Строка назначается конкретному AMP на основе значения первичного индекса. Teradata использует алгоритм хеширования, чтобы определить, какой AMP получает строку.
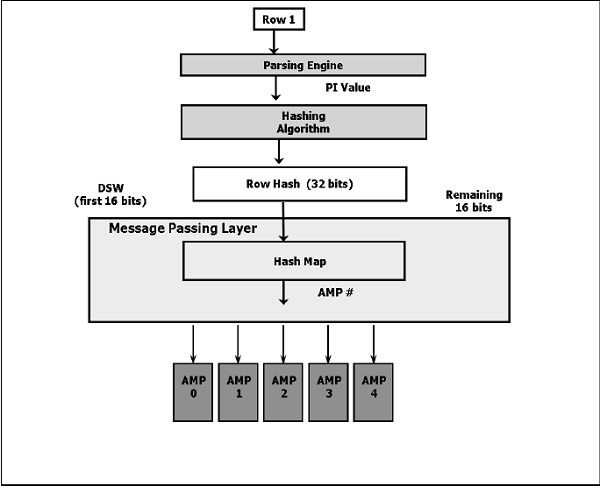
Ниже приведена диаграмма высокого уровня алгоритма хеширования.
Ниже приведены шаги для вставки данных.
-
Клиент отправляет запрос.
-
Парсер получает запрос и передает значение PI записи в алгоритм хэширования.
-
Алгоритм хеширования хеширует значение основного индекса и возвращает 32-битное число, называемое хэш-строкой.
-
Биты высшего порядка хэша строки (первые 16 бит) используются для идентификации записи карты хеша. Хеш-карта содержит один AMP #. Хэш-карта — это массив блоков, который содержит конкретный номер AMP.
-
BYNET отправляет данные в указанный AMP.
-
AMP использует 32-битный хэш строки, чтобы найти строку на своем диске.
-
Если есть какая-либо запись с таким же хешем строки, то она увеличивает идентификатор уникальности, который является 32-битным числом. Для нового хэша строки идентификатор уникальности присваивается как 1 и увеличивается всякий раз, когда вставляется запись с таким же хэшем строки.
-
Сочетание хэша строки и идентификатора уникальности называется идентификатором строки.
-
Идентификатор строки префикс каждой записи на диске.
-
Каждая строка таблицы в AMP логически сортируется по их идентификаторам строк.
Клиент отправляет запрос.
Парсер получает запрос и передает значение PI записи в алгоритм хэширования.
Алгоритм хеширования хеширует значение основного индекса и возвращает 32-битное число, называемое хэш-строкой.
Биты высшего порядка хэша строки (первые 16 бит) используются для идентификации записи карты хеша. Хеш-карта содержит один AMP #. Хэш-карта — это массив блоков, который содержит конкретный номер AMP.
BYNET отправляет данные в указанный AMP.
AMP использует 32-битный хэш строки, чтобы найти строку на своем диске.
Если есть какая-либо запись с таким же хешем строки, то она увеличивает идентификатор уникальности, который является 32-битным числом. Для нового хэша строки идентификатор уникальности присваивается как 1 и увеличивается всякий раз, когда вставляется запись с таким же хэшем строки.
Сочетание хэша строки и идентификатора уникальности называется идентификатором строки.
Идентификатор строки префикс каждой записи на диске.
Каждая строка таблицы в AMP логически сортируется по их идентификаторам строк.
Как хранятся таблицы
Таблицы сортируются по их идентификатору строки (хэш строки + идентификатор уникальности) и затем сохраняются в AMP. Идентификатор строки сохраняется с каждой строкой данных.