Spark — Введение
Отрасли широко используют Hadoop для анализа своих наборов данных. Причина заключается в том, что платформа Hadoop основана на простой модели программирования (MapReduce) и обеспечивает масштабируемое, гибкое, отказоустойчивое и экономически эффективное вычислительное решение. Здесь основной задачей является поддержание скорости обработки больших наборов данных с точки зрения времени ожидания между запросами и времени ожидания для запуска программы.
Spark был представлен Apache Software Foundation для ускорения процесса вычислительных вычислений Hadoop.
В отличие от распространенного мнения, Spark не является модифицированной версией Hadoop и на самом деле не зависит от Hadoop, поскольку имеет собственное управление кластером. Hadoop — это только один из способов реализации Spark.
Spark использует Hadoop двумя способами: один — хранилище, а второй — обработка . Поскольку Spark имеет свои собственные вычисления управления кластером, он использует Hadoop только для целей хранения.
Apache Spark
Apache Spark — это молниеносная технология кластерных вычислений, предназначенная для быстрых вычислений. Он основан на Hadoop MapReduce и расширяет модель MapReduce, чтобы эффективно использовать ее для других типов вычислений, включая интерактивные запросы и потоковую обработку. Главной особенностью Spark являются кластерные вычисления в памяти, которые увеличивают скорость обработки приложения.
Spark предназначен для широкого спектра рабочих нагрузок, таких как пакетные приложения, итерационные алгоритмы, интерактивные запросы и потоковая передача. Помимо поддержки всех этих рабочих нагрузок в соответствующей системе, это снижает нагрузку на управление обслуживанием отдельных инструментов.
Эволюция Apache Spark
Spark — это один из подпроектов Hadoop, разработанный в 2009 году в AMPLab Калифорнийского университета в Беркли Матей Захария. Он был открыт в 2010 году по лицензии BSD. Он был пожертвован программному фонду Apache в 2013 году, и теперь Apache Spark стал проектом Apache высшего уровня с февраля 2014 года.
Особенности Apache Spark
Apache Spark имеет следующие особенности.
-
Скорость — Spark помогает запускать приложения в кластере Hadoop, до 100 раз быстрее в памяти и в 10 раз быстрее при работе на диске. Это возможно за счет уменьшения количества операций чтения / записи на диск. Он хранит промежуточные данные обработки в памяти.
-
Поддерживает несколько языков — Spark предоставляет встроенные API в Java, Scala или Python. Поэтому вы можете писать приложения на разных языках. Spark предлагает 80 высокоуровневых операторов для интерактивных запросов.
-
Расширенная аналитика — Spark поддерживает не только «Map» и «Reduce». Он также поддерживает запросы SQL, потоковые данные, машинное обучение (ML) и алгоритмы Graph.
Скорость — Spark помогает запускать приложения в кластере Hadoop, до 100 раз быстрее в памяти и в 10 раз быстрее при работе на диске. Это возможно за счет уменьшения количества операций чтения / записи на диск. Он хранит промежуточные данные обработки в памяти.
Поддерживает несколько языков — Spark предоставляет встроенные API в Java, Scala или Python. Поэтому вы можете писать приложения на разных языках. Spark предлагает 80 высокоуровневых операторов для интерактивных запросов.
Расширенная аналитика — Spark поддерживает не только «Map» и «Reduce». Он также поддерживает запросы SQL, потоковые данные, машинное обучение (ML) и алгоритмы Graph.
Искра, построенная на Hadoop
На следующей диаграмме показаны три способа построения Spark с использованием компонентов Hadoop.
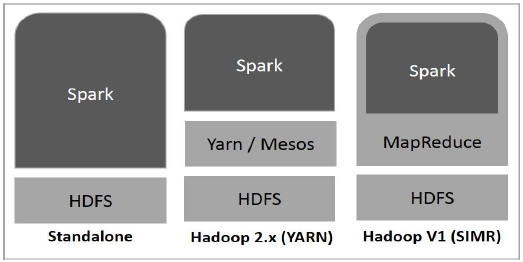
Существует три способа развертывания Spark, как описано ниже.
-
Автономное — Spark. Автономное развертывание означает, что Spark занимает место над HDFS (распределенной файловой системой Hadoop), а пространство явно выделяется для HDFS. Здесь Spark и MapReduce будут работать бок о бок, чтобы охватить все искровые задания в кластере.
-
Hadoop Yarn — Развертывание Hadoop Yarn означает, что искра работает на Yarn без предварительной установки или доступа с правами root. Это помогает интегрировать Spark в экосистему Hadoop или стек Hadoop. Это позволяет другим компонентам работать поверх стека.
-
Spark в MapReduce (SIMR) — Spark в MapReduce используется для запуска искрового задания в дополнение к автономному развертыванию. С SIMR пользователь может запустить Spark и использовать его оболочку без какого-либо административного доступа.
Автономное — Spark. Автономное развертывание означает, что Spark занимает место над HDFS (распределенной файловой системой Hadoop), а пространство явно выделяется для HDFS. Здесь Spark и MapReduce будут работать бок о бок, чтобы охватить все искровые задания в кластере.
Hadoop Yarn — Развертывание Hadoop Yarn означает, что искра работает на Yarn без предварительной установки или доступа с правами root. Это помогает интегрировать Spark в экосистему Hadoop или стек Hadoop. Это позволяет другим компонентам работать поверх стека.
Spark в MapReduce (SIMR) — Spark в MapReduce используется для запуска искрового задания в дополнение к автономному развертыванию. С SIMR пользователь может запустить Spark и использовать его оболочку без какого-либо административного доступа.
Компоненты искры
На следующем рисунке изображены различные компоненты Spark.
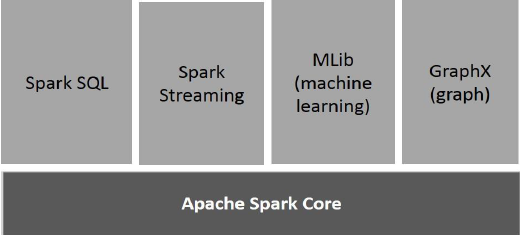
Apache Spark Core
Spark Core — основной движок общего исполнения для платформы spark, на котором построены все остальные функции. Он обеспечивает вычисления в памяти и ссылки на наборы данных во внешних системах хранения.
Spark SQL
Spark SQL — это компонент поверх Spark Core, который представляет новую абстракцию данных, называемую SchemaRDD, которая обеспечивает поддержку структурированных и полуструктурированных данных.
Spark Streaming
Spark Streaming использует возможность быстрого планирования Spark Core для выполнения потоковой аналитики. Он принимает данные в мини-пакетах и выполняет преобразования RDD (Resilient Distributed Datasets) для этих мини-пакетов данных.
MLlib (Библиотека машинного обучения)
MLlib является распределенной структурой машинного обучения выше Spark из-за распределенной архитектуры Spark на основе памяти. Согласно тестам, это делается разработчиками MLlib против реализаций Alternating Least Squares (ALS). Spark MLlib в девять раз быстрее, чем дисковая версия Apache Mahout для Hadoop (до того, как Mahout получил интерфейс Spark).
Graphx
GraphX - это распределенная среда обработки графов поверх Spark. Он предоставляет API для выражения вычислений графов, который может моделировать пользовательские графы с помощью API абстракции Pregel. Это также обеспечивает оптимизированное время выполнения для этой абстракции.
Искра — RDD
Эластичные распределенные наборы данных
Эластичные распределенные наборы данных (RDD) — это фундаментальная структура данных Spark. Это неизменяемая распределенная коллекция объектов. Каждый набор данных в RDD разделен на логические разделы, которые могут быть вычислены на разных узлах кластера. СДР могут содержать объекты Python, Java или Scala любого типа, включая определяемые пользователем классы.
Формально СДР — это секционированная коллекция записей только для чтения. СДР могут быть созданы с помощью детерминированных операций с данными в стабильном хранилище или с другими СДР. СДР — это отказоустойчивая совокупность элементов, которые могут работать параллельно.
Существует два способа создания RDD — распараллеливание существующей коллекции в вашей программе драйвера или обращение к набору данных во внешней системе хранения, такой как общая файловая система, HDFS, HBase или любой источник данных, предлагающий формат ввода Hadoop.
Spark использует концепцию RDD для достижения более быстрых и эффективных операций MapReduce. Давайте сначала обсудим, как происходят операции MapReduce и почему они не столь эффективны.
Обмен данными медленен в MapReduce
MapReduce широко используется для обработки и генерации больших наборов данных с параллельным распределенным алгоритмом в кластере. Это позволяет пользователям писать параллельные вычисления, используя набор операторов высокого уровня, не беспокоясь о распределении работы и отказоустойчивости.
К сожалению, в большинстве современных платформ единственный способ повторно использовать данные между вычислениями (например, между двумя заданиями MapReduce) — это записать их во внешнюю стабильную систему хранения (например, HDFS). Хотя эта структура предоставляет множество абстракций для доступа к вычислительным ресурсам кластера, пользователям все еще нужно больше.
Итеративные и интерактивные приложения требуют более быстрого обмена данными между параллельными заданиями. Обмен данными в MapReduce происходит медленно из-за репликации , сериализации и дискового ввода-вывода . Что касается системы хранения, большинства приложений Hadoop, они проводят более 90% времени, выполняя операции чтения-записи HDFS.
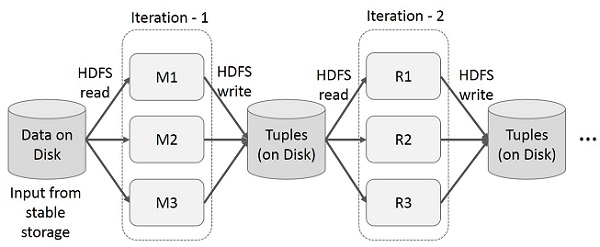
Итерационные операции на MapReduce
Повторное использование промежуточных результатов в нескольких вычислениях в многоэтапных приложениях. На следующем рисунке показано, как работает текущий каркас, выполняя итерационные операции над MapReduce. Это приводит к значительным накладным расходам из-за репликации данных, дискового ввода-вывода и сериализации, что замедляет работу системы.
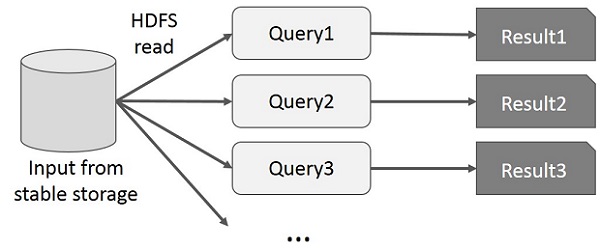
Интерактивные операции на MapReduce
Пользователь запускает специальные запросы к одному и тому же подмножеству данных. Каждый запрос будет выполнять дисковый ввод-вывод в стабильном хранилище, что может влиять на время выполнения приложения.
На следующем рисунке показано, как работает текущая структура при выполнении интерактивных запросов в MapReduce.
Обмен данными с использованием Spark RDD
Обмен данными в MapReduce происходит медленно из-за репликации , сериализации и дискового ввода-вывода . Большинство приложений Hadoop тратят более 90% времени на операции чтения-записи HDFS.
Признавая эту проблему, исследователи разработали специализированную среду под названием Apache Spark. Ключевой идеей искры является R esilient D istributed D atasets (RDD); он поддерживает вычисления в памяти. Это означает, что он хранит состояние памяти как объект между заданиями, и объект разделяется между этими заданиями. Обмен данными в памяти в 10-100 раз быстрее, чем в сети и на диске.
Давайте теперь попробуем выяснить, как итеративные и интерактивные операции выполняются в Spark RDD.
Итерационные операции на Spark RDD
На приведенной ниже иллюстрации показаны итерационные операции на Spark RDD. Он будет хранить промежуточные результаты в распределенной памяти вместо стабильного хранилища (диска) и сделает систему быстрее.
Примечание. Если Распределенная память (ОЗУ) достаточна для хранения промежуточных результатов (State of JOB), то эти результаты будут сохранены на диске.
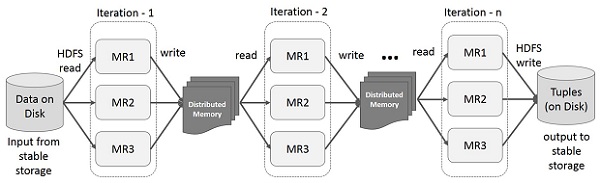
Интерактивные операции на Spark RDD
На этом рисунке показаны интерактивные операции на Spark RDD. Если разные запросы выполняются для одного и того же набора данных несколько раз, эти конкретные данные могут быть сохранены в памяти для лучшего времени выполнения.
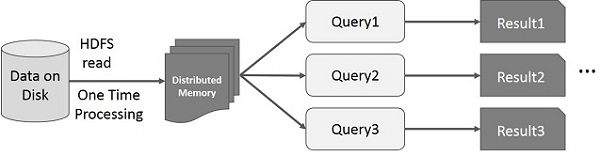
По умолчанию каждый преобразованный СДР может пересчитываться каждый раз, когда вы выполняете над ним действие. Однако вы также можете сохранить RDD в памяти, и в этом случае Spark сохранит элементы в кластере для более быстрого доступа при следующем запросе. Существует также поддержка сохранения RDD на диске или репликации на нескольких узлах.
Spark — Установка
Spark — это подпроект Hadoop. Поэтому лучше установить Spark в систему на основе Linux. Следующие шаги показывают, как установить Apache Spark.
Шаг 1: Проверка установки Java
Установка Java является одной из обязательных вещей при установке Spark. Попробуйте следующую команду, чтобы проверить версию JAVA.
$java -version
Если Java уже установлена в вашей системе, вы увидите следующий ответ:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если в вашей системе не установлена Java, то установите Java, прежде чем переходить к следующему шагу.
Шаг 2: Проверка установки Scala
Вам следует использовать язык Scala для реализации Spark. Итак, давайте проверим установку Scala с помощью следующей команды.
$scala -version
Если Scala уже установлен в вашей системе, вы увидите следующий ответ:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
Если в вашей системе не установлен Scala, перейдите к следующему шагу для установки Scala.
Шаг 3: Загрузка Scala
Загрузите последнюю версию Scala, перейдя по следующей ссылке Скачать Scala . Для этого урока мы используем версию scala-2.11.6. После загрузки вы найдете tar-файл Scala в папке загрузки.
Шаг 4: Установка Scala
Следуйте приведенным ниже инструкциям для установки Scala.
Извлеките файл архива Scala
Введите следующую команду для распаковки tar-файла Scala.
$ tar xvf scala-2.11.6.tgz
Переместить файлы программного обеспечения Scala
Используйте следующие команды для перемещения файлов программного обеспечения Scala в соответствующий каталог (/ usr / local / scala) .
$ su – Password: # cd /home/Hadoop/Downloads/ # mv scala-2.11.6 /usr/local/scala # exit
Установить PATH для Scala
Используйте следующую команду для настройки PATH для Scala.
$ export PATH = $PATH:/usr/local/scala/bin
Проверка установки Scala
После установки лучше это проверить. Используйте следующую команду для проверки установки Scala.
$scala -version
Если Scala уже установлен в вашей системе, вы увидите следующий ответ:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
Шаг 5: Загрузка Apache Spark
Загрузите последнюю версию Spark, перейдя по следующей ссылке Скачать Spark . Для этого урока мы используем версию spark-1.3.1-bin-hadoop2.6 . После загрузки вы найдете файл Spark tar в папке загрузки.
Шаг 6: Установка Spark
Следуйте приведенным ниже инструкциям для установки Spark.
Извлечение Spark смолы
Следующая команда для извлечения файла spark tar.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgz
Перемещение файлов программного обеспечения Spark
Следующие команды для перемещения файлов программного обеспечения Spark в соответствующий каталог (/ usr / local / spark) .
$ su – Password: # cd /home/Hadoop/Downloads/ # mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark # exit
Настройка среды для Spark
Добавьте следующую строку в файл ~ /.bashrc . Это означает добавление места, где находится файл программного обеспечения искры, в переменную PATH.
export PATH = $PATH:/usr/local/spark/bin
Используйте следующую команду для поиска файла ~ / .bashrc.
$ source ~/.bashrc
Шаг 7: Проверка установки Spark
Напишите следующую команду для открытия оболочки Spark.
$spark-shell
Если искра установлена успешно, вы найдете следующий вывод.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
Spark SQL — Введение
Spark представляет программный модуль для обработки структурированных данных, который называется Spark SQL. Он предоставляет программную абстракцию под названием DataFrame и может выступать в качестве механизма распределенного SQL-запроса.
Особенности Spark SQL
Ниже приведены особенности Spark SQL —
-
Интегрирован — легко смешивать SQL-запросы с программами Spark Spark SQL позволяет запрашивать структурированные данные в виде распределенного набора данных (RDD) в Spark со встроенными API-интерфейсами в Python, Scala и Java. Такая тесная интеграция позволяет легко выполнять запросы SQL вместе со сложными аналитическими алгоритмами.
-
Унифицированный доступ к данным — загрузка и запрос данных из различных источников. СХД-схемы обеспечивают единый интерфейс для эффективной работы со структурированными данными, включая таблицы Apache Hive, файлы паркета и файлы JSON.
-
Совместимость Hive — запускать неизмененные запросы Hive на существующих складах. Spark SQL повторно использует внешний интерфейс Hive и MetaStore, обеспечивая полную совместимость с существующими данными Hive, запросами и пользовательскими функциями. Просто установите его вместе с Hive.
-
Стандартное подключение — подключение через JDBC или ODBC. Spark SQL включает серверный режим с возможностью подключения JDBC и ODBC промышленного стандарта.
-
Масштабируемость — используйте один и тот же механизм для интерактивных и длинных запросов. Spark SQL использует модель RDD для поддержки отказоустойчивости в середине запроса, позволяя также масштабироваться и для больших заданий. Не беспокойтесь об использовании другого движка для исторических данных.
Интегрирован — легко смешивать SQL-запросы с программами Spark Spark SQL позволяет запрашивать структурированные данные в виде распределенного набора данных (RDD) в Spark со встроенными API-интерфейсами в Python, Scala и Java. Такая тесная интеграция позволяет легко выполнять запросы SQL вместе со сложными аналитическими алгоритмами.
Унифицированный доступ к данным — загрузка и запрос данных из различных источников. СХД-схемы обеспечивают единый интерфейс для эффективной работы со структурированными данными, включая таблицы Apache Hive, файлы паркета и файлы JSON.
Совместимость Hive — запускать неизмененные запросы Hive на существующих складах. Spark SQL повторно использует внешний интерфейс Hive и MetaStore, обеспечивая полную совместимость с существующими данными Hive, запросами и пользовательскими функциями. Просто установите его вместе с Hive.
Стандартное подключение — подключение через JDBC или ODBC. Spark SQL включает серверный режим с возможностью подключения JDBC и ODBC промышленного стандарта.
Масштабируемость — используйте один и тот же механизм для интерактивных и длинных запросов. Spark SQL использует модель RDD для поддержки отказоустойчивости в середине запроса, позволяя также масштабироваться и для больших заданий. Не беспокойтесь об использовании другого движка для исторических данных.
Архитектура Spark SQL
Следующая иллюстрация объясняет архитектуру Spark SQL —
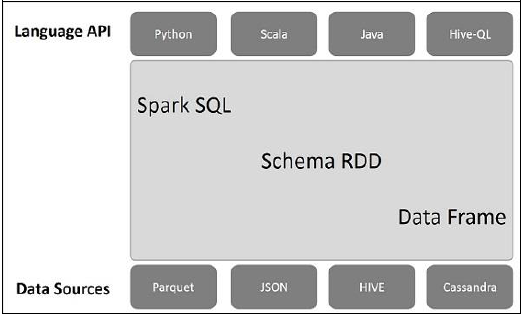
Эта архитектура содержит три уровня, а именно: Language API, Schema RDD и Data Sources.
-
Язык API — Spark совместим с разными языками и Spark SQL. Также поддерживается этими языками API (python, scala, java, HiveQL).
-
Схема RDD — Spark Core разработана со специальной структурой данных, называемой RDD. Как правило, Spark SQL работает со схемами, таблицами и записями. Поэтому мы можем использовать схему RDD в качестве временной таблицы. Мы можем назвать эту схему RDD как фрейм данных.
-
Источники данных. Обычно источником данных для spark-core является текстовый файл, файл Avro и т. Д. Однако источники данных для Spark SQL отличаются. Это файл Parquet, документ JSON, таблицы HIVE и база данных Cassandra.
Язык API — Spark совместим с разными языками и Spark SQL. Также поддерживается этими языками API (python, scala, java, HiveQL).
Схема RDD — Spark Core разработана со специальной структурой данных, называемой RDD. Как правило, Spark SQL работает со схемами, таблицами и записями. Поэтому мы можем использовать схему RDD в качестве временной таблицы. Мы можем назвать эту схему RDD как фрейм данных.
Источники данных. Обычно источником данных для spark-core является текстовый файл, файл Avro и т. Д. Однако источники данных для Spark SQL отличаются. Это файл Parquet, документ JSON, таблицы HIVE и база данных Cassandra.
Мы обсудим больше об этом в следующих главах.
Spark SQL — DataFrames
DataFrame — это распределенная коллекция данных, которая организована в именованные столбцы. Концептуально это эквивалентно реляционным таблицам с хорошими методами оптимизации.
DataFrame может быть создан из массива различных источников, таких как таблицы Hive, файлы структурированных данных, внешние базы данных или существующие RDD. Этот API был разработан для современных приложений Big Data и Data Science, основанных на DataFrame в R Programming и Pandas в Python .
Особенности DataFrame
Вот несколько характерных особенностей DataFrame:
-
Возможность обработки данных размером от килобайта до петабайта от одного узла к большому кластеру.
-
Поддерживает различные форматы данных (Avro, CSV, эластичный поиск и Cassandra) и системы хранения (HDFS, таблицы HIVE, MySQL и т. Д.).
-
Современная оптимизация и генерация кода с помощью оптимизатора Spark SQL Catalyst (структура преобразования дерева).
-
Может быть легко интегрирован со всеми инструментами и средами больших данных через Spark-Core.
-
Предоставляет API для программирования на Python, Java, Scala и R.
Возможность обработки данных размером от килобайта до петабайта от одного узла к большому кластеру.
Поддерживает различные форматы данных (Avro, CSV, эластичный поиск и Cassandra) и системы хранения (HDFS, таблицы HIVE, MySQL и т. Д.).
Современная оптимизация и генерация кода с помощью оптимизатора Spark SQL Catalyst (структура преобразования дерева).
Может быть легко интегрирован со всеми инструментами и средами больших данных через Spark-Core.
Предоставляет API для программирования на Python, Java, Scala и R.
SQLContext
SQLContext является классом и используется для инициализации функций Spark SQL. Объект класса SparkContext (sc) необходим для инициализации объекта класса SQLContext.
Следующая команда используется для инициализации SparkContext через spark-shell.
$ spark-shell
По умолчанию объект SparkContext инициализируется именем sc при запуске spark-shell.
Используйте следующую команду для создания SQLContext.
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
пример
Давайте рассмотрим пример записей сотрудников в файле JSON с именем employee.json . Используйте следующие команды для создания DataFrame (df) и прочитайте документ JSON с именем employee.json со следующим содержимым.
employee.json — Поместите этот файл в каталог, где находится текущий указатель scala> .
{ {"id" : "1201", "name" : "satish", "age" : "25"} {"id" : "1202", "name" : "krishna", "age" : "28"} {"id" : "1203", "name" : "amith", "age" : "39"} {"id" : "1204", "name" : "javed", "age" : "23"} {"id" : "1205", "name" : "prudvi", "age" : "23"} }
Операции с фреймами данных
DataFrame предоставляет предметно-ориентированный язык для управления структурированными данными. Здесь мы приведем несколько основных примеров обработки структурированных данных с использованием DataFrames.
Выполните шаги, приведенные ниже, для выполнения операций DataFrame —
Прочитайте документ JSON
Сначала мы должны прочитать документ JSON. Исходя из этого, сгенерируйте DataFrame с именем (dfs).
Используйте следующую команду, чтобы прочитать документ JSON с именем employee.json . Данные отображаются в виде таблицы с полями — id, name и age.
scala> val dfs = sqlContext.read.json("employee.json")
Вывод — Имена полей берутся автоматически из employee.json .
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]
Показать данные
Если вы хотите увидеть данные в DataFrame, используйте следующую команду.
scala> dfs.show()
Вывод. Вы можете просматривать данные о сотрудниках в табличном формате.
<console>:22, took 0.052610 s +----+------+--------+ |age | id | name | +----+------+--------+ | 25 | 1201 | satish | | 28 | 1202 | krishna| | 39 | 1203 | amith | | 23 | 1204 | javed | | 23 | 1205 | prudvi | +----+------+--------+
Используйте метод printSchema
Если вы хотите увидеть структуру (схему) объекта DataFrame, используйте следующую команду.
scala> dfs.printSchema()
Выход
root |-- age: string (nullable = true) |-- id: string (nullable = true) |-- name: string (nullable = true)
Использовать метод выбора
Используйте следующую команду для извлечения имени -колонки среди трех столбцов из DataFrame.
scala> dfs.select("name").show()
Выход — Вы можете увидеть значения столбца имени .
<console>:22, took 0.044023 s +--------+ | name | +--------+ | satish | | krishna| | amith | | javed | | prudvi | +--------+
Использовать фильтр возраста
Используйте следующую команду для поиска сотрудников, возраст которых превышает 23 (возраст> 23).
scala> dfs.filter(dfs("age") > 23).show()
Выход
<console>:22, took 0.078670 s +----+------+--------+ |age | id | name | +----+------+--------+ | 25 | 1201 | satish | | 28 | 1202 | krishna| | 39 | 1203 | amith | +----+------+--------+
Используйте метод groupBy
Используйте следующую команду для подсчета числа сотрудников одного возраста.
scala> dfs.groupBy("age").count().show()
Выход — два сотрудника в возрасте 23 года.
<console>:22, took 5.196091 s +----+-----+ |age |count| +----+-----+ | 23 | 2 | | 25 | 1 | | 28 | 1 | | 39 | 1 | +----+-----+
Выполнение SQL-запросов программно
SQLContext позволяет приложениям программно выполнять запросы SQL при выполнении функций SQL и возвращает результат в виде DataFrame.
Как правило, в фоновом режиме SparkSQL поддерживает два разных метода для преобразования существующих RDD в DataFrames —
| Старший нет | Методы и описание |
|---|---|
| 1 | Вывод схемы с помощью отражения
Этот метод использует отражение для создания схемы RDD, которая содержит объекты определенных типов. |
| 2 | Программно определяя схему
Второй метод создания DataFrame — через программный интерфейс, который позволяет создать схему и затем применить ее к существующему RDD. |
Этот метод использует отражение для создания схемы RDD, которая содержит объекты определенных типов.
Второй метод создания DataFrame — через программный интерфейс, который позволяет создать схему и затем применить ее к существующему RDD.
Spark SQL — источники данных
Интерфейс DataFrame позволяет различным источникам данных работать на Spark SQL. Это временная таблица и может работать как обычный СДР. Регистрация DataFrame в виде таблицы позволяет выполнять SQL-запросы к его данным.
В этой главе мы опишем общие методы загрузки и сохранения данных с использованием различных источников данных Spark. После этого мы подробно обсудим конкретные параметры, доступные для встроенных источников данных.
В SparkSQL доступны разные типы источников данных, некоторые из которых перечислены ниже:
Spark SQL может автоматически захватывать схему набора данных JSON и загружать ее в виде DataFrame.
Hive поставляется в комплекте с библиотекой Spark как HiveContext, которая наследуется от SQLContext.
Паркет — это столбчатый формат, поддерживаемый многими системами обработки данных.