Хранилище данных — Обзор
Термин «Хранилище данных» был впервые введен Биллом Инмоном в 1990 году. По словам Инмона, хранилище данных представляет собой предметно-ориентированный, интегрированный, изменяющийся во времени и энергонезависимый сбор данных. Эти данные помогают аналитикам принимать обоснованные решения в организации.
Операционная база данных ежедневно подвергается частым изменениям из-за проводимых транзакций. Предположим, что руководитель бизнеса хочет проанализировать предыдущие отзывы о любых данных, таких как продукт, поставщик или любые данные о потребителе, тогда у руководителя не будет данных, доступных для анализа, поскольку предыдущие данные были обновлены в результате транзакций.
Хранилища данных предоставляют нам обобщенные и консолидированные данные в многомерном представлении. Наряду с обобщенным и консолидированным представлением данных хранилища данных также предоставляют нам инструменты онлайн-аналитической обработки (OLAP). Эти инструменты помогают нам в интерактивном и эффективном анализе данных в многомерном пространстве. Этот анализ приводит к обобщению данных и интеллектуальному анализу данных.
Функции интеллектуального анализа данных, такие как сопоставление, кластеризация, классификация, прогнозирование, могут быть интегрированы с операциями OLAP для улучшения интерактивного интеллектуального анализа знаний на нескольких уровнях абстракции. Вот почему хранилище данных стало важной платформой для анализа данных и аналитической обработки в Интернете.
Понимание хранилища данных
-
Хранилище данных — это база данных, которая хранится отдельно от оперативной базы данных организации.
-
В хранилище данных нет частых обновлений.
-
Он обладает консолидированными историческими данными, которые помогают организации анализировать свой бизнес.
-
Хранилище данных помогает руководителям организовывать, понимать и использовать свои данные для принятия стратегических решений.
-
Системы хранилища данных помогают в интеграции разнообразных прикладных систем.
-
Система хранилища данных помогает в консолидированном анализе исторических данных.
Хранилище данных — это база данных, которая хранится отдельно от оперативной базы данных организации.
В хранилище данных нет частых обновлений.
Он обладает консолидированными историческими данными, которые помогают организации анализировать свой бизнес.
Хранилище данных помогает руководителям организовывать, понимать и использовать свои данные для принятия стратегических решений.
Системы хранилища данных помогают в интеграции разнообразных прикладных систем.
Система хранилища данных помогает в консолидированном анализе исторических данных.
Почему хранилище данных отделено от оперативных баз данных
Хранилища данных хранятся отдельно от операционных баз данных по следующим причинам:
-
Оперативная база данных создается для хорошо известных задач и рабочих нагрузок, таких как поиск определенных записей, индексация и т. Д. В контрактах запросы к хранилищу данных часто являются сложными и представляют общую форму данных.
-
Операционные базы данных поддерживают одновременную обработку нескольких транзакций. Механизмы контроля и восстановления параллелизма требуются для действующих баз данных, чтобы обеспечить надежность и согласованность базы данных.
-
Оперативный запрос к базе данных позволяет читать и изменять операции, тогда как для запроса OLAP требуется только доступ только для чтения к сохраненным данным.
-
Оперативная база данных поддерживает текущие данные. С другой стороны, хранилище данных поддерживает исторические данные.
Оперативная база данных создается для хорошо известных задач и рабочих нагрузок, таких как поиск определенных записей, индексация и т. Д. В контрактах запросы к хранилищу данных часто являются сложными и представляют общую форму данных.
Операционные базы данных поддерживают одновременную обработку нескольких транзакций. Механизмы контроля и восстановления параллелизма требуются для действующих баз данных, чтобы обеспечить надежность и согласованность базы данных.
Оперативный запрос к базе данных позволяет читать и изменять операции, тогда как для запроса OLAP требуется только доступ только для чтения к сохраненным данным.
Оперативная база данных поддерживает текущие данные. С другой стороны, хранилище данных поддерживает исторические данные.
Особенности хранилища данных
Ключевые особенности хранилища данных обсуждаются ниже —
-
Предметно-ориентированный. Хранилище данных является предметно-ориентированным, поскольку предоставляет информацию по предмету, а не по текущим операциям организации. Такими субъектами могут быть продукт, клиенты, поставщики, продажи, выручка и т. Д. Хранилище данных не ориентировано на текущие операции, а сосредоточено на моделировании и анализе данных для принятия решений.
-
Интегрированный. Хранилище данных создается путем интеграции данных из разнородных источников, таких как реляционные базы данных, плоские файлы и т. Д. Эта интеграция повышает эффективность анализа данных.
-
Вариант времени — данные, собранные в хранилище данных, идентифицируются с определенным периодом времени. Данные в хранилище данных предоставляют информацию с исторической точки зрения.
-
Энергонезависимый — энергонезависимый означает, что предыдущие данные не удаляются при добавлении новых данных. Хранилище данных хранится отдельно от оперативной базы данных, и поэтому частые изменения в оперативной базе данных не отражаются в хранилище данных.
Предметно-ориентированный. Хранилище данных является предметно-ориентированным, поскольку предоставляет информацию по предмету, а не по текущим операциям организации. Такими субъектами могут быть продукт, клиенты, поставщики, продажи, выручка и т. Д. Хранилище данных не ориентировано на текущие операции, а сосредоточено на моделировании и анализе данных для принятия решений.
Интегрированный. Хранилище данных создается путем интеграции данных из разнородных источников, таких как реляционные базы данных, плоские файлы и т. Д. Эта интеграция повышает эффективность анализа данных.
Вариант времени — данные, собранные в хранилище данных, идентифицируются с определенным периодом времени. Данные в хранилище данных предоставляют информацию с исторической точки зрения.
Энергонезависимый — энергонезависимый означает, что предыдущие данные не удаляются при добавлении новых данных. Хранилище данных хранится отдельно от оперативной базы данных, и поэтому частые изменения в оперативной базе данных не отражаются в хранилище данных.
Примечание. Хранилище данных не требует обработки транзакций, восстановления и управления параллелизмом, поскольку оно физически хранится и отделено от операционной базы данных.
Приложения хранилища данных
Как обсуждалось ранее, хранилище данных помогает руководителям предприятий организовывать, анализировать и использовать свои данные для принятия решений. Хранилище данных служит единственной частью системы обратной связи «план-выполнение-оценка» для управления предприятием. Хранилища данных широко используются в следующих областях —
- Финансовые услуги
- Банковские услуги
- Потребительские товары
- Розничные секторы
- Контролируемое производство
Типы хранилищ данных
Обработка информации, аналитическая обработка и извлечение данных — это три типа приложений хранилища данных, которые обсуждаются ниже:
-
Обработка информации — хранилище данных позволяет обрабатывать хранящиеся в нем данные. Данные могут быть обработаны с помощью запросов, базового статистического анализа, отчетности с использованием кросс-таблиц, таблиц, диаграмм или графиков.
-
Аналитическая обработка — хранилище данных поддерживает аналитическую обработку информации, хранящейся в нем. Данные можно анализировать с помощью базовых операций OLAP, включая срезы и детали, детализацию, детализацию и поворот.
-
Интеллектуальный анализ данных. Интеллектуальный анализ данных поддерживает обнаружение знаний путем поиска скрытых закономерностей и ассоциаций, построения аналитических моделей, выполнения классификации и прогнозирования. Эти результаты добычи могут быть представлены с использованием инструментов визуализации.
Обработка информации — хранилище данных позволяет обрабатывать хранящиеся в нем данные. Данные могут быть обработаны с помощью запросов, базового статистического анализа, отчетности с использованием кросс-таблиц, таблиц, диаграмм или графиков.
Аналитическая обработка — хранилище данных поддерживает аналитическую обработку информации, хранящейся в нем. Данные можно анализировать с помощью базовых операций OLAP, включая срезы и детали, детализацию, детализацию и поворот.
Интеллектуальный анализ данных. Интеллектуальный анализ данных поддерживает обнаружение знаний путем поиска скрытых закономерностей и ассоциаций, построения аналитических моделей, выполнения классификации и прогнозирования. Эти результаты добычи могут быть представлены с использованием инструментов визуализации.
| Sr.No. | Хранилище данных (OLAP) | Оперативная база данных (OLTP) |
|---|---|---|
| 1 | Он включает в себя историческую обработку информации. | Это включает в себя ежедневную обработку. |
| 2 | OLAP-системы используются работниками умственного труда, такими как руководители, менеджеры и аналитики. | Системы OLTP используются клерками, администраторами баз данных или специалистами по базам данных. |
| 3 | Он используется для анализа бизнеса. | Он используется для ведения бизнеса. |
| 4 | Это сосредотачивается на Информации. | Он фокусируется на данных в. |
| 5 | Он основан на схеме «звезда», «снежинка» и «схеме фактов». | Он основан на модели отношений сущностей. |
| 6 | Это сосредотачивается на Информации. | Это ориентировано на приложения. |
| 7 | Содержит исторические данные. | Содержит текущие данные. |
| 8 | Он предоставляет обобщенные и сводные данные. | Он предоставляет примитивные и очень подробные данные. |
| 9 | Он обеспечивает обобщенное и многомерное представление данных. | Это обеспечивает детальное и плоское реляционное представление данных. |
| 10 | Количество пользователей исчисляется сотнями. | Количество пользователей в тысячах. |
| 11 | Количество записей, к которым осуществляется доступ, исчисляется миллионами. | Количество записей достигло десятков. |
| 12 | Размер базы данных составляет от 100 ГБ до 100 ТБ. | Размер базы данных составляет от 100 МБ до 100 ГБ. |
| 13 | Это очень гибкие. | Это обеспечивает высокую производительность. |
Хранилище данных — Концепции
Что такое хранилище данных?
Хранилище данных — это процесс создания и использования хранилища данных. Хранилище данных создается путем интеграции данных из нескольких разнородных источников, которые поддерживают аналитическую отчетность, структурированные и / или специальные запросы и принятие решений. Хранилище данных включает в себя очистку данных, интеграцию данных и консолидацию данных.
Использование информации о хранилище данных
Существуют технологии поддержки принятия решений, которые помогают использовать данные, доступные в хранилище данных. Эти технологии помогают руководителям быстро и эффективно использовать склад. Они могут собирать данные, анализировать их и принимать решения на основе информации, представленной на складе. Собранную на складе информацию можно использовать в любом из следующих доменов:
-
Настройка производственных стратегий — Стратегии продуктов можно хорошо настроить, переставив продукты и управляя портфелями продуктов, сравнивая продажи ежеквартально или ежегодно.
-
Анализ клиента — анализ клиента выполняется путем анализа покупательских предпочтений, времени покупки, бюджетных циклов и т. Д.
-
Анализ операций — хранилище данных также помогает в управлении взаимоотношениями с клиентами и внесении исправлений в окружающую среду. Информация также позволяет нам анализировать бизнес-операции.
Настройка производственных стратегий — Стратегии продуктов можно хорошо настроить, переставив продукты и управляя портфелями продуктов, сравнивая продажи ежеквартально или ежегодно.
Анализ клиента — анализ клиента выполняется путем анализа покупательских предпочтений, времени покупки, бюджетных циклов и т. Д.
Анализ операций — хранилище данных также помогает в управлении взаимоотношениями с клиентами и внесении исправлений в окружающую среду. Информация также позволяет нам анализировать бизнес-операции.
Интеграция гетерогенных баз данных
Для интеграции разнородных баз данных у нас есть два подхода —
- Подход, основанный на запросах
- Обновленный подход
Query-Driven подход
Это традиционный подход к интеграции разнородных баз данных. Этот подход использовался для создания оболочек и интеграторов поверх множества разнородных баз данных. Эти интеграторы также известны как посредники.
Процесс Query-Driven подход
-
Когда запрос выдается на стороне клиента, словарь метаданных преобразует запрос в соответствующую форму для отдельных разнородных сайтов.
-
Теперь эти запросы отображаются и отправляются локальному обработчику запросов.
-
Результаты из разнородных сайтов интегрированы в глобальный набор ответов.
Когда запрос выдается на стороне клиента, словарь метаданных преобразует запрос в соответствующую форму для отдельных разнородных сайтов.
Теперь эти запросы отображаются и отправляются локальному обработчику запросов.
Результаты из разнородных сайтов интегрированы в глобальный набор ответов.
Недостатки
-
Подход, основанный на запросах, требует сложных процессов интеграции и фильтрации.
-
Этот подход очень неэффективен.
-
Это очень дорого для частых запросов.
-
Этот подход также очень дорог для запросов, которые требуют агрегирования.
Подход, основанный на запросах, требует сложных процессов интеграции и фильтрации.
Этот подход очень неэффективен.
Это очень дорого для частых запросов.
Этот подход также очень дорог для запросов, которые требуют агрегирования.
Обновленный подход
Это альтернатива традиционному подходу. Современные системы хранения данных следуют подходу, основанному на обновлениях, а не традиционному подходу, который обсуждался ранее. В подходе на основе обновлений информация из нескольких разнородных источников заранее интегрируется и хранится на складе. Эта информация доступна для прямого запроса и анализа.
преимущества
Этот подход имеет следующие преимущества —
-
Такой подход обеспечивает высокую производительность.
-
Данные копируются, обрабатываются, интегрируются, аннотируются, суммируются и реструктурируются в хранилище семантических данных заранее.
-
Обработка запросов не требует интерфейса для обработки данных в локальных источниках.
Такой подход обеспечивает высокую производительность.
Данные копируются, обрабатываются, интегрируются, аннотируются, суммируются и реструктурируются в хранилище семантических данных заранее.
Обработка запросов не требует интерфейса для обработки данных в локальных источниках.
Функции инструментов и утилит хранилища данных
Ниже приведены функции инструментов и утилит хранилища данных —
-
Извлечение данных — включает сбор данных из нескольких разнородных источников.
-
Очистка данных — включает поиск и исправление ошибок в данных.
-
Преобразование данных — включает преобразование данных из прежнего формата в формат хранилища.
-
Загрузка данных — включает в себя сортировку, суммирование, консолидацию, проверку целостности и создание индексов и разделов.
-
Обновление — включает обновление из источников данных в хранилище.
Извлечение данных — включает сбор данных из нескольких разнородных источников.
Очистка данных — включает поиск и исправление ошибок в данных.
Преобразование данных — включает преобразование данных из прежнего формата в формат хранилища.
Загрузка данных — включает в себя сортировку, суммирование, консолидацию, проверку целостности и создание индексов и разделов.
Обновление — включает обновление из источников данных в хранилище.
Примечание. Очистка данных и преобразование данных являются важными шагами в улучшении качества данных и результатов анализа данных.
Хранилище данных — терминология
В этой главе мы обсудим некоторые наиболее часто используемые термины в хранилищах данных.
Метаданные
Метаданные просто определяются как данные о данных. Данные, которые используются для представления других данных, называются метаданными. Например, индекс книги служит метаданными для содержания в книге. Другими словами, мы можем сказать, что метаданные — это обобщенные данные, которые приводят нас к подробным данным.
С точки зрения хранилища данных, мы можем определить метаданные следующим образом:
-
Метаданные — это дорожная карта к хранилищу данных.
-
Метаданные в хранилище данных определяют объекты хранилища.
-
Метаданные действуют как каталог. Этот каталог помогает системе поддержки принятия решений определить местонахождение хранилища данных.
Метаданные — это дорожная карта к хранилищу данных.
Метаданные в хранилище данных определяют объекты хранилища.
Метаданные действуют как каталог. Этот каталог помогает системе поддержки принятия решений определить местонахождение хранилища данных.
Хранилище метаданных
Хранилище метаданных является неотъемлемой частью системы хранилища данных. Он содержит следующие метаданные —
-
Бизнес-метаданные. Содержит информацию о владельце данных, определение бизнеса и изменяющиеся политики.
-
Операционные метаданные — включает в себя валюту данных и линии данных. Денежная единица данных относится к активным, архивным или очищенным данным. Линия данных означает историю перенесенных данных и применяемые к ним преобразования.
-
Данные для отображения из операционной среды в хранилище данных. Эти метаданные включают исходные базы данных и их содержимое, извлечение данных, разделение данных, правила очистки, преобразования, правила обновления и очистки данных.
-
Алгоритмы суммирования — включает алгоритмы измерений, данные о гранулярности, агрегации, суммировании и т. Д.
Бизнес-метаданные. Содержит информацию о владельце данных, определение бизнеса и изменяющиеся политики.
Операционные метаданные — включает в себя валюту данных и линии данных. Денежная единица данных относится к активным, архивным или очищенным данным. Линия данных означает историю перенесенных данных и применяемые к ним преобразования.
Данные для отображения из операционной среды в хранилище данных. Эти метаданные включают исходные базы данных и их содержимое, извлечение данных, разделение данных, правила очистки, преобразования, правила обновления и очистки данных.
Алгоритмы суммирования — включает алгоритмы измерений, данные о гранулярности, агрегации, суммировании и т. Д.
Куб данных
Куб данных помогает нам представлять данные в нескольких измерениях. Это определяется размерами и фактами. Измерения — это объекты, в отношении которых предприятие сохраняет записи.
Иллюстрация куба данных
Предположим, что компания хочет отслеживать записи о продажах с помощью хранилища данных о продажах относительно времени, позиции, филиала и местоположения. Эти размеры позволяют отслеживать ежемесячные продажи и в каком филиале были проданы товары. Существует таблица, связанная с каждым измерением. Эта таблица называется таблицей измерений. Например, таблица измерений «item» может иметь такие атрибуты, как item_name, item_type и item_brand.
В следующей таблице представлено двумерное представление данных продаж для компании с точки зрения времени, товара и местоположения.
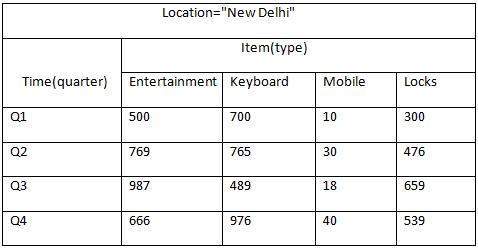
Но здесь, в этой двумерной таблице, у нас есть записи только по времени и предмету. Продажи в Нью-Дели показаны с учетом времени и размеров товаров в соответствии с типом проданных товаров. Если мы хотим просмотреть данные о продажах с еще одним измерением, скажем, с измерением местоположения, то было бы полезно трехмерное представление. Трехмерное представление данных о продажах относительно времени, товара и местоположения показано в таблице ниже —
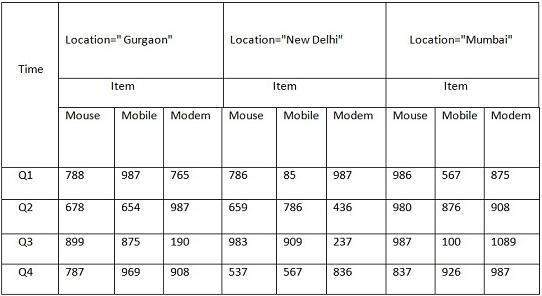
Приведенная выше трехмерная таблица может быть представлена в виде трехмерного куба данных, как показано на следующем рисунке.
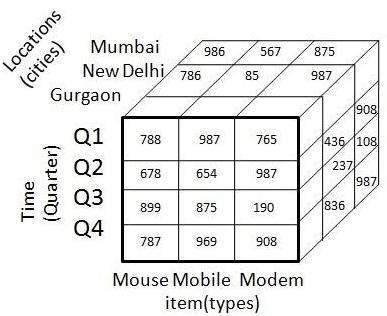
Data Mart
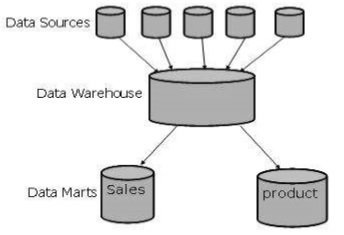
Витрины данных содержат подмножество общеорганизационных данных, которые полезны для определенных групп людей в организации. Другими словами, витрина данных содержит только те данные, которые относятся к конкретной группе. Например, витрина маркетинговых данных может содержать только данные, относящиеся к товарам, покупателям и продажам. Витрины данных ограничены предметами.
Что нужно помнить о витринах данных
-
Серверы на базе Windows или Unix / Linux используются для реализации витрин данных. Они реализованы на недорогих серверах.
-
Цикл реализации витрины данных измеряется в короткие периоды времени, то есть в неделях, а не в месяцах или годах.
-
Жизненный цикл витрин данных может быть сложным в долгосрочной перспективе, если их планирование и дизайн не являются общеорганизационными.
-
Витрины данных имеют небольшой размер.
-
Витрины данных настраиваются отделом.
-
Источником витрины данных является хранилище данных, имеющее структурную структуру.
-
Витрины данных являются гибкими.
Серверы на базе Windows или Unix / Linux используются для реализации витрин данных. Они реализованы на недорогих серверах.
Цикл реализации витрины данных измеряется в короткие периоды времени, то есть в неделях, а не в месяцах или годах.
Жизненный цикл витрин данных может быть сложным в долгосрочной перспективе, если их планирование и дизайн не являются общеорганизационными.
Витрины данных имеют небольшой размер.
Витрины данных настраиваются отделом.
Источником витрины данных является хранилище данных, имеющее структурную структуру.
Витрины данных являются гибкими.
На следующем рисунке показано графическое представление витрин данных.
Виртуальный склад
Вид на оперативное хранилище данных называется виртуальным хранилищем. Это легко построить виртуальный склад. Создание виртуального хранилища требует избыточных мощностей на серверах действующих баз данных.
Хранилище данных — процесс доставки
Хранилище данных никогда не бывает статичным; это развивается, поскольку бизнес расширяется. По мере развития бизнеса его требования постоянно меняются, и поэтому хранилище данных должно быть спроектировано таким образом, чтобы соответствовать этим изменениям. Следовательно, система хранилища данных должна быть гибкой.
В идеале должен быть процесс доставки для доставки хранилища данных. Однако проекты хранилищ данных обычно страдают от различных проблем, которые затрудняют выполнение задач и результатов в строгой и упорядоченной манере, требуемой методом водопада. В большинстве случаев требования не поняты полностью. Архитектура, проектирование и сборка компонентов могут быть выполнены только после сбора и изучения всех требований.
способ доставки
Метод доставки — это вариант подхода совместной разработки приложений, принятого для доставки хранилища данных. Мы организовали процесс доставки в хранилище данных, чтобы минимизировать риски. Подход, который мы обсудим здесь, не сокращает общий масштаб времени доставки, но гарантирует, что преимущества для бизнеса будут предоставляться постепенно в процессе разработки.
Примечание. Процесс доставки разбит на этапы, чтобы снизить риск проекта и доставки.
Следующая диаграмма объясняет этапы процесса доставки —
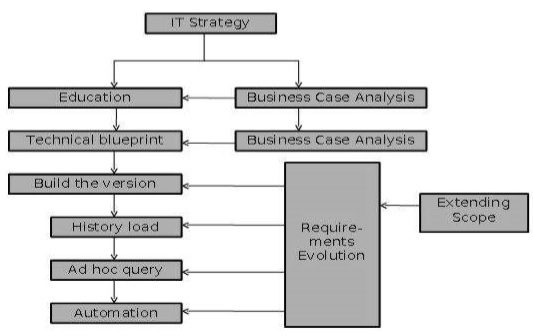
ИТ стратегия
Хранилище данных — это стратегические инвестиции, которые требуют бизнес-процесса для получения выгод. ИТ-стратегия необходима для обеспечения и сохранения финансирования проекта.
Бизнес-кейс
Целью бизнес-кейса является оценка бизнес-преимуществ, которые следует извлечь из использования хранилища данных. Эти выгоды могут быть не поддаются количественной оценке, но прогнозируемые выгоды должны быть четко указаны. Если у хранилища данных нет четкого бизнес-обоснования, то на каком-то этапе в процессе доставки бизнес может столкнуться с проблемами доверия. Поэтому в проектах хранилищ данных нам необходимо понимать экономическое обоснование инвестиций.
Образование и прототипирование
Организации экспериментируют с концепцией анализа данных и изучают ценность наличия хранилища данных, прежде чем соглашаться на решение. Это решается путем прототипирования. Это помогает в понимании осуществимости и преимуществ хранилища данных. Деятельность по созданию прототипов в малых масштабах может способствовать процессу обучения, если:
-
Прототип решает определенную техническую задачу.
-
Прототип можно выбросить после того, как будет показана концепция осуществимости.
-
Действие обращается к небольшому подмножеству возможного содержимого данных хранилища данных.
-
График активности не является критическим.
Прототип решает определенную техническую задачу.
Прототип можно выбросить после того, как будет показана концепция осуществимости.
Действие обращается к небольшому подмножеству возможного содержимого данных хранилища данных.
График активности не является критическим.
Следующие пункты должны быть учтены, чтобы выпустить раннюю версию и обеспечить бизнес-преимущества.
-
Определите архитектуру, которая способна развиваться.
-
Сосредоточьтесь на бизнес-требованиях и технических этапах проекта.
-
Ограничьте область действия первой фазы сборки до минимума, обеспечивающего преимущества для бизнеса.
-
Понимать краткосрочные и среднесрочные требования к хранилищу данных.
Определите архитектуру, которая способна развиваться.
Сосредоточьтесь на бизнес-требованиях и технических этапах проекта.
Ограничьте область действия первой фазы сборки до минимума, обеспечивающего преимущества для бизнеса.
Понимать краткосрочные и среднесрочные требования к хранилищу данных.
Бизнес-требования
Чтобы обеспечить качественные результаты, мы должны убедиться, что общие требования понятны. Если мы понимаем бизнес-требования как для краткосрочных, так и для среднесрочных периодов, мы можем разработать решение для удовлетворения краткосрочных требований. Краткосрочное решение может быть затем превращено в полное решение.
На этом этапе определяются следующие аспекты:
-
Бизнес-правило, которое должно применяться к данным.
-
Логическая модель для информации в хранилище данных.
-
Профили запросов для немедленного требования.
-
Исходные системы, которые предоставляют эти данные.
Бизнес-правило, которое должно применяться к данным.
Логическая модель для информации в хранилище данных.
Профили запросов для немедленного требования.
Исходные системы, которые предоставляют эти данные.
Технический План
На этом этапе необходимо создать общую архитектуру, удовлетворяющую долгосрочным требованиям. На этом этапе также предоставляются компоненты, которые должны быть внедрены в короткие сроки, чтобы получить какую-либо выгоду для бизнеса. В проекте необходимо указать следующее.
- Общая архитектура системы.
- Политика хранения данных.
- Стратегия резервного копирования и восстановления.
- Архитектура сервера и витрины.
- План мощности для оборудования и инфраструктуры.
- Компоненты дизайна базы данных.
Сборка версии
На этом этапе производится первая поставка продукции. Этот производственный результат является наименьшим компонентом хранилища данных. Этот наименьший компонент добавляет выгоду для бизнеса.
Загрузка истории
Это фаза, на которой остаток требуемой истории загружается в хранилище данных. На этом этапе мы не добавляем новые объекты, но, вероятно, будут созданы дополнительные физические таблицы для хранения увеличенных объемов данных.
Давайте возьмем пример. Предположим, что фаза версии сборки предоставила хранилище данных анализа розничных продаж с историей за 2 месяца. Эта информация позволит пользователю анализировать только последние тенденции и решать краткосрочные проблемы. Пользователь в этом случае не может определить годовые и сезонные тренды. Чтобы помочь ему в этом, история продаж за последние 2 года может быть загружена из архива. Теперь данные 40 ГБ расширены до 400 ГБ.
Примечание. Процедуры резервного копирования и восстановления могут стать сложными, поэтому рекомендуется выполнять это действие в отдельной фазе.
Специальный запрос
На этом этапе мы настраиваем специальный инструмент запросов, который используется для управления хранилищем данных. Эти инструменты могут генерировать запрос к базе данных.
Примечание. Рекомендуется не использовать эти инструменты доступа, когда база данных существенно изменяется.
автоматизация
На этом этапе процессы оперативного управления полностью автоматизированы. Это будет включать —
-
Преобразование данных в форму, пригодную для анализа.
-
Мониторинг профилей запросов и определение соответствующих агрегатов для поддержания производительности системы.
-
Извлечение и загрузка данных из разных исходных систем.
-
Генерация агрегатов из предопределенных определений в хранилище данных.
-
Резервное копирование, восстановление и архивация данных.
Преобразование данных в форму, пригодную для анализа.
Мониторинг профилей запросов и определение соответствующих агрегатов для поддержания производительности системы.
Извлечение и загрузка данных из разных исходных систем.
Генерация агрегатов из предопределенных определений в хранилище данных.
Резервное копирование, восстановление и архивация данных.
Расширение сферы
На этом этапе хранилище данных расширяется для удовлетворения нового набора бизнес-требований. Область может быть расширена двумя способами —
-
Загружая дополнительные данные в хранилище данных.
-
Вводя новые витрины данных, используя существующую информацию.
Загружая дополнительные данные в хранилище данных.
Вводя новые витрины данных, используя существующую информацию.
Примечание. Этот этап следует выполнять отдельно, поскольку он требует значительных усилий и сложности.
Требования Эволюция
С точки зрения процесса доставки, требования всегда меняются. Они не статичны. Процесс доставки должен поддерживать это и позволять отражать эти изменения в системе.
Эта проблема решается путем проектирования хранилища данных на основе использования данных в бизнес-процессах, в отличие от требований к данным существующих запросов.
Архитектура предназначена для изменения и расширения в соответствии с потребностями бизнеса, процесс работает как процесс разработки псевдо-приложений, где новые требования постоянно включаются в деятельность по разработке и создаются частичные результаты. Эти частичные результаты возвращаются пользователям, а затем дорабатываются, обеспечивая постоянное обновление всей системы в соответствии с потребностями бизнеса.
Хранилище данных — системные процессы
У нас есть фиксированное число операций, которые должны применяться к оперативным базам данных, и у нас есть четко определенные методы, такие как использование нормализованных данных , сохранение размера таблицы и т. Д. Эти методы подходят для предоставления решения. Но в случае систем поддержки принятия решений мы не знаем, какие запросы и операции необходимо выполнить в будущем. Поэтому методы, применяемые к оперативным базам данных, не подходят для хранилищ данных.
В этой главе мы поговорим о том, как создавать решения для хранилищ данных на основе передовых технологий открытых систем, таких как Unix и реляционные базы данных.
Поток процессов в хранилище данных
Существует четыре основных процесса, которые способствуют созданию хранилища данных:
- Извлеките и загрузите данные.
- Очистка и преобразование данных.
- Резервное копирование и архивирование данных.
- Управление запросами и направление их в соответствующие источники данных.
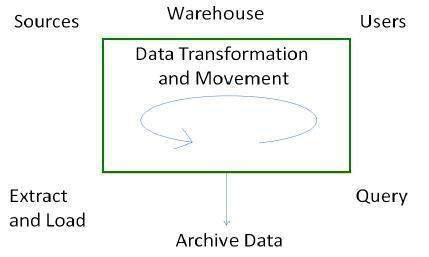
Процесс извлечения и загрузки
Извлечение данных берет данные из исходных систем. Загрузка данных берет извлеченные данные и загружает их в хранилище данных.
Примечание. Перед загрузкой данных в хранилище данных информация, извлеченная из внешних источников, должна быть реконструирована.
Управление процессом
Управление процессом включает определение того, когда начинать извлечение данных, и проверку согласованности данных. Процесс управления гарантирует, что инструменты, логические модули и программы выполняются в правильной последовательности и в правильное время.
Когда начинать извлечение
При извлечении данные должны находиться в согласованном состоянии, т. Е. Хранилище данных должно представлять пользователю единую согласованную версию информации.
Например, в хранилище данных профилирования клиентов в телекоммуникационном секторе нелогично объединять список клиентов в среду в 8 часов вечера из базы данных клиентов с событиями подписки клиентов до 20 часов вечера во вторник. Это будет означать, что мы находим клиентов, для которых нет связанных подписок.
Загрузка данных
После извлечения данных они загружаются во временное хранилище данных, где они очищаются и становятся согласованными.
Примечание. Проверки согласованности выполняются только тогда, когда все источники данных загружены во временное хранилище данных.
Очистить и преобразовать процесс
Как только данные извлечены и загружены во временное хранилище данных, настало время выполнить очистку и преобразование. Вот список шагов, вовлеченных в Очистку и Преобразование —
- Очистить и преобразовать загруженные данные в структуру
- Разделите данные
- агрегирование
Очистить и преобразовать загруженные данные в структуру
Очистка и преобразование загруженных данных помогает ускорить запросы. Это может быть сделано путем согласования данных —
- внутри себя.
- с другими данными в том же источнике данных.
- с данными в других исходных системах.
- с существующими данными, присутствующими на складе.
Преобразование включает в себя преобразование исходных данных в структуру. Структурирование данных повышает производительность запросов и снижает эксплуатационные расходы. Данные, содержащиеся в хранилище данных, должны быть преобразованы для поддержки требований к производительности и контроля текущих эксплуатационных расходов.
Разделите данные
Это позволит оптимизировать производительность оборудования и упростить управление хранилищем данных. Здесь мы разбиваем каждую таблицу фактов на несколько отдельных разделов.
агрегирование
Агрегация необходима для ускорения общих запросов. Агрегация основывается на том факте, что наиболее распространенные запросы будут анализировать подмножество или агрегацию подробных данных.
Резервное копирование и архивирование данных
Чтобы восстановить данные в случае потери данных, сбоя программного обеспечения или аппаратного сбоя, необходимо регулярно выполнять резервное копирование. Архивирование включает в себя удаление старых данных из системы в формате, который позволяет быстро восстанавливать их при необходимости.
Например, в хранилище данных анализа розничных продаж может потребоваться хранить данные в течение 3 лет, а последние 6 месяцев данные хранятся в сети. В таком сценарии часто требуется, чтобы иметь возможность делать ежемесячные сравнения для этого года и прошлого года. В этом случае нам требуется восстановить некоторые данные из архива.
Процесс управления запросами
Этот процесс выполняет следующие функции —
-
управляет запросами.
-
помогает ускорить время выполнения запроса.
-
направляет запросы к их наиболее эффективным источникам данных.
-
гарантирует, что все системные источники используются наиболее эффективно.
-
отслеживает фактические профили запросов.
управляет запросами.
помогает ускорить время выполнения запроса.
направляет запросы к их наиболее эффективным источникам данных.
гарантирует, что все системные источники используются наиболее эффективно.
отслеживает фактические профили запросов.
Информация, сгенерированная в этом процессе, используется процессом управления складом, чтобы определить, какие агрегаты генерировать. Этот процесс обычно не работает во время обычной загрузки информации в хранилище данных.
Хранилище данных — Архитектура
В этой главе мы обсудим структуру бизнес-анализа для проектирования хранилища данных и архитектуру хранилища данных.
Структура бизнес-анализа
Бизнес-аналитик получает информацию из хранилищ данных, чтобы измерить производительность и внести критические изменения, чтобы завоевать других владельцев бизнеса на рынке. Наличие хранилища данных дает следующие преимущества:
-
Поскольку хранилище данных может быстро и эффективно собирать информацию, оно может повысить производительность бизнеса.
-
Хранилище данных предоставляет нам согласованное представление о клиентах и товарах, следовательно, оно помогает нам управлять отношениями с клиентами.
-
Хранилище данных также помогает снизить затраты, отслеживая тенденции и закономерности в течение длительного периода последовательным и надежным образом.
Поскольку хранилище данных может быстро и эффективно собирать информацию, оно может повысить производительность бизнеса.
Хранилище данных предоставляет нам согласованное представление о клиентах и товарах, следовательно, оно помогает нам управлять отношениями с клиентами.
Хранилище данных также помогает снизить затраты, отслеживая тенденции и закономерности в течение длительного периода последовательным и надежным образом.
Чтобы спроектировать эффективное и действенное хранилище данных, нам необходимо понимать и анализировать потребности бизнеса и создавать структуру бизнес-анализа . У каждого человека разные взгляды на дизайн хранилища данных. Эти взгляды следующие:
-
Представление сверху вниз — это представление позволяет выбрать соответствующую информацию, необходимую для хранилища данных.
-
Представление источника данных — это представление представляет информацию, которая собирается, хранится и управляется операционной системой.
-
Представление хранилища данных — это представление включает таблицы фактов и таблицы измерений. Он представляет информацию, хранящуюся в хранилище данных.
-
Представление бизнес-запроса — это представление данных с точки зрения конечного пользователя.
Представление сверху вниз — это представление позволяет выбрать соответствующую информацию, необходимую для хранилища данных.
Представление источника данных — это представление представляет информацию, которая собирается, хранится и управляется операционной системой.
Представление хранилища данных — это представление включает таблицы фактов и таблицы измерений. Он представляет информацию, хранящуюся в хранилище данных.
Представление бизнес-запроса — это представление данных с точки зрения конечного пользователя.
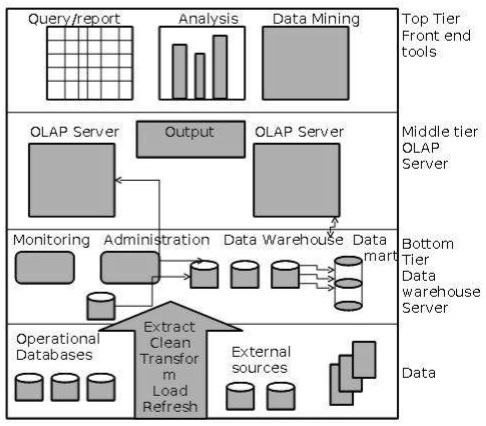
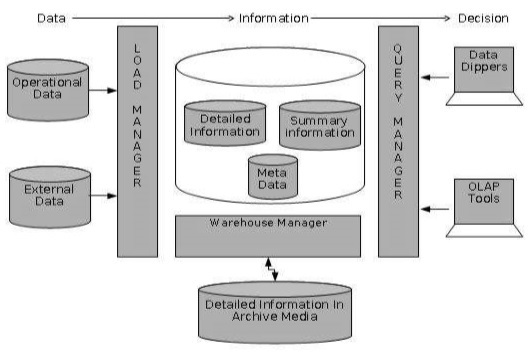
Трехуровневая архитектура хранилища данных
Обычно хранилища данных используют трехуровневую архитектуру. Ниже приведены три уровня архитектуры хранилища данных.
-
Нижний уровень — нижний уровень архитектуры — сервер базы данных хранилища данных. Это система реляционных баз данных. Мы используем внутренние инструменты и утилиты для подачи данных на нижний уровень. Эти внутренние инструменты и утилиты выполняют функции извлечения, очистки, загрузки и обновления.
-
Средний уровень. На среднем уровне у нас есть OLAP-сервер, который может быть реализован любым из следующих способов.
-
По реляционной OLAP (ROLAP), которая является расширенной системой управления реляционной базой данных. ROLAP отображает операции над многомерными данными в стандартные реляционные операции.
-
Модель многомерного OLAP (MOLAP), которая напрямую реализует многомерные данные и операции.
-
-
Верхний уровень — этот уровень является уровнем клиентского интерфейса. Этот уровень содержит инструменты запросов и инструменты отчетности, инструменты анализа и инструменты анализа данных.
Нижний уровень — нижний уровень архитектуры — сервер базы данных хранилища данных. Это система реляционных баз данных. Мы используем внутренние инструменты и утилиты для подачи данных на нижний уровень. Эти внутренние инструменты и утилиты выполняют функции извлечения, очистки, загрузки и обновления.
Средний уровень. На среднем уровне у нас есть OLAP-сервер, который может быть реализован любым из следующих способов.
По реляционной OLAP (ROLAP), которая является расширенной системой управления реляционной базой данных. ROLAP отображает операции над многомерными данными в стандартные реляционные операции.
Модель многомерного OLAP (MOLAP), которая напрямую реализует многомерные данные и операции.
Верхний уровень — этот уровень является уровнем клиентского интерфейса. Этот уровень содержит инструменты запросов и инструменты отчетности, инструменты анализа и инструменты анализа данных.
Следующая диаграмма изображает трехуровневую архитектуру хранилища данных —
Модели хранилищ данных
С точки зрения архитектуры хранилища данных у нас есть следующие модели хранилища данных —
- Виртуальный склад
- Витрина данных
- Корпоративный склад
Виртуальный склад
Вид на оперативное хранилище данных называется виртуальным хранилищем. Это легко построить виртуальный склад. Создание виртуального хранилища требует избыточных мощностей на серверах действующих баз данных.
Data Mart
Витрина данных содержит подмножество общеорганизационных данных. Это подмножество данных является ценным для конкретных групп организации.
Другими словами, мы можем утверждать, что витрины данных содержат данные, специфичные для конкретной группы. Например, витрина маркетинговых данных может содержать данные, связанные с товарами, клиентами и продажами. Витрины данных ограничены предметами.
Что нужно помнить о витринах данных —
-
Для реализации витрин данных используются серверы на основе окон или Unix / Linux. Они реализованы на недорогих серверах.
-
Циклы витрины данных реализации измеряются в короткие периоды времени, т. Е. В неделях, а не в месяцах или годах.
-
Жизненный цикл витрины данных может быть сложным в долгосрочной перспективе, если его планирование и дизайн не являются общеорганизационными.
-
Витрины данных имеют небольшой размер.
-
Витрины данных настраиваются отделом.
-
Источником витрины данных является хранилище данных, имеющее структурную структуру.
-
Данные витрины являются гибкими.
Для реализации витрин данных используются серверы на основе окон или Unix / Linux. Они реализованы на недорогих серверах.
Циклы витрины данных реализации измеряются в короткие периоды времени, т. Е. В неделях, а не в месяцах или годах.
Жизненный цикл витрины данных может быть сложным в долгосрочной перспективе, если его планирование и дизайн не являются общеорганизационными.
Витрины данных имеют небольшой размер.
Витрины данных настраиваются отделом.
Источником витрины данных является хранилище данных, имеющее структурную структуру.
Данные витрины являются гибкими.
Корпоративный склад
-
Склад предприятия собирает всю информацию и предметы, охватывающие всю организацию
-
Это обеспечивает нам интеграцию данных в масштабах всего предприятия.
-
Данные интегрированы из операционных систем и внешних поставщиков информации.
-
Эта информация может варьироваться от нескольких гигабайт до сотен гигабайт, терабайт или более.
Склад предприятия собирает всю информацию и предметы, охватывающие всю организацию
Это обеспечивает нам интеграцию данных в масштабах всего предприятия.
Данные интегрированы из операционных систем и внешних поставщиков информации.
Эта информация может варьироваться от нескольких гигабайт до сотен гигабайт, терабайт или более.
Менеджер нагрузки
Этот компонент выполняет операции, необходимые для извлечения и загрузки процесса.
Размер и сложность диспетчера нагрузки варьируются между конкретными решениями от одного хранилища данных до другого.
Архитектура диспетчера нагрузки
Диспетчер загрузки выполняет следующие функции —
-
Извлечь данные из исходной системы.
-
Быстрая загрузка извлеченных данных во временное хранилище данных.
-
Выполните простые преобразования в структуру, похожую на структуру хранилища данных.
Извлечь данные из исходной системы.
Быстрая загрузка извлеченных данных во временное хранилище данных.
Выполните простые преобразования в структуру, похожую на структуру хранилища данных.
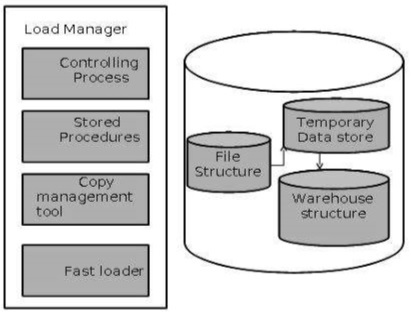
Извлечь данные из источника
Данные извлекаются из оперативных баз данных или внешних поставщиков информации. Шлюзы — это прикладные программы, которые используются для извлечения данных. Он поддерживается базовой СУБД и позволяет клиентской программе генерировать SQL для выполнения на сервере. Open Database Connection (ODBC), Java Database Connection (JDBC), являются примерами шлюза.
Быстрая загрузка
-
Чтобы минимизировать общее окно загрузки, данные должны быть загружены в хранилище в кратчайшие сроки.
-
Преобразования влияют на скорость обработки данных.
-
Более эффективно загружать данные в реляционную базу данных до применения преобразований и проверок.
-
Технология шлюза оказывается непригодной, так как она неэффективна, когда речь идет о больших объемах данных.
Чтобы минимизировать общее окно загрузки, данные должны быть загружены в хранилище в кратчайшие сроки.
Преобразования влияют на скорость обработки данных.
Более эффективно загружать данные в реляционную базу данных до применения преобразований и проверок.
Технология шлюза оказывается непригодной, так как она неэффективна, когда речь идет о больших объемах данных.
Простые преобразования
Во время загрузки может потребоваться выполнить простые преобразования. После того, как это было завершено, мы можем выполнить сложные проверки. Предположим, что мы загружаем транзакцию продажи EPOS, нам нужно выполнить следующие проверки:
- Удалите все столбцы, которые не требуются на складе.
- Преобразуйте все значения в требуемые типы данных.
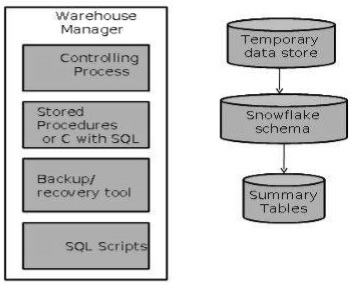
Заведующий складом
Менеджер склада отвечает за процесс управления складом. Он состоит из стороннего системного программного обеспечения, программ на C и сценариев оболочки.
Размер и сложность менеджеров склада варьируются в зависимости от конкретных решений.
Архитектура менеджера склада
Менеджер склада включает в себя следующее:
- Процесс контроля
- Хранимые процедуры или C с SQL
- Инструмент резервного копирования / восстановления
- Сценарии SQL
Операции, выполняемые менеджером склада
-
Менеджер склада анализирует данные для проверки согласованности и ссылочной целостности.
-
Создает индексы, бизнес-представления, разделы на основе базовых данных.
-
Создает новые агрегаты и обновляет существующие агрегаты. Создает нормализации.
-
Преобразует и объединяет исходные данные в опубликованное хранилище данных.
-
Резервное копирование данных в хранилище данных.
-
Архивирует данные, которые достигли конца своей захваченной жизни.
Менеджер склада анализирует данные для проверки согласованности и ссылочной целостности.
Создает индексы, бизнес-представления, разделы на основе базовых данных.
Создает новые агрегаты и обновляет существующие агрегаты. Создает нормализации.
Преобразует и объединяет исходные данные в опубликованное хранилище данных.
Резервное копирование данных в хранилище данных.
Архивирует данные, которые достигли конца своей захваченной жизни.
Примечание . Менеджер склада также анализирует профили запросов, чтобы определить, подходят ли индексы и агрегаты.
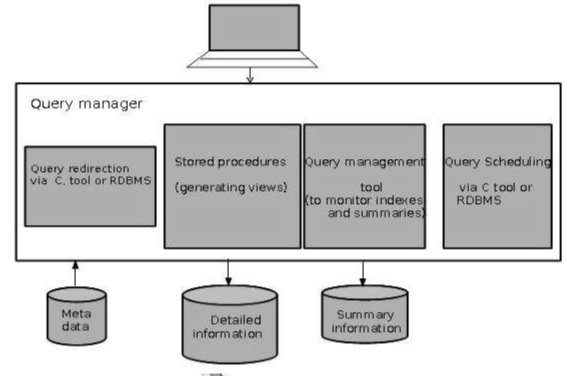
Менеджер запросов
-
Менеджер запросов отвечает за направление запросов к подходящим таблицам.
-
Направляя запросы в соответствующие таблицы, можно увеличить скорость запросов и генерации ответов.
-
Диспетчер запросов отвечает за планирование выполнения запросов, заданных пользователем.
Менеджер запросов отвечает за направление запросов к подходящим таблицам.
Направляя запросы в соответствующие таблицы, можно увеличить скорость запросов и генерации ответов.
Диспетчер запросов отвечает за планирование выполнения запросов, заданных пользователем.
Архитектура Query Manager
На следующем снимке экрана показана архитектура диспетчера запросов. Включает в себя следующее:
- Перенаправление запросов через инструмент C или RDBMS
- Хранимые процедуры
- Инструмент управления запросами
- Планирование запросов с помощью инструмента C или RDBMS
- Планирование запросов с помощью стороннего программного обеспечения
Подробная информация
Подробная информация не хранится в сети, скорее она агрегируется на следующий уровень детализации и затем архивируется на ленту. Детальная информационная часть хранилища данных хранит подробную информацию в схеме «звездная пластинка». Подробная информация загружается в хранилище данных для дополнения агрегированных данных.
Следующая диаграмма показывает наглядное представление о том, где хранится подробная информация и как она используется.
Примечание. Если подробная информация хранится в автономном режиме для минимизации дискового хранилища, мы должны убедиться, что данные были извлечены, очищены и преобразованы в схему «звездообразных» перед их архивированием.
Сводная информация
Сводная информация является частью хранилища данных, в котором хранятся предопределенные агрегаты. Эти агрегаты генерируются менеджером склада. Сводная информация должна рассматриваться как переходная. Он изменяется на ходу, чтобы отвечать на изменяющиеся профили запросов.
Примечания к сводной информации следующие:
-
Сводная информация ускоряет выполнение обычных запросов.
-
Это увеличивает эксплуатационные расходы.
-
Его необходимо обновлять всякий раз, когда новые данные загружаются в хранилище данных.
-
Возможно, что оно не было зарезервировано, так как оно может быть сгенерировано свежим из подробной информации.
Сводная информация ускоряет выполнение обычных запросов.
Это увеличивает эксплуатационные расходы.
Его необходимо обновлять всякий раз, когда новые данные загружаются в хранилище данных.
Возможно, что оно не было зарезервировано, так как оно может быть сгенерировано свежим из подробной информации.
Хранилище данных — OLAP
Онлайновый сервер аналитической обработки (OLAP) основан на многомерной модели данных. Это позволяет менеджерам и аналитикам получать информацию, используя быстрый, согласованный и интерактивный доступ к информации. В этой главе рассматриваются типы OLAP, операции над OLAP, различия между OLAP, а также статистические базы данных и OLTP.
Типы OLAP-серверов
У нас есть четыре типа серверов OLAP —
- Реляционный OLAP (ROLAP)
- Многомерный OLAP (MOLAP)
- Гибридный OLAP (HOLAP)
- Специализированные SQL-серверы
Реляционный OLAP
Серверы ROLAP размещаются между реляционным внутренним сервером и клиентскими интерфейсными инструментами. Для хранения данных хранилища и управления ими ROLAP использует реляционные или расширенно-реляционные СУБД.
ROLAP включает в себя следующее —
- Реализация агрегационной навигационной логики.
- Оптимизация для каждой серверной части СУБД.
- Дополнительные инструменты и услуги.
Многомерный OLAP
MOLAP использует многомерное хранилище на основе массива для многомерного представления данных. В случае многомерных хранилищ данных использование хранилища может быть низким, если набор данных является разреженным. Поэтому многие серверы MOLAP используют два уровня представления хранилища данных для обработки плотных и разреженных наборов данных.
Гибридный OLAP
Гибридный OLAP представляет собой комбинацию ROLAP и MOLAP. Он предлагает более высокую масштабируемость ROLAP и более быстрое вычисление MOLAP. Серверы HOLAP позволяют хранить большие объемы данных подробной информации. Агрегации хранятся отдельно в магазине MOLAP.
Специализированные SQL-серверы
Специализированные серверы SQL обеспечивают расширенный язык запросов и поддержку обработки запросов для запросов SQL по схемам типа «звезда» и «снежинка» в среде только для чтения.
OLAP Операции
Поскольку серверы OLAP основаны на многомерном представлении данных, мы обсудим операции OLAP в многомерных данных.
Вот список операций OLAP —
- Свернуть
- Дрель-вниз
- Ломтик и кости
- Поворот (поворот)
Свернуть
Свертывание выполняет агрегацию в кубе данных любым из следующих способов:
- Поднимаясь по иерархии понятий для измерения
- По уменьшению размеров
Следующая диаграмма иллюстрирует, как работает свертка.
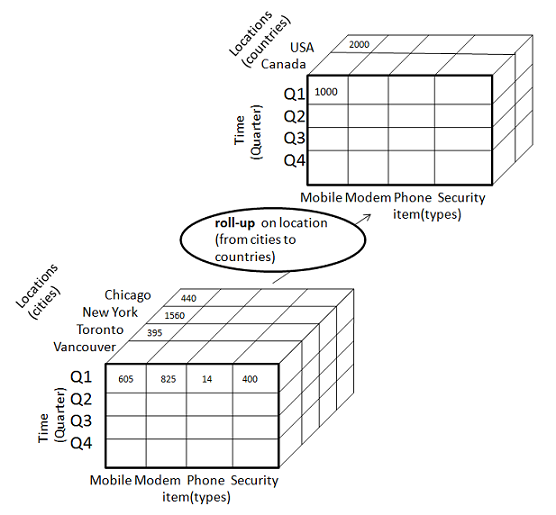
-
Свертывание выполняется путем подъема иерархии понятий для местоположения измерения.
-
Первоначально концепция иерархии была «улица <город <провинция <страна».
-
При сворачивании данные агрегируются по возрастанию иерархии местоположений от уровня города до уровня страны.
-
Данные сгруппированы по городам, а не по странам.
-
При выполнении свертки одно или несколько измерений из куба данных удаляются.
Свертывание выполняется путем подъема иерархии понятий для местоположения измерения.
Первоначально концепция иерархии была «улица <город <провинция <страна».
При сворачивании данные агрегируются по возрастанию иерархии местоположений от уровня города до уровня страны.
Данные сгруппированы по городам, а не по странам.
При выполнении свертки одно или несколько измерений из куба данных удаляются.
Дрель-вниз
Развертка — это обратная операция свертки. Это выполняется одним из следующих способов —
- Пошаговая иерархия понятий для измерения
- Вводя новое измерение.
Следующая диаграмма иллюстрирует, как работает детализация —
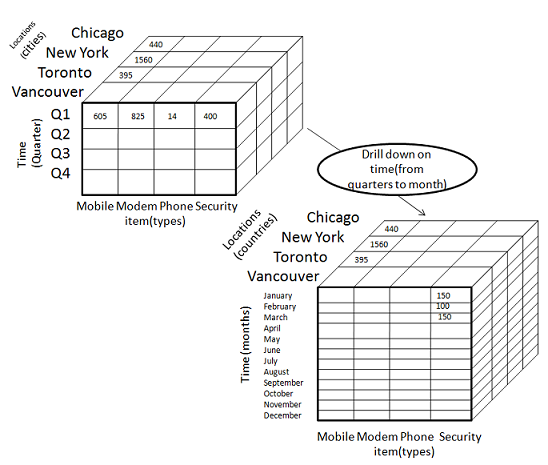
-
Развертывание выполняется путем понижения иерархии понятий для времени измерения.
-
Первоначально концепция иерархии была «день <месяц <квартал <год».
-
При детализации измерение времени спускается с уровня квартала до уровня месяца.
-
При выполнении детализации добавляются одно или несколько измерений из куба данных.
-
Он перемещает данные от менее подробных данных к очень подробным данным.
Развертывание выполняется путем понижения иерархии понятий для времени измерения.
Первоначально концепция иерархии была «день <месяц <квартал <год».
При детализации измерение времени спускается с уровня квартала до уровня месяца.
При выполнении детализации добавляются одно или несколько измерений из куба данных.
Он перемещает данные от менее подробных данных к очень подробным данным.
Ломтик
Операция среза выбирает одно конкретное измерение из данного куба и предоставляет новый вложенный куб. Рассмотрим следующую диаграмму, которая показывает, как работает слайс.
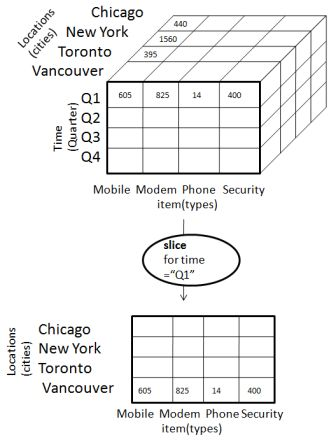
-
Здесь Slice выполняется для измерения «время» с использованием критерия time = «Q1».
-
Он сформирует новый вложенный куб, выбрав одно или несколько измерений.
Здесь Slice выполняется для измерения «время» с использованием критерия time = «Q1».
Он сформирует новый вложенный куб, выбрав одно или несколько измерений.
Игральная кость
Кости выбирает два или более измерений из данного куба и предоставляет новый вложенный куб. Рассмотрим следующую диаграмму, которая показывает операцию игры в кости.
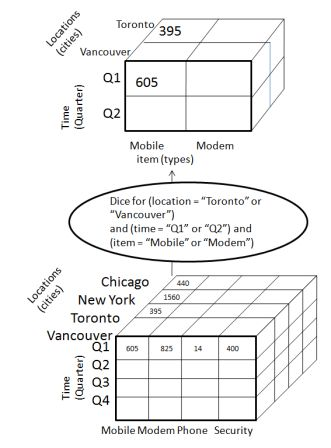
Операция с кубиками на кубе на основе следующих критериев выбора включает три измерения.
- (location = «Торонто» или «Ванкувер»)
- (время = «Q1» или «Q2»)
- (item = «Mobile» или «Modem»)
стержень
Операция поворота также называется вращением. Он вращает оси данных в поле зрения, чтобы обеспечить альтернативное представление данных. Рассмотрим следующую диаграмму, которая показывает операцию поворота.
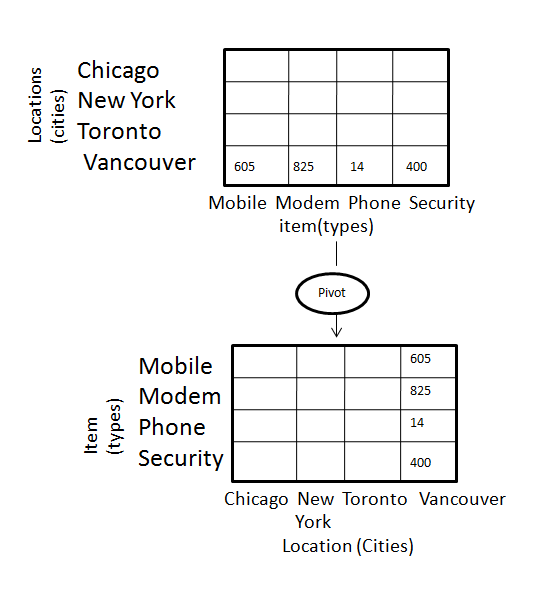
OLAP против OLTP
| Sr.No. | Хранилище данных (OLAP) | Оперативная база данных (OLTP) |
|---|---|---|
| 1 | Включает в себя историческую обработку информации. | Включает ежедневную обработку. |
| 2 | Системы OLAP используются работниками умственного труда, такими как руководители, менеджеры и аналитики. | Системы OLTP используются клерками, администраторами баз данных или специалистами по базам данных. |
| 3 | Полезно при анализе бизнеса. | Полезно для ведения бизнеса. |
| 4 | Это сосредотачивается на Информации. | Он фокусируется на данных в. |
| 5 | На основе схемы «Звезда», «Снежинка», «Схема и схема фактов». | На основе модели отношений сущностей. |
| 6 | Содержит исторические данные. | Содержит текущие данные. |
| 7 | Предоставляет обобщенные и сводные данные. | Предоставляет примитивные и очень подробные данные. |
| 8 | Предоставляет обобщенное и многомерное представление данных. | Обеспечивает подробное и плоское реляционное представление данных. |
| 9 | Количество или пользователей исчисляется сотнями. | Количество пользователей в тысячах. |
| 10 | Количество обращений к записи в миллионах. | Количество записей достигло десятков. |
| 11 | Размер базы данных от 100 ГБ до 1 ТБ | Размер базы данных от 100 МБ до 1 ГБ. |
| 12 | Очень гибкий. | Обеспечивает высокую производительность. |
Хранилище данных — реляционный OLAP
Реляционные серверы OLAP размещаются между реляционным внутренним сервером и клиентскими интерфейсными инструментами. Для хранения и управления данными хранилища реляционная OLAP использует реляционную или расширенно-реляционную СУБД.
ROLAP включает в себя следующее —
- Реализация агрегации навигационной логики
- Оптимизация для каждого сервера СУБД
- Дополнительные инструменты и услуги
Очки для запоминания
-
Серверы ROLAP отлично масштабируются.
-
Инструменты ROLAP анализируют большие объемы данных в нескольких измерениях.
-
Инструменты ROLAP хранят и анализируют очень изменчивые и изменчивые данные.
Серверы ROLAP отлично масштабируются.
Инструменты ROLAP анализируют большие объемы данных в нескольких измерениях.
Инструменты ROLAP хранят и анализируют очень изменчивые и изменчивые данные.
Реляционная архитектура OLAP
ROLAP включает в себя следующие компоненты —
- Сервер базы данных
- ROLAP сервер
- Фронтальный инструмент.
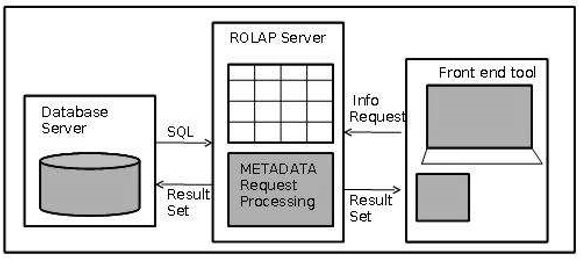
преимущества
- Серверы ROLAP могут быть легко использованы с существующими СУБД.
- Данные могут храниться эффективно, поскольку никакие нулевые факты не могут быть сохранены.
- Инструменты ROLAP не используют предварительно рассчитанные кубы данных.
- DSS-сервер микро-стратегии использует подход ROLAP.
Недостатки
-
Низкая производительность запросов.
-
Некоторые ограничения масштабируемости в зависимости от используемой архитектуры технологии.
Низкая производительность запросов.
Некоторые ограничения масштабируемости в зависимости от используемой архитектуры технологии.
Хранилище данных — многомерный OLAP
В многомерном OLAP (MOLAP) используются многомерные механизмы хранения на основе массива для многомерного представления данных. В случае многомерных хранилищ данных использование хранилища может быть низким, если набор данных является разреженным. Поэтому многие серверы MOLAP используют два уровня представления хранилища данных для обработки плотных и разреженных наборов данных.
Очки для запоминания —
-
Инструменты MOLAP обрабатывают информацию с постоянным временем отклика независимо от уровня суммирования или выбранных расчетов.
-
Инструменты MOLAP должны избегать многих сложностей создания реляционной базы данных для хранения данных для анализа.
-
Инструменты MOLAP требуют максимально возможной производительности.
-
Сервер MOLAP использует два уровня представления хранилища для обработки плотных и разреженных наборов данных.
-
Более плотные субкубы идентифицируются и сохраняются как структура массива.
-
Разреженные вложенные кубы используют технологию сжатия.
Инструменты MOLAP обрабатывают информацию с постоянным временем отклика независимо от уровня суммирования или выбранных расчетов.
Инструменты MOLAP должны избегать многих сложностей создания реляционной базы данных для хранения данных для анализа.
Инструменты MOLAP требуют максимально возможной производительности.
Сервер MOLAP использует два уровня представления хранилища для обработки плотных и разреженных наборов данных.
Более плотные субкубы идентифицируются и сохраняются как структура массива.
Разреженные вложенные кубы используют технологию сжатия.
MOLAP Архитектура
MOLAP включает в себя следующие компоненты —
- Сервер базы данных.
- MOLAP сервер.
- Фронтальный инструмент.
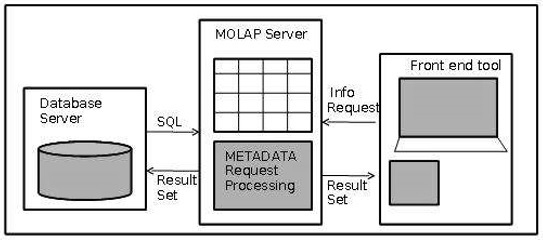
преимущества
- MOLAP позволяет максимально быстро индексировать предварительно вычисленные итоговые данные.
- Помогает пользователям, подключенным к сети, которым необходимо анализировать большие, менее определенные данные.
- Легче в использовании, поэтому MOLAP подходит для неопытных пользователей.
Недостатки
- MOLAP не могут содержать подробные данные.
- Использование хранилища может быть низким, если набор данных является разреженным.
МОЛАП против РОЛАП
| Sr.No. | MOLAP | ROLAP |
|---|---|---|
| 1 | Поиск информации происходит быстро. | Поиск информации сравнительно медленный. |
| 2 | Использует разреженный массив для хранения наборов данных. | Использует реляционную таблицу. |
| 3 | MOLAP лучше всего подходит для неопытных пользователей, поскольку он очень прост в использовании. | ROLAP лучше всего подходит для опытных пользователей. |
| 4 | Поддерживает отдельную базу данных для кубов данных. | Для этого может не потребоваться пространство, отличное от доступного в хранилище данных |
| 5 | Объект СУБД слабый. | Средство СУБД является сильным. |
Хранилище данных — схемы
Схема представляет собой логическое описание всей базы данных. Он включает в себя имя и описание записей всех типов записей, включая все связанные элементы данных и агрегаты. Как и база данных, хранилище данных также требует поддержки схемы. База данных использует реляционную модель, в то время как хранилище данных использует схемы Star, Snowflake и Fact Constellation. В этой главе мы обсудим схемы, используемые в хранилище данных.
Схема звезды
-
Каждое измерение в звездообразной схеме представлено только одномерной таблицей.
-
Эта таблица измерений содержит набор атрибутов.
-
На следующей диаграмме показаны данные о продажах компании по четырем измерениям, а именно: время, позиция, филиал и местоположение.
Каждое измерение в звездообразной схеме представлено только одномерной таблицей.
Эта таблица измерений содержит набор атрибутов.
На следующей диаграмме показаны данные о продажах компании по четырем измерениям, а именно: время, позиция, филиал и местоположение.
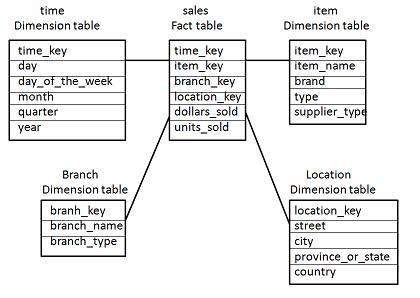
-
В центре находится таблица фактов. Он содержит ключи к каждому из четырех измерений.
-
Таблица фактов также содержит атрибуты, а именно проданные доллары и проданные единицы.
В центре находится таблица фактов. Он содержит ключи к каждому из четырех измерений.
Таблица фактов также содержит атрибуты, а именно проданные доллары и проданные единицы.
Примечание. Каждое измерение имеет только одну таблицу измерений, и каждая таблица содержит набор атрибутов. Например, таблица измерения местоположения содержит атрибут set {location_key, street, city, провинция_or_state, страна}. Это ограничение может привести к избыточности данных. Например, «Ванкувер» и «Виктория» оба города находятся в канадской провинции Британская Колумбия. Записи для таких городов могут вызвать избыточность данных вдоль атрибутов провинция_или_стата и страна.
Снежинка Схема
-
Некоторые таблицы измерений в схеме Snowflake нормализованы.
-
Нормализация разбивает данные на дополнительные таблицы.
-
В отличие от схемы Star, таблица измерений в схеме снежинки нормализована. Например, таблица измерений элементов в звездообразной схеме нормализована и разделена на две таблицы измерений, а именно таблицу элементов и поставщиков.
Некоторые таблицы измерений в схеме Snowflake нормализованы.
Нормализация разбивает данные на дополнительные таблицы.
В отличие от схемы Star, таблица измерений в схеме снежинки нормализована. Например, таблица измерений элементов в звездообразной схеме нормализована и разделена на две таблицы измерений, а именно таблицу элементов и поставщиков.
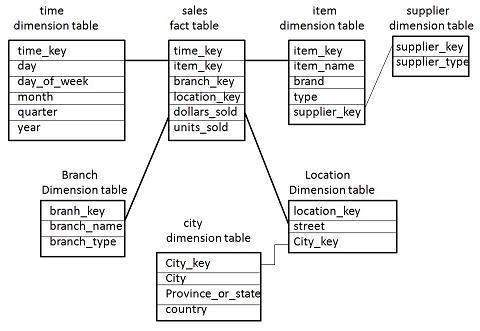
-
Теперь таблица измерений элемента содержит атрибуты item_key, item_name, type, brand и supplier-key.
-
Ключ поставщика связан с таблицей измерений поставщика. Таблица измерений поставщика содержит атрибуты supplier_key и supplier_type.
Теперь таблица измерений элемента содержит атрибуты item_key, item_name, type, brand и supplier-key.
Ключ поставщика связан с таблицей измерений поставщика. Таблица измерений поставщика содержит атрибуты supplier_key и supplier_type.
Примечание. Из-за нормализации в схеме «Снежинка» избыточность уменьшается, и, следовательно, становится проще в обслуживании и экономит место для хранения.
Схема Созвездия Фактов
-
Созвездие фактов имеет несколько таблиц фактов. Это также известно как схема галактики.
-
На следующей диаграмме показаны две таблицы фактов, а именно: продажи и доставка.
Созвездие фактов имеет несколько таблиц фактов. Это также известно как схема галактики.
На следующей диаграмме показаны две таблицы фактов, а именно: продажи и доставка.
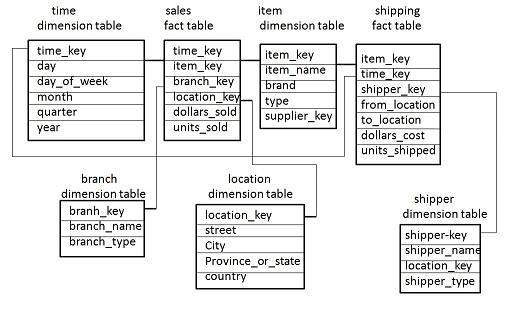
-
Таблица фактов продаж такая же, как в схеме «звезда».
-
Таблица фактов доставки имеет пять измерений: item_key, time_key, shipper_key, from_location, to_location.
-
Таблица фактов отгрузки также содержит две меры: проданные доллары и проданные единицы.
-
Также возможно разделить таблицы измерений между таблицами фактов. Например, таблицы измерений времени, позиции и местоположения совместно используются таблицей фактов продаж и отгрузки.
Таблица фактов продаж такая же, как в схеме «звезда».
Таблица фактов доставки имеет пять измерений: item_key, time_key, shipper_key, from_location, to_location.
Таблица фактов отгрузки также содержит две меры: проданные доллары и проданные единицы.
Также возможно разделить таблицы измерений между таблицами фактов. Например, таблицы измерений времени, позиции и местоположения совместно используются таблицей фактов продаж и отгрузки.
Определение схемы
Многомерная схема определяется с помощью Data Mining Query Language (DMQL). Два примитива, определение куба и определение измерения, могут использоваться для определения хранилищ данных и витрин данных.
Синтаксис для определения куба
define cube < cube_name > [ < dimension-list > }: < measure_list >
Синтаксис для определения измерения
define dimension < dimension_name > as ( < attribute_or_dimension_list > )
Определение схемы звезды
Обсуждаемая нами схема типа «звезда» может быть определена с помощью Data Mining Query Language (DMQL) следующим образом:
define cube sales star [time, item, branch, location]:
dollars sold = sum(sales in dollars), units sold = count(*)
define dimension time as (time key, day, day of week, month, quarter, year)
define dimension item as (item key, item name, brand, type, supplier type)
define dimension branch as (branch key, branch name, branch type)
define dimension location as (location key, street, city, province or state, country)
Определение схемы снежинки
Схему снежинки можно определить с помощью DMQL следующим образом:
define cube sales snowflake [time, item, branch, location]: dollars sold = sum(sales in dollars), units sold = count(*) define dimension time as (time key, day, day of week, month, quarter, year) define dimension item as (item key, item name, brand, type, supplier (supplier key, supplier type)) define dimension branch as (branch key, branch name, branch type) define dimension location as (location key, street, city (city key, city, province or state, country))
Определение схемы фактов
Схема констелляции фактов может быть определена с использованием DMQL следующим образом:
define cube sales [time, item, branch, location]: dollars sold = sum(sales in dollars), units sold = count(*) define dimension time as (time key, day, day of week, month, quarter, year) define dimension item as (item key, item name, brand, type, supplier type) define dimension branch as (branch key, branch name, branch type) define dimension location as (location key, street, city, province or state,country) define cube shipping [time, item, shipper, from location, to location]: dollars cost = sum(cost in dollars), units shipped = count(*) define dimension time as time in cube sales define dimension item as item in cube sales define dimension shipper as (shipper key, shipper name, location as location in cube sales, shipper type) define dimension from location as location in cube sales define dimension to location as location in cube sales
Хранилище данных — стратегия разделения
Разделение сделано для повышения производительности и облегчения управления данными. Разделение также помогает сбалансировать различные требования системы. Он оптимизирует производительность оборудования и упрощает управление хранилищем данных, разбивая каждую таблицу фактов на несколько отдельных разделов. В этой главе мы обсудим различные стратегии разделения.
Почему необходимо разделить?
Разделение важно по следующим причинам —
- Для легкого управления,
- Чтобы помочь резервному копированию / восстановлению,
- Для повышения производительности.
Для легкого управления
Таблица фактов в хранилище данных может достигать сотен гигабайт. Этот огромный размер таблицы фактов очень сложен как единое целое. Поэтому оно нуждается в разделении.
Помочь Резервному копированию / Восстановлению
Если мы не разбиваем таблицу фактов, то мы должны загрузить полную таблицу фактов со всеми данными. Разбиение позволяет нам загружать столько данных, сколько требуется на регулярной основе. Это сокращает время загрузки, а также повышает производительность системы.
Примечание — Для того, чтобы сократить размер резервной копии, все , кроме текущего раздела разделы могут быть помечены как только для чтения. Затем мы можем поместить эти разделы в состояние, в котором они не могут быть изменены. Тогда они могут быть сохранены. Это означает, что для резервного копирования требуется только текущий раздел.
Повысить производительность
Разделив таблицу фактов на наборы данных, можно улучшить процедуры запроса. Повышена производительность запроса, поскольку теперь запрос сканирует только те релевантные разделы. Не нужно сканировать все данные.
Горизонтальное разбиение
Существуют различные способы разделения таблицы фактов. При горизонтальном разделении мы должны учитывать требования к управляемости хранилища данных.
Разбиение по времени на равные отрезки
В этой стратегии разделения таблица фактов разделена на основе периода времени. Здесь каждый период времени представляет значительный срок хранения в бизнесе. Например, если пользователь запрашивает данные за месяц, то целесообразно разделить данные на месячные сегменты. Мы можем повторно использовать многораздельные таблицы, удалив в них данные.
Разделение по времени на сегменты разных размеров
Этот тип раздела выполняется там, где к устаревшим данным обращаются редко. Он реализован в виде набора небольших разделов для относительно текущих данных, большего раздела для неактивных данных.
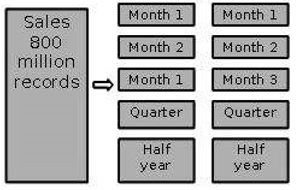
Указывает на заметку
-
Подробная информация остается доступной онлайн.
-
Количество физических таблиц остается относительно небольшим, что снижает эксплуатационные расходы.
-
Этот метод подходит для случаев, когда требуется сочетание данных, погружающихся в недавнюю историю, и интеллектуального анализа данных во всей истории.
-
Этот метод бесполезен, когда профиль секционирования изменяется регулярно, потому что перераспределение увеличит эксплуатационные расходы хранилища данных.
Подробная информация остается доступной онлайн.
Количество физических таблиц остается относительно небольшим, что снижает эксплуатационные расходы.
Этот метод подходит для случаев, когда требуется сочетание данных, погружающихся в недавнюю историю, и интеллектуального анализа данных во всей истории.
Этот метод бесполезен, когда профиль секционирования изменяется регулярно, потому что перераспределение увеличит эксплуатационные расходы хранилища данных.
Перегородка в другом измерении
Таблицу фактов можно также разбить на основе измерений, отличных от времени, таких как группа продуктов, регион, поставщик или любое другое измерение. Давайте иметь пример.
Предположим, что рыночная функция была структурирована в отдельные региональные департаменты, например, по штатам. Если каждый регион хочет запрашивать информацию, полученную в пределах своего региона, было бы более эффективно разделить таблицу фактов на региональные разделы. Это приведет к ускорению запросов, поскольку не требуется сканировать информацию, которая не имеет отношения к делу.
Указывает на заметку
-
Запрос не должен сканировать нерелевантные данные, что ускоряет процесс запроса.
-
Этот метод не подходит, если размеры в будущем вряд ли изменятся. Таким образом, стоит определить, что измерение не изменится в будущем.
-
Если измерение изменится, тогда всю таблицу фактов придется перераспределить.
Запрос не должен сканировать нерелевантные данные, что ускоряет процесс запроса.
Этот метод не подходит, если размеры в будущем вряд ли изменятся. Таким образом, стоит определить, что измерение не изменится в будущем.
Если измерение изменится, тогда всю таблицу фактов придется перераспределить.
Примечание. Рекомендуется выполнять разбиение только на основе измерения времени, если только вы не уверены, что предлагаемая группировка измерений не изменится в течение срока службы хранилища данных.
Разделение по размеру таблицы
Если нет четкой основы для разделения таблицы фактов на какое-либо измерение, то мы должны разделить таблицу фактов на основе их размера. Мы можем установить предопределенный размер в качестве критической точки. Когда таблица превышает заданный размер, создается новый раздел таблицы.
Указывает на заметку
-
Это разделение сложно управлять.
-
Требуются метаданные, чтобы определить, какие данные хранятся в каждом разделе.
Это разделение сложно управлять.
Требуются метаданные, чтобы определить, какие данные хранятся в каждом разделе.
Размеры разделов
Если измерение содержит большое количество записей, необходимо разделить измерения. Здесь мы должны проверить размер измерения.
Рассмотрим большой дизайн, который меняется со временем. Если нам нужно сохранить все варианты, чтобы применить сравнения, это измерение может быть очень большим. Это определенно повлияет на время отклика.
Круглые Робиновые Перегородки
В методе циклического перебора, когда требуется новый раздел, старый архивируется. Он использует метаданные, чтобы пользовательский инструмент доступа мог обращаться к правильному разделу таблицы.
Этот метод позволяет легко автоматизировать средства управления таблицами в хранилище данных.
Вертикальная перегородка
Вертикальное разбиение, разбивает данные по вертикали. На следующих рисунках показано, как выполняется вертикальное разбиение.
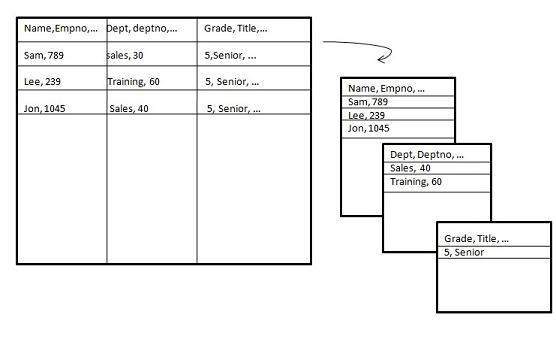
Вертикальное разбиение может быть выполнено следующими двумя способами:
- нормализация
- Разделение строк
нормализация
Нормализация — это стандартный реляционный метод организации базы данных. В этом методе строки свернуты в одну строку, следовательно, это уменьшает пространство. Посмотрите на следующие таблицы, которые показывают, как выполняется нормализация.
Таблица до нормализации
| Код товара | Кол-во | Значение | sales_date | store_id | Название магазина | Место нахождения | Область, край |
|---|---|---|---|---|---|---|---|
| 30 | 5 | 3,67 | 3-августа-13 | 16 | солнечно | Бангалор | S |
| 35 | 4 | 5,33 | 3-Sep-13 | 16 | солнечно | Бангалор | S |
| 40 | 5 | 2,50 | 3-Sep-13 | 64 | Сан — | Mumbai | W |
| 45 | 7 | 5,66 | 3-Sep-13 | 16 | солнечно | Бангалор | S |
Таблица после нормализации
| store_id | Название магазина | Место нахождения | Область, край |
|---|---|---|---|
| 16 | солнечно | Бангалор | W |
| 64 | Сан — | Mumbai | S |
| Код товара | Количество | Значение | sales_date | store_id |
|---|---|---|---|---|
| 30 | 5 | 3,67 | 3-августа-13 | 16 |
| 35 | 4 | 5,33 | 3-Sep-13 | 16 |
| 40 | 5 | 2,50 | 3-Sep-13 | 64 |
| 45 | 7 | 5,66 | 3-Sep-13 | 16 |
Разделение строк
Разделение строк приводит к тому, что между разделами остается однозначная карта. Мотивом разделения строк является ускорение доступа к большому столу за счет уменьшения его размера.
Примечание. При использовании вертикального разбиения убедитесь, что нет необходимости выполнять основную операцию соединения между двумя разделами.
Определить ключ к разделу
Очень важно правильно выбрать ключ раздела. Выбор неправильного ключа раздела приведет к реорганизации таблицы фактов. Давайте иметь пример. Предположим, мы хотим разбить следующую таблицу.
Account_Txn_Table transaction_id account_id transaction_type value transaction_date region branch_name
Мы можем выбрать раздел на любой ключ. Два возможных ключа могут быть
- область, край
- Дата сделки
Предположим, что бизнес организован в 30 географических регионах, и каждый регион имеет разное количество филиалов. Это даст нам 30 разделов, что разумно. Такое разбиение достаточно хорошо, потому что наши требования показали, что подавляющее большинство запросов ограничено собственным бизнес-регионом пользователя.
Если мы разделим по транзакции вместо даты по региону, то последняя транзакция из каждого региона будет в одном разделе. Теперь пользователь, который хочет просматривать данные в своем собственном регионе, должен выполнять запросы по нескольким разделам.
Следовательно, стоит определить правильный ключ разделения.
Хранилище данных — концепции метаданных
Что такое метаданные?
Метаданные просто определяются как данные о данных. Данные, которые используются для представления других данных, называются метаданными. Например, индекс книги служит метаданными для содержания в книге. Другими словами, мы можем сказать, что метаданные — это обобщенные данные, которые приводят нас к подробным данным. С точки зрения хранилища данных мы можем определить метаданные следующим образом.
-
Метаданные — это дорожная карта к хранилищу данных.
-
Метаданные в хранилище данных определяют объекты хранилища.
-
Метаданные действуют как каталог. Этот каталог помогает системе поддержки принятия решений определить местонахождение хранилища данных.
Метаданные — это дорожная карта к хранилищу данных.
Метаданные в хранилище данных определяют объекты хранилища.
Метаданные действуют как каталог. Этот каталог помогает системе поддержки принятия решений определить местонахождение хранилища данных.
Примечание. В хранилище данных мы создаем метаданные для имен данных и определений данного хранилища данных. Наряду с этими метаданными, дополнительные метаданные также создаются для отметки времени любых извлеченных данных, источника извлеченных данных.
Категории метаданных
Метаданные можно разделить на три категории:
-
Бизнес-метаданные. Содержит информацию о владельце данных, определение бизнеса и изменяющиеся политики.
-
Технические метаданные. Включают имена систем баз данных, имена и размеры таблиц и столбцов, типы данных и допустимые значения. Технические метаданные также включают структурную информацию, такую как атрибуты и индексы первичного и внешнего ключей.
-
Операционные метаданные — включает в себя валюту данных и линии передачи данных. Валюта данных означает, являются ли данные активными, заархивированными или очищенными. Происхождение данных означает историю перенесенных данных и примененных к ним преобразований.
Бизнес-метаданные. Содержит информацию о владельце данных, определение бизнеса и изменяющиеся политики.
Технические метаданные. Включают имена систем баз данных, имена и размеры таблиц и столбцов, типы данных и допустимые значения. Технические метаданные также включают структурную информацию, такую как атрибуты и индексы первичного и внешнего ключей.
Операционные метаданные — включает в себя валюту данных и линии передачи данных. Валюта данных означает, являются ли данные активными, заархивированными или очищенными. Происхождение данных означает историю перенесенных данных и примененных к ним преобразований.
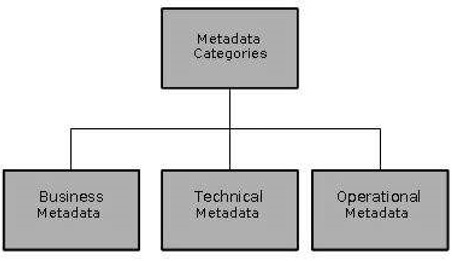
Роль метаданных
Метаданные играют очень важную роль в хранилище данных. Роль метаданных в хранилище отличается от данных хранилища, но играет важную роль. Различные роли метаданных объясняются ниже.
-
Метаданные действуют как каталог.
-
Этот каталог помогает системе поддержки принятия решений определить местонахождение хранилища данных.
-
Метаданные помогают в системе поддержки принятия решений для отображения данных при преобразовании данных из операционной среды в среду хранилища данных.
-
Метаданные помогают в обобщении между текущими подробными данными и сильно обобщенными данными.
-
Метаданные также помогают в обобщении между слегка детализированными данными и сильно обобщенными данными.
-
Метаданные используются для инструментов запросов.
-
Метаданные используются в инструментах извлечения и очистки.
-
Метаданные используются в инструментах отчетности.
-
Метаданные используются в инструментах преобразования.
-
Метаданные играют важную роль в загрузке функций.
Метаданные действуют как каталог.
Этот каталог помогает системе поддержки принятия решений определить местонахождение хранилища данных.
Метаданные помогают в системе поддержки принятия решений для отображения данных при преобразовании данных из операционной среды в среду хранилища данных.
Метаданные помогают в обобщении между текущими подробными данными и сильно обобщенными данными.
Метаданные также помогают в обобщении между слегка детализированными данными и сильно обобщенными данными.
Метаданные используются для инструментов запросов.
Метаданные используются в инструментах извлечения и очистки.
Метаданные используются в инструментах отчетности.
Метаданные используются в инструментах преобразования.
Метаданные играют важную роль в загрузке функций.
Следующая диаграмма показывает роли метаданных.
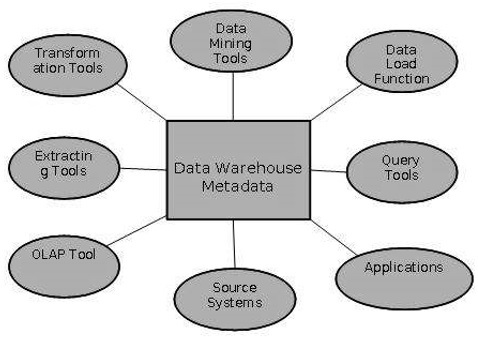
Хранилище метаданных
Хранилище метаданных является неотъемлемой частью системы хранилища данных. Он имеет следующие метаданные —
-
Определение хранилища данных — включает описание структуры хранилища данных. Описание определяется схемой, представлением, иерархиями, определениями производных данных, местоположениями и содержимым витрины данных.
-
Бизнес-метаданные. Содержит информацию о владельце данных, определение бизнеса и изменяющиеся политики.
-
Операционные метаданные — включает в себя валюту данных и линии передачи данных. Валюта данных означает, являются ли данные активными, заархивированными или очищенными. Происхождение данных означает историю перенесенных данных и примененных к ним преобразований.
-
Данные для отображения из операционной среды в хранилище данных — включает исходные базы данных и их содержимое, извлечение данных, очистку разделов данных, правила преобразования, правила обновления и очистки данных.
-
Алгоритмы суммирования — включает алгоритмы измерений, данные о гранулярности, агрегации, суммировании и т. Д.
Определение хранилища данных — включает описание структуры хранилища данных. Описание определяется схемой, представлением, иерархиями, определениями производных данных, местоположениями и содержимым витрины данных.
Бизнес-метаданные. Содержит информацию о владельце данных, определение бизнеса и изменяющиеся политики.
Операционные метаданные — включает в себя валюту данных и линии передачи данных. Валюта данных означает, являются ли данные активными, заархивированными или очищенными. Происхождение данных означает историю перенесенных данных и примененных к ним преобразований.
Данные для отображения из операционной среды в хранилище данных — включает исходные базы данных и их содержимое, извлечение данных, очистку разделов данных, правила преобразования, правила обновления и очистки данных.
Алгоритмы суммирования — включает алгоритмы измерений, данные о гранулярности, агрегации, суммировании и т. Д.
Проблемы управления метаданными
Важность метаданных невозможно переоценить. Метаданные помогают повысить точность отчетов, проверяют преобразование данных и обеспечивают точность расчетов. Метаданные также обеспечивают определение бизнес-терминов для конечных пользователей. Со всеми этими видами использования метаданных у него также есть свои проблемы. Некоторые из проблем обсуждаются ниже.
-
Метаданные в большой организации разбросаны по всей организации. Эти метаданные распространяются в электронных таблицах, базах данных и приложениях.
-
Метаданные могут присутствовать в текстовых файлах или мультимедийных файлах. Чтобы использовать эти данные для решений по управлению информацией, они должны быть правильно определены.
-
Общепромышленных стандартов не существует. Поставщики решений для управления данными имеют узкую направленность.
-
Нет простых и общепринятых способов передачи метаданных.
Метаданные в большой организации разбросаны по всей организации. Эти метаданные распространяются в электронных таблицах, базах данных и приложениях.
Метаданные могут присутствовать в текстовых файлах или мультимедийных файлах. Чтобы использовать эти данные для решений по управлению информацией, они должны быть правильно определены.
Общепромышленных стандартов не существует. Поставщики решений для управления данными имеют узкую направленность.
Нет простых и общепринятых способов передачи метаданных.
Хранилище данных — Мартинг данных
Зачем нам нужен Data Mart?
Ниже перечислены причины создания витрины данных —
-
Разделить данные, чтобы навязать стратегии контроля доступа.
-
Для ускорения запросов за счет уменьшения объема данных для сканирования.
-
Для сегментирования данных на разные аппаратные платформы.
-
Для структурирования данных в форме, подходящей для инструмента доступа пользователя.
Разделить данные, чтобы навязать стратегии контроля доступа.
Для ускорения запросов за счет уменьшения объема данных для сканирования.
Для сегментирования данных на разные аппаратные платформы.
Для структурирования данных в форме, подходящей для инструмента доступа пользователя.
Примечание. Не используйте витрину данных по любой другой причине, так как эксплуатационные затраты на витрину данных могут быть очень высокими Перед преобразованием данных убедитесь, что стратегия преобразования данных соответствует вашему конкретному решению.
Экономичное Маркетинг Данных
Следуйте приведенным ниже инструкциям, чтобы сделать вывод данных экономически эффективным —
- Определить функциональные расщепления
- Определите требования к инструменту доступа пользователя
- Определите проблемы контроля доступа
Определить функциональные расщепления
На этом этапе мы определяем, имеет ли организация естественные функциональные разделения. Мы ищем разделение между отделами и определяем, как отделы используют информацию, как правило, в изоляции от остальной части организации. Давайте иметь пример.
Рассмотрим розничную организацию, где каждый продавец отвечает за максимизацию продаж группы товаров. Для этого ниже приведены ценные сведения —
- сделка купли-продажи на ежедневной основе
- прогноз продаж на еженедельной основе
- позиция на бирже ежедневно
- движения акций на ежедневной основе
Поскольку продавец не заинтересован в продуктах, с которыми он не имеет дело, представление данных представляет собой подмножество данных, относящихся к группе продуктов, представляющей интерес. На следующей диаграмме показано распределение данных для разных пользователей.
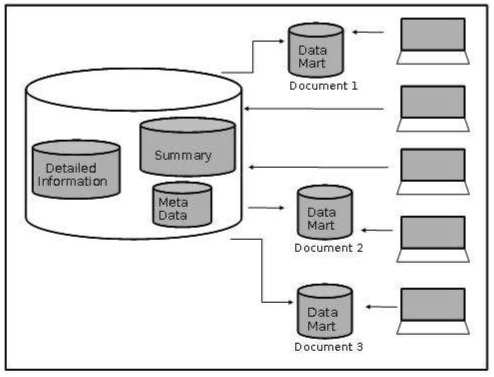
Ниже приведены вопросы, которые необходимо учитывать при определении функционального разделения —
-
Структура отдела может измениться.
-
Продукты могут переключаться из одного отдела в другой.
-
Продавец может запросить тенденцию продаж других продуктов, чтобы проанализировать, что происходит с продажами.
Структура отдела может измениться.
Продукты могут переключаться из одного отдела в другой.
Продавец может запросить тенденцию продаж других продуктов, чтобы проанализировать, что происходит с продажами.
Примечание. Нам необходимо определить преимущества для бизнеса и техническую осуществимость использования витрины данных.
Определите требования к инструменту доступа пользователя
Нам нужны витрины данных для поддержки пользовательских инструментов доступа, которые требуют внутренних структур данных. Данные в таких структурах находятся вне контроля хранилища данных, но их необходимо регулярно заполнять и обновлять.
Есть некоторые инструменты, которые заполняются непосредственно из исходной системы, но некоторые не могут. Поэтому дополнительные требования, выходящие за рамки данного инструмента, необходимо определить на будущее.
Примечание. Чтобы обеспечить согласованность данных во всех инструментах доступа, данные не должны заполняться напрямую из хранилища данных, а для каждого инструмента должен быть свой собственный киоск данных.
Определите проблемы контроля доступа
Должны быть правила конфиденциальности, обеспечивающие доступ к данным только авторизованным пользователям. Например, хранилище данных для розничного банковского учреждения гарантирует, что все счета принадлежат одному юридическому лицу. Законы о конфиденциальности могут заставить вас полностью запретить доступ к информации, которая не принадлежит конкретному банку.
Витрины данных позволяют нам построить целостную стену путем физического разделения сегментов данных в хранилище данных. Чтобы избежать возможных проблем с конфиденциальностью, подробные данные могут быть удалены из хранилища данных. Мы можем создать витрину данных для каждого юридического лица и загрузить ее через хранилище данных с подробными данными счета.
Проектирование витрин данных
Витрины данных должны быть спроектированы как уменьшенная версия схемы «звездных хлопьев» в хранилище данных и должны соответствовать структуре базы данных хранилища данных. Это помогает поддерживать контроль над экземплярами базы данных.
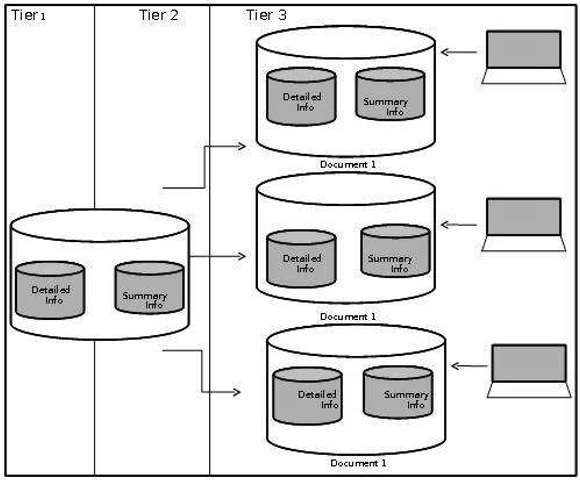
Сводные данные представляют собой данные, представленные таким же образом, как если бы они были разработаны в хранилище данных. Сводные таблицы помогают использовать все данные измерений в схеме starflake.
Стоимость передачи данных
Меры стоимости для передачи данных следующие:
- Стоимость аппаратного и программного обеспечения
- Доступ к сети
- Ограничения временного окна
Стоимость аппаратного и программного обеспечения
Хотя киоски данных создаются на одном и том же оборудовании, они требуют дополнительного оборудования и программного обеспечения. Для обработки пользовательских запросов требуется дополнительная вычислительная мощность и дисковое пространство. Если в хранилище данных существуют подробные данные и витрина данных, то мы столкнемся с дополнительными расходами на хранение и управление реплицированными данными.
Примечание. Мартинг данных является более дорогим, чем агрегации, поэтому его следует использовать как дополнительную стратегию, а не как альтернативную стратегию.
Доступ к сети
Витрина данных может находиться в другом месте, чем хранилище данных, поэтому мы должны убедиться, что локальная или глобальная сети способны обрабатывать объемы данных, передаваемые в процессе загрузки витрины данных.
Ограничения временного окна
Степень, в которой процесс загрузки витрины данных будет влиять в доступное временное окно, зависит от сложности преобразований и объемов отправляемых данных. Определение того, сколько витрин данных возможно, зависит от —
- Емкость сети.
- Доступно временное окно
- Объем передаваемых данных
- Механизмы, используемые для вставки данных в киоск данных
Хранилище данных — системные менеджеры
Управление системой является обязательным для успешного внедрения хранилища данных. Самые важные системные менеджеры —
- Менеджер конфигурации системы
- Диспетчер системного планирования
- Менеджер системных событий
- Системный менеджер баз данных
- Менеджер восстановления системы резервного копирования
Диспетчер конфигурации системы
-
Менеджер конфигурации системы отвечает за управление настройкой и настройкой хранилища данных.
-
Структура диспетчера конфигурации варьируется от одной операционной системы к другой.
-
В структуре конфигурации Unix менеджер варьируется от поставщика к поставщику.
-
Диспетчеры конфигурации имеют единый пользовательский интерфейс.
-
Интерфейс диспетчера конфигурации позволяет нам контролировать все аспекты системы.
Менеджер конфигурации системы отвечает за управление настройкой и настройкой хранилища данных.
Структура диспетчера конфигурации варьируется от одной операционной системы к другой.
В структуре конфигурации Unix менеджер варьируется от поставщика к поставщику.
Диспетчеры конфигурации имеют единый пользовательский интерфейс.
Интерфейс диспетчера конфигурации позволяет нам контролировать все аспекты системы.
Примечание . Наиболее важным инструментом настройки является диспетчер ввода-вывода.
Диспетчер системного планирования
Диспетчер системного планирования отвечает за успешное внедрение хранилища данных. Его целью является планирование специальных запросов. Каждая операционная система имеет свой собственный планировщик с той или иной формой механизма пакетного управления. Список функций, которые должен иметь диспетчер системного планирования, следующий:
- Работа через границы кластера или MPP
- Справиться с международными разницами во времени
- Справиться с ошибкой работы
- Обрабатывать несколько запросов
- Поддержка приоритетов работы
- Перезапустите или поставьте в очередь невыполненные задания
- Уведомить пользователя или процесс, когда работа завершена
- Ведение графиков работ при перебоях в работе системы
- Перераспределить задания в другие очереди
- Поддержка остановки и запуска очередей
- Журнал заданий в очереди
- Работа с обработкой между очередями
Примечание. Приведенный выше список можно использовать в качестве параметров оценки для оценки хорошего планировщика.
Вот некоторые важные задания, которые планировщик должен уметь выполнять:
- Ежедневное и специальное планирование запросов
- Выполнение требований регулярного отчета
- Загрузка данных
- Обработка данных
- Создание индекса
- Резервное копирование
- Создание агрегации
- Преобразование данных
Примечание. Если хранилище данных работает в кластерной или MPP-архитектуре, тогда диспетчер системного планирования должен быть способен работать по всей архитектуре.
Диспетчер системных событий
Менеджер событий — это своего рода программное обеспечение. Менеджер событий управляет событиями, которые определены в системе хранилища данных. Мы не можем управлять хранилищем данных вручную, потому что структура хранилища данных очень сложна. Поэтому нам нужен инструмент, который автоматически обрабатывает все события без какого-либо вмешательства пользователя.
Примечание. Менеджер событий отслеживает события и обрабатывает их. Менеджер событий также отслеживает множество вещей, которые могут пойти не так в этой сложной системе хранилища данных.
События
События — это действия, которые генерируются пользователем или самой системой. Можно отметить, что событие является измеримым, наблюдаемым появлением определенного действия.
Ниже приведен список общих событий, которые необходимо отслеживать.
- Аппаратный сбой
- Недостаточно места на некоторых ключевых дисках
- Процесс умирает
- Процесс, возвращающий ошибку
- Загрузка процессора превышает порог 805
- Внутренний конфликт на точках сериализации базы данных
- Превышение коэффициентов попадания в буферный кеш или сбой ниже порогового значения
- Стол, достигающий максимума своего размера
- Чрезмерная перестановка памяти
- Таблица не может быть расширена из-за недостатка места
- Диски с узкими местами ввода / вывода
- Использование временной или сортировочной зоны, достигающей определенных порогов
- Любое другое использование разделяемой памяти базы данных
Самая важная вещь о событиях — то, что они должны быть в состоянии выполнить самостоятельно. Пакеты событий определяют процедуры для предопределенных событий. Код, связанный с каждым событием, называется обработчиком события. Этот код выполняется всякий раз, когда происходит событие.
Менеджер системы и базы данных
Менеджер системы и базы данных может быть двумя отдельными частями программного обеспечения, но они выполняют одну и ту же работу. Цель этих инструментов — автоматизировать определенные процессы и упростить выполнение других. Критерии выбора системы и менеджера баз данных следующие:
- увеличить квоту пользователя.
- назначать и отменять назначение ролей пользователям
- назначать и отменять назначение профилей пользователям
- выполнять управление пространством базы данных
- контролировать и сообщать об использовании пространства
- привести в порядок фрагментированное и неиспользуемое пространство
- добавить и расширить пространство
- добавлять и удалять пользователей
- управлять паролем пользователя
- управлять сводными или временными таблицами
- назначить или отменить временное пространство для пользователя и от пользователя
- освободить пробел из старых или устаревших временных таблиц
- управлять журналами ошибок и трассировки
- просматривать файлы журналов и трассировки
- ошибка перенаправления или информация трассировки
- включить и выключить журнал ошибок и трассировки
- выполнять системное управление пространством
- контролировать и сообщать об использовании пространства
- очистить старые и неиспользуемые каталоги файлов
- добавить или расширить пространство.
Диспетчер резервного копирования системы
Средство резервного копирования и восстановления позволяет оператору и персоналу управления выполнять резервное копирование данных. Обратите внимание, что диспетчер резервного копирования системы должен быть интегрирован с используемым программным обеспечением диспетчера расписания. Важные функции, необходимые для управления резервными копиями:
- планирование
- Резервное копирование данных
- Осведомленность базы данных
Резервные копии создаются только для защиты от потери данных. Ниже приведены важные моменты, которые нужно помнить —
-
Программное обеспечение для резервного копирования будет хранить некоторую форму базы данных о том, где и когда была сохранена часть данных.
-
Менеджер резервного копирования должен иметь хороший внешний интерфейс для этой базы данных.
-
Программное обеспечение для резервного копирования должно быть осведомлено о базе данных.
-
Зная о базе данных, программное обеспечение может рассматриваться в терминах базы данных и не будет выполнять резервные копии, которые не будут жизнеспособными.
Программное обеспечение для резервного копирования будет хранить некоторую форму базы данных о том, где и когда была сохранена часть данных.
Менеджер резервного копирования должен иметь хороший внешний интерфейс для этой базы данных.
Программное обеспечение для резервного копирования должно быть осведомлено о базе данных.
Зная о базе данных, программное обеспечение может рассматриваться в терминах базы данных и не будет выполнять резервные копии, которые не будут жизнеспособными.
Хранилище данных — руководители процессов
Менеджеры процессов отвечают за поддержание потока данных как в хранилище данных, так и из него. Есть три разных типа менеджеров процессов —
- Менеджер нагрузки
- Заведующий складом
- Менеджер запросов
Диспетчер загрузки хранилища данных
Менеджер загрузки выполняет операции, необходимые для извлечения и загрузки данных в базу данных. Размер и сложность диспетчера нагрузки различаются в зависимости от конкретного решения для одного хранилища данных.
Архитектура диспетчера нагрузки
Диспетчер нагрузки выполняет следующие функции —
-
Извлечение данных из исходной системы.
-
Быстрая загрузка извлеченных данных во временное хранилище данных.
-
Выполните простые преобразования в структуру, похожую на структуру хранилища данных.
Извлечение данных из исходной системы.
Быстрая загрузка извлеченных данных во временное хранилище данных.
Выполните простые преобразования в структуру, похожую на структуру хранилища данных.
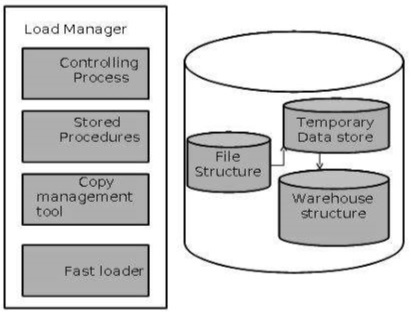
Извлечь данные из источника
Данные извлекаются из оперативных баз данных или внешних поставщиков информации. Шлюзы — это прикладные программы, которые используются для извлечения данных. Он поддерживается базовой СУБД и позволяет клиентской программе генерировать SQL для выполнения на сервере. Open Database Connection (ODBC) и Java Database Connection (JDBC) являются примерами шлюза.
Быстрая загрузка
-
Чтобы минимизировать общее окно загрузки, данные должны быть загружены в хранилище в кратчайшие сроки.
-
Преобразования влияют на скорость обработки данных.
-
Более эффективно загружать данные в реляционную базу данных до применения преобразований и проверок.
-
Технология шлюзов не подходит, так как они неэффективны, когда задействованы большие объемы данных.
Чтобы минимизировать общее окно загрузки, данные должны быть загружены в хранилище в кратчайшие сроки.
Преобразования влияют на скорость обработки данных.
Более эффективно загружать данные в реляционную базу данных до применения преобразований и проверок.
Технология шлюзов не подходит, так как они неэффективны, когда задействованы большие объемы данных.
Простые преобразования
Во время загрузки может потребоваться выполнить простые преобразования. После выполнения простых преобразований мы можем выполнять сложные проверки. Предположим, что мы загружаем транзакцию продажи EPOS, нам нужно выполнить следующие проверки:
- Удалите все столбцы, которые не требуются на складе.
- Преобразуйте все значения в требуемые типы данных.
Заведующий складом
Менеджер склада отвечает за процесс управления складом. Он состоит из стороннего системного программного обеспечения, программ на C и сценариев оболочки. Размер и сложность менеджера склада зависит от конкретных решений.
Архитектура менеджера склада
Менеджер склада включает в себя следующее:
- Процесс контроля
- Хранимые процедуры или C с SQL
- Инструмент резервного копирования / восстановления
- Скрипты SQL
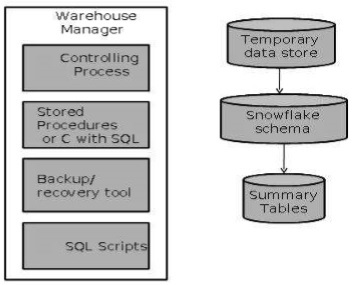
Функции менеджера склада
Менеджер склада выполняет следующие функции —
-
Анализирует данные для проверки целостности и проверки ссылочной целостности.
-
Создает индексы, бизнес-представления, разделы на основе базовых данных.
-
Создает новые агрегаты и обновляет существующие агрегаты.
-
Создает нормализации.
-
Преобразует и объединяет исходные данные временного хранилища в опубликованное хранилище данных.
-
Резервное копирование данных в хранилище данных.
-
Архивирует данные, которые достигли конца своей захваченной жизни.
Анализирует данные для проверки целостности и проверки ссылочной целостности.
Создает индексы, бизнес-представления, разделы на основе базовых данных.
Создает новые агрегаты и обновляет существующие агрегаты.
Создает нормализации.
Преобразует и объединяет исходные данные временного хранилища в опубликованное хранилище данных.
Резервное копирование данных в хранилище данных.
Архивирует данные, которые достигли конца своей захваченной жизни.
Примечание . Менеджер склада анализирует профили запросов, чтобы определить, подходят ли индекс и агрегаты.
Менеджер запросов
Менеджер запросов отвечает за направление запросов к подходящим таблицам. Направляя запросы в соответствующие таблицы, это ускоряет процесс запроса и ответа. Кроме того, диспетчер запросов отвечает за планирование выполнения запросов, публикуемых пользователем.
Архитектура Query Manager
Диспетчер запросов включает в себя следующие компоненты —
- Перенаправление запросов через инструмент C или RDBMS
- Хранимые процедуры
- Инструмент управления запросами
- Планирование запросов с помощью инструмента C или RDBMS
- Планирование запросов с помощью стороннего программного обеспечения
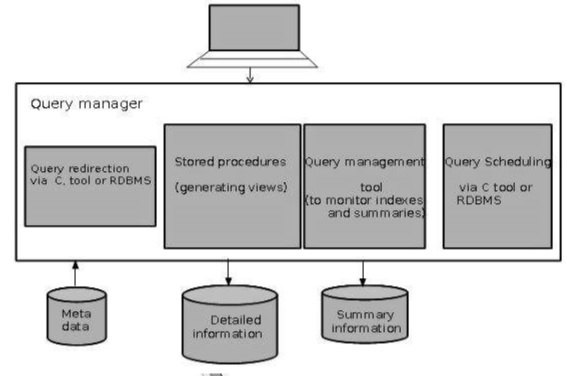
Функции диспетчера запросов
-
Он представляет данные пользователю в понятной им форме.
-
Он планирует выполнение запросов, опубликованных конечным пользователем.
-
В нем хранятся профили запросов, чтобы менеджер хранилища мог определить, какие индексы и агрегаты подходят.
Он представляет данные пользователю в понятной им форме.
Он планирует выполнение запросов, опубликованных конечным пользователем.
В нем хранятся профили запросов, чтобы менеджер хранилища мог определить, какие индексы и агрегаты подходят.
Хранилище данных — безопасность
Цель хранилища данных — сделать большие объемы данных легкодоступными для пользователей, что позволяет пользователям извлекать информацию о бизнесе в целом. Но мы знаем, что на данные могут быть наложены некоторые ограничения безопасности, которые могут стать препятствием для доступа к информации. Если аналитик имеет ограниченное представление о данных, то невозможно получить полную картину тенденций в бизнесе.
Данные от каждого аналитика могут быть обобщены и переданы руководству, где могут быть агрегированы различные сводные данные. Поскольку совокупность сводок не может быть такой же, как и совокупность в целом, можно пропустить некоторые информационные тренды в данных, если кто-то не анализирует данные в целом.
Требования безопасности
Добавление функций безопасности влияет на производительность хранилища данных, поэтому важно определить требования безопасности как можно раньше. Трудно добавить функции безопасности после запуска хранилища данных.
На этапе проектирования хранилища данных мы должны помнить, какие источники данных могут быть добавлены позже и как это повлияет на добавление этих источников данных. Мы должны рассмотреть следующие возможности на этапе проектирования.
-
Будут ли новые источники данных требовать введения новых ограничений безопасности и / или аудита?
-
Добавлены ли новые пользователи, которые имеют ограниченный доступ к данным, которые уже общедоступны?
Будут ли новые источники данных требовать введения новых ограничений безопасности и / или аудита?
Добавлены ли новые пользователи, которые имеют ограниченный доступ к данным, которые уже общедоступны?
Такая ситуация возникает, когда будущие пользователи и источники данных недостаточно известны. В такой ситуации нам необходимо использовать знания бизнеса и цели хранилища данных, чтобы знать возможные требования.
Следующие действия затрагиваются мерами безопасности —
- Доступ пользователя
- Загрузка данных
- Перемещение данных
- Генерация запросов
Доступ пользователя
Нам нужно сначала классифицировать данные, а затем классифицировать пользователей на основе данных, к которым они могут получить доступ. Другими словами, пользователи классифицируются в соответствии с данными, к которым они могут получить доступ.
Классификация данных
Следующие два подхода могут быть использованы для классификации данных —
-
Данные могут быть классифицированы в соответствии с их чувствительностью. Высокочувствительные данные классифицируются как строго ограниченные, а менее чувствительные данные классифицируются как менее строгие.
-
Данные также могут быть классифицированы в соответствии с функцией работы. Это ограничение позволяет только определенным пользователям просматривать конкретные данные. Здесь мы ограничиваем пользователей просматривать только ту часть данных, в которой они заинтересованы и за которую несут ответственность.
Данные могут быть классифицированы в соответствии с их чувствительностью. Высокочувствительные данные классифицируются как строго ограниченные, а менее чувствительные данные классифицируются как менее строгие.
Данные также могут быть классифицированы в соответствии с функцией работы. Это ограничение позволяет только определенным пользователям просматривать конкретные данные. Здесь мы ограничиваем пользователей просматривать только ту часть данных, в которой они заинтересованы и за которую несут ответственность.
Есть некоторые проблемы во втором подходе. Чтобы понять, давайте иметь пример. Предположим, вы создаете хранилище данных для банка. Учтите, что данные, хранящиеся в хранилище данных, являются данными транзакций для всех учетных записей. Вопрос здесь в том, кому разрешено просматривать данные транзакции. Решение заключается в классификации данных в соответствии с функцией.
Пользовательская классификация
Следующие подходы могут быть использованы для классификации пользователей —
-
Пользователи могут быть классифицированы в соответствии с иерархией пользователей в организации, то есть пользователи могут быть классифицированы по отделам, разделам, группам и т. Д.
-
Пользователи также могут быть классифицированы в соответствии с их ролью, а люди сгруппированы по отделам в зависимости от их роли.
Пользователи могут быть классифицированы в соответствии с иерархией пользователей в организации, то есть пользователи могут быть классифицированы по отделам, разделам, группам и т. Д.
Пользователи также могут быть классифицированы в соответствии с их ролью, а люди сгруппированы по отделам в зависимости от их роли.
Классификация на основе кафедры
Давайте рассмотрим пример хранилища данных, где пользователи из отдела продаж и маркетинга. Мы можем обеспечить безопасность с точки зрения компании сверху вниз, причем доступ сосредоточен на разных отделах. Но могут быть некоторые ограничения для пользователей на разных уровнях. Эта структура показана на следующей диаграмме.
Но если каждый отдел получает доступ к разным данным, мы должны разработать безопасный доступ для каждого отдела в отдельности. Это может быть достигнуто за счет витрин данных отдела. Поскольку эти витрины данных отделены от хранилища данных, мы можем применять отдельные ограничения безопасности для каждого киоска данных. Этот подход показан на следующем рисунке.
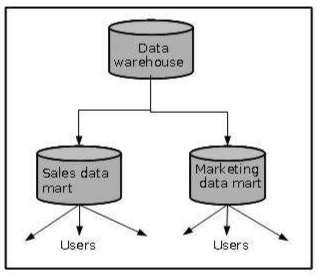
Классификация на основе роли
Если данные, как правило, доступны для всех отделов, полезно следовать иерархии доступа к ролям. Другими словами, если к данным обычно обращаются все отделы, тогда применяются ограничения безопасности в соответствии с ролью пользователя. Иерархия доступа к ролям показана на следующем рисунке.
Требования к аудиту
Аудит является подмножеством безопасности, дорогостоящей деятельностью. Аудит может привести к значительным накладным расходам в системе. Чтобы вовремя завершить аудит, нам требуется больше оборудования, и поэтому рекомендуется, по возможности, отключать аудит. Требования аудита могут быть классифицированы следующим образом:
- связи
- Отключения
- Доступ к данным
- Изменение данных
Примечание. Для каждой из вышеупомянутых категорий необходимо провести аудит успеха, неудачи или того и другого. С точки зрения безопасности, аудит сбоев очень важен. Аудит отказов важен, потому что они могут выделить несанкционированный или мошеннический доступ.
Требования к сети
Безопасность сети так же важна, как и другие ценные бумаги. Мы не можем игнорировать требования безопасности сети. Нам нужно рассмотреть следующие вопросы —
-
Нужно ли шифровать данные перед их передачей в хранилище данных?
-
Существуют ли ограничения на какие сетевые маршруты могут принимать данные?
Нужно ли шифровать данные перед их передачей в хранилище данных?
Существуют ли ограничения на какие сетевые маршруты могут принимать данные?
Эти ограничения должны быть тщательно рассмотрены. Ниже приведены моменты, которые нужно помнить —
-
Процесс шифрования и дешифрования увеличит накладные расходы. Это потребовало бы большей вычислительной мощности и времени обработки.
-
Стоимость шифрования может быть высокой, если система уже является загруженной системой, поскольку шифрование несет исходная система.
Процесс шифрования и дешифрования увеличит накладные расходы. Это потребовало бы большей вычислительной мощности и времени обработки.
Стоимость шифрования может быть высокой, если система уже является загруженной системой, поскольку шифрование несет исходная система.
Движение данных
Существуют потенциальные последствия для безопасности при перемещении данных. Предположим, нам нужно передать некоторые ограниченные данные в виде плоского файла для загрузки. Когда данные загружаются в хранилище данных, возникают следующие вопросы:
- Где хранится плоский файл?
- У кого есть доступ к этому дисковому пространству?
Если мы говорим о резервном копировании этих плоских файлов, возникают следующие вопросы:
- Вы резервное копирование зашифрованных или дешифрованных версий?
- Нужно ли делать эти резервные копии на специальные ленты, которые хранятся отдельно?
- У кого есть доступ к этим лентам?
Также необходимо учитывать некоторые другие формы перемещения данных, такие как наборы результатов запроса. Вопросы, поднятые при создании временной таблицы, следующие:
- Где находится этот временный стол?
- Как вы делаете такую таблицу видимой?
Мы должны избегать случайного нарушения требований безопасности. Если пользователь с доступом к ограниченным данным может создавать доступные временные таблицы, данные могут быть видны неавторизованным пользователям. Мы можем преодолеть эту проблему, имея отдельную временную область для пользователей с доступом к ограниченным данным.
Документация
Требования аудита и безопасности должны быть надлежащим образом задокументированы. Это будет рассматриваться как часть оправдания. Этот документ может содержать всю информацию, полученную от —
- Классификация данных
- Пользовательская классификация
- Требования к сети
- Требования к перемещению и хранению данных
- Все проверяемые действия
Влияние безопасности на дизайн
Безопасность влияет на код приложения и сроки разработки. Безопасность влияет на следующую область —
- Разработка приложения
- Дизайн базы данных
- тестирование
Разработка приложения
Безопасность влияет на общую разработку приложений, а также на разработку важных компонентов хранилища данных, таких как менеджер нагрузки, менеджер хранилища и менеджер запросов. Диспетчер загрузки может потребовать проверки кода для фильтрации записей и размещения их в разных местах. Также могут потребоваться дополнительные правила преобразования, чтобы скрыть определенные данные. Также могут быть требования дополнительных метаданных для обработки любых дополнительных объектов.
Чтобы создать и поддерживать дополнительные представления, менеджеру хранилища может потребоваться дополнительный код для обеспечения безопасности. Дополнительные проверки, возможно, должны быть закодированы в хранилище данных, чтобы предотвратить его одурачивание для перемещения данных в место, где они не должны быть доступны. Диспетчер запросов требует изменений для обработки любых ограничений доступа. Диспетчер запросов должен знать обо всех дополнительных представлениях и агрегатах.
Дизайн базы данных
На структуру базы данных также влияет, потому что, когда меры безопасности осуществляются, увеличивается количество представлений и таблиц. Добавление безопасности увеличивает размер базы данных и, следовательно, увеличивает сложность проектирования и управления базой данных. Это также увеличит сложность плана управления резервным копированием и восстановления.
тестирование
Тестирование хранилища данных — сложный и длительный процесс. Повышение безопасности хранилища данных также влияет на сложность времени тестирования. Это влияет на тестирование следующими двумя способами —
-
Это увеличит время, необходимое для интеграции и тестирования системы.
-
Добавлена функциональность для тестирования, которая увеличит размер пакета тестирования.
Это увеличит время, необходимое для интеграции и тестирования системы.
Добавлена функциональность для тестирования, которая увеличит размер пакета тестирования.
Хранилище данных — Резервное копирование
Хранилище данных — это сложная система, которая содержит огромный объем данных. Поэтому важно выполнить резервное копирование всех данных, чтобы они стали доступны для восстановления в будущем в соответствии с требованиями. В этой главе мы обсудим вопросы при разработке стратегии резервного копирования.
Терминологии резервного копирования
Прежде чем продолжить, вы должны знать некоторые термины резервного копирования, описанные ниже.
-
Полное резервное копирование — резервное копирование всей базы данных одновременно. Эта резервная копия включает в себя все файлы базы данных, управляющие файлы и файлы журнала.
-
Частичное резервное копирование. Как следует из названия, оно не создает полную резервную копию базы данных. Частичное резервное копирование очень полезно в больших базах данных, потому что они допускают стратегию, согласно которой различные части базы данных резервируются в циклическом порядке на ежедневной основе, так что резервное копирование всей базы данных выполняется раз в неделю.
-
Холодное резервное копирование — холодное резервное копирование выполняется, когда база данных полностью закрыта. В среде с несколькими экземплярами все экземпляры должны быть закрыты.
-
Горячее резервное копирование — горячее резервное копирование выполняется, когда ядро базы данных запущено и работает. Требования к горячему резервированию варьируются от СУБД к СУБД.
-
Резервное копирование в онлайн-хранилище — оно очень похоже на горячее резервное копирование.
Полное резервное копирование — резервное копирование всей базы данных одновременно. Эта резервная копия включает в себя все файлы базы данных, управляющие файлы и файлы журнала.
Частичное резервное копирование. Как следует из названия, оно не создает полную резервную копию базы данных. Частичное резервное копирование очень полезно в больших базах данных, потому что они допускают стратегию, согласно которой различные части базы данных резервируются в циклическом порядке на ежедневной основе, так что резервное копирование всей базы данных выполняется раз в неделю.
Холодное резервное копирование — холодное резервное копирование выполняется, когда база данных полностью закрыта. В среде с несколькими экземплярами все экземпляры должны быть закрыты.
Горячее резервное копирование — горячее резервное копирование выполняется, когда ядро базы данных запущено и работает. Требования к горячему резервированию варьируются от СУБД к СУБД.
Резервное копирование в онлайн-хранилище — оно очень похоже на горячее резервное копирование.
Аппаратное резервное копирование
Важно решить, какое оборудование использовать для резервного копирования. Скорость обработки резервного копирования и восстановления зависит от используемого оборудования, способа подключения оборудования, пропускной способности сети, программного обеспечения для резервного копирования и скорости системы ввода-вывода сервера. Здесь мы обсудим некоторые из доступных аппаратных средств и их плюсы и минусы. Эти выборы следующие:
- Ленточная технология
- Резервные копии дисков
Ленточная технология
Выбор ленты можно классифицировать следующим образом:
- Лента медиа
- Автономные ленточные накопители
- Ленточные накопители
- Ленточные силосы
Лента Медиа
Существует несколько разновидностей ленточных носителей. Некоторые стандарты носителей на магнитной ленте перечислены в таблице ниже.
| Лента Медиа | Вместимость | Скорость ввода / вывода |
|---|---|---|
| DLT | 40 ГБ | 3 МБ / с |
| 3490E | 1,6 ГБ | 3 МБ / с |
| 8 мм | 14 ГБ | 1 МБ / с |
Другие факторы, которые необходимо учитывать, следующие:
- Надежность магнитной ленты
- Стоимость ленточного носителя за единицу
- Масштабируемость
- Стоимость обновлений до ленточной системы
- Стоимость ленточного носителя за единицу
- Срок годности ленты среднего
Автономные ленточные накопители
Ленточные накопители можно подключить следующими способами:
- Прямо на сервер
- В сети доступны устройства
- Удаленно на другую машину
Могут возникнуть проблемы при подключении стримеров к хранилищу данных.
-
Предположим, что сервер является машиной с 48 узлами MPP. Мы не знаем узла для подключения ленточного накопителя и не знаем, как распределить их по узлам сервера, чтобы получить оптимальную производительность с наименьшим нарушением работы сервера и наименьшей внутренней задержкой ввода-вывода.
-
Подключение стримера в качестве устройства, доступного в сети, требует от сети высокой скорости передачи данных. Убедитесь, что достаточная пропускная способность доступна в то время, когда вам это нужно.
-
Удаленное подключение стримеров также требует высокой пропускной способности.
Предположим, что сервер является машиной с 48 узлами MPP. Мы не знаем узла для подключения ленточного накопителя и не знаем, как распределить их по узлам сервера, чтобы получить оптимальную производительность с наименьшим нарушением работы сервера и наименьшей внутренней задержкой ввода-вывода.
Подключение стримера в качестве устройства, доступного в сети, требует от сети высокой скорости передачи данных. Убедитесь, что достаточная пропускная способность доступна в то время, когда вам это нужно.
Удаленное подключение стримеров также требует высокой пропускной способности.
Накопители ленты
Способ загрузки нескольких лент в один ленточный накопитель известен как накопители на магнитной ленте. Укладчик размонтирует текущую ленту, когда закончит с ней, и загрузит следующую ленту, следовательно, одновременно доступна только одна лента. Цена и возможности могут различаться, но общая возможность заключается в том, что они могут выполнять автоматическое резервное копирование.
Ленточные силосы
Ленточные силосы обеспечивают большие емкости магазина. Ленточные хранилища могут хранить и управлять тысячами лент. Они могут интегрировать несколько стримеров. У них есть программное и аппаратное обеспечение для маркировки и хранения лент, которые они хранят. Очень часто бункер подключается удаленно по сети или по выделенному каналу. Мы должны убедиться, что пропускная способность соединения зависит от работы.
Резервные копии дисков
Методы резервного копирования на диск —
- Резервное копирование с диска на диск
- Разбитое зеркало
Эти методы используются в системе OLTP. Эти методы минимизируют время простоя базы данных и максимизируют доступность.
Резервное копирование с диска на диск
Здесь резервное копирование делается на диск, а не на ленту. Резервное копирование с диска на диск выполняется по следующим причинам:
- Скорость начальных резервных копий
- Скорость восстановления
Резервное копирование данных с диска на диск происходит намного быстрее, чем на ленту. Однако это промежуточный этап резервного копирования. Позже данные копируются на ленту. Другое преимущество резервного копирования с диска на диск заключается в том, что он предоставляет вам онлайн-копию последней резервной копии.
Зеркальное разрушение
Идея состоит в том, чтобы диски были отражены для устойчивости в течение рабочего дня. Когда требуется резервное копирование, один из наборов зеркал может быть поврежден. Этот метод является вариантом резервного копирования с диска на диск.
Примечание . Может потребоваться отключение базы данных, чтобы гарантировать целостность резервной копии.
Оптические музыкальные автоматы
Оптические музыкальные автоматы позволяют хранить данные рядом с линией. Этот метод позволяет управлять большим количеством оптических дисков так же, как накопитель на магнитной ленте или накопитель на ленте. Недостаток этого метода в том, что он имеет более низкую скорость записи, чем диски. Но оптические носители обеспечивают длительный срок службы и надежность, что делает их хорошим выбором среды для архивирования.
Резервное копирование программного обеспечения
Доступны программные средства, которые помогают в процессе резервного копирования. Эти программные инструменты поставляются в комплекте. Эти инструменты не только выполняют резервное копирование, они могут эффективно управлять и контролировать стратегии резервного копирования. Есть много пакетов программного обеспечения, доступных на рынке. Некоторые из них перечислены в следующей таблице —
| Имя пакета | продавец |
|---|---|
| Сетевик | Легато |
| ADSM | IBM |
| эпоха | Epoch Systems |
| Омнибак II | HP |
| Александрия | последовательный |
Критерии выбора пакетов программного обеспечения
Критерии выбора лучшего программного пакета перечислены ниже —
- Насколько масштабируем продукт при добавлении ленточных накопителей?
- У пакета есть опция клиент-сервер, или он должен работать на самом сервере базы данных?
- Будет ли это работать в кластере и средах MPP?
- Какая степень параллелизма требуется?
- Какие платформы поддерживаются пакетом?
- Поддерживает ли пакет легкий доступ к информации о содержимом ленты?
- База данных пакета осведомлена?
- Какие ленточные накопители и ленточные носители поддерживаются пакетом?
Хранилище данных — Тюнинг
Хранилище данных продолжает развиваться, и непредсказуемо, какой запрос пользователь собирается публиковать в будущем. Поэтому становится сложнее настроить систему хранилища данных. В этой главе мы обсудим, как настроить различные аспекты хранилища данных, такие как производительность, загрузка данных, запросы и т. Д.
Трудности в настройке хранилища данных
Настройка хранилища данных является сложной процедурой по следующим причинам:
-
Хранилище данных является динамичным; оно никогда не остается постоянным.
-
Очень сложно предсказать, какой запрос пользователь отправит в будущем.
-
Бизнес-требования меняются со временем.
-
Пользователи и их профили постоянно меняются.
-
Пользователь может переключаться из одной группы в другую.
-
Загрузка данных на склад также меняется со временем.
Хранилище данных является динамичным; оно никогда не остается постоянным.
Очень сложно предсказать, какой запрос пользователь отправит в будущем.
Бизнес-требования меняются со временем.
Пользователи и их профили постоянно меняются.
Пользователь может переключаться из одной группы в другую.
Загрузка данных на склад также меняется со временем.
Примечание. Очень важно иметь полное представление о хранилище данных.
Оценка эффективности
Вот список объективных показателей эффективности —
- Среднее время ответа на запрос
- Скорость сканирования
- Время, использованное на запрос дня
- Использование памяти на процесс
- Пропускная способность ввода / вывода
Ниже приведены моменты, которые нужно помнить.
-
Необходимо указать меры в соглашении об уровне обслуживания (SLA).
-
Бесполезно пытаться настроить время отклика, если оно уже лучше, чем требуется.
-
Важно иметь реалистичные ожидания при оценке эффективности.
-
Также важно, чтобы у пользователей были реальные ожидания.
-
Чтобы скрыть сложность системы от пользователя, следует использовать агрегаты и представления.
-
Также возможно, что пользователь может написать запрос, который вы не настроили.
Необходимо указать меры в соглашении об уровне обслуживания (SLA).
Бесполезно пытаться настроить время отклика, если оно уже лучше, чем требуется.
Важно иметь реалистичные ожидания при оценке эффективности.
Также важно, чтобы у пользователей были реальные ожидания.
Чтобы скрыть сложность системы от пользователя, следует использовать агрегаты и представления.
Также возможно, что пользователь может написать запрос, который вы не настроили.
Настройка загрузки данных
Загрузка данных является важной частью ночной обработки. Ничто другое не может работать, пока загрузка данных не будет завершена. Это точка входа в систему.
Примечание. Если при передаче данных или при получении данных возникает задержка, это влияет на всю систему. Поэтому очень важно сначала настроить загрузку данных.
Существуют различные подходы настройки загрузки данных, которые обсуждаются ниже —
-
Самым распространенным подходом является вставка данных с использованием уровня SQL . При таком подходе необходимо выполнять обычные проверки и ограничения. Когда данные вставляются в таблицу, запускается код, чтобы проверить, достаточно ли места для вставки данных. Если недостаточно места, возможно, потребуется больше места для этих таблиц. Эти проверки требуют времени для выполнения и являются дорогостоящими для процессора.
-
Второй подход состоит в том, чтобы обойти все эти проверки и ограничения и поместить данные непосредственно в предварительно отформатированные блоки. Эти блоки позже записываются в базу данных. Это быстрее, чем первый подход, но он может работать только с целыми блоками данных. Это может привести к некоторой потере пространства.
-
Третий подход заключается в том, что при загрузке данных в таблицу, которая уже содержит таблицу, мы можем поддерживать индексы.
-
Четвертый подход говорит, что для загрузки данных в таблицы, которые уже содержат данные, отбросьте индексы и воссоздайте их, когда загрузка данных будет завершена. Выбор между третьим и четвертым подходом зависит от того, сколько данных уже загружено и сколько индексов необходимо перестроить.
Самым распространенным подходом является вставка данных с использованием уровня SQL . При таком подходе необходимо выполнять обычные проверки и ограничения. Когда данные вставляются в таблицу, запускается код, чтобы проверить, достаточно ли места для вставки данных. Если недостаточно места, возможно, потребуется больше места для этих таблиц. Эти проверки требуют времени для выполнения и являются дорогостоящими для процессора.
Второй подход состоит в том, чтобы обойти все эти проверки и ограничения и поместить данные непосредственно в предварительно отформатированные блоки. Эти блоки позже записываются в базу данных. Это быстрее, чем первый подход, но он может работать только с целыми блоками данных. Это может привести к некоторой потере пространства.
Третий подход заключается в том, что при загрузке данных в таблицу, которая уже содержит таблицу, мы можем поддерживать индексы.
Четвертый подход говорит, что для загрузки данных в таблицы, которые уже содержат данные, отбросьте индексы и воссоздайте их, когда загрузка данных будет завершена. Выбор между третьим и четвертым подходом зависит от того, сколько данных уже загружено и сколько индексов необходимо перестроить.
Проверка целостности
Проверка целостности сильно влияет на производительность нагрузки. Ниже приведены моменты, которые нужно помнить —
-
Проверки целостности должны быть ограничены, потому что они требуют большой вычислительной мощности.
-
Проверка целостности должна применяться в исходной системе, чтобы избежать снижения производительности при загрузке данных.
Проверки целостности должны быть ограничены, потому что они требуют большой вычислительной мощности.
Проверка целостности должна применяться в исходной системе, чтобы избежать снижения производительности при загрузке данных.
Настройка запросов
У нас есть два вида запросов в хранилище данных —
- Фиксированные запросы
- Специальные запросы
Фиксированные Запросы
Фиксированные запросы четко определены. Ниже приведены примеры фиксированных запросов:
- регулярные отчеты
- Консервированные запросы
- Общие скопления
Настройка фиксированных запросов в хранилище данных такая же, как в реляционной системе баз данных. Разница лишь в том, что объем запрашиваемых данных может быть разным. Рекомендуется хранить наиболее успешный план выполнения при тестировании фиксированных запросов. Сохранение этого плана выполнения позволит нам определить изменение размера данных и перекос данных, поскольку это приведет к изменению плана выполнения.
Примечание. Мы не можем сделать больше для таблиц фактов, но при работе с таблицами измерений или агрегатами для настройки этих запросов можно использовать обычный набор настроек SQL, механизм хранения и методы доступа.
Специальные запросы
Чтобы понять специальные запросы, важно знать специальных пользователей хранилища данных. Для каждого пользователя или группы пользователей необходимо знать следующее:
- Количество пользователей в группе
- Используют ли они специальные запросы через регулярные промежутки времени
- Часто ли они используют специальные запросы
- Используют ли они специальные запросы иногда с неизвестными интервалами.
- Максимальный размер запроса, который они склонны выполнять
- Средний размер запроса, который они склонны выполнять
- Требуют ли они детализированного доступа к базовым данным
- Истекшее время входа в день
- Пиковое время ежедневного использования
- Количество запросов, которые они запускают в час пик
Указывает на заметку
-
Важно отслеживать профили пользователей и определять запросы, которые выполняются на регулярной основе.
-
Также важно, чтобы выполненная настройка не влияла на производительность.
-
Определите похожие и специальные запросы, которые часто выполняются.
-
Если эти запросы идентифицированы, база данных изменится, и для этих запросов могут быть добавлены новые индексы.
-
Если эти запросы идентифицированы, то могут быть созданы новые агрегаты специально для тех запросов, которые приведут к их эффективному выполнению.
Важно отслеживать профили пользователей и определять запросы, которые выполняются на регулярной основе.
Также важно, чтобы выполненная настройка не влияла на производительность.
Определите похожие и специальные запросы, которые часто выполняются.
Если эти запросы идентифицированы, база данных изменится, и для этих запросов могут быть добавлены новые индексы.
Если эти запросы идентифицированы, то могут быть созданы новые агрегаты специально для тех запросов, которые приведут к их эффективному выполнению.
Хранилище данных — Тестирование
Тестирование очень важно для систем хранилищ данных, чтобы они работали правильно и эффективно. Существует три основных уровня тестирования, выполняемых в хранилище данных:
- Модульное тестирование
- Интеграционное тестирование
- Тестирование системы
Модульное тестирование
-
В модульном тестировании каждый компонент тестируется отдельно.
-
Каждый модуль, т. Е. Процедура, программа, SQL Script, оболочка Unix проверяется.
-
Этот тест выполняется разработчиком.
В модульном тестировании каждый компонент тестируется отдельно.
Каждый модуль, т. Е. Процедура, программа, SQL Script, оболочка Unix проверяется.
Этот тест выполняется разработчиком.
Интеграционное тестирование
-
В интеграционном тестировании различные модули приложения объединяются, а затем проверяются на количество входов.
-
Это выполняется для проверки, хорошо ли работают различные компоненты после интеграции.
В интеграционном тестировании различные модули приложения объединяются, а затем проверяются на количество входов.
Это выполняется для проверки, хорошо ли работают различные компоненты после интеграции.
Тестирование системы
-
При тестировании системы все приложение хранилища данных тестируется вместе.
-
Целью тестирования системы является проверка правильности совместной работы всей системы.
-
Тестирование системы выполняется командой тестирования.
-
Поскольку размер всего хранилища данных очень велик, обычно можно выполнить минимальное тестирование системы, прежде чем можно будет принять план тестирования.
При тестировании системы все приложение хранилища данных тестируется вместе.
Целью тестирования системы является проверка правильности совместной работы всей системы.
Тестирование системы выполняется командой тестирования.
Поскольку размер всего хранилища данных очень велик, обычно можно выполнить минимальное тестирование системы, прежде чем можно будет принять план тестирования.
Расписание испытаний
Прежде всего, график тестирования создается в процессе разработки плана тестирования. В этом графике мы прогнозируем приблизительное время, необходимое для тестирования всей системы хранилища данных.
Существуют различные методологии для создания расписания тестирования, но ни одна из них не является идеальной, поскольку хранилище данных очень сложное и большое. Также система хранения данных развивается в природе. При создании расписания тестирования могут возникнуть следующие проблемы:
-
Простая проблема может иметь большой размер запроса, который может занять день или более, то есть запрос не выполняется в желаемом масштабе времени.
-
Возможны сбои оборудования, такие как потеря диска или ошибки пользователя, например, случайное удаление таблицы или перезапись большой таблицы.
Простая проблема может иметь большой размер запроса, который может занять день или более, то есть запрос не выполняется в желаемом масштабе времени.
Возможны сбои оборудования, такие как потеря диска или ошибки пользователя, например, случайное удаление таблицы или перезапись большой таблицы.
Примечание. Из-за вышеупомянутых трудностей рекомендуется всегда удваивать время, которое вы обычно предоставляете для тестирования.
Тестирование Backup Recovery
Тестирование стратегии резервного копирования чрезвычайно важно. Вот список сценариев, для которых необходимо это тестирование:
- Медиа провал
- Потеря или повреждение табличного пространства или файла данных
- Потеря или повреждение файла журнала повторов
- Потеря или повреждение контрольного файла
- Ошибка экземпляра
- Потеря или повреждение архивного файла
- Потеря или повреждение стола
- Сбой во время сбоя данных
Тестирование операционной среды
Есть ряд аспектов, которые необходимо проверить. Эти аспекты перечислены ниже.
-
Безопасность — для проверки безопасности требуется отдельный документ безопасности. Этот документ содержит список запрещенных операций и разработанных тестов для каждого.
-
Планировщик — программное обеспечение для планирования требуется для контроля ежедневных операций хранилища данных. Это необходимо проверить во время тестирования системы. Для программного обеспечения планирования требуется интерфейс с хранилищем данных, которому потребуется планировщик для управления обработкой в течение ночи и управления агрегатами.
-
Конфигурация диска. — Конфигурацию диска также необходимо протестировать для выявления узких мест ввода-вывода. Тест должен быть выполнен несколько раз с различными настройками.
-
Инструменты управления. — Требуется протестировать все инструменты управления во время тестирования системы. Вот список инструментов, которые необходимо протестировать.
- Менеджер по корпоративным мероприятиям
- Системный менеджер
- Менеджер баз данных
- Менеджер конфигурации
- Диспетчер резервного копирования
Безопасность — для проверки безопасности требуется отдельный документ безопасности. Этот документ содержит список запрещенных операций и разработанных тестов для каждого.
Планировщик — программное обеспечение для планирования требуется для контроля ежедневных операций хранилища данных. Это необходимо проверить во время тестирования системы. Для программного обеспечения планирования требуется интерфейс с хранилищем данных, которому потребуется планировщик для управления обработкой в течение ночи и управления агрегатами.
Конфигурация диска. — Конфигурацию диска также необходимо протестировать для выявления узких мест ввода-вывода. Тест должен быть выполнен несколько раз с различными настройками.
Инструменты управления. — Требуется протестировать все инструменты управления во время тестирования системы. Вот список инструментов, которые необходимо протестировать.
Тестирование базы данных
База данных тестируется следующими тремя способами:
-
Тестирование менеджера баз данных и инструментов мониторинга. Для тестирования менеджера баз данных и инструментов мониторинга их следует использовать при создании, запуске и управлении тестовой базой данных.
-
Тестирование функций базы данных — вот список функций, которые мы должны протестировать —
-
Запросы параллельно
-
Создать индекс параллельно
-
Загрузка данных параллельно
-
-
Тестирование производительности базы данных. Выполнение запросов играет очень важную роль в показателях производительности хранилища данных. Существуют наборы фиксированных запросов, которые необходимо регулярно выполнять, и они должны быть протестированы. Чтобы протестировать специальные запросы, нужно пройти документ с требованиями пользователя и полностью понять бизнес. Потратьте время, чтобы протестировать самые неуклюжие запросы, которые бизнес, вероятно, будет задавать в отношении различных стратегий индексации и агрегирования.
Тестирование менеджера баз данных и инструментов мониторинга. Для тестирования менеджера баз данных и инструментов мониторинга их следует использовать при создании, запуске и управлении тестовой базой данных.
Тестирование функций базы данных — вот список функций, которые мы должны протестировать —
Запросы параллельно
Создать индекс параллельно
Загрузка данных параллельно
Тестирование производительности базы данных. Выполнение запросов играет очень важную роль в показателях производительности хранилища данных. Существуют наборы фиксированных запросов, которые необходимо регулярно выполнять, и они должны быть протестированы. Чтобы протестировать специальные запросы, нужно пройти документ с требованиями пользователя и полностью понять бизнес. Потратьте время, чтобы протестировать самые неуклюжие запросы, которые бизнес, вероятно, будет задавать в отношении различных стратегий индексации и агрегирования.
Тестирование приложения
-
Все менеджеры должны быть правильно интегрированы и работать, чтобы гарантировать, что сквозная загрузка, индексирование, агрегирование и запросы работают в соответствии с ожиданиями.
-
Каждая функция каждого менеджера должна работать правильно
-
Также необходимо протестировать приложение в течение определенного периода времени.
-
Задания на выходные и на конец месяца также должны быть проверены.
Все менеджеры должны быть правильно интегрированы и работать, чтобы гарантировать, что сквозная загрузка, индексирование, агрегирование и запросы работают в соответствии с ожиданиями.
Каждая функция каждого менеджера должна работать правильно
Также необходимо протестировать приложение в течение определенного периода времени.
Задания на выходные и на конец месяца также должны быть проверены.
Логистика теста
Целью системного тестирования является проверка всех следующих областей:
- Планирование программного обеспечения
- Оперативные операционные процедуры
- Стратегия восстановления резервной копии
- Инструменты управления и планирования
- Ночная обработка
- Выполнение запроса
Примечание . Наиболее важным моментом является проверка масштабируемости. Невыполнение этого требования оставит нам системный дизайн, который не работает при росте системы.
Хранилище данных — будущие аспекты
Ниже приведены будущие аспекты хранилищ данных.
-
Поскольку мы видели, что размер открытой базы данных вырос примерно вдвое по сравнению с ее величиной за последние несколько лет, это показывает значительную ценность, которую она содержит.
-
По мере роста размера баз данных оценки того, что составляет очень большую базу данных, продолжают расти.
-
Доступное сегодня оборудование и программное обеспечение не позволяют хранить большой объем данных в сети. Например, для записи телефонных разговоров Telco требуется 10 ТБ данных, которые должны храниться в сети, что соответствует размеру записи за один месяц. Если потребуется вести учет продаж, маркетинга клиента, сотрудников и т. Д., То размер будет более 100 ТБ.
-
Запись содержит текстовую информацию и некоторые мультимедийные данные. Мультимедийные данные не могут быть легко обработаны как текстовые данные. Поиск мультимедийных данных — непростая задача, тогда как текстовая информация может быть получена с помощью реляционного программного обеспечения, доступного сегодня.
-
Помимо планирования размеров, сложно создавать и запускать системы хранилищ данных, размер которых постоянно увеличивается. По мере увеличения количества пользователей размер хранилища данных также увеличивается. Этим пользователям также потребуется доступ к системе.
-
С ростом Интернета, существует требование пользователей для доступа к данным в Интернете.
Поскольку мы видели, что размер открытой базы данных вырос примерно вдвое по сравнению с ее величиной за последние несколько лет, это показывает значительную ценность, которую она содержит.
По мере роста размера баз данных оценки того, что составляет очень большую базу данных, продолжают расти.
Доступное сегодня оборудование и программное обеспечение не позволяют хранить большой объем данных в сети. Например, для записи телефонных разговоров Telco требуется 10 ТБ данных, которые должны храниться в сети, что соответствует размеру записи за один месяц. Если потребуется вести учет продаж, маркетинга клиента, сотрудников и т. Д., То размер будет более 100 ТБ.
Запись содержит текстовую информацию и некоторые мультимедийные данные. Мультимедийные данные не могут быть легко обработаны как текстовые данные. Поиск мультимедийных данных — непростая задача, тогда как текстовая информация может быть получена с помощью реляционного программного обеспечения, доступного сегодня.
Помимо планирования размеров, сложно создавать и запускать системы хранилищ данных, размер которых постоянно увеличивается. По мере увеличения количества пользователей размер хранилища данных также увеличивается. Этим пользователям также потребуется доступ к системе.
С ростом Интернета, существует требование пользователей для доступа к данным в Интернете.
Следовательно, будущая форма хранилища данных будет сильно отличаться от того, что создается сегодня.