HCatalog — Введение
HCatalog — это инструмент для управления хранением таблиц в Hadoop. Он предоставляет доступ к табличным данным мета-хранилища Hive другим приложениям Hadoop. Это позволяет пользователям с различными инструментами обработки данных (Pig, MapReduce) легко записывать данные в сетку. Это гарантирует, что пользователям не нужно беспокоиться о том, где и в каком формате хранятся их данные.
HCatalog работает как ключевой компонент Hive и позволяет пользователям хранить свои данные в любом формате и любой структуре.
Почему HCatalog?
Включение правильного инструмента для правильной работы
Экосистема Hadoop содержит различные инструменты для обработки данных, такие как Hive, Pig и MapReduce. Хотя эти инструменты не требуют метаданных, они все равно могут извлечь из них пользу, когда они присутствуют. Совместное использование хранилища метаданных также позволяет пользователям разных инструментов более легко обмениваться данными. Рабочий процесс, в котором данные загружаются и нормализуются с помощью MapReduce или Pig, а затем анализируются с помощью Hive, очень распространен. Если все эти инструменты совместно используют одно хранилище метаданных, то пользователи каждого инструмента имеют немедленный доступ к данным, созданным с помощью другого инструмента. Никаких шагов загрузки или передачи не требуется.
Захват состояния обработки для обеспечения общего доступа
HCatalog может публиковать результаты вашей аналитики. Таким образом, другой программист может получить доступ к вашей аналитической платформе через «REST». Опубликованные вами схемы также полезны для других исследователей данных. Другие исследователи данных используют ваши открытия в качестве входных данных для последующего открытия.
Интегрируйте Hadoop со всем
Hadoop как среда обработки и хранения открывает широкие возможности для предприятия; однако, чтобы стимулировать принятие, он должен работать с существующими инструментами и дополнять их. Hadoop должен служить входом для вашей аналитической платформы или интегрироваться с вашими хранилищами операционных данных и веб-приложениями. Организация должна пользоваться преимуществами Hadoop, не изучая совершенно новый набор инструментов. Службы REST открывают платформу для предприятия со знакомым API и SQL-подобным языком. Корпоративные системы управления данными используют HCatalog для более глубокой интеграции с платформой Hadoop.
HCatalog Architecture
На следующем рисунке показана общая архитектура HCatalog.
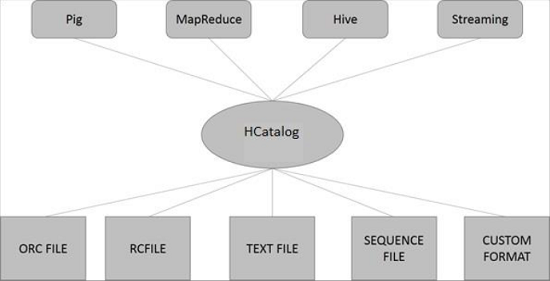
HCatalog поддерживает чтение и запись файлов в любом формате, для которого может быть записан SerDe (сериализатор-десериализатор). По умолчанию HCatalog поддерживает форматы файлов RCFile, CSV, JSON, SequenceFile и ORC. Чтобы использовать пользовательский формат, вы должны предоставить InputFormat, OutputFormat и SerDe.
HCatalog построен поверх метастафа Hive и включает DDL Hive. HCatalog предоставляет интерфейсы чтения и записи для Pig и MapReduce и использует интерфейс командной строки Hive для выдачи определений данных и команд исследования метаданных.
HCatalog — Установка
Все подпроекты Hadoop, такие как Hive, Pig и HBase, поддерживают операционную систему Linux. Следовательно, вам нужно установить Linux-версию в вашей системе. HCatalog объединен с Hive Installation 26 марта 2013 года. Начиная с версии Hive-0.11.0, HCatalog поставляется с Hive Installation. Поэтому следуйте приведенным ниже инструкциям, чтобы установить Hive, который, в свою очередь, автоматически установит HCatalog в вашу систему.
Шаг 1: Проверка установки JAVA
Java должна быть установлена в вашей системе перед установкой Hive. Вы можете использовать следующую команду, чтобы проверить, установлена ли у вас Java в вашей системе:
$ java –version
Если Java уже установлена в вашей системе, вы увидите следующий ответ:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если у вас не установлена Java в вашей системе, вам нужно выполнить шаги, указанные ниже.
Шаг 2. Установка Java
Загрузите Java (JDK <последняя версия> — X64.tar.gz), перейдя по следующей ссылке http://www.oracle.com/
Затем jdk-7u71-linux-x64.tar.gz будет загружен в вашу систему.
Обычно вы найдете загруженный Java-файл в папке Downloads. Проверьте его и извлеките файл jdk-7u71-linux-x64.gz, используя следующие команды.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Откройте root и введите следующие команды.
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл ~ / .bashrc .
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
Теперь проверьте установку, используя команду java -version из терминала, как описано выше.
Шаг 3: Проверка установки Hadoop
Hadoop должен быть установлен в вашей системе перед установкой Hive. Давайте проверим установку Hadoop с помощью следующей команды —
$ hadoop version
Если Hadoop уже установлен в вашей системе, вы получите следующий ответ:
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
Если Hadoop не установлен в вашей системе, выполните следующие шаги:
Шаг 4: Загрузка Hadoop
Загрузите и извлеките Hadoop 2.4.1 из Apache Software Foundation, используя следующие команды.
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Шаг 5. Установка Hadoop в псевдо-распределенном режиме
Следующие шаги используются для установки Hadoop 2.4.1 в псевдораспределенном режиме.
Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc .
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Конфигурация Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Вам необходимо внести соответствующие изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Для разработки программ Hadoop с использованием Java вам необходимо сбросить переменные среды Java в файле hadoop-env.sh , заменив значение JAVA_HOME местоположением Java в вашей системе.
export JAVA_HOME=/usr/local/jdk1.7.0_71
Ниже приведен список файлов, которые вы должны отредактировать для настройки Hadoop.
ядро-site.xml
Файл core-site.xml содержит такую информацию, как номер порта, используемый для экземпляра Hadoop, память, выделенная для файловой системы, лимит памяти для хранения данных и размер буферов чтения / записи.
Откройте файл core-site.xml и добавьте следующие свойства между тегами <configuration> и </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
HDFS-site.xml
Файл hdfs-site.xml содержит такую информацию, как значение данных репликации, путь namenode и путь datanode в ваших локальных файловых системах. Это место, где вы хотите хранить инфраструктуру Hadoop.
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
Этот файл используется, чтобы указать, какую платформу MapReduce мы используем. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего, вам нужно скопировать файл из mapred-site, xml.template в файл mapred-site.xml, используя следующую команду.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Шаг 6: Проверка установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Настройка Namenode
Настройте namenode с помощью команды «hdfs namenode -format» следующим образом:
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем —
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Проверка Hadoop DFS
Следующая команда используется для запуска DFS. Выполнение этой команды запустит вашу файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Скрипт проверки пряжи
Следующая команда используется для запуска скрипта Yarn. Выполнение этой команды запустит ваши демоны Yarn.
$ start-yarn.sh
Ожидаемый результат следующий:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/ yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop — 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в своем браузере.
http://localhost:50070/
Проверьте все приложения для кластера
Номер порта по умолчанию для доступа ко всем приложениям кластера — 8088. Используйте следующий URL для посещения этой службы.
http://localhost:8088/
Когда вы закончите установку Hadoop, перейдите к следующему шагу и установите Hive в вашей системе.
Шаг 7: Загрузка Hive
Мы используем hive-0.14.0 в этом уроке. Вы можете скачать его, перейдя по следующей ссылке http://apache.petsads.us/hive/hive-0.14.0/ . Предположим, что он загружается в каталог / Downloads . Здесь мы загружаем архив Hive с именем « apache-hive-0.14.0-bin.tar.gz » для этого урока. Следующая команда используется для проверки загрузки —
$ cd Downloads $ ls
При успешной загрузке вы увидите следующий ответ —
apache-hive-0.14.0-bin.tar.gz
Шаг 8: Установка куста
Следующие шаги необходимы для установки Hive в вашей системе. Предположим, что архив Hive загружен в каталог / Downloads .
Извлечение и проверка архива улья
Следующая команда используется для проверки загрузки и извлечения архива Hive.
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ ls
При успешной загрузке вы увидите следующий ответ —
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz
Копирование файлов в каталог / usr / local / hive
Нам нужно скопировать файлы из суперпользователя «su -». Следующие команды используются для копирования файлов из извлеченного каталога в каталог / usr / local / hive .
$ su - passwd: # cd /home/user/Download # mv apache-hive-0.14.0-bin /usr/local/hive # exit
Настройка среды для Hive
Вы можете настроить среду Hive, добавив следующие строки в файл ~ / .bashrc —
export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:. export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Следующая команда используется для выполнения файла ~ / .bashrc.
$ source ~/.bashrc
Шаг 9: Настройка Hive
Чтобы настроить Hive с Hadoop, вам нужно отредактировать файл hive-env.sh , который находится в каталоге $ HIVE_HOME / conf . Следующие команды перенаправляют в папку конфигурации Hive и копируют файл шаблона —
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.sh
Отредактируйте файл hive-env.sh , добавив следующую строку —
export HADOOP_HOME=/usr/local/hadoop
На этом установка Hive завершена. Теперь вам требуется внешний сервер базы данных для настройки Metastore. Мы используем базу данных Apache Derby.
Шаг 10: Загрузка и установка Apache Derby
Следуйте приведенным ниже инструкциям, чтобы загрузить и установить Apache Derby —
Загрузка Apache Derby
Следующая команда используется для загрузки Apache Derby. Загрузка занимает некоторое время.
$ cd ~ $ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
Следующая команда используется для проверки загрузки —
$ ls
При успешной загрузке вы увидите следующий ответ —
db-derby-10.4.2.0-bin.tar.gz
Извлечение и проверка архива дерби
Следующие команды используются для извлечения и проверки архива Derby —
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz $ ls
При успешной загрузке вы увидите следующий ответ —
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz
Копирование файлов в каталог / usr / local / derby
Нам нужно скопировать из суперпользователя «su -». Следующие команды используются для копирования файлов из извлеченного каталога в каталог / usr / local / derby —
$ su - passwd: # cd /home/user # mv db-derby-10.4.2.0-bin /usr/local/derby # exit
Настройка среды для дерби
Вы можете настроить среду Derby, добавив следующие строки в файл ~ / .bashrc —
export DERBY_HOME=/usr/local/derby export PATH=$PATH:$DERBY_HOME/bin export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
Следующая команда используется для выполнения файла ~ / .bashrc —
$ source ~/.bashrc
Создать каталог для Metastore
Создайте каталог с именем data в каталоге $ DERBY_HOME для хранения данных Metastore.
$ mkdir $DERBY_HOME/data
Установка Derby и настройка среды завершены.
Шаг 11: Настройка Hive Metastore
Настройка Metastore означает указание Hive, где хранится база данных. Вы можете сделать это, отредактировав файл hive-site.xml , который находится в каталоге $ HIVE_HOME / conf . Прежде всего, скопируйте файл шаблона с помощью следующей команды —
$ cd $HIVE_HOME/conf $ cp hive-default.xml.template hive-site.xml
Отредактируйте файл hive-site.xml и добавьте следующие строки между тегами <configuration> и </ configuration> —
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby://localhost:1527/metastore_db;create = true</value> <description>JDBC connect string for a JDBC metastore</description> </property>
Создайте файл с именем jpox.properties и добавьте в него следующие строки:
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl org.jpox.autoCreateSchema = false org.jpox.validateTables = false org.jpox.validateColumns = false org.jpox.validateConstraints = false org.jpox.storeManagerType = rdbms org.jpox.autoCreateSchema = true org.jpox.autoStartMechanismMode = checked org.jpox.transactionIsolation = read_committed javax.jdo.option.DetachAllOnCommit = true javax.jdo.option.NontransactionalRead = true javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true javax.jdo.option.ConnectionUserName = APP javax.jdo.option.ConnectionPassword = mine
Шаг 12: Проверка установки куста
Перед запуском Hive необходимо создать папку / tmp и отдельную папку Hive в HDFS. Здесь мы используем папку / user / hive / warehouse . Вам необходимо установить разрешение на запись для этих вновь созданных папок, как показано ниже —
chmod g+w
Теперь установите их в HDFS перед проверкой Hive. Используйте следующие команды —
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
Следующие команды используются для проверки установки Hive —
$ cd $HIVE_HOME $ bin/hive
При успешной установке Hive вы получите следующий ответ —
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/ hive-log4j.properties Hive history =/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt …………………. hive>
Вы можете выполнить следующую примерную команду для отображения всех таблиц:
hive> show tables; OK Time taken: 2.798 seconds hive>
Шаг 13: Проверьте установку HCatalog
Используйте следующую команду, чтобы установить системную переменную HCAT_HOME для HCatalog Home.
export HCAT_HOME = $HiVE_HOME/HCatalog
Используйте следующую команду для проверки установки HCatalog.
cd $HCAT_HOME/bin ./hcat
Если установка прошла успешно, вы увидите следующий вывод:
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statement
HCatalog — CLI
Интерфейс командной строки HCatalog (CLI) можно вызвать из команды $ HIVE_HOME / HCatalog / bin / hcat, где $ HIVE_HOME — домашний каталог Hive. hcat — это команда, используемая для инициализации сервера HCatalog.
Используйте следующую команду для инициализации командной строки HCatalog.
cd $HCAT_HOME/bin ./hcat
Если установка была выполнена правильно, вы получите следующий вывод —
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statement
Интерфейс командной строки HCatalog поддерживает следующие параметры командной строки:
| Sr.No | вариант | Пример и описание |
|---|---|---|
| 1 | -г |
hcat -g mygroup … Создаваемая таблица должна иметь группу «mygroup». |
| 2 | -п |
hcat -p rwxr-xr-x … Создаваемая таблица должна иметь разрешения на чтение, запись и выполнение. |
| 3 | -f |
hcat -f myscript.HКаталог … myscript.HCatalog — это файл сценария, содержащий команды DDL для выполнения. |
| 4 | -e |
hcat -e ‘создать таблицу mytable (int);’ … Считайте следующую строку командой DDL и выполните ее. |
| 5 | -D |
hcat -Dkey = значение … Передает пару ключ-значение в HCatalog как системное свойство Java. |
| 6 | — |
hcat Распечатывает сообщение об использовании. |
hcat -g mygroup …
Создаваемая таблица должна иметь группу «mygroup».
hcat -p rwxr-xr-x …
Создаваемая таблица должна иметь разрешения на чтение, запись и выполнение.
hcat -f myscript.HКаталог …
myscript.HCatalog — это файл сценария, содержащий команды DDL для выполнения.
hcat -e ‘создать таблицу mytable (int);’ …
Считайте следующую строку командой DDL и выполните ее.
hcat -Dkey = значение …
Передает пару ключ-значение в HCatalog как системное свойство Java.
hcat
Распечатывает сообщение об использовании.
Примечание —
-
Опции -g и -p не обязательны.
-
Одновременно может быть предоставлена опция -e или -f , но не обе.
-
Порядок опций не имеет значения; Вы можете указать параметры в любом порядке.
Опции -g и -p не обязательны.
Одновременно может быть предоставлена опция -e или -f , но не обе.
Порядок опций не имеет значения; Вы можете указать параметры в любом порядке.
| Sr.No | DDL Команда и описание |
|---|---|
| 1 |
СОЗДАТЬ СТОЛ Создайте таблицу с помощью HCatalog. Если вы создадите таблицу с предложением CLUSTERED BY, вы не сможете писать в нее с помощью Pig или MapReduce. |
| 2 |
ALTER TABLE Поддерживается за исключением параметров REBUILD и CONCATENATE. Его поведение остается таким же, как в Hive. |
| 3 |
DROP TABLE Поддерживается. Поведение такое же, как улей (уронить всю таблицу и структуру). |
| 4 |
CREATE / ALTER / DROP VIEW Поддерживается. Поведение такое же, как улей. Примечание. Pig и MapReduce не могут читать или писать в представления. |
| 5 |
ПОКАЗАТЬ СТОЛЫ Показать список таблиц. |
| 6 |
ПОКАЗАТЬ РАЗДЕЛЫ Показать список разделов. |
| 7 |
Создать / удалить индекс Поддерживаются операции CREATE и DROP FUNCTION, но созданные функции должны быть зарегистрированы в Pig и помещены в CLASSPATH для MapReduce. |
| 8 |
ОПИСАНИЯ Поддерживается. Поведение такое же, как улей. Опишите структуру. |
СОЗДАТЬ СТОЛ
Создайте таблицу с помощью HCatalog. Если вы создадите таблицу с предложением CLUSTERED BY, вы не сможете писать в нее с помощью Pig или MapReduce.
ALTER TABLE
Поддерживается за исключением параметров REBUILD и CONCATENATE. Его поведение остается таким же, как в Hive.
DROP TABLE
Поддерживается. Поведение такое же, как улей (уронить всю таблицу и структуру).
CREATE / ALTER / DROP VIEW
Поддерживается. Поведение такое же, как улей.
Примечание. Pig и MapReduce не могут читать или писать в представления.
ПОКАЗАТЬ СТОЛЫ
Показать список таблиц.
ПОКАЗАТЬ РАЗДЕЛЫ
Показать список разделов.
Создать / удалить индекс
Поддерживаются операции CREATE и DROP FUNCTION, но созданные функции должны быть зарегистрированы в Pig и помещены в CLASSPATH для MapReduce.
ОПИСАНИЯ
Поддерживается. Поведение такое же, как улей. Опишите структуру.
Некоторые из команд из приведенной выше таблицы объясняются в следующих главах.
HCatalog — Создать таблицу
В этой главе объясняется, как создать таблицу и как вставить в нее данные. Соглашения о создании таблицы в HCatalog очень похожи на создание таблицы с использованием Hive.
Создать таблицу Заявление
Создать таблицу — это инструкция, используемая для создания таблицы в метастафе Hive с использованием HCatalog. Его синтаксис и пример следующие:
Синтаксис
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
пример
Предположим, вам нужно создать таблицу с именем employee с помощью оператора CREATE TABLE . В следующей таблице перечислены поля и их типы данных в таблице сотрудников.
| Sr.No | Имя поля | Тип данных |
|---|---|---|
| 1 | Ид | ИНТ |
| 2 | название | строка |
| 3 | Оплата труда | терка |
| 4 | обозначение | строка |
Следующие данные определяют поддерживаемые поля, такие как комментарий , поля в формате строки, такие как терминатор поля, терминатор строк и тип хранимого файла .
COMMENT ‘Employee details’ FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED IN TEXT FILE
Следующий запрос создает таблицу с именем employee, используя приведенные выше данные.
./hcat –e "CREATE TABLE IF NOT EXISTS employee ( eid int, name String, salary String, destination String) \ COMMENT 'Employee details' \ ROW FORMAT DELIMITED \ FIELDS TERMINATED BY ‘\t’ \ LINES TERMINATED BY ‘\n’ \ STORED AS TEXTFILE;"
Если вы добавите опцию ЕСЛИ НЕ СУЩЕСТВУЕТ, HCatalog игнорирует инструкцию, если таблица уже существует.
После успешного создания таблицы вы увидите следующий ответ:
OK Time taken: 5.905 seconds
Заявление о загрузке данных
Как правило, после создания таблицы в SQL мы можем вставить данные с помощью оператора Insert. Но в HCatalog мы вставляем данные с помощью оператора LOAD DATA.
При вставке данных в HCatalog лучше использовать LOAD DATA для хранения массовых записей. Есть два способа загрузки данных: один из локальной файловой системы, а второй из файловой системы Hadoop .
Синтаксис
Синтаксис для LOAD DATA выглядит следующим образом —
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- LOCAL — это идентификатор для указания локального пути. Это необязательно.
- ПЕРЕЗАПИСАТЬ необязательно для перезаписи данных в таблице.
- РАЗДЕЛ необязательно.
пример
Мы вставим следующие данные в таблицу. Это текстовый файл с именем sample.txt в каталоге / home / user .
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin
Следующий запрос загружает данный текст в таблицу.
./hcat –e "LOAD DATA LOCAL INPATH '/home/user/sample.txt' OVERWRITE INTO TABLE employee;"
При успешной загрузке вы увидите следующий ответ —
OK Time taken: 15.905 seconds
HCatalog — Alter Table
В этой главе объясняется, как изменить атрибуты таблицы, например изменить имя таблицы, изменить имена столбцов, добавить столбцы и удалить или заменить столбцы.
Изменить таблицу
Вы можете использовать инструкцию ALTER TABLE, чтобы изменить таблицу в Hive.
Синтаксис
Оператор принимает любой из следующих синтаксисов в зависимости от того, какие атрибуты мы хотим изменить в таблице.
ALTER TABLE name RENAME TO new_name ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) ALTER TABLE name DROP [COLUMN] column_name ALTER TABLE name CHANGE column_name new_name new_type ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
Некоторые из сценариев описаны ниже.
Переименовать в … Заявление
Следующий запрос переименовывает таблицу из сотрудника в emp .
./hcat –e "ALTER TABLE employee RENAME TO emp;"
Изменить заявление
В следующей таблице приведены поля таблицы сотрудников и показаны поля, которые необходимо изменить (жирным шрифтом).
| Имя поля | Преобразовать из типа данных | Изменить имя поля | Преобразовать в тип данных |
|---|---|---|---|
| Ид | ИНТ | Ид | ИНТ |
| название | строка | ENAME | строка |
| оплата труда | терка | оплата труда | двойной |
| обозначение | строка | обозначение | строка |
Следующие запросы переименовывают имя столбца и тип данных столбца, используя вышеуказанные данные —
./hcat –e "ALTER TABLE employee CHANGE name ename String;" ./hcat –e "ALTER TABLE employee CHANGE salary salary Double;"
Добавить столбец Заявление
Следующий запрос добавляет столбец с именем dept к таблице сотрудников .
./hcat –e "ALTER TABLE employee ADD COLUMNS (dept STRING COMMENT 'Department name');"
Заменить заявление
Следующий запрос удаляет все столбцы из таблицы employee и заменяет их столбцами emp и name —
./hcat – e "ALTER TABLE employee REPLACE COLUMNS ( eid INT empid Int, ename STRING name String);"
Выписка со стола
В этой главе описывается, как удалить таблицу в HCatalog. Когда вы удаляете таблицу из метастора, она удаляет данные таблицы / столбца и их метаданные. Это может быть обычная таблица (хранящаяся в metastore) или внешняя таблица (хранящаяся в локальной файловой системе); HCatalog относится к обоим одинаково, независимо от их типа.
Синтаксис выглядит следующим образом —
DROP TABLE [IF EXISTS] table_name;
Следующий запрос удаляет таблицу с именем employee —
./hcat –e "DROP TABLE IF EXISTS employee;"
При успешном выполнении запроса вы увидите следующий ответ:
OK Time taken: 5.3 seconds
HCatalog — Просмотр
В этой главе описывается, как создавать и управлять представлением в HCatalog. Представления базы данных создаются с помощью оператора CREATE VIEW . Представления могут быть созданы из одной таблицы, нескольких таблиц или другого представления.
Чтобы создать представление, пользователь должен иметь соответствующие системные привилегии в соответствии с конкретной реализацией.
Создать представление заявления
CREATE VIEW создает вид с заданным именем. Выдается ошибка, если таблица или представление с таким именем уже существует. Вы можете использовать IF NOT EXISTS, чтобы пропустить ошибку.
Если имена столбцов не указаны, имена столбцов представления будут автоматически получены из определяющего выражения SELECT .
Примечание. Если в SELECT содержатся ненасыщенные скалярные выражения, такие как x + y, имена столбцов полученного представления будут сгенерированы в виде _C0, _C1 и т. Д.
При переименовании столбцов также могут быть предоставлены комментарии к столбцам. Комментарии не наследуются автоматически от нижележащих столбцов.
Оператор CREATE VIEW завершится ошибкой, если определяющее представление выражение SELECT недопустимо.
Синтаксис
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT view_comment] [TBLPROPERTIES (property_name = property_value, ...)] AS SELECT ...;
пример
Ниже приведены данные таблицы сотрудников. Теперь давайте посмотрим, как создать представление с именем Emp_Deg_View, содержащее поля id, name, Designation и оклад сотрудника с зарплатой, превышающей 35 000.
+------+-------------+--------+-------------------+-------+ | ID | Name | Salary | Designation | Dept | +------+-------------+--------+-------------------+-------+ | 1201 | Gopal | 45000 | Technical manager | TP | | 1202 | Manisha | 45000 | Proofreader | PR | | 1203 | Masthanvali | 30000 | Technical writer | TP | | 1204 | Kiran | 40000 | Hr Admin | HR | | 1205 | Kranthi | 30000 | Op Admin | Admin | +------+-------------+--------+-------------------+-------+
Ниже приведена команда для создания представления на основе приведенных выше данных.
./hcat –e "CREATE VIEW Emp_Deg_View (salary COMMENT ' salary more than 35,000') AS SELECT id, name, salary, designation FROM employee WHERE salary ≥ 35000;"
Выход
OK Time taken: 5.3 seconds
Отбросить заявление
DROP VIEW удаляет метаданные для указанного представления. При отбрасывании представления, на которое ссылаются другие представления, предупреждение не выводится (зависимые представления остаются висящими как недействительные и должны быть удалены или воссозданы пользователем).
Синтаксис
DROP VIEW [IF EXISTS] view_name;
пример
Следующая команда используется для удаления представления с именем Emp_Deg_View .
DROP VIEW Emp_Deg_View;
HCatalog — Показать таблицы
Вы часто хотите перечислить все таблицы в базе данных или перечислить все столбцы в таблице. Очевидно, что каждая база данных имеет свой синтаксис для перечисления таблиц и столбцов.
Оператор Show Tables отображает имена всех таблиц. По умолчанию в нем перечислены таблицы из текущей базы данных или с предложением IN в указанной базе данных.
В этой главе описывается, как перечислить все таблицы из текущей базы данных в HCatalog.
Показать таблицы
Синтаксис SHOW TABLES следующий:
SHOW TABLES [IN database_name] ['identifier_with_wildcards'];
Следующий запрос отображает список таблиц —
./hcat –e "Show tables;"
При успешном выполнении запроса вы увидите следующий ответ:
OK emp employee Time taken: 5.3 seconds
HCatalog — Показать разделы
Раздел — это условие для табличных данных, которое используется для создания отдельной таблицы или представления. SHOW PARTITIONS перечисляет все существующие разделы для данной базовой таблицы. Разделы перечислены в алфавитном порядке. После Hive 0.6 также можно указать части спецификации раздела для фильтрации результирующего списка.
Вы можете использовать команду SHOW PARTITIONS, чтобы увидеть разделы, которые существуют в определенной таблице. В этой главе описывается, как составить список разделов определенной таблицы в HCatalog.
Показать раздел разделов
Синтаксис выглядит следующим образом —
SHOW PARTITIONS table_name;
Следующий запрос удаляет таблицу с именем employee —
./hcat –e "Show partitions employee;"
При успешном выполнении запроса вы увидите следующий ответ:
OK Designation = IT Time taken: 5.3 seconds
Динамический раздел
HCatalog организует таблицы в разделы. Это способ разделения таблицы на связанные части на основе значений разделенных столбцов, таких как дата, город и отдел. Используя разделы, легко запросить часть данных.
Например, таблица с именем Tab1 содержит данные о сотрудниках, такие как id, name, dept и yoj (т. Е. Год присоединения). Предположим, вам нужно получить сведения обо всех сотрудниках, присоединившихся в 2012 году. Запрос ищет всю информацию во всей таблице. Однако если вы разделите данные о сотрудниках по году и сохраните их в отдельном файле, это сократит время обработки запроса. В следующем примере показано, как разделить файл и его данные:
Следующий файл содержит таблицу сотрудников .
/ Tab1 / employeedata / файл1
id, name, dept, yoj 1, gopal, TP, 2012 2, kiran, HR, 2012 3, kaleel, SC, 2013 4, Prasanth, SC, 2013
Приведенные выше данные разбиты на два файла с использованием года.
/ Tab1 / employeedata / 2012 / file2
1, gopal, TP, 2012 2, kiran, HR, 2012
/ Tab1 / employeedata / 2013 / file3
3, kaleel, SC, 2013 4, Prasanth, SC, 2013
Добавление раздела
Мы можем добавить разделы в таблицу, изменив таблицу. Предположим, у нас есть таблица с именем employee, в которой есть такие поля, как Id, Name, Salary, Designation, Dept и yoj.
Синтаксис
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (p_column = p_col_value, p_column = p_col_value, ...)
Следующий запрос используется для добавления раздела в таблицу сотрудников .
./hcat –e "ALTER TABLE employee ADD PARTITION (year = '2013') location '/2012/part2012';"
Переименование раздела
Вы можете использовать команду RENAME-TO, чтобы переименовать раздел. Его синтаксис выглядит следующим образом —
./hact –e "ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;"
Следующий запрос используется для переименования раздела —
./hcat –e "ALTER TABLE employee PARTITION (year=’1203’) RENAME TO PARTITION (Yoj='1203');"
Отбрасывание раздела
Синтаксис команды, используемой для удаления раздела, следующий:
./hcat –e "ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec,. PARTITION partition_spec,...;"
Следующий запрос используется для удаления раздела —
./hcat –e "ALTER TABLE employee DROP [IF EXISTS] PARTITION (year=’1203’);"
HCatalog — Индексы
Создание индекса
Индекс — это не что иное, как указатель на определенный столбец таблицы. Создание индекса означает создание указателя на определенный столбец таблицы. Его синтаксис выглядит следующим образом —
CREATE INDEX index_name ON TABLE base_table_name (col_name, ...) AS 'index.handler.class.name' [WITH DEFERRED REBUILD] [IDXPROPERTIES (property_name = property_value, ...)] [IN TABLE index_table_name] [PARTITIONED BY (col_name, ...)][ [ ROW FORMAT ...] STORED AS ... | STORED BY ... ] [LOCATION hdfs_path] [TBLPROPERTIES (...)]
пример
Давайте возьмем пример, чтобы понять понятие индекса. Используйте ту же таблицу сотрудников, которую мы использовали ранее с полями Id, Name, Salary, Designation и Dept. Создайте индекс index_salary для столбца salary таблицы employee .
Следующий запрос создает индекс —
./hcat –e "CREATE INDEX inedx_salary ON TABLE employee(salary) AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';"
Это указатель на столбец зарплаты . Если столбец изменен, изменения сохраняются с использованием значения индекса.
Отбрасывание индекса
Следующий синтаксис используется для удаления индекса —
DROP INDEX <index_name> ON <table_name>
Следующий запрос удаляет индекс index_salary —
./hcat –e "DROP INDEX index_salary ON employee;"
HCatalog — Reader Writer
HCatalog содержит API передачи данных для параллельного ввода и вывода без использования MapReduce. Этот API использует базовую абстракцию хранения таблиц и строк для чтения данных из кластера Hadoop и записи данных в него.
API передачи данных содержит в основном три класса; это —
-
HCatReader — читает данные из кластера Hadoop.
-
HCatWriter — записывает данные в кластер Hadoop.
-
DataTransferFactory — генерирует экземпляры чтения и записи.
HCatReader — читает данные из кластера Hadoop.
HCatWriter — записывает данные в кластер Hadoop.
DataTransferFactory — генерирует экземпляры чтения и записи.
Этот API подходит для настройки главного-подчиненного узла. Давайте обсудим больше о HCatReader и HCatWriter .
HCatReader
HCatReader — это абстрактный класс, внутренний для HCatalog, который абстрагируется от сложностей базовой системы, из которой должны быть получены записи.
| С. Нет. | Название и описание метода |
|---|---|
| 1 |
Открытый абстрактный ReaderContext prepareRead () создает исключение HCatException Это должно быть вызвано на главном узле для получения ReaderContext, который затем должен быть сериализован и отправлен подчиненным узлам. |
| 2 |
Открытый абстрактный итератор <HCatRecorder> read () создает исключение HCaException Это должно быть вызвано на подчиненных узлах для чтения HCatRecords. |
| 3 |
Публичная конфигурация getConf () Он вернет объект класса конфигурации. |
Открытый абстрактный ReaderContext prepareRead () создает исключение HCatException
Это должно быть вызвано на главном узле для получения ReaderContext, который затем должен быть сериализован и отправлен подчиненным узлам.
Открытый абстрактный итератор <HCatRecorder> read () создает исключение HCaException
Это должно быть вызвано на подчиненных узлах для чтения HCatRecords.
Публичная конфигурация getConf ()
Он вернет объект класса конфигурации.
Класс HCatReader используется для чтения данных из HDFS. Чтение представляет собой двухэтапный процесс, в котором первый шаг выполняется на главном узле внешней системы. Второй шаг выполняется параллельно на нескольких подчиненных узлах.
Чтения сделаны на ReadEntity . Прежде чем вы начнете читать, вам нужно определить ReadEntity для чтения. Это можно сделать через ReadEntity.Builder . Вы можете указать имя базы данных, имя таблицы, раздел и строку фильтра. Например —
ReadEntity.Builder builder = new ReadEntity.Builder();
ReadEntity entity = builder.withDatabase("mydb").withTable("mytbl").build(); 10.
Приведенный выше фрагмент кода определяет объект ReadEntity («entity»), содержащий таблицу с именем mytbl в базе данных с именем mydb , которую можно использовать для чтения всех строк этой таблицы. Обратите внимание, что эта таблица должна существовать в HCatalog до начала этой операции.
После определения ReadEntity вы получаете экземпляр HCatReader, используя ReadEntity и конфигурацию кластера —
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);
Следующим шагом является получение ReaderContext от читателя следующим образом:
ReaderContext cntxt = reader.prepareRead();
HCatWriter
Эта абстракция является внутренней для HCatalog. Это облегчает запись в HCatalog из внешних систем. Не пытайтесь создавать это напрямую. Вместо этого используйте DataTransferFactory.
| Sr.No. | Название и описание метода |
|---|---|
| 1 |
Открытый абстрактный WriterContext prepareRead () генерирует исключение HCatException Внешняя система должна вызывать этот метод ровно один раз из главного узла. Возвращает WriterContext . Это должно быть сериализовано и отправлено на подчиненные узлы для создания там HCatWriter . |
| 2 |
Открытый абстрактный void write (Iterator <HCatRecord> recordItr) выдает исключение HCaException Этот метод должен использоваться на подчиненных узлах для выполнения записи. RecordItr — это объект-итератор, содержащий коллекцию записей для записи в HCatalog. |
| 3 |
Открытый абстрактный void abort (WriterContext cntxt) создает исключение HCatException Этот метод должен вызываться на главном узле. Основная цель этого метода заключается в выполнении очистки в случае сбоев. |
| 4 |
открытый абстрактный void commit (WriterContext cntxt) выдает исключение HCatException Этот метод должен вызываться на главном узле. Целью этого метода является фиксация метаданных. |
Открытый абстрактный WriterContext prepareRead () генерирует исключение HCatException
Внешняя система должна вызывать этот метод ровно один раз из главного узла. Возвращает WriterContext . Это должно быть сериализовано и отправлено на подчиненные узлы для создания там HCatWriter .
Открытый абстрактный void write (Iterator <HCatRecord> recordItr) выдает исключение HCaException
Этот метод должен использоваться на подчиненных узлах для выполнения записи. RecordItr — это объект-итератор, содержащий коллекцию записей для записи в HCatalog.
Открытый абстрактный void abort (WriterContext cntxt) создает исключение HCatException
Этот метод должен вызываться на главном узле. Основная цель этого метода заключается в выполнении очистки в случае сбоев.
открытый абстрактный void commit (WriterContext cntxt) выдает исключение HCatException
Этот метод должен вызываться на главном узле. Целью этого метода является фиксация метаданных.
Подобно чтению, запись также представляет собой двухэтапный процесс, в котором первый шаг выполняется на главном узле. Впоследствии второй шаг происходит параллельно на подчиненных узлах.
Запись выполняется в WriteEntity, который может быть сконструирован аналогично reads —
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withDatabase("mydb").withTable("mytbl").build();
Приведенный выше код создает объектный объект WriteEntity, который можно использовать для записи в таблицу с именем mytbl в базе данных mydb .
После создания WriteEntity следующим шагом является получение WriterContext —
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config); WriterContext info = writer.prepareWrite();
Все вышеперечисленные шаги выполняются на главном узле. Затем главный узел сериализует объект WriterContext и делает его доступным для всех ведомых устройств.
На подчиненных узлах вам необходимо получить HCatWriter с помощью WriterContext следующим образом:
HCatWriter writer = DataTransferFactory.getHCatWriter(context);
Затем писатель принимает итератор в качестве аргумента для метода write —
writer.write(hCatRecordItr);
Затем автор вызывает getNext () для этого итератора в цикле и записывает все записи, прикрепленные к итератору.
Файл TestReaderWriter.java используется для проверки классов HCatreader и HCatWriter. Следующая программа демонстрирует, как использовать HCatReader и HCatWriter API для чтения данных из исходного файла и последующей записи их в файл назначения.
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.metastore.api.MetaException;
import org.apache.hadoop.hive.ql.CommandNeedRetryException;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hive.HCatalog.common.HCatException;
import org.apache.hive.HCatalog.data.transfer.DataTransferFactory;
import org.apache.hive.HCatalog.data.transfer.HCatReader;
import org.apache.hive.HCatalog.data.transfer.HCatWriter;
import org.apache.hive.HCatalog.data.transfer.ReadEntity;
import org.apache.hive.HCatalog.data.transfer.ReaderContext;
import org.apache.hive.HCatalog.data.transfer.WriteEntity;
import org.apache.hive.HCatalog.data.transfer.WriterContext;
import org.apache.hive.HCatalog.mapreduce.HCatBaseTest;
import org.junit.Assert;
import org.junit.Test;
public class TestReaderWriter extends HCatBaseTest {
@Test
public void test() throws MetaException, CommandNeedRetryException,
IOException, ClassNotFoundException {
driver.run("drop table mytbl");
driver.run("create table mytbl (a string, b int)");
Iterator<Entry<String, String>> itr = hiveConf.iterator();
Map<String, String> map = new HashMap<String, String>();
while (itr.hasNext()) {
Entry<String, String> kv = itr.next();
map.put(kv.getKey(), kv.getValue());
}
WriterContext cntxt = runsInMaster(map);
File writeCntxtFile = File.createTempFile("hcat-write", "temp");
writeCntxtFile.deleteOnExit();
// Serialize context.
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(writeCntxtFile));
oos.writeObject(cntxt);
oos.flush();
oos.close();
// Now, deserialize it.
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(writeCntxtFile));
cntxt = (WriterContext) ois.readObject();
ois.close();
runsInSlave(cntxt);
commit(map, true, cntxt);
ReaderContext readCntxt = runsInMaster(map, false);
File readCntxtFile = File.createTempFile("hcat-read", "temp");
readCntxtFile.deleteOnExit();
oos = new ObjectOutputStream(new FileOutputStream(readCntxtFile));
oos.writeObject(readCntxt);
oos.flush();
oos.close();
ois = new ObjectInputStream(new FileInputStream(readCntxtFile));
readCntxt = (ReaderContext) ois.readObject();
ois.close();
for (int i = 0; i < readCntxt.numSplits(); i++) {
runsInSlave(readCntxt, i);
}
}
private WriterContext runsInMaster(Map<String, String> config) throws HCatException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
WriterContext info = writer.prepareWrite();
return info;
}
private ReaderContext runsInMaster(Map<String, String> config,
boolean bogus) throws HCatException {
ReadEntity entity = new ReadEntity.Builder().withTable("mytbl").build();
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);
ReaderContext cntxt = reader.prepareRead();
return cntxt;
}
private void runsInSlave(ReaderContext cntxt, int slaveNum) throws HCatException {
HCatReader reader = DataTransferFactory.getHCatReader(cntxt, slaveNum);
Iterator<HCatRecord> itr = reader.read();
int i = 1;
while (itr.hasNext()) {
HCatRecord read = itr.next();
HCatRecord written = getRecord(i++);
// Argh, HCatRecord doesnt implement equals()
Assert.assertTrue("Read: " + read.get(0) + "Written: " + written.get(0),
written.get(0).equals(read.get(0)));
Assert.assertTrue("Read: " + read.get(1) + "Written: " + written.get(1),
written.get(1).equals(read.get(1)));
Assert.assertEquals(2, read.size());
}
//Assert.assertFalse(itr.hasNext());
}
private void runsInSlave(WriterContext context) throws HCatException {
HCatWriter writer = DataTransferFactory.getHCatWriter(context);
writer.write(new HCatRecordItr());
}
private void commit(Map<String, String> config, boolean status,
WriterContext context) throws IOException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
if (status) {
writer.commit(context);
} else {
writer.abort(context);
}
}
private static HCatRecord getRecord(int i) {
List<Object> list = new ArrayList<Object>(2);
list.add("Row #: " + i);
list.add(i);
return new DefaultHCatRecord(list);
}
private static class HCatRecordItr implements Iterator<HCatRecord> {
int i = 0;
@Override
public boolean hasNext() {
return i++ < 100 ? true : false;
}
@Override
public HCatRecord next() {
return getRecord(i);
}
@Override
public void remove() {
throw new RuntimeException();
}
}
}
Вышеупомянутая программа считывает данные из HDFS в виде записей и записывает данные записи в mytable.
HCatalog — Формат ввода-вывода
Интерфейсы HCatInputFormat и HCatOutputFormat используются для чтения данных из HDFS и после обработки записывают полученные данные в HDFS с помощью задания MapReduce. Давайте разработаем интерфейсы формата ввода и вывода.
HCatInputFormat
HCatInputFormat используется с заданиями MapReduce для чтения данных из таблиц, управляемых HCatalog. HCatInputFormat предоставляет Hadoop 0.20 MapReduce API для чтения данных, как если бы они были опубликованы в таблице.
| Sr.No. | Название и описание метода |
|---|---|
| 1 |
public static HCatInputFormat setInput (Job job, String dbName, String tableName) выдает IOException Установите входы для использования в работе. Он запрашивает метастаз с заданной входной спецификацией и сериализует соответствующие разделы в конфигурации задания для задач MapReduce. |
| 2 |
public static HCatInputFormat setInput (Config конфигурации, String dbName, String tableName) выдает IOException Установите входы для использования в работе. Он запрашивает метастаз с заданной входной спецификацией и сериализует соответствующие разделы в конфигурации задания для задач MapReduce. |
| 3 |
public HCatInputFormat setFilter (String filter) выбрасывает IOException Установите фильтр на входной таблице. |
| 4 |
public HCatInputFormat setProperties (Свойства свойств) бросает IOException Установите свойства для формата ввода. |
public static HCatInputFormat setInput (Job job, String dbName, String tableName) выдает IOException
Установите входы для использования в работе. Он запрашивает метастаз с заданной входной спецификацией и сериализует соответствующие разделы в конфигурации задания для задач MapReduce.
public static HCatInputFormat setInput (Config конфигурации, String dbName, String tableName) выдает IOException
Установите входы для использования в работе. Он запрашивает метастаз с заданной входной спецификацией и сериализует соответствующие разделы в конфигурации задания для задач MapReduce.
public HCatInputFormat setFilter (String filter) выбрасывает IOException
Установите фильтр на входной таблице.
public HCatInputFormat setProperties (Свойства свойств) бросает IOException
Установите свойства для формата ввода.
API-интерфейс HCatInputFormat включает следующие методы:
- setInput
- setOutputSchema
- getTableSchema
Чтобы использовать HCatInputFormat для чтения данных, сначала создайте экземпляр InputJobInfo с необходимой информацией из считываемой таблицы, а затем вызовите setInput с InputJobInfo .
Вы можете использовать метод setOutputSchema, чтобы включить схему проекции , чтобы указать поля вывода. Если схема не указана, будут возвращены все столбцы в таблице. Вы можете использовать метод getTableSchema, чтобы определить схему таблицы для указанной входной таблицы.
HCatOutputFormat
HCatOutputFormat используется с заданиями MapReduce для записи данных в таблицы, управляемые HCatalog. HCatOutputFormat предоставляет Hadoop 0.20 MapReduce API для записи данных в таблицу. Когда задание MapReduce использует HCatOutputFormat для записи вывода, используется выходной формат по умолчанию, настроенный для таблицы, и новый раздел публикуется в таблице после завершения задания.
| Sr.No. | Название и описание метода |
|---|---|
| 1 |
public static void setOutput (Config конфигурации, учетные данные Credentials, OutputJobInfo outputJobInfo) выбрасывает IOException Установите информацию о выходе для записи для работы. Он запрашивает сервер метаданных, чтобы найти StorageHandler для использования в таблице. Выдает ошибку, если раздел уже опубликован. |
| 2 |
public static void setSchema (Config конфигурации, схема HCatSchema) выдает IOException Установите схему для данных, записываемых в раздел. Схема таблицы используется по умолчанию для раздела, если это не вызывается. |
| 3 |
public RecordWriter <WritableComparable <?>, HCatRecord> getRecordWriter (контекст TaskAttemptContext) выбрасывает IOException, InterruptedException Получить запись писателя для работы. Он использует стандартный выходной формат StorageHandler для получения записи. |
| 4 |
public OutputCommitter getOutputCommitter (TaskAttemptContext context) выбрасывает IOException, InterruptedException Получите выходной коммиттер для этого выходного формата. Это гарантирует, что вывод фиксируется правильно. |
public static void setOutput (Config конфигурации, учетные данные Credentials, OutputJobInfo outputJobInfo) выбрасывает IOException
Установите информацию о выходе для записи для работы. Он запрашивает сервер метаданных, чтобы найти StorageHandler для использования в таблице. Выдает ошибку, если раздел уже опубликован.
public static void setSchema (Config конфигурации, схема HCatSchema) выдает IOException
Установите схему для данных, записываемых в раздел. Схема таблицы используется по умолчанию для раздела, если это не вызывается.
public RecordWriter <WritableComparable <?>, HCatRecord> getRecordWriter (контекст TaskAttemptContext) выбрасывает IOException, InterruptedException
Получить запись писателя для работы. Он использует стандартный выходной формат StorageHandler для получения записи.
public OutputCommitter getOutputCommitter (TaskAttemptContext context) выбрасывает IOException, InterruptedException
Получите выходной коммиттер для этого выходного формата. Это гарантирует, что вывод фиксируется правильно.
API-интерфейс HCatOutputFormat включает следующие методы:
- setOutput
- setSchema
- getTableSchema
Первый вызов в HCatOutputFormat должен быть установлен setOutput ; любой другой вызов выдаст исключение, сообщающее, что формат вывода не инициализирован.
Схема для записываемых данных указывается методом setSchema . Вы должны вызвать этот метод, предоставив схему данных, которые вы пишете. Если ваши данные имеют ту же схему, что и схема таблицы, вы можете использовать HCatOutputFormat.getTableSchema (), чтобы получить схему таблицы, а затем передать ее в setSchema () .
пример
Следующая программа MapReduce считывает данные из одной таблицы, которая, как предполагается, имеет целое число во втором столбце («столбец 1»), и подсчитывает, сколько экземпляров каждого отдельного значения она находит. То есть он делает эквивалент « выберите col1, count (*) из группы $ table по col1; ».
Например, если значения во втором столбце равны {1, 1, 1, 3, 3, 5}, программа выдаст следующий вывод значений и считает:
1, 3 3, 2 5, 1
Давайте теперь посмотрим на код программы —
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.HCatalog.common.HCatConstants;
import org.apache.HCatalog.data.DefaultHCatRecord;
import org.apache.HCatalog.data.HCatRecord;
import org.apache.HCatalog.data.schema.HCatSchema;
import org.apache.HCatalog.mapreduce.HCatInputFormat;
import org.apache.HCatalog.mapreduce.HCatOutputFormat;
import org.apache.HCatalog.mapreduce.InputJobInfo;
import org.apache.HCatalog.mapreduce.OutputJobInfo;
public class GroupByAge extends Configured implements Tool {
public static class Map extends Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable> {
int age;
@Override
protected void map(
WritableComparable key, HCatRecord value,
org.apache.hadoop.mapreduce.Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable>.Context context
)throws IOException, InterruptedException {
age = (Integer) value.get(1);
context.write(new IntWritable(age), new IntWritable(1));
}
}
public static class Reduce extends Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord> {
@Override
protected void reduce(
IntWritable key, java.lang.Iterable<IntWritable> values,
org.apache.hadoop.mapreduce.Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord>.Context context
)throws IOException ,InterruptedException {
int sum = 0;
Iterator<IntWritable> iter = values.iterator();
while (iter.hasNext()) {
sum++;
iter.next();
}
HCatRecord record = new DefaultHCatRecord(2);
record.set(0, key.get());
record.set(1, sum);
context.write(null, record);
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
args = new GenericOptionsParser(conf, args).getRemainingArgs();
String serverUri = args[0];
String inputTableName = args[1];
String outputTableName = args[2];
String dbName = null;
String principalID = System
.getProperty(HCatConstants.HCAT_METASTORE_PRINCIPAL);
if (principalID != null)
conf.set(HCatConstants.HCAT_METASTORE_PRINCIPAL, principalID);
Job job = new Job(conf, "GroupByAge");
HCatInputFormat.setInput(job, InputJobInfo.create(dbName, inputTableName, null));
// initialize HCatOutputFormat
job.setInputFormatClass(HCatInputFormat.class);
job.setJarByClass(GroupByAge.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(WritableComparable.class);
job.setOutputValueClass(DefaultHCatRecord.class);
HCatOutputFormat.setOutput(job, OutputJobInfo.create(dbName, outputTableName, null));
HCatSchema s = HCatOutputFormat.getTableSchema(job);
System.err.println("INFO: output schema explicitly set for writing:" + s);
HCatOutputFormat.setSchema(job, s);
job.setOutputFormatClass(HCatOutputFormat.class);
return (job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new GroupByAge(), args);
System.exit(exitCode);
}
}
Перед компиляцией вышеуказанной программы вам необходимо скачать несколько jar- файлов и добавить их в classpath для этого приложения. Вам необходимо загрузить все банки Hive и HCatalog (HCatalog-core-0.5.0.jar, hive-metastore-0.10.0.jar, libthrift-0.7.0.jar, hive-exec-0.10.0.jar, libfb303-0.7.0.jar, jdo2-api-2.3-ec.jar, slf4j-api-1.6.1.jar).
Используйте следующие команды, чтобы скопировать эти файлы JAR из локального в HDFS и добавить их в путь к классам .
bin/hadoop fs -copyFromLocal $HCAT_HOME/share/HCatalog/HCatalog-core-0.5.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/hive-metastore-0.10.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/libthrift-0.7.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/hive-exec-0.10.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/libfb303-0.7.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/jdo2-api-2.3-ec.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/slf4j-api-1.6.1.jar /tmp export LIB_JARS=hdfs:///tmp/HCatalog-core-0.5.0.jar, hdfs:///tmp/hive-metastore-0.10.0.jar, hdfs:///tmp/libthrift-0.7.0.jar, hdfs:///tmp/hive-exec-0.10.0.jar, hdfs:///tmp/libfb303-0.7.0.jar, hdfs:///tmp/jdo2-api-2.3-ec.jar, hdfs:///tmp/slf4j-api-1.6.1.jar
Используйте следующую команду, чтобы скомпилировать и выполнить данную программу.
$HADOOP_HOME/bin/hadoop jar GroupByAge tmp/hive
Теперь проверьте выходной каталог (hdfs: user / tmp / hive) для вывода (part_0000, part_0001).
HCatalog — Загрузчик и Хранитель
API-интерфейсы HCatLoader и HCatStorer используются со сценариями Pig для чтения и записи данных в таблицы, управляемые HCatalog. Для этих интерфейсов не требуется настройка, специфичная для HCatalog.
Лучше иметь некоторые знания о скриптах Apache Pig, чтобы лучше понять эту главу. Для дальнейшего ознакомления, пожалуйста, ознакомьтесь с нашим руководством Apache Pig .
HCatloader
HCatLoader используется со сценариями Pig для чтения данных из таблиц, управляемых HCatalog. Используйте следующий синтаксис для загрузки данных в HDFS с использованием HCatloader.
A = LOAD 'tablename' USING org.apache.HCatalog.pig.HCatLoader();
Вы должны указать имя таблицы в одинарных кавычках: LOAD ‘tablename’ . Если вы используете базу данных не по умолчанию, то вы должны указать свой ввод как ‘ dbname.tablename’ .
Метастабор Hive позволяет создавать таблицы без указания базы данных. Если вы создали таблицы таким способом, тогда имя базы данных будет «default» и не требуется при указании таблицы для HCatLoader.
Следующая таблица содержит важные методы и описание класса HCatloader.
| Sr.No. | Название и описание метода |
|---|---|
| 1 |
public InputFormat <?,?> getInputFormat () выдает IOException Прочитайте формат ввода данных загрузки, используя класс HCatloader. |
| 2 |
public StringlativeToAbsolutePath (расположение строки, путь curDir) выдает IOException Возвращает строковый формат абсолютного пути . |
| 3 |
public void setLocation (расположение строки, задание) выдает IOException Он устанавливает место, где можно выполнить задание. |
| 4 |
public Tuple getNext () генерирует IOException Возвращает текущий кортеж ( ключ и значение ) из цикла. |
public InputFormat <?,?> getInputFormat () выдает IOException
Прочитайте формат ввода данных загрузки, используя класс HCatloader.
public StringlativeToAbsolutePath (расположение строки, путь curDir) выдает IOException
Возвращает строковый формат абсолютного пути .
public void setLocation (расположение строки, задание) выдает IOException
Он устанавливает место, где можно выполнить задание.
public Tuple getNext () генерирует IOException
Возвращает текущий кортеж ( ключ и значение ) из цикла.
HCatStorer
HCatStorer используется со сценариями Pig для записи данных в таблицы, управляемые HCatalog. Используйте следующий синтаксис для операции хранения.
A = LOAD ... B = FOREACH A ... ... ... my_processed_data = ... STORE my_processed_data INTO 'tablename' USING org.apache.HCatalog.pig.HCatStorer();
Вы должны указать имя таблицы в одинарных кавычках: LOAD ‘tablename’ . И база данных, и таблица должны быть созданы до запуска скрипта Pig. Если вы используете базу данных не по умолчанию, то вы должны указать свой ввод как ‘dbname.tablename’ .
Метастабор Hive позволяет создавать таблицы без указания базы данных. Если вы создали таблицы таким образом, тогда имя базы данных будет «default», и вам не нужно указывать имя базы данных в операторе store .
Для предложения USING у вас может быть строковый аргумент, представляющий пары ключ / значение для разделов. Это обязательный аргумент, когда вы пишете в многораздельную таблицу, а столбец раздела отсутствует в выходном столбце. Значения ключей раздела НЕ должны быть в кавычках.
Следующая таблица содержит важные методы и описание класса HCatStorer.
| Sr.No. | Название и описание метода |
|---|---|
| 1 |
public OutputFormat getOutputFormat () выбрасывает IOException Прочитайте выходной формат сохраненных данных, используя класс HCatStorer. |
| 2 |
public void setStoreLocation (расположение строки, задание) выдает IOException Устанавливает место, где выполнить это приложение магазина . |
| 3 |
public void storeSchema (схема ResourceSchema, String arg1, Job job) выдает IOException Сохраните схему. |
| 4 |
public void prepareToWrite (писатель RecordWriter) бросает IOException Это помогает записывать данные в определенный файл, используя RecordWriter. |
| 5 |
public void putNext (Tuple tuple) выдает IOException Записывает данные кортежа в файл. |
public OutputFormat getOutputFormat () выбрасывает IOException
Прочитайте выходной формат сохраненных данных, используя класс HCatStorer.
public void setStoreLocation (расположение строки, задание) выдает IOException
Устанавливает место, где выполнить это приложение магазина .
public void storeSchema (схема ResourceSchema, String arg1, Job job) выдает IOException
Сохраните схему.
public void prepareToWrite (писатель RecordWriter) бросает IOException
Это помогает записывать данные в определенный файл, используя RecordWriter.
public void putNext (Tuple tuple) выдает IOException
Записывает данные кортежа в файл.
Бегущая Свинья с HCatalog
Свинья не собирает банки HCatalog автоматически. Чтобы ввести необходимые файлы jar , вы можете либо использовать флаг в команде Pig, либо установить переменные окружения PIG_CLASSPATH и PIG_OPTS, как описано ниже.
Чтобы ввести соответствующие банки для работы с HCatalog, просто включите следующий флаг:
pig –useHCatalog <Sample pig scripts file>
Настройка CLASSPATH для выполнения
Используйте следующую настройку CLASSPATH для синхронизации HCatalog с Apache Pig.
export HADOOP_HOME = <path_to_hadoop_install> export HIVE_HOME = <path_to_hive_install> export HCAT_HOME = <path_to_hcat_install> export PIG_CLASSPATH = $HCAT_HOME/share/HCatalog/HCatalog-core*.jar:\ $HCAT_HOME/share/HCatalog/HCatalog-pig-adapter*.jar:\ $HIVE_HOME/lib/hive-metastore-*.jar:$HIVE_HOME/lib/libthrift-*.jar:\ $HIVE_HOME/lib/hive-exec-*.jar:$HIVE_HOME/lib/libfb303-*.jar:\ $HIVE_HOME/lib/jdo2-api-*-ec.jar:$HIVE_HOME/conf:$HADOOP_HOME/conf:\ $HIVE_HOME/lib/slf4j-api-*.jar
пример
Предположим, у нас есть файл student_details.txt в HDFS со следующим содержимым.
student_details.txt
001, Rajiv, Reddy, 21, 9848022337, Hyderabad 002, siddarth, Battacharya, 22, 9848022338, Kolkata 003, Rajesh, Khanna, 22, 9848022339, Delhi 004, Preethi, Agarwal, 21, 9848022330, Pune 005, Trupthi, Mohanthy, 23, 9848022336, Bhuwaneshwar 006, Archana, Mishra, 23, 9848022335, Chennai 007, Komal, Nayak, 24, 9848022334, trivendram 008, Bharathi, Nambiayar, 24, 9848022333, Chennai
У нас также есть пример сценария с именем sample_script.pig в том же каталоге HDFS. Этот файл содержит операторы, выполняющие операции и преобразования в отношении студента , как показано ниже.
student = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING
PigStorage(',') as (id:int, firstname:chararray, lastname:chararray,
phone:chararray, city:chararray);
student_order = ORDER student BY age DESC;
STORE student_order INTO 'student_order_table' USING org.apache.HCatalog.pig.HCatStorer();
student_limit = LIMIT student_order 4;
Dump student_limit;
-
Первая инструкция скрипта загрузит данные в файл student_details.txt в виде отношения с именем student .
-
Второе утверждение скрипта упорядочит кортежи отношения в порядке убывания в зависимости от возраста и сохранит его как student_order .
-
Третий оператор хранит обработанные данные результатов student_order в отдельной таблице с именем student_order_table .
-
Четвертое утверждение скрипта будет хранить первые четыре кортежа student_order как student_limit .
-
Наконец, пятое утверждение выведет содержимое отношения student_limit .
Первая инструкция скрипта загрузит данные в файл student_details.txt в виде отношения с именем student .
Второе утверждение скрипта упорядочит кортежи отношения в порядке убывания в зависимости от возраста и сохранит его как student_order .
Третий оператор хранит обработанные данные результатов student_order в отдельной таблице с именем student_order_table .
Четвертое утверждение скрипта будет хранить первые четыре кортежа student_order как student_limit .
Наконец, пятое утверждение выведет содержимое отношения student_limit .
Давайте теперь выполним пример sample_script.pig, как показано ниже.
$./pig -useHCatalog hdfs://localhost:9000/pig_data/sample_script.pig
Теперь проверьте выходной каталог (hdfs: user / tmp / hive) для вывода (part_0000, part_0001).