Эластичные распределенные наборы данных (RDD) — это фундаментальная структура данных Spark. Это неизменяемая распределенная коллекция объектов. Каждый набор данных в RDD разделен на логические разделы, которые могут быть вычислены на разных узлах кластера. СДР могут содержать объекты Python, Java или Scala любого типа, включая определяемые пользователем классы.
Формально СДР — это секционированная коллекция записей только для чтения. СДР могут быть созданы с помощью детерминированных операций с данными в стабильном хранилище или с другими СДР. СДР — это отказоустойчивая совокупность элементов, которые могут работать параллельно.
Существует два способа создания RDD — распараллеливание существующей коллекции в вашей программе драйвера или обращение к набору данных во внешней системе хранения, такой как общая файловая система, HDFS, HBase или любой источник данных, предлагающий формат ввода Hadoop.
Spark использует концепцию RDD для достижения более быстрых и эффективных операций MapReduce. Давайте сначала обсудим, как происходят операции MapReduce и почему они не столь эффективны.
Обмен данными медленен в MapReduce
MapReduce широко используется для обработки и генерации больших наборов данных с параллельным распределенным алгоритмом в кластере. Это позволяет пользователям писать параллельные вычисления, используя набор операторов высокого уровня, не беспокоясь о распределении работы и отказоустойчивости.
К сожалению, в большинстве современных платформ единственный способ повторно использовать данные между вычислениями (например, между двумя заданиями MapReduce) — это записать их во внешнюю стабильную систему хранения (Ex-HDFS). Хотя эта структура предоставляет множество абстракций для доступа к вычислительным ресурсам кластера, пользователям все еще нужно больше.
Итеративные и интерактивные приложения требуют более быстрого обмена данными между параллельными заданиями. Обмен данными в MapReduce происходит медленно из-за репликации, сериализации и дискового ввода-вывода . Что касается системы хранения, большинства приложений Hadoop, они проводят более 90% времени, выполняя операции чтения-записи HDFS.
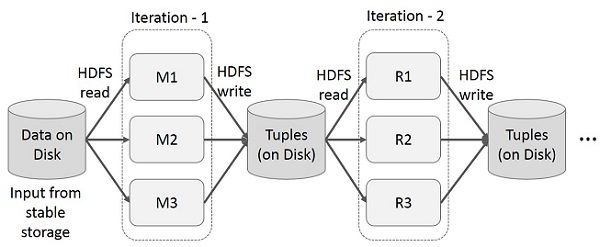
Итерационные операции на MapReduce
Повторное использование промежуточных результатов в нескольких вычислениях в многоэтапных приложениях. На следующем рисунке показано, как работает текущий каркас, выполняя итерационные операции над MapReduce. Это приводит к значительным накладным расходам из-за репликации данных, дискового ввода-вывода и сериализации, что замедляет работу системы.
Интерактивные операции на MapReduce
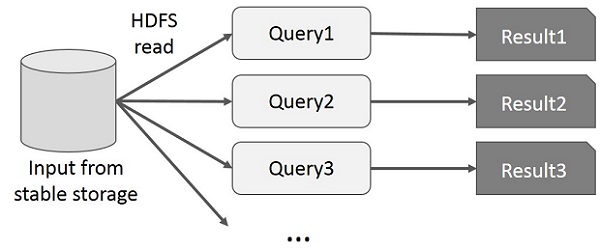
Пользователь запускает специальные запросы к одному и тому же подмножеству данных. Каждый запрос будет выполнять дисковый ввод-вывод в стабильном хранилище, что может влиять на время выполнения приложения.
На следующем рисунке показано, как работает текущая структура при выполнении интерактивных запросов в MapReduce.
Обмен данными с использованием Spark RDD
Обмен данными в MapReduce происходит медленно из-за репликации, сериализации и дискового ввода-вывода . Большинство приложений Hadoop тратят более 90% времени на операции чтения-записи HDFS.
Признавая эту проблему, исследователи разработали специализированную среду под названием Apache Spark. Ключевой идеей искры является R esilient D istributed D atasets (RDD); он поддерживает вычисления в памяти. Это означает, что он хранит состояние памяти как объект между заданиями, и объект разделяется между этими заданиями. Обмен данными в памяти в 10-100 раз быстрее, чем в сети и на диске.
Давайте теперь попробуем выяснить, как итеративные и интерактивные операции выполняются в Spark RDD.
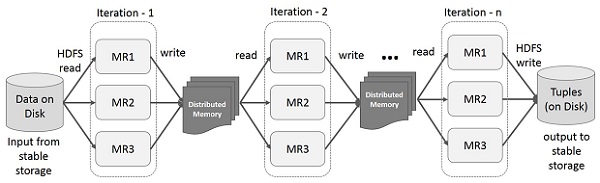
Итерационные операции на Spark RDD
На приведенной ниже иллюстрации показаны итерационные операции на Spark RDD. Он будет хранить промежуточные результаты в распределенной памяти вместо стабильного хранилища (диска) и сделает систему быстрее.
Примечание. Если распределенной памяти (ОЗУ) недостаточно для хранения промежуточных результатов (состояния задания), эти результаты будут сохранены на диске.
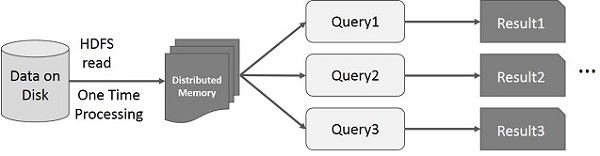
Интерактивные операции на Spark RDD
На этом рисунке показаны интерактивные операции на Spark RDD. Если разные запросы выполняются для одного и того же набора данных несколько раз, эти конкретные данные могут быть сохранены в памяти для лучшего времени выполнения.
По умолчанию каждый преобразованный СДР может пересчитываться каждый раз, когда вы выполняете над ним действие. Однако вы также можете сохранить RDD в памяти, и в этом случае Spark сохранит элементы в кластере для более быстрого доступа при следующем запросе. Существует также поддержка сохранения RDD на диске или репликации на нескольких узлах.