Teradata — Введение
Teradata — одна из популярных систем управления реляционными базами данных. Он в основном подходит для создания крупномасштабных приложений хранилищ данных. Teradata достигает этого с помощью концепции параллелизма. Он разработан компанией под названием Teradata.
История Терадата
Ниже приведен краткий обзор истории Teradata с перечислением основных этапов.
-
1979 — Teradata была включена.
-
1984 — Выпуск первой базы данных компьютера DBC / 1012.
-
1986 — журнал Fortune назвал Teradata «Продуктом года».
-
1999 — Крупнейшая база данных в мире, использующая Teradata с 130 терабайтами.
-
2002 — выпущена Teradata V2R5 с первичным индексом раздела и сжатием.
-
2006 — запуск решения для управления основными данными Teradata.
-
2008 — выпущена Teradata 13.0 с активным хранилищем данных.
-
2011 — приобретает Teradata Aster и входит в Advanced Analytics Space.
-
2012 — представлена Teradata 14.0.
-
2014 — представлена версия Teradata 15.0.
1979 — Teradata была включена.
1984 — Выпуск первой базы данных компьютера DBC / 1012.
1986 — журнал Fortune назвал Teradata «Продуктом года».
1999 — Крупнейшая база данных в мире, использующая Teradata с 130 терабайтами.
2002 — выпущена Teradata V2R5 с первичным индексом раздела и сжатием.
2006 — запуск решения для управления основными данными Teradata.
2008 — выпущена Teradata 13.0 с активным хранилищем данных.
2011 — приобретает Teradata Aster и входит в Advanced Analytics Space.
2012 — представлена Teradata 14.0.
2014 — представлена версия Teradata 15.0.
Особенности Teradata
Ниже приведены некоторые особенности Teradata —
-
Неограниченный параллелизм — система баз данных Teradata основана на архитектуре массовой параллельной обработки (MPP). Архитектура MPP равномерно распределяет рабочую нагрузку по всей системе. Система Teradata распределяет задачу среди своих процессов и запускает их параллельно, чтобы обеспечить быстрое выполнение задачи.
-
Архитектура Shared Nothing — Архитектура Teradata называется Архитектурой Shared Nothing. Узлы Teradata, его процессорные модули доступа (AMP) и диски, связанные с AMP, работают независимо. Они не передаются другим.
-
Линейная масштабируемость — системы Teradata обладают высокой масштабируемостью. Они могут масштабироваться до 2048 узлов. Например, вы можете удвоить емкость системы, удвоив количество AMP.
-
Возможность подключения — Teradata может подключаться к системам, подключенным к каналу, таким как мейнфрейм или системы, подключенные к сети.
-
Оптимизатор зрелости — Оптимизатор Teradata является одним из зрелых оптимизаторов на рынке. Он был разработан, чтобы быть параллельным с самого начала. Это было доработано для каждого выпуска.
-
SQL — Teradata поддерживает отраслевой стандарт SQL для взаимодействия с данными, хранящимися в таблицах. В дополнение к этому, он имеет собственное расширение.
-
Надежные утилиты — Teradata предоставляет надежные утилиты для импорта / экспорта данных из / в систему Teradata, такие как FastLoad, MultiLoad, FastExport и TPT.
-
Автоматическое распространение — Teradata автоматически распределяет данные на диски без какого-либо ручного вмешательства.
Неограниченный параллелизм — система баз данных Teradata основана на архитектуре массовой параллельной обработки (MPP). Архитектура MPP равномерно распределяет рабочую нагрузку по всей системе. Система Teradata распределяет задачу среди своих процессов и запускает их параллельно, чтобы обеспечить быстрое выполнение задачи.
Архитектура Shared Nothing — Архитектура Teradata называется Архитектурой Shared Nothing. Узлы Teradata, его процессорные модули доступа (AMP) и диски, связанные с AMP, работают независимо. Они не передаются другим.
Линейная масштабируемость — системы Teradata обладают высокой масштабируемостью. Они могут масштабироваться до 2048 узлов. Например, вы можете удвоить емкость системы, удвоив количество AMP.
Возможность подключения — Teradata может подключаться к системам, подключенным к каналу, таким как мейнфрейм или системы, подключенные к сети.
Оптимизатор зрелости — Оптимизатор Teradata является одним из зрелых оптимизаторов на рынке. Он был разработан, чтобы быть параллельным с самого начала. Это было доработано для каждого выпуска.
SQL — Teradata поддерживает отраслевой стандарт SQL для взаимодействия с данными, хранящимися в таблицах. В дополнение к этому, он имеет собственное расширение.
Надежные утилиты — Teradata предоставляет надежные утилиты для импорта / экспорта данных из / в систему Teradata, такие как FastLoad, MultiLoad, FastExport и TPT.
Автоматическое распространение — Teradata автоматически распределяет данные на диски без какого-либо ручного вмешательства.
Teradata — Установка
Teradata предоставляет Teradata express для VMWARE, которая является полностью работающей виртуальной машиной Teradata. Он обеспечивает до 1 терабайта памяти. Teradata предоставляет версию VMware объемом 40 ГБ и 1 ТБ.
Предпосылки
Поскольку виртуальная машина 64-битная, ваш процессор должен поддерживать 64-битную.
Шаги установки для Windows
Шаг 1. Загрузите требуемую версию виртуальной машины по ссылке https://downloads.teradata.com/download/database/teradata-express-for-vmware-player.
Шаг 2 — Извлеките файл и укажите целевую папку.
Шаг 3 — Загрузите проигрыватель VMWare Workstation по ссылке https://my.vmware.com/web/vmware/downloads . Он доступен как для Windows, так и для Linux. Загрузите проигрыватель рабочей станции VMWARE для Windows.
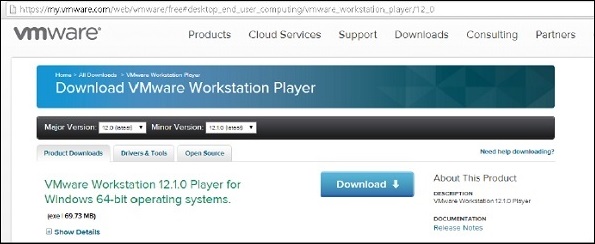
Шаг 4 — После завершения загрузки установите программное обеспечение.
Шаг 5 — После завершения установки запустите клиент VMWARE.
Шаг 6 — Выберите «Открыть виртуальную машину». Перейдите через извлеченную папку Teradata VMWare и выберите файл с расширением .vmdk.
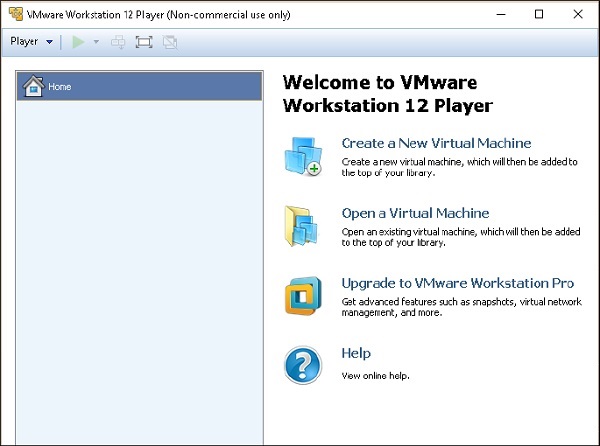
Шаг 7 — Teradata VMWare добавляется в клиент VMWare. Выберите добавленное Teradata VMware и нажмите «Играть на виртуальной машине».
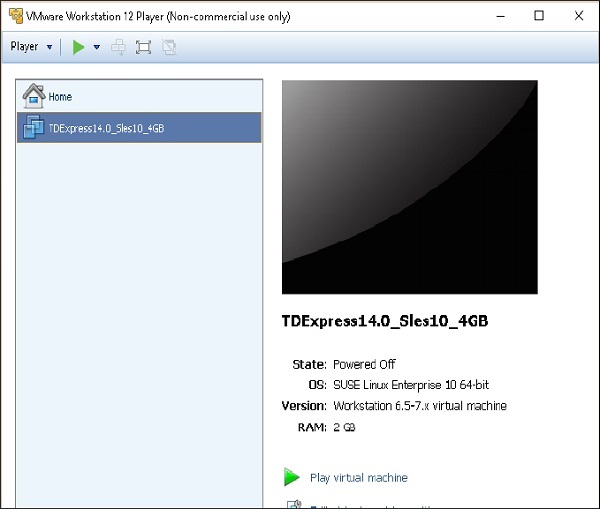
Шаг 8 — Если вы получаете всплывающее окно с обновлениями программного обеспечения, вы можете выбрать «Напомнить мне позже».
Шаг 9 — Введите имя пользователя как root, нажмите tab, введите пароль как root и снова нажмите Enter.
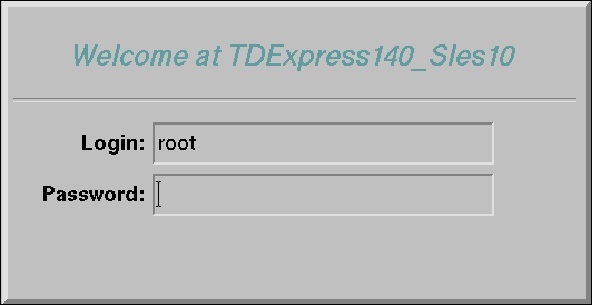
Шаг 10 — Когда на рабочем столе появится следующий экран, дважды щелкните «root’s home». Затем дважды щелкните «Терминал генома». Это откроет Shell.

Шаг 11 — В следующей оболочке введите команду /etc/init.d/tpa start. Это запустит сервер Teradata.
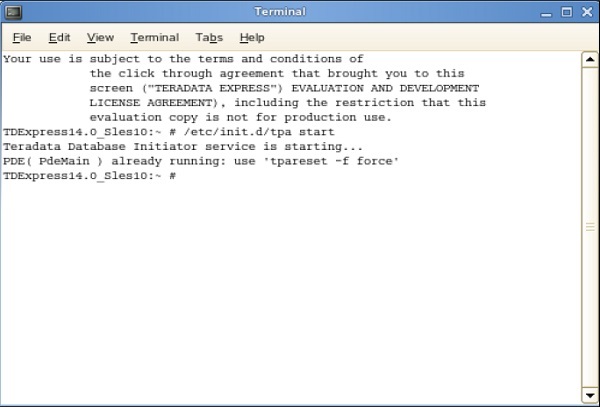
Начиная BTEQ
Утилита BTEQ используется для интерактивной отправки SQL-запросов. Ниже приведены шаги для запуска утилиты BTEQ.
Шаг 1 — Введите команду / sbin / ifconfig и запишите IP-адрес VMWare.
Шаг 2 — Запустите команду bteq. В командной строке введите команду.
Вход <ipaddress> / dbc, dbc; и введите При запросе пароля введите пароль как dbc;
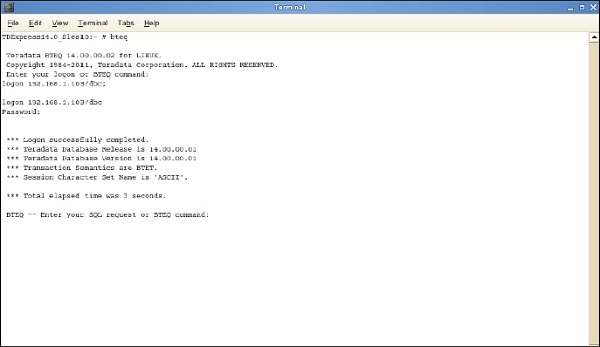
Вы можете войти в систему Teradata с помощью BTEQ и выполнить любые запросы SQL.
Терадата — Архитектура
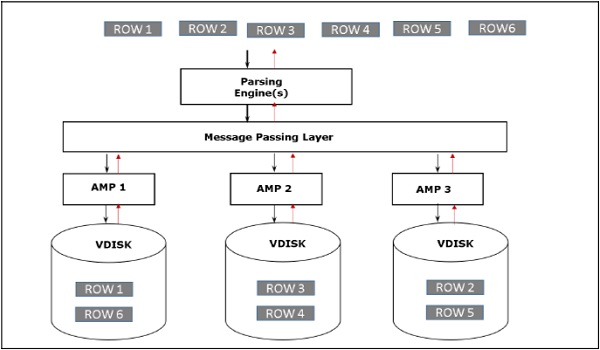
Архитектура Teradata основана на архитектуре массовой параллельной обработки (MPP). Основными компонентами Teradata являются механизм синтаксического анализа, BYNET и процессорные модули доступа (AMP). Следующая диаграмма показывает архитектуру высокого уровня узла Teradata.
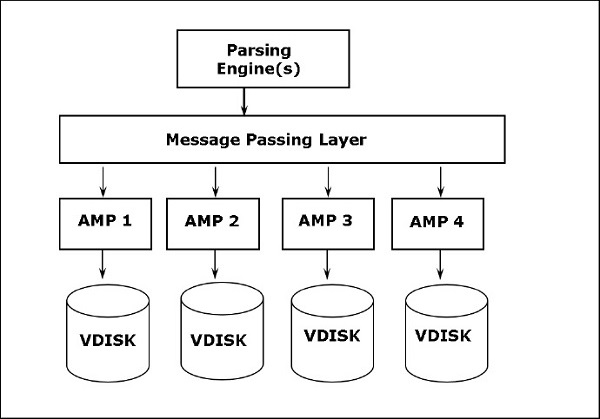
Компоненты Терадата
Ключевые компоненты Teradata следующие:
-
Узел — это базовая единица в системе Teradata. Каждый отдельный сервер в системе Teradata называется узлом. Узел состоит из собственной операционной системы, процессора, памяти, собственной копии программного обеспечения СУБД Teradata и дискового пространства. Шкаф состоит из одного или нескольких узлов.
-
Механизм синтаксического анализа — Механизм синтаксического анализа отвечает за получение запросов от клиента и подготовку эффективного плана выполнения. Обязанности разбора двигателя —
-
Получить запрос SQL от клиента
-
Разбор проверки SQL-запроса на наличие синтаксических ошибок
-
Проверьте, имеет ли пользователь необходимые права доступа к объектам, используемым в запросе SQL.
-
Проверьте, существуют ли объекты, используемые в SQL, на самом деле
-
Подготовьте план выполнения для выполнения запроса SQL и передайте его в BYNET
-
Получает результаты от AMP и отправляет клиенту
-
-
Уровень передачи сообщений — Уровень передачи сообщений, называемый BYNET, является сетевым уровнем в системе Teradata. Это позволяет осуществлять связь между PE и AMP, а также между узлами. Он получает план выполнения от Parsing Engine и отправляет в AMP. Аналогичным образом он получает результаты от AMP и отправляет их в механизм синтаксического анализа.
-
Процессор модуля доступа (AMP) — AMP, называемые виртуальными процессорами (vprocs), — это те, которые фактически сохраняют и извлекают данные. AMP получают данные и план выполнения от Parsing Engine, выполняют преобразование любых типов данных, агрегирование, фильтрацию, сортировку и сохраняют данные на дисках, связанных с ними. Записи из таблиц равномерно распределяются между AMP в системе. Каждый AMP связан с набором дисков, на которых хранятся данные. Только тот AMP может читать / записывать данные с дисков.
Узел — это базовая единица в системе Teradata. Каждый отдельный сервер в системе Teradata называется узлом. Узел состоит из собственной операционной системы, процессора, памяти, собственной копии программного обеспечения СУБД Teradata и дискового пространства. Шкаф состоит из одного или нескольких узлов.
Механизм синтаксического анализа — Механизм синтаксического анализа отвечает за получение запросов от клиента и подготовку эффективного плана выполнения. Обязанности разбора двигателя —
Получить запрос SQL от клиента
Разбор проверки SQL-запроса на наличие синтаксических ошибок
Проверьте, имеет ли пользователь необходимые права доступа к объектам, используемым в запросе SQL.
Проверьте, существуют ли объекты, используемые в SQL, на самом деле
Подготовьте план выполнения для выполнения запроса SQL и передайте его в BYNET
Получает результаты от AMP и отправляет клиенту
Уровень передачи сообщений — Уровень передачи сообщений, называемый BYNET, является сетевым уровнем в системе Teradata. Это позволяет осуществлять связь между PE и AMP, а также между узлами. Он получает план выполнения от Parsing Engine и отправляет в AMP. Аналогичным образом он получает результаты от AMP и отправляет их в механизм синтаксического анализа.
Процессор модуля доступа (AMP) — AMP, называемые виртуальными процессорами (vprocs), — это те, которые фактически сохраняют и извлекают данные. AMP получают данные и план выполнения от Parsing Engine, выполняют преобразование любых типов данных, агрегирование, фильтрацию, сортировку и сохраняют данные на дисках, связанных с ними. Записи из таблиц равномерно распределяются между AMP в системе. Каждый AMP связан с набором дисков, на которых хранятся данные. Только тот AMP может читать / записывать данные с дисков.
Архитектура хранения
Когда клиент выполняет запросы для вставки записей, механизм синтаксического анализа отправляет записи в BYNET. BYNET извлекает записи и отправляет строку в целевой AMP. AMP хранит эти записи на своих дисках. Следующая диаграмма показывает архитектуру хранения Teradata.
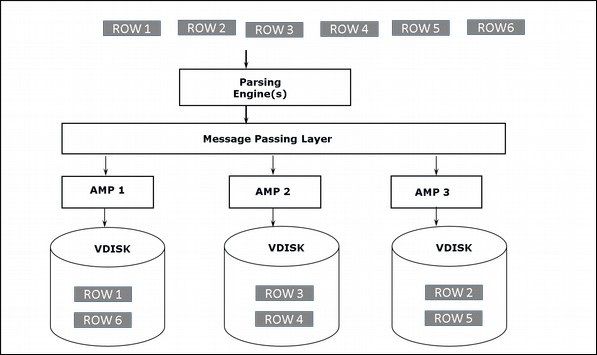
Архитектура поиска
Когда клиент выполняет запросы для извлечения записей, механизм синтаксического анализа отправляет запрос в BYNET. BYNET отправляет запрос на поиск соответствующим AMP. Затем AMP выполняют поиск на своих дисках параллельно, идентифицируют необходимые записи и отправляют в BYNET. Затем BYNET отправляет записи в Parsing Engine, который, в свою очередь, отправляет клиенту. Ниже приводится поисковая архитектура Teradata.
Teradata — реляционные концепции
Система управления реляционными базами данных (RDBMS) — это программное обеспечение СУБД, которое помогает взаимодействовать с базами данных. Они используют язык структурированных запросов (SQL) для взаимодействия с данными, хранящимися в таблицах.
База данных
База данных представляет собой набор логически связанных данных. К ним обращаются многие пользователи для разных целей. Например, база данных продаж содержит всю информацию о продажах, которая хранится во многих таблицах.
таблицы
Таблицы — это базовая единица в РСУБД, где хранятся данные. Таблица представляет собой набор строк и столбцов. Ниже приведен пример таблицы сотрудников.
| Сотрудник № | Имя | Фамилия | Дата рождения |
|---|---|---|---|
| 101 | Майк | Джеймс | 1/5/1980 |
| 104 | Alex | Стюарт | 11/6/1984 |
| 102 | Роберт | Williams | 3/5/1983 |
| 105 | Роберт | Джеймс | 12/1/1984 |
| 103 | Питер | Павел | 4/1/1983 |
Колонны
Столбец содержит аналогичные данные. Например, столбец BirthDate в таблице Employee содержит информацию birth_date для всех сотрудников.
| Дата рождения |
|---|
| 1/5/1980 |
| 11/6/1984 |
| 3/5/1983 |
| 12/1/1984 |
| 4/1/1983 |
Строка
Строка — это один экземпляр всех столбцов. Например, в таблице сотрудников одна строка содержит информацию об одном сотруднике.
| Сотрудник № | Имя | Фамилия | Дата рождения |
|---|---|---|---|
| 101 | Майк | Джеймс | 1/5/1980 |
Основной ключ
Первичный ключ используется для уникальной идентификации строки в таблице. В столбце первичного ключа недопустимы повторяющиеся значения, и они не могут принимать значения NULL. Это обязательное поле в таблице.
Иностранный ключ
Внешние ключи используются для построения отношений между таблицами. Внешний ключ в дочерней таблице определяется как первичный ключ в родительской таблице. Таблица может иметь более одного внешнего ключа. Он может принимать повторяющиеся значения, а также нулевые значения. Внешние ключи необязательны в таблице.
Teradata — Типы данных
Каждый столбец в таблице связан с типом данных. Типы данных определяют, какие значения будут храниться в столбце. Teradata поддерживает несколько типов данных. Ниже приведены некоторые из часто используемых типов данных.
| Типы данных | Длина (байт) | Диапазон значений |
|---|---|---|
| BYTEINT | 1 | От -128 до +127 |
| SMALLINT | 2 | От -32768 до +32767 |
| INTEGER | 4 | От -2 147 483 648 до + 2147 483 647 |
| BIGINT | 8 | От -9,233,372,036,854,775,80 до +9,233,372,036,854,775,8 07 |
| ДЕСЯТИЧНЫЙ | 1-16 | |
| NUMERIC | 1-16 | |
| FLOAT | 8 | Формат IEEE |
| CHAR | Фиксированный формат | 1-64,000 |
| VARCHAR | переменная | 1-64,000 |
| ДАТА | 4 | YYYYYMMDD |
| ВРЕМЯ | 6 или 8 | ЧЧММСС.нннннн или ЧЧММСС.нннннн + ЧЧММ |
| TIMESTAMP | 10 или 12 | ГГММДДЧЧММСС.нннннн или ГГММДДЧЧММСС.нннннн + ЧЧММ |
Терадата — Столы
Таблицы в реляционной модели определяются как сбор данных. Они представлены в виде строк и столбцов.
Типы столов
Типы Teradata поддерживает различные типы таблиц.
-
Постоянная таблица — это таблица по умолчанию, которая содержит данные, вставленные пользователем, и постоянно хранит данные.
-
Таблица изменчивости — данные, вставленные в таблицу изменчивости, сохраняются только во время сеанса пользователя. Таблица и данные удаляются в конце сеанса. Эти таблицы в основном используются для хранения промежуточных данных во время преобразования данных.
-
Глобальная временная таблица — определение глобальной временной таблицы является постоянным, но данные в таблице удаляются в конце сеанса пользователя.
-
Производная таблица — Производная таблица содержит промежуточные результаты в запросе. Их время жизни находится в пределах запроса, в котором они создаются, используются и удаляются.
Постоянная таблица — это таблица по умолчанию, которая содержит данные, вставленные пользователем, и постоянно хранит данные.
Таблица изменчивости — данные, вставленные в таблицу изменчивости, сохраняются только во время сеанса пользователя. Таблица и данные удаляются в конце сеанса. Эти таблицы в основном используются для хранения промежуточных данных во время преобразования данных.
Глобальная временная таблица — определение глобальной временной таблицы является постоянным, но данные в таблице удаляются в конце сеанса пользователя.
Производная таблица — Производная таблица содержит промежуточные результаты в запросе. Их время жизни находится в пределах запроса, в котором они создаются, используются и удаляются.
Set Versus Multiset
Teradata классифицирует таблицы как таблицы SET или MULTISET в зависимости от того, как обрабатываются дубликаты записей. Таблица, определенная как таблица SET, не хранит дублирующиеся записи, тогда как таблица MULTISET может хранить дублирующиеся записи.
| Sr.No | Команды таблицы и описание |
|---|---|
| 1 | Создать таблицу
Команда CREATE TABLE используется для создания таблиц в Teradata. |
| 2 | Изменить таблицу
Команда ALTER TABLE используется для добавления или удаления столбцов из существующей таблицы. |
| 3 | Drop Table
Команда DROP TABLE используется для удаления таблицы. |
Команда CREATE TABLE используется для создания таблиц в Teradata.
Команда ALTER TABLE используется для добавления или удаления столбцов из существующей таблицы.
Команда DROP TABLE используется для удаления таблицы.
Teradata — манипулирование данными
В этой главе представлены команды SQL, используемые для манипулирования данными, хранящимися в таблицах Teradata.
Вставить записи
Оператор INSERT INTO используется для вставки записей в таблицу.
Синтаксис
Ниже приведен общий синтаксис INSERT INTO.
INSERT INTO <tablename> (column1, column2, column3,…) VALUES (value1, value2, value3 …);
пример
В следующем примере вставляются записи в таблицу сотрудников.
INSERT INTO Employee ( EmployeeNo, FirstName, LastName, BirthDate, JoinedDate, DepartmentNo ) VALUES ( 101, 'Mike', 'James', '1980-01-05', '2005-03-27', 01 );
После вставки вышеуказанного запроса вы можете использовать оператор SELECT для просмотра записей из таблицы.
| Сотрудник № | Имя | Фамилия | JoinedDate | DepartmentNo | Дата рождения |
|---|---|---|---|---|---|
| 101 | Майк | Джеймс | 3/27/2005 | 1 | 1/5/1980 |
Вставить из другой таблицы
Оператор INSERT SELECT используется для вставки записей из другой таблицы.
Синтаксис
Ниже приведен общий синтаксис INSERT INTO.
INSERT INTO <tablename> (column1, column2, column3,…) SELECT column1, column2, column3… FROM <source table>;
пример
В следующем примере вставляются записи в таблицу сотрудников. Создайте таблицу с именем Employee_Bkup с тем же определением столбца, что и у таблицы employee, перед выполнением следующего запроса вставки.
INSERT INTO Employee_Bkup ( EmployeeNo, FirstName, LastName, BirthDate, JoinedDate, DepartmentNo ) SELECT EmployeeNo, FirstName, LastName, BirthDate, JoinedDate, DepartmentNo FROM Employee;
Когда вышеуказанный запрос будет выполнен, он вставит все записи из таблицы employee в таблицу employee_bkup.
правила
-
Количество столбцов, указанное в списке VALUES, должно соответствовать столбцам, указанным в предложении INSERT INTO.
-
Значения обязательны для столбцов NOT NULL.
-
Если значения не указаны, то для пустых полей вставляется NULL.
-
Типы данных столбцов, указанные в предложении VALUES, должны быть совместимы с типами данных столбцов в предложении INSERT.
Количество столбцов, указанное в списке VALUES, должно соответствовать столбцам, указанным в предложении INSERT INTO.
Значения обязательны для столбцов NOT NULL.
Если значения не указаны, то для пустых полей вставляется NULL.
Типы данных столбцов, указанные в предложении VALUES, должны быть совместимы с типами данных столбцов в предложении INSERT.
Обновить записи
Оператор UPDATE используется для обновления записей из таблицы.
Синтаксис
Ниже приводится общий синтаксис для UPDATE.
UPDATE <tablename> SET <columnnamme> = <new value> [WHERE condition];
пример
В следующем примере обновляется отдел сотрудника до 03 для сотрудника 101.
UPDATE Employee SET DepartmentNo = 03 WHERE EmployeeNo = 101;
В следующем выводе вы видите, что DepartmentNo обновлен с 1 до 3 для EmployeeNo 101.
SELECT Employeeno, DepartmentNo FROM Employee; *** Query completed. One row found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo DepartmentNo ----------- ------------- 101 3
правила
-
Вы можете обновить одно или несколько значений таблицы.
-
Если условие WHERE не указано, то затрагиваются все строки таблицы.
-
Вы можете обновить таблицу значениями из другой таблицы.
Вы можете обновить одно или несколько значений таблицы.
Если условие WHERE не указано, то затрагиваются все строки таблицы.
Вы можете обновить таблицу значениями из другой таблицы.
Удалить записи
Оператор DELETE FROM используется для обновления записей из таблицы.
Синтаксис
Ниже приведен общий синтаксис для DELETE FROM.
DELETE FROM <tablename> [WHERE condition];
пример
В следующем примере удаляется сотрудник 101 из таблицы employee.
DELETE FROM Employee WHERE EmployeeNo = 101;
В следующем выводе вы можете видеть, что сотрудник 101 удален из таблицы.
SELECT EmployeeNo FROM Employee; *** Query completed. No rows found. *** Total elapsed time was 1 second.
правила
-
Вы можете обновить одну или несколько записей таблицы.
-
Если условие WHERE не указано, удаляются все строки таблицы.
-
Вы можете обновить таблицу значениями из другой таблицы.
Вы можете обновить одну или несколько записей таблицы.
Если условие WHERE не указано, удаляются все строки таблицы.
Вы можете обновить таблицу значениями из другой таблицы.
Teradata — оператор SELECT
Оператор SELECT используется для извлечения записей из таблицы.
Синтаксис
Ниже приведен основной синтаксис оператора SELECT.
SELECT column 1, column 2, ..... FROM tablename;
пример
Рассмотрим следующую таблицу сотрудников.
| Сотрудник № | Имя | Фамилия | JoinedDate | DepartmentNo | Дата рождения |
|---|---|---|---|---|---|
| 101 | Майк | Джеймс | 3/27/2005 | 1 | 1/5/1980 |
| 102 | Роберт | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Питер | Павел | 3/21/2007 | 2 | 4/1/1983 |
| 104 | Alex | Стюарт | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Роберт | Джеймс | 1/4/2008 | 3 | 12/1/1984 |
Ниже приведен пример инструкции SELECT.
SELECT EmployeeNo,FirstName,LastName FROM Employee;
Когда этот запрос выполняется, он выбирает столбцы EmployeeNo, FirstName и LastName из таблицы employee.
EmployeeNo FirstName LastName ----------- ------------------------------ --------------------------- 101 Mike James 104 Alex Stuart 102 Robert Williams 105 Robert James 103 Peter Paul
Если вы хотите извлечь все столбцы из таблицы, вы можете использовать следующую команду вместо перечисления всех столбцов.
SELECT * FROM Employee;
Приведенный выше запрос извлечет все записи из таблицы сотрудников.
ГДЕ оговорка
Предложение WHERE используется для фильтрации записей, возвращаемых оператором SELECT. Условие связано с предложением WHERE. Только те записи, которые удовлетворяют условию в предложении WHERE, возвращаются.
Синтаксис
Ниже приводится синтаксис оператора SELECT с предложением WHERE.
SELECT * FROM tablename WHERE[condition];
пример
Следующий запрос извлекает записи, где EmployeeNo равен 101.
SELECT * FROM Employee WHERE EmployeeNo = 101;
Когда этот запрос выполняется, он возвращает следующие записи.
EmployeeNo FirstName LastName ----------- ------------------------------ ----------------------------- 101 Mike James
СОРТИРОВАТЬ ПО
Когда выполняется инструкция SELECT, возвращаемые строки не имеют определенного порядка. Предложение ORDER BY используется для упорядочения записей в порядке возрастания / убывания по любым столбцам.
Синтаксис
Ниже приводится синтаксис оператора SELECT с предложением ORDER BY.
SELECT * FROM tablename ORDER BY column 1, column 2..;
пример
Следующий запрос извлекает записи из таблицы сотрудников и упорядочивает результаты по FirstName.
SELECT * FROM Employee ORDER BY FirstName;
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert James
ГРУППА ПО
Предложение GROUP BY используется вместе с оператором SELECT и объединяет похожие записи в группы.
Синтаксис
Ниже приводится синтаксис оператора SELECT с предложением GROUP BY.
SELECT column 1, column2 …. FROM tablename GROUP BY column 1, column 2..;
пример
В следующем примере группируются записи по столбцу DepartmentNo и указывается общее количество для каждого отдела.
SELECT DepartmentNo,Count(*) FROM Employee GROUP BY DepartmentNo;
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3
Teradata — логические и условные операторы
Teradata поддерживает следующие логические и условные операторы. Эти операторы используются для сравнения и объединения нескольких условий.
| Синтаксис | Имея в виду |
|---|---|
| > | Лучше чем |
| < | Меньше, чем |
| > = | Больше или равно |
| <= | Меньше или равно |
| знак равно | Равно |
| МЕЖДУ | Если значения в пределах диапазона |
| В | Если значения в <выражение> |
| НЕ В | Если значения не в <выражение> |
| НУЛЕВОЙ | Если значение равно NULL |
| НЕ НУЛЬ | Если значение НЕ NULL |
| А ТАКЖЕ | Объедините несколько условий. Оценивается как истинное, только если выполнены все условия |
| ИЛИ ЖЕ | Объедините несколько условий. Оценивается как истинное, только если выполняется одно из условий. |
| НЕ | Меняет смысл условия |
МЕЖДУ
Команда BETWEEN используется для проверки, находится ли значение в диапазоне значений.
пример
Рассмотрим следующую таблицу сотрудников.
| Сотрудник № | Имя | Фамилия | JoinedDate | DepartmentNo | Дата рождения |
|---|---|---|---|---|---|
| 101 | Майк | Джеймс | 3/27/2005 | 1 | 1/5/1980 |
| 102 | Роберт | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Питер | Павел | 3/21/2007 | 2 | 4/1/1983 |
| 104 | Alex | Стюарт | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Роберт | Джеймс | 1/4/2008 | 3 | 12/1/1984 |
В следующем примере извлекаются записи с номерами сотрудников в диапазоне от 101,102 до 103.
SELECT EmployeeNo, FirstName FROM Employee WHERE EmployeeNo BETWEEN 101 AND 103;
Когда вышеуказанный запрос выполняется, он возвращает записи о сотрудниках с сотрудником № от 101 до 103.
*** Query completed. 3 rows found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo FirstName ----------- ------------------------------ 101 Mike 102 Robert 103 Peter
В
Команда IN используется для проверки значения по заданному списку значений.
пример
В следующем примере извлекаются записи с номерами сотрудников в 101, 102 и 103.
SELECT EmployeeNo, FirstName FROM Employee WHERE EmployeeNo in (101,102,103);
Приведенный выше запрос возвращает следующие записи.
*** Query completed. 3 rows found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo FirstName ----------- ------------------------------ 101 Mike 102 Robert 103 Peter
НЕ В
Команда NOT IN отменяет результат команды IN. Он извлекает записи со значениями, которые не соответствуют заданному списку.
пример
В следующем примере извлекаются записи с номерами сотрудников не в 101, 102 и 103.
SELECT * FROM Employee WHERE EmployeeNo not in (101,102,103);
Приведенный выше запрос возвращает следующие записи.
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert James
Teradata — операторы SET
Операторы SET объединяют результаты нескольких операторов SELECT. Это может выглядеть аналогично объединениям, но объединения объединяют столбцы из нескольких таблиц, тогда как операторы SET объединяют строки из нескольких строк.
правила
-
Количество столбцов в каждом операторе SELECT должно быть одинаковым.
-
Типы данных из каждого SELECT должны быть совместимы.
-
ORDER BY должен быть включен только в окончательный оператор SELECT.
Количество столбцов в каждом операторе SELECT должно быть одинаковым.
Типы данных из каждого SELECT должны быть совместимы.
ORDER BY должен быть включен только в окончательный оператор SELECT.
UNION
Оператор UNION используется для объединения результатов нескольких операторов SELECT. Это игнорирует дубликаты.
Синтаксис
Ниже приведен основной синтаксис оператора UNION.
SELECT col1, col2, col3… FROM <table 1> [WHERE condition] UNION SELECT col1, col2, col3… FROM <table 2> [WHERE condition];
пример
Рассмотрим следующую таблицу сотрудников и таблицу зарплат.
| Сотрудник № | Имя | Фамилия | JoinedDate | DepartmentNo | Дата рождения |
|---|---|---|---|---|---|
| 101 | Майк | Джеймс | 3/27/2005 | 1 | 1/5/1980 |
| 102 | Роберт | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Питер | Павел | 3/21/2007 | 2 | 4/1/1983 |
| 104 | Alex | Стюарт | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Роберт | Джеймс | 1/4/2008 | 3 | 12/1/1984 |
| Сотрудник № | Валовой | дедукция | NetPay |
|---|---|---|---|
| 101 | 40000 | 4000 | 36000 |
| 102 | 80000 | 6000 | 74000 |
| 103 | 90000 | 7000 | 83000 |
| 104 | 75000 | 5000 | 70000 |
Следующий запрос UNION объединяет значение EmployeeNo из таблицы Employee и Salary.
SELECT EmployeeNo FROM Employee UNION SELECT EmployeeNo FROM Salary;
Когда запрос выполняется, он производит следующий вывод.
EmployeeNo ----------- 101 102 103 104 105
СОЮЗ ВСЕХ
Оператор UNION ALL похож на оператор UNION, он объединяет результаты из нескольких таблиц, включая повторяющиеся строки.
Синтаксис
Ниже приведен основной синтаксис оператора UNION ALL.
SELECT col1, col2, col3… FROM <table 1> [WHERE condition] UNION ALL SELECT col1, col2, col3… FROM <table 2> [WHERE condition];
пример
Ниже приведен пример для оператора UNION ALL.
SELECT EmployeeNo FROM Employee UNION ALL SELECT EmployeeNo FROM Salary;
Когда вышеуказанный запрос выполняется, он производит следующий вывод. Вы можете видеть, что он также возвращает дубликаты.
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103
ПЕРЕСЕЧЕНИЕ
Команда INTERSECT также используется для объединения результатов из нескольких операторов SELECT. Он возвращает строки из первого оператора SELECT, который имеет соответствующее совпадение во втором операторе SELECT. Другими словами, он возвращает строки, которые существуют в обоих инструкциях SELECT.
Синтаксис
Ниже приведен основной синтаксис оператора INTERSECT.
SELECT col1, col2, col3… FROM <table 1> [WHERE condition] INTERSECT SELECT col1, col2, col3… FROM <table 2> [WHERE condition];
пример
Ниже приведен пример оператора INTERSECT. Он возвращает значения EmployeeNo, которые существуют в обеих таблицах.
SELECT EmployeeNo FROM Employee INTERSECT SELECT EmployeeNo FROM Salary;
Когда вышеуказанный запрос выполняется, он возвращает следующие записи. EmployeeNo 105 исключен, поскольку он не существует в таблице SALARY.
EmployeeNo ----------- 101 104 102 103
МИНУС / КРОМЕ
Команды MINUS / EXCEPT объединяют строки из нескольких таблиц и возвращают строки, которые находятся в первом SELECT, но не во втором SELECT. Они оба возвращают одинаковые результаты.
Синтаксис
Ниже приведен основной синтаксис оператора MINUS.
SELECT col1, col2, col3… FROM <table 1> [WHERE condition] MINUS SELECT col1, col2, col3… FROM <table 2> [WHERE condition];
пример
Ниже приведен пример оператора MINUS.
SELECT EmployeeNo FROM Employee MINUS SELECT EmployeeNo FROM Salary;
Когда этот запрос выполняется, он возвращает следующую запись.
EmployeeNo ----------- 105
Teradata — Манипулирование строками
Teradata предоставляет несколько функций для управления строками. Эти функции совместимы со стандартом ANSI.
| Sr.No | Функция и описание строки |
|---|---|
| 1 | ||
Объединяет строки вместе |
| 2 | SUBSTR
Извлекает часть строки (расширение Teradata) |
| 3 | SUBSTRING
Извлекает часть строки (стандарт ANSI) |
| 4 | ИНДЕКС
Находит позицию символа в строке (расширение Teradata) |
| 5 | ПОЗИЦИЯ
Находит позицию символа в строке (стандарт ANSI) |
| 6 | ОТДЕЛКА
Обрезает заготовки из струны |
| 7 | ВЕРХНИЙ
Преобразует строку в верхний регистр |
| 8 | НИЖНИЙ
Преобразует строку в нижний регистр |
Объединяет строки вместе
Извлекает часть строки (расширение Teradata)
Извлекает часть строки (стандарт ANSI)
Находит позицию символа в строке (расширение Teradata)
Находит позицию символа в строке (стандарт ANSI)
Обрезает заготовки из струны
Преобразует строку в верхний регистр
Преобразует строку в нижний регистр
пример
В следующей таблице перечислены некоторые строковые функции с результатами.
| Строковая функция | Результат |
|---|---|
| ВЫБЕРИТЕ ПОДПИСЬ («склад» ОТ 1 ЗА 4) | изделия |
| SELECT SUBSTR («склад», 1,4) | изделия |
| ВЫБЕРИТЕ «данные» || » || ‘склад’ | хранилище данных |
| ВЫБЕРИТЕ ВЕРХНИЙ («данные») | ДАННЫЕ |
| ВЫБЕРИТЕ НИЖЕ («ДАННЫЕ») | данные |
Teradata — Дата / Время Функции
В этой главе рассматриваются функции даты и времени, доступные в Teradata.
Дата Хранения
Даты хранятся в виде целого числа внутри, используя следующую формулу.
((YEAR - 1900) * 10000) + (MONTH * 100) + DAY
Вы можете использовать следующий запрос, чтобы проверить, как хранятся даты.
SELECT CAST(CURRENT_DATE AS INTEGER);
Поскольку даты хранятся как целые числа, вы можете выполнять над ними некоторые арифметические операции. Teradata предоставляет функции для выполнения этих операций.
ВЫПИСКА
Функция EXTRACT извлекает части дня, месяца и года из значения DATE. Эта функция также используется для извлечения часа, минуты и секунды из значения TIME / TIMESTAMP.
пример
В следующих примерах показано, как извлечь значения Год, Месяц, Дата, Час, Минута и секунды из значений Дата и Отметка времени.
SELECT EXTRACT(YEAR FROM CURRENT_DATE); EXTRACT(YEAR FROM Date) ----------------------- 2016 SELECT EXTRACT(MONTH FROM CURRENT_DATE); EXTRACT(MONTH FROM Date) ------------------------ 1 SELECT EXTRACT(DAY FROM CURRENT_DATE); EXTRACT(DAY FROM Date) ------------------------ 1 SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP); EXTRACT(HOUR FROM Current TimeStamp(6)) --------------------------------------- 4 SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP); EXTRACT(MINUTE FROM Current TimeStamp(6)) ----------------------------------------- 54 SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP); EXTRACT(SECOND FROM Current TimeStamp(6)) ----------------------------------------- 27.140000
ИНТЕРВАЛ
Teradata предоставляет функцию INTERVAL для выполнения арифметических операций со значениями DATE и TIME. Есть два типа ИНТЕРВАЛЬНЫХ функций.
Год-Месяц Интервал
- ГОД
- ГОД В МЕСЯЦ
- МЕСЯЦ
Дневной интервал
- ДЕНЬ
- ДЕНЬ ЧАСОВ
- ДЕНЬ В МИНУТУ
- ДЕНЬ ВТОРОЙ
- ЧАС
- ЧАС МИНУТ
- ЧАС ВТОРОГО
- МИНУТЫ
- МИНУТА ВТОРОГО
- ВТОРОЙ
пример
Следующий пример добавляет 3 года к текущей дате.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR; Date (Date+ 3) -------- --------- 16/01/01 19/01/01
Следующий пример добавляет 3 года и 01 месяц к текущей дате.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH; Date (Date+ 3-01) -------- ------------ 16/01/01 19/02/01
В следующем примере добавляется 01 день, 05 часов и 10 минут к текущей отметке времени.
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE; Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10) -------------------------------- -------------------------------- 2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00
Teradata — встроенные функции
Teradata предоставляет встроенные функции, которые являются расширениями для SQL. Ниже приведены общие встроенные функции.
| функция | Результат |
|---|---|
| ВЫБЕРИТЕ ДАТУ; | Дата ——— 16/01/01 |
| SELECT CURRENT_DATE; | Дата ——— 16/01/01 |
| ВЫБЕРИТЕ ВРЕМЯ; | Время ——— 4:50:29 |
| SELECT CURRENT_TIME; | Время ——— 4:50:29 |
| SELECT CURRENT_TIMESTAMP; | Текущее время (6) ——————————— 2016-01-01 04: 51: 06.990000 + 00: 00 |
| ВЫБЕРИТЕ БАЗУ ДАННЫХ; | База данных —————————— TDUSER |
Teradata — Совокупные функции
Teradata поддерживает общие агрегатные функции. Их можно использовать с оператором SELECT.
-
COUNT — считает строки
-
SUM — Суммирует значения указанных столбцов
-
MAX — возвращает большое значение указанного столбца
-
MIN — возвращает минимальное значение указанного столбца
-
AVG — возвращает среднее значение указанного столбца
COUNT — считает строки
SUM — Суммирует значения указанных столбцов
MAX — возвращает большое значение указанного столбца
MIN — возвращает минимальное значение указанного столбца
AVG — возвращает среднее значение указанного столбца
пример
Рассмотрим следующую таблицу зарплат.
| Сотрудник № | Валовой | дедукция | NetPay |
|---|---|---|---|
| 101 | 40000 | 4000 | 36000 |
| 104 | 75000 | 5000 | 70000 |
| 102 | 80000 | 6000 | 74000 |
| 105 | 70000 | 4000 | 66000 |
| 103 | 90000 | 7000 | 83000 |
COUNT
В следующем примере подсчитывается количество записей в таблице Salary.
SELECT count(*) from Salary; Count(*) ----------- 5
МАКСИМУМ
В следующем примере возвращается максимальная чистая заработная плата сотрудника.
SELECT max(NetPay) from Salary; Maximum(NetPay) --------------------- 83000
MIN
В следующем примере возвращается минимальная чистая зарплата сотрудника из таблицы зарплат.
SELECT min(NetPay) from Salary; Minimum(NetPay) --------------------- 36000
AVG
В следующем примере возвращается среднее значение чистой заработной платы сотрудников из таблицы.
SELECT avg(NetPay) from Salary; Average(NetPay) --------------------- 65800
SUM
В следующем примере вычисляется сумма чистого оклада сотрудников по всем записям таблицы зарплат.
SELECT sum(NetPay) from Salary; Sum(NetPay) ----------------- 329000
Teradata — CASE и COALESCE
В этой главе описываются функции CASE и COALESCE Teradata.
CASE Expression
Выражение CASE сравнивает каждую строку с условием или предложением WHEN и возвращает результат первого совпадения. Если совпадений нет, возвращается результат из ELSE.
Синтаксис
Ниже приводится синтаксис выражения CASE.
CASE <expression> WHEN <expression> THEN result-1 WHEN <expression> THEN result-2 ELSE Result-n END
пример
Рассмотрим следующую таблицу сотрудников.
| Сотрудник № | Имя | Фамилия | JoinedDate | DepartmentNo | Дата рождения |
|---|---|---|---|---|---|
| 101 | Майк | Джеймс | 3/27/2005 | 1 | 1/5/1980 |
| 102 | Роберт | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Питер | Павел | 3/21/2007 | 2 | 4/1/1983 |
| 104 | Alex | Стюарт | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Роберт | Джеймс | 1/4/2008 | 3 | 12/1/1984 |
В следующем примере оценивается столбец DepartmentNo и возвращается значение 1, если номер отдела равен 1; возвращает 2, если номер отдела равен 3; в противном случае он возвращает значение как неверный отдел.
SELECT EmployeeNo, CASE DepartmentNo WHEN 1 THEN 'Admin' WHEN 2 THEN 'IT' ELSE 'Invalid Dept' END AS Department FROM Employee;
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
*** Query completed. 5 rows found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo Department ----------- ------------ 101 Admin 104 IT 102 IT 105 Invalid Dept 103 IT
Вышеупомянутое выражение CASE также может быть записано в следующей форме, которая даст тот же результат, что и выше.
SELECT EmployeeNo, CASE WHEN DepartmentNo = 1 THEN 'Admin' WHEN DepartmentNo = 2 THEN 'IT' ELSE 'Invalid Dept' END AS Department FROM Employee;
COALESCE
COALESCE — это оператор, который возвращает первое ненулевое значение выражения. Возвращает NULL, если все аргументы выражения оцениваются как NULL. Ниже приводится синтаксис.
Синтаксис
COALESCE(expression 1, expression 2, ....)
пример
SELECT EmployeeNo, COALESCE(dept_no, 'Department not found') FROM employee;
NULLIF
Инструкция NULLIF возвращает NULL, если аргументы равны.
Синтаксис
Ниже приводится синтаксис оператора NULLIF.
NULLIF(expression 1, expression 2)
пример
В следующем примере возвращается NULL, если значение DepartmentNo равно 3. В противном случае возвращается значение DepartmentNo.
SELECT EmployeeNo, NULLIF(DepartmentNo,3) AS department FROM Employee;
Приведенный выше запрос возвращает следующие записи. Вы можете видеть, что у сотрудника 105 есть отдел №. как NULL.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2
Teradata — первичный индекс
Первичный индекс используется, чтобы указать, где данные находятся в Teradata. Он используется для указания того, какой AMP получает строку данных. Каждая таблица в Teradata должна иметь определенный первичный индекс. Если первичный индекс не определен, Teradata автоматически назначает первичный индекс. Первичный индекс обеспечивает самый быстрый способ доступа к данным. Основной может иметь максимум 64 столбца.
Первичный индекс определяется при создании таблицы. Есть 2 типа первичных индексов.
- Уникальный первичный индекс (UPI)
- Неуникальный первичный индекс (NUPI)
Уникальный первичный индекс (UPI)
Если в таблице определено наличие UPI, то в столбце, который считается UPI, не должно быть повторяющихся значений. Если будут введены какие-либо повторяющиеся значения, они будут отклонены.
Создать уникальный первичный индекс
В следующем примере создается таблица зарплаты со столбцом EmployeeNo в качестве уникального первичного индекса.
CREATE SET TABLE Salary ( EmployeeNo INTEGER, Gross INTEGER, Deduction INTEGER, NetPay INTEGER ) UNIQUE PRIMARY INDEX(EmployeeNo);
Неуникальный первичный индекс (NUPI)
Если определено, что таблица имеет NUPI, то столбец, рассматриваемый как UPI, может принимать повторяющиеся значения.
Создать неуникальный первичный индекс
В следующем примере создается таблица счетов сотрудников со столбцом EmployeeNo в качестве Неуникального первичного индекса. EmployeeNo определяется как неуникальный первичный индекс, поскольку сотрудник может иметь несколько учетных записей в таблице; один для счета заработной платы и другой для счета возмещения.
CREATE SET TABLE Employee _Accounts ( EmployeeNo INTEGER, employee_bank_account_type BYTEINT. employee_bank_account_number INTEGER, employee_bank_name VARCHAR(30), employee_bank_city VARCHAR(30) ) PRIMARY INDEX(EmployeeNo);
Teradata — Joins
Объединение используется для объединения записей из более чем одной таблицы. Таблицы объединяются на основе общих столбцов / значений из этих таблиц.
Существуют разные типы соединений.
- Внутреннее соединение
- Левое внешнее соединение
- Правое внешнее соединение
- Полное внешнее соединение
- Самостоятельное присоединение
- Перекрестное соединение
- Декартово-Производственное Объединение
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
Внутреннее объединение объединяет записи из нескольких таблиц и возвращает значения, которые существуют в обеих таблицах.
Синтаксис
Ниже приводится синтаксис оператора INNER JOIN.
SELECT col1, col2, col3…. FROM Table-1 INNER JOIN Table-2 ON (col1 = col2) <WHERE condition>;
пример
Рассмотрим следующую таблицу сотрудников и таблицу зарплат.
| Сотрудник № | Имя | Фамилия | JoinedDate | DepartmentNo | Дата рождения |
|---|---|---|---|---|---|
| 101 | Майк | Джеймс | 3/27/2005 | 1 | 1/5/1980 |
| 102 | Роберт | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Питер | Павел | 3/21/2007 | 2 | 4/1/1983 |
| 104 | Alex | Стюарт | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Роберт | Джеймс | 1/4/2008 | 3 | 12/1/1984 |
| Сотрудник № | Валовой | дедукция | NetPay |
|---|---|---|---|
| 101 | 40000 | 4000 | 36000 |
| 102 | 80000 | 6000 | 74000 |
| 103 | 90000 | 7000 | 83000 |
| 104 | 75000 | 5000 | 70000 |
Следующий запрос объединяет таблицу Employee и таблицу Salary в общем столбце EmployeeNo. Каждой таблице присваивается псевдоним A и B, а столбцы имеют правильный псевдоним.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay FROM Employee A INNER JOIN Salary B ON (A.EmployeeNo = B. EmployeeNo);
Когда вышеуказанный запрос выполняется, он возвращает следующие записи. Сотрудник 105 не включен в результат, поскольку у него нет соответствующих записей в таблице зарплаты.
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
НАРУЖНОЕ СОЕДИНЕНИЕ
LEFT OUTER JOIN и RIGHT OUTER JOIN также объединяют результаты из нескольких таблиц.
-
LEFT OUTER JOIN возвращает все записи из левой таблицы и возвращает только совпадающие записи из правой таблицы.
-
RIGHT OUTER JOIN возвращает все записи из правой таблицы и возвращает только совпадающие строки из левой таблицы.
-
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ объединяет результаты как ЛЕВЫХ ВНЕШНИХ, так и ПРАВИЛЬНЫХ ВНЕШНИХ СОЕДИНЕНИЙ. Он возвращает как совпадающие, так и не совпадающие строки из соединенных таблиц.
LEFT OUTER JOIN возвращает все записи из левой таблицы и возвращает только совпадающие записи из правой таблицы.
RIGHT OUTER JOIN возвращает все записи из правой таблицы и возвращает только совпадающие строки из левой таблицы.
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ объединяет результаты как ЛЕВЫХ ВНЕШНИХ, так и ПРАВИЛЬНЫХ ВНЕШНИХ СОЕДИНЕНИЙ. Он возвращает как совпадающие, так и не совпадающие строки из соединенных таблиц.
Синтаксис
Ниже приводится синтаксис оператора OUTER JOIN. Вам необходимо использовать один из вариантов: ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ, ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ или ПОЛНОЕ НАРУЖНОЕ СОЕДИНЕНИЕ.
SELECT col1, col2, col3…. FROM Table-1 LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN Table-2 ON (col1 = col2) <WHERE condition>;
пример
Рассмотрим следующий пример запроса LEFT OUTER JOIN. Он возвращает все записи из таблицы Employee и соответствующие записи из таблицы Salary.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay FROM Employee A LEFT OUTER JOIN Salary B ON (A.EmployeeNo = B. EmployeeNo) ORDER BY A.EmployeeNo;
Когда вышеуказанный запрос выполняется, он производит следующий вывод. Для сотрудника 105 значение NetPay равно NULL, поскольку в таблице зарплат нет соответствующих записей.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?
CROSS JOIN
Перекрестное соединение соединяет каждую строку из левой таблицы с каждой строкой из правой таблицы.
Синтаксис
Ниже приведен синтаксис оператора CROSS JOIN.
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay FROM Employee A CROSS JOIN Salary B WHERE A.EmployeeNo = 101 ORDER BY B.EmployeeNo;
Когда вышеуказанный запрос выполняется, он производит следующий вывод. Сотрудник № 101 из таблицы Employee объединяется с каждой записью из таблицы Salary.
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000
Teradata — подзапросы
Подзапрос возвращает записи из одной таблицы на основе значений из другой таблицы. Это запрос SELECT в другом запросе. Запрос SELECT, вызываемый как внутренний запрос, выполняется первым, а результат используется внешним запросом. Некоторые из его характерных особенностей —
-
Запрос может иметь несколько подзапросов, а подзапросы могут содержать другой подзапрос.
-
Подзапросы не возвращают дубликаты записей.
-
Если подзапрос возвращает только одно значение, вы можете использовать оператор =, чтобы использовать его с внешним запросом. Если он возвращает несколько значений, вы можете использовать IN или NOT IN.
Запрос может иметь несколько подзапросов, а подзапросы могут содержать другой подзапрос.
Подзапросы не возвращают дубликаты записей.
Если подзапрос возвращает только одно значение, вы можете использовать оператор =, чтобы использовать его с внешним запросом. Если он возвращает несколько значений, вы можете использовать IN или NOT IN.
Синтаксис
Ниже приводится общий синтаксис подзапросов.
SELECT col1, col2, col3,… FROM Outer Table WHERE col1 OPERATOR ( Inner SELECT Query);
пример
Рассмотрим следующую таблицу зарплат.
| Сотрудник № | Валовой | дедукция | NetPay |
|---|---|---|---|
| 101 | 40000 | 4000 | 36000 |
| 102 | 80000 | 6000 | 74000 |
| 103 | 90000 | 7000 | 83000 |
| 104 | 75000 | 5000 | 70000 |
Следующий запрос определяет номер сотрудника с самой высокой зарплатой. Внутренний SELECT выполняет функцию агрегирования для возврата максимального значения NetPay, а внешний запрос SELECT использует это значение для возврата записи сотрудника с этим значением.
SELECT EmployeeNo, NetPay FROM Salary WHERE NetPay = (SELECT MAX(NetPay) FROM Salary);
Когда этот запрос выполняется, он производит следующий вывод.
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000
Teradata — Типы таблиц
Teradata поддерживает следующие типы таблиц для хранения временных данных.
- Производная таблица
- Летучий стол
- Глобальная временная таблица
Производная таблица
Производные таблицы создаются, используются и удаляются в запросе. Они используются для хранения промежуточных результатов в запросе.
пример
В следующем примере строится производная таблица EmpSal с записями сотрудников с зарплатой более 75000.
SELECT Emp.EmployeeNo, Emp.FirstName, Empsal.NetPay FROM Employee Emp, (select EmployeeNo , NetPay from Salary where NetPay >= 75000) Empsal where Emp.EmployeeNo = Empsal.EmployeeNo;
Когда вышеуказанный запрос выполняется, он возвращает сотрудников с зарплатой, превышающей 75000.
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000
Летучий стол
Изменчивые таблицы создаются, используются и удаляются в пользовательском сеансе. Их определение не сохраняется в словаре данных. Они содержат промежуточные данные запроса, который часто используется. Ниже приводится синтаксис.
Синтаксис
CREATE [SET|MULTISET] VOALTILE TABLE tablename <table definitions> <column definitions> <index definitions> ON COMMIT [DELETE|PRESERVE] ROWS
пример
CREATE VOLATILE TABLE dept_stat ( dept_no INTEGER, avg_salary INTEGER, max_salary INTEGER, min_salary INTEGER ) PRIMARY INDEX(dept_no) ON COMMIT PRESERVE ROWS;
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
*** Table has been created. *** Total elapsed time was 1 second.
Глобальная временная таблица
Определение глобальной временной таблицы хранится в словаре данных и может использоваться многими пользователями / сеансами. Но данные, загруженные в глобальную временную таблицу, сохраняются только во время сеанса. Вы можете реализовать до 2000 глобальных временных таблиц за сеанс. Ниже приводится синтаксис.
Синтаксис
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename <table definitions> <column definitions> <index definitions>
пример
CREATE SET GLOBAL TEMPORARY TABLE dept_stat ( dept_no INTEGER, avg_salary INTEGER, max_salary INTEGER, min_salary INTEGER ) PRIMARY INDEX(dept_no);
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
*** Table has been created. *** Total elapsed time was 1 second.
Терадата — космические концепции
В Teradata есть три типа пространств.
Постоянное пространство
Постоянное пространство — это максимальный объем пространства, доступный пользователю / базе данных для хранения строк данных. Постоянные таблицы, журналы, резервные таблицы и вспомогательные подтаблицы индекса используют постоянное пространство.
Постоянное пространство не выделено заранее для базы данных / пользователя. Они просто определены как максимальное количество места, которое база данных / пользователь может использовать. Количество постоянного пространства делится на количество AMP. Всякий раз, когда предел AMP превышает, генерируется сообщение об ошибке.
Spool Space
Буферное пространство — это неиспользуемое постоянное пространство, которое используется системой для хранения промежуточных результатов запроса SQL. Пользователи без места в буфере не могут выполнить любой запрос.
Подобно постоянному пространству, пространство буфера определяет максимальный объем пространства, которое может использовать пользователь. Спул пространство делится на количество AMP. Всякий раз, когда превышается предел AMP, пользователь получает ошибку места в буфере.
Temp Space
Временное пространство — это неиспользуемое постоянное пространство, которое используется глобальными временными таблицами. Временное пространство также делится на количество AMP.
Терадата — вторичный индекс
Таблица может содержать только один первичный индекс. Чаще всего вы сталкиваетесь со сценариями, в которых таблица содержит другие столбцы, по которым часто осуществляется доступ к данным. Teradata выполнит полное сканирование таблицы для этих запросов. Вторичные индексы решают эту проблему.
Вторичные индексы — это альтернативный путь доступа к данным. Есть некоторые различия между первичным индексом и вторичным индексом.
-
Вторичный индекс не участвует в распределении данных.
-
Значения вторичного индекса хранятся в подстолях. Эти таблицы встроены во все AMP.
-
Вторичные индексы не являются обязательными.
-
Они могут быть созданы во время создания таблицы или после создания таблицы.
-
Они занимают дополнительное пространство, так как они создают вспомогательную таблицу, и они также требуют обслуживания, поскольку вложенные таблицы необходимо обновлять для каждой новой строки.
Вторичный индекс не участвует в распределении данных.
Значения вторичного индекса хранятся в подстолях. Эти таблицы встроены во все AMP.
Вторичные индексы не являются обязательными.
Они могут быть созданы во время создания таблицы или после создания таблицы.
Они занимают дополнительное пространство, так как они создают вспомогательную таблицу, и они также требуют обслуживания, поскольку вложенные таблицы необходимо обновлять для каждой новой строки.
Есть два типа вторичных индексов —
- Уникальный вторичный индекс (USI)
- Неуникальный вторичный индекс (NUSI)
Уникальный вторичный индекс (USI)
Уникальный вторичный индекс допускает только уникальные значения для столбцов, определенных как USI. Доступ к строке по USI — операция с двумя усилителями.
Создать уникальный вторичный индекс
В следующем примере создается USI для столбца EmployeeNo таблицы employee.
CREATE UNIQUE INDEX(EmployeeNo) on employee;
Неуникальный вторичный индекс (NUSI)
Неуникальный вторичный индекс позволяет дублировать значения для столбцов, определенных как NUSI. Доступ к строке по NUSI является операцией на всех усилителях.
Создать неуникальный вторичный индекс
В следующем примере создается NUSI для столбца FirstName таблицы employee.
CREATE INDEX(FirstName) on Employee;
Терадата — Статистика
Оптимизатор Teradata предлагает стратегию выполнения для каждого запроса SQL. Эта стратегия выполнения основана на статистике, собранной для таблиц, используемых в запросе SQL. Статистика в таблице собирается с помощью команды COLLECT STATISTICS. Оптимизатору требуется информация об окружающей среде и демографические данные, чтобы разработать оптимальную стратегию выполнения.
Информация об окружающей среде
- Количество узлов, AMP и процессоров
- Количество памяти
Демография данных
- Количество рядов
- Размер строки
- Диапазон значений в таблице
- Количество строк на значение
- Количество нулей
Существует три подхода для сбора статистики на столе.
- Случайная выборка AMP
- Полный сбор статистики
- Использование опции SAMPLE
Сбор статистики
Команда COLLECT STATISTICS используется для сбора статистики по таблице.
Синтаксис
Ниже приведен основной синтаксис для сбора статистики по таблице.
COLLECT [SUMMARY] STATISTICS INDEX (indexname) COLUMN (columnname) ON <tablename>;
пример
В следующем примере выполняется сбор статистики по столбцу EmployeeNo таблицы Employee.
COLLECT STATISTICS COLUMN(EmployeeNo) ON Employee;
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
*** Update completed. 2 rows changed. *** Total elapsed time was 1 second.
Просмотр статистики
Вы можете просмотреть собранную статистику, используя команду HELP STATISTICS.
Синтаксис
Ниже приведен синтаксис для просмотра собранной статистики.
HELP STATISTICS <tablename>;
пример
Ниже приведен пример для просмотра статистики, собранной в таблице Employee.
HELP STATISTICS employee;
Когда вышеуказанный запрос выполняется, он дает следующий результат.
Date Time Unique Values Column Names -------- -------- -------------------- ----------------------- 16/01/01 08:07:04 5 * 16/01/01 07:24:16 3 DepartmentNo 16/01/01 08:07:04 5 EmployeeNo
Терадата — Сжатие
Сжатие используется для уменьшения памяти, используемой таблицами. В Teradata сжатие может сжимать до 255 различных значений, включая NULL. Поскольку объем хранилища сокращен, Teradata может хранить больше записей в блоке. Это приводит к улучшению времени ответа на запрос, поскольку любая операция ввода-вывода может обрабатывать больше строк на блок. Сжатие может быть добавлено при создании таблицы с помощью CREATE TABLE или после создания таблицы с помощью команды ALTER TABLE.
Ограничения
- Только 255 значений могут быть сжаты в столбце.
- Столбец первичного индекса не может быть сжат.
- Изменчивые таблицы не могут быть сжаты.
Многозначное сжатие (MVC)
Следующая таблица сжимает поле DepatmentNo для значений 1, 2 и 3. Когда сжатие применяется к столбцу, значения для этого столбца не сохраняются вместе со строкой. Вместо этого значения сохраняются в заголовке таблицы в каждом AMP, и в строку добавляются только биты присутствия, чтобы указать значение.
CREATE SET TABLE employee ( EmployeeNo integer, FirstName CHAR(30), LastName CHAR(30), BirthDate DATE FORMAT 'YYYY-MM-DD-', JoinedDate DATE FORMAT 'YYYY-MM-DD-', employee_gender CHAR(1), DepartmentNo CHAR(02) COMPRESS(1,2,3) ) UNIQUE PRIMARY INDEX(EmployeeNo);
Сжатие с несколькими значениями можно использовать, когда у вас есть столбец в большой таблице с конечными значениями.
Терадата — Объяснить
Команда EXPLAIN возвращает план выполнения механизма синтаксического анализа на английском языке. Его можно использовать с любым оператором SQL, кроме как с другой командой EXPLAIN. Когда запросу предшествует команда EXPLAIN, план выполнения механизма синтаксического анализа возвращается пользователю вместо AMP.
Примеры EXPLAIN
Рассмотрим таблицу Employee со следующим определением.
CREATE SET TABLE EMPLOYEE,FALLBACK ( EmployeeNo INTEGER, FirstName VARCHAR(30), LastName VARCHAR(30), DOB DATE FORMAT 'YYYY-MM-DD', JoinedDate DATE FORMAT 'YYYY-MM-DD', DepartmentNo BYTEINT ) UNIQUE PRIMARY INDEX ( EmployeeNo );
Некоторые примеры плана EXPLAIN приведены ниже.
Полное сканирование таблицы (FTS)
Если в операторе SELECT не указано никаких условий, оптимизатор может выбрать полное сканирование таблицы, где осуществляется доступ к каждой строке таблицы.
пример
Ниже приведен пример запроса, в котором оптимизатор может выбрать FTS.
EXPLAIN SELECT * FROM employee;
Когда вышеуказанный запрос выполняется, он производит следующий вывод. Как видно, оптимизатор выбирает доступ ко всем AMP и всем строкам в AMP.
1) First, we lock a distinct TDUSER."pseudo table" for read on a RowHash to prevent global deadlock for TDUSER.employee. 2) Next, we lock TDUSER.employee for read. 3) We do an all-AMPs RETRIEVE step from TDUSER.employee by way of an all-rows scan with no residual conditions into Spool 1 (group_amps), which is built locally on the AMPs. The size of Spool 1 is estimated with low confidence to be 2 rows (116 bytes). The estimated time for this step is 0.03 seconds. 4) Finally, we send out an END TRANSACTION step to all AMPs involved in processing the request. → The contents of Spool 1 are sent back to the user as the result of statement 1. The total estimated time is 0.03 seconds.
Уникальный первичный индекс
Когда доступ к строкам осуществляется с использованием уникального первичного индекса, это одна операция AMP.
EXPLAIN SELECT * FROM employee WHERE EmployeeNo = 101;
Когда вышеуказанный запрос выполняется, он производит следующий вывод. Как можно видеть, это извлечение с одним AMP, и оптимизатор использует уникальный первичный индекс для доступа к строке.
1) First, we do a single-AMP RETRIEVE step from TDUSER.employee by way of the unique primary index "TDUSER.employee.EmployeeNo = 101" with no residual conditions. The estimated time for this step is 0.01 seconds. → The row is sent directly back to the user as the result of statement 1. The total estimated time is 0.01 seconds.
Уникальный вторичный индекс
Когда доступ к строкам осуществляется с использованием уникального вторичного индекса, это операция с двумя амперами.
пример
Рассмотрим таблицу Заработная плата со следующим определением.
CREATE SET TABLE SALARY,FALLBACK ( EmployeeNo INTEGER, Gross INTEGER, Deduction INTEGER, NetPay INTEGER ) PRIMARY INDEX ( EmployeeNo ) UNIQUE INDEX (EmployeeNo);
Рассмотрим следующее утверждение SELECT.
EXPLAIN SELECT * FROM Salary WHERE EmployeeNo = 101;
Когда вышеуказанный запрос выполняется, он производит следующий вывод. Как видно, оптимизатор извлекает строку в двухамперной операции с использованием уникального вторичного индекса.
1) First, we do a two-AMP RETRIEVE step from TDUSER.Salary by way of unique index # 4 "TDUSER.Salary.EmployeeNo = 101" with no residual conditions. The estimated time for this step is 0.01 seconds. → The row is sent directly back to the user as the result of statement 1. The total estimated time is 0.01 seconds.
Дополнительные условия
Ниже приведен список терминов, обычно встречающихся в плане EXPLAIN.
… (Последнее использование) …
Файл спула больше не нужен и будет выпущен после завершения этого шага.
… без остаточных условий …
Все применимые условия были применены к строкам.
… КОНЕЦ СДЕЛКИ …
Блокировки транзакций снимаются, и изменения фиксируются.
… устранение дублирующихся строк …
Дублирующиеся строки существуют только в файлах спула, а не в таблицах. Выполнение операции DISTINCT.
… путем обхода индекса #n, извлекающего только идентификаторы строк …
Создается буферный файл, содержащий идентификаторы строк, найденные во вторичном индексе (индекс #n)
… мы делаем смс (установить шаг манипуляции) …
Объединение строк с использованием оператора UNION, MINUS или INTERSECT.
… который перераспределяется по хэш-коду для всех AMP.
Перераспределение данных при подготовке к объединению.
… который дублируется на всех AMP.
Дублирование данных из таблицы меньшего размера (с точки зрения SPOOL) при подготовке к объединению.
… (one_AMP) или (group_AMPs)
Указывает, что вместо всех AMP будет использоваться один AMP или подмножество AMP.
Teradata — алгоритм хеширования
Строка назначается конкретному AMP на основе значения первичного индекса. Teradata использует алгоритм хеширования, чтобы определить, какой AMP получает строку.
Ниже приведена диаграмма высокого уровня алгоритма хеширования.
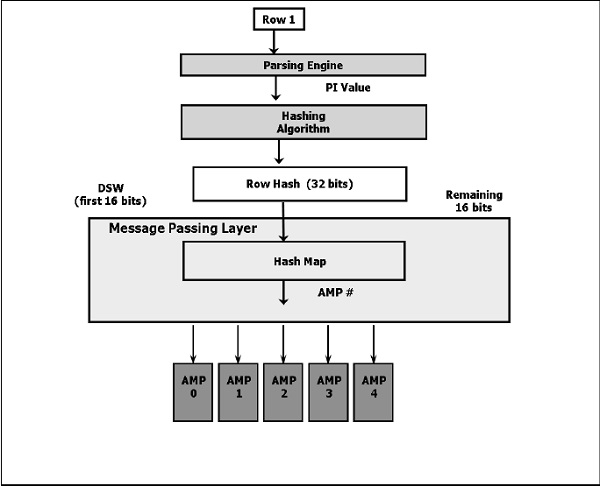
Ниже приведены шаги для вставки данных.
-
Клиент отправляет запрос.
-
Парсер получает запрос и передает значение PI записи в алгоритм хэширования.
-
Алгоритм хеширования хеширует значение основного индекса и возвращает 32-битное число, называемое хэш-строкой.
-
Биты высшего порядка хэша строки (первые 16 бит) используются для идентификации записи карты хеша. Хеш-карта содержит один AMP #. Хэш-карта — это массив блоков, который содержит конкретный номер AMP.
-
BYNET отправляет данные в указанный AMP.
-
AMP использует 32-битный хэш строки, чтобы найти строку на своем диске.
-
Если есть какая-либо запись с таким же хешем строки, то она увеличивает идентификатор уникальности, который является 32-битным числом. Для нового хэша строки идентификатор уникальности присваивается как 1 и увеличивается всякий раз, когда вставляется запись с таким же хэшем строки.
-
Сочетание хэша строки и идентификатора уникальности называется идентификатором строки.
-
Идентификатор строки префикс каждой записи на диске.
-
Каждая строка таблицы в AMP логически сортируется по их идентификаторам строк.
Клиент отправляет запрос.
Парсер получает запрос и передает значение PI записи в алгоритм хэширования.
Алгоритм хеширования хеширует значение основного индекса и возвращает 32-битное число, называемое хэш-строкой.
Биты высшего порядка хэша строки (первые 16 бит) используются для идентификации записи карты хеша. Хеш-карта содержит один AMP #. Хэш-карта — это массив блоков, который содержит конкретный номер AMP.
BYNET отправляет данные в указанный AMP.
AMP использует 32-битный хэш строки, чтобы найти строку на своем диске.
Если есть какая-либо запись с таким же хешем строки, то она увеличивает идентификатор уникальности, который является 32-битным числом. Для нового хэша строки идентификатор уникальности присваивается как 1 и увеличивается всякий раз, когда вставляется запись с таким же хэшем строки.
Сочетание хэша строки и идентификатора уникальности называется идентификатором строки.
Идентификатор строки префикс каждой записи на диске.
Каждая строка таблицы в AMP логически сортируется по их идентификаторам строк.
Как хранятся таблицы
Таблицы сортируются по их идентификатору строки (хэш строки + идентификатор уникальности) и затем сохраняются в AMP. Идентификатор строки сохраняется с каждой строкой данных.
| Ряд хэш | ID уникальности | Сотрудник № | Имя | Фамилия |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | Майк | Джеймс |
| 2A01 2612 | 0000 0001 | 104 | Alex | Стюарт |
| 2A01 2613 | 0000 0001 | 102 | Роберт | Williams |
| 2A01 2614 | 0000 0001 | 105 | Роберт | Джеймс |
| 2A01 2615 | 0000 0001 | 103 | Питер | Павел |
Teradata — Индекс JOIN
JOIN INDEX — это материализованное представление. Его определение постоянно сохраняется, и данные обновляются всякий раз, когда обновляются базовые таблицы, указанные в индексе соединения. ИНДЕКС СОЕДИНЕНИЯ может содержать одну или несколько таблиц, а также содержать предварительно агрегированные данные. Индексы объединения в основном используются для повышения производительности.
Доступны разные типы индексов соединения.
- Индекс объединения в одну таблицу (STJI)
- Индекс объединения нескольких таблиц (MTJI)
- Совокупный индекс присоединения (AJI)
Индекс объединения в одну таблицу
Индекс объединения отдельных таблиц позволяет разбить большую таблицу на основе столбцов первичного индекса, отличных от столбца базовой таблицы.
Синтаксис
Ниже приведен синтаксис JOIN INDEX.
CREATE JOIN INDEX <index name> AS <SELECT Query> <Index Definition>;
пример
Рассмотрим следующие таблицы сотрудников и зарплат.
CREATE SET TABLE EMPLOYEE,FALLBACK ( EmployeeNo INTEGER, FirstName VARCHAR(30) , LastName VARCHAR(30) , DOB DATE FORMAT 'YYYY-MM-DD', JoinedDate DATE FORMAT 'YYYY-MM-DD', DepartmentNo BYTEINT ) UNIQUE PRIMARY INDEX ( EmployeeNo ); CREATE SET TABLE SALARY,FALLBACK ( EmployeeNo INTEGER, Gross INTEGER, Deduction INTEGER, NetPay INTEGER ) PRIMARY INDEX ( EmployeeNo ) UNIQUE INDEX (EmployeeNo);
Ниже приведен пример, который создает индекс соединения с именем Employee_JI для таблицы Employee.
CREATE JOIN INDEX Employee_JI AS SELECT EmployeeNo,FirstName,LastName, BirthDate,JoinedDate,DepartmentNo FROM Employee PRIMARY INDEX(FirstName);
Если пользователь отправляет запрос с предложением WHERE в EmployeeNo, то система запросит таблицу Employee, используя уникальный первичный индекс. Если пользователь запрашивает таблицу сотрудников, используя employee_name, тогда система может получить доступ к индексу соединения Employee_JI, используя employee_name. Строки индекса соединения хэшируются в столбце employee_name. Если индекс соединения не определен, а имя сотрудника не определено как вторичный индекс, тогда система выполнит полное сканирование таблицы, чтобы получить доступ к строкам, которые занимают много времени.
Вы можете запустить следующий план EXPLAIN и проверить план оптимизатора. В следующем примере вы можете видеть, что оптимизатор использует индекс соединения вместо базовой таблицы Employee, когда таблица запрашивает с использованием столбца Employee_Name.
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
*** Help information returned. 8 rows.
*** Total elapsed time was 1 second.
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.
Индекс объединения нескольких таблиц
Индекс объединения нескольких таблиц создается путем объединения нескольких таблиц. Индекс объединения нескольких таблиц может использоваться для хранения результирующего набора часто соединяемых таблиц для повышения производительности.
пример
В следующем примере создается JOIN INDEX с именем Employee_Salary_JI путем объединения таблиц Employee и Salary.
CREATE JOIN INDEX Employee_Salary_JI AS SELECT a.EmployeeNo,a.FirstName,a.LastName, a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay FROM Employee a INNER JOIN Salary b ON(a.EmployeeNo = b.EmployeeNo) PRIMARY INDEX(FirstName);
Всякий раз, когда обновляются базовые таблицы Employee или Salary, индекс соединения Employee_Salary_JI также автоматически обновляется. Если вы выполняете запрос, соединяющий таблицы Employee и Salary, оптимизатор может выбрать прямой доступ к данным из Employee_Salary_JI, а не к таблицам. План EXPLAIN по запросу можно использовать для проверки того, выберет ли оптимизатор базовую таблицу или индекс соединения.
Совокупный индекс присоединения
Если таблица последовательно агрегируется в определенных столбцах, то для повышения производительности можно определить агрегированный индекс соединения. Одним из ограничений агрегатного индекса соединения является то, что он поддерживает только функции SUM и COUNT.
пример
В следующем примере Сотрудник и Зарплата объединяются для определения общей заработной платы по отделу.
CREATE JOIN INDEX Employee_Salary_JI AS SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay FROM Employee a INNER JOIN Salary b ON(a.EmployeeNo = b.EmployeeNo) GROUP BY a.DepartmentNo Primary Index(DepartmentNo);
Teradata — Просмотров
Представления — это объекты базы данных, построенные по запросу. Представления могут быть построены с использованием одной таблицы или нескольких таблиц путем объединения. Их определение постоянно хранится в словаре данных, но они не хранят копию данных. Данные для представления строятся динамически.
Представление может содержать подмножество строк таблицы или подмножество столбцов таблицы.
Создать представление
Представления создаются с помощью оператора CREATE VIEW.
Синтаксис
Ниже приведен синтаксис для создания представления.
CREATE/REPLACE VIEW <viewname> AS <select query>;
пример
Рассмотрим следующую таблицу сотрудников.
| Сотрудник № | Имя | Фамилия | Дата рождения |
|---|---|---|---|
| 101 | Майк | Джеймс | 1/5/1980 |
| 104 | Alex | Стюарт | 11/6/1984 |
| 102 | Роберт | Williams | 3/5/1983 |
| 105 | Роберт | Джеймс | 12/1/1984 |
| 103 | Питер | Павел | 4/1/1983 |
В следующем примере создается представление таблицы Employee.
CREATE VIEW Employee_View AS SELECT EmployeeNo, FirstName, LastName, FROM Employee;
Использование представлений
Вы можете использовать обычный оператор SELECT для извлечения данных из представлений.
пример
В следующем примере извлекаются записи из Employee_View;
SELECT EmployeeNo, FirstName, LastName FROM Employee_View;
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter Paul
Изменение видов
Существующее представление можно изменить с помощью оператора REPLACE VIEW.
Ниже приведен синтаксис для изменения представления.
REPLACE VIEW <viewname> AS <select query>;
пример
В следующем примере изменяется вид Employee_View для добавления дополнительных столбцов.
REPLACE VIEW Employee_View AS SELECT EmployeeNo, FirstName, BirthDate, JoinedDate DepartmentNo FROM Employee;
Drop View
Существующее представление можно отбросить с помощью оператора DROP VIEW.
Синтаксис
Ниже приводится синтаксис DROP VIEW.
DROP VIEW <viewname>;
пример
Ниже приведен пример удаления представления Employee_View.
DROP VIEW Employee_View;
Преимущества просмотров
-
Представления обеспечивают дополнительный уровень безопасности, ограничивая строки или столбцы таблицы.
-
Пользователям может быть предоставлен доступ только к представлениям вместо базовых таблиц.
-
Упрощает использование нескольких таблиц, предварительно соединяя их с помощью Views.
Представления обеспечивают дополнительный уровень безопасности, ограничивая строки или столбцы таблицы.
Пользователям может быть предоставлен доступ только к представлениям вместо базовых таблиц.
Упрощает использование нескольких таблиц, предварительно соединяя их с помощью Views.
Teradata — Макросы
Макрос — это набор операторов SQL, которые сохраняются и выполняются путем вызова имени макроса. Определение макросов хранится в словаре данных. Пользователям нужна только привилегия EXEC для выполнения макроса. Пользователям не нужны отдельные привилегии для объектов базы данных, используемых внутри макроса. Макро операторы выполняются как одна транзакция. В случае сбоя одного из операторов SQL в макросе все операторы откатываются. Макросы могут принимать параметры. Макросы могут содержать операторы DDL, но это должен быть последний оператор в макросе.
Создать макросы
Макросы создаются с помощью оператора CREATE MACRO.
Синтаксис
Ниже приведен общий синтаксис команды CREATE MACRO.
CREATE MACRO <macroname> [(parameter1, parameter2,...)] ( <sql statements> );
пример
Рассмотрим следующую таблицу сотрудников.
| Сотрудник № | Имя | Фамилия | Дата рождения |
|---|---|---|---|
| 101 | Майк | Джеймс | 1/5/1980 |
| 104 | Alex | Стюарт | 11/6/1984 |
| 102 | Роберт | Williams | 3/5/1983 |
| 105 | Роберт | Джеймс | 12/1/1984 |
| 103 | Питер | Павел | 4/1/1983 |
В следующем примере создается макрос с именем Get_Emp. Он содержит оператор выбора для извлечения записей из таблицы сотрудников.
CREATE MACRO Get_Emp AS ( SELECT EmployeeNo, FirstName, LastName FROM employee ORDER BY EmployeeNo; );
Выполнение макросов
Макросы выполняются с помощью команды EXEC.
Синтаксис
Ниже приводится синтаксис команды EXECUTE MACRO.
EXEC <macroname>;
пример
В следующем примере выполняются имена макросов Get_Emp; Когда следующая команда выполняется, она извлекает все записи из таблицы сотрудников.
EXEC Get_Emp; *** Query completed. 5 rows found. 3 columns returned. *** Total elapsed time was 1 second. EmployeeNo FirstName LastName ----------- ------------------------------ --------------------------- 101 Mike James 102 Robert Williams 103 Peter Paul 104 Alex Stuart 105 Robert James
Параметризованные макросы
Макросы Teradata могут принимать параметры. В макросе на эти параметры ссылаются; (точка с запятой).
Ниже приведен пример макроса, который принимает параметры.
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS ( SELECT EmployeeNo, NetPay FROM Salary WHERE EmployeeNo = :EmployeeNo; );
Выполнение параметризованных макросов
Макросы выполняются с помощью команды EXEC. Вам нужны привилегии EXEC для выполнения макросов.
Синтаксис
Ниже приведен синтаксис оператора EXECUTE MACRO.
EXEC <macroname>(value);
пример
В следующем примере выполняются имена макросов Get_Emp; Он принимает сотрудника нет в качестве параметра и извлекает записи из таблицы сотрудников для этого сотрудника.
EXEC Get_Emp_Salary(101); *** Query completed. One row found. 2 columns returned. *** Total elapsed time was 1 second. EmployeeNo NetPay ----------- ------------ 101 36000
Teradata — хранимая процедура
Хранимая процедура содержит набор операторов SQL и процедурных операторов. Они могут содержать только процедурные заявления. Определение хранимой процедуры хранится в базе данных, а параметры хранятся в таблицах словаря данных.
преимущества
-
Хранимые процедуры снижают нагрузку на сеть между клиентом и сервером.
-
Обеспечивает лучшую безопасность, поскольку доступ к данным осуществляется через хранимые процедуры, а не напрямую.
-
Обеспечивает лучшее обслуживание, поскольку бизнес-логика проверяется и хранится на сервере.
Хранимые процедуры снижают нагрузку на сеть между клиентом и сервером.
Обеспечивает лучшую безопасность, поскольку доступ к данным осуществляется через хранимые процедуры, а не напрямую.
Обеспечивает лучшее обслуживание, поскольку бизнес-логика проверяется и хранится на сервере.
Процедура создания
Хранимые процедуры создаются с использованием оператора CREATE PROCEDURE.
Синтаксис
Ниже приведен общий синтаксис оператора CREATE PROCEDURE.
CREATE PROCEDURE <procedurename> ( [parameter 1 data type, parameter 2 data type..] ) BEGIN <SQL or SPL statements>; END;
пример
Рассмотрим следующую таблицу зарплат.
| Сотрудник № | Валовой | дедукция | NetPay |
|---|---|---|---|
| 101 | 40000 | 4000 | 36000 |
| 102 | 80000 | 6000 | 74000 |
| 103 | 90000 | 7000 | 83000 |
| 104 | 75000 | 5000 | 70000 |
В следующем примере создается хранимая процедура с именем InsertSalary для принятия значений и вставки в таблицу зарплат.
CREATE PROCEDURE InsertSalary ( IN in_EmployeeNo INTEGER, IN in_Gross INTEGER, IN in_Deduction INTEGER, IN in_NetPay INTEGER ) BEGIN INSERT INTO Salary ( EmployeeNo, Gross, Deduction, NetPay ) VALUES ( :in_EmployeeNo, :in_Gross, :in_Deduction, :in_NetPay ); END;
Выполнение процедур
Хранимые процедуры выполняются с использованием оператора CALL.
Синтаксис
Ниже приведен общий синтаксис оператора CALL.
CALL <procedure name> [(parameter values)];
пример
В следующем примере вызывается хранимая процедура InsertSalary и вставляется запись в таблицу зарплат.
CALL InsertSalary(105,20000,2000,18000);
Как только вышеуказанный запрос выполнен, он производит следующий вывод, и вы можете видеть вставленную строку в таблице Salary.
| Сотрудник № | Валовой | дедукция | NetPay |
|---|---|---|---|
| 101 | 40000 | 4000 | 36000 |
| 102 | 80000 | 6000 | 74000 |
| 103 | 90000 | 7000 | 83000 |
| 104 | 75000 | 5000 | 70000 |
| 105 | 20000 | 2000 | 18 000 |
Teradata — стратегии JOIN
В этой главе рассматриваются различные стратегии JOIN, доступные в Teradata.
Методы соединения
Teradata использует различные методы соединения для выполнения операций соединения. Некоторые из наиболее часто используемых методов соединения —
- Объединить присоединиться
- Вложенное соединение
- Регистрация продукта
Объединить присоединиться
Метод Merge Join имеет место, когда соединение основано на условии равенства. Соединение слиянием требует, чтобы соединяющиеся строки были на одном AMP. Строки объединяются на основе их хеш-функции. Объединение слиянием использует разные стратегии объединения, чтобы привести строки к одному AMP.
Стратегия № 1
Если соединительные столбцы являются первичными индексами соответствующих таблиц, то соединительные строки уже находятся в том же AMP. В этом случае распространение не требуется.
Рассмотрим следующие таблицы сотрудников и зарплат.
CREATE SET TABLE EMPLOYEE,FALLBACK ( EmployeeNo INTEGER, FirstName VARCHAR(30) , LastName VARCHAR(30) , DOB DATE FORMAT 'YYYY-MM-DD', JoinedDate DATE FORMAT 'YYYY-MM-DD', DepartmentNo BYTEINT ) UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE Salary ( EmployeeNo INTEGER, Gross INTEGER, Deduction INTEGER, NetPay INTEGER ) UNIQUE PRIMARY INDEX(EmployeeNo);
Когда эти две таблицы объединяются в столбце EmployeeNo, перераспределение не происходит, так как EmployeeNo является основным индексом обеих таблиц, которые объединяются.
Стратегия № 2
Рассмотрим следующие таблицы сотрудников и отделов.
CREATE SET TABLE EMPLOYEE,FALLBACK ( EmployeeNo INTEGER, FirstName VARCHAR(30) , LastName VARCHAR(30) , DOB DATE FORMAT 'YYYY-MM-DD', JoinedDate DATE FORMAT 'YYYY-MM-DD', DepartmentNo BYTEINT ) UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE DEPARTMENT,FALLBACK ( DepartmentNo BYTEINT, DepartmentName CHAR(15) ) UNIQUE PRIMARY INDEX ( DepartmentNo );
Если эти две таблицы объединены в столбце DeparmentNo, то строки необходимо перераспределить, поскольку DepartmentNo является первичным индексом в одной таблице и неосновным индексом в другой таблице. В этом случае объединяющиеся строки могут не находиться в одном AMP. В этом случае Teradata может перераспределить таблицу сотрудников по столбцу DepartmentNo.
Стратегия № 3
Для приведенных выше таблиц Employee и Department Teradata может дублировать таблицу Department во всех AMP, если размер таблицы Department невелик.
Вложенное соединение
Nested Join не использует все AMP. Для выполнения вложенного соединения одним из условий должно быть равенство уникального первичного индекса одной таблицы, а затем присоединение этого столбца к любому индексу другой таблицы.
В этом случае система извлекает одну строку, используя уникальный первичный индекс одной таблицы, и использует этот хэш строки для извлечения совпадающих записей из другой таблицы. Вложенное соединение — самый эффективный из всех методов соединения.
Регистрация продукта
Product Join сравнивает каждую подходящую строку из одной таблицы с каждой подходящей строкой из другой таблицы. Присоединение продукта может происходить из-за следующих факторов:
- Где условие отсутствует.
- Условие соединения не основано на условии равенства.
- Таблица псевдонимов не является правильным.
- Несколько условий объединения.
Teradata — разделенный первичный индекс
Секционированный первичный индекс (PPI) — это механизм индексации, который полезен для повышения производительности определенных запросов. Когда строки вставляются в таблицу, они сохраняются в AMP и располагаются в порядке их хэширования. Когда таблица определена с помощью PPI, строки сортируются по номеру раздела. Внутри каждого раздела они располагаются по хешу строк. Строки присваиваются разделу на основе определенного выражения раздела.
преимущества
-
Избегайте полного сканирования таблицы для определенных запросов.
-
Избегайте использования вторичного индекса, который требует дополнительной физической структуры и дополнительного обслуживания ввода-вывода.
-
Быстрый доступ к подмножеству большой таблицы.
-
Быстро отбросьте старые данные и добавьте новые.
Избегайте полного сканирования таблицы для определенных запросов.
Избегайте использования вторичного индекса, который требует дополнительной физической структуры и дополнительного обслуживания ввода-вывода.
Быстрый доступ к подмножеству большой таблицы.
Быстро отбросьте старые данные и добавьте новые.
пример
Рассмотрим следующую таблицу «Заказы» с первичным индексом для номера заказа.
| Хранить нет | № заказа | Дата заказа | Весь заказ |
|---|---|---|---|
| 101 | 7501 | 2015-10-01 | 900 |
| 101 | 7502 | 2015-10-02 | 1200 |
| 102 | 7503 | 2015-10-02 | 3000 |
| 102 | 7504 | 2015-10-03 | 2454 |
| 101 | 7505 | 2015-10-03 | 1201 |
| 103 | 7506 | 2015-10-04 | 2454 |
| 101 | 7507 | 2015-10-05 | 1201 |
| 101 | 7508 | 2015-10-05 | 1201 |
Предположим, что записи распределены между AMP, как показано в следующих таблицах. Записанные данные хранятся в AMP, сортируются по их хешу строк.
| RowHash | № заказа | Дата заказа |
|---|---|---|
| 1 | 7505 | 2015-10-03 |
| 2 | 7504 | 2015-10-03 |
| 3 | 7501 | 2015-10-01 |
| 4 | 7508 | 2015-10-05 |
| RowHash | № заказа | Дата заказа |
|---|---|---|
| 1 | 7507 | 2015-10-05 |
| 2 | 7502 | 2015-10-02 |
| 3 | 7506 | 2015-10-04 |
| 4 | 7503 | 2015-10-02 |
Если вы запустите запрос для извлечения заказов на определенную дату, тогда оптимизатор может выбрать использование полного сканирования таблицы, тогда будут доступны все записи в AMP. Чтобы избежать этого, вы можете определить дату заказа как первичный индекс с разделами. Когда строки вставляются в таблицу заказов, они разбиваются по дате заказа. Внутри каждого раздела они будут упорядочены по хешу строк.
Следующие данные показывают, как записи будут храниться в AMP, если они разбиты по дате заказа. Если запрос выполняется для доступа к записям по дате заказа, то будет доступен только раздел, содержащий записи для этого конкретного заказа.
| раздел | RowHash | № заказа | Дата заказа |
|---|---|---|---|
| 0 | 3 | 7501 | 2015-10-01 |
| 1 | 1 | 7505 | 2015-10-03 |
| 1 | 2 | 7504 | 2015-10-03 |
| 2 | 4 | 7508 | 2015-10-05 |
| раздел | RowHash | № заказа | Дата заказа |
|---|---|---|---|
| 0 | 2 | 7502 | 2015-10-02 |
| 0 | 4 | 7503 | 2015-10-02 |
| 1 | 3 | 7506 | 2015-10-04 |
| 2 | 1 | 7507 | 2015-10-05 |
Ниже приведен пример создания таблицы с разделом первичного индекса. Предложение PARTITION BY используется для определения раздела.
CREATE SET TABLE Orders ( StoreNo SMALLINT, OrderNo INTEGER, OrderDate DATE FORMAT 'YYYY-MM-DD', OrderTotal INTEGER ) PRIMARY INDEX(OrderNo) PARTITION BY RANGE_N ( OrderDate BETWEEN DATE '2010-01-01' AND '2016-12-31' EACH INTERVAL '1' DAY );
В приведенном выше примере таблица разделена по столбцу OrderDate. Там будет один отдельный раздел на каждый день.
Teradata — OLAP Функции
Функции OLAP аналогичны агрегатным функциям, за исключением того, что агрегатные функции будут возвращать только одно значение, тогда как функция OLAP будет предоставлять отдельные строки в дополнение к агрегатам.
Синтаксис
Ниже приведен общий синтаксис функции OLAP.
<aggregate function> OVER ([PARTITION BY] [ORDER BY columnname][ROWS BETWEEN UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING)
Функции агрегации могут быть SUM, COUNT, MAX, MIN, AVG.
пример
Рассмотрим следующую таблицу зарплат.
| Сотрудник № | Валовой | дедукция | NetPay |
|---|---|---|---|
| 101 | 40000 | 4000 | 36000 |
| 102 | 80000 | 6000 | 74000 |
| 103 | 90000 | 7000 | 83000 |
| 104 | 75000 | 5000 | 70000 |
Ниже приведен пример для определения накопленной суммы или промежуточной суммы NetPay в таблице зарплаты. Записи сортируются по EmployeeNo, а совокупная сумма рассчитывается по столбцу NetPay.
SELECT EmployeeNo, NetPay, SUM(Netpay) OVER(ORDER BY EmployeeNo ROWS UNBOUNDED PRECEDING) as TotalSalary FROM Salary;
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
EmployeeNo NetPay TotalSalary ----------- ----------- ----------- 101 36000 36000 102 74000 110000 103 83000 193000 104 70000 263000 105 18000 281000
РАНГ
Функция RANK упорядочивает записи на основе предоставленного столбца. Функция RANK также может фильтровать количество записей, возвращаемых на основе ранга.
Синтаксис
Ниже приведен общий синтаксис для использования функции RANK.
RANK() OVER ([PARTITION BY columnnlist] [ORDER BY columnlist][DESC|ASC])
пример
Рассмотрим следующую таблицу сотрудников.
| Сотрудник № | Имя | Фамилия | JoinedDate | DepartmentID | Дата рождения |
|---|---|---|---|---|---|
| 101 | Майк | Джеймс | 3/27/2005 | 1 | 1/5/1980 |
| 102 | Роберт | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Питер | Павел | 3/21/2007 | 2 | 4/1/1983 |
| 104 | Alex | Стюарт | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Роберт | Джеймс | 1/4/2008 | 3 | 12/1/1984 |
Следующий запрос упорядочивает записи таблицы сотрудников по дате присоединения и присваивает ранжирование по дате присоединения.
SELECT EmployeeNo, JoinedDate,RANK() OVER(ORDER BY JoinedDate) as Seniority FROM Employee;
Когда вышеуказанный запрос выполняется, он производит следующий вывод.
EmployeeNo JoinedDate Seniority ----------- ---------- ----------- 101 2005-03-27 1 103 2007-03-21 2 102 2007-04-25 3 105 2008-01-04 4 104 2008-02-01 5
Предложение PARTITION BY группирует данные по столбцам, определенным в предложении PARTITION BY, и выполняет функцию OLAP в каждой группе. Ниже приведен пример запроса, в котором используется предложение PARTITION BY.
SELECT EmployeeNo, JoinedDate,RANK() OVER(PARTITION BY DeparmentNo ORDER BY JoinedDate) as Seniority FROM Employee;
Когда вышеуказанный запрос выполняется, он производит следующий вывод. Вы можете видеть, что ранг сбрасывается для каждого отдела.
EmployeeNo DepartmentNo JoinedDate Seniority
----------- ------------ ---------- -----------
101 1 2005-03-27 1
103 2 2007-03-21 1
102 2 2007-04-25 2
104 2 2008-02-01 3
105 3 2008-01-04 1
Teradata — Защита данных
В этой главе рассматриваются функции, доступные для защиты данных в Teradata.
Переходный журнал
Teradata использует Transient Journal для защиты данных от сбоев транзакций. Всякий раз, когда выполняются какие-либо транзакции, временный журнал хранит копию предыдущих изображений затронутых строк до тех пор, пока транзакция не будет выполнена успешно или откат успешно. Затем предыдущие изображения отбрасываются. Временные журналы хранятся в каждом AMP. Это автоматический процесс, и его нельзя отключить.
Отступать
Fallback защищает данные таблицы, сохраняя вторую копию строк таблицы в другом AMP, называемом Fallback AMP. Если происходит сбой одного AMP, доступ к резервным строкам. При этом, даже если один AMP выходит из строя, данные по-прежнему доступны через резервный AMP. Резервный вариант можно использовать при создании таблицы или после создания таблицы. Резервный режим гарантирует, что вторая копия строк таблицы всегда хранится в другом AMP, чтобы защитить данные от сбоя AMP. Однако резервная копия занимает вдвое больше памяти и ввода-вывода для вставки / удаления / обновления.
Следующая диаграмма показывает, как резервные копии строк хранятся в другом AMP.
Down AMP Recovery Journal
Журнал восстановления Down AMP активируется при сбое AMP и защите таблицы от сбоев. Этот журнал отслеживает все изменения данных несостоявшегося AMP. Журнал активируется на остальных AMP в кластере. Это автоматический процесс, и его нельзя отключить. После сбоя AMP данные из журнала восстановления Down AMP синхронизируются с AMP. Как только это сделано, журнал отбрасывается.
Клик
Клика — это механизм, используемый Teradata для защиты данных от сбоев Node. Клика — это не что иное, как набор узлов Teradata, которые совместно используют общий набор дисковых массивов. Когда происходит сбой узла, vprocs из отказавшего узла мигрирует на другие узлы в клике и продолжает получать доступ к своим дисковым массивам.
Горячий резервный узел
Узел горячего резервирования — это узел, который не участвует в производственной среде. Если узел выходит из строя, то vprocs из вышедших из строя узлов мигрирует в узел горячего резервирования. После восстановления неисправного узла он становится узлом горячего резервирования. Узлы горячего резервирования используются для поддержания производительности в случае сбоев узлов.
RAID
Резервный массив независимых дисков (RAID) — это механизм, используемый для защиты данных от сбоев диска. Дисковый массив состоит из набора дисков, которые сгруппированы как логическая единица. Этот блок может выглядеть как один блок для пользователя, но они могут быть распределены по нескольким дискам.
RAID 1 обычно используется в Teradata. В RAID 1 каждый диск связан с зеркальным диском. Любые изменения данных на первичном диске также отражаются в зеркальной копии. В случае сбоя основного диска можно получить доступ к данным с зеркального диска.
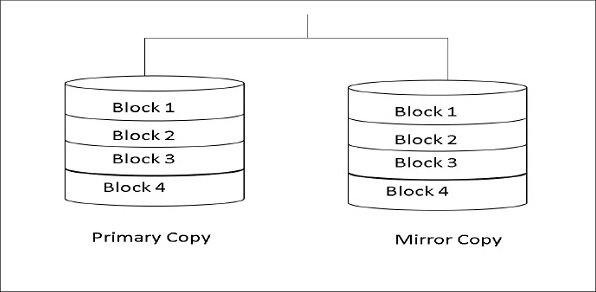
Teradata — Управление пользователями
В этой главе обсуждались различные стратегии управления пользователями в Teradata.
пользователей
Пользователь создается с помощью команды CREATE USER. В Teradata пользователь также похож на базу данных. Им обоим может быть назначено пространство и они содержат объекты базы данных, за исключением того, что пользователю назначен пароль.
Синтаксис
Ниже приводится синтаксис CREATE USER.
CREATE USER username AS [PERMANENT|PERM] = n BYTES PASSWORD = password TEMPORARY = n BYTES SPOOL = n BYTES;
При создании пользователя обязательны значения имени пользователя, постоянного пространства и пароля. Другие поля являются необязательными.
пример
Ниже приведен пример для создания пользователя TD01.
CREATE USER TD01 AS PERMANENT = 1000000 BYTES PASSWORD = ABC$124 TEMPORARY = 1000000 BYTES SPOOL = 1000000 BYTES;
Счета
При создании нового пользователя пользователь может быть привязан к учетной записи. Опция ACCOUNT в CREATE USER используется для назначения учетной записи. Пользователь может быть назначен на несколько учетных записей.
Синтаксис
Ниже приведен синтаксис CREATE USER с опцией учетной записи.
CREATE USER username PERM = n BYTES PASSWORD = password ACCOUNT = accountid
пример
В следующем примере создается пользователь TD02 и назначается учетная запись как ИТ и администратор.
CREATE USER TD02 AS PERMANENT = 1000000 BYTES PASSWORD = abc$123 TEMPORARY = 1000000 BYTES SPOOL = 1000000 BYTES ACCOUNT = (‘IT’,’Admin’);
Пользователь может указать идентификатор учетной записи при входе в систему Teradata или после входа в систему с помощью команды SET SESSION.
.LOGON username, passowrd,accountid OR SET SESSION ACCOUNT = accountid
Предоставить привилегии
Команда GRANT используется для назначения пользователю или базе данных одной или нескольких привилегий на объектах базы данных.
Синтаксис
Ниже приводится синтаксис команды GRANT.
GRANT privileges ON objectname TO username;
Привилегии могут быть ВСТАВИТЬ, ВЫБРАТЬ, ОБНОВИТЬ, ССЫЛКИ.
пример
Ниже приведен пример заявления GRANT.
GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;
Отозвать привилегии
Команда REVOKE удаляет привилегии пользователей или баз данных. Команда REVOKE может удалить только явные привилегии.
Синтаксис
Ниже приведен основной синтаксис команды REVOKE.
REVOKE [ALL|privileges] ON objectname FROM username;
пример
Ниже приведен пример команды REVOKE.
REVOKE INSERT,SELECT ON Employee FROM TD01;
Teradata — настройка производительности
В этой главе обсуждается процедура настройки производительности в Teradata.
объяснять
Первым шагом в настройке производительности является использование EXPLAIN в вашем запросе. План EXPLAIN содержит подробную информацию о том, как оптимизатор выполнит ваш запрос. В плане объяснения проверьте ключевые слова, такие как уровень достоверности, используемая стратегия объединения, размер файла спула, перераспределение и т. Д.
Собирать статистику
Оптимизатор использует демографию данных для разработки эффективной стратегии исполнения. Команда COLLECT STATISTICS используется для сбора демографических данных таблицы. Убедитесь, что статистика, собранная по столбцам, актуальна.
-
Соберите статистику по столбцам, которые используются в предложении WHERE, и по столбцам, используемым в условии соединения.
-
Сбор статистики по столбцам Уникальный первичный индекс.
-
Сбор статистики по столбцам Неуникальный вторичный индекс. Оптимизатор решит, может ли он использовать NUSI или Full Table Scan.
-
Соберите статистику по индексу соединения, хотя статистика по базовой таблице собрана.
-
Сбор статистики по разделам столбцов.
Соберите статистику по столбцам, которые используются в предложении WHERE, и по столбцам, используемым в условии соединения.
Сбор статистики по столбцам Уникальный первичный индекс.
Сбор статистики по столбцам Неуникальный вторичный индекс. Оптимизатор решит, может ли он использовать NUSI или Full Table Scan.
Соберите статистику по индексу соединения, хотя статистика по базовой таблице собрана.
Сбор статистики по разделам столбцов.
Типы данных
Убедитесь, что используются правильные типы данных. Это позволит избежать использования чрезмерного хранения, чем требуется.
преобразование
Убедитесь, что типы данных столбцов, используемых в условии соединения, совместимы, чтобы избежать явного преобразования данных.
Сортировать
Удалите ненужные предложения ORDER BY, если это не требуется.
Спул Пространство Проблема
Ошибка места в буфере генерируется, если запрос превышает ограничение на объем буфера в AMP для этого пользователя. Проверьте план объяснения и определите шаг, который занимает больше места в буфере. Эти промежуточные запросы можно разделить и разместить отдельно для построения временных таблиц.
Основной индекс
Убедитесь, что первичный индекс правильно определен для таблицы. Столбец первичного индекса должен равномерно распределять данные и должен часто использоваться для доступа к данным.
SET Table
Если вы определите таблицу SET, оптимизатор проверит, является ли запись дубликатом для каждой вставленной записи. Чтобы удалить дублирующее условие проверки, вы можете определить уникальный вторичный индекс для таблицы.
ОБНОВЛЕНИЕ на большом столе
Обновление большой таблицы займет много времени. Вместо обновления таблицы вы можете удалить записи и вставить записи с измененными строками.
Удаление временных таблиц
Удалите временные таблицы (промежуточные таблицы) и volatiles, если они больше не нужны. Это высвободит постоянное пространство и освободит место.
МУЛЬТИСЕТ Стол
Если вы уверены, что входные записи не будут иметь повторяющихся записей, то вы можете определить целевую таблицу как таблицу MULTISET, чтобы избежать проверки повторяющихся строк, используемой таблицей SET.
Teradata — FastLoad
Утилита FastLoad используется для загрузки данных в пустые таблицы. Поскольку он не использует временные журналы, данные могут быть загружены быстро. Он не загружает повторяющиеся строки, даже если целевая таблица является таблицей MULTISET.
ограничение
Таблица назначения не должна иметь вторичного индекса, индекса соединения и ссылки на внешний ключ.
Как работает FastLoad
FastLoad выполняется в два этапа.
Фаза 1
-
Механизмы синтаксического анализа считывают записи из входного файла и отправляют блок каждому AMP.
-
Каждый AMP хранит блоки записей.
-
Затем AMP хэшируют каждую запись и перераспределяют их в правильный AMP.
-
В конце Фазы 1 у каждого AMP есть свои строки, но они не находятся в последовательности хэша строки.
Механизмы синтаксического анализа считывают записи из входного файла и отправляют блок каждому AMP.
Каждый AMP хранит блоки записей.
Затем AMP хэшируют каждую запись и перераспределяют их в правильный AMP.
В конце Фазы 1 у каждого AMP есть свои строки, но они не находятся в последовательности хэша строки.
Фаза 2
-
Этап 2 начинается, когда FastLoad получает инструкцию END LOADING.
-
Каждый AMP сортирует записи по хешу строк и записывает их на диск.
-
Блокировки на целевой таблице сняты, а таблицы ошибок удалены.
Этап 2 начинается, когда FastLoad получает инструкцию END LOADING.
Каждый AMP сортирует записи по хешу строк и записывает их на диск.
Блокировки на целевой таблице сняты, а таблицы ошибок удалены.
пример
Создайте текстовый файл со следующими записями и назовите его как employee.txt.
101,Mike,James,1980-01-05,2010-03-01,1 102,Robert,Williams,1983-03-05,2010-09-01,1 103,Peter,Paul,1983-04-01,2009-02-12,2 104,Alex,Stuart,1984-11-06,2014-01-01,2 105,Robert,James,1984-12-01,2015-03-09,3
Ниже приведен пример сценария FastLoad для загрузки вышеуказанного файла в таблицу Employee_Stg.
LOGON 192.168.1.102/dbc,dbc; DATABASE tduser; BEGIN LOADING tduser.Employee_Stg ERRORFILES Employee_ET, Employee_UV CHECKPOINT 10; SET RECORD VARTEXT ","; DEFINE in_EmployeeNo (VARCHAR(10)), in_FirstName (VARCHAR(30)), in_LastName (VARCHAR(30)), in_BirthDate (VARCHAR(10)), in_JoinedDate (VARCHAR(10)), in_DepartmentNo (VARCHAR(02)), FILE = employee.txt; INSERT INTO Employee_Stg ( EmployeeNo, FirstName, LastName, BirthDate, JoinedDate, DepartmentNo ) VALUES ( :in_EmployeeNo, :in_FirstName, :in_LastName, :in_BirthDate (FORMAT 'YYYY-MM-DD'), :in_JoinedDate (FORMAT 'YYYY-MM-DD'), :in_DepartmentNo ); END LOADING; LOGOFF;
Выполнение скрипта FastLoad
После того как входной файл employee.txt создан и скрипт FastLoad назван EmployeeLoad.fl, вы можете запустить скрипт FastLoad с помощью следующей команды в UNIX и Windows.
FastLoad < EmployeeLoad.fl;
Как только вышеуказанная команда будет выполнена, скрипт FastLoad запустится и выдаст журнал. В журнале вы можете увидеть количество записей, обработанных FastLoad, и код состояния.
**** 03:19:14 END LOADING COMPLETE
Total Records Read = 5
Total Error Table 1 = 0 ---- Table has been dropped
Total Error Table 2 = 0 ---- Table has been dropped
Total Inserts Applied = 5
Total Duplicate Rows = 0
Start: Fri Jan 8 03:19:13 2016
End : Fri Jan 8 03:19:14 2016
**** 03:19:14 Application Phase statistics:
Elapsed time: 00:00:01 (in hh:mm:ss)
0008 LOGOFF;
**** 03:19:15 Logging off all sessions
Условия FastLoad
Ниже приведен список общих терминов, используемых в скрипте FastLoad.
-
LOGON — вход в Teradata и инициирование одного или нескольких сеансов.
-
БАЗА ДАННЫХ — Устанавливает базу данных по умолчанию.
-
НАЧАЛО ЗАГРУЗКИ — Определяет таблицу для загрузки.
-
ERRORFILES — определяет 2 таблицы ошибок, которые необходимо создать / обновить.
-
CHECKPOINT — Определяет, когда взять контрольную точку.
-
SET RECORD — указывает, является ли формат входного файла отформатированным, двоичным, текстовым или неформатированным.
-
DEFINE — Определяет структуру входного файла.
-
ФАЙЛ — Определяет имя входного файла и путь.
-
INSERT — вставляет записи из входного файла в целевую таблицу.
-
КОНЕЦ ЗАГРУЗКИ — Инициирует фазу 2 FastLoad. Распределяет записи в целевой таблице.
-
LOGOFF — Завершает все сеансы и завершает FastLoad.
LOGON — вход в Teradata и инициирование одного или нескольких сеансов.
БАЗА ДАННЫХ — Устанавливает базу данных по умолчанию.
НАЧАЛО ЗАГРУЗКИ — Определяет таблицу для загрузки.
ERRORFILES — определяет 2 таблицы ошибок, которые необходимо создать / обновить.
CHECKPOINT — Определяет, когда взять контрольную точку.
SET RECORD — указывает, является ли формат входного файла отформатированным, двоичным, текстовым или неформатированным.
DEFINE — Определяет структуру входного файла.
ФАЙЛ — Определяет имя входного файла и путь.
INSERT — вставляет записи из входного файла в целевую таблицу.
КОНЕЦ ЗАГРУЗКИ — Инициирует фазу 2 FastLoad. Распределяет записи в целевой таблице.
LOGOFF — Завершает все сеансы и завершает FastLoad.
Teradata — MultiLoad
MultiLoad может загружать несколько таблиц одновременно, а также может выполнять различные типы задач, таких как INSERT, DELETE, UPDATE и UPSERT. Он может загружать до 5 таблиц одновременно и выполнять до 20 операций DML в скрипте. Таблица назначения не требуется для MultiLoad.
MultiLoad поддерживает два режима —
- ИМПОРТИРОВАТЬ
- УДАЛЯТЬ
MultiLoad требует рабочую таблицу, таблицу журнала и две таблицы ошибок в дополнение к целевой таблице.
-
Таблица журнала — используется для сохранения контрольных точек, снятых во время загрузки, которые будут использоваться для перезапуска.
-
Таблицы ошибок — эти таблицы вставляются во время загрузки при возникновении ошибки. Первая таблица ошибок хранит ошибки преобразования, тогда как вторая таблица ошибок хранит дубликаты записей.
-
Таблица журналов — содержит результаты каждого этапа MultiLoad для перезапуска.
-
Рабочая таблица — скрипт MultiLoad создает одну рабочую таблицу для каждой целевой таблицы. Рабочая таблица используется для хранения задач DML и входных данных.
Таблица журнала — используется для сохранения контрольных точек, снятых во время загрузки, которые будут использоваться для перезапуска.
Таблицы ошибок — эти таблицы вставляются во время загрузки при возникновении ошибки. Первая таблица ошибок хранит ошибки преобразования, тогда как вторая таблица ошибок хранит дубликаты записей.
Таблица журналов — содержит результаты каждого этапа MultiLoad для перезапуска.
Рабочая таблица — скрипт MultiLoad создает одну рабочую таблицу для каждой целевой таблицы. Рабочая таблица используется для хранения задач DML и входных данных.
ограничение
MultiLoad имеет некоторые ограничения.
- Уникальный вторичный индекс не поддерживается на целевой таблице.
- Ссылочная целостность не поддерживается.
- Триггеры не поддерживаются.
Как работает MultiLoad
Импорт MultiLoad имеет пять этапов —
-
Этап 1 — Предварительный этап — выполняет основные действия по настройке.
-
Этап 2 — этап транзакции DML — проверяет синтаксис операторов DML и переносит их в систему Teradata.
-
Этап 3 — Этап сбора данных — переносит входные данные в рабочие таблицы и блокирует таблицу.
-
Этап 4 — Этап применения — Применяет все операции DML.
-
Фаза 5 — Фаза очистки — Снимает блокировку стола.
Этап 1 — Предварительный этап — выполняет основные действия по настройке.
Этап 2 — этап транзакции DML — проверяет синтаксис операторов DML и переносит их в систему Teradata.
Этап 3 — Этап сбора данных — переносит входные данные в рабочие таблицы и блокирует таблицу.
Этап 4 — Этап применения — Применяет все операции DML.
Фаза 5 — Фаза очистки — Снимает блокировку стола.
Шаги, включенные в скрипт MultiLoad:
-
Шаг 1 — Настройте таблицу журнала.
-
Шаг 2 — Войдите в Teradata.
-
Шаг 3 — Укажите таблицы Target, Work и Error.
-
Шаг 4 — Определите формат файла INPUT.
-
Шаг 5 — Определите запросы DML.
-
Шаг 6 — Назовите файл ИМПОРТ.
-
Шаг 7 — Укажите LAYOUT для использования.
-
Шаг 8 — Инициируйте загрузку.
-
Шаг 9 — Завершите загрузку и завершите сеансы.
Шаг 1 — Настройте таблицу журнала.
Шаг 2 — Войдите в Teradata.
Шаг 3 — Укажите таблицы Target, Work и Error.
Шаг 4 — Определите формат файла INPUT.
Шаг 5 — Определите запросы DML.
Шаг 6 — Назовите файл ИМПОРТ.
Шаг 7 — Укажите LAYOUT для использования.
Шаг 8 — Инициируйте загрузку.
Шаг 9 — Завершите загрузку и завершите сеансы.
пример
Создайте текстовый файл со следующими записями и назовите его как employee.txt.
101,Mike,James,1980-01-05,2010-03-01,1 102,Robert,Williams,1983-03-05,2010-09-01,1 103,Peter,Paul,1983-04-01,2009-02-12,2 104,Alex,Stuart,1984-11-06,2014-01-01,2 105,Robert,James,1984-12-01,2015-03-09,3
В следующем примере представлен скрипт MultiLoad, который считывает записи из таблицы сотрудников и загружает их в таблицу Employee_Stg.
.LOGTABLE tduser.Employee_log; .LOGON 192.168.1.102/dbc,dbc; .BEGIN MLOAD TABLES Employee_Stg; .LAYOUT Employee; .FIELD in_EmployeeNo * VARCHAR(10); .FIELD in_FirstName * VARCHAR(30); .FIELD in_LastName * VARCHAR(30); .FIELD in_BirthDate * VARCHAR(10); .FIELD in_JoinedDate * VARCHAR(10); .FIELD in_DepartmentNo * VARCHAR(02); .DML LABEL EmpLabel; INSERT INTO Employee_Stg ( EmployeeNo, FirstName, LastName, BirthDate, JoinedDate, DepartmentNo ) VALUES ( :in_EmployeeNo, :in_FirstName, :in_Lastname, :in_BirthDate, :in_JoinedDate, :in_DepartmentNo ); .IMPORT INFILE employee.txt FORMAT VARTEXT ',' LAYOUT Employee APPLY EmpLabel; .END MLOAD; LOGOFF;
Выполнение MultiLoad-скрипта
После создания входного файла employee.txt и сценария мультизагрузки с именем EmployeeLoad.ml можно запустить сценарий мультизагрузки с помощью следующей команды в UNIX и Windows.
Multiload < EmployeeLoad.ml;
Teradata — FastExport
Утилита FastExport используется для экспорта данных из таблиц Teradata в плоские файлы. Он также может генерировать данные в формате отчета. Данные могут быть извлечены из одной или нескольких таблиц с помощью Join. Поскольку FastExport экспортирует данные в блоках по 64 КБ, это полезно для извлечения большого объема данных.
пример
Рассмотрим следующую таблицу сотрудников.
| Сотрудник № | Имя | Фамилия | Дата рождения |
|---|---|---|---|
| 101 | Майк | Джеймс | 1/5/1980 |
| 104 | Alex | Стюарт | 11/6/1984 |
| 102 | Роберт | Williams | 3/5/1983 |
| 105 | Роберт | Джеймс | 12/1/1984 |
| 103 | Питер | Павел | 4/1/1983 |
Ниже приведен пример скрипта FastExport. Он экспортирует данные из таблицы сотрудников и записывает их в файл employeeedata.txt.
.LOGTABLE tduser.employee_log; .LOGON 192.168.1.102/dbc,dbc; DATABASE tduser; .BEGIN EXPORT SESSIONS 2; .EXPORT OUTFILE employeedata.txt MODE RECORD FORMAT TEXT; SELECT CAST(EmployeeNo AS CHAR(10)), CAST(FirstName AS CHAR(15)), CAST(LastName AS CHAR(15)), CAST(BirthDate AS CHAR(10)) FROM Employee; .END EXPORT; .LOGOFF;
Выполнение скрипта FastExport
Когда сценарий написан и назван employee.fx, вы можете использовать следующую команду для выполнения сценария.
fexp < employee.fx
После выполнения вышеуказанной команды вы получите следующий вывод в файле busyedata.txt.
103 Peter Paul 1983-04-01 101 Mike James 1980-01-05 102 Robert Williams 1983-03-05 105 Robert James 1984-12-01 104 Alex Stuart 1984-11-06
Условия FastExport
Ниже приведен список терминов, обычно используемых в скрипте FastExport.
-
LOGTABLE — указывает таблицу журнала для цели перезапуска.
-
LOGON — вход в Teradata и инициирование одного или нескольких сеансов.
-
БАЗА ДАННЫХ — Устанавливает базу данных по умолчанию.
-
НАЧАЛО ЭКСПОРТА — указывает на начало экспорта.
-
EXPORT — указывает целевой файл и формат экспорта.
-
SELECT — указывает запрос на выборку для экспорта данных.
-
END EXPORT — указывает конец FastExport.
-
LOGOFF — Заканчивает все сеансы и завершает FastExport.
LOGTABLE — указывает таблицу журнала для цели перезапуска.
LOGON — вход в Teradata и инициирование одного или нескольких сеансов.
БАЗА ДАННЫХ — Устанавливает базу данных по умолчанию.
НАЧАЛО ЭКСПОРТА — указывает на начало экспорта.
EXPORT — указывает целевой файл и формат экспорта.
SELECT — указывает запрос на выборку для экспорта данных.
END EXPORT — указывает конец FastExport.
LOGOFF — Заканчивает все сеансы и завершает FastExport.
Teradata — BTEQ
Утилита BTEQ — мощная утилита в Teradata, которую можно использовать как в пакетном, так и в интерактивном режиме. Его можно использовать для запуска любого оператора DDL, оператора DML, создания макросов и хранимых процедур. BTEQ можно использовать для импорта данных в таблицы Teradata из плоского файла, а также для извлечения данных из таблиц в файлы или отчеты.
Условия BTEQ
Ниже приведен список терминов, обычно используемых в скриптах BTEQ.
-
LOGON — используется для входа в систему Teradata.
-
ACTIVITYCOUNT — возвращает количество строк, затронутых предыдущим запросом.
-
ERRORCODE — возвращает код состояния предыдущего запроса.
-
БАЗА ДАННЫХ — Устанавливает базу данных по умолчанию.
-
LABEL — назначает метку для набора команд SQL.
-
RUN FILE — выполняет запрос, содержащийся в файле.
-
GOTO — передает управление метке.
-
LOGOFF — выходит из базы данных и завершает все сеансы.
-
ИМПОРТ — Указывает путь к входному файлу.
-
EXPORT — указывает путь к выходному файлу и инициирует экспорт.
LOGON — используется для входа в систему Teradata.
ACTIVITYCOUNT — возвращает количество строк, затронутых предыдущим запросом.
ERRORCODE — возвращает код состояния предыдущего запроса.
БАЗА ДАННЫХ — Устанавливает базу данных по умолчанию.
LABEL — назначает метку для набора команд SQL.
RUN FILE — выполняет запрос, содержащийся в файле.
GOTO — передает управление метке.
LOGOFF — выходит из базы данных и завершает все сеансы.
ИМПОРТ — Указывает путь к входному файлу.
EXPORT — указывает путь к выходному файлу и инициирует экспорт.
пример
Ниже приведен пример скрипта BTEQ.
.LOGON 192.168.1.102/dbc,dbc; DATABASE tduser; CREATE TABLE employee_bkup ( EmployeeNo INTEGER, FirstName CHAR(30), LastName CHAR(30), DepartmentNo SMALLINT, NetPay INTEGER ) Unique Primary Index(EmployeeNo); .IF ERRORCODE <> 0 THEN .EXIT ERRORCODE; SELECT * FROM Employee Sample 1; .IF ACTIVITYCOUNT <> 0 THEN .GOTO InsertEmployee; DROP TABLE employee_bkup; .IF ERRORCODE <> 0 THEN .EXIT ERRORCODE; .LABEL InsertEmployee INSERT INTO employee_bkup SELECT a.EmployeeNo, a.FirstName, a.LastName, a.DepartmentNo, b.NetPay FROM Employee a INNER JOIN Salary b ON (a.EmployeeNo = b.EmployeeNo); .IF ERRORCODE <> 0 THEN .EXIT ERRORCODE; .LOGOFF;
Приведенный выше скрипт выполняет следующие задачи.
Вход в систему Teradata.
Устанавливает базу данных по умолчанию.
Создает таблицу с именем employee_bkup.
Выбирает одну запись из таблицы Employee, чтобы проверить, есть ли в таблице какие-либо записи.
Удаляет таблицу employee_bkup, если таблица пуста.
Переносит элемент управления в Label InsertEmployee, который вставляет записи в таблицу employee_bkup.
Проверяет ERRORCODE, чтобы убедиться, что оператор выполнен успешно, после каждого оператора SQL.
ACTIVITYCOUNT возвращает количество записей, выбранных / затронутых предыдущим SQL-запросом.