ArangoDB — мультимодельная первая база данных
ArangoDB провозглашается разработчиками как родная многомодельная база данных. Это в отличие от других баз данных NoSQL. В этой базе данных данные могут храниться в виде документов, пар ключ / значение или графиков. И с одним декларативным языком запросов, любой или все ваши данные могут быть доступны. Кроме того, различные модели могут быть объединены в одном запросе. И, благодаря его мультимодельному стилю, можно создавать простые приложения, которые будут масштабироваться по горизонтали с любой или всеми тремя моделями данных.
Слоистые и родные многомодельные базы данных
В этом разделе мы выделим принципиальное различие между нативной и многоуровневой многоуровневой базой данных.
Многие поставщики баз данных называют свой продукт «мультимоделью», но добавление графического слоя в хранилище ключей / значений или документов не считается нативной мультимоделью.
С ArangoDB, одним и тем же ядром с одним и тем же языком запросов, можно объединить разные модели данных и функции в одном запросе, как мы уже указывали в предыдущем разделе. В ArangoDB нет «переключения» между моделями данных, и нет перемещения данных от A к B для выполнения запросов. Это приводит к преимуществам производительности для ArangoDB по сравнению с «многоуровневыми» подходами.
Потребность в мультимодальной базе данных
Интерпретация основной идеи [Фаулера] приводит нас к пониманию преимуществ использования различных подходящих моделей данных для разных частей персистентного уровня, причем этот уровень является частью более широкой архитектуры программного обеспечения.
В соответствии с этим можно, например, использовать реляционную базу данных для сохранения структурированных табличных данных; хранилище документов для неструктурированных, объектоподобных данных; хранилище ключей / значений для хеш-таблицы; и графовая база данных для сильно связанных ссылочных данных.
Однако традиционная реализация этого подхода приведет к использованию нескольких баз данных в одном проекте. Это может привести к некоторым операционным трениям (более сложное развертывание, более частые обновления), а также к проблемам согласованности данных и дублирования.
Следующая задача после объединения данных для трех моделей данных заключается в разработке и реализации общего языка запросов, который может позволить администраторам данных выражать различные запросы, такие как запросы документов, поиск по ключу / значению, графические запросы и произвольные комбинации. из этих.
Под графическими запросами мы подразумеваем запросы, включающие теоретико-графические соображения. В частности, они могут включать в себя конкретные возможности подключения, поступающие с краев. Например, ShortestPath, GraphTraversal и Соседи .
Графики идеально подходят в качестве модели данных для отношений. Во многих реальных случаях, таких как социальная сеть, система рекомендаций и т. Д., Очень естественной моделью данных является график. Он захватывает отношения и может содержать информацию метки с каждым ребром и с каждой вершиной. Кроме того, документы JSON естественным образом подходят для хранения данных вершин и ребер этого типа.
ArangoDB ─ Особенности
Существуют различные примечательные особенности ArangoDB. Мы выделим основные функции ниже —
- Мультимодельная парадигма
- ACID Свойства
- HTTP API
ArangoDB поддерживает все популярные модели баз данных. Ниже приведены несколько моделей, поддерживаемых ArangoDB —
- Модель документа
- Модель ключ / значение
- Модель графика
Для извлечения данных из базы данных достаточно одного языка запросов.
Четыре свойства атомарности, согласованности, изоляции и долговечности (ACID) описывают гарантии транзакций базы данных. ArangoDB поддерживает ACID-совместимые транзакции.
ArangoDB позволяет клиентам, таким как браузеры, взаимодействовать с базой данных через HTTP API, API ориентирован на ресурсы и расширяется с помощью JavaScript.
ArangoDB — Преимущества
Ниже приведены преимущества использования ArangoDB —
Укрепление
Как собственная многомодельная база данных, ArangoDB устраняет необходимость развертывания нескольких баз данных и, таким образом, уменьшает количество компонентов и их обслуживание. Следовательно, это снижает сложность технологического стека для приложения. В дополнение к консолидации ваших общих технических потребностей, это упрощение приводит к снижению совокупной стоимости владения и повышению гибкости.
Упрощенное масштабирование производительности
Со временем приложения растут, ArangoDB может справляться с растущими потребностями в производительности и хранении, независимо масштабируя их с помощью различных моделей данных. Так как ArangoDB может масштабироваться как по вертикали, так и по горизонтали, то есть в случае, когда ваша производительность требует снижения (преднамеренного, желаемого замедления), вашу внутреннюю систему можно легко уменьшить, чтобы сэкономить на оборудовании, а также на эксплуатационных расходах.
Снижение операционной сложности
Постановление Polyglot Persistence — использовать лучшие инструменты для каждой работы, которую вы выполняете. Для некоторых задач требуется база данных документов, в то время как для других может потребоваться база данных графов. В результате работы с базами данных одной модели это может привести к множеству операционных проблем. Интеграция баз данных с одной моделью — сложная работа сама по себе. Но самой большой проблемой является построение большой связной структуры с согласованностью данных и отказоустойчивостью между отдельными, не связанными системами баз данных. Это может оказаться почти невозможным.
Постоянство Polyglot можно обрабатывать с помощью собственной многомодельной базы данных, поскольку она позволяет легко получать данные Polyglot, но в то же время обеспечивает согласованность данных в отказоустойчивой системе. С ArangoDB мы можем использовать правильную модель данных для сложной работы.
Сильная согласованность данных
Если использовать несколько баз данных с одной моделью, то непротиворечивость данных может стать проблемой. Эти базы данных не предназначены для взаимодействия друг с другом, поэтому необходимо реализовать некоторую форму функциональности транзакций, чтобы обеспечить согласованность данных между различными моделями.
Поддерживая транзакции ACID, ArangoDB управляет вашими различными моделями данных с помощью единого бэкэнда, обеспечивая высокую согласованность для одного экземпляра и атомарные операции при работе в режиме кластера.
Отказоустойчивость
Это сложная задача — создать отказоустойчивые системы с множеством несвязанных компонентов. Эта задача становится более сложной при работе с кластерами. Требуются знания для развертывания и обслуживания таких систем с использованием различных технологий и / или технологических стеков. Более того, интеграция нескольких подсистем, предназначенных для автономной работы, влечет за собой большие инженерные и эксплуатационные расходы.
В качестве объединенного технологического стека мультимодельная база данных представляет собой элегантное решение. ArangoDB предназначен для использования в современных модульных архитектурах с различными моделями данных и для кластерного использования.
Более низкая общая стоимость владения
Каждая технология баз данных требует постоянного обслуживания, исправлений ошибок и других изменений кода, предоставляемых поставщиком. Использование многомодельной базы данных значительно снижает связанные с этим затраты на обслуживание, просто устраняя количество технологий баз данных при разработке приложения.
операции
Обеспечение транзакционных гарантий на нескольких машинах является реальной проблемой, и лишь немногие базы данных NoSQL дают такие гарантии. Будучи нативной мультимоделью, ArangoDB навязывает транзакции, чтобы гарантировать согласованность данных.
Основные понятия и терминология
В этой главе мы обсудим основные понятия и термины для ArangoDB. Очень важно иметь ноу-хау основных базовых терминов, связанных с технической темой, с которой мы имеем дело.
Термины для ArangoDB перечислены ниже —
- Документ
- Коллекция
- Идентификатор коллекции
- Название коллекции
- База данных
- Имя базы данных
- Организация базы данных
С точки зрения модели данных, ArangoDB может рассматриваться как документно-ориентированная база данных, поскольку понятие документа является математической идеей последней. Документно-ориентированные базы данных являются одной из основных категорий баз данных NoSQL.
Иерархия выглядит следующим образом: документы сгруппированы в коллекции, а коллекции существуют в базах данных
Должно быть очевидно, что Идентификатор и Имя являются двумя атрибутами для коллекции и базы данных.
Обычно два документа (вершины), хранящиеся в собраниях документов, связаны документом (ребром), хранящимся в собрании ребер. Это модель данных графа ArangoDB. Он следует математической концепции ориентированного, помеченного графа, за исключением того, что ребра не только имеют метки, но и являются полноценными документами.
Ознакомившись с основными терминами этой базы данных, мы начнем понимать модель графических данных ArangoDB. В этой модели существует два типа коллекций: коллекции документов и граничные коллекции. В пограничных коллекциях хранятся документы, а также есть два специальных атрибута: первый — это атрибут _from , а второй — атрибут _to . Эти атрибуты используются для создания ребер (отношений) между документами, существенными для базы данных графа. Коллекции документов также называются коллекциями вершин в контексте графов (см. Любую книгу теории графов).
Давайте теперь посмотрим, насколько важны базы данных. Они важны, потому что коллекции существуют внутри баз данных. В одном экземпляре ArangoDB может быть одна или несколько баз данных. Для мультитенантных установок обычно используются разные базы данных, поскольку различные наборы данных внутри них (коллекции, документы и т. Д.) Изолированы друг от друга. База данных по умолчанию _system является особенной, потому что ее нельзя удалить. Пользователи управляются в этой базе данных, и их учетные данные действительны для всех баз данных экземпляра сервера.
ArangoDB — Системные требования
В этой главе мы обсудим системные требования для ArangoDB.
Системные требования для ArangoDB следующие:
- VPS-сервер с установкой Ubuntu
- Оперативная память: 1 ГБ; Процессор: 2,2 ГГц
Для всех команд в этом уроке мы использовали экземпляр Ubuntu 16.04 (xenial) с оперативной памятью 1 ГБ и одним процессором с тактовой частотой 2,2 ГГц. И все команды arangosh в этом руководстве были протестированы для ArangoDB версии 3.1.27.
Как установить ArangoDB?
В этом разделе мы увидим, как установить ArangoDB. ArangoDB поставляется с предварительной сборкой для многих операционных систем и дистрибутивов. Для получения более подробной информации, пожалуйста, обратитесь к документации ArangoDB. Как уже упоминалось, для этого урока мы будем использовать Ubuntu 16.04×64.
Первый шаг — загрузить открытый ключ для своих репозиториев.
# wget https://www.arangodb.com/repositories/arangodb31/ xUbuntu_16.04/Release.key
Выход
--2017-09-03 12:13:24-- https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/Release.key Resolving https://www.arangodb.com/ (www.arangodb.com)... 104.25.1 64.21, 104.25.165.21, 2400:cb00:2048:1::6819:a415, ... Connecting to https://www.arangodb.com/ (www.arangodb.com)|104.25. 164.21|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 3924 (3.8K) [application/pgpkeys] Saving to: ‘Release.key’ Release.key 100%[===================>] 3.83K - .-KB/s in 0.001s 2017-09-03 12:13:25 (2.61 MB/s) - ‘Release.key’ saved [39 24/3924]
Важным моментом является то, что вы должны увидеть Release.key, сохраненный в конце вывода.
Давайте установим сохраненный ключ, используя следующую строку кода —
# sudo apt-key add Release.key
Выход
OK
Выполните следующие команды, чтобы добавить репозиторий apt и обновить индекс:
# sudo apt-add-repository 'deb https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/ /' # sudo apt-get update
В качестве последнего шага мы можем установить ArangoDB —
# sudo apt-get install arangodb3
Выход
Reading package lists... Done Building dependency tree Reading state information... Done The following package was automatically installed and is no longer required: grub-pc-bin Use 'sudo apt autoremove' to remove it. The following NEW packages will be installed: arangodb3 0 upgraded, 1 newly installed, 0 to remove and 17 not upgraded. Need to get 55.6 MB of archives. After this operation, 343 MB of additional disk space will be used.
Нажмите Enter . Теперь начнется процесс установки ArangoDB —
Get:1 https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04 arangodb3 3.1.27 [55.6 MB] Fetched 55.6 MB in 59s (942 kB/s) Preconfiguring packages ... Selecting previously unselected package arangodb3. (Reading database ... 54209 files and directories currently installed.) Preparing to unpack .../arangodb3_3.1.27_amd64.deb ... Unpacking arangodb3 (3.1.27) ... Processing triggers for systemd (229-4ubuntu19) ... Processing triggers for ureadahead (0.100.0-19) ... Processing triggers for man-db (2.7.5-1) ... Setting up arangodb3 (3.1.27) ... Database files are up-to-date.
Когда установка ArangoDB близка к завершению, появится следующий экран —
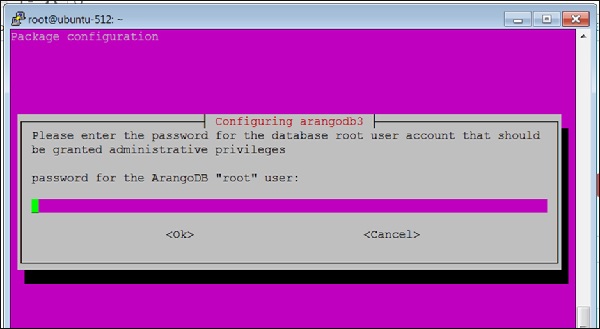
Здесь вам будет предложено ввести пароль для пользователя root ArangoDB. Запишите это внимательно.
Выберите опцию да, когда появится следующее диалоговое окно —
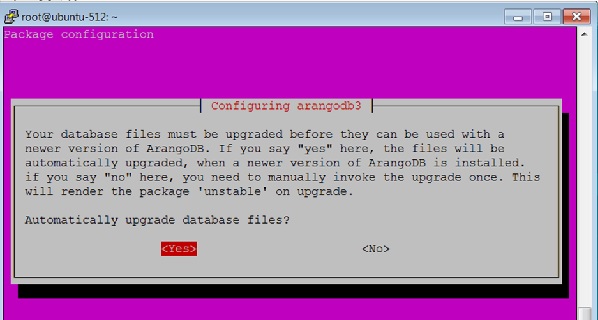
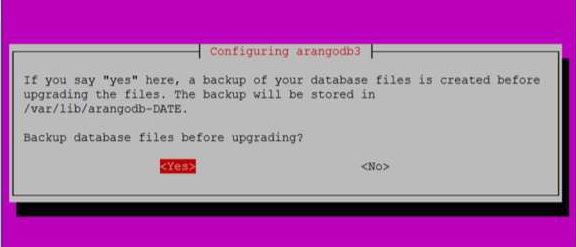
Когда вы нажимаете Да, как в приведенном выше диалоговом окне, появляется следующее диалоговое окно. Нажмите Да здесь.
Вы также можете проверить состояние ArangoDB с помощью следующей команды —
# sudo systemctl status arangodb3
Выход
arangodb3.service - LSB: arangodb
Loaded: loaded (/etc/init.d/arangodb3; bad; vendor pre set: enabled)
Active: active (running) since Mon 2017-09-04 05:42:35 UTC;
4min 46s ago
Docs: man:systemd-sysv-generator(8)
Process: 2642 ExecStart=/etc/init.d/arangodb3 start (code = exited,
status = 0/SUC
Tasks: 22
Memory: 158.6M
CPU: 3.117s
CGroup: /system.slice/arangodb3.service
├─2689 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
└─2690 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
Sep 04 05:42:33 ubuntu-512 systemd[1]: Starting LSB: arangodb...
Sep 04 05:42:33 ubuntu-512 arangodb3[2642]: * Starting arango database server a
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: {startup} starting up in daemon mode
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: changed working directory for child
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: ...done.
Sep 04 05:42:35 ubuntu-512 systemd[1]: StartedLSB: arang odb.
Sep 04 05:46:59 ubuntu-512 systemd[1]: Started LSB: arangodb. lines 1-19/19 (END)
ArangoDB теперь готов к использованию.
Чтобы вызвать терминал arangosh, введите в терминале следующую команду —
# arangosh
Выход
Please specify a password:
Укажите пароль root, созданный во время установки.
_ __ _ _ __ __ _ _ __ __ _ ___ | | / | '__/ _ | ’ \ / ` |/ _ / | ’ | (| | | | (| | | | | (| | () _ \ | | | _,|| _,|| ||_, |_/|/| || |__/
arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8 5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016) Copyright (c) ArangoDB GmbH Pretty printing values. Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27 [server], database: '_system', username: 'root' Please note that a new minor version '3.2.2' is available Type 'tutorial' for a tutorial or 'help' to see common examples 127.0.0.1:8529@_system> exit
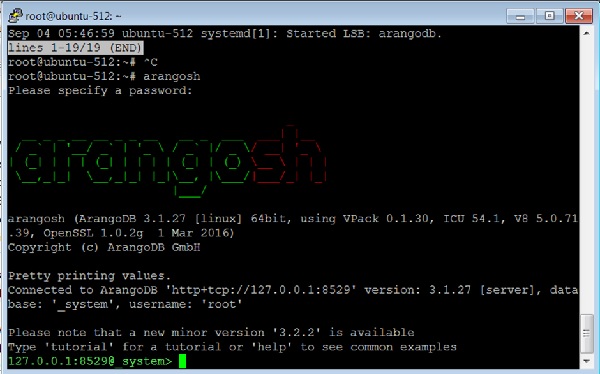
Чтобы выйти из ArangoDB, введите следующую команду —
127.0.0.1:8529@_system> exit
Выход
Uf wiederluege! Na shledanou! Auf Wiedersehen! Bye Bye! Adiau! ¡Hasta luego! Εις το επανιδείν! להתראות ! Arrivederci! Tot ziens! Adjö! Au revoir! さようなら До свидания! Até Breve! !خداحافظ
ArangoDB — Командная строка
В этой главе мы обсудим, как работает Arangosh в качестве командной строки для ArangoDB. Мы начнем с изучения того, как добавить пользователя базы данных.
Примечание. Помните, что цифровая клавиатура может не работать на Arangosh.
Предположим, что пользователь — «Гарри», а пароль — «hpwdb».
127.0.0.1:8529@_system> require("org/arangodb/users").save("harry", "hpwdb");
Выход
{
"user" : "harry",
"active" : true,
"extra" : {},
"changePassword" : false,
"code" : 201
}
ArangoDB — веб-интерфейс
В этой главе мы узнаем, как включить / отключить Аутентификацию и как привязать ArangoDB к общедоступному сетевому интерфейсу.
# arangosh --server.endpoint tcp://127.0.0.1:8529 --server.database "_system"
Он попросит вас сохранить ранее сохраненный пароль —
Please specify a password:
Используйте пароль, который вы создали для root, при настройке.
Вы также можете использовать curl для проверки того, что вы действительно получаете ответы HTTP 401 (неавторизованного) на запросы, требующие аутентификации —
# curl --dump - http://127.0.0.1:8529/_api/version
Выход
HTTP/1.1 401 Unauthorized X-Content-Type-Options: nosniff Www-Authenticate: Bearer token_type = "JWT", realm = "ArangoDB" Server: ArangoDB Connection: Keep-Alive Content-Type: text/plain; charset = utf-8 Content-Length: 0
Чтобы не вводить пароль каждый раз в процессе обучения, мы отключим аутентификацию. Для этого откройте файл конфигурации —
# vim /etc/arangodb3/arangod.conf
Вы должны изменить цветовую схему, если код не виден должным образом.
:colorscheme desert
Установите для аутентификации значение false, как показано на скриншоте ниже.
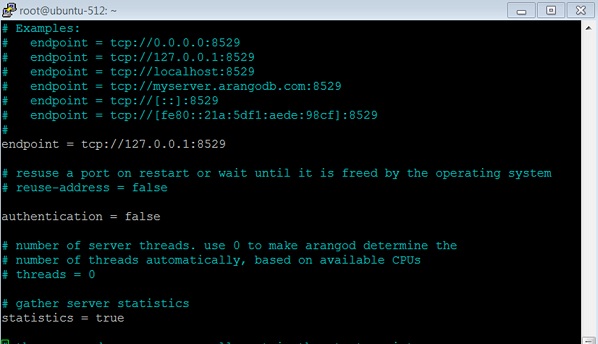
Перезапустите сервис —
# service arangodb3 restart
Если вы сделаете аутентификацию ложной, вы сможете войти в систему (либо с пользователем root, либо с созданным пользователем, в данном случае с Harry ), не вводя пароль, пожалуйста, укажите пароль .
Давайте проверим версию API, когда аутентификация выключена —
# curl --dump - http://127.0.0.1:8529/_api/version
Выход
HTTP/1.1 200 OK
X-Content-Type-Options: nosniff
Server: ArangoDB
Connection: Keep-Alive
Content-Type: application/json; charset=utf-8
Content-Length: 60
{"server":"arango","version":"3.1.27","license":"community"}
ArangoDB — Примеры сценариев
В этой главе мы рассмотрим два примера сценария. Эти примеры проще для понимания и помогут нам понять, как работает функциональность ArangoDB.
Чтобы продемонстрировать API, ArangoDB поставляется с предустановленным набором понятных графов. Есть два метода для создания экземпляров этих графиков в вашей ArangoDB —
- Добавьте вкладку «Пример» в окне создания графика в веб-интерфейсе,
- или загрузите модуль @ arangodb / graph-examples / example-graph в Arangosh.
Для начала загрузим график с помощью веб-интерфейса. Для этого запустите веб-интерфейс и нажмите на вкладку графиков .
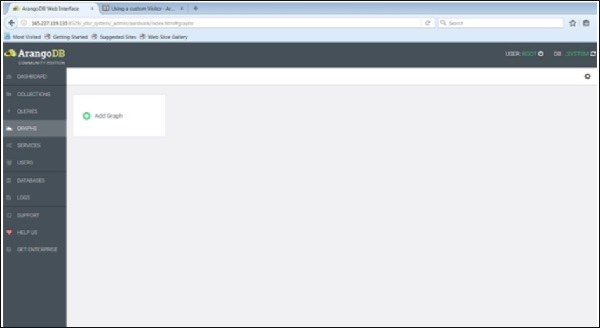
Откроется диалоговое окно « Создать график ». Мастер содержит две вкладки — Примеры и График . Вкладка График открыта по умолчанию; Предположим, что мы хотим создать новый граф, он запросит имя и другие определения для графа.
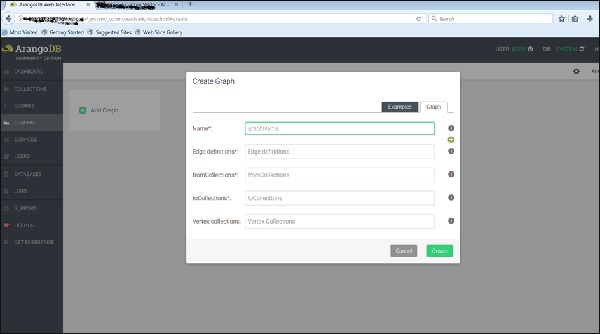
Теперь мы загрузим уже созданный график. Для этого мы выберем вкладку Примеры .
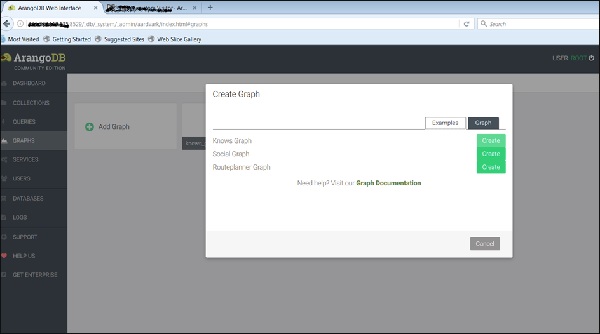
Мы можем видеть три примера графиков. Выберите Knows_Graph и нажмите зеленую кнопку Создать.
Создав их, вы можете проверить их в веб-интерфейсе, который использовался для создания рисунков ниже.
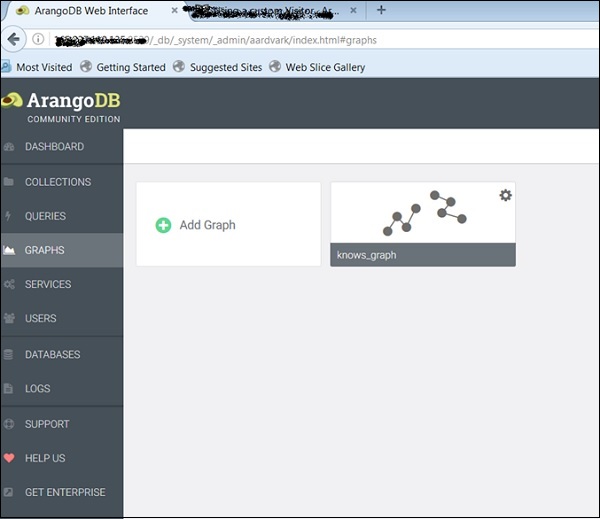
Знающий_Граф
Давайте теперь посмотрим, как работает Knows_Graph . Выберите Knows_Graph, и он будет получать данные графика.
Knows_Graph состоит из одной совокупности вершин, связанных через одно собрание ребер. В нем будут пять человек: Алиса, Боб, Чарли, Дейв и Ева в качестве вершин. У нас будут следующие направленные отношения
Alice knows Bob Bob knows Charlie Bob knows Dave Eve knows Alice Eve knows Bob
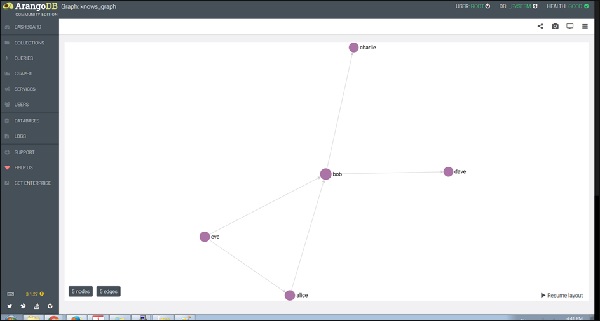
Если вы щелкнете по узлу (вершине), скажем, «bob», он покажет имя атрибута ID (people / bob).
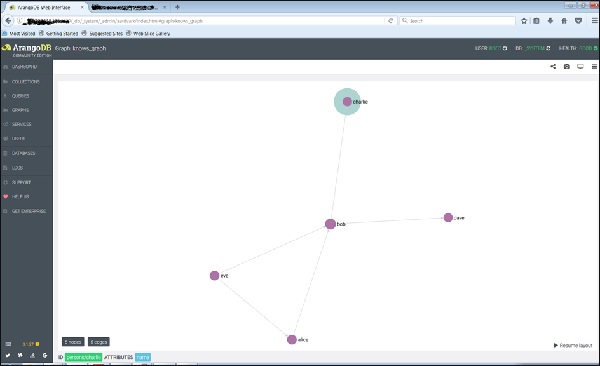
А при щелчке по любому ребру будут показаны атрибуты ID (знает / 4590).
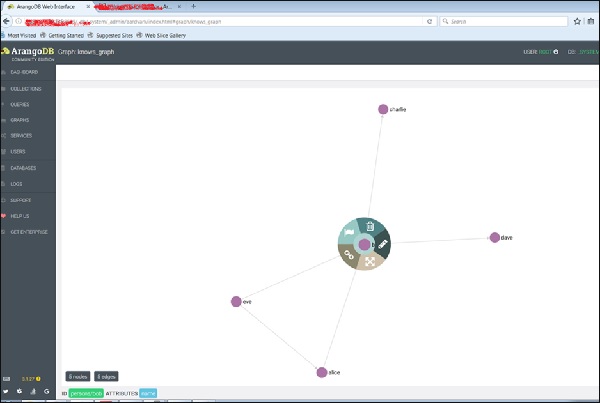
Вот как мы его создаем, проверяем его вершины и ребра.
Давайте добавим еще один график, на этот раз используя Арангоша. Для этого нам нужно включить другую конечную точку в файл конфигурации ArangoDB.
Как добавить несколько конечных точек
Откройте файл конфигурации —
# vim /etc/arangodb3/arangod.conf
Добавьте другую конечную точку, как показано на снимке экрана терминала ниже.
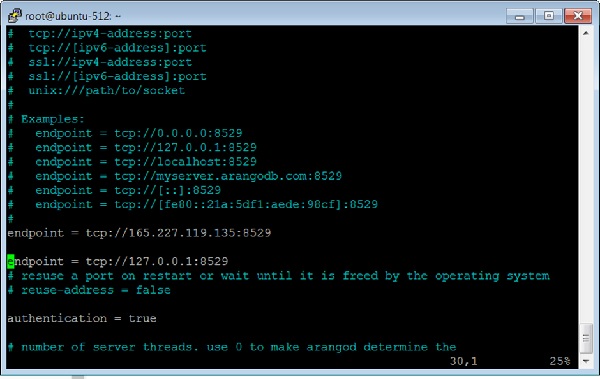
Перезапустите ArangoDB —
# service arangodb3 restart
Запустите Arangosh —
# arangosh Please specify a password: _ __ _ _ __ __ _ _ __ __ _ ___ ___| |__ / _` | '__/ _` | '_ \ / _` |/ _ \/ __| '_ \ | (_| | | | (_| | | | | (_| | (_) \__ \ | | | \__,_|_| \__,_|_| |_|\__, |\___/|___/_| |_| |___/ arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8 5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016) Copyright (c) ArangoDB GmbH Pretty printing values. Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27 [server], database: '_system', username: 'root' Please note that a new minor version '3.2.2' is available Type 'tutorial' for a tutorial or 'help' to see common examples 127.0.0.1:8529@_system>
Social_Graph
Давайте теперь поймем, что такое Social_Graph и как он работает. На графике показан набор людей и их отношения —
В этом примере женщины и мужчины представлены в качестве вершин в двух коллекциях вершин — женских и мужских. Ребра являются их связями в коллекции ребер отношений. Мы описали, как создать этот график с помощью Arangosh. Читатель может обойти его и изучить его атрибуты, как мы это делали с Knows_Graph.
ArangoDB — Модели данных и моделирование
В этой главе мы сосредоточимся на следующих темах —
- Взаимодействие с базой данных
- Модель данных
- Извлечение данных
ArangoDB поддерживает модель данных на основе документов, а также модель данных на основе графиков. Давайте сначала опишем модель данных на основе документа.
Документы ArangoDB очень похожи на формат JSON. В документе содержится ноль или более атрибутов, а значение присваивается каждому атрибуту. Значение может быть атомарного типа, такого как число, логическое или нулевое, литеральная строка, или составного типа данных, такого как внедренный документ / объект или массив. Массивы или подобъекты могут состоять из этих типов данных, что подразумевает, что один документ может представлять нетривиальные структуры данных.
Далее в иерархии документы организованы в коллекции, которые могут не содержать документов (теоретически) или более одного документа. Можно сравнить документы со строками, а коллекции с таблицами (здесь таблицы и строки относятся к системам управления реляционными базами данных — RDBMS).
Но в СУБД определение столбцов является обязательным условием для сохранения записей в таблице, вызывая схемы этих определений. Однако, как новая функция, ArangoDB не содержит схем — нет априорной причины для указания, какие атрибуты будут иметь документ.
И в отличие от РСУБД, каждый документ может быть структурирован совершенно иначе, чем другой документ. Эти документы могут быть сохранены вместе в одной коллекции. Практически, общие характеристики могут существовать среди документов в коллекции, однако система баз данных, то есть сама ArangoDB, не привязывает вас к конкретной структуре данных.
Теперь мы попытаемся понять [ модель данных графа ] ArangoDB, для которой требуются два вида коллекций — первый — это наборы документов (известные как группы вершин на языке теории групп), второй — наборы ребер. Между этими двумя типами есть тонкая разница. В пограничных коллекциях также хранятся документы, но они характеризуются наличием двух уникальных атрибутов: _from и _to для создания отношений между документами. На практике документ (край чтения) связывает два документа (вершины чтения), оба хранятся в своих соответствующих коллекциях. Эта архитектура основана на теоретико-графической концепции помеченного ориентированного графа, исключая ребра, которые могут иметь не только метки, но и сам по себе может быть полным JSON-подобным документом.
Для вычисления свежих данных, удаления документов или управления ими используются запросы, которые выбирают или фильтруют документы в соответствии с заданными критериями. Будучи простыми в качестве «примера запроса» или такими же сложными, как «соединения», запросы кодируются на языке запросов AQL — ArangoDB.
ArangoDB — Методы базы данных
В этой главе мы обсудим различные методы базы данных в ArangoDB.
Для начала давайте получим свойства базы данных —
- название
- Я БЫ
- Дорожка
Сначала мы призываем Арангоша. Как только Arangosh вызван, мы перечислим базы данных, которые мы создали до сих пор —
Мы будем использовать следующую строку кода для вызова Arangosh —
127.0.0.1:8529@_system> db._databases()
Выход
[ "_system", "song_collection" ]
Мы видим две базы данных, одну _систему, созданную по умолчанию, и вторую композицию song_collection, которую мы создали.
Давайте теперь перейдем к базе данных song_collection со следующей строкой кода —
127.0.0.1:8529@_system> db._useDatabase("song_collection")
Выход
true 127.0.0.1:8529@song_collection>
Мы рассмотрим свойства нашей базы данных song_collection.
Чтобы найти имя
Мы будем использовать следующую строку кода, чтобы найти имя.
127.0.0.1:8529@song_collection> db._name()
Выход
song_collection
Чтобы найти идентификатор —
Мы будем использовать следующую строку кода, чтобы найти идентификатор.
song_collection
Выход
4838
Чтобы найти путь —
Мы будем использовать следующую строку кода, чтобы найти путь.
127.0.0.1:8529@song_collection> db._path()
Выход
/var/lib/arangodb3/databases/database-4838
Давайте теперь проверим, находимся ли мы в системной базе данных или нет, используя следующую строку кода:
127.0.0.1:8529@song_collection&t; db._isSystem()
Выход
false
Это означает, что мы не находимся в системной базе данных (как мы создали и перешли на song_collection). Следующий скриншот поможет вам понять это.
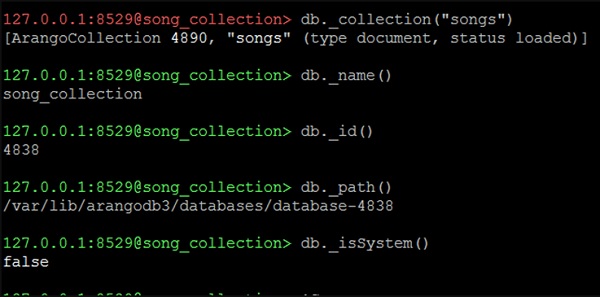
Чтобы получить определенную коллекцию, скажем песни —
Мы будем использовать следующую строку кода, чтобы получить конкретную коллекцию.
127.0.0.1:8529@song_collection> db._collection("songs")
Выход
[ArangoCollection 4890, "songs" (type document, status loaded)]
Строка кода возвращает одну коллекцию.
Давайте перейдем к основам операций с базой данных в наших последующих главах.
ArangoDB — Crud Operations
В этой главе мы изучим различные операции с Арангошем.
Ниже приведены возможные операции с Arangosh —
- Создание коллекции документов
- Создание документов
- Чтение документов
- Обновление документов
Давайте начнем с создания новой базы данных. Мы будем использовать следующую строку кода для создания новой базы данных —
127.0.0.1:8529@_system> db._createDatabase("song_collection")
true
Следующая строка кода поможет вам перейти на новую базу данных —
127.0.0.1:8529@_system> db._useDatabase("song_collection")
true
Подсказка переместится на «@@ song_collection»
127.0.0.1:8529@song_collection>
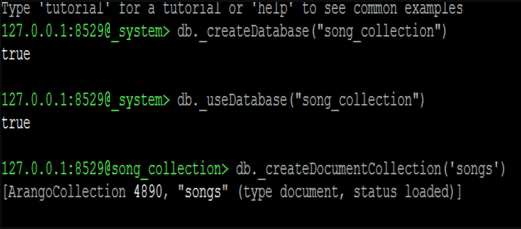
Отсюда мы будем изучать операции CRUD. Давайте создадим коллекцию в новой базе данных —
127.0.0.1:8529@song_collection> db._createDocumentCollection('songs')
Выход
[ArangoCollection 4890, "songs" (type document, status loaded)] 127.0.0.1:8529@song_collection>
Давайте добавим несколько документов (объекты JSON) в нашу коллекцию песен.
Мы добавляем первый документ следующим образом —
127.0.0.1:8529@song_collection> db.songs.save({title: "A Man's Best Friend",
lyricist: "Johnny Mercer", composer: "Johnny Mercer", Year: 1950, _key:
"A_Man"})
Выход
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVClbW---"
}
Давайте добавим другие документы в базу данных. Это поможет нам изучить процесс запроса данных. Вы можете скопировать эти коды и вставить их в Arangosh, чтобы подражать процессу —
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Accentchuate The Politics",
lyricist: "Johnny Mercer",
composer: "Harold Arlen", Year: 1944,
_key: "Accentchuate_The"
}
)
{
"_id" : "songs/Accentchuate_The",
"_key" : "Accentchuate_The",
"_rev" : "_VjVDnzO---"
}
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Affable Balding Me",
lyricist: "Johnny Mercer",
composer: "Robert Emmett Dolan",
Year: 1950,
_key: "Affable_Balding"
}
)
{
"_id" : "songs/Affable_Balding",
"_key" : "Affable_Balding",
"_rev" : "_VjVEFMm---"
}
Как читать документы
_Key или дескриптор документа могут быть использованы для получения документа. Используйте дескриптор документа, если нет необходимости проходить через саму коллекцию. Если у вас есть коллекция, функция документа проста в использовании —
127.0.0.1:8529@song_collection> db.songs.document("A_Man");
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVClbW---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950
}
Как обновить документы
Для обновления сохраненных данных доступны две опции — заменить и обновить .
Функция обновления исправляет документ, объединяя его с заданными атрибутами. С другой стороны, функция замены заменит предыдущий документ новым. Замена все равно произойдет, даже если будут предоставлены совершенно другие атрибуты. Сначала мы увидим неразрушающее обновление, обновив атрибут Production` в песне —
127.0.0.1:8529@song_collection> db.songs.update("songs/A_Man",{production:
"Top Banana"});
Выход
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVOcqe---",
"_oldRev" : "_VjVClbW---"
}
Давайте теперь прочитаем обновленные атрибуты песни —
127.0.0.1:8529@song_collection> db.songs.document('A_Man');
Выход
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVOcqe---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950,
"production" : "Top Banana"
}
Большой документ может быть легко обновлен с помощью функции обновления , особенно когда атрибутов очень мало.
Напротив, функция замены отменит ваши данные при использовании их с тем же документом.
127.0.0.1:8529@song_collection> db.songs.replace("songs/A_Man",{production:
"Top Banana"});
Давайте теперь проверим песню, которую мы только что обновили, с помощью следующей строки кода:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');
Выход
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVRhOq---",
"production" : "Top Banana"
}
Теперь вы можете заметить, что в документе больше нет исходных данных.
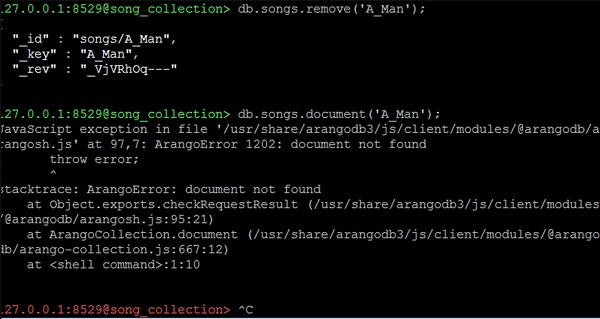
Как удалить документы
Функция удаления используется в сочетании с дескриптором документа для удаления документа из коллекции —
127.0.0.1:8529@song_collection> db.songs.remove('A_Man');
Давайте теперь проверим атрибуты песни, которые мы только что удалили, используя следующую строку кода:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');
Мы получим ошибку исключения, такую как следующая:
JavaScript exception in file '/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js' at 97,7: ArangoError 1202: document not found ! throw error; ! ^ stacktrace: ArangoError: document not found at Object.exports.checkRequestResult (/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js:95:21) at ArangoCollection.document (/usr/share/arangodb3/js/client/modules/@arangodb/arango-collection.js:667:12) at <shell command>:1:10
Crud Operations с использованием веб-интерфейса
В нашей предыдущей главе мы узнали, как выполнять различные операции над документами с помощью Arangosh, командной строки. Теперь мы узнаем, как выполнять те же операции с помощью веб-интерфейса. Для начала введите следующий адрес — http: // your_server_ip: 8529 / _db / song_collection / _admin / aardvark / index.html # login в адресной строке вашего браузера. Вы будете перенаправлены на следующую страницу входа.
Теперь введите имя пользователя и пароль.
В случае успеха появится следующий экран. Нам нужно сделать выбор для базы данных, с которой будет работать база данных _system по умолчанию. Давайте выберем базу данных song_collection и нажмем на зеленую вкладку —
Создание коллекции
В этом разделе мы узнаем, как создать коллекцию. Нажмите вкладку Коллекции на панели навигации вверху.
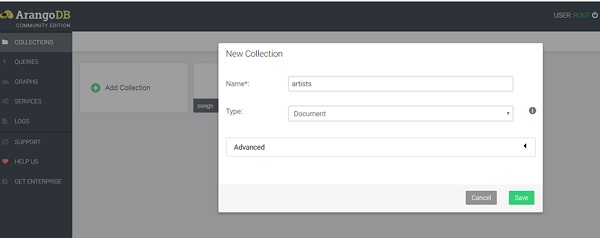
Наша командная строка добавлена коллекция песен видны. Нажав на это покажет записи. Теперь мы добавим коллекцию художников, используя веб-интерфейс. Коллекция песен, которые мы создали с помощью Arangosh, уже есть. В поле «Имя» напишите исполнителей в открывшемся диалоговом окне « Новая коллекция ». Расширенные параметры можно смело игнорировать, и тип коллекции по умолчанию, т. Е. Document, подходит.
Нажав на кнопку Сохранить, вы, наконец, создадите коллекцию, и теперь две коллекции будут видны на этой странице.
Заполнение вновь созданной коллекции документами
При нажатии на коллекцию художников вам будет представлена пустая коллекция —
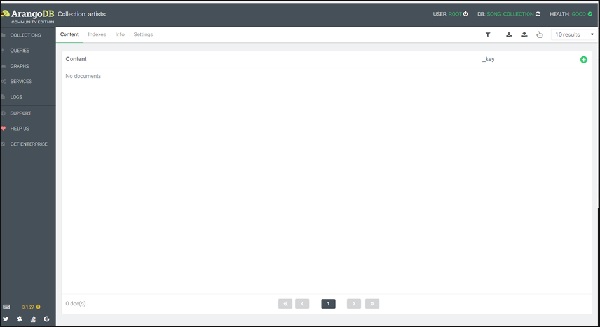
Чтобы добавить документ, вам нужно нажать на знак +, расположенный в правом верхнем углу. Когда вас попросят ввести _key , введите Affable_Balding в качестве ключа.
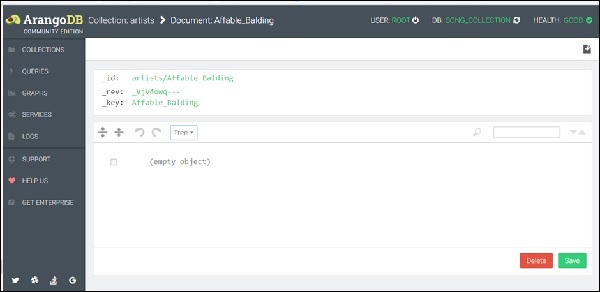
Теперь появится форма для добавления и редактирования атрибутов документа. Существует два способа добавления атрибутов: Графический и Дерево . Графический способ интуитивно понятен, но медленен, поэтому мы переключимся на представление « Код» , используя раскрывающееся меню «Дерево», чтобы выбрать его.
Чтобы упростить процесс, мы создали образец данных в формате JSON, который вы можете скопировать, а затем вставить в область редактора запросов —
{«artist»: «Johnny Mercer», «title»: «Affable Balding Me», «composer»: «Robert Emmett Dolan», «Year»: 1950}
(Примечание: следует использовать только одну пару фигурных скобок; см. Скриншот ниже)
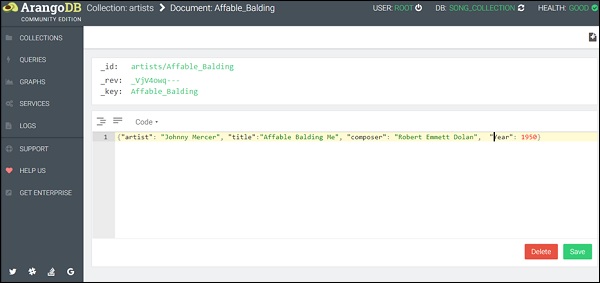
Вы можете заметить, что мы процитировали ключи, а также значения в режиме просмотра кода. Теперь нажмите Сохранить . После успешного завершения на странице на мгновение появляется зеленая вспышка.
Как читать документы
Чтобы прочитать документы, вернитесь на страницу «Коллекции».
При нажатии на коллекцию художников появляется новая запись.
Как обновить документы
Это просто редактировать записи в документе; вам просто нужно нажать на строку, которую вы хотите редактировать в обзоре документа. Здесь снова будет представлен тот же редактор запросов, что и при создании новых документов.
Удаление документов
Вы можете удалить документы, нажав значок «-». Каждая строка документа имеет этот знак в конце. Вам будет предложено подтвердить, чтобы избежать небезопасного удаления.
Более того, для конкретной коллекции другие операции, такие как фильтрация документов, управление индексами и импорт данных, также существуют на странице обзора коллекций .
В нашей следующей главе мы обсудим важную функцию веб-интерфейса — редактор запросов AQL.
Запрос данных с помощью AQL
В этой главе мы обсудим, как запрашивать данные с помощью AQL. Мы уже обсуждали в наших предыдущих главах, что ArangoDB разработал свой собственный язык запросов и называется он AQL.
Давайте теперь начнем взаимодействовать с AQL. Как показано на рисунке ниже, в веб-интерфейсе нажмите вкладку AQL Editor, расположенную в верхней части панели навигации. Появится пустой редактор запросов.
При необходимости вы можете переключиться на редактор из представления результатов и наоборот, щелкнув вкладки «Запрос» или «Результат» в верхнем правом углу, как показано на рисунке ниже —
Среди прочего, редактор имеет подсветку синтаксиса, функции отмены и повтора и сохранение запросов. Подробную справку можно найти в официальной документации. Мы выделим несколько основных и часто используемых функций редактора запросов AQL.
Основы AQL
В AQL запрос представляет конечный результат, который должен быть достигнут, но не процесс, посредством которого должен быть достигнут конечный результат. Эта функция широко известна как декларативное свойство языка. Кроме того, AQL может также запрашивать и изменять данные, и, таким образом, сложные запросы могут создаваться путем объединения обоих процессов.
Обратите внимание, что AQL полностью совместим с ACID. Чтение или изменение запросов либо завершатся полностью, либо не завершатся вовсе. Даже чтение данных документа будет заканчиваться последовательной единицей данных.
Мы добавляем две новые песни в коллекцию песен, которую мы уже создали. Вместо того, чтобы печатать, вы можете скопировать следующий запрос и вставить его в редактор AQL —
FOR song IN [
{
title: "Air-Minded Executive", lyricist: "Johnny Mercer",
composer: "Bernie Hanighen", Year: 1940, _key: "Air-Minded"
},
{
title: "All Mucked Up", lyricist: "Johnny Mercer", composer:
"Andre Previn", Year: 1974, _key: "All_Mucked"
}
]
INSERT song IN songs
Нажмите кнопку «Выполнить» в левом нижнем углу.
Он напишет два новых документа в сборник песен .
Этот запрос описывает, как работает цикл FOR в AQL; он перебирает список документов в кодировке JSON, выполняя кодированные операции с каждым из документов в коллекции. Различными операциями могут быть создание новых структур, фильтрация, выбор документов, изменение или вставка документов в базу данных (см. Мгновенный пример). По сути, AQL может эффективно выполнять операции CRUD.
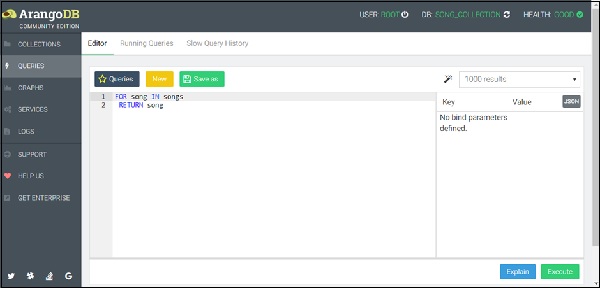
Чтобы найти все песни в нашей базе данных, давайте еще раз выполним следующий запрос, эквивалентный песням SELECT * FROM базы данных типа SQL (поскольку редактор запоминает последний запрос, нажмите кнопку * New * , чтобы очистить редактор ) —
FOR song IN songs RETURN song
Результирующий набор покажет список песен, сохраненных в коллекции песен, как показано на скриншоте ниже.
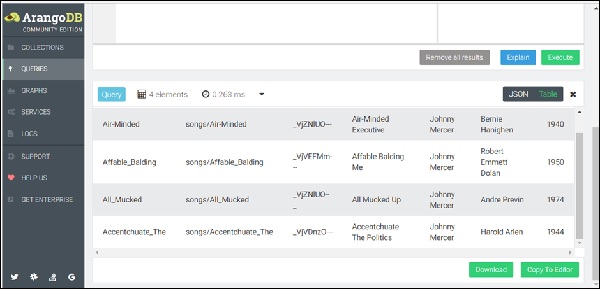
Такие операции, как FILTER, SORT и LIMIT, могут быть добавлены в тело цикла For, чтобы сузить и упорядочить результат.
FOR song IN songs FILTER song.Year > 1940 RETURN song
Приведенный выше запрос даст песни, созданные после 1940 года, на вкладке «Результат» (см. Изображение ниже).
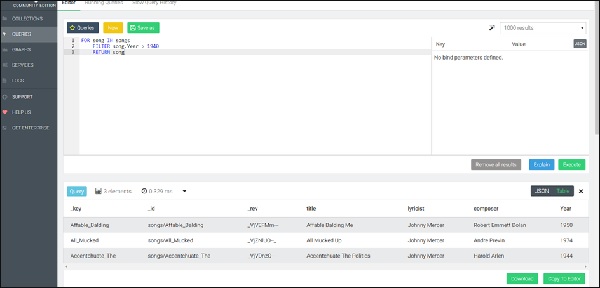
Ключ документа используется в этом примере, но любой другой атрибут также может использоваться в качестве эквивалента для фильтрации. Поскольку ключ документа гарантированно будет уникальным, этому фильтру будет соответствовать не более одного документа. Для других атрибутов это может быть не так. Чтобы вернуть подмножество активных пользователей (определяемое атрибутом с именем status), отсортированное по имени в порядке возрастания, мы используем следующий синтаксис:
FOR song IN songs FILTER song.Year > 1940 SORT song.composer RETURN song LIMIT 2
Мы сознательно включили этот пример. Здесь мы наблюдаем сообщение об ошибке синтаксиса запроса, выделенное красным цветом AQL. Этот синтаксис выделяет ошибки и полезен при отладке ваших запросов, как показано на скриншоте ниже.
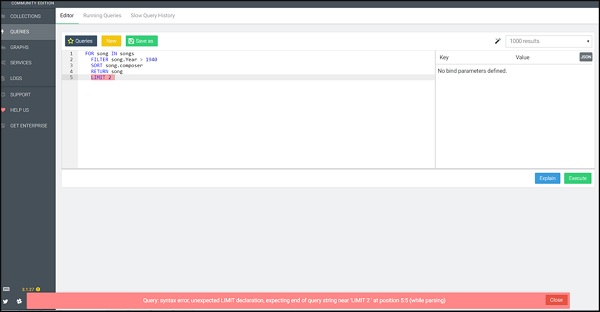
Давайте теперь запустим правильный запрос (обратите внимание на исправление) —
FOR song IN songs FILTER song.Year > 1940 SORT song.composer LIMIT 2 RETURN song
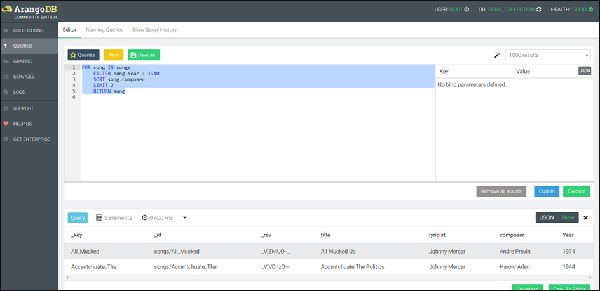
Сложный запрос в AQL
AQL оснащен несколькими функциями для всех поддерживаемых типов данных. Присвоение переменных в запросе позволяет создавать очень сложные вложенные конструкции. Таким образом, операции с большими объемами данных перемещаются ближе к данным на бэкэнде, чем к клиенту (например, браузеру). Чтобы понять это, давайте сначала добавим произвольные длительности (продолжительности) к песням.
Давайте начнем с первой функции, т. Е. Функции обновления —
UPDATE { _key: "All_Mucked" }
WITH { length: 180 }
IN songs
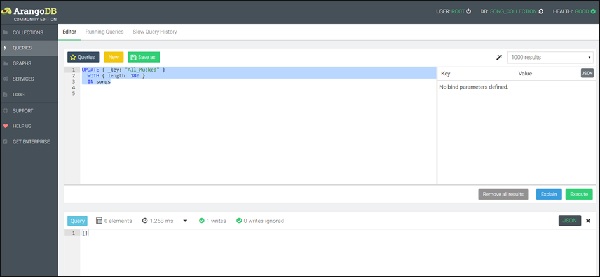
Мы видим, что один документ был написан, как показано на скриншоте выше.
Давайте теперь обновим и другие документы (песни).
UPDATE { _key: "Affable_Balding" }
WITH { length: 200 }
IN songs
Теперь мы можем проверить, что все наши песни имеют новую длину атрибута —
FOR song IN songs RETURN song
Выход
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_VkC5lbS---",
"title": "Air-Minded Executive",
"lyricist": "Johnny Mercer",
"composer": "Bernie Hanighen",
"Year": 1940,
"length": 210
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_VkC4eM2---",
"title": "Affable Balding Me",
"lyricist": "Johnny Mercer",
"composer": "Robert Emmett Dolan",
"Year": 1950,
"length": 200
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vjah9Pu---",
"title": "All Mucked Up",
"lyricist": "Johnny Mercer",
"composer": "Andre Previn",
"Year": 1974,
"length": 180
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_VkC3WzW---",
"title": "Accentchuate The Politics",
"lyricist": "Johnny Mercer",
"composer": "Harold Arlen",
"Year": 1944,
"length": 190
}
]
Чтобы проиллюстрировать использование других ключевых слов AQL, таких как LET, FILTER, SORT и т. Д., Теперь мы отформатируем длительности песни в формате mm: ss .
запрос
FOR song IN songs
FILTER song.length > 150
LET seconds = song.length % 60
LET minutes = FLOOR(song.length / 60)
SORT song.composer
RETURN
{
Title: song.title,
Composer: song.composer,
Duration: CONCAT_SEPARATOR(':',minutes, seconds)
}
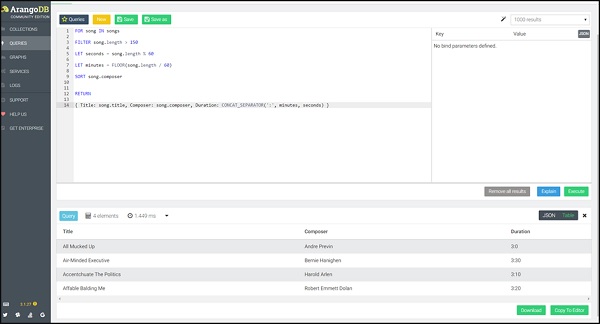
На этот раз мы вернем название песни вместе с продолжительностью. Функция Return позволяет вам создать новый объект JSON для возврата для каждого входного документа.
Теперь поговорим о функции «Соединения» базы данных AQL.
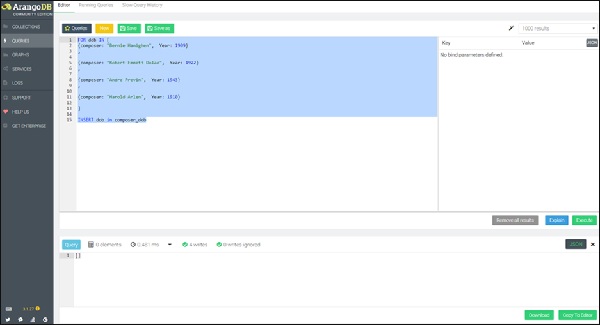
Давайте начнем с создания коллекции composer_dob . Далее, мы создадим четыре документа с гипотетической датой рождения композиторов, выполнив следующий запрос в поле запроса:
FOR dob IN [
{composer: "Bernie Hanighen", Year: 1909}
,
{composer: "Robert Emmett Dolan", Year: 1922}
,
{composer: "Andre Previn", Year: 1943}
,
{composer: "Harold Arlen", Year: 1910}
]
INSERT dob in composer_dob
Чтобы подчеркнуть сходство с SQL, мы представляем вложенный запрос цикла FOR в AQL, приводящий к операции REPLACE, повторяющейся сначала во внутреннем цикле, по всей записи композитора, а затем по всем связанным песням, создавая новый документ, содержащий атрибут song_with_composer_key вместо атрибута песни .
Здесь идет запрос —
FOR s IN songs
FOR c IN composer_dob
FILTER s.composer == c.composer
LET song_with_composer_key = MERGE(
UNSET(s, 'composer'),
{composer_key:c._key}
)
REPLACE s with song_with_composer_key IN songs
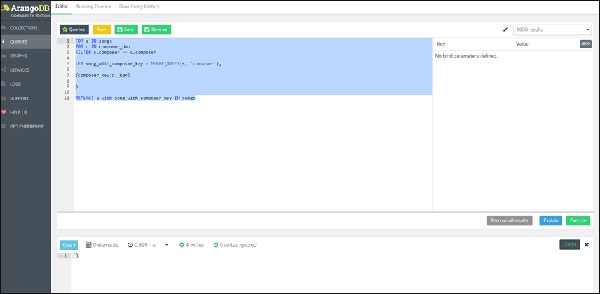
Теперь давайте снова запустим запрос FOR song IN song RETURN song, чтобы увидеть, как изменилась коллекция песен.
Выход
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_Vk8kFoK---",
"Year": 1940,
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive"
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_Vk8kFoK--_",
"Year": 1950,
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me"
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vk8kFoK--A",
"Year": 1974,
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up"
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"Year": 1944,
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics"
}
]
Приведенный выше запрос завершает процесс переноса данных, добавляя ключ composer_key к каждой песне.
Теперь следующий запрос снова является вложенным запросом цикла FOR, но на этот раз он приводит к операции Join, добавляя имя связанного композитора (выбирая с помощью `composer_key`) к каждой песне —
FOR s IN songs
FOR c IN composer_dob
FILTER c._key == s.composer_key
RETURN MERGE(s,
{ composer: c.composer }
)
Выход
[
{
"Year": 1940,
"_id": "songs/Air-Minded",
"_key": "Air-Minded",
"_rev": "_Vk8kFoK---",
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive",
"composer": "Bernie Hanighen"
},
{
"Year": 1950,
"_id": "songs/Affable_Balding",
"_key": "Affable_Balding",
"_rev": "_Vk8kFoK--_",
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me",
"composer": "Robert Emmett Dolan"
},
{
"Year": 1974,
"_id": "songs/All_Mucked",
"_key": "All_Mucked",
"_rev": "_Vk8kFoK--A",
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up",
"composer": "Andre Previn"
},
{
"Year": 1944,
"_id": "songs/Accentchuate_The",
"_key": "Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics",
"composer": "Harold Arlen"
}
]
ArangoDB — Примеры запросов AQL
В этой главе мы рассмотрим несколько примеров запросов AQL к базе данных актеров и фильмов . Эти запросы основаны на графиках.
проблема
Имея коллекцию актеров, коллекцию фильмов и коллекцию ребер actIn (со свойством year) для соединения вершины, как показано ниже —
[Актер] <- сниматься в -> [Фильм]
Как мы получаем —
- Все актеры, которые действовали в «movie1» ИЛИ «movie2»?
- Все актеры, которые снимались в фильмах «кино1» и «кино2»?
- Все общие фильмы между «актер1» и «актер2»?
- Все актеры, которые снимались в 3 и более фильмах?
- Во всех фильмах, где снимались ровно 6 актеров?
- Количество актеров по фильмам?
- Количество фильмов по актеру?
- Количество фильмов, сыгранных актером в период с 2005 по 2010 год?
Решение
В процессе решения и получения ответов на вышеупомянутые запросы мы будем использовать Arangosh для создания набора данных и выполнения запросов по нему. Все запросы AQL являются строками и могут быть просто скопированы в ваш любимый драйвер вместо Arangosh.
Давайте начнем с создания набора тестовых данных в Арангоше. Сначала скачайте этот файл —
# wget -O dataset.js https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharing
Выход
... HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘dataset.js’ dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s 2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]
В выводе выше вы можете видеть, что мы загрузили файл JavaScript dataset.js. Этот файл содержит команды Arangosh для создания набора данных в базе данных. Вместо того, чтобы копировать и вставлять команды одну за другой, мы будем использовать опцию —javascript.execute на Arangosh, чтобы выполнять несколько команд неинтерактивно. Считайте, что это команда спасателей жизни!
Теперь выполните следующую команду на оболочке —
$ arangosh --javascript.execute dataset.js
Введите пароль при появлении запроса, как вы можете видеть на скриншоте выше. Теперь мы сохранили данные, поэтому мы создадим запросы AQL, чтобы ответить на конкретные вопросы, поднятые в начале этой главы.
Первый вопрос
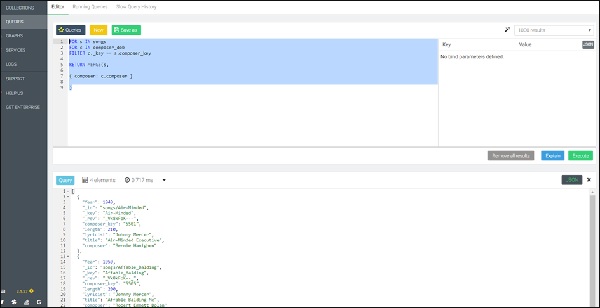
Давайте возьмем первый вопрос: все актеры, которые действовали в «movie1» ИЛИ «movie2» . Предположим, мы хотим найти имена всех актеров, которые действовали в «TheMatrix» ИЛИ «TheDevilsAdvocate» —
Мы начнем с одного фильма за раз, чтобы получить имена актеров —
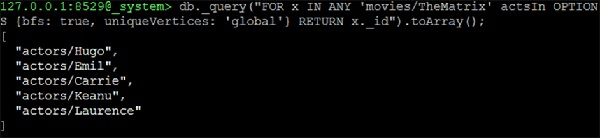
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();
Выход
Мы получим следующий вывод —
[ "actors/Hugo", "actors/Emil", "actors/Carrie", "actors/Keanu", "actors/Laurence" ]
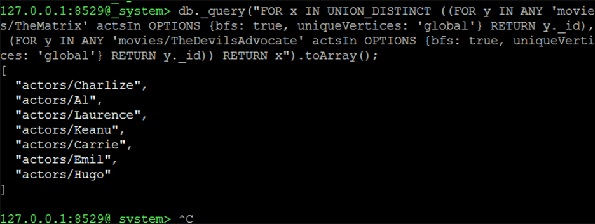
Теперь мы продолжаем формировать UNION_DISTINCT из двух запросов NEIGHBORS, которые будут решением —
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
Выход
[ "actors/Charlize", "actors/Al", "actors/Laurence", "actors/Keanu", "actors/Carrie", "actors/Emil", "actors/Hugo" ]
Второй вопрос
Давайте теперь рассмотрим второй вопрос: все актеры, которые участвовали как в «movie1», так и в «movie2» . Это почти идентично вопросу выше. Но на этот раз нас интересует не СОЮЗ, а ПЕРЕКЛЮЧЕНИЕ —
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
Выход
Мы получим следующий вывод —
[ "actors/Keanu" ]

Третий вопрос
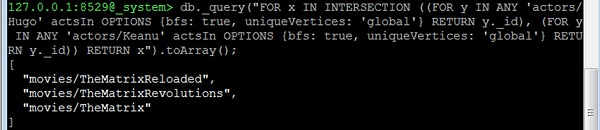
Давайте теперь рассмотрим третий вопрос: все обычные фильмы между «actor1» и «actor2» . Это фактически идентично вопросу об общих актерах в movie1 и movie2. Нам просто нужно изменить начальные вершины. В качестве примера, давайте найдем все фильмы, где Хьюго Уивинг («Хьюго») и Киану Ривз снимаются вместе —
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();
Выход
Мы получим следующий вывод —
[ "movies/TheMatrixReloaded", "movies/TheMatrixRevolutions", "movies/TheMatrix" ]
Четвертый вопрос
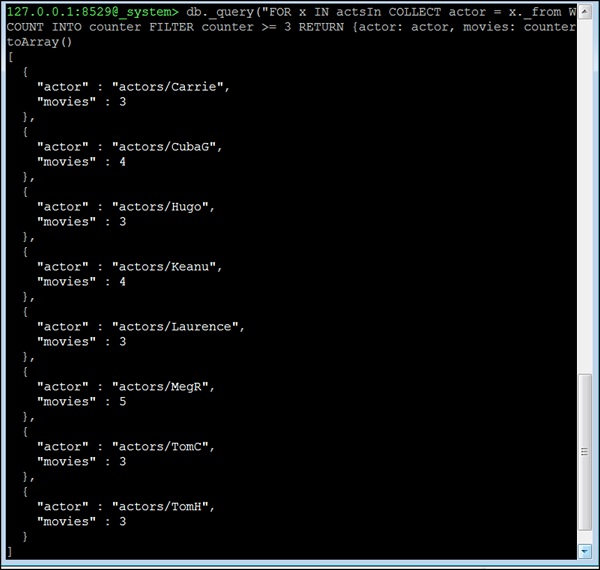
Давайте теперь рассмотрим четвертый вопрос. Все актеры, которые снялись в 3 и более фильмах . Этот вопрос другой; мы не можем использовать функцию соседей здесь. Вместо этого мы будем использовать краевой индекс и оператор COLLECT AQL для группировки. Основная идея состоит в том, чтобы сгруппировать все ребра по их startVertex (который в этом наборе данных всегда является актером). Затем мы удаляем всех актеров с менее чем 3 фильмами из результата, так как здесь мы включили количество фильмов, в которых актер сыграл —
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()
Выход
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
По оставшимся вопросам мы обсудим формирование запроса и предоставим только запросы. Читатель должен выполнить запрос самостоятельно на терминале Arangosh.
Пятый вопрос
Давайте теперь рассмотрим пятый вопрос: все фильмы, в которых снялись ровно 6 актеров . Та же идея, что и в запросе ранее, но с фильтром равенства. Однако теперь нам нужен фильм вместо актера, поэтому мы возвращаем атрибут _to —
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()
Количество актеров по фильмам?
Мы помним в нашем наборе данных _to на краю соответствует фильму, поэтому мы считаем, как часто появляется один и тот же _to . Это количество актеров. Запрос почти идентичен запросам до, но без фильтра после COLLECT —
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()
Шестой вопрос
Давайте теперь рассмотрим шестой вопрос: количество фильмов актера .
То, как мы нашли решения для наших вышеупомянутых запросов, поможет вам найти решение и для этого запроса.
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()
ArangoDB — Как развернуть
В этой главе мы опишем различные возможности для развертывания ArangoDB.
Развертывание: один экземпляр
Мы уже узнали, как развернуть единственный экземпляр Linux (Ubuntu) в одной из наших предыдущих глав. Давайте теперь посмотрим, как сделать развертывание с помощью Docker.
Развертывание: Докер
Для развертывания с использованием docker мы установим Docker на нашу машину. Для получения дополнительной информации о Docker, пожалуйста, обратитесь к нашему руководству по Docker .
После установки Docker вы можете использовать следующую команду —
docker run -e ARANGO_RANDOM_ROOT_PASSWORD = 1 -d --name agdb-foo -d arangodb/arangodb
Он создаст и запустит экземпляр Docker ArangoDB с идентифицирующим именем agdbfoo в качестве фонового процесса Docker.
Также терминал напечатает идентификатор процесса.
По умолчанию порт 8529 зарезервирован для ArangoDB для прослушивания запросов. Также этот порт автоматически доступен для всех контейнеров приложений Docker, которые вы могли связать.