В этой главе мы обсудим протоколы согласованности кэша, чтобы справиться с проблемами несогласованности мультикаша.
Проблема когерентности кэша
В многопроцессорной системе несоответствие данных может происходить среди смежных уровней или в пределах одного уровня иерархии памяти. Например, кэш и основная память могут иметь несовместимые копии одного и того же объекта.
Поскольку несколько процессоров работают параллельно, и независимо несколько кэшей могут иметь разные копии одного и того же блока памяти, это создает проблему когерентности кэша . Схемы согласования кэша помогают избежать этой проблемы, поддерживая единообразное состояние для каждого кэшированного блока данных.
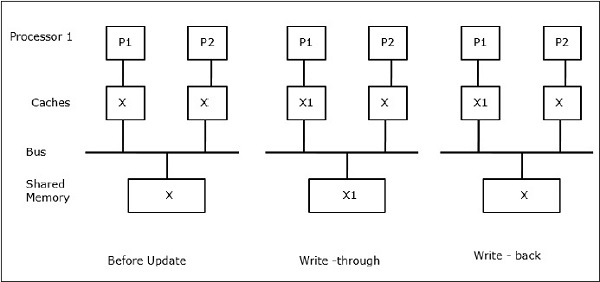
Пусть X будет элементом общих данных, на которые ссылаются два процессора, P1 и P2. В начале три копии X соответствуют. Если процессор P1 записывает новые данные X1 в кэш, используя политику сквозной записи , эта же копия будет немедленно записана в общую память. В этом случае возникает несоответствие между кэш-памятью и основной памятью. Когда используется политика обратной записи , основная память будет обновляться, когда измененные данные в кеше заменяются или становятся недействительными.
В целом, существует три источника проблемы несоответствия —
- Обмен записываемыми данными
- Процесс миграции
- Активность ввода / вывода
Протоколы Snoopy Bus
Протоколы Snoopy обеспечивают согласованность данных между кэш-памятью и разделяемой памятью посредством системы памяти на основе шины. Политики записи-недействительности и записи-обновления используются для поддержания целостности кэша.
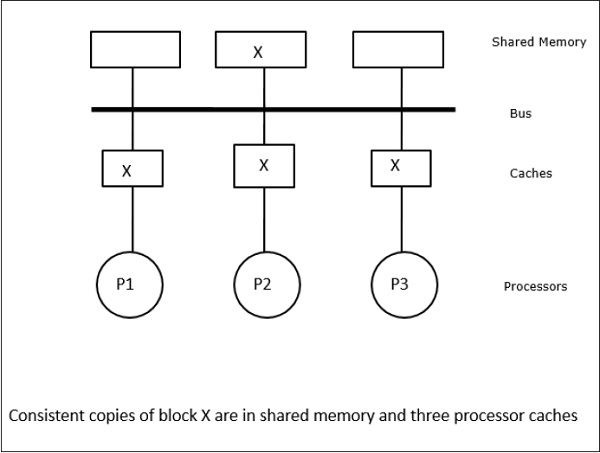
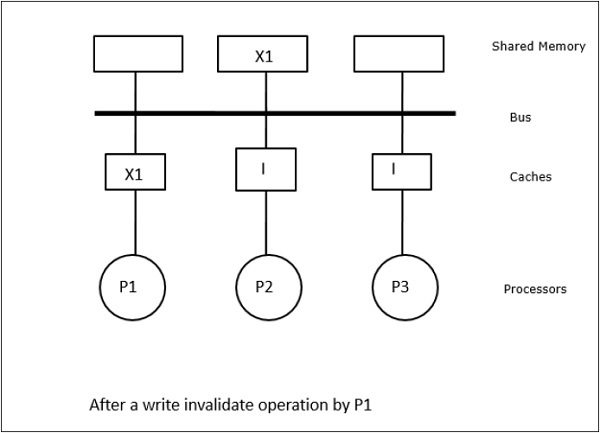
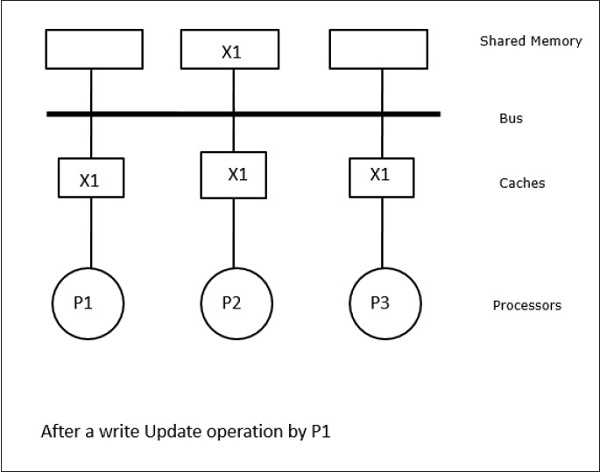
В этом случае у нас есть три процессора P1, P2 и P3, имеющие непротиворечивую копию элемента данных ‘X’ в своей локальной кэш-памяти и в общей памяти (рисунок-а). Процессор P1 записывает X1 в свою кэш-память, используя протокол недействительной записи . Таким образом, все остальные копии становятся недействительными через шину. Он обозначается буквой «Я» (рис. Б). Недействительные блоки также называются грязными , то есть их не следует использовать. Протокол записи-обновления обновляет все копии кэша через шину. При использовании кэша обратной записи копия памяти также обновляется (рисунок-в).
Кэш-события и действия
Следующие события и действия происходят при выполнении команд доступа к памяти и аннулирования —
-
Промах чтения — когда процессор хочет прочитать блок, а его нет в кэше, происходит промах чтения. Это инициирует операцию чтения шины . Если грязной копии не существует, то основная память, которая имеет согласованную копию, передает копию в запрашивающую кэш-память. Если в удаленной кеш-памяти существует грязная копия, этот кеш ограничит основную память и отправит копию в запрашивающую кеш-память. В обоих случаях копия кэша войдет в действительное состояние после пропуска чтения.
-
Хит записи — если копия находится в грязном или зарезервированном состоянии, запись выполняется локально, а новое состояние грязное. Если новое состояние действительно, команда write-invalidate транслируется на все кэши, аннулируя их копии. Когда разделяемая память записывается, результирующее состояние резервируется после этой первой записи.
-
Ошибка записи — если процессору не удается записать в локальную кэш-память, копия должна поступить либо из основной памяти, либо из удаленной кэш-памяти с грязным блоком. Это делается отправкой команды read-invalidate , которая сделает недействительными все копии кэша. Затем локальная копия обновляется с грязным состоянием.
-
Хит чтения — Хит чтения всегда выполняется в локальной кэш-памяти без изменения состояния или использования шины снупи для аннулирования.
-
Замена блока — если копия загрязнена, ее необходимо записать обратно в основную память методом замены блока. Однако, когда копия находится в допустимом, зарезервированном или недействительном состоянии, замена не производится.
Промах чтения — когда процессор хочет прочитать блок, а его нет в кэше, происходит промах чтения. Это инициирует операцию чтения шины . Если грязной копии не существует, то основная память, которая имеет согласованную копию, передает копию в запрашивающую кэш-память. Если в удаленной кеш-памяти существует грязная копия, этот кеш ограничит основную память и отправит копию в запрашивающую кеш-память. В обоих случаях копия кэша войдет в действительное состояние после пропуска чтения.
Хит записи — если копия находится в грязном или зарезервированном состоянии, запись выполняется локально, а новое состояние грязное. Если новое состояние действительно, команда write-invalidate транслируется на все кэши, аннулируя их копии. Когда разделяемая память записывается, результирующее состояние резервируется после этой первой записи.
Ошибка записи — если процессору не удается записать в локальную кэш-память, копия должна поступить либо из основной памяти, либо из удаленной кэш-памяти с грязным блоком. Это делается отправкой команды read-invalidate , которая сделает недействительными все копии кэша. Затем локальная копия обновляется с грязным состоянием.
Хит чтения — Хит чтения всегда выполняется в локальной кэш-памяти без изменения состояния или использования шины снупи для аннулирования.
Замена блока — если копия загрязнена, ее необходимо записать обратно в основную память методом замены блока. Однако, когда копия находится в допустимом, зарезервированном или недействительном состоянии, замена не производится.
Протоколы на основе каталогов
Используя многоступенчатую сеть для создания большого мультипроцессора с сотнями процессоров, необходимо изменить протоколы Snoopy Cache для соответствия возможностям сети. Широковещательная передача, являющаяся очень дорогой для выполнения в многоступенчатой сети, команды согласованности отправляются только тем кэшам, которые хранят копию блока. Это является причиной разработки протоколов на основе каталогов для мультипроцессоров, подключенных к сети.
В системе протоколов на основе каталогов данные, подлежащие обмену, помещаются в общий каталог, который поддерживает согласованность между кэшами. Здесь каталог действует как фильтр, где процессоры запрашивают разрешение на загрузку записи из первичной памяти в свою кеш-память. Если запись изменяется, каталог либо обновляет ее, либо делает недействительными другие кэши с этой записью.
Механизмы аппаратной синхронизации
Синхронизация — это особая форма связи, где вместо управления данными происходит обмен информацией между процессами связи, находящимися в одном или разных процессорах.
Многопроцессорные системы используют аппаратные механизмы для реализации низкоуровневых операций синхронизации. Большинство мультипроцессоров имеют аппаратные механизмы для наложения атомарных операций, таких как операции чтения из памяти, записи или чтения-изменения-записи, для реализации некоторых примитивов синхронизации. Помимо операций с атомарной памятью, некоторые межпроцессорные прерывания также используются для целей синхронизации.
Когерентность кэша в машинах с общей памятью
Поддержание когерентности кэша является проблемой в многопроцессорной системе, когда процессоры содержат локальную кэш-память. Несоответствие данных между различными кешами легко происходит в этой системе.
Основные проблемные области —
- Обмен записываемыми данными
- Процесс миграции
- Активность ввода / вывода
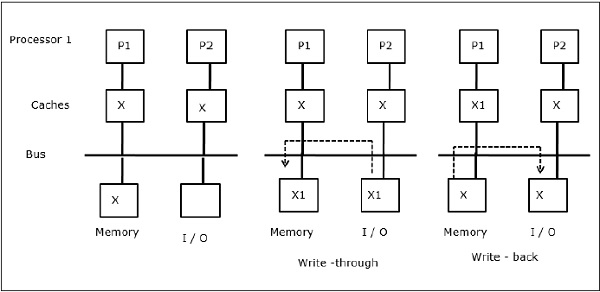
Обмен записываемыми данными
Когда два процессора (P1 и P2) имеют один и тот же элемент данных (X) в своих локальных кэшах, и один процесс (P1) выполняет запись в элемент данных (X), поскольку кэш-память — это локальный кэш P1 сквозной записи, основная память Также обновлено. Теперь, когда P2 пытается прочитать элемент данных (X), он не находит X, потому что элемент данных в кэше P2 устарел.
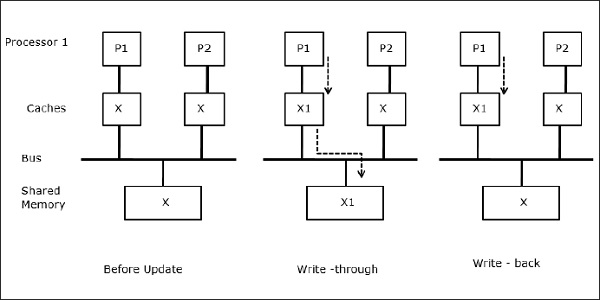
Процесс миграции
На первом этапе кеш P1 содержит элемент данных X, тогда как P2 ничего не имеет. Процесс на P2 сначала записывает на X, а затем мигрирует на P1. Теперь процесс начинает чтение элемента данных X, но, поскольку процессор P1 устарел, данные не могут быть прочитаны. Итак, процесс в P1 записывает данные в элемент X и затем мигрирует в P2. После миграции процесс на P2 начинает считывать элемент данных X, но обнаруживает устаревшую версию X в основной памяти.
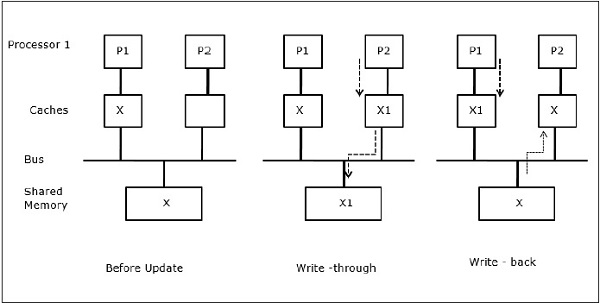
Активность ввода / вывода
Как показано на рисунке, устройство ввода-вывода добавляется к шине в двухпроцессорной многопроцессорной архитектуре. В начале оба кэша содержат элемент данных X. Когда устройство ввода-вывода получает новый элемент X, оно сохраняет новый элемент непосредственно в основной памяти. Теперь, когда P1 или P2 (предположим, P1) пытается прочитать элемент X, он получает устаревшую копию. Итак, P1 выполняет запись в элемент X. Теперь, если устройство ввода-вывода пытается передать X, оно получает устаревшую копию.
Единый доступ к памяти (UMA)
Архитектура унифицированного доступа к памяти (UMA) означает, что общая память одинакова для всех процессоров в системе. Популярными классами машин UMA, которые обычно используются для (файловых) серверов, являются так называемые симметричные мультипроцессоры (SMP). В SMP все системные ресурсы, такие как память, диски, другие устройства ввода-вывода и т. Д., Доступны процессорам единообразно.
Неравномерный доступ к памяти (NUMA)
В архитектуре NUMA есть несколько кластеров SMP, имеющих внутреннюю непрямую / совместно используемую сеть, которые связаны в масштабируемую сеть передачи сообщений. Итак, архитектура NUMA — это логически распределенная физически распределенная архитектура памяти.
В машине NUMA кэш-контроллер процессора определяет, является ли ссылка на память локальной памятью SMP или удаленной. Чтобы уменьшить количество удаленных обращений к памяти, архитектуры NUMA обычно применяют процессоры кэширования, которые могут кэшировать удаленные данные. Но когда задействованы кеши, необходимо поддерживать когерентность кеша. Таким образом, эти системы также известны как CC-NUMA (Cache Coherent NUMA).
Архитектура кэш-памяти только (COMA)
Машины COMA аналогичны машинам NUMA, с той лишь разницей, что основная память машин COMA выступает в качестве кэшей с прямым отображением или ассоциативным множеством. Блоки данных хешируются в месте в кеше DRAM в соответствии с их адресами. Данные, которые извлекаются удаленно, на самом деле хранятся в локальной основной памяти. Более того, блоки данных не имеют фиксированного домашнего местоположения, они могут свободно перемещаться по всей системе.
Архитектуры COMA в основном имеют иерархическую сеть передачи сообщений. Переключатель в таком дереве содержит каталог с элементами данных в качестве своего поддерева. Поскольку данные не имеют домашнего местоположения, их нужно явно искать. Это означает, что удаленный доступ требует обхода по коммутаторам в дереве для поиска в их каталогах требуемых данных. Таким образом, если коммутатор в сети получает несколько запросов от своего поддерева для одних и тех же данных, он объединяет их в один запрос, который отправляется родителю коммутатора. Когда запрашиваемые данные возвращаются, коммутатор отправляет несколько копий по своему поддереву.
COMA против CC-NUMA
Ниже приведены различия между COMA и CC-NUMA.
COMA имеет тенденцию быть более гибким, чем CC-NUMA, потому что COMA прозрачно поддерживает миграцию и репликацию данных без необходимости в ОС.
Машины COMA дороги и сложны в сборке, потому что им требуется нестандартное оборудование для управления памятью, а протокол когерентности сложнее реализовать.
Удаленный доступ в COMA часто медленнее, чем в CC-NUMA, поскольку для поиска данных необходимо пройти через древовидную сеть.