Функциональное программирование — Введение
Языки функционального программирования специально разработаны для обработки символьных вычислений и обработки списков. Функциональное программирование основано на математических функциях. Вот некоторые из популярных языков функционального программирования: Lisp, Python, Erlang, Haskell, Clojure и т. Д.
Языки функционального программирования подразделяются на две группы, а именно:
-
Чистые функциональные языки — эти типы функциональных языков поддерживают только функциональные парадигмы. Например — Хаскелл.
-
Impure Functional Languages — эти типы функциональных языков поддерживают функциональные парадигмы и императивный стиль программирования. Например — ЛИСП.
Чистые функциональные языки — эти типы функциональных языков поддерживают только функциональные парадигмы. Например — Хаскелл.
Impure Functional Languages — эти типы функциональных языков поддерживают функциональные парадигмы и императивный стиль программирования. Например — ЛИСП.
Функциональное программирование — характеристики
Наиболее важные характеристики функционального программирования следующие:
-
Языки функционального программирования разработаны на основе математических функций, которые используют условные выражения и рекурсию для выполнения вычислений.
-
Функциональное программирование поддерживает функции высшего порядка и ленивые функции оценки .
-
Языки функционального программирования не поддерживают элементы управления потоком, такие как операторы цикла и условные операторы, такие как If-Else и операторы Switch. Они напрямую используют функции и функциональные вызовы.
-
Как и ООП, функциональные языки программирования поддерживают такие популярные понятия, как абстракция, инкапсуляция, наследование и полиморфизм.
Языки функционального программирования разработаны на основе математических функций, которые используют условные выражения и рекурсию для выполнения вычислений.
Функциональное программирование поддерживает функции высшего порядка и ленивые функции оценки .
Языки функционального программирования не поддерживают элементы управления потоком, такие как операторы цикла и условные операторы, такие как If-Else и операторы Switch. Они напрямую используют функции и функциональные вызовы.
Как и ООП, функциональные языки программирования поддерживают такие популярные понятия, как абстракция, инкапсуляция, наследование и полиморфизм.
Функциональное программирование — преимущества
Функциональное программирование предлагает следующие преимущества —
-
Код без ошибок — Функциональное программирование не поддерживает состояние , поэтому нет побочных эффектов, и мы можем писать коды без ошибок.
-
Эффективное параллельное программирование — функциональные языки программирования не имеют изменяемого состояния, поэтому проблем с изменением состояния не возникает. Можно программировать «Функции» для параллельной работы как «инструкции». Такие коды поддерживают легкое повторное использование и тестируемость.
-
Эффективность — Функциональные программы состоят из независимых блоков, которые могут работать одновременно. В результате такие программы более эффективны.
-
Поддерживает вложенные функции — Функциональное программирование поддерживает вложенные функции.
-
Ленивая оценка — Функциональное программирование поддерживает Ленивые Функциональные Конструкции, такие как Ленивые Списки, Ленивые Карты и т. Д.
Код без ошибок — Функциональное программирование не поддерживает состояние , поэтому нет побочных эффектов, и мы можем писать коды без ошибок.
Эффективное параллельное программирование — функциональные языки программирования не имеют изменяемого состояния, поэтому проблем с изменением состояния не возникает. Можно программировать «Функции» для параллельной работы как «инструкции». Такие коды поддерживают легкое повторное использование и тестируемость.
Эффективность — Функциональные программы состоят из независимых блоков, которые могут работать одновременно. В результате такие программы более эффективны.
Поддерживает вложенные функции — Функциональное программирование поддерживает вложенные функции.
Ленивая оценка — Функциональное программирование поддерживает Ленивые Функциональные Конструкции, такие как Ленивые Списки, Ленивые Карты и т. Д.
Недостатком функционального программирования является большой объем памяти. Поскольку у него нет состояния, вам нужно каждый раз создавать новые объекты для выполнения действий.
Функциональное программирование используется в ситуациях, когда нам приходится выполнять множество различных операций с одним и тем же набором данных.
-
Lisp используется для приложений искусственного интеллекта, таких как машинное обучение, обработка языка, моделирование речи и зрения и т. Д.
-
Встроенные интерпретаторы Lisp добавляют программируемость в некоторые системы, такие как Emacs.
Lisp используется для приложений искусственного интеллекта, таких как машинное обучение, обработка языка, моделирование речи и зрения и т. Д.
Встроенные интерпретаторы Lisp добавляют программируемость в некоторые системы, такие как Emacs.
Функциональное программирование против объектно-ориентированного программирования
В следующей таблице приведены основные различия между функциональным программированием и объектно-ориентированным программированием.
| Функциональное программирование | OOP |
|---|---|
| Использует неизменные данные. | Использует изменяемые данные. |
| Следует декларативной модели программирования. | Следует модели императивного программирования. |
| Основное внимание уделяется: «Что вы делаете» | Фокус на «Как дела» |
| Поддерживает параллельное программирование | Не подходит для параллельного программирования |
| Его функции не имеют побочных эффектов | Его методы могут вызвать серьезные побочные эффекты. |
| Управление потоком осуществляется с помощью вызовов функций и вызовов функций с рекурсией | Управление потоком осуществляется с помощью циклов и условных операторов. |
| Он использует концепцию «Рекурсия» для итерации сбор данных. | Он использует концепцию «петли» для итерации сбора данных. Например: цикл For-each в Java |
| Порядок выполнения выписок не так важен. | Порядок выполнения выписок очень важен. |
| Поддерживает как «Абстракция над данными», так и «Абстракция над поведением». | Поддерживает только «Абстракция над данными». |
Эффективность программного кода
Эффективность программного кода прямо пропорциональна алгоритмической эффективности и скорости выполнения. Хорошая эффективность обеспечивает более высокую производительность.
Факторы, которые влияют на эффективность программы, включают в себя:
- Скорость машины
- Скорость компилятора
- Операционная система
- Выбор правильного языка программирования
- Порядок данных в программе организован
- Алгоритм, используемый для решения проблемы
Эффективность языка программирования может быть улучшена путем выполнения следующих задач —
-
Удаляя ненужный код или код, который идет на избыточную обработку.
-
Используя оптимальную память и энергонезависимую память
-
Благодаря использованию повторно используемых компонентов, где это применимо.
-
Используя обработку ошибок и исключений на всех уровнях программы.
-
Создавая программный код, который обеспечивает целостность и согласованность данных.
-
Разрабатывая программный код, который соответствует логике проектирования и последовательности действий.
Удаляя ненужный код или код, который идет на избыточную обработку.
Используя оптимальную память и энергонезависимую память
Благодаря использованию повторно используемых компонентов, где это применимо.
Используя обработку ошибок и исключений на всех уровнях программы.
Создавая программный код, который обеспечивает целостность и согласованность данных.
Разрабатывая программный код, который соответствует логике проектирования и последовательности действий.
Эффективный программный код может максимально сократить потребление ресурсов и время выполнения с минимальным риском для операционной среды.
Обзор функций
В терминах программирования функция — это блок операторов, который выполняет определенную задачу. Функции принимают данные, обрабатывают их и возвращают результат. Функции написаны в первую очередь для поддержки концепции повторного использования. Как только функция написана, ее можно легко вызывать, без необходимости писать один и тот же код снова и снова.
Различные функциональные языки используют разный синтаксис для написания функции.
Предпосылки для написания функции
Прежде чем писать функцию, программист должен знать следующие моменты:
-
Назначение функции должно быть известно программисту.
-
Алгоритм функции должен быть известен программисту.
-
Переменные данных функций и их цель должны быть известны программисту.
-
Данные функции должны быть известны программисту, вызываемому пользователем.
Назначение функции должно быть известно программисту.
Алгоритм функции должен быть известен программисту.
Переменные данных функций и их цель должны быть известны программисту.
Данные функции должны быть известны программисту, вызываемому пользователем.
Управление потоком функции
Когда функция «вызывается», программа «передает» управление для выполнения функции, и ее «поток управления» выглядит следующим образом:
-
Программа достигает оператора, содержащего «вызов функции».
-
Первая строка внутри функции выполняется.
-
Все операторы внутри функции выполняются сверху вниз.
-
Когда функция выполняется успешно, элемент управления возвращается к оператору, с которого она началась.
-
Любые данные, вычисленные и возвращенные функцией, используются вместо функции в исходной строке кода.
Программа достигает оператора, содержащего «вызов функции».
Первая строка внутри функции выполняется.
Все операторы внутри функции выполняются сверху вниз.
Когда функция выполняется успешно, элемент управления возвращается к оператору, с которого она началась.
Любые данные, вычисленные и возвращенные функцией, используются вместо функции в исходной строке кода.
Синтаксис функции
Общий синтаксис функции выглядит следующим образом —
returnType functionName(type1 argument1, type2 argument2, . . . ) {
// function body
}
Определение функции в C ++
Давайте рассмотрим пример, чтобы понять, как можно определить функцию в C ++, который является языком объектно-ориентированного программирования. В следующем коде есть функция, которая добавляет два числа и предоставляет результат в качестве вывода.
#include <stdio.h> int addNum(int a, int b); // function prototype int main() { int sum; sum = addNum(5,6); // function call printf("sum = %d",sum); return 0; } int addNum (int a,int b) { // function definition int result; result = a + b; return result; // return statement }
Это даст следующий результат —
Sum = 11
Определение функции в Erlang
Давайте посмотрим, как можно определить ту же функцию в Erlang, который является функциональным языком программирования.
-module(helloworld). -export([add/2,start/0]). add(A,B) -> C = A + B, io:fwrite("~w~n",[C]). start() -> add(5,6).
Это даст следующий результат —
11
Функциональный прототип
Прототип функции — это объявление функции, которое включает тип возврата, имя-функции и список аргументов. Это похоже на определение функции без функции-тела.
Например: некоторые языки программирования поддерживают создание прототипов функций, а некоторые нет.
В C ++ мы можем сделать прототип функции ‘sum’ следующим образом:
int sum(int a, int b)
Примечание. Языки программирования, такие как Python, Erlang и т. Д., Не поддерживают создание прототипов функций, нам нужно объявить полную функцию.
Какая польза от прототипа функции?
Прототип функции используется компилятором при вызове функции. Компилятор использует его для обеспечения правильности возвращаемого типа, правильного списка аргументов и правильного их возвращаемого типа.
Функция Подпись
Сигнатура функции аналогична прототипу функции, в котором количество параметров, тип данных параметров и порядок появления должны быть в одинаковом порядке. Например —
void Sum(int a, int b, int c); // function 1 void Sum(float a, float b, float c); // function 2 void Sum(float a, float b, float c); // function 3
Function1 и Function2 имеют разные подписи. Function2 и Function3 имеют одинаковые подписи.
Примечание. Перегрузка функций и переопределение функций, которые мы обсудим в последующих главах, основаны на концепции сигнатур функций.
-
Перегрузка функций возможна, когда класс имеет несколько функций с одинаковым именем, но разными сигнатурами.
-
Переопределение функции возможно, когда функция производного класса имеет то же имя и сигнатуру, что и ее базовый класс.
Перегрузка функций возможна, когда класс имеет несколько функций с одинаковым именем, но разными сигнатурами.
Переопределение функции возможно, когда функция производного класса имеет то же имя и сигнатуру, что и ее базовый класс.
Функциональное программирование — типы функций
Функции бывают двух типов —
- Предопределенные функции
- Пользовательские функции
В этой главе мы подробно обсудим функции.
Предопределенные функции
Это функции, которые встроены в язык для выполнения операций и хранятся в стандартной библиотеке функций.
Например: «Strcat» в C ++ и «concat» в Haskell используются для добавления двух строк, «strlen» в C ++ и «len» в Python используются для вычисления длины строки.
Программа для печати длины строки в C ++
Следующая программа показывает, как вы можете напечатать длину строки, используя C ++ —
#include <iostream> #include <string.h> #include <stdio.h> using namespace std; int main() { char str[20] = "Hello World"; int len; len = strlen(str); cout<<"String length is: "<<len; return 0; }
Это даст следующий результат —
String length is: 11
Программа для печати длины строки в Python
Следующая программа показывает, как напечатать длину строки, используя Python, который является функциональным языком программирования.
str = "Hello World"; print("String length is: ", len(str))
Это даст следующий результат —
('String length is: ', 11)
Пользовательские функции
Пользовательские функции определяются пользователем для выполнения конкретных задач. Есть четыре различных шаблона для определения функции —
- Функции без аргумента и без возвращаемого значения
- Функции без аргумента, но с возвращаемым значением
- Функции с аргументом, но без возвращаемого значения
- Функции с аргументом и возвращаемым значением
Функции без аргумента и без возвращаемого значения
Следующая программа показывает, как определить функцию без аргумента и без возвращаемого значения в C ++.
#include <iostream> using namespace std; void function1() { cout <<"Hello World"; } int main() { function1(); return 0; }
Это даст следующий результат —
Hello World
Следующая программа показывает, как вы можете определить аналогичную функцию (без аргумента и без возвращаемого значения) в Python —
def function1(): print ("Hello World") function1()
Это даст следующий результат —
Hello World
Функции без аргумента, но с возвращаемым значением
Следующая программа показывает, как определить функцию без аргумента, но с возвращаемым значением в C ++.
#include <iostream> using namespace std; string function1() { return("Hello World"); } int main() { cout<<function1(); return 0; }
Это даст следующий результат —
Hello World
Следующая программа показывает, как вы можете определить подобную функцию (без аргумента, кроме возвращаемого значения) в Python —
def function1(): return "Hello World" res = function1() print(res)
Это даст следующий результат —
Hello World
Функции с аргументом, но без возвращаемого значения
Следующая программа показывает, как определить функцию с аргументом, но без возвращаемого значения в C ++ —
#include <iostream> using namespace std; void function1(int x, int y) { int c; c = x+y; cout<<"Sum is: "<<c; } int main() { function1(4,5); return 0; }
Это даст следующий результат —
Sum is: 9
Следующая программа показывает, как вы можете определить аналогичную функцию в Python —
def function1(x,y): c = x + y print("Sum is:",c) function1(4,5)
Это даст следующий результат —
('Sum is:', 9)
Функции с аргументом и возвращаемым значением
Следующая программа показывает, как определить функцию в C ++ без аргумента, но с возвращаемым значением —
#include <iostream> using namespace std; int function1(int x, int y) { int c; c = x + y; return c; } int main() { int res; res = function1(4,5); cout<<"Sum is: "<<res; return 0; }
Это даст следующий результат —
Sum is: 9
Следующая программа показывает, как определить аналогичную функцию (с аргументом и возвращаемым значением) в Python —
def function1(x,y): c = x + y return c res = function1(4,5) print("Sum is ",res)
Это даст следующий результат —
('Sum is ', 9)
Функциональное программирование — вызов по значению
После определения функции нам нужно передать в нее аргументы, чтобы получить желаемый результат. Большинство языков программирования поддерживают вызов по значению и вызов по ссылочным методам для передачи аргументов в функции.
В этой главе мы узнаем, что «вызов по значению» работает на объектно-ориентированном языке программирования, таком как C ++, и на функциональном языке программирования, таком как Python.
В методе Call by Value исходное значение не может быть изменено . Когда мы передаем аргумент функции, он сохраняется локально параметром функции в памяти стека. Следовательно, значения изменяются только внутри функции, и это не оказывает влияния вне функции.
Вызов по значению в C ++
Следующая программа показывает, как Call by Value работает в C ++:
#include <iostream> using namespace std; void swap(int a, int b) { int temp; temp = a; a = b; b = temp; cout<<"\n"<<"value of a inside the function: "<<a; cout<<"\n"<<"value of b inside the function: "<<b; } int main() { int a = 50, b = 70; cout<<"value of a before sending to function: "<<a; cout<<"\n"<<"value of b before sending to function: "<<b; swap(a, b); // passing value to function cout<<"\n"<<"value of a after sending to function: "<<a; cout<<"\n"<<"value of b after sending to function: "<<b; return 0; }
Это даст следующий результат —
value of a before sending to function: 50 value of b before sending to function: 70 value of a inside the function: 70 value of b inside the function: 50 value of a after sending to function: 50 value of b after sending to function: 70
Вызов по значению в Python
Следующая программа показывает, как Call by Value работает в Python —
def swap(a,b): t = a; a = b; b = t; print "value of a inside the function: :",a print "value of b inside the function: ",b # Now we can call the swap function a = 50 b = 75 print "value of a before sending to function: ",a print "value of b before sending to function: ",b swap(a,b) print "value of a after sending to function: ", a print "value of b after sending to function: ",b
Это даст следующий результат —
value of a before sending to function: 50 value of b before sending to function: 75 value of a inside the function: : 75 value of b inside the function: 50 value of a after sending to function: 50 value of b after sending to function: 75
Функциональное программирование — вызов по ссылке
В Call by Reference исходное значение изменяется, потому что мы передаем ссылочный адрес аргументов. Фактические и формальные аргументы имеют одинаковое адресное пространство, поэтому любое изменение значения внутри функции отражается как внутри, так и снаружи функции.
Вызов по ссылке в C ++
Следующая программа показывает, как Call by Value работает в C ++:
#include <iostream> using namespace std; void swap(int *a, int *b) { int temp; temp = *a; *a = *b; *b = temp; cout<<"\n"<<"value of a inside the function: "<<*a; cout<<"\n"<<"value of b inside the function: "<<*b; } int main() { int a = 50, b = 75; cout<<"\n"<<"value of a before sending to function: "<<a; cout<<"\n"<<"value of b before sending to function: "<<b; swap(&a, &b); // passing value to function cout<<"\n"<<"value of a after sending to function: "<<a; cout<<"\n"<<"value of b after sending to function: "<<b; return 0; }
Это даст следующий результат —
value of a before sending to function: 50 value of b before sending to function: 75 value of a inside the function: 75 value of b inside the function: 50 value of a after sending to function: 75 value of b after sending to function: 50
Звоните по ссылке в Python
Следующая программа показывает, как Call by Value работает в Python —
def swap(a,b): t = a; a = b; b = t; print "value of a inside the function: :",a print "value of b inside the function: ",b return(a,b) # Now we can call swap function a = 50 b =75 print "value of a before sending to function: ",a print "value of b before sending to function: ",b x = swap(a,b) print "value of a after sending to function: ", x[0] print "value of b after sending to function: ",x[1]
Это даст следующий результат —
value of a before sending to function: 50 value of b before sending to function: 75 value of a inside the function: 75 value of b inside the function: 50 value of a after sending to function: 75 value of b after sending to function: 50
Перегрузка функций
Когда у нас есть несколько функций с одним и тем же именем, но с разными параметрами, то говорят, что они перегружены. Этот метод используется для повышения читабельности программы.
Есть два способа перегрузить функцию:
- Имея разное количество аргументов
- Наличие разных типов аргументов
Перегрузка функций обычно выполняется, когда нам нужно выполнить одну операцию с другим количеством или типом аргументов.
Перегрузка функций в C ++
В следующем примере показано, как происходит перегрузка функций в C ++, который является объектно-ориентированным языком программирования.
#include <iostream> using namespace std; void addnum(int,int); void addnum(int,int,int); int main() { addnum (5,5); addnum (5,2,8); return 0; } void addnum (int x, int y) { cout<<"Integer number: "<<x+y<<endl; } void addnum (int x, int y, int z) { cout<<"Float number: "<<x+y+z<<endl; }
Это даст следующий результат —
Integer number: 10 Float number: 15
Перегрузка функций в Эрланге
В следующем примере показано, как выполнить перегрузку функций в Erlang, который является функциональным языком программирования.
-module(helloworld). -export([addnum/2,addnum/3,start/0]). addnum(X,Y) -> Z = X+Y, io:fwrite("~w~n",[Z]). addnum(X,Y,Z) -> A = X+Y+Z, io:fwrite("~w~n",[A]). start() -> addnum(5,5), addnum(5,2,8).
Это даст следующий результат —
10 15
Переопределение функций
Когда базовый класс и производный класс имеют функции-члены с одинаковыми именами, одинаковыми типами возвращаемых данных и одинаковым списком аргументов, то это называется переопределением функций.
Переопределение функций с использованием C ++
В следующем примере показано, как выполняется переопределение функций в C ++, который является языком программирования с ограниченным доступом.
#include <iostream> using namespace std; class A { public: void display() { cout<<"Base class"; } }; class B:public A { public: void display() { cout<<"Derived Class"; } }; int main() { B obj; obj.display(); return 0; }
Это даст следующий вывод
Derived Class
Переопределение функций с использованием Python
В следующем примере показано, как выполнить переопределение функций в Python, который является функциональным языком программирования.
class A(object): def disp(self): print "Base Class" class B(A): def disp(self): print "Derived Class" x = A() y = B() x.disp() y.disp()
Это даст следующий результат —
Base Class Derived Class
Функциональное программирование — рекурсия
Функция, которая вызывает себя, известна как рекурсивная функция, а этот метод известен как рекурсия. Инструкция рекурсии продолжается до тех пор, пока другая инструкция не помешает этому.
Рекурсия в C ++
В следующем примере показано, как работает рекурсия в C ++, который является объектно-ориентированным языком программирования.
#include <stdio.h> long int fact(int n); int main() { int n; printf("Enter a positive integer: "); scanf("%d", &n); printf("Factorial of %d = %ld", n, fact(n)); return 0; } long int fact(int n) { if (n >= 1) return n*fact(n-1); else return 1; }
Это даст следующий вывод
Enter a positive integer: 5 Factorial of 5 = 120
Рекурсия в Python
В следующем примере показано, как работает рекурсия в Python, который является функциональным языком программирования.
def fact(n): if n == 1: return n else: return n* fact (n-1) # accepts input from user num = int(input("Enter a number: ")) # check whether number is positive or not if num > 0: print("Sorry, factorial does not exist for negative numbers") else: print("The factorial of " + str(num) + " is " + str(fact(num)))
Это даст следующий результат —
Enter a number: 6 The factorial of 6 is 720
Функции высшего порядка
Функция высшего порядка (HOF) — это функция, которая соответствует хотя бы одному из следующих условий:
- Принимает или больше функций в качестве аргумента
- Возвращает функцию в качестве результата
HOF в PHP
В следующем примере показано, как написать функцию более высокого порядка в PHP, который является объектно-ориентированным языком программирования.
<?php $twice = function($f, $v) { return $f($f($v)); }; $f = function($v) { return $v + 3; }; echo($twice($f, 7));
Это даст следующий результат —
13
HOF в Python
В следующем примере показано, как написать функцию более высокого порядка в Python, который является объектно-ориентированным языком программирования.
def twice(function): return lambda x: function(function(x)) def f(x): return x + 3 g = twice(f) print g(7)
Это даст следующий результат —
13
Функциональное программирование — типы данных
Тип данных определяет тип значения, которое может иметь объект, и какие операции над ним могут выполняться. Тип данных должен быть объявлен первым перед использованием. Различные языки программирования поддерживают разные типы данных. Например,
- C поддерживает char, int, float, long и т. Д.
- Python поддерживает String, List, Tuple и т. Д.
В широком смысле, есть три типа типов данных —
-
Основные типы данных — это предопределенные типы данных, которые используются программистом напрямую для хранения только одного значения согласно требованию, то есть целочисленного типа, символьного типа или плавающего типа. Например — int, char, float и т. Д.
-
Производные типы данных. Эти типы данных создаются с использованием встроенного типа данных, который разработан программистом для хранения нескольких значений одного типа в соответствии с их требованиями. Например — массив, указатель, функция, список и т. Д.
-
Определяемые пользователем типы данных. Эти типы данных выводятся с использованием встроенных типов данных, которые объединены в один тип данных для хранения нескольких значений одного и того же типа или другого типа или обоих в соответствии с требованиями. Например — класс, структура и т. Д.
Основные типы данных — это предопределенные типы данных, которые используются программистом напрямую для хранения только одного значения согласно требованию, то есть целочисленного типа, символьного типа или плавающего типа. Например — int, char, float и т. Д.
Производные типы данных. Эти типы данных создаются с использованием встроенного типа данных, который разработан программистом для хранения нескольких значений одного типа в соответствии с их требованиями. Например — массив, указатель, функция, список и т. Д.
Определяемые пользователем типы данных. Эти типы данных выводятся с использованием встроенных типов данных, которые объединены в один тип данных для хранения нескольких значений одного и того же типа или другого типа или обоих в соответствии с требованиями. Например — класс, структура и т. Д.
Типы данных, поддерживаемые C ++
В следующей таблице перечислены типы данных, поддерживаемые C ++ —
| Тип данных | Размер | Спектр |
|---|---|---|
| голец | 1 байт | От -128 до 127 или от 0 до 255 |
| без знака | 1 байт | От 0 до 255 |
| подписанный символ | 1 байт | От -128 до 127 |
| ИНТ | 4 байта | От -2147483648 до 2147483647 |
| без знака int | 4 байта | От 0 до 4294967295 |
| подписанный int | 4 байта | От -2147483648 до 2147483647 |
| короткий int | 2 байта | От -32768 до 32767 |
| беззнаковый короткий int | 2 байта | От 0 до 65 535 |
| подписанный короткий int | 2 байта | От -32768 до 32767 |
| длинный инт | 4 байта | От -2 147 483 648 до 2 147 483 647 |
| подписанный длинный int | 4 байта | От -2 147 483 648 до 2 147 483 647 |
| без знака длинный int | 4 байта | От 0 до 4 294 967 295 |
| поплавок | 4 байта | +/- 3.4e +/- 38 (~ 7 цифр) |
| двойной | 8 байт | +/- 1.7e +/- 308 (~ 15 цифр) |
| длинный двойной | 8 байт | +/- 1.7e +/- 308 (~ 15 цифр) |
Типы данных, поддерживаемые Java
Следующие типы данных поддерживаются Java —
| Тип данных | Размер | Спектр |
|---|---|---|
| байт | 1 байт | От -128 до 127 |
| голец | 2 байта | От 0 до 65 536 |
| короткая | 2 байта | От -32 7688 до 32 767 |
| ИНТ | 4 байта | От -2 147 483 648 до 2 147 483 647 |
| долго | 8 байт | От -9,223,372,036,854,775,808 до 9,223,372,036,854,775,807 |
| поплавок | 4 байта | От -2147483648 до 2147483647 |
| двойной | 8 байт | + 9,223 * 1018 |
| логический | 1 бит | Правда или ложь |
Типы данных, поддерживаемые Erlang
В этом разделе мы обсудим типы данных, поддерживаемые Erlang, который является функциональным языком программирования.
Число
Erlang поддерживает два типа числовых литералов, то есть целое число и число с плавающей точкой . Посмотрите на следующий пример, который показывает, как добавить два целочисленных значения —
-module(helloworld). -export([start/0]). start() -> io:fwrite("~w",[5+4]).
Это даст следующий результат —
9
Атом
Атом — это строка, значение которой нельзя изменить. Он должен начинаться со строчной буквы и может содержать любые буквенно-цифровые символы и специальные символы. Когда атом содержит специальные символы, он должен быть заключен в одинарные кавычки (‘). Посмотрите на следующий пример, чтобы лучше понять.
-module(helloworld). -export([start/0]). start()-> io:fwrite(monday).
Это даст следующий результат —
monday
Примечание. Попробуйте изменить атом на «понедельник» с большой буквы «М». Программа выдаст ошибку.
логический
Этот тип данных используется для отображения результата как true или false . Посмотрите на следующий пример. Он показывает, как сравнить два целых числа.
-module(helloworld). -export([start/0]). start() -> io:fwrite(5 =< 9).
Это даст следующий результат —
true
Битовая строка
Битовая строка используется для хранения области нетипизированной памяти. Посмотрите на следующий пример. Он показывает, как преобразовать 2 бита строки битов в список.
-module(helloworld). -export([start/0]). start() -> Bin2 = <<15,25>>, P = binary_to_list(Bin2), io:fwrite("~w",[P]).
Это даст следующий результат —
[15,25]
Кортеж
Кортеж — это составной тип данных, имеющий фиксированное количество терминов. Каждый член кортежа известен как элемент . Количество элементов — это размер кортежа. В следующем примере показано, как определить кортеж из 5 терминов и распечатать его размер.
-module(helloworld). -export([start/0]). start() -> K = {abc,50,pqr,60,{xyz,75}} , io:fwrite("~w",[tuple_size(K)]).
Это даст следующий результат —
5
карта
Карта — это составной тип данных с переменным количеством ассоциаций ключ-значение. Каждая ассоциация ключ-значение на карте называется парой ассоциации . Ключевые и значимые части пары называются элементами . Количество пар ассоциаций называется размером карты. В следующем примере показано, как определить карту из 3 отображений и вывести ее размер.
-module(helloworld). -export([start/0]). start() -> Map1 = #{name => 'abc',age => 40, gender => 'M'}, io:fwrite("~w",[map_size(Map1)]).
Это даст следующий результат —
3
Список
Список — это составной тип данных, имеющий переменное количество терминов. Каждый термин в списке называется элементом. Количество элементов называется длиной списка. В следующем примере показано, как определить список из 5 элементов и распечатать его размер.
-module(helloworld). -export([start/0]). start() -> List1 = [10,15,20,25,30] , io:fwrite("~w",[length(List1)]).
Это даст следующий результат —
5
Примечание. Тип данных ‘String’ не определен в Erlang.
Функциональное программирование — полиморфизм
Полиморфизм в терминах программирования означает многократное повторное использование одного кода. Более конкретно, это способность программы обрабатывать объекты по-разному в зависимости от их типа данных или класса.
Полиморфизм бывает двух типов —
-
Полиморфизм времени компиляции — этот тип полиморфизма может быть достигнут с использованием перегрузки метода.
-
Полиморфизм во время выполнения — этот тип полиморфизма может быть достигнут с использованием переопределения метода и виртуальных функций.
Полиморфизм времени компиляции — этот тип полиморфизма может быть достигнут с использованием перегрузки метода.
Полиморфизм во время выполнения — этот тип полиморфизма может быть достигнут с использованием переопределения метода и виртуальных функций.
Преимущества полиморфизма
Полиморфизм предлагает следующие преимущества —
-
Это помогает программисту повторно использовать коды, т. Е. Классы, когда они написаны, протестированы и реализованы, могут быть повторно использованы по мере необходимости. Экономит много времени.
-
Одна переменная может использоваться для хранения нескольких типов данных.
-
Легко отлаживать коды.
Это помогает программисту повторно использовать коды, т. Е. Классы, когда они написаны, протестированы и реализованы, могут быть повторно использованы по мере необходимости. Экономит много времени.
Одна переменная может использоваться для хранения нескольких типов данных.
Легко отлаживать коды.
Полиморфные типы данных
Полиморфные типы данных могут быть реализованы с использованием общих указателей, которые хранят только байтовый адрес, без типа данных, хранящихся по этому адресу памяти. Например,
function1(void *p, void *q)
где p и q являются общими указателями, которые могут содержать значение типа int, float (или любое другое) в качестве аргумента.
Полиморфная функция в C ++
Следующая программа показывает, как использовать полиморфные функции в C ++, который является объектно-ориентированным языком программирования.
#include <iostream> Using namespace std: class A { public: void show() { cout << "A class method is called/n"; } }; class B:public A { public: void show() { cout << "B class method is called/n"; } }; int main() { A x; // Base class object B y; // Derived class object x.show(); // A class method is called y.show(); // B class method is called return 0; }
Это даст следующий результат —
A class method is called B class method is called
Полиморфная функция в Python
Следующая программа показывает, как использовать полиморфные функции в Python, который является функциональным языком программирования.
class A(object):
def show(self):
print "A class method is called"
class B(A):
def show(self):
print "B class method is called"
def checkmethod(clasmethod):
clasmethod.show()
AObj = A()
BObj = B()
checkmethod(AObj)
checkmethod(BObj)
Это даст следующий результат —
A class method is called B class method is called
Функциональное программирование — строки
Строка — это группа символов, включая пробелы. Можно сказать, что это одномерный массив символов, который заканчивается символом NULL (‘\ 0’). Строку также можно рассматривать как предопределенный класс, который поддерживается большинством языков программирования, таких как C, C ++, Java, PHP, Erlang, Haskell, Lisp и т. Д.
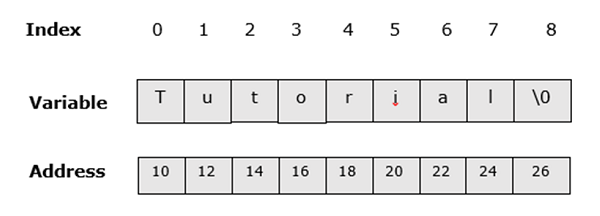
На следующем рисунке показано, как строка «Учебник» будет выглядеть в памяти.
Создать строку в C ++
Следующая программа представляет собой пример, который показывает, как создать строку в C ++, который является объектно-ориентированным языком программирования.
#include <iostream>
using namespace std;
int main () {
char greeting[20] = {'H', 'o', 'l', 'i', 'd', 'a', 'y', '\0'};
cout << "Today is: ";
cout << greeting << endl;
return 0;
}
Это даст следующий результат —
Today is: Holiday
Строка в Эрланге
Следующая программа представляет собой пример, который показывает, как создать строку в Erlang, который является функциональным языком программирования.
-module(helloworld).
-export([start/0]).
start() ->
Str = "Today is: Holiday",
io:fwrite("~p~n",[Str]).
Это даст следующий результат —
"Today is: Holiday"
Строковые операции в C ++
Различные языки программирования поддерживают разные методы для строк. В следующей таблице показано несколько предопределенных строковых методов, поддерживаемых C ++.
| S.No. | Метод и описание |
|---|---|
| 1 |
STRCPY (s1, s2) Копирует строку s2 в строку s1 |
| 2 |
Strcat (s1, s2) Добавляет строку s2 в конце s1 |
| 3 |
STRLEN (s1) Это обеспечивает длину строки s1 |
| 4 |
STRCMP (s1, s2) Возвращает 0, когда строки s1 и s2 совпадают |
| 5 |
Strchr (s1, гл) Возвращает указатель на первое вхождение символа ch в строке s1 |
| 6 |
Strstr (s1, s2) Возвращает указатель на первое вхождение строки s2 в строку s1 |
STRCPY (s1, s2)
Копирует строку s2 в строку s1
Strcat (s1, s2)
Добавляет строку s2 в конце s1
STRLEN (s1)
Это обеспечивает длину строки s1
STRCMP (s1, s2)
Возвращает 0, когда строки s1 и s2 совпадают
Strchr (s1, гл)
Возвращает указатель на первое вхождение символа ch в строке s1
Strstr (s1, s2)
Возвращает указатель на первое вхождение строки s2 в строку s1
Следующая программа показывает, как вышеуказанные методы могут быть использованы в C ++ —
#include <iostream>
#include <cstring>
using namespace std;
int main () {
char str1[20] = "Today is ";
char str2[20] = "Monday";
char str3[20];
int len ;
strcpy( str3, str1); // copy str1 into str3
cout << "strcpy( str3, str1) : " << str3 << endl;
strcat( str1, str2); // concatenates str1 and str2
cout << "strcat( str1, str2): " << str1 << endl;
len = strlen(str1); // String length after concatenation
cout << "strlen(str1) : " << len << endl;
return 0;
}
Это даст следующий результат —
strcpy(str3, str1) : Today is strcat(str1, str2) : Today is Monday strlen(str1) : 15
Струнные операции в Эрланге
В следующей таблице приведен список предопределенных строковых методов, поддерживаемых Erlang.
| S.No. | Метод и описание |
|---|---|
| 1 |
Len (s1) Предоставляет строку s2 в строку s1 |
| 2 |
равен (s1, s2) Возвращает true, когда строки s1 и s2 равны, иначе возвращает false |
| 3 |
CONCAT (s1, s2) Добавляет строку s2 в конце строки s1 |
| 4 |
ул (s1, гл) Возвращает позицию индекса символа ch в строке s1 |
| 5 |
ул (с1, с2) Возвращает позицию индекса s2 в строке s1 |
| 6 |
зиЬзЬг (s1, s2, Num) Этот метод возвращает строку s2 из строки s1 на основе начальной позиции и количества символов из начальной позиции |
| 7 |
to_lower (s1) Этот метод возвращает строку в нижнем регистре |
Len (s1)
Предоставляет строку s2 в строку s1
равен (s1, s2)
Возвращает true, когда строки s1 и s2 равны, иначе возвращает false
CONCAT (s1, s2)
Добавляет строку s2 в конце строки s1
ул (s1, гл)
Возвращает позицию индекса символа ch в строке s1
ул (с1, с2)
Возвращает позицию индекса s2 в строке s1
зиЬзЬг (s1, s2, Num)
Этот метод возвращает строку s2 из строки s1 на основе начальной позиции и количества символов из начальной позиции
to_lower (s1)
Этот метод возвращает строку в нижнем регистре
Следующая программа показывает, как вышеуказанные методы могут быть использованы в Erlang.
-module(helloworld).
-import(string,[concat/2]).
-export([start/0]).
start() ->
S1 = "Today is ",
S2 = "Monday",
S3 = concat(S1,S2),
io:fwrite("~p~n",[S3]).
Это даст следующий результат —
"Today is Monday"
Функциональное программирование — списки
Список — это наиболее универсальный тип данных, доступный на функциональных языках программирования, который используется для хранения коллекции похожих элементов данных. Концепция похожа на массивы в объектно-ориентированном программировании. Элементы списка могут быть написаны в квадратных скобках, разделенных запятыми. Способ записи данных в список варьируется от языка к языку.
Программа для создания списка номеров в Java
Список не является типом данных в Java / C / C ++, но у нас есть альтернативные способы создания списка в Java, т. Е. С помощью ArrayList и LinkedList .
В следующем примере показано, как создать список в Java. Здесь мы используем метод Linked List для создания списка чисел.
import java.util.*;
import java.lang.*;
import java.io.*;
/* Name of the class has to be "Main" only if the class is public. */
public class HelloWorld {
public static void main (String[] args) throws java.lang.Exception {
List<String> listStrings = new LinkedList<String>();
listStrings.add("1");
listStrings.add("2");
listStrings.add("3");
listStrings.add("4");
listStrings.add("5");
System.out.println(listStrings);
}
}
Это даст следующий результат —
[1, 2, 3, 4, 5]
Программа для создания списка номеров в Erlang
-module(helloworld).
-export([start/0]).
start() ->
Lst = [1,2,3,4,5],
io:fwrite("~w~n",[Lst]).
Это даст следующий результат —
[1 2 3 4 5]
Список операций в Java
В этом разделе мы обсудим некоторые операции, которые можно выполнять над списками в Java.
Добавление элементов в список
Методы add (Object), add (index, Object), addAll () используются для добавления элементов в список. Например,
ListStrings.add(3, “three”)
Удаление элементов из списка
Методы remove (index) или removeobject () используются для удаления элементов из списка. Например,
ListStrings.remove(3,”three”)
Примечание. Для удаления всех элементов из списка используется метод clear ().
Извлечение элементов из списка
Метод get () используется для извлечения элементов из списка в указанном месте. Методы getfirst () и getlast () можно использовать в классе LinkedList. Например,
String str = ListStrings.get(2)
Обновление элементов в списке
Метод set (index, element) используется для обновления элемента по указанному индексу с помощью указанного элемента. Например,
listStrings.set(2,”to”)
Сортировка элементов в списке
Методы collection.sort () и collection.reverse () используются для сортировки списка в порядке возрастания или убывания. Например,
Collection.sort(listStrings)
Поиск элементов в списке
Следующие три метода используются согласно требованию —
Логический метод содержит (Object) возвращает true, если список содержит указанный элемент, иначе он возвращает false .
Метод int indexOf (Object) возвращает индекс первого вхождения указанного элемента в списке, иначе он возвращает -1, если элемент не найден.
int lastIndexOf (Object) возвращает индекс последнего вхождения указанного элемента в списке, иначе он возвращает -1, если элемент не найден.
Операции со списком в Erlang
В этом разделе мы обсудим некоторые операции, которые можно выполнять над списками в Erlang.
Добавление двух списков
Метод append (listfirst, listsecond) используется для создания нового списка путем добавления двух списков. Например,
append(list1,list2)
Удаление элемента
Метод delete (element, listname) используется для удаления указанного элемента из списка и возвращает новый список. Например,
delete(5,list1)
Удаление последнего элемента из списка
Метод droplast (listname) используется для удаления последнего элемента из списка и возврата нового списка. Например,
droplast(list1)
Поиск элемента
Метод member (element, listname) используется для поиска элемента в списке, если он найден, он возвращает true, иначе возвращает false. Например,
member(5,list1)
Получение максимального и минимального значения
Методы max (listname) и min (listname) используются для поиска максимальных и минимальных значений в списке. Например,
max(list1)
Сортировка элементов списка
Методы sort (listname) и reverse (listname) используются для сортировки списка в порядке возрастания или убывания. Например,
sort(list1)
Добавление элементов списка
Метод sum (listname) используется для добавления всех элементов списка и возврата их суммы. Например,
sum(list1)
Сортировка списка в порядке возрастания и убывания с использованием Java
Следующая программа показывает, как сортировать список в порядке возрастания и убывания, используя Java —
import java.util.*;
import java.lang.*;
import java.io.*;
public class SortList {
public static void main (String[] args) throws java.lang.Exception {
List<String> list1 = new ArrayList<String>();
list1.add("5");
list1.add("3");
list1.add("1");
list1.add("4");
list1.add("2");
System.out.println("list before sorting: " + list1);
Collections.sort(list1);
System.out.println("list in ascending order: " + list1);
Collections.reverse(list1);
System.out.println("list in dsending order: " + list1);
}
}
Это даст следующий результат —
list before sorting : [5, 3, 1, 4, 2] list in ascending order : [1, 2, 3, 4, 5] list in dsending order : [5, 4, 3, 2, 1]
Сортировать список в порядке возрастания, используя Erlang
Следующая программа показывает, как сортировать список в порядке возрастания и убывания, используя Erlang, который является функциональным языком программирования.
-module(helloworld).
-import(lists,[sort/1]).
-export([start/0]).
start() ->
List1 = [5,3,4,2,1],
io:fwrite("~p~n",[sort(List1)]),
Это даст следующий результат —
[1,2,3,4,5]
Функциональное программирование — кортеж
Кортеж — это составной тип данных, имеющий фиксированное количество терминов. Каждый термин в кортеже известен как элемент . Количество элементов — это размер кортежа.
Программа для определения кортежа в C #
Следующая программа показывает, как определить кортеж из четырех терминов и распечатать их с помощью C #, который является объектно-ориентированным языком программирования.
using System;
public class Test {
public static void Main() {
var t1 = Tuple.Create(1, 2, 3, new Tuple<int, int>(4, 5));
Console.WriteLine("Tuple:" + t1);
}
}
Это даст следующий результат —
Tuple :(1, 2, 3, (4, 5))
Программа для определения кортежа в Erlang
Следующая программа показывает, как определить кортеж из четырех терминов и распечатать их, используя Erlang, который является функциональным языком программирования.
-module(helloworld).
-export([start/0]).
start() ->
P = {1,2,3,{4,5}} ,
io:fwrite("~w",[P]).
Это даст следующий результат —
{1, 2, 3, {4, 5}}
Преимущества Tuple
Кортежи предлагают следующие преимущества —
-
Кортежи имеют штрафной размер по своей природе, т.е. мы не можем добавлять / удалять элементы в / из кортежа.
-
Мы можем искать любой элемент в кортеже.
-
Кортежи работают быстрее, чем списки, потому что они имеют постоянный набор значений.
-
Кортежи можно использовать в качестве ключей словаря, поскольку они содержат неизменяемые значения, такие как строки, числа и т. Д.
Кортежи имеют штрафной размер по своей природе, т.е. мы не можем добавлять / удалять элементы в / из кортежа.
Мы можем искать любой элемент в кортеже.
Кортежи работают быстрее, чем списки, потому что они имеют постоянный набор значений.
Кортежи можно использовать в качестве ключей словаря, поскольку они содержат неизменяемые значения, такие как строки, числа и т. Д.
Кортежи и списки
| Кортеж | Список |
|---|---|
| Кортежи неизменны , т. Е. Мы не можем обновлять их данные. | Список изменчив , то есть мы можем обновить его данные. |
| Элементы в кортеже могут быть разного типа. | Все элементы в списке одного типа. |
| Кортежи обозначены круглыми скобками вокруг элементов. | Списки обозначены квадратными скобками вокруг элементов. |
Операции над кортежами
В этом разделе мы обсудим несколько операций, которые можно выполнить над кортежем.
Проверьте, является ли вставленное значение кортежем или нет
Метод is_tuple (tuplevalues) используется для определения, является ли вставленное значение кортежем или нет. Он возвращает истину, когда вставленное значение является кортежем, иначе он возвращает ложь . Например,
-module(helloworld).
-export([start/0]).
start() ->
K = {abc,50,pqr,60,{xyz,75}} , io:fwrite("~w",[is_tuple(K)]).
Это даст следующий результат —
True
Преобразование списка в кортеж
Метод list_to_tuple (listvalues) преобразует список в кортеж. Например,
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[list_to_tuple([1,2,3,4,5])]).
Это даст следующий результат —
{1, 2, 3, 4, 5}
Преобразование кортежа в список
Метод tuple_to_list (tuplevalues) преобразует указанный кортеж в формат списка. Например,
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[tuple_to_list({1,2,3,4,5})]).
Это даст следующий результат —
[1, 2, 3, 4, 5]
Проверьте размер кортежа
Метод tuple_size (tuplename) возвращает размер кортежа. Например,
-module(helloworld).
-export([start/0]).
start() ->
K = {abc,50,pqr,60,{xyz,75}} ,
io:fwrite("~w",[tuple_size(K)]).
Это даст следующий результат —
5
Функциональное программирование — записи
Запись — это структура данных для хранения фиксированного количества элементов. Это похоже на структуру на языке Си. Во время компиляции его выражения переводятся в выражения кортежей.
Как создать запись?
Ключевое слово «запись» используется для создания записей, указанных с именем записи и ее полями. Его синтаксис выглядит следующим образом —
record(recodname, {field1, field2, . . fieldn})
Синтаксис для вставки значений в запись:
#recordname {fieldName1 = value1, fieldName2 = value2 .. fieldNamen = valuen}
Программа для создания записей с использованием Erlang
В следующем примере мы создали запись имени студента, имеющую два поля: sname и sid .
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5}.
Программа для создания записей с использованием C ++
В следующем примере показано, как создавать записи с использованием C ++, который является объектно-ориентированным языком программирования.
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
15
};
int main() {
student S;
S.sname = "Sachin";
S.sid = 5;
return 0;
}
Программа для доступа к значениям записи, используя Erlang
Следующая программа показывает, как получить доступ к значениям записи, используя Erlang, который является функциональным языком программирования.
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5},
io:fwrite("~p~n",[S#student.sid]),
io:fwrite("~p~n",[S#student.sname]).
Это даст следующий результат —
5 "Sachin"
Программа для доступа к значениям записи с использованием C ++
Следующая программа показывает, как получить доступ к значениям записи с помощью C ++ —
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
};
int main() {
student S;
S.sname = "Sachin";
S.sid = 5;
cout<<S.sid<<"\n"<<S.sname;
return 0;
}
Это даст следующий результат —
5 Sachin
Значения записи можно обновить, изменив значение на определенное поле и затем присвоив эту запись новому имени переменной. Взгляните на следующие два примера, чтобы понять, как это делается с использованием объектно-ориентированного и функционального языков программирования.
Программа для обновления значений записей с использованием Erlang
Следующая программа показывает, как обновить значения записей с помощью Erlang —
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5},
S1 = S#student{sname = "Jonny"},
io:fwrite("~p~n",[S1#student.sid]),
io:fwrite("~p~n",[S1#student.sname]).
Это даст следующий результат —
5 "Jonny"
Программа для обновления значений записей с использованием C ++
Следующая программа показывает, как обновить значения записей с помощью C ++ —
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
};
int main() {
student S;
S.sname = "Jonny";
S.sid = 5;
cout<<S.sname<<"\n"<<S.sid;
cout<<"\n"<< "value after updating"<<"\n";
S.sid = 10;
cout<<S.sname<<"\n"<<S.sid;
return 0;
}
Это даст следующий результат —
Jonny 5 value after updating Jonny 10
Функциональное программирование — лямбда-исчисление
Лямбда-исчисление — это структура, разработанная Алонзо Черчем в 1930-х годах для изучения вычислений с функциями.
-
Создание функции — Черч ввел обозначение λx.E для обозначения функции, в которой «x» является формальным аргументом, а «E» — функциональным телом. Эти функции могут быть без имен и без аргументов.
-
Применение функции — Черч использовал обозначение E 1 .E 2 для обозначения применения функции E 1 к фактическому аргументу E 2 . И все функции на один аргумент.
Создание функции — Черч ввел обозначение λx.E для обозначения функции, в которой «x» является формальным аргументом, а «E» — функциональным телом. Эти функции могут быть без имен и без аргументов.
Применение функции — Черч использовал обозначение E 1 .E 2 для обозначения применения функции E 1 к фактическому аргументу E 2 . И все функции на один аргумент.
Синтаксис лямбда-исчисления
Исчисление Ламдбы включает в себя три различных типа выражений:
E :: = x (переменные)
| E 1 E 2 (функция приложения)
| λx.E (создание функции)
Где λx.E называется лямбда-абстракцией, а E называется λ-выражением.
Оценка лямбда-исчисления
Чистое лямбда-исчисление не имеет встроенных функций. Давайте оценим следующее выражение —
(+ (* 5 6) (* 8 3))
Здесь мы не можем начать с «+», потому что он работает только с числами. Есть два приводимых выражения: (* 5 6) и (* 8 3).
Мы можем уменьшить либо один в первую очередь. Например —
(+ (* 5 6) (* 8 3)) (+ 30 (* 8 3)) (+ 30 24) = 54
β-редукция Правило
Нам нужно правило редукции для обработки λs
(λx . * 2 x) 4 (* 2 4) = 8
Это называется β-редукцией.
Формальный параметр может быть использован несколько раз —
(λx . + x x) 4 (+ 4 4) = 8
Когда есть несколько терминов, мы можем обработать их следующим образом:
(λx . (λx . + (− x 1)) x 3) 9
Внутренний x принадлежит внутреннему λ, а внешний x принадлежит внешнему.
(λx . + (− x 1)) 9 3 + (− 9 1) 3 + 8 3 = 11
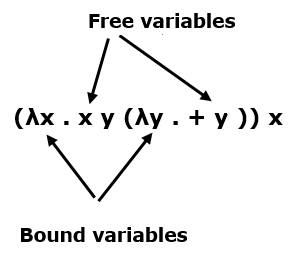
Свободные и связанные переменные
В выражении каждое появление переменной является либо «свободным» (для λ), либо «связанным» (для λ).
β-редукция (λx. E) y заменяет каждый x , свободный в E, на y . Например —
Альфа уменьшение
Альфа-сокращение очень просто, и это может быть сделано без изменения значения лямбда-выражения.
λx . (λx . x) (+ 1 x) ↔ α λx . (λy . y) (+ 1 x)
Например —
(λx . (λx . + (− x 1)) x 3) 9 (λx . (λy . + (− y 1)) x 3) 9 (λy . + (− y 1)) 9 3 + (− 9 1) 3 + 8 3 11
Теорема Черча-Россера
Теорема Черча-Россера гласит следующее:
-
Если E1 ↔ E2, то существует E, такое, что E1 → E и E2 → E. «Уменьшение любым способом может в конечном итоге привести к тому же результату».
-
Если E1 → E2, а E2 — нормальная форма, то происходит нормальное упорядочение E1 до E2. «Уменьшение нормального порядка всегда будет давать нормальную форму, если таковая существует».
Если E1 ↔ E2, то существует E, такое, что E1 → E и E2 → E. «Уменьшение любым способом может в конечном итоге привести к тому же результату».
Если E1 → E2, а E2 — нормальная форма, то происходит нормальное упорядочение E1 до E2. «Уменьшение нормального порядка всегда будет давать нормальную форму, если таковая существует».
Функциональное программирование — Ленивая оценка
Ленивая оценка — это стратегия оценки, которая удерживает оценку выражения до тех пор, пока не потребуется его значение. Это позволяет избежать повторной оценки. Haskell — хороший пример такого функционального языка программирования, основы которого основаны на Lazy Evaluation.
Ленивая оценка используется в функциях карт Unix для повышения их производительности путем загрузки только необходимых страниц с диска. Для оставшихся страниц память не будет выделена.
Ленивая оценка — преимущества
-
Это позволяет языковой среде выполнения отбрасывать подвыражения, которые не связаны напрямую с конечным результатом выражения.
-
Это уменьшает временную сложность алгоритма, отбрасывая временные вычисления и условные выражения.
-
Это позволяет программисту получать доступ к компонентам структур данных вне их порядка после их инициализации, если они свободны от каких-либо циклических зависимостей.
-
Лучше всего подходит для загрузки данных, к которым редко обращаются.
Это позволяет языковой среде выполнения отбрасывать подвыражения, которые не связаны напрямую с конечным результатом выражения.
Это уменьшает временную сложность алгоритма, отбрасывая временные вычисления и условные выражения.
Это позволяет программисту получать доступ к компонентам структур данных вне их порядка после их инициализации, если они свободны от каких-либо циклических зависимостей.
Лучше всего подходит для загрузки данных, к которым редко обращаются.
Ленивая оценка — недостатки
-
Это заставляет языковую среду выполнения хранить оценку подвыражений до тех пор, пока она не потребуется в конечном результате, создавая thunks (объекты с задержкой).
-
Иногда это увеличивает пространственную сложность алгоритма.
-
Очень сложно найти его производительность, потому что он содержит множество выражений перед их выполнением.
Это заставляет языковую среду выполнения хранить оценку подвыражений до тех пор, пока она не потребуется в конечном результате, создавая thunks (объекты с задержкой).
Иногда это увеличивает пространственную сложность алгоритма.
Очень сложно найти его производительность, потому что он содержит множество выражений перед их выполнением.
Ленивая оценка с использованием Python
Метод диапазона в Python следует концепции Lazy Evaluation. Это экономит время выполнения для больших диапазонов, и нам никогда не требуются все значения за раз, поэтому также экономит потребление памяти. Посмотрите на следующий пример.
r = range(10) print(r) range(0, 10) print(r[3])
Это даст следующий результат —
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 3
Операции ввода-вывода файла
Нам нужны файлы для хранения результатов программы, когда программа завершается. Используя файлы, мы можем получить доступ к соответствующей информации, используя различные команды на разных языках.
Вот список некоторых операций, которые можно выполнять над файлом:
- Создание нового файла
- Открытие существующего файла
- Чтение содержимого файла
- Поиск данных в файле
- Запись в новый файл
- Обновление содержимого в существующий файл
- Удаление файла
- Закрытие файла
Запись в файл
Чтобы записать содержимое в файл, нам сначала нужно открыть нужный файл. Если указанный файл не существует, то будет создан новый файл.
Давайте посмотрим, как записать содержимое в файл, используя C ++.
пример
#include <iostream>
#include <fstream>
using namespace std;
int main () {
ofstream myfile;
myfile.open ("Tempfile.txt", ios::out);
myfile << "Writing Contents to file.\n";
cout << "Data inserted into file";
myfile.close();
return 0;
}
Примечание —
-
fstream — это класс потока, используемый для управления операциями чтения / записи файла.
-
ofstream — это класс потока, используемый для записи содержимого в файл.
fstream — это класс потока, используемый для управления операциями чтения / записи файла.
ofstream — это класс потока, используемый для записи содержимого в файл.
Давайте посмотрим, как записать содержимое в файл, используя Erlang, который является функциональным языком программирования.
-module(helloworld).
-export([start/0]).
start() ->
{ok, File1} = file:open("Tempfile.txt", [write]),
file:write(File1,"Writting contents to file"),
io:fwrite("Data inserted into file\n").
Примечание —
-
Чтобы открыть файл, который мы должны использовать, откройте (имя файла, режим) .
-
Синтаксис для записи содержимого в файл: write (filemode, file_content) .
Чтобы открыть файл, который мы должны использовать, откройте (имя файла, режим) .
Синтаксис для записи содержимого в файл: write (filemode, file_content) .
Вывод. Когда мы запустим этот код, «Запись содержимого в файл» будет записана в файл Tempfile.txt . Если файл имеет какой-либо существующий контент, то он будет перезаписан.
Чтение из файла
Для чтения из файла сначала необходимо открыть указанный файл в режиме чтения . Если файл не существует, его соответствующий метод возвращает NULL.
Следующая программа показывает, как читать содержимое файла в C ++ —
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main () {
string readfile;
ifstream myfile ("Tempfile.txt",ios::in);
if (myfile.is_open()) {
while ( getline (myfile,readfile) ) {
cout << readfile << '\n';
}
myfile.close();
} else
cout << "file doesn't exist";
return 0;
}
Это даст следующий результат —
Writing contents to file
Примечание. В этой программе мы открыли текстовый файл в режиме чтения с помощью «ios :: in», а затем распечатали его содержимое на экране. Мы использовали цикл while для чтения содержимого файла построчно с помощью метода «getline».
Следующая программа показывает, как выполнить ту же операцию, используя Erlang . Здесь мы будем использовать метод read_file (filename), чтобы прочитать все содержимое из указанного файла.
-module(helloworld).
-export([start/0]).
start() ->
rdfile = file:read_file("Tempfile.txt"),
io:fwrite("~p~n",[rdfile]).
Это даст следующий результат —
ok, Writing contents to file
Удалить существующий файл
Мы можем удалить существующий файл, используя файловые операции. Следующая программа показывает, как удалить существующий файл с помощью C ++ —
#include <stdio.h>
int main () {
if(remove( "Tempfile.txt" ) != 0 )
perror( "File doesn’t exist, can’t delete" );
else
puts( "file deleted successfully " );
return 0;
}
Это даст следующий результат —
file deleted successfully
Следующая программа показывает, как вы можете выполнить ту же операцию в Erlang . Здесь мы будем использовать метод delete (имя файла), чтобы удалить существующий файл.
-module(helloworld).
-export([start/0]).
start() ->
file:delete("Tempfile.txt").
Вывод. Если файл «Tempfile.txt» существует, он будет удален.
Определение размера файла
Следующая программа показывает, как вы можете определить размер файла с помощью C ++. Здесь функция fseek устанавливает индикатор позиции, связанный с потоком, на новую позицию, тогда как ftell возвращает текущую позицию в потоке.
#include <stdio.h>
int main () {
FILE * checkfile;
long size;
checkfile = fopen ("Tempfile.txt","rb");
if (checkfile == NULL)
perror ("file can’t open");
else {
fseek (checkfile, 0, SEEK_END); // non-portable
size = ftell (checkfile);
fclose (checkfile);
printf ("Size of Tempfile.txt: %ld bytes.\n",size);
}
return 0;
}
Вывод. Если файл «Tempfile.txt» существует, он покажет свой размер в байтах.
Следующая программа показывает, как вы можете выполнить ту же операцию в Erlang. Здесь мы будем использовать метод file_size (имя файла), чтобы определить размер файла.
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w~n",[filelib:file_size("Tempfile.txt")]).
Вывод. Если файл «Tempfile.txt» существует, он покажет свой размер в байтах. В противном случае будет отображаться «0».