HCatalog — это инструмент для управления хранением таблиц в Hadoop. Он предоставляет доступ к табличным данным мета-хранилища Hive другим приложениям Hadoop. Это позволяет пользователям с различными инструментами обработки данных (Pig, MapReduce) легко записывать данные в сетку. Это гарантирует, что пользователям не нужно беспокоиться о том, где и в каком формате хранятся их данные.
HCatalog работает как ключевой компонент Hive и позволяет пользователям хранить свои данные в любом формате и любой структуре.
Почему HCatalog?
Включение правильного инструмента для правильной работы
Экосистема Hadoop содержит различные инструменты для обработки данных, такие как Hive, Pig и MapReduce. Хотя эти инструменты не требуют метаданных, они все равно могут извлечь из них пользу, когда они присутствуют. Совместное использование хранилища метаданных также позволяет пользователям разных инструментов более легко обмениваться данными. Рабочий процесс, в котором данные загружаются и нормализуются с помощью MapReduce или Pig, а затем анализируются с помощью Hive, очень распространен. Если все эти инструменты совместно используют одно хранилище метаданных, то пользователи каждого инструмента имеют немедленный доступ к данным, созданным с помощью другого инструмента. Никаких шагов загрузки или передачи не требуется.
Захват состояния обработки для обеспечения общего доступа
HCatalog может публиковать результаты вашей аналитики. Таким образом, другой программист может получить доступ к вашей аналитической платформе через «REST». Опубликованные вами схемы также полезны для других исследователей данных. Другие исследователи данных используют ваши открытия в качестве входных данных для последующего открытия.
Интегрируйте Hadoop со всем
Hadoop как среда обработки и хранения открывает широкие возможности для предприятия; однако, чтобы стимулировать принятие, он должен работать с существующими инструментами и дополнять их. Hadoop должен служить входом для вашей аналитической платформы или интегрироваться с вашими хранилищами операционных данных и веб-приложениями. Организация должна пользоваться преимуществами Hadoop, не изучая совершенно новый набор инструментов. Службы REST открывают платформу для предприятия со знакомым API и SQL-подобным языком. Корпоративные системы управления данными используют HCatalog для более глубокой интеграции с платформой Hadoop.
HCatalog Architecture
На следующем рисунке показана общая архитектура HCatalog.
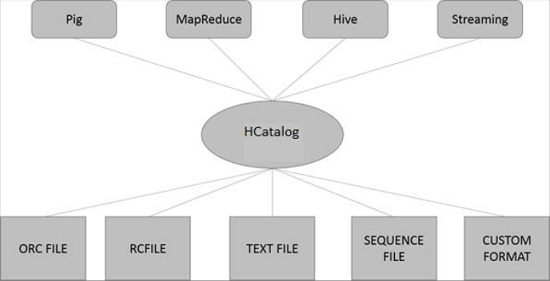
HCatalog поддерживает чтение и запись файлов в любом формате, для которого может быть записан SerDe (сериализатор-десериализатор). По умолчанию HCatalog поддерживает форматы файлов RCFile, CSV, JSON, SequenceFile и ORC. Чтобы использовать пользовательский формат, вы должны предоставить InputFormat, OutputFormat и SerDe.
HCatalog построен поверх метастафа Hive и включает DDL Hive. HCatalog предоставляет интерфейсы чтения и записи для Pig и MapReduce и использует интерфейс командной строки Hive для выдачи определений данных и команд исследования метаданных.