"));
//creating column family descriptor
HColumnDescriptor family = new HColumnDescriptor(toBytes("column family"));
//adding coloumn family to HTable
table.addFamily(family);
Шаг 3: Выполнить через Admin
Используя метод createTable () класса HBaseAdmin , вы можете выполнить созданную таблицу в режиме администратора.
admin.createTable(table);
Ниже приведена полная программа для создания таблицы через администратора.
import java.io.IOException; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.conf.Configuration; public class CreateTable { public static void main(String[] args) throws IOException { // Instantiating configuration class Configuration con = HBaseConfiguration.create(); // Instantiating HbaseAdmin class HBaseAdmin admin = new HBaseAdmin(con); // Instantiating table descriptor class HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("emp")); // Adding column families to table descriptor tableDescriptor.addFamily(new HColumnDescriptor("personal")); tableDescriptor.addFamily(new HColumnDescriptor("professional")); // Execute the table through admin admin.createTable(tableDescriptor); System.out.println(" Table created "); } }
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac CreateTable.java $java CreateTable
Следующее должно быть выводом:
Table created
HBase — Листинг Таблица
Отображение таблицы с использованием HBase Shell
list — это команда, которая используется для вывода списка всех таблиц в HBase. Ниже приведен синтаксис команды list.
hbase(main):001:0 > list
Когда вы набираете эту команду и выполняете ее в приглашении HBase, она отобразит список всех таблиц в HBase, как показано ниже.
hbase(main):001:0> list TABLE emp
Здесь вы можете увидеть таблицу с именем emp.
Список таблиц с использованием Java API
Следуйте приведенным ниже инструкциям, чтобы получить список таблиц из HBase с использованием Java-API.
Шаг 1
У вас есть метод listTables () в классе HBaseAdmin, чтобы получить список всех таблиц в HBase. Этот метод возвращает массив объектов HTableDescriptor .
//creating a configuration object Configuration conf = HBaseConfiguration.create(); //Creating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf); //Getting all the list of tables using HBaseAdmin object HTableDescriptor[] tableDescriptor = admin.listTables();
Шаг 2
Вы можете получить длину массива HTableDescriptor [], используя переменную длины класса HTableDescriptor . Получить имя таблицы из этого объекта, используя метод getNameAsString () . Запустите цикл ‘for’, используя их, и получите список таблиц в HBase.
Ниже приведена программа для вывода списка всех таблиц в HBase с использованием Java API.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ListTables {
public static void main(String args[])throws MasterNotRunningException, IOException{
// Instantiating a configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();
// printing all the table names.
for (int i=0; i<tableDescriptor.length;i++ ){
System.out.println(tableDescriptor[i].getNameAsString());
}
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac ListTables.java $java ListTables
Следующее должно быть выводом:
User emp
HBase — отключение таблицы
Отключение таблицы с помощью HBase Shell
Чтобы удалить таблицу или изменить ее настройки, необходимо сначала отключить таблицу с помощью команды отключения. Вы можете включить его, используя команду enable.
Ниже приведен синтаксис для отключения таблицы:
disable ‘emp’
пример
Ниже приведен пример, который показывает, как отключить таблицу.
hbase(main):025:0> disable 'emp' 0 row(s) in 1.2760 seconds
верификация
После отключения таблицы вы все еще можете ощутить ее существование с помощью команд list и существующие . Вы не можете отсканировать это. Это даст вам следующую ошибку.
hbase(main):028:0> scan 'emp' ROW COLUMN + CELL ERROR: emp is disabled.
выключен
Эта команда используется для определения, отключена ли таблица. Его синтаксис выглядит следующим образом.
hbase> is_disabled 'table name'
В следующем примере проверяется, отключена ли таблица с именем emp. Если он отключен, он вернет true, а если нет, то вернет false.
hbase(main):031:0> is_disabled 'emp' true 0 row(s) in 0.0440 seconds
отключить все
Эта команда используется для отключения всех таблиц, соответствующих данному регулярному выражению. Синтаксис команды disable_all приведен ниже.
hbase> disable_all 'r.*'
Предположим, что в HBase есть 5 таблиц, а именно: раджа, раджани, раджендра, раджеш и раджу. Следующий код отключит все таблицы, начинающиеся с raj.
hbase(main):002:07> disable_all 'raj.*' raja rajani rajendra rajesh raju Disable the above 5 tables (y/n)? y 5 tables successfully disabled
Отключить таблицу с помощью Java API
Чтобы проверить, отключена ли таблица, используется метод isTableDisabled (), а для отключения таблицы — метод disableTable () . Эти методы принадлежат классу HBaseAdmin . Следуйте приведенным ниже инструкциям, чтобы отключить таблицу.
Шаг 1
Создайте класс HBaseAdmin, как показано ниже.
// Creating configuration object Configuration conf = HBaseConfiguration.create(); // Creating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf);
Шаг 2
Убедитесь, что таблица отключена, используя метод isTableDisabled (), как показано ниже.
Boolean b = admin.isTableDisabled("emp");
Шаг 3
Если таблица не отключена, отключите ее, как показано ниже.
if(!b){
admin.disableTable("emp");
System.out.println("Table disabled");
}
Ниже приведена полная программа для проверки, отключена ли таблица; если нет, то как это отключить.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DisableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying weather the table is disabled
Boolean bool = admin.isTableDisabled("emp");
System.out.println(bool);
// Disabling the table using HBaseAdmin object
if(!bool){
admin.disableTable("emp");
System.out.println("Table disabled");
}
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac DisableTable.java $java DsiableTable
Следующее должно быть выводом:
false Table disabled
HBase — Включение таблицы
Включение таблицы с помощью HBase Shell
Синтаксис для включения таблицы:
enable ‘emp’
пример
Ниже приведен пример включения таблицы.
hbase(main):005:0> enable 'emp' 0 row(s) in 0.4580 seconds
верификация
После включения таблицы отсканируйте ее. Если вы видите схему, ваша таблица успешно включена.
hbase(main):006:0> scan 'emp' ROW COLUMN + CELL 1 column = personal data:city, timestamp = 1417516501, value = hyderabad 1 column = personal data:name, timestamp = 1417525058, value = ramu 1 column = professional data:designation, timestamp = 1417532601, value = manager 1 column = professional data:salary, timestamp = 1417524244109, value = 50000 2 column = personal data:city, timestamp = 1417524574905, value = chennai 2 column = personal data:name, timestamp = 1417524556125, value = ravi 2 column = professional data:designation, timestamp = 14175292204, value = sr:engg 2 column = professional data:salary, timestamp = 1417524604221, value = 30000 3 column = personal data:city, timestamp = 1417524681780, value = delhi 3 column = personal data:name, timestamp = 1417524672067, value = rajesh 3 column = professional data:designation, timestamp = 14175246987, value = jr:engg 3 column = professional data:salary, timestamp = 1417524702514, value = 25000 3 row(s) in 0.0400 seconds
включен
Эта команда используется для определения, включена ли таблица. Его синтаксис выглядит следующим образом:
hbase> is_enabled 'table name'
Следующий код проверяет, включена ли таблица с именем emp . Если он включен, он вернет true, а если нет, то вернет false.
hbase(main):031:0> is_enabled 'emp' true 0 row(s) in 0.0440 seconds
Включить таблицу с помощью Java API
Чтобы проверить, включена ли таблица, используется метод isTableEnabled () ; и для включения таблицы используется метод enableTable () . Эти методы принадлежат классу HBaseAdmin . Следуйте инструкциям ниже, чтобы включить таблицу.
Шаг 1
Создайте класс HBaseAdmin, как показано ниже.
// Creating configuration object Configuration conf = HBaseConfiguration.create(); // Creating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf);
Шаг 2
Проверьте, включена ли таблица с помощью метода isTableEnabled (), как показано ниже.
Boolean bool = admin.isTableEnabled("emp");
Шаг 3
Если таблица не отключена, отключите ее, как показано ниже.
if(!bool){
admin.enableTable("emp");
System.out.println("Table enabled");
}
Ниже приведена полная программа для проверки того, включена ли таблица, а если нет, то как ее включить.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class EnableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying whether the table is disabled
Boolean bool = admin.isTableEnabled("emp");
System.out.println(bool);
// Enabling the table using HBaseAdmin object
if(!bool){
admin.enableTable("emp");
System.out.println("Table Enabled");
}
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac EnableTable.java $java EnableTable
Следующее должно быть выводом:
false Table Enabled
HBase — Опишите и измените
описывать
Эта команда возвращает описание таблицы. Его синтаксис выглядит следующим образом:
hbase> describe 'table name'
Ниже приведен вывод команды description в таблицу emp .
hbase(main):006:0> describe 'emp'
DESCRIPTION
ENABLED
'emp', {NAME ⇒ 'READONLY', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER
⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒ 'NONE', VERSIONS ⇒
'1', TTL true
⇒ 'FOREVER', MIN_VERSIONS ⇒ '0', KEEP_DELETED_CELLS ⇒ 'false',
BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME
⇒ 'personal
data', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW',
REPLICATION_SCOPE ⇒ '0', VERSIONS ⇒ '5', COMPRESSION ⇒ 'NONE',
MIN_VERSIONS ⇒ '0', TTL
⇒ 'FOREVER', KEEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536',
IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'professional
data', DATA_BLO
CK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0',
VERSIONS ⇒ '1', COMPRESSION ⇒ 'NONE', MIN_VERSIONS ⇒ '0', TTL ⇒
'FOREVER', K
EEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒
'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'table_att_unset',
DATA_BLOCK_ENCODING ⇒ 'NO
NE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒
'NONE', VERSIONS ⇒ '1', TTL ⇒ 'FOREVER', MIN_VERSIONS ⇒ '0',
KEEP_DELETED_CELLS
⇒ 'false', BLOCKSIZE ⇒ '6
изменять
Alter — команда, используемая для внесения изменений в существующую таблицу. С помощью этой команды вы можете изменить максимальное количество ячеек семейства столбцов, установить и удалить операторы области действия таблицы и удалить семейство столбцов из таблицы.
Изменение максимального количества ячеек семейства столбцов
Ниже приведен синтаксис для изменения максимального количества ячеек семейства столбцов.
hbase> alter 't1', NAME ⇒ 'f1', VERSIONS ⇒ 5
В следующем примере максимальное количество ячеек установлено на 5.
hbase(main):003:0> alter 'emp', NAME ⇒ 'personal data', VERSIONS ⇒ 5 Updating all regions with the new schema... 0/1 regions updated. 1/1 regions updated. Done. 0 row(s) in 2.3050 seconds
Операторы таблицы
Используя alter, вы можете устанавливать и удалять операторы области таблицы, такие как MAX_FILESIZE, READONLY, MEMSTORE_FLUSHSIZE, DEFERRED_LOG_FLUSH и т. Д.
Настройка только для чтения
Ниже приведен синтаксис, чтобы сделать таблицу только для чтения.
hbase>alter 't1', READONLY(option)
В следующем примере мы сделали таблицу emp доступной только для чтения.
hbase(main):006:0> alter 'emp', READONLY Updating all regions with the new schema... 0/1 regions updated. 1/1 regions updated. Done. 0 row(s) in 2.2140 seconds
Удаление Операторов Области Таблицы
Мы также можем удалить операторы области таблицы. Ниже приведен синтаксис для удаления «MAX_FILESIZE» из таблицы emp.
hbase> alter 't1', METHOD ⇒ 'table_att_unset', NAME ⇒ 'MAX_FILESIZE'
Удаление семейства столбцов
Используя alter, вы также можете удалить семейство столбцов. Ниже приведен синтаксис для удаления семейства столбцов с помощью alter.
hbase> alter ‘ table name ’, ‘delete’ ⇒ ‘ column family ’
Ниже приведен пример удаления семейства столбцов из таблицы emp.
Предположим, в HBase есть таблица с именем employee. Он содержит следующие данные:
hbase(main):006:0> scan 'employee' ROW COLUMN+CELL row1 column = personal:city, timestamp = 1418193767, value = hyderabad row1 column = personal:name, timestamp = 1418193806767, value = raju row1 column = professional:designation, timestamp = 1418193767, value = manager row1 column = professional:salary, timestamp = 1418193806767, value = 50000 1 row(s) in 0.0160 seconds
Теперь давайте удалим семейство столбцов с именем professional с помощью команды alter.
hbase(main):007:0> alter 'employee','delete'⇒'professional' Updating all regions with the new schema... 0/1 regions updated. 1/1 regions updated. Done. 0 row(s) in 2.2380 seconds
Теперь проверьте данные в таблице после внесения изменений. Обратите внимание, что столбец семейства «профессиональный» больше не существует, поскольку мы его удалили.
hbase(main):003:0> scan 'employee' ROW COLUMN + CELL row1 column = personal:city, timestamp = 14181936767, value = hyderabad row1 column = personal:name, timestamp = 1418193806767, value = raju 1 row(s) in 0.0830 seconds
Добавление семейства столбцов с использованием Java API
Вы можете добавить семейство столбцов в таблицу, используя метод addColumn () класса HBAseAdmin . Следуйте приведенным ниже инструкциям, чтобы добавить семейство столбцов в таблицу.
Шаг 1
Создайте класс HBaseAdmin .
// Instantiating configuration object Configuration conf = HBaseConfiguration.create(); // Instantiating HBaseAdmin class HBaseAdmin admin = new HBaseAdmin(conf);
Шаг 2
Метод addColumn () требует имя таблицы и объект класса HColumnDescriptor . Поэтому создайте экземпляр класса HColumnDescriptor . В свою очередь, конструктор HColumnDescriptor требует добавления имени семейства столбцов. Здесь мы добавляем семейство столбцов с именем «contactDetails» в существующую таблицу «employee».
// Instantiating columnDescriptor object
HColumnDescriptor columnDescriptor = new
HColumnDescriptor("contactDetails");
Шаг 3
Добавьте семейство столбцов, используя метод addColumn . Передайте имя таблицы и объект класса HColumnDescriptor в качестве параметров этому методу.
// Adding column family
admin.addColumn("employee", new HColumnDescriptor("columnDescriptor"));
Ниже приведена полная программа для добавления семейства столбцов к существующей таблице.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class AddColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Instantiating columnDescriptor class
HColumnDescriptor columnDescriptor = new HColumnDescriptor("contactDetails");
// Adding column family
admin.addColumn("employee", columnDescriptor);
System.out.println("coloumn added");
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac AddColumn.java $java AddColumn
Приведенная выше компиляция работает, только если вы указали путь к классу в « .bashrc ». Если вы этого не сделали, следуйте приведенной ниже процедуре, чтобы скомпилировать файл .java.
//if "/home/home/hadoop/hbase " is your Hbase home folder then. $javac -cp /home/hadoop/hbase/lib/*: Demo.java
Если все пойдет хорошо, он выдаст следующий вывод:
column added
Удаление семейства столбцов с помощью Java API
Вы можете удалить семейство столбцов из таблицы, используя метод deleteColumn () класса HBAseAdmin . Следуйте приведенным ниже инструкциям, чтобы добавить семейство столбцов в таблицу.
Шаг 1
Создайте класс HBaseAdmin .
// Instantiating configuration object Configuration conf = HBaseConfiguration.create(); // Instantiating HBaseAdmin class HBaseAdmin admin = new HBaseAdmin(conf);
Шаг 2
Добавьте семейство столбцов, используя метод deleteColumn () . Передайте имя таблицы и имя семейства столбцов в качестве параметров этому методу.
// Deleting column family
admin.deleteColumn("employee", "contactDetails");
Ниже приведена полная программа для удаления семейства столбцов из существующей таблицы.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Deleting a column family
admin.deleteColumn("employee","contactDetails");
System.out.println("coloumn deleted");
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac DeleteColumn.java $java DeleteColumn
Следующее должно быть выводом:
column deleted
HBase — существует
Наличие таблицы с использованием HBase Shell
Вы можете проверить существование таблицы, используя команду существующие . В следующем примере показано, как использовать эту команду.
hbase(main):024:0> exists 'emp' Table emp does exist 0 row(s) in 0.0750 seconds ================================================================== hbase(main):015:0> exists 'student' Table student does not exist 0 row(s) in 0.0480 seconds
Проверка существования таблицы с помощью Java API
Вы можете проверить существование таблицы в HBase, используя метод tableExists () класса HBaseAdmin . Выполните шаги, приведенные ниже, чтобы проверить существование таблицы в HBase.
Шаг 1
Instantiate the HBaseAdimn class // Instantiating configuration object Configuration conf = HBaseConfiguration.create(); // Instantiating HBaseAdmin class HBaseAdmin admin = new HBaseAdmin(conf);
Шаг 2
Проверьте существование таблицы с помощью метода tableExists () .
Ниже приведена Java-программа для проверки существования таблицы в HBase с использованием Java-API.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class TableExists{
public static void main(String args[])throws IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying the existance of the table
boolean bool = admin.tableExists("emp");
System.out.println( bool);
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac TableExists.java $java TableExists
Следующее должно быть выводом:
true
HBase — сбросить таблицу
Отбрасывание таблицы с помощью HBase Shell
Используя команду drop , вы можете удалить таблицу. Прежде чем бросить стол, вы должны отключить его.
hbase(main):018:0> disable 'emp' 0 row(s) in 1.4580 seconds hbase(main):019:0> drop 'emp' 0 row(s) in 0.3060 seconds
Убедитесь, что таблица удалена с помощью команды Существует.
hbase(main):020:07gt; exists 'emp' Table emp does not exist 0 row(s) in 0.0730 seconds
drop_all
Эта команда используется для удаления таблиц, соответствующих «регулярному выражению», данному в команде. Его синтаксис выглядит следующим образом:
hbase> drop_all ‘t.*’
Примечание: перед тем, как бросить стол, вы должны отключить его.
пример
Предположим, есть таблицы с именами раджа, раджани, раджендра, раджеш и раджу.
hbase(main):017:0> list TABLE raja rajani rajendra rajesh raju 9 row(s) in 0.0270 seconds
Все эти таблицы начинаются с букв raj . Прежде всего, давайте отключим все эти таблицы с помощью команды disable_all, как показано ниже.
hbase(main):002:0> disable_all 'raj.*' raja rajani rajendra rajesh raju Disable the above 5 tables (y/n)? y 5 tables successfully disabled
Теперь вы можете удалить их все с помощью команды drop_all, как указано ниже.
hbase(main):018:0> drop_all 'raj.*' raja rajani rajendra rajesh raju Drop the above 5 tables (y/n)? y 5 tables successfully dropped
Удаление таблицы с использованием Java API
Вы можете удалить таблицу с помощью метода deleteTable () в классе HBaseAdmin . Следуйте приведенным ниже инструкциям, чтобы удалить таблицу с помощью API Java.
Шаг 1
Создайте класс HBaseAdmin.
// creating a configuration object Configuration conf = HBaseConfiguration.create(); // Creating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf);
Шаг 2
Отключите таблицу с помощью метода disableTable () класса HBaseAdmin .
admin.disableTable("emp1");
Шаг 3
Теперь удалите таблицу, используя метод deleteTable () класса HBaseAdmin .
admin.deleteTable("emp12");
Ниже приведена полная Java-программа для удаления таблицы в HBase.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// disabling table named emp
admin.disableTable("emp12");
// Deleting emp
admin.deleteTable("emp12");
System.out.println("Table deleted");
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac DeleteTable.java $java DeleteTable
Следующее должно быть выводом:
Table deleted
HBase — выключение
выход
Вы выходите из оболочки, набирая команду выхода .
hbase(main):021:0> exit
Остановка HBase
Чтобы остановить HBase, перейдите в домашнюю папку HBase и введите следующую команду.
./bin/stop-hbase.sh
Остановка HBase с использованием Java API
Вы можете выключить HBase, используя метод shutdown () класса HBaseAdmin . Следуйте инструкциям ниже, чтобы выключить HBase:
Шаг 1
Создайте экземпляр класса HbaseAdmin.
// Instantiating configuration object Configuration conf = HBaseConfiguration.create(); // Instantiating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf);
Шаг 2
Завершите работу HBase с помощью метода shutdown () класса HBaseAdmin .
admin.shutdown();
Ниже приведена программа для остановки HBase.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ShutDownHbase{
public static void main(String args[])throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Shutting down HBase
System.out.println("Shutting down hbase");
admin.shutdown();
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac ShutDownHbase.java $java ShutDownHbase
Следующее должно быть выводом:
Shutting down hbase
HBase — клиентский API
В этой главе описывается клиентский API Java для HBase, который используется для выполнения операций CRUD над таблицами HBase. HBase написан на Java и имеет собственный API Java. Поэтому он обеспечивает программный доступ к языку манипулирования данными (DML).
Конфигурация класса HBase
Добавляет файлы конфигурации HBase в конфигурацию. Этот класс принадлежит пакету org.apache.hadoop.hbase .
Методы и описание
| S.No. | Методы и описание |
|---|---|
| 1 |
статический org.apache.hadoop.conf.Configuration create () Этот метод создает конфигурацию с ресурсами HBase. |
статический org.apache.hadoop.conf.Configuration create ()
Этот метод создает конфигурацию с ресурсами HBase.
Класс HTable
HTable — это внутренний класс HBase, представляющий таблицу HBase. Это реализация таблицы, которая используется для связи с одной таблицей HBase. Этот класс принадлежит классу org.apache.hadoop.hbase.client .
Конструкторы
| S.No. | Конструкторы и описание |
|---|---|
| 1 |
HTable () |
| 2 |
HTable (TableName tableName, соединение ClusterConnection, пул ExecutorService) Используя этот конструктор, вы можете создать объект для доступа к таблице HBase. |
HTable ()
HTable (TableName tableName, соединение ClusterConnection, пул ExecutorService)
Используя этот конструктор, вы можете создать объект для доступа к таблице HBase.
Методы и описание
| S.No. | Методы и описание |
|---|---|
| 1 |
void close () Освобождает все ресурсы HTable. |
| 2 |
аннулировать удаление (Delete delete) Удаляет указанные ячейки / строки. |
| 3 |
логическое существует (Get Get) Используя этот метод, вы можете проверить наличие столбцов в таблице, как указано в Get. |
| 4 |
Результат получить (Получить получить) Извлекает определенные ячейки из данного ряда. |
| 5 |
org.apache.hadoop.conf.Configuration getConfiguration () Возвращает объект конфигурации, используемый этим экземпляром. |
| 6 |
TableName getName () Возвращает экземпляр имени таблицы этой таблицы. |
| 7 |
HTableDescriptor getTableDescriptor () Возвращает дескриптор таблицы для этой таблицы. |
| 8 |
byte [] getTableName () Возвращает имя этой таблицы. |
| 9 |
Пустота положить (положить положить) Используя этот метод, вы можете вставить данные в таблицу. |
void close ()
Освобождает все ресурсы HTable.
аннулировать удаление (Delete delete)
Удаляет указанные ячейки / строки.
логическое существует (Get Get)
Используя этот метод, вы можете проверить наличие столбцов в таблице, как указано в Get.
Результат получить (Получить получить)
Извлекает определенные ячейки из данного ряда.
org.apache.hadoop.conf.Configuration getConfiguration ()
Возвращает объект конфигурации, используемый этим экземпляром.
TableName getName ()
Возвращает экземпляр имени таблицы этой таблицы.
HTableDescriptor getTableDescriptor ()
Возвращает дескриптор таблицы для этой таблицы.
byte [] getTableName ()
Возвращает имя этой таблицы.
Пустота положить (положить положить)
Используя этот метод, вы можете вставить данные в таблицу.
Класс Путь
Этот класс используется для выполнения операций Put для одной строки. Он принадлежит пакету org.apache.hadoop.hbase.client .
Конструкторы
| S.No. | Конструкторы и описание |
|---|---|
| 1 |
Put (строка байта []) Используя этот конструктор, вы можете создать операцию Put для указанной строки. |
| 2 |
Put (byte [] rowArray, int rowOffset, int rowLength) Используя этот конструктор, вы можете сделать копию переданного ключа строки, чтобы сохранить его локальным. |
| 3 |
Put (byte [] rowArray, int rowOffset, int rowLength, long ts) Используя этот конструктор, вы можете сделать копию переданного ключа строки, чтобы сохранить его локальным. |
| 4 |
Put (byte [] row, long ts) Используя этот конструктор, мы можем создать операцию Put для указанной строки, используя данную временную метку. |
Put (строка байта [])
Используя этот конструктор, вы можете создать операцию Put для указанной строки.
Put (byte [] rowArray, int rowOffset, int rowLength)
Используя этот конструктор, вы можете сделать копию переданного ключа строки, чтобы сохранить его локальным.
Put (byte [] rowArray, int rowOffset, int rowLength, long ts)
Используя этот конструктор, вы можете сделать копию переданного ключа строки, чтобы сохранить его локальным.
Put (byte [] row, long ts)
Используя этот конструктор, мы можем создать операцию Put для указанной строки, используя данную временную метку.
методы
| S.No. | Методы и описание |
|---|---|
| 1 |
Положите add (семейство byte [], спецификатор byte [], значение byte []) Добавляет указанный столбец и значение к этой операции Put. |
| 2 |
Положите add (семейство byte [], спецификатор byte [], long ts, значение byte []) Добавляет указанный столбец и значение с указанной меткой времени в качестве версии для этой операции Put. |
| 3 |
Поместите add (семейство byte [], спецификатор ByteBuffer, long ts, значение ByteBuffer) Добавляет указанный столбец и значение с указанной меткой времени в качестве версии для этой операции Put. |
| 4 |
Поместите add (семейство byte [], спецификатор ByteBuffer, long ts, значение ByteBuffer) Добавляет указанный столбец и значение с указанной меткой времени в качестве версии для этой операции Put. |
Положите add (семейство byte [], спецификатор byte [], значение byte [])
Добавляет указанный столбец и значение к этой операции Put.
Положите add (семейство byte [], спецификатор byte [], long ts, значение byte [])
Добавляет указанный столбец и значение с указанной меткой времени в качестве версии для этой операции Put.
Поместите add (семейство byte [], спецификатор ByteBuffer, long ts, значение ByteBuffer)
Добавляет указанный столбец и значение с указанной меткой времени в качестве версии для этой операции Put.
Поместите add (семейство byte [], спецификатор ByteBuffer, long ts, значение ByteBuffer)
Добавляет указанный столбец и значение с указанной меткой времени в качестве версии для этой операции Put.
Класс Получить
Этот класс используется для выполнения операций Get в одной строке. Этот класс принадлежит пакету org.apache.hadoop.hbase.client .
Конструктор
| S.No. | Конструктор и описание |
|---|---|
| 1 |
Получить (строка байта []) Используя этот конструктор, вы можете создать операцию Get для указанной строки. |
| 2 | Получить (получить получить) |
Получить (строка байта [])
Используя этот конструктор, вы можете создать операцию Get для указанной строки.
методы
| S.No. | Методы и описание |
|---|---|
| 1 |
Получить addColumn (семейство byte [], спецификатор byte []) Извлекает столбец из определенного семейства с указанным квалификатором. |
| 2 |
Получить addFamily (семейство byte []) Извлекает все столбцы из указанного семейства. |
Получить addColumn (семейство byte [], спецификатор byte [])
Извлекает столбец из определенного семейства с указанным квалификатором.
Получить addFamily (семейство byte [])
Извлекает все столбцы из указанного семейства.
Класс Удалить
Этот класс используется для выполнения операций удаления в одной строке. Чтобы удалить всю строку, создайте экземпляр объекта Delete с удаляемой строкой. Этот класс принадлежит пакету org.apache.hadoop.hbase.client .
Конструктор
| S.No. | Конструктор и описание |
|---|---|
| 1 |
Удалить (строка байта []) Создает операцию удаления для указанной строки. |
| 2 |
Удалить (byte [] rowArray, int rowOffset, int rowLength) Создает операцию удаления для указанной строки и метки времени. |
| 3 |
Удалить (byte [] rowArray, int rowOffset, int rowLength, long ts) Создает операцию удаления для указанной строки и метки времени. |
| 4 |
Удалить (строка байта [], длинная метка времени) Создает операцию удаления для указанной строки и метки времени. |
Удалить (строка байта [])
Создает операцию удаления для указанной строки.
Удалить (byte [] rowArray, int rowOffset, int rowLength)
Создает операцию удаления для указанной строки и метки времени.
Удалить (byte [] rowArray, int rowOffset, int rowLength, long ts)
Создает операцию удаления для указанной строки и метки времени.
Удалить (строка байта [], длинная метка времени)
Создает операцию удаления для указанной строки и метки времени.
методы
| S.No. | Методы и описание |
|---|---|
| 1 |
Удалить addColumn (семейство byte [], спецификатор byte []) Удаляет последнюю версию указанного столбца. |
| 2 |
Удалить addColumns (семейство byte [], спецификатор byte [], длинная метка времени) Удаляет все версии указанного столбца с отметкой времени, меньшей или равной указанной отметке времени. |
| 3 |
Удалить addFamily (семейство byte []) Удаляет все версии всех столбцов указанного семейства. |
| 4 |
Удалить addFamily (семейство byte [], длинная метка времени) Удаляет все столбцы указанного семейства с отметкой времени, меньшей или равной указанной отметке времени. |
Удалить addColumn (семейство byte [], спецификатор byte [])
Удаляет последнюю версию указанного столбца.
Удалить addColumns (семейство byte [], спецификатор byte [], длинная метка времени)
Удаляет все версии указанного столбца с отметкой времени, меньшей или равной указанной отметке времени.
Удалить addFamily (семейство byte [])
Удаляет все версии всех столбцов указанного семейства.
Удалить addFamily (семейство byte [], длинная метка времени)
Удаляет все столбцы указанного семейства с отметкой времени, меньшей или равной указанной отметке времени.
Результат класса
Этот класс используется для получения результата одной строки запроса Get или Scan.
Конструкторы
| S.No. | Конструкторы |
|---|---|
| 1 |
Результат() Используя этот конструктор, вы можете создать пустой результат без полезной нагрузки KeyValue; возвращает ноль, если вы вызываете raw Cells (). |
Результат()
Используя этот конструктор, вы можете создать пустой результат без полезной нагрузки KeyValue; возвращает ноль, если вы вызываете raw Cells ().
методы
| S.No. | Методы и описание |
|---|---|
| 1 |
byte [] getValue (семейство byte [], спецификатор byte []) Этот метод используется для получения последней версии указанного столбца. |
| 2 |
byte [] getRow () Этот метод используется для получения ключа строки, соответствующего строке, из которой был создан этот результат. |
byte [] getValue (семейство byte [], спецификатор byte [])
Этот метод используется для получения последней версии указанного столбца.
byte [] getRow ()
Этот метод используется для получения ключа строки, соответствующего строке, из которой был создан этот результат.
HBase — Создание данных
Вставка данных с помощью HBase Shell
Эта глава демонстрирует, как создавать данные в таблице HBase. Для создания данных в таблице HBase используются следующие команды и методы:
-
поставить команду,
-
метод add () класса Put и
-
Метод put () класса HTable .
поставить команду,
метод add () класса Put и
Метод put () класса HTable .
В качестве примера, мы собираемся создать следующую таблицу в HBase.
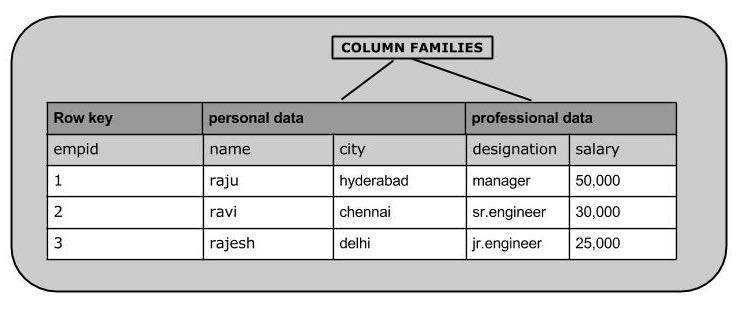
Используя команду put , вы можете вставить строки в таблицу. Его синтаксис выглядит следующим образом:
put ’<table name>’,’row1’,’<colfamily:colname>’,’<value>’
Вставка первой строки
Давайте вставим значения первой строки в таблицу emp, как показано ниже.
hbase(main):005:0> put 'emp','1','personal data:name','raju' 0 row(s) in 0.6600 seconds hbase(main):006:0> put 'emp','1','personal data:city','hyderabad' 0 row(s) in 0.0410 seconds hbase(main):007:0> put 'emp','1','professional data:designation','manager' 0 row(s) in 0.0240 seconds hbase(main):007:0> put 'emp','1','professional data:salary','50000' 0 row(s) in 0.0240 seconds
Вставьте оставшиеся строки, используя команду put таким же образом. Если вы вставите всю таблицу, вы получите следующий результат.
hbase(main):022:0> scan 'emp' ROW COLUMN+CELL 1 column=personal data:city, timestamp=1417524216501, value=hyderabad 1 column=personal data:name, timestamp=1417524185058, value=ramu 1 column=professional data:designation, timestamp=1417524232601, value=manager 1 column=professional data:salary, timestamp=1417524244109, value=50000 2 column=personal data:city, timestamp=1417524574905, value=chennai 2 column=personal data:name, timestamp=1417524556125, value=ravi 2 column=professional data:designation, timestamp=1417524592204, value=sr:engg 2 column=professional data:salary, timestamp=1417524604221, value=30000 3 column=personal data:city, timestamp=1417524681780, value=delhi 3 column=personal data:name, timestamp=1417524672067, value=rajesh 3 column=professional data:designation, timestamp=1417524693187, value=jr:engg 3 column=professional data:salary, timestamp=1417524702514, value=25000
Вставка данных с использованием Java API
Вы можете вставить данные в Hbase, используя метод add () класса Put . Вы можете сохранить его, используя метод put () класса HTable . Эти классы принадлежат пакету org.apache.hadoop.hbase.client . Ниже приведены шаги для создания данных в таблице HBase.
Шаг 1: Создание класса конфигурации
Класс Configuration добавляет файлы конфигурации HBase к своему объекту. Вы можете создать объект конфигурации с помощью метода create () класса HbaseConfiguration, как показано ниже.
Configuration conf = HbaseConfiguration.create();
Шаг 2: Создание класса HTable
У вас есть класс HTable , реализация Table в HBase. Этот класс используется для связи с одной таблицей HBase. При создании экземпляра этого класса он принимает объект конфигурации и имя таблицы в качестве параметров. Вы можете создать экземпляр класса HTable, как показано ниже.
HTable hTable = new HTable(conf, tableName);
Шаг 3: Создание PutClass
Для вставки данных в таблицу HBase используется метод add () и его варианты. Этот метод принадлежит Put , поэтому создайте экземпляр класса put. Этот класс требует имя строки, в которую вы хотите вставить данные, в строковом формате. Вы можете создать экземпляр класса Put, как показано ниже.
Put p = new Put(Bytes.toBytes("row1"));
Шаг 4: Вставить данные
Метод add () класса Put используется для вставки данных. Требуются 3-байтовые массивы, представляющие семейство столбцов, квалификатор столбца (имя столбца) и значение для вставки, соответственно. Вставьте данные в таблицу HBase, используя метод add (), как показано ниже.
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));
Шаг 5: сохранить данные в таблице
После вставки необходимых строк сохраните изменения, добавив экземпляр put в метод put () класса HTable, как показано ниже.
hTable.put(p);
Шаг 6: Закройте экземпляр HTable
После создания данных в таблице HBase закройте экземпляр HTable с помощью метода close (), как показано ниже.
hTable.close();
Ниже приведена полная программа для создания данных в HBase Table.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
// accepts a row name.
Put p = new Put(Bytes.toBytes("row1"));
// adding values using add() method
// accepts column family name, qualifier/row name ,value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("name"),Bytes.toBytes("raju"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("hyderabad"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("designation"),
Bytes.toBytes("manager"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("salary"),
Bytes.toBytes("50000"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data inserted");
// closing HTable
hTable.close();
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac InsertData.java $java InsertData
Следующее должно быть выводом:
data inserted
HBase — обновить данные
Обновление данных с помощью HBase Shell
Вы можете обновить существующее значение ячейки, используя команду put . Для этого просто следуйте тому же синтаксису и укажите новое значение, как показано ниже.
put ‘table name’,’row ’,'Column family:column name',’new value’
Вновь данное значение заменяет существующее значение, обновляя строку.
пример
Предположим, что в HBase есть таблица emp со следующими данными.
hbase(main):003:0> scan 'emp' ROW COLUMN + CELL row1 column = personal:name, timestamp = 1418051555, value = raju row1 column = personal:city, timestamp = 1418275907, value = Hyderabad row1 column = professional:designation, timestamp = 14180555,value = manager row1 column = professional:salary, timestamp = 1418035791555,value = 50000 1 row(s) in 0.0100 seconds
Следующая команда обновит значение города сотрудника по имени Раджу до Дели.
hbase(main):002:0> put 'emp','row1','personal:city','Delhi' 0 row(s) in 0.0400 seconds
Обновленная таблица выглядит следующим образом: вы можете увидеть, что город Раджу был изменен на «Дели».
hbase(main):003:0> scan 'emp' ROW COLUMN + CELL row1 column = personal:name, timestamp = 1418035791555, value = raju row1 column = personal:city, timestamp = 1418274645907, value = Delhi row1 column = professional:designation, timestamp = 141857555,value = manager row1 column = professional:salary, timestamp = 1418039555, value = 50000 1 row(s) in 0.0100 seconds
Обновление данных с использованием Java API
Вы можете обновить данные в определенной ячейке, используя метод put () . Следуйте приведенным ниже инструкциям, чтобы обновить существующее значение ячейки таблицы.
Шаг 1: Создание класса конфигурации
Класс конфигурации добавляет файлы конфигурации HBase к своему объекту. Вы можете создать объект конфигурации с помощью метода create () класса HbaseConfiguration, как показано ниже.
Configuration conf = HbaseConfiguration.create();
Шаг 2: Создание класса HTable
У вас есть класс HTable , реализация Table в HBase. Этот класс используется для связи с одной таблицей HBase. При создании экземпляра этого класса он принимает объект конфигурации и имя таблицы в качестве параметров. Вы можете создать экземпляр класса HTable, как показано ниже.
HTable hTable = new HTable(conf, tableName);
Шаг 3: Создание класса Put
Для вставки данных в таблицу HBase используется метод add () и его варианты. Этот метод принадлежит Put , поэтому создайте экземпляр класса put . Этот класс требует имя строки, в которую вы хотите вставить данные, в строковом формате. Вы можете создать экземпляр класса Put, как показано ниже.
Put p = new Put(Bytes.toBytes("row1"));
Шаг 4: Обновите существующую ячейку
Метод add () класса Put используется для вставки данных. Требуются 3-байтовые массивы, представляющие семейство столбцов, квалификатор столбца (имя столбца) и значение для вставки, соответственно. Вставьте данные в таблицу HBase, используя метод add (), как показано ниже.
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));
Шаг 5: сохранить данные в таблице
После вставки необходимых строк сохраните изменения, добавив экземпляр put в метод put () класса HTable, как показано ниже.
hTable.put(p);
Шаг 6: Закройте экземпляр HTable
После создания данных в HBase Table закройте экземпляр HTable с помощью метода close (), как показано ниже.
hTable.close();
Ниже приведена полная программа для обновления данных в конкретной таблице.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class UpdateData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
//accepts a row name
Put p = new Put(Bytes.toBytes("row1"));
// Updating a cell value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data Updated");
// closing HTable
hTable.close();
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac UpdateData.java $java UpdateData
Следующее должно быть выводом:
data Updated
HBase — чтение данных
Чтение данных с использованием HBase Shell
Команда get и метод get () класса HTable используются для чтения данных из таблицы в HBase. Используя команду get , вы можете получить одну строку данных за раз. Его синтаксис выглядит следующим образом:
get ’<table name>’,’row1’
пример
В следующем примере показано, как использовать команду get. Давайте просканируем первую строку таблицы emp .
hbase(main):012:0> get 'emp', '1' COLUMN CELL personal : city timestamp = 1417521848375, value = hyderabad personal : name timestamp = 1417521785385, value = ramu professional: designation timestamp = 1417521885277, value = manager professional: salary timestamp = 1417521903862, value = 50000 4 row(s) in 0.0270 seconds
Чтение определенной колонки
Ниже приведен синтаксис для чтения определенного столбца с использованием метода get .
hbase> get 'table name', ‘rowid’, {COLUMN ⇒ ‘column family:column name ’}
пример
Ниже приведен пример для чтения определенного столбца в таблице HBase.
hbase(main):015:0> get 'emp', 'row1', {COLUMN ⇒ 'personal:name'}
COLUMN CELL
personal:name timestamp = 1418035791555, value = raju
1 row(s) in 0.0080 seconds
Чтение данных с использованием Java API
Чтобы прочитать данные из таблицы HBase, используйте метод get () класса HTable. Этот метод требует экземпляр класса Get . Следуйте приведенным ниже инструкциям, чтобы получить данные из таблицы HBase.
Шаг 1: Создание класса конфигурации
Класс конфигурации добавляет файлы конфигурации HBase к своему объекту. Вы можете создать объект конфигурации с помощью метода create () класса HbaseConfiguration, как показано ниже.
Configuration conf = HbaseConfiguration.create();
Шаг 2: Создание класса HTable
У вас есть класс HTable , реализация Table в HBase. Этот класс используется для связи с одной таблицей HBase. При создании экземпляра этого класса он принимает объект конфигурации и имя таблицы в качестве параметров. Вы можете создать экземпляр класса HTable, как показано ниже.
HTable hTable = new HTable(conf, tableName);
Шаг 3: Создание класса Get
Вы можете извлечь данные из таблицы HBase, используя метод get () класса HTable . Этот метод извлекает ячейку из данной строки. Требуется объект класса Get в качестве параметра. Создайте его, как показано ниже.
Get get = new Get(toBytes("row1"));
Шаг 4: Чтение данных
При получении данных вы можете получить одну строку по идентификатору, или получить набор строк по набору идентификаторов строк, или отсканировать всю таблицу или подмножество строк.
Вы можете получить данные таблицы HBase, используя варианты метода add в классе Get .
Чтобы получить определенный столбец из определенного семейства столбцов, используйте следующий метод.
get.addFamily(personal)
Чтобы получить все столбцы из определенного семейства столбцов, используйте следующий метод.
get.addColumn(personal, name)
Шаг 5: Получите результат
Получите результат, передав свой экземпляр класса Get методу get класса HTable . Этот метод возвращает объект класса Result , который содержит запрошенный результат. Ниже приведено использование метода get () .
Result result = table.get(g);
Шаг 6: чтение значений из экземпляра результата
Класс Result предоставляет метод getValue () для чтения значений из своего экземпляра. Используйте его, как показано ниже, чтобы прочитать значения из экземпляра Result .
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));
Ниже приведена полная программа для чтения значений из таблицы HBase.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
public class RetriveData{
public static void main(String[] args) throws IOException, Exception{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating Get class
Get g = new Get(Bytes.toBytes("row1"));
// Reading the data
Result result = table.get(g);
// Reading values from Result class object
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));
// Printing the values
String name = Bytes.toString(value);
String city = Bytes.toString(value1);
System.out.println("name: " + name + " city: " + city);
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac RetriveData.java $java RetriveData
Следующее должно быть выводом:
name: Raju city: Delhi
HBase — Удалить данные
Удаление определенной ячейки в таблице
Используя команду удаления , вы можете удалить определенную ячейку в таблице. Синтаксис команды удаления выглядит следующим образом:
delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’
пример
Вот пример для удаления определенной ячейки. Здесь мы удаляем зарплату.
hbase(main):006:0> delete 'emp', '1', 'personal data:city', 1417521848375 0 row(s) in 0.0060 seconds
Удаление всех ячеек в таблице
Используя команду «deleteall», вы можете удалить все ячейки подряд. Ниже приведен синтаксис команды deleteall.
deleteall ‘<table name>’, ‘<row>’,
пример
Вот пример команды «deleteall», где мы удаляем все ячейки строки 1 таблицы emp.
hbase(main):007:0> deleteall 'emp','1' 0 row(s) in 0.0240 seconds
Проверьте таблицу с помощью команды сканирования . Снимок таблицы после удаления таблицы приведен ниже.
hbase(main):022:0> scan 'emp' ROW COLUMN + CELL 2 column = personal data:city, timestamp = 1417524574905, value = chennai 2 column = personal data:name, timestamp = 1417524556125, value = ravi 2 column = professional data:designation, timestamp = 1417524204, value = sr:engg 2 column = professional data:salary, timestamp = 1417524604221, value = 30000 3 column = personal data:city, timestamp = 1417524681780, value = delhi 3 column = personal data:name, timestamp = 1417524672067, value = rajesh 3 column = professional data:designation, timestamp = 1417523187, value = jr:engg 3 column = professional data:salary, timestamp = 1417524702514, value = 25000
Удаление данных с использованием Java API
Вы можете удалить данные из таблицы HBase, используя метод delete () класса HTable . Следуйте приведенным ниже инструкциям, чтобы удалить данные из таблицы.
Шаг 1: Создание класса конфигурации
Класс конфигурации добавляет файлы конфигурации HBase к своему объекту. Вы можете создать объект конфигурации с помощью метода create () класса HbaseConfiguration, как показано ниже.
Configuration conf = HbaseConfiguration.create();
Шаг 2: Создание класса HTable
У вас есть класс HTable , реализация Table в HBase. Этот класс используется для связи с одной таблицей HBase. При создании экземпляра этого класса он принимает объект конфигурации и имя таблицы в качестве параметров. Вы можете создать экземпляр класса HTable, как показано ниже.
HTable hTable = new HTable(conf, tableName);
Шаг 3: Создание класса удаления
Создайте класс Delete , передав идентификатор строки, которая должна быть удалена, в формате байтового массива. Вы также можете передать метку времени и Rowlock этому конструктору.
Delete delete = new Delete(toBytes("row1"));
Шаг 4. Выберите данные для удаления
Вы можете удалить данные, используя методы удаления класса Delete . Этот класс имеет различные методы удаления. Выберите столбцы или семейства столбцов, которые будут удалены с помощью этих методов. Посмотрите на следующие примеры, которые показывают использование методов класса Delete.
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));
Шаг 5: Удалить данные
Удалите выбранные данные, передав экземпляр delete методу delete () класса HTable, как показано ниже.
table.delete(delete);
Шаг 6: Закройте HTableInstance
После удаления данных закройте экземпляр HTable .
table.close();
Ниже приведена полная программа для удаления данных из таблицы HBase.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.util.Bytes;
public class DeleteData {
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(conf, "employee");
// Instantiating Delete class
Delete delete = new Delete(Bytes.toBytes("row1"));
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));
// deleting the data
table.delete(delete);
// closing the HTable object
table.close();
System.out.println("data deleted.....");
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac Deletedata.java $java DeleteData
Следующее должно быть выводом:
data deleted
HBase — Сканирование
Сканирование с использованием HBase Shell
Команда сканирования используется для просмотра данных в HTable. Используя команду сканирования, вы можете получить данные таблицы. Его синтаксис выглядит следующим образом:
scan ‘<table name>’
пример
В следующем примере показано, как читать данные из таблицы с помощью команды сканирования. Здесь мы читаем таблицу emp .
hbase(main):010:0> scan 'emp' ROW COLUMN + CELL 1 column = personal data:city, timestamp = 1417521848375, value = hyderabad 1 column = personal data:name, timestamp = 1417521785385, value = ramu 1 column = professional data:designation, timestamp = 1417585277,value = manager 1 column = professional data:salary, timestamp = 1417521903862, value = 50000 1 row(s) in 0.0370 seconds
Сканирование с использованием Java API
Полная программа для сканирования всей таблицы данных с использованием Java API выглядит следующим образом.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating the Scan class
Scan scan = new Scan();
// Scanning the required columns
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("city"));
// Getting the scan result
ResultScanner scanner = table.getScanner(scan);
// Reading values from scan result
for (Result result = scanner.next(); result != null; result = Scanner.next())
System.out.println("Found row : " + result);
//closing the scanner
scanner.close();
}
}
Скомпилируйте и выполните вышеуказанную программу, как показано ниже.
$javac ScanTable.java $java ScanTable
Следующее должно быть выводом:
Found row :
keyvalues={row1/personal:city/1418275612888/Put/vlen=5/mvcc=0,
row1/personal:name/1418035791555/Put/vlen=4/mvcc=0}
HBase — считать и усекать
подсчитывать
Вы можете посчитать количество строк в таблице, используя команду count . Его синтаксис выглядит следующим образом:
count ‘<table name>’
После удаления первой строки таблица emp будет иметь две строки. Проверьте это, как показано ниже.
hbase(main):023:0> count 'emp' 2 row(s) in 0.090 seconds ⇒ 2
усекать
Эта команда отключает отбрасывание и воссоздает таблицу. Синтаксис усечения выглядит следующим образом:
hbase> truncate 'table name'
пример
Ниже приведен пример команды truncate. Здесь мы усекли таблицу emp .
hbase(main):011:0> truncate 'emp' Truncating 'one' table (it may take a while): - Disabling table... - Truncating table... 0 row(s) in 1.5950 seconds
После усечения таблицы используйте команду сканирования для проверки. Вы получите таблицу с нулевыми строками.
hbase(main):017:0> scan ‘emp’ ROW COLUMN + CELL 0 row(s) in 0.3110 seconds
HBase — Безопасность
Мы можем предоставлять и отзывать разрешения для пользователей в HBase. В целях безопасности существует три команды: grant, revoke и user_permission.
даровать
Команда grant предоставляет определенные права, такие как чтение, запись, выполнение и администратор таблицы, определенному пользователю. Синтаксис команды предоставления выглядит следующим образом:
hbase> grant <user> <permissions> [<table> [<column family> [<column; qualifier>]]
Мы можем предоставить пользователю ноль или более привилегий из набора RWXCA, где
- R — представляет привилегию чтения.
- W — представляет привилегию записи.
- X — представляет привилегию выполнения.
- C — представляет привилегию создания.
- A — представляет привилегию администратора.
Ниже приведен пример, который предоставляет все привилегии пользователю с именем «Tutorialspoint».
hbase(main):018:0> grant 'Tutorialspoint', 'RWXCA'
отзывать
Команда revoke используется для отзыва прав доступа пользователя к таблице. Его синтаксис выглядит следующим образом:
hbase> revoke <user>
Следующий код отменяет все разрешения от пользователя с именем «Tutorialspoint».
hbase(main):006:0> revoke 'Tutorialspoint'
user_permission
Эта команда используется для получения списка всех разрешений для конкретной таблицы. Синтаксис user_permission выглядит следующим образом:
hbase>user_permission ‘tablename’
В следующем коде перечислены все права пользователя таблицы emp.