Термин «Большие данные» используется для сбора больших наборов данных, которые включают огромный объем, высокую скорость и разнообразные данные, число которых увеличивается день ото дня. Используя традиционные системы управления данными, трудно обрабатывать большие данные. Поэтому Apache Software Foundation представил платформу Hadoop для решения задач управления и обработки больших данных.
Hadoop
Hadoop — это среда с открытым исходным кодом для хранения и обработки больших данных в распределенной среде. Он содержит два модуля: один — MapReduce, а другой — распределенную файловую систему Hadoop (HDFS).
-
MapReduce: это модель параллельного программирования для обработки больших объемов структурированных, полуструктурированных и неструктурированных данных на больших кластерах товарного оборудования.
-
HDFS: распределенная файловая система Hadoop является частью инфраструктуры Hadoop, используемой для хранения и обработки наборов данных. Он обеспечивает отказоустойчивую файловую систему для работы на обычном оборудовании.
MapReduce: это модель параллельного программирования для обработки больших объемов структурированных, полуструктурированных и неструктурированных данных на больших кластерах товарного оборудования.
HDFS: распределенная файловая система Hadoop является частью инфраструктуры Hadoop, используемой для хранения и обработки наборов данных. Он обеспечивает отказоустойчивую файловую систему для работы на обычном оборудовании.
Экосистема Hadoop содержит различные подпроекты (инструменты), такие как Sqoop, Pig и Hive, которые используются для помощи модулям Hadoop.
-
Sqoop: используется для импорта и экспорта данных между HDFS и RDBMS.
-
Свинья: Это процедурная языковая платформа, используемая для разработки скрипта для операций MapReduce.
-
Hive: это платформа, используемая для разработки сценариев типа SQL для выполнения операций MapReduce.
Sqoop: используется для импорта и экспорта данных между HDFS и RDBMS.
Свинья: Это процедурная языковая платформа, используемая для разработки скрипта для операций MapReduce.
Hive: это платформа, используемая для разработки сценариев типа SQL для выполнения операций MapReduce.
Примечание. Существуют различные способы выполнения операций MapReduce:
- Традиционный подход с использованием программы Java MapReduce для структурированных, полуструктурированных и неструктурированных данных.
- Подход сценариев для MapReduce для обработки структурированных и полуструктурированных данных с использованием Pig.
- Язык запросов Hive (HiveQL или HQL) для MapReduce для обработки структурированных данных с использованием Hive.
Что такое улей
Hive — это инструмент инфраструктуры хранилища данных для обработки структурированных данных в Hadoop. Он находится на вершине Hadoop для суммирования больших данных и упрощает запросы и анализ.
Изначально Hive разрабатывался Facebook, позже Apache Software Foundation взялся за него и развивал его как открытый исходный код под названием Apache Hive. Используется разными компаниями. Например, Amazon использует его в Amazon Elastic MapReduce.
Улей нет
- Реляционная база данных
- Проект для обработки транзакций OnLine (OLTP)
- Язык запросов в реальном времени и обновлений на уровне строк
Особенности Улья
- Он хранит схему в базе данных и обрабатывает данные в HDFS.
- Он предназначен для OLAP.
- Он предоставляет язык типов SQL для запросов, называемых HiveQL или HQL.
- Это знакомо, быстро, масштабируемо и расширяемо.
Архитектура улья
Следующая диаграмма компонентов изображает архитектуру Hive:
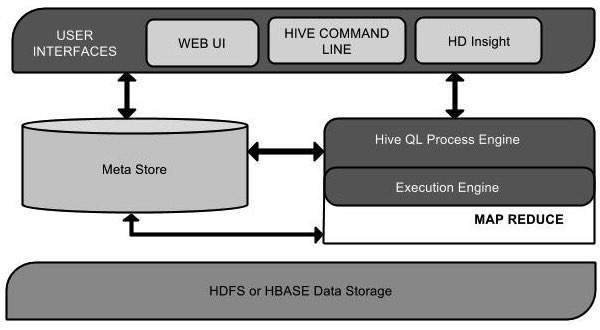
Эта диаграмма компонентов содержит различные единицы. Следующая таблица описывает каждую единицу:
| Название объекта | операция |
|---|---|
| Пользовательский интерфейс | Hive — это программное обеспечение инфраструктуры хранилища данных, которое может создавать взаимодействие между пользователем и HDFS. Пользовательские интерфейсы, которые поддерживает Hive: веб-интерфейс Hive, командная строка Hive и Hive HD Insight (на сервере Windows). |
| Мета Магазин | Hive выбирает соответствующие серверы баз данных для хранения схемы или метаданных таблиц, баз данных, столбцов в таблице, их типов данных и сопоставления HDFS. |
| HiveQL Process Engine | HiveQL аналогичен SQL для запроса информации о схеме в Metastore. Это одна из замен традиционного подхода к программе MapReduce. Вместо того, чтобы писать программу MapReduce на Java, мы можем написать запрос для задания MapReduce и обработать его. |
| Двигатель исполнения | Соединительной частью HiveQL Process Engine и MapReduce является Hive Execution Engine. Механизм выполнения обрабатывает запрос и генерирует результаты так же, как и результаты MapReduce. Он использует аромат MapReduce. |
| HDFS или HBASE | Распределенная файловая система Hadoop или HBASE — это методы хранения данных для хранения данных в файловой системе. |
Работа Улей
На следующей диаграмме показан рабочий процесс между Hive и Hadoop.
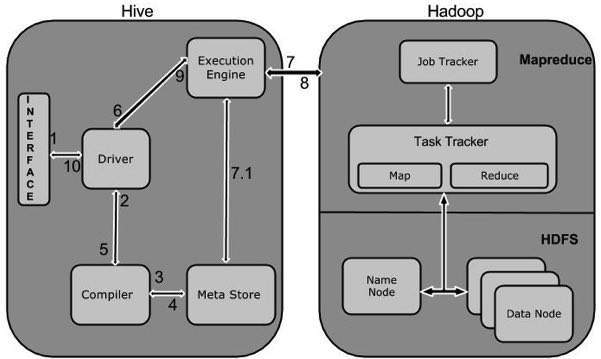
Следующая таблица определяет, как Hive взаимодействует с платформой Hadoop:
Интерфейс Hive, такой как командная строка или веб-интерфейс, отправляет запрос драйверу (любой драйвер базы данных, такой как JDBC, ODBC и т. Д.) Для выполнения.
Драйвер пользуется помощью компилятора запросов, который анализирует запрос, чтобы проверить синтаксис и план запроса или требование запроса.
Компилятор отправляет запрос метаданных в Metastore (любую базу данных).
Metastore отправляет метаданные как ответ компилятору.
Компилятор проверяет требование и отправляет план водителю. На этом разбор и компиляция запроса завершены.
Драйвер отправляет план выполнения в механизм выполнения.
Внутренне процесс выполнения задания является заданием MapReduce. Механизм выполнения отправляет задание в JobTracker, который находится в узле Name, и назначает это задание в TaskTracker, который находится в узле Data. Здесь запрос выполняет задание MapReduce.
Между тем во время выполнения механизм исполнения может выполнять операции метаданных с Metastore.
Механизм выполнения получает результаты от узлов данных.
Механизм выполнения отправляет эти результирующие значения драйверу.
Драйвер отправляет результаты в интерфейсы Hive.