Параллельная обработка была разработана как эффективная технология в современных компьютерах для удовлетворения потребностей в более высокой производительности, низкой стоимости и точных результатах в реальных приложениях. Параллельные события распространены на современных компьютерах из-за практики многопрограммирования, многопроцессорности или мультикомпьютера.
Современные компьютеры имеют мощные и обширные программные пакеты. Чтобы проанализировать развитие производительности компьютеров, сначала мы должны понять основные разработки аппаратного и программного обеспечения.
-
Основные этапы развития компьютера — Есть два основных этапа развития компьютера — механические или электромеханические части. Современные компьютеры развивались после внедрения электронных компонентов. Электроны с высокой подвижностью в электронных компьютерах заменили рабочие части в механических компьютерах. Для передачи информации электрический сигнал, который распространяется почти со скоростью света, заменяется механическими передачами или рычагами.
-
Элементы современных компьютеров . Современная компьютерная система состоит из компьютерного оборудования, наборов команд, прикладных программ, системного программного обеспечения и пользовательского интерфейса.
Основные этапы развития компьютера — Есть два основных этапа развития компьютера — механические или электромеханические части. Современные компьютеры развивались после внедрения электронных компонентов. Электроны с высокой подвижностью в электронных компьютерах заменили рабочие части в механических компьютерах. Для передачи информации электрический сигнал, который распространяется почти со скоростью света, заменяется механическими передачами или рычагами.
Элементы современных компьютеров . Современная компьютерная система состоит из компьютерного оборудования, наборов команд, прикладных программ, системного программного обеспечения и пользовательского интерфейса.
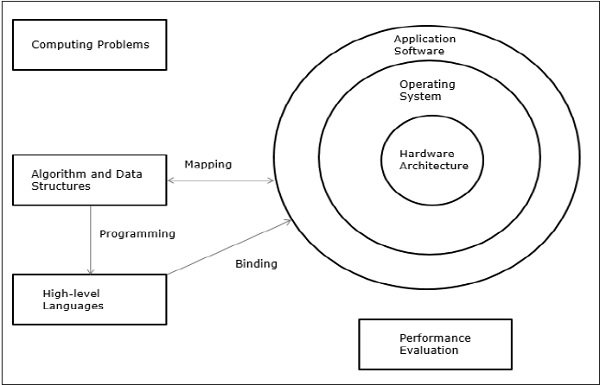
Компьютерные проблемы подразделяются на числовые вычисления, логические рассуждения и обработку транзакций. Некоторые сложные проблемы могут потребовать комбинации всех трех режимов обработки.
-
Эволюция компьютерной архитектуры. За последние четыре десятилетия компьютерная архитектура претерпела революционные изменения. Мы начали с архитектуры фон Неймана, и теперь у нас есть мультикомпьютеры и мультипроцессоры.
-
Производительность компьютерной системы. Производительность компьютерной системы зависит как от возможностей машины, так и от поведения программы. Возможности машины могут быть улучшены с помощью лучших аппаратных технологий, передовых архитектурных функций и эффективного управления ресурсами. Поведение программы непредсказуемо, так как оно зависит от приложения и условий выполнения
Эволюция компьютерной архитектуры. За последние четыре десятилетия компьютерная архитектура претерпела революционные изменения. Мы начали с архитектуры фон Неймана, и теперь у нас есть мультикомпьютеры и мультипроцессоры.
Производительность компьютерной системы. Производительность компьютерной системы зависит как от возможностей машины, так и от поведения программы. Возможности машины могут быть улучшены с помощью лучших аппаратных технологий, передовых архитектурных функций и эффективного управления ресурсами. Поведение программы непредсказуемо, так как оно зависит от приложения и условий выполнения
Мультипроцессоры и мультикомпьютеры
В этом разделе мы обсудим два типа параллельных компьютеров —
- Мультипроцессоры
- Мультикомпьютеры
Мультикомпьютеры с общей памятью
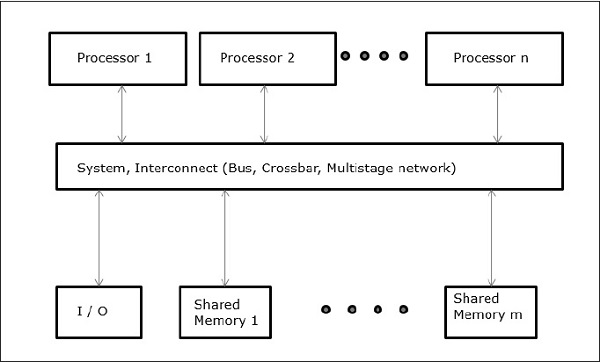
Три наиболее распространенные модели мультипроцессоров с общей памятью —
Единый доступ к памяти (UMA)
В этой модели все процессоры равномерно распределяют физическую память. Все процессоры имеют одинаковое время доступа ко всем словам памяти. Каждый процессор может иметь личную кеш-память. То же правило соблюдается для периферийных устройств.
Когда все процессоры имеют равный доступ ко всем периферийным устройствам, система называется симметричным мультипроцессором . Когда только один или несколько процессоров могут получить доступ к периферийным устройствам, система называется асимметричным мультипроцессором .
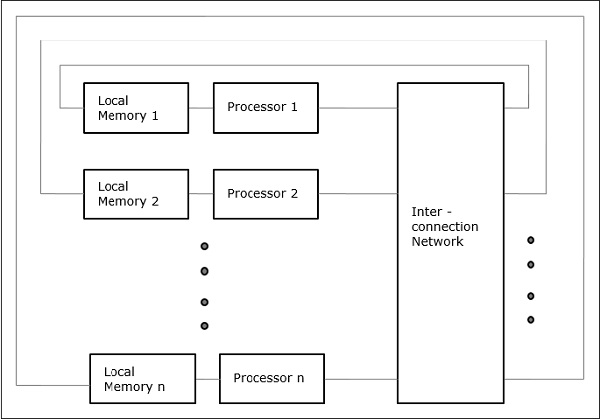
Неоднородный доступ к памяти (NUMA)
В многопроцессорной модели NUMA время доступа зависит от местоположения слова памяти. Здесь разделяемая память физически распределяется между всеми процессорами, называемой локальной памятью. Коллекция всей локальной памяти образует глобальное адресное пространство, к которому могут обращаться все процессоры.
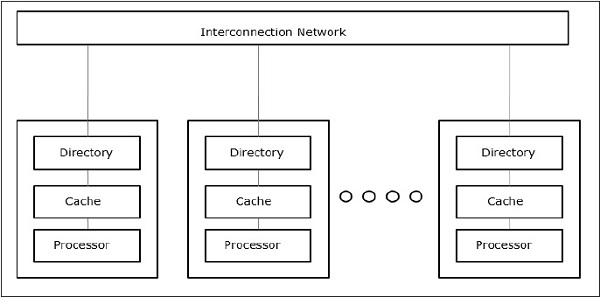
Архитектура кэш-памяти только (COMA)
Модель COMA является частным случаем модели NUMA. Здесь все распределенные основные памяти преобразуются в кэш-память.
-
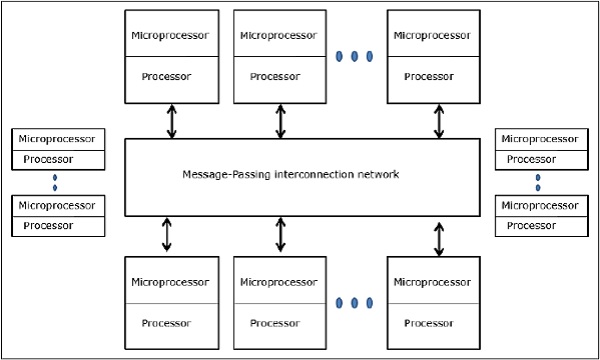
Мультикомпьютеры с распределенной памятью. Мультикомпьютерная система с распределенной памятью состоит из нескольких компьютеров, известных как узлы, соединенные между собой сетью передачи сообщений. Каждый узел действует как автономный компьютер, имеющий процессор, локальную память и иногда устройства ввода-вывода. В этом случае все локальные воспоминания являются частными и доступны только для локальных процессоров. Вот почему традиционные машины называются машинами без удаленного доступа к памяти (NORMA) .
Мультикомпьютеры с распределенной памятью. Мультикомпьютерная система с распределенной памятью состоит из нескольких компьютеров, известных как узлы, соединенные между собой сетью передачи сообщений. Каждый узел действует как автономный компьютер, имеющий процессор, локальную память и иногда устройства ввода-вывода. В этом случае все локальные воспоминания являются частными и доступны только для локальных процессоров. Вот почему традиционные машины называются машинами без удаленного доступа к памяти (NORMA) .
Мультивектор и SIMD Компьютеры
В этом разделе мы обсудим суперкомпьютеры и параллельные процессоры для векторной обработки и параллелизма данных.
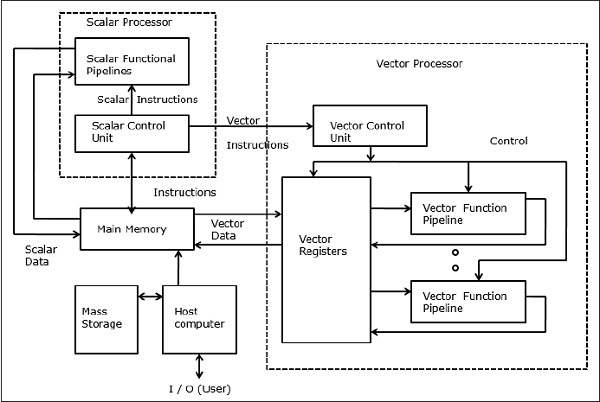
Вектор Суперкомпьютеры
В векторном компьютере векторный процессор присоединяется к скалярному процессору в качестве дополнительной функции. Хост-компьютер сначала загружает программу и данные в основную память. Затем скалярный блок управления декодирует все инструкции. Если декодированные инструкции являются скалярными операциями или программными операциями, скалярный процессор выполняет эти операции, используя скалярные функциональные конвейеры.
С другой стороны, если декодированные инструкции являются векторными операциями, то инструкции будут отправлены в модуль векторного управления.
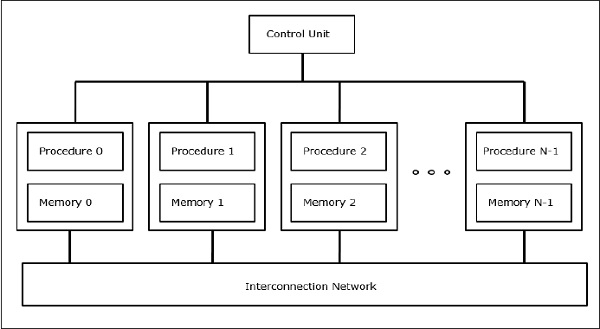
SIMD Суперкомпьютеры
В компьютерах SIMD число процессоров N связано с блоком управления, и все процессоры имеют свои отдельные блоки памяти. Все процессоры связаны между собой сетью.
Модели PRAM и VLSI
Идеальная модель дает подходящую основу для разработки параллельных алгоритмов без учета физических ограничений или деталей реализации.
Модели могут быть применены для получения теоретических ограничений производительности на параллельных компьютерах или для оценки сложности СБИС в области чипа и времени работы до его изготовления.
Параллельные машины с произвольным доступом
Шепердсон и Стерджис (1963) смоделировали обычные однопроцессорные компьютеры как машины с произвольным доступом (ОЗУ). Fortune и Wyllie (1978) разработали модель машины с произвольным доступом (PRAM) для моделирования идеализированного параллельного компьютера с нулевыми затратами на доступ к памяти и синхронизацией.
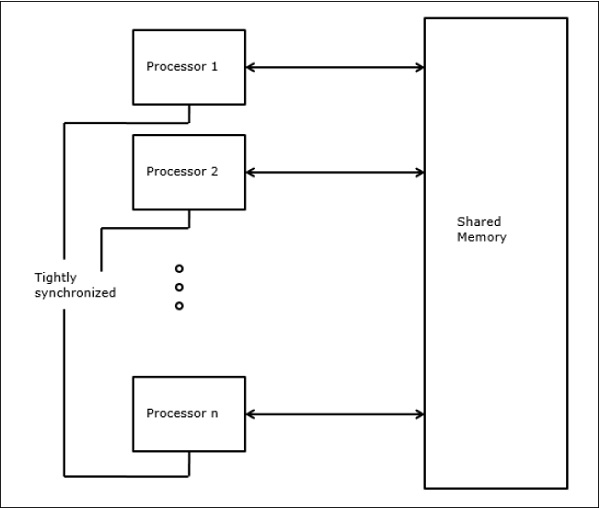
N-процессор PRAM имеет блок общей памяти. Эта общая память может быть централизована или распределена между процессорами. Эти процессоры работают в синхронизированном цикле чтения-записи, записи-памяти и вычислительного цикла. Таким образом, эти модели определяют, как обрабатываются параллельные операции чтения и записи.
Ниже приведены возможные операции обновления памяти.
-
Эксклюзивное чтение (ER). В этом методе в каждом цикле только один процессор может читать из любой области памяти.
-
Эксклюзивная запись (EW). В этом методе по крайней мере один процессор может одновременно выполнять запись в область памяти.
-
Одновременное чтение (CR) — позволяет нескольким процессорам считывать одну и ту же информацию из одной и той же области памяти в одном цикле.
-
Параллельная запись (CW) — позволяет одновременные операции записи в одну и ту же область памяти. Чтобы избежать конфликта записи, настроены некоторые политики.
Эксклюзивное чтение (ER). В этом методе в каждом цикле только один процессор может читать из любой области памяти.
Эксклюзивная запись (EW). В этом методе по крайней мере один процессор может одновременно выполнять запись в область памяти.
Одновременное чтение (CR) — позволяет нескольким процессорам считывать одну и ту же информацию из одной и той же области памяти в одном цикле.
Параллельная запись (CW) — позволяет одновременные операции записи в одну и ту же область памяти. Чтобы избежать конфликта записи, настроены некоторые политики.
Модель сложности СБИС
Параллельные компьютеры используют микросхемы VLSI для изготовления процессорных массивов, массивов памяти и крупных коммутационных сетей.
В настоящее время технологии СБИС являются двухмерными. Размер чипа VLSI пропорционален объему памяти (памяти), доступной в этом чипе.
Мы можем вычислить пространственную сложность алгоритма по площади чипа (A) реализации чипа VLSI этого алгоритма. Если T — это время (задержка), необходимое для выполнения алгоритма, то AT задает верхнюю границу общего числа битов, обработанных с помощью чипа (или ввода-вывода). Для некоторых вычислений существует нижняя граница f (s), такая что
AT 2 > = O (f (s))
Где A = площадь чипа и T = время
Треки архитектурного развития
Эволюция параллельных компьютеров я распространил по следующим трекам —
- Несколько треков процессора
- Многопроцессорная дорожка
- Мультикомпьютерный трек
- Несколько данных трек
- Векторный трек
- SIMD трек
- Отслеживание нескольких потоков
- Многопоточный трек
- Отслеживание потока данных
В многопроцессорной дорожке предполагается, что разные потоки выполняются одновременно на разных процессорах и обмениваются данными через общую память (многопроцессорная дорожка) или систему передачи сообщений (многопользовательская дорожка).
При множественном отслеживании данных предполагается, что один и тот же код выполняется для огромного количества данных. Это выполняется путем выполнения одних и тех же инструкций для последовательности элементов данных (векторная дорожка) или посредством выполнения одной и той же последовательности инструкций для аналогичного набора данных (SIMD-дорожка).
При отслеживании нескольких потоков предполагается, что выполняется чередование различных потоков на одном и том же процессоре, чтобы скрыть задержки синхронизации между потоками, выполняющимися на разных процессорах. Чередование потоков может быть грубым (многопоточная дорожка) или точным (дорожка потока данных).