Spark представляет программный модуль для обработки структурированных данных, который называется Spark SQL. Он предоставляет программную абстракцию под названием DataFrame и может выступать в качестве механизма распределенного SQL-запроса.
Особенности Spark SQL
Ниже приведены особенности Spark SQL —
-
Интегрирован — легко смешивать SQL-запросы с программами Spark Spark SQL позволяет запрашивать структурированные данные в виде распределенного набора данных (RDD) в Spark со встроенными API-интерфейсами в Python, Scala и Java. Такая тесная интеграция позволяет легко выполнять запросы SQL вместе со сложными аналитическими алгоритмами.
-
Унифицированный доступ к данным — загрузка и запрос данных из различных источников. СХД-схемы обеспечивают единый интерфейс для эффективной работы со структурированными данными, включая таблицы Apache Hive, файлы паркета и файлы JSON.
-
Совместимость Hive — запускать неизмененные запросы Hive на существующих складах. Spark SQL повторно использует внешний интерфейс Hive и MetaStore, обеспечивая полную совместимость с существующими данными Hive, запросами и пользовательскими функциями. Просто установите его вместе с Hive.
-
Стандартное подключение — подключение через JDBC или ODBC. Spark SQL включает серверный режим с возможностью подключения JDBC и ODBC промышленного стандарта.
-
Масштабируемость — используйте один и тот же механизм для интерактивных и длинных запросов. Spark SQL использует модель RDD для поддержки отказоустойчивости в середине запроса, позволяя также масштабироваться и для больших заданий. Не беспокойтесь об использовании другого движка для исторических данных.
Интегрирован — легко смешивать SQL-запросы с программами Spark Spark SQL позволяет запрашивать структурированные данные в виде распределенного набора данных (RDD) в Spark со встроенными API-интерфейсами в Python, Scala и Java. Такая тесная интеграция позволяет легко выполнять запросы SQL вместе со сложными аналитическими алгоритмами.
Унифицированный доступ к данным — загрузка и запрос данных из различных источников. СХД-схемы обеспечивают единый интерфейс для эффективной работы со структурированными данными, включая таблицы Apache Hive, файлы паркета и файлы JSON.
Совместимость Hive — запускать неизмененные запросы Hive на существующих складах. Spark SQL повторно использует внешний интерфейс Hive и MetaStore, обеспечивая полную совместимость с существующими данными Hive, запросами и пользовательскими функциями. Просто установите его вместе с Hive.
Стандартное подключение — подключение через JDBC или ODBC. Spark SQL включает серверный режим с возможностью подключения JDBC и ODBC промышленного стандарта.
Масштабируемость — используйте один и тот же механизм для интерактивных и длинных запросов. Spark SQL использует модель RDD для поддержки отказоустойчивости в середине запроса, позволяя также масштабироваться и для больших заданий. Не беспокойтесь об использовании другого движка для исторических данных.
Архитектура Spark SQL
Следующая иллюстрация объясняет архитектуру Spark SQL —
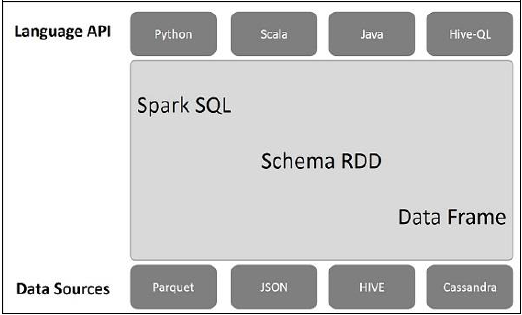
Эта архитектура содержит три уровня, а именно: Language API, Schema RDD и Data Sources.
-
Язык API — Spark совместим с разными языками и Spark SQL. Также поддерживается этими языками API (python, scala, java, HiveQL).
-
Схема RDD — Spark Core разработана со специальной структурой данных, называемой RDD. Как правило, Spark SQL работает со схемами, таблицами и записями. Поэтому мы можем использовать схему RDD в качестве временной таблицы. Мы можем назвать эту схему RDD как фрейм данных.
-
Источники данных. Обычно источником данных для spark-core является текстовый файл, файл Avro и т. Д. Однако источники данных для Spark SQL отличаются. Это файл Parquet, документ JSON, таблицы HIVE и база данных Cassandra.
Язык API — Spark совместим с разными языками и Spark SQL. Также поддерживается этими языками API (python, scala, java, HiveQL).
Схема RDD — Spark Core разработана со специальной структурой данных, называемой RDD. Как правило, Spark SQL работает со схемами, таблицами и записями. Поэтому мы можем использовать схему RDD в качестве временной таблицы. Мы можем назвать эту схему RDD как фрейм данных.
Источники данных. Обычно источником данных для spark-core является текстовый файл, файл Avro и т. Д. Однако источники данных для Spark SQL отличаются. Это файл Parquet, документ JSON, таблицы HIVE и база данных Cassandra.
Мы обсудим больше об этом в следующих главах.