Apache Spark — Введение
Отрасли широко используют Hadoop для анализа своих наборов данных. Причина заключается в том, что платформа Hadoop основана на простой модели программирования (MapReduce) и обеспечивает масштабируемое, гибкое, отказоустойчивое и экономически эффективное вычислительное решение. Здесь основной задачей является поддержание скорости обработки больших наборов данных с точки зрения времени ожидания между запросами и времени ожидания для запуска программы.
Spark был представлен Apache Software Foundation для ускорения процесса вычислительных вычислений Hadoop.
В отличие от распространенного мнения, Spark не является модифицированной версией Hadoop и на самом деле не зависит от Hadoop, поскольку имеет собственное управление кластером. Hadoop — это только один из способов реализации Spark.
Spark использует Hadoop двумя способами: один — хранилище, а второй — обработка . Поскольку Spark имеет свои собственные вычисления управления кластером, он использует Hadoop только для целей хранения.
Apache Spark
Apache Spark — это молниеносная технология кластерных вычислений, предназначенная для быстрых вычислений. Он основан на Hadoop MapReduce и расширяет модель MapReduce, чтобы эффективно использовать ее для других типов вычислений, включая интерактивные запросы и потоковую обработку. Главной особенностью Spark являются кластерные вычисления в памяти, которые увеличивают скорость обработки приложения.
Spark предназначен для широкого спектра рабочих нагрузок, таких как пакетные приложения, итерационные алгоритмы, интерактивные запросы и потоковая передача. Помимо поддержки всех этих рабочих нагрузок в соответствующей системе, это снижает нагрузку на управление обслуживанием отдельных инструментов.
Эволюция Apache Spark
Spark — это один из подпроектов Hadoop, разработанный в 2009 году в AMPLab Калифорнийского университета в Беркли Матей Захария. Он был открыт в 2010 году по лицензии BSD. Он был пожертвован программному фонду Apache в 2013 году, и теперь Apache Spark стал проектом Apache высшего уровня с февраля 2014 года.
Особенности Apache Spark
Apache Spark имеет следующие особенности.
-
Скорость — Spark помогает запускать приложения в кластере Hadoop, до 100 раз быстрее в памяти и в 10 раз быстрее при работе на диске. Это возможно за счет уменьшения количества операций чтения / записи на диск. Он хранит промежуточные данные обработки в памяти.
-
Поддерживает несколько языков — Spark предоставляет встроенные API в Java, Scala или Python. Поэтому вы можете писать приложения на разных языках. Spark предлагает 80 высокоуровневых операторов для интерактивных запросов.
-
Расширенная аналитика — Spark поддерживает не только «Map» и «Reduce». Он также поддерживает запросы SQL, потоковые данные, машинное обучение (ML) и алгоритмы Graph.
Скорость — Spark помогает запускать приложения в кластере Hadoop, до 100 раз быстрее в памяти и в 10 раз быстрее при работе на диске. Это возможно за счет уменьшения количества операций чтения / записи на диск. Он хранит промежуточные данные обработки в памяти.
Поддерживает несколько языков — Spark предоставляет встроенные API в Java, Scala или Python. Поэтому вы можете писать приложения на разных языках. Spark предлагает 80 высокоуровневых операторов для интерактивных запросов.
Расширенная аналитика — Spark поддерживает не только «Map» и «Reduce». Он также поддерживает запросы SQL, потоковые данные, машинное обучение (ML) и алгоритмы Graph.
Искра, построенная на Hadoop
На следующей диаграмме показаны три способа построения Spark с использованием компонентов Hadoop.
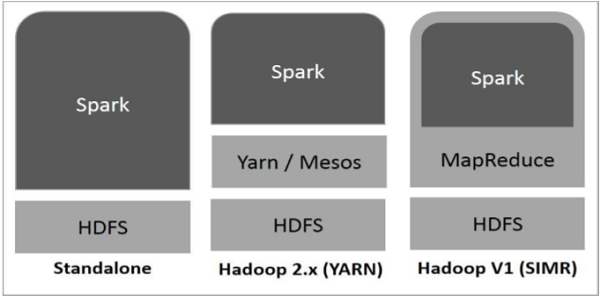
Существует три способа развертывания Spark, как описано ниже.
-
Автономное — Spark. Автономное развертывание означает, что Spark занимает место над HDFS (распределенной файловой системой Hadoop), а пространство явно выделяется для HDFS. Здесь Spark и MapReduce будут работать бок о бок, чтобы охватить все искровые задания в кластере.
-
Hadoop Yarn — Развертывание Hadoop Yarn означает, что искра работает на Yarn без предварительной установки или доступа с правами root. Это помогает интегрировать Spark в экосистему Hadoop или стек Hadoop. Это позволяет другим компонентам работать поверх стека.
-
Spark в MapReduce (SIMR) — Spark в MapReduce используется для запуска искрового задания в дополнение к автономному развертыванию. С SIMR пользователь может запустить Spark и использовать его оболочку без какого-либо административного доступа.
Автономное — Spark. Автономное развертывание означает, что Spark занимает место над HDFS (распределенной файловой системой Hadoop), а пространство явно выделяется для HDFS. Здесь Spark и MapReduce будут работать бок о бок, чтобы охватить все искровые задания в кластере.
Hadoop Yarn — Развертывание Hadoop Yarn означает, что искра работает на Yarn без предварительной установки или доступа с правами root. Это помогает интегрировать Spark в экосистему Hadoop или стек Hadoop. Это позволяет другим компонентам работать поверх стека.
Spark в MapReduce (SIMR) — Spark в MapReduce используется для запуска искрового задания в дополнение к автономному развертыванию. С SIMR пользователь может запустить Spark и использовать его оболочку без какого-либо административного доступа.
Компоненты искры
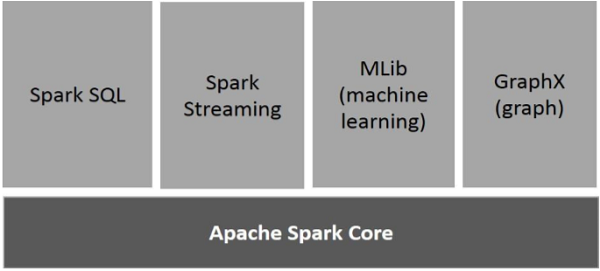
На следующем рисунке изображены различные компоненты Spark.
Apache Spark Core
Spark Core — основной движок общего исполнения для платформы spark, на котором построены все остальные функции. Он обеспечивает вычисления в памяти и ссылки на наборы данных во внешних системах хранения.
Spark SQL
Spark SQL — это компонент поверх Spark Core, который представляет новую абстракцию данных, называемую SchemaRDD, которая обеспечивает поддержку структурированных и полуструктурированных данных.
Spark Streaming
Spark Streaming использует возможность быстрого планирования Spark Core для выполнения потоковой аналитики. Он принимает данные в мини-пакетах и выполняет преобразования RDD (Resilient Distributed Datasets) для этих мини-пакетов данных.
MLlib (Библиотека машинного обучения)
MLlib является распределенной структурой машинного обучения выше Spark из-за распределенной архитектуры Spark на основе памяти. Согласно тестам, это делается разработчиками MLlib против реализаций Alternating Least Squares (ALS). Spark MLlib в девять раз быстрее, чем дисковая версия Apache Mahout для Hadoop (до того, как Mahout получил интерфейс Spark).
Graphx
GraphX - это распределенная среда обработки графов поверх Spark. Он предоставляет API для выражения вычислений графов, который может моделировать пользовательские графы с помощью API абстракции Pregel. Это также обеспечивает оптимизированное время выполнения для этой абстракции.
Апач Спарк — СДР
Эластичные распределенные наборы данных
Эластичные распределенные наборы данных (RDD) — это фундаментальная структура данных Spark. Это неизменяемая распределенная коллекция объектов. Каждый набор данных в RDD разделен на логические разделы, которые могут быть вычислены на разных узлах кластера. СДР могут содержать объекты Python, Java или Scala любого типа, включая определяемые пользователем классы.
Формально СДР — это секционированная коллекция записей только для чтения. СДР могут быть созданы с помощью детерминированных операций с данными в стабильном хранилище или с другими СДР. СДР — это отказоустойчивая совокупность элементов, которые могут работать параллельно.
Существует два способа создания RDD — распараллеливание существующей коллекции в вашей программе драйвера или обращение к набору данных во внешней системе хранения, такой как общая файловая система, HDFS, HBase или любой источник данных, предлагающий формат ввода Hadoop.
Spark использует концепцию RDD для достижения более быстрых и эффективных операций MapReduce. Давайте сначала обсудим, как происходят операции MapReduce и почему они не столь эффективны.
Обмен данными медленен в MapReduce
MapReduce широко используется для обработки и генерации больших наборов данных с параллельным распределенным алгоритмом в кластере. Это позволяет пользователям писать параллельные вычисления, используя набор операторов высокого уровня, не беспокоясь о распределении работы и отказоустойчивости.
К сожалению, в большинстве современных платформ единственный способ повторно использовать данные между вычислениями (например, между двумя заданиями MapReduce) — это записать их во внешнюю стабильную систему хранения (Ex-HDFS). Хотя эта структура предоставляет множество абстракций для доступа к вычислительным ресурсам кластера, пользователям все еще нужно больше.
Итеративные и интерактивные приложения требуют более быстрого обмена данными между параллельными заданиями. Обмен данными в MapReduce происходит медленно из-за репликации, сериализации и дискового ввода-вывода . Что касается системы хранения, большинства приложений Hadoop, они проводят более 90% времени, выполняя операции чтения-записи HDFS.
Итерационные операции на MapReduce
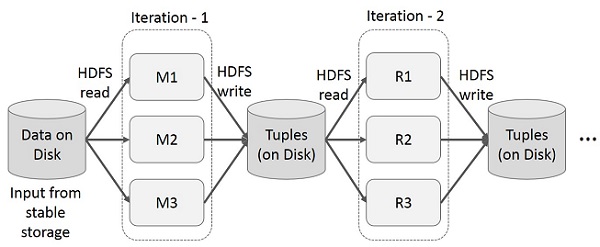
Повторное использование промежуточных результатов в нескольких вычислениях в многоэтапных приложениях. На следующем рисунке показано, как работает текущий каркас, выполняя итерационные операции над MapReduce. Это приводит к значительным накладным расходам из-за репликации данных, дискового ввода-вывода и сериализации, что замедляет работу системы.
Интерактивные операции на MapReduce
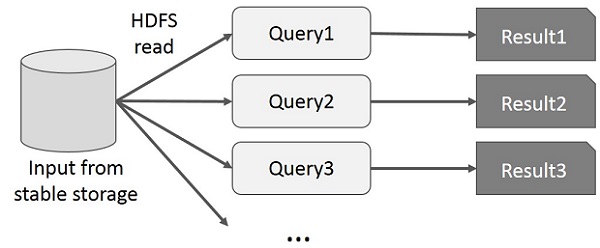
Пользователь запускает специальные запросы к одному и тому же подмножеству данных. Каждый запрос будет выполнять дисковый ввод-вывод в стабильном хранилище, что может влиять на время выполнения приложения.
На следующем рисунке показано, как работает текущая структура при выполнении интерактивных запросов в MapReduce.
Обмен данными с использованием Spark RDD
Обмен данными в MapReduce происходит медленно из-за репликации, сериализации и дискового ввода-вывода . Большинство приложений Hadoop тратят более 90% времени на операции чтения-записи HDFS.
Признавая эту проблему, исследователи разработали специализированную среду под названием Apache Spark. Ключевой идеей искры является R esilient D istributed D atasets (RDD); он поддерживает вычисления в памяти. Это означает, что он хранит состояние памяти как объект между заданиями, и объект разделяется между этими заданиями. Обмен данными в памяти в 10-100 раз быстрее, чем в сети и на диске.
Давайте теперь попробуем выяснить, как итеративные и интерактивные операции выполняются в Spark RDD.
Итерационные операции на Spark RDD
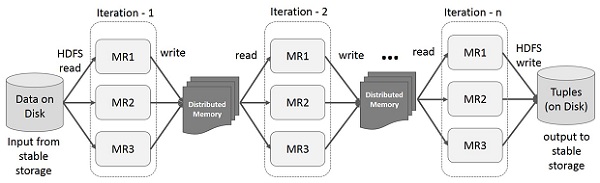
На приведенной ниже иллюстрации показаны итерационные операции на Spark RDD. Он будет хранить промежуточные результаты в распределенной памяти вместо стабильного хранилища (диска) и сделает систему быстрее.
Примечание. Если распределенной памяти (ОЗУ) достаточно для хранения промежуточных результатов (состояния задания), то эти результаты будут сохранены на диске.
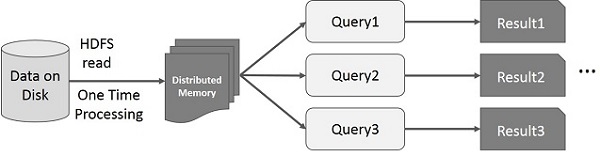
Интерактивные операции на Spark RDD
На этом рисунке показаны интерактивные операции на Spark RDD. Если разные запросы выполняются для одного и того же набора данных несколько раз, эти конкретные данные могут быть сохранены в памяти для лучшего времени выполнения.
По умолчанию каждый преобразованный СДР может пересчитываться каждый раз, когда вы выполняете над ним действие. Однако вы также можете сохранить RDD в памяти, и в этом случае Spark сохранит элементы в кластере для более быстрого доступа при следующем запросе. Существует также поддержка сохранения RDD на диске или репликации на нескольких узлах.
Apache Spark — Установка
Spark — это подпроект Hadoop. Поэтому лучше установить Spark в систему на основе Linux. Следующие шаги показывают, как установить Apache Spark.
Шаг 1. Проверка установки Java
Установка Java является одной из обязательных вещей при установке Spark. Попробуйте следующую команду, чтобы проверить версию JAVA.
$java -version
Если Java уже установлена в вашей системе, вы увидите следующий ответ:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если в вашей системе не установлена Java, то установите Java, прежде чем переходить к следующему шагу.
Шаг 2: Проверка установки Scala
Вам следует использовать язык Scala для реализации Spark. Итак, давайте проверим установку Scala с помощью следующей команды.
$scala -version
Если Scala уже установлен в вашей системе, вы увидите следующий ответ:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
Если в вашей системе не установлен Scala, перейдите к следующему шагу для установки Scala.
Шаг 3: Скачиваем Scala
Загрузите последнюю версию Scala, перейдя по следующей ссылке Скачать Scala . Для этого урока мы используем версию scala-2.11.6. После загрузки вы найдете tar-файл Scala в папке загрузки.
Шаг 4: Установка Scala
Следуйте приведенным ниже инструкциям для установки Scala.
Извлеките файл архива Scala
Введите следующую команду для распаковки tar-файла Scala.
$ tar xvf scala-2.11.6.tgz
Переместить файлы программного обеспечения Scala
Используйте следующие команды для перемещения файлов программного обеспечения Scala в соответствующий каталог (/ usr / local / scala) .
$ su – Password: # cd /home/Hadoop/Downloads/ # mv scala-2.11.6 /usr/local/scala # exit
Установить PATH для Scala
Используйте следующую команду для настройки PATH для Scala.
$ export PATH = $PATH:/usr/local/scala/bin
Проверка установки Scala
После установки лучше это проверить. Используйте следующую команду для проверки установки Scala.
$scala -version
Если Scala уже установлен в вашей системе, вы увидите следующий ответ:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
Шаг 5: Загрузка Apache Spark
Загрузите последнюю версию Spark, перейдя по следующей ссылке Скачать Spark . Для этого урока мы используем версию spark-1.3.1-bin-hadoop2.6 . После загрузки вы найдете файл Spark tar в папке загрузки.
Шаг 6: Установка Spark
Следуйте приведенным ниже инструкциям для установки Spark.
Извлечение Spark смолы
Следующая команда для извлечения файла spark tar.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgz
Перемещение файлов программного обеспечения Spark
Следующие команды для перемещения файлов программного обеспечения Spark в соответствующий каталог (/ usr / local / spark) .
$ su – Password: # cd /home/Hadoop/Downloads/ # mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark # exit
Настройка среды для Spark
Добавьте следующую строку в файл ~ /.bashrc . Это означает добавление места, где находится файл программного обеспечения искры, в переменную PATH.
export PATH=$PATH:/usr/local/spark/bin
Используйте следующую команду для поиска файла ~ / .bashrc.
$ source ~/.bashrc
Шаг 7: Проверка установки Spark
Напишите следующую команду для открытия оболочки Spark.
$spark-shell
Если искра установлена успешно, вы найдете следующий вывод.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
Apache Spark — основное программирование
Spark Core — основа всего проекта. Он обеспечивает распределенную диспетчеризацию задач, планирование и основные функции ввода / вывода. Spark использует специализированную фундаментальную структуру данных, известную как RDD (Resilient Distributed Datasets), которая представляет собой логический набор данных, распределенных по компьютерам. СДР могут быть созданы двумя способами; один из них — ссылка на наборы данных во внешних системах хранения, а второй — применение преобразований (например, map, filter, reducer, join) к существующим RDD.
Абстракция RDD предоставляется через встроенный в язык API. Это упрощает сложность программирования, потому что способ, которым приложения манипулируют RDD, подобен манипулированию локальными коллекциями данных.
Spark Shell
Spark предоставляет интерактивную оболочку — мощный инструмент для интерактивного анализа данных. Он доступен на языке Scala или Python. Основная абстракция Spark — это распределенная коллекция элементов, называемая Resilient Distributed Dataset (RDD). СДР могут быть созданы из входных форматов Hadoop (например, файлов HDFS) или путем преобразования других СДР.
Open Spark Shell
Следующая команда используется для открытия оболочки Spark.
$ spark-shell
Создать простую СДР
Давайте создадим простой RDD из текстового файла. Используйте следующую команду для создания простого СДР.
scala> val inputfile = sc.textFile(“input.txt”)
Выход для вышеуказанной команды
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12
Spark RDD API вводит несколько трансформаций и несколько действий для управления RDD.
Преобразования СДР
Преобразования RDD возвращают указатель на новый RDD и позволяют создавать зависимости между RDD. Каждый RDD в цепочке зависимостей (String of Dependencies) имеет функцию для вычисления своих данных и имеет указатель (зависимость) на свой родительский RDD.
Spark ленив, поэтому ничего не будет выполнено, если вы не вызовете какое-либо преобразование или действие, которое вызовет создание и выполнение задания. Посмотрите на следующий фрагмент примера подсчета слов.
Следовательно, преобразование СДР — это не набор данных, а шаг в программе (может быть, единственный шаг), в котором говорится Spark, как получать данные и что с ними делать.
| S.No | Трансформации и смысл |
|---|---|
| 1 |
карта (FUNC) Возвращает новый распределенный набор данных, сформированный путем передачи каждого элемента источника через функцию func . |
| 2 |
фильтр (FUNC) Возвращает новый набор данных, сформированный путем выбора тех элементов источника, для которых func возвращает true. |
| 3 |
flatMap (FUNC) Аналогично map, но каждый входной элемент может быть сопоставлен с 0 или более выходными элементами (поэтому func должен возвращать Seq, а не один элемент). |
| 4 |
mapPartitions (FUNC) Аналогично map, но запускается отдельно на каждом разделе (блоке) RDD, поэтому func должен иметь тип Iterator <T> ⇒ Iterator <U> при работе на RDD типа T. |
| 5 |
mapPartitionsWithIndex (FUNC) Аналогично разделам карты, но также предоставляет func целочисленное значение, представляющее индекс раздела, поэтому func должен иметь тип (Int, Iterator <T>) ⇒ Iterator <U> при работе на RDD типа T. |
| 6 |
образец (с заменой, дробью, семенами) Выборка части данных с заменой или без нее с использованием заданного начального числа генератора случайных чисел. |
| 7 |
союз (otherDataset) Возвращает новый набор данных, который содержит объединение элементов в исходном наборе данных и аргумент. |
| 8 |
Пересечение (otherDataset) Возвращает новый RDD, содержащий пересечение элементов в наборе исходных данных и аргумента. |
| 9 |
различны ([numTasks]) Возвращает новый набор данных, который содержит отдельные элементы исходного набора данных. |
| 10 |
groupByKey ([numTasks]) При вызове из набора данных (K, V) пар возвращает набор данных из (K, Iterable <V>) пар. Примечание. Если вы группируете данные для выполнения агрегации (например, суммы или среднего значения) по каждому ключу, то при использовании lowerByKey или aggregateByKey производительность будет значительно выше. |
| 11 |
reduByKey (func, [numTasks]) При вызове набора данных из пар (K, V) возвращает набор данных из пар (K, V), в которых значения для каждого ключа агрегируются с использованием заданной функции функции сокращения, которая должна иметь тип (V, V) ⇒ V Как и в groupByKey, число задач сокращения настраивается через необязательный второй аргумент. |
| 12 |
aggregateByKey (zeroValue) (seqOp, combOp, [numTasks]) При вызове набора данных из пар (K, V) возвращает набор данных из пар (K, U), в которых значения для каждого ключа агрегируются с использованием заданных функций объединения и нейтрального «нулевого» значения. Позволяет тип агрегированного значения, который отличается от типа входного значения, избегая ненужных распределений. Как и в groupByKey, число задач сокращения настраивается через необязательный второй аргумент. |
| 13 |
sortByKey ([по возрастанию], [numTasks]) При вызове набора данных из пар (K, V), где K реализует Ordered, возвращает набор данных из пар (K, V), отсортированных по ключам в порядке возрастания или убывания, как указано в логическом аргументе возрастания. |
| 14 |
присоединиться (otherDataset, [numTasks]) При вызове наборов данных типа (K, V) и (K, W) возвращает набор данных из (K, (V, W)) пар со всеми парами элементов для каждого ключа. Внешние объединения поддерживаются с помощью leftOuterJoin, rightOuterJoin и fullOuterJoin. |
| 15 |
cogroup (otherDataset, [numTasks]) При вызове наборов данных типа (K, V) и (K, W) возвращает набор данных из (K, (Iterable <V>, Iterable <W>))). Эта операция также называется группой С. |
| 16 |
декартовы (otherDataset) При вызове наборов данных типов T и U возвращает набор данных из (T, U) пар (всех пар элементов). |
| 17 |
труба (команда, [envVars]) Передайте каждый раздел RDD с помощью команды оболочки, например, Perl или bash. Элементы RDD записываются в stdin процесса, а строки, выводимые в его stdout, возвращаются как RDD строк. |
| 18 |
коалесценции (numPartitions) Уменьшите количество разделов в СДР до numPartitions. Полезно для более эффективного выполнения операций после фильтрации большого набора данных. |
| 19 |
передел (numPartitions) Произвольно переставьте данные в RDD, чтобы создать больше или меньше разделов и распределить их по ним. Это всегда перетасовывает все данные по сети. |
| 20 |
repartitionAndSortWithinPartitions (разметки) Разделите СДР в соответствии с указанным разделителем и в каждом полученном разделе сортируйте записи по их ключам. Это более эффективно, чем вызывать перераспределение и последующую сортировку внутри каждого раздела, потому что это может толкнуть сортировку вниз в механизм перемешивания. |
карта (FUNC)
Возвращает новый распределенный набор данных, сформированный путем передачи каждого элемента источника через функцию func .
фильтр (FUNC)
Возвращает новый набор данных, сформированный путем выбора тех элементов источника, для которых func возвращает true.
flatMap (FUNC)
Аналогично map, но каждый входной элемент может быть сопоставлен с 0 или более выходными элементами (поэтому func должен возвращать Seq, а не один элемент).
mapPartitions (FUNC)
Аналогично map, но запускается отдельно на каждом разделе (блоке) RDD, поэтому func должен иметь тип Iterator <T> ⇒ Iterator <U> при работе на RDD типа T.
mapPartitionsWithIndex (FUNC)
Аналогично разделам карты, но также предоставляет func целочисленное значение, представляющее индекс раздела, поэтому func должен иметь тип (Int, Iterator <T>) ⇒ Iterator <U> при работе на RDD типа T.
образец (с заменой, дробью, семенами)
Выборка части данных с заменой или без нее с использованием заданного начального числа генератора случайных чисел.
союз (otherDataset)
Возвращает новый набор данных, который содержит объединение элементов в исходном наборе данных и аргумент.
Пересечение (otherDataset)
Возвращает новый RDD, содержащий пересечение элементов в наборе исходных данных и аргумента.
различны ([numTasks])
Возвращает новый набор данных, который содержит отдельные элементы исходного набора данных.
groupByKey ([numTasks])
При вызове из набора данных (K, V) пар возвращает набор данных из (K, Iterable <V>) пар.
Примечание. Если вы группируете данные для выполнения агрегации (например, суммы или среднего значения) по каждому ключу, то при использовании lowerByKey или aggregateByKey производительность будет значительно выше.
reduByKey (func, [numTasks])
При вызове набора данных из пар (K, V) возвращает набор данных из пар (K, V), в которых значения для каждого ключа агрегируются с использованием заданной функции функции сокращения, которая должна иметь тип (V, V) ⇒ V Как и в groupByKey, число задач сокращения настраивается через необязательный второй аргумент.
aggregateByKey (zeroValue) (seqOp, combOp, [numTasks])
При вызове набора данных из пар (K, V) возвращает набор данных из пар (K, U), в которых значения для каждого ключа агрегируются с использованием заданных функций объединения и нейтрального «нулевого» значения. Позволяет тип агрегированного значения, который отличается от типа входного значения, избегая ненужных распределений. Как и в groupByKey, число задач сокращения настраивается через необязательный второй аргумент.
sortByKey ([по возрастанию], [numTasks])
При вызове набора данных из пар (K, V), где K реализует Ordered, возвращает набор данных из пар (K, V), отсортированных по ключам в порядке возрастания или убывания, как указано в логическом аргументе возрастания.
присоединиться (otherDataset, [numTasks])
При вызове наборов данных типа (K, V) и (K, W) возвращает набор данных из (K, (V, W)) пар со всеми парами элементов для каждого ключа. Внешние объединения поддерживаются с помощью leftOuterJoin, rightOuterJoin и fullOuterJoin.
cogroup (otherDataset, [numTasks])
При вызове наборов данных типа (K, V) и (K, W) возвращает набор данных из (K, (Iterable <V>, Iterable <W>))). Эта операция также называется группой С.
декартовы (otherDataset)
При вызове наборов данных типов T и U возвращает набор данных из (T, U) пар (всех пар элементов).
труба (команда, [envVars])
Передайте каждый раздел RDD с помощью команды оболочки, например, Perl или bash. Элементы RDD записываются в stdin процесса, а строки, выводимые в его stdout, возвращаются как RDD строк.
коалесценции (numPartitions)
Уменьшите количество разделов в СДР до numPartitions. Полезно для более эффективного выполнения операций после фильтрации большого набора данных.
передел (numPartitions)
Произвольно переставьте данные в RDD, чтобы создать больше или меньше разделов и распределить их по ним. Это всегда перетасовывает все данные по сети.
repartitionAndSortWithinPartitions (разметки)
Разделите СДР в соответствии с указанным разделителем и в каждом полученном разделе сортируйте записи по их ключам. Это более эффективно, чем вызывать перераспределение и последующую сортировку внутри каждого раздела, потому что это может толкнуть сортировку вниз в механизм перемешивания.
действия
| S.No | Действие и смысл |
|---|---|
| 1 |
уменьшить (FUNC) Агрегируйте элементы набора данных с помощью функции func (которая принимает два аргумента и возвращает один). Функция должна быть коммутативной и ассоциативной, чтобы ее можно было правильно вычислить параллельно. |
| 2 |
собирать () Возвращает все элементы набора данных в виде массива в программе драйвера. Это обычно полезно после фильтра или другой операции, которая возвращает достаточно маленькое подмножество данных. |
| 3 |
кол — () Возвращает количество элементов в наборе данных. |
| 4 |
первый() Возвращает первый элемент набора данных (аналогично take (1)). |
| 5 |
принять (п) Возвращает массив с первыми n элементами набора данных. |
| 6 |
takeSample (withReplacement, num, [seed]) Возвращает массив со случайной выборкой из num элементов набора данных с заменой или без нее, при желании предварительно указав начальное число генератора случайных чисел. |
| 7 |
takeOrdered (n, [ordering]) Возвращает первые n элементов СДР, используя их естественный порядок или пользовательский компаратор. |
| 8 |
saveAsTextFile (путь) Записывает элементы набора данных в виде текстового файла (или набора текстовых файлов) в заданный каталог в локальной файловой системе, HDFS или любой другой файловой системе, поддерживаемой Hadoop. Spark вызывает toString для каждого элемента, чтобы преобразовать его в строку текста в файле. |
| 9 |
saveAsSequenceFile (путь) (Java и Scala) Записывает элементы набора данных в виде файла последовательности Hadoop по заданному пути в локальной файловой системе, HDFS или любой другой файловой системе, поддерживаемой Hadoop. Это доступно для RDD пар ключ-значение, которые реализуют интерфейс Hadoop с возможностью записи. В Scala он также доступен для типов, которые неявно преобразуются в Writable (Spark включает преобразования для базовых типов, таких как Int, Double, String и т. Д.). |
| 10 |
saveAsObjectFile (путь) (Java и Scala) Записывает элементы набора данных в простом формате, используя сериализацию Java, которую затем можно загрузить с помощью SparkContext.objectFile (). |
| 11 |
countByKey () Доступно только для RDD типа (K, V). Возвращает хэш-карту (K, Int) пар с количеством каждого ключа. |
| 12 |
Еогеасп (FUNC) Запускает функцию func для каждого элемента набора данных. Обычно это делается для побочных эффектов, таких как обновление Аккумулятора или взаимодействие с внешними системами хранения. Примечание. Изменение переменных, отличных от Accumulators, за пределами foreach () может привести к неопределенному поведению. См. Понимание замыканий для более подробной информации. |
уменьшить (FUNC)
Агрегируйте элементы набора данных с помощью функции func (которая принимает два аргумента и возвращает один). Функция должна быть коммутативной и ассоциативной, чтобы ее можно было правильно вычислить параллельно.
собирать ()
Возвращает все элементы набора данных в виде массива в программе драйвера. Это обычно полезно после фильтра или другой операции, которая возвращает достаточно маленькое подмножество данных.
кол — ()
Возвращает количество элементов в наборе данных.
первый()
Возвращает первый элемент набора данных (аналогично take (1)).
принять (п)
Возвращает массив с первыми n элементами набора данных.
takeSample (withReplacement, num, [seed])
Возвращает массив со случайной выборкой из num элементов набора данных с заменой или без нее, при желании предварительно указав начальное число генератора случайных чисел.
takeOrdered (n, [ordering])
Возвращает первые n элементов СДР, используя их естественный порядок или пользовательский компаратор.
saveAsTextFile (путь)
Записывает элементы набора данных в виде текстового файла (или набора текстовых файлов) в заданный каталог в локальной файловой системе, HDFS или любой другой файловой системе, поддерживаемой Hadoop. Spark вызывает toString для каждого элемента, чтобы преобразовать его в строку текста в файле.
saveAsSequenceFile (путь) (Java и Scala)
Записывает элементы набора данных в виде файла последовательности Hadoop по заданному пути в локальной файловой системе, HDFS или любой другой файловой системе, поддерживаемой Hadoop. Это доступно для RDD пар ключ-значение, которые реализуют интерфейс Hadoop с возможностью записи. В Scala он также доступен для типов, которые неявно преобразуются в Writable (Spark включает преобразования для базовых типов, таких как Int, Double, String и т. Д.).
saveAsObjectFile (путь) (Java и Scala)
Записывает элементы набора данных в простом формате, используя сериализацию Java, которую затем можно загрузить с помощью SparkContext.objectFile ().
countByKey ()
Доступно только для RDD типа (K, V). Возвращает хэш-карту (K, Int) пар с количеством каждого ключа.
Еогеасп (FUNC)
Запускает функцию func для каждого элемента набора данных. Обычно это делается для побочных эффектов, таких как обновление Аккумулятора или взаимодействие с внешними системами хранения.
Примечание. Изменение переменных, отличных от Accumulators, за пределами foreach () может привести к неопределенному поведению. См. Понимание замыканий для более подробной информации.
Программирование с помощью RDD
Давайте рассмотрим реализации нескольких преобразований и действий RDD в программировании RDD на примере.
пример
Рассмотрим пример подсчета слов — он подсчитывает каждое слово, встречающееся в документе. Рассмотрим следующий текст в качестве входных данных и сохраняем как файл input.txt в домашнем каталоге.
input.txt — входной файл.
people are not as beautiful as they look, as they walk or as they talk. they are only as beautiful as they love, as they care as they share.
Следуйте процедуре, приведенной ниже, чтобы выполнить данный пример.
Открытый Spark-Shell
Следующая команда используется для открытия искровой оболочки. Как правило, искра строится с использованием Scala. Поэтому программа Spark работает в среде Scala.
$ spark-shell
Если оболочка Spark открывается успешно, вы найдете следующий вывод. Посмотрите на последнюю строку вывода «Контекст Spark, доступный как sc» означает, что контейнер Spark автоматически создает объект контекста spark с именем sc . Перед началом первого шага программы должен быть создан объект SparkContext.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
Создать СДР
Сначала мы должны прочитать входной файл с помощью Spark-Scala API и создать RDD.
Следующая команда используется для чтения файла из заданного местоположения. Здесь создается новый RDD с именем inputfile. String, заданная в качестве аргумента в методе textFile («»), является абсолютным путем к имени входного файла. Однако если указано только имя файла, это означает, что входной файл находится в текущем местоположении.
scala> val inputfile = sc.textFile("input.txt")
Выполнить преобразование количества слов
Наша цель — посчитать слова в файле. Создайте плоскую карту для разбиения каждой строки на слова ( flatMap (строка ⇒ line.split («») ).
Затем прочитайте каждое слово как ключ со значением ‘1’ (<ключ, значение> = <слово, 1>), используя функцию карты (карта (слово ⇒ (слово, 1) ).
Наконец, уменьшите эти ключи, добавив значения похожих ключей ( reduByKey (_ + _) ).
Следующая команда используется для выполнения логики подсчета слов. После выполнения этого вы не найдете никаких выходных данных, потому что это не действие, а преобразование; указывать новый RDD или сообщать искре, что делать с данными данными)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);
Текущий СДР
При работе с RDD, если вы хотите узнать о текущем RDD, используйте следующую команду. Он покажет вам описание текущего RDD и его зависимостей для отладки.
scala> counts.toDebugString
Кэширование трансформаций
Вы можете пометить СДР как сохраняемый с помощью методов persist () или cache (). При первом вычислении в действии оно будет храниться в памяти узлов. Используйте следующую команду, чтобы сохранить промежуточные преобразования в памяти.
scala> counts.cache()
Применяя действие
Применение действия, такого как сохранение всех преобразований, приводит к созданию текстового файла. Аргумент String для метода saveAsTextFile («») — это абсолютный путь к выходной папке. Попробуйте следующую команду, чтобы сохранить вывод в текстовом файле. В следующем примере папка «output» находится в текущем местоположении.
scala> counts.saveAsTextFile("output")
Проверка вывода
Откройте другой терминал, чтобы перейти в домашнюю директорию (где в другом терминале выполняется искра). Используйте следующие команды для проверки выходного каталога.
[hadoop@localhost ~]$ cd output/ [hadoop@localhost output]$ ls -1 part-00000 part-00001 _SUCCESS
Следующая команда используется для просмотра выходных данных из файлов Part-00000 .
[hadoop@localhost output]$ cat part-00000
Выход
(people,1) (are,2) (not,1) (as,8) (beautiful,2) (they, 7) (look,1)
Следующая команда используется для просмотра выходных данных из файлов Part-00001 .
[hadoop@localhost output]$ cat part-00001
Выход
(walk, 1) (or, 1) (talk, 1) (only, 1) (love, 1) (care, 1) (share, 1)
ООН сохранит хранилище
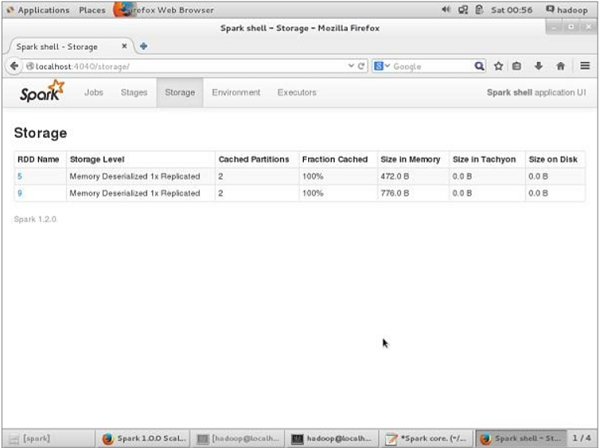
Перед тем как UN-persisting, если вы хотите увидеть место для хранения, которое используется для этого приложения, используйте следующий URL в вашем браузере.
http://localhost:4040
Вы увидите следующий экран, который показывает объем памяти, используемый для приложения, которое выполняется в оболочке Spark.
Если вы хотите, чтобы UN-persist хранилище определенного RDD не использовалось, используйте следующую команду.
Scala> counts.unpersist()
Вы увидите вывод следующим образом —
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list 15/06/27 00:57:33 INFO BlockManager: Removing RDD 9 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810) 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106) res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14
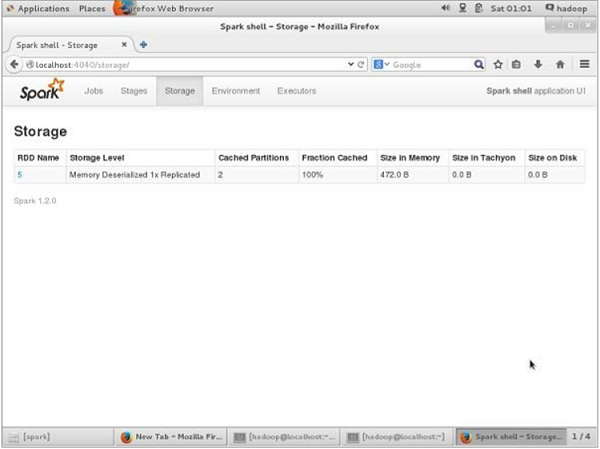
Для проверки места в браузере используйте следующий URL.
http://localhost:4040/
Вы увидите следующий экран. Он показывает объем памяти, используемый для приложения, которое выполняется в оболочке Spark.
Apache Spark — Развертывание
Приложение Spark, использующее spark-submit, — это команда оболочки, используемая для развертывания приложения Spark в кластере. Он использует все соответствующие менеджеры кластеров через единый интерфейс. Следовательно, вам не нужно настраивать приложение для каждого из них.
пример
Давайте возьмем тот же пример подсчета слов, который мы использовали ранее, используя команды оболочки. Здесь мы рассмотрим тот же пример в качестве искрового приложения.
Пример ввода
Следующий текст представляет собой входные данные, и файл с именем находится в .txt .
people are not as beautiful as they look, as they walk or as they talk. they are only as beautiful as they love, as they care as they share.
Посмотрите на следующую программу —
SparkWordCount.scala
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark._ object SparkWordCount { def main(args: Array[String]) { val sc = new SparkContext( "local", "Word Count", "/usr/local/spark", Nil, Map(), Map()) /* local = master URL; Word Count = application name; */ /* /usr/local/spark = Spark Home; Nil = jars; Map = environment */ /* Map = variables to work nodes */ /*creating an inputRDD to read text file (in.txt) through Spark context*/ val input = sc.textFile("in.txt") /* Transform the inputRDD into countRDD */ val count = input.flatMap(line ⇒ line.split(" ")) .map(word ⇒ (word, 1)) .reduceByKey(_ + _) /* saveAsTextFile method is an action that effects on the RDD */ count.saveAsTextFile("outfile") System.out.println("OK"); } }
Сохраните вышеуказанную программу в файл с именем SparkWordCount.scala и поместите его в пользовательский каталог с именем spark-application .
Примечание. При преобразовании inputRDD в countRDD мы используем flatMap () для токенизации строк (из текстового файла) в слова, метод map () для подсчета частоты слова и метод reduByKey () для подсчета каждого повторения слова.
Используйте следующие шаги, чтобы отправить эту заявку. Выполните все шаги в каталоге spark-application через терминал.
Шаг 1: Загрузите Spark Ja
Для компиляции необходим jar ядра Spark, поэтому загрузите spark-core_2.10-1.3.0.jar по следующей ссылке Spar core jar и переместите файл jar из каталога загрузки в каталог spark-application .
Шаг 2: Скомпилируйте программу
Скомпилируйте вышеуказанную программу, используя команду, приведенную ниже. Эта команда должна быть выполнена из каталога spark-application. Здесь /usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar — это jar поддержки Hadoop, взятый из библиотеки Spark.
$ scalac -classpath "spark-core_2.10-1.3.0.jar:/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar" SparkPi.scala
Шаг 3: Создайте JAR
Создайте jar-файл приложения spark, используя следующую команду. Здесь wordcount — это имя файла для jar-файла.
jar -cvf wordcount.jar SparkWordCount*.class spark-core_2.10-1.3.0.jar/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar
Шаг 4: Отправить искру
Отправьте приложение spark, используя следующую команду —
spark-submit --class SparkWordCount --master local wordcount.jar
Если он выполнен успешно, вы найдете вывод, приведенный ниже. ОК, пропускающий следующий вывод, предназначен для идентификации пользователя, и это последняя строка программы. Если вы внимательно прочитаете следующий вывод, вы найдете разные вещи, такие как —
- успешно запущен сервис ‘sparkDriver’ на порту 42954
- MemoryStore запущен с объемом 267,3 МБ
- Запущен SparkUI по адресу http://192.168.1.217:4040
- Добавлен JAR-файл: /home/hadoop/piapplication/count.jar
- ResultStage 1 (saveAsTextFile в SparkPi.scala: 11) завершился за 0,566 с
- Остановлен веб-интерфейс Spark на http://192.168.1.217:4040
- MemoryStore очищен
15/07/08 13:56:04 INFO Slf4jLogger: Slf4jLogger started 15/07/08 13:56:04 INFO Utils: Successfully started service 'sparkDriver' on port 42954. 15/07/08 13:56:04 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.1.217:42954] 15/07/08 13:56:04 INFO MemoryStore: MemoryStore started with capacity 267.3 MB 15/07/08 13:56:05 INFO HttpServer: Starting HTTP Server 15/07/08 13:56:05 INFO Utils: Successfully started service 'HTTP file server' on port 56707. 15/07/08 13:56:06 INFO SparkUI: Started SparkUI at http://192.168.1.217:4040 15/07/08 13:56:07 INFO SparkContext: Added JAR file:/home/hadoop/piapplication/count.jar at http://192.168.1.217:56707/jars/count.jar with timestamp 1436343967029 15/07/08 13:56:11 INFO Executor: Adding file:/tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af/userFiles-df4f4c20-a368-4cdd-a2a7-39ed45eb30cf/count.jar to class loader 15/07/08 13:56:11 INFO HadoopRDD: Input split: file:/home/hadoop/piapplication/in.txt:0+54 15/07/08 13:56:12 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2001 bytes result sent to driver (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11), which is now runnable 15/07/08 13:56:12 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11) 15/07/08 13:56:13 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at SparkPi.scala:11) finished in 0.566 s 15/07/08 13:56:13 INFO DAGScheduler: Job 0 finished: saveAsTextFile at SparkPi.scala:11, took 2.892996 s OK 15/07/08 13:56:13 INFO SparkContext: Invoking stop() from shutdown hook 15/07/08 13:56:13 INFO SparkUI: Stopped Spark web UI at http://192.168.1.217:4040 15/07/08 13:56:13 INFO DAGScheduler: Stopping DAGScheduler 15/07/08 13:56:14 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 15/07/08 13:56:14 INFO Utils: path = /tmp/spark-45a07b83-42ed-42b3-b2c2823d8d99c5af/blockmgr-ccdda9e3-24f6-491b-b509-3d15a9e05818, already present as root for deletion. 15/07/08 13:56:14 INFO MemoryStore: MemoryStore cleared 15/07/08 13:56:14 INFO BlockManager: BlockManager stopped 15/07/08 13:56:14 INFO BlockManagerMaster: BlockManagerMaster stopped 15/07/08 13:56:14 INFO SparkContext: Successfully stopped SparkContext 15/07/08 13:56:14 INFO Utils: Shutdown hook called 15/07/08 13:56:14 INFO Utils: Deleting directory /tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af 15/07/08 13:56:14 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
Шаг 5: Проверка вывода
После успешного выполнения программы вы найдете каталог с именем outfile в каталоге spark-application.
Следующие команды используются для открытия и проверки списка файлов в каталоге outfile.
$ cd outfile $ ls Part-00000 part-00001 _SUCCESS
Команды для проверки вывода в файле part-00000 :
$ cat part-00000 (people,1) (are,2) (not,1) (as,8) (beautiful,2) (they, 7) (look,1)
Команды для проверки вывода в файле part-00001:
$ cat part-00001 (walk, 1) (or, 1) (talk, 1) (only, 1) (love, 1) (care, 1) (share, 1)
Просмотрите следующий раздел, чтобы узнать больше о команде «spark-submit».
Синтаксис Spark-submit
spark-submit [options] <app jar | python file> [app arguments]
Опции
| S.No | вариант | Описание |
|---|---|---|
| 1 | —мастер | spark: // хост: порт, mesos: // хост: порт, пряжа или локальный. |
| 2 | —deploy-режим | Запустить ли драйверную программу локально («клиент») или на одной из рабочих машин внутри кластера («кластер») (по умолчанию: клиент). |
| 3 | —учебный класс | Основной класс вашего приложения (для приложений Java / Scala). |
| 4 | —название | Название вашей заявки. |
| 5 | —jars | Разделенный запятыми список локальных jar-файлов для включения в путь к классу драйвера и исполнителя. |
| 6 | —packages | Разделенный запятыми список maven координат jar для включения в classpath драйвера и исполнителя. |
| 7 | —repositories | Разделенный запятыми список дополнительных удаленных репозиториев для поиска maven координат, заданных с помощью —packages. |
| 8 | —py-файлы | Разделенный запятыми список файлов .zip, .egg или .py для размещения в PYTHON PATH для приложений Python. |
| 9 | —files | Разделенный запятыми список файлов для размещения в рабочем каталоге каждого исполнителя. |
| 10 | —conf (prop = val) | Произвольное свойство конфигурации Spark. |
| 11 | —properties-файл | Путь к файлу для загрузки дополнительных свойств. Если не указано, это будет искать conf / spark-defaults. |
| 12 | —driver-память | Память для драйвера (например, 1000M, 2G) (по умолчанию: 512M). |
| 13 | —driver-ява-варианты | Дополнительные параметры Java для передачи драйверу. |
| 14 | —driver библиотека-путь | Дополнительные записи пути к библиотеке для передачи драйверу. |
| 15 | —driver-класс-путь |
Дополнительные записи пути к классу для передачи драйверу. Обратите внимание, что фляги, добавленные с помощью —jars, автоматически включаются в путь к классам. |
| 16 | —executor-память | Память на исполнителя (например, 1000M, 2G) (по умолчанию: 1G). |
| 17 | —proxy пользователь | Пользователь подражает при подаче заявки. |
| 18 | — Помогите -h | Показать это справочное сообщение и выйти. |
| 19 | —verbose, -v | Распечатать дополнительный отладочный вывод. |
| 20 | —версия | Распечатать версию текущей Spark. |
| 21 | —driver-cores NUM | Ядра для водителя (по умолчанию: 1). |
| 22 | —supervise | Если дано, перезапускает драйвер при сбое. |
| 23 | —убийство | Если дано, убивает указанного водителя. |
| 24 | —статус | Если дано, запрашивает статус указанного драйвера. |
| 25 | —total-исполнитель-сердечники | Всего ядер для всех исполнителей. |
| 26 | —executor-сердечники | Количество ядер на исполнителя. (По умолчанию: 1 в режиме YARN или все доступные ядра на рабочем в автономном режиме). |
Дополнительные записи пути к классу для передачи драйверу.
Обратите внимание, что фляги, добавленные с помощью —jars, автоматически включаются в путь к классам.
Расширенное программирование искр
Spark содержит два разных типа общих переменных: один — широковещательные переменные, а второй — аккумуляторы .
-
Широковещательные переменные — используются для эффективного распределения больших значений.
-
Аккумуляторы — используются для сбора информации определенного сбора.
Широковещательные переменные — используются для эффективного распределения больших значений.
Аккумуляторы — используются для сбора информации определенного сбора.
Переменные трансляции
Широковещательные переменные позволяют программисту хранить переменную только для чтения в кэше на каждом компьютере, а не отправлять ее копию с задачами. Их можно использовать, например, для эффективного предоставления каждому узлу копии большого входного набора данных. Spark также пытается распределить переменные вещания, используя эффективные алгоритмы вещания, чтобы снизить стоимость связи.
Действия Spark выполняются через набор этапов, разделенных распределенными «случайными» операциями. Spark автоматически передает общие данные, необходимые для задач на каждом этапе.
Передаваемые таким образом данные кэшируются в сериализованной форме и десериализуются перед выполнением каждой задачи. Это означает, что явное создание широковещательных переменных полезно только тогда, когда для задач на нескольких этапах требуются одни и те же данные или когда важно кэширование данных в десериализованной форме.
Переменные широковещания создаются из переменной v с помощью вызова SparkContext.broadcast (v) . Переменная широковещания является оберткой вокруг v , и к ее значению можно обратиться, вызвав метод value . Код, приведенный ниже, показывает это —
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
Выход —
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
После создания широковещательной переменной ее следует использовать вместо значения v в любых функциях, выполняемых в кластере, чтобы v не отправлялось на узлы более одного раза. Кроме того, объект v не должен изменяться после его широковещания, чтобы гарантировать, что все узлы получают одинаковое значение широковещательной переменной.
Аккумуляторы
Аккумуляторы — это переменные, которые «добавляются» только через ассоциативную операцию и поэтому могут эффективно поддерживаться параллельно. Их можно использовать для реализации счетчиков (как в MapReduce) или сумм. Spark изначально поддерживает аккумуляторы числовых типов, и программисты могут добавлять поддержку новых типов. Если аккумуляторы созданы с именем, они будут отображаться в пользовательском интерфейсе Spark . Это может быть полезно для понимания хода выполнения этапов (ПРИМЕЧАНИЕ. Это еще не поддерживается в Python).
Аккумулятор создается из начального значения v путем вызова SparkContext.accumulator (v) . Задачи, работающие в кластере, могут затем добавить его, используя метод add или оператор + = (в Scala и Python). Тем не менее, они не могут прочитать его значение. Только программа драйвера может прочитать значение аккумулятора, используя метод его значения .
Код, приведенный ниже, показывает аккумулятор, который используется для сложения элементов массива —
scala> val accum = sc.accumulator(0) scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
Если вы хотите увидеть вывод кода выше, используйте следующую команду —
scala> accum.value
Выход
res2: Int = 10
Числовые операции RDD
Spark позволяет выполнять различные операции с числовыми данными, используя один из предопределенных методов API. Числовые операции Spark реализованы с помощью потокового алгоритма, который позволяет строить модель по одному элементу за раз.
Эти операции вычисляются и возвращаются как объект StatusCounter путем вызова метода status () .
| S.No | Методы и смысл |
|---|---|
| 1 |
кол — () Количество элементов в СДР. |
| 2 |
Имею в виду() Среднее количество элементов в СДР. |
| 3 |
Sum () Общая стоимость элементов в СДР. |
| 4 |
Максимум() Максимальное значение среди всех элементов в СДР. |
| 5 |
Min () Минимальное значение среди всех элементов в СДР. |
| 6 |
Дисперсия () Дисперсия элементов. |
| 7 |
STDEV () Стандартное отклонение. |
кол — ()
Количество элементов в СДР.
Имею в виду()
Среднее количество элементов в СДР.
Sum ()
Общая стоимость элементов в СДР.
Максимум()
Максимальное значение среди всех элементов в СДР.
Min ()
Минимальное значение среди всех элементов в СДР.
Дисперсия ()
Дисперсия элементов.
STDEV ()
Стандартное отклонение.
Если вы хотите использовать только один из этих методов, вы можете вызвать соответствующий метод непосредственно в RDD.