XML — Обзор
XML расшифровывается как расширяемый язык. Это текстовый язык разметки, основанный на стандартном обобщенном языке разметки (SGML).
XML-теги идентифицируют данные и используются для хранения и организации данных, а не указывают, как их отображать как HTML-теги, которые используются для отображения данных. XML не собирается заменять HTML в ближайшем будущем, но он открывает новые возможности, применяя многие успешные функции HTML.
Есть три важных характеристики XML, которые делают его полезным в различных системах и решениях:
-
XML расширяем — XML позволяет вам создавать свои собственные описательные теги или язык, который подходит вашему приложению.
-
XML переносит данные, не представляет их — XML позволяет хранить данные независимо от того, как они будут представлены.
-
XML является общедоступным стандартом — XML был разработан организацией под названием World Wide Web Consortium (W3C) и доступен в качестве открытого стандарта.
XML расширяем — XML позволяет вам создавать свои собственные описательные теги или язык, который подходит вашему приложению.
XML переносит данные, не представляет их — XML позволяет хранить данные независимо от того, как они будут представлены.
XML является общедоступным стандартом — XML был разработан организацией под названием World Wide Web Consortium (W3C) и доступен в качестве открытого стандарта.
Использование XML
Краткий список использования XML говорит само за себя —
-
XML может работать за сценой, чтобы упростить создание документов HTML для крупных веб-сайтов.
-
XML может использоваться для обмена информацией между организациями и системами.
-
XML можно использовать для выгрузки и перезагрузки баз данных.
-
XML может использоваться для хранения и упорядочения данных, что может настраивать ваши потребности в обработке данных.
-
XML можно легко объединить с таблицами стилей для создания практически любого желаемого результата.
-
Фактически, любой тип данных может быть выражен в виде XML-документа.
XML может работать за сценой, чтобы упростить создание документов HTML для крупных веб-сайтов.
XML может использоваться для обмена информацией между организациями и системами.
XML можно использовать для выгрузки и перезагрузки баз данных.
XML может использоваться для хранения и упорядочения данных, что может настраивать ваши потребности в обработке данных.
XML можно легко объединить с таблицами стилей для создания практически любого желаемого результата.
Фактически, любой тип данных может быть выражен в виде XML-документа.
Что такое разметка?
XML — это язык разметки, который определяет набор правил для кодирования документов в формате, который читается человеком и читается машиной. Так что же такое язык разметки? Разметка — это информация, добавляемая в документ, которая определенным образом усиливает его значение, поскольку она идентифицирует части и то, как они связаны друг с другом. Более конкретно, язык разметки — это набор символов, которые могут быть помещены в текст документа для разграничения и маркировки частей этого документа.
В следующем примере показано, как выглядит XML-разметка при внедрении в фрагмент текста:
<message> <text>Hello, world!</text> </message>
Этот фрагмент содержит символы разметки или теги, такие как <message> … </ message> и <text> … </ text>. Теги <message> и </ message> отмечают начало и конец фрагмента кода XML. Теги <text> и </ text> окружают текст Hello, world !.
Является ли XML языком программирования?
Язык программирования состоит из грамматических правил и собственного словарного запаса, который используется для создания компьютерных программ. Эти программы инструктируют компьютер для выполнения определенных задач. XML не может считаться языком программирования, поскольку он не выполняет никаких вычислений или алгоритмов. Обычно он хранится в простом текстовом файле и обрабатывается специальным программным обеспечением, способным интерпретировать XML.
XML — синтаксис
В этой главе мы обсудим простые правила синтаксиса для написания XML-документа. Ниже приведен полный документ XML —
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
Вы можете заметить, что в приведенном выше примере есть два вида информации:
-
Разметка, вроде <контактная информация>
-
Текст или символьные данные, Tutorials Point и (040) 123-4567 .
Разметка, вроде <контактная информация>
Текст или символьные данные, Tutorials Point и (040) 123-4567 .
Следующая диаграмма изображает правила синтаксиса для записи разметки и текста разного типа в XML-документе.
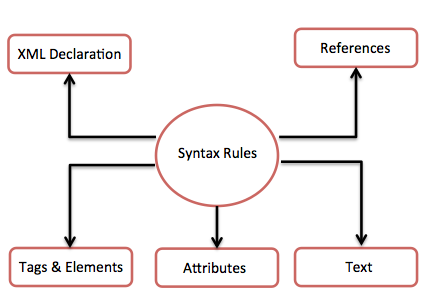
Давайте рассмотрим каждый компонент вышеприведенной диаграммы в деталях.
Декларация XML
XML-документ может дополнительно иметь декларацию XML. Это написано следующим образом —
<?xml version = "1.0" encoding = "UTF-8"?>
Где версия — это версия XML, а кодировка указывает кодировку символов, используемую в документе.
Синтаксические правила для декларации XML
-
Декларация XML чувствительна к регистру и должна начинаться с « <? Xml> », где « xml » пишется строчными буквами.
-
Если документ содержит декларацию XML, то он строго должен быть первым утверждением документа XML.
-
Декларация XML строго должна быть первым утверждением в документе XML.
-
Протокол HTTP может переопределить значение кодировки, которое вы указали в объявлении XML.
Декларация XML чувствительна к регистру и должна начинаться с « <? Xml> », где « xml » пишется строчными буквами.
Если документ содержит декларацию XML, то он строго должен быть первым утверждением документа XML.
Декларация XML строго должна быть первым утверждением в документе XML.
Протокол HTTP может переопределить значение кодировки, которое вы указали в объявлении XML.
Теги и элементы
Файл XML структурирован несколькими XML-элементами, также называемыми XML-узлами или XML-тегами. Имена XML-элементов заключены в треугольные скобки <>, как показано ниже —
<element>
Синтаксические правила для тегов и элементов
Синтаксис элемента — каждый XML-элемент должен быть закрыт либо начальным, либо конечным элементом, как показано ниже —
<element>....</element>
или в простых случаях, просто так —
<element/>
Вложенность элементов — XML-элемент может содержать несколько XML-элементов в качестве своих дочерних элементов, но дочерние элементы не должны перекрываться. т. е. конечный тег элемента должен иметь то же имя, что и у самого последнего непревзойденного начального тега.
В следующем примере показаны неверные вложенные теги.
<?xml version = "1.0"?> <contact-info> <company>TutorialsPoint <contact-info> </company>
В следующем примере показаны правильные вложенные теги —
<?xml version = "1.0"?> <contact-info> <company>TutorialsPoint</company> <contact-info>
Корневой элемент — XML-документ может иметь только один корневой элемент. Например, следующее не является правильным XML-документом, поскольку элементы x и y находятся на верхнем уровне без корневого элемента —
<x>...</x> <y>...</y>
В следующем примере показан правильно сформированный документ XML:
<root> <x>...</x> <y>...</y> </root>
Чувствительность к регистру — Имена XML-элементов чувствительны к регистру. Это означает, что имя начального и конечного элементов должно быть точно в одном и том же случае.
Например, <контактная информация> отличается от <контактная информация>
Атрибуты XML
Атрибут задает одно свойство для элемента, используя пару имя / значение. XML-элемент может иметь один или несколько атрибутов. Например —
<a href = "http://www.tutorialspoint.com/">Tutorialspoint!</a>
Здесь href — имя атрибута, а http://www.tutorialspoint.com/ — значение атрибута.
Синтаксические правила для атрибутов XML
-
Имена атрибутов в XML (в отличие от HTML) чувствительны к регистру. То есть HREF и href считаются двумя различными атрибутами XML.
-
Один и тот же атрибут не может иметь два значения в синтаксисе. В следующем примере показан неверный синтаксис, поскольку атрибут b указан дважды
—
Имена атрибутов в XML (в отличие от HTML) чувствительны к регистру. То есть HREF и href считаются двумя различными атрибутами XML.
Один и тот же атрибут не может иметь два значения в синтаксисе. В следующем примере показан неверный синтаксис, поскольку атрибут b указан дважды
<a b = "x" c = "y" b = "z">....</a>
-
Имена атрибутов определяются без кавычек, тогда как значения атрибутов всегда должны появляться в кавычках. Следующий пример демонстрирует неправильный синтаксис XML
—
Имена атрибутов определяются без кавычек, тогда как значения атрибутов всегда должны появляться в кавычках. Следующий пример демонстрирует неправильный синтаксис XML
<a b = x>....</a>
В приведенном выше синтаксисе значение атрибута не определено в кавычках.
XML ссылки
Ссылки обычно позволяют добавлять или включать дополнительный текст или разметку в документ XML. Ссылки всегда начинаются с символа «&», который является зарезервированным символом, и заканчиваются символом «;». XML имеет два типа ссылок:
-
Ссылки на сущности — ссылка на сущность содержит имя между начальным и конечным разделителями. Например, & amp; где amp это имя . Имя относится к предварительно определенной строке текста и / или разметки.
-
Ссылки на символы — они содержат ссылки, такие как & # 65; , содержит хеш-знак («#»), за которым следует число. Число всегда относится к коду Unicode символа. В этом случае 65 относится к алфавиту «А».
Ссылки на сущности — ссылка на сущность содержит имя между начальным и конечным разделителями. Например, & amp; где amp это имя . Имя относится к предварительно определенной строке текста и / или разметки.
Ссылки на символы — они содержат ссылки, такие как & # 65; , содержит хеш-знак («#»), за которым следует число. Число всегда относится к коду Unicode символа. В этом случае 65 относится к алфавиту «А».
Текст XML
Имена XML-элементов и XML-атрибутов чувствительны к регистру, что означает, что имена начальных и конечных элементов должны быть записаны в одном и том же регистре. Чтобы избежать проблем с кодировкой символов, все файлы XML должны быть сохранены как файлы Unicode UTF-8 или UTF-16.
Пробельные символы, такие как пробелы, табуляции и разрывы строк между XML-элементами и между XML-атрибутами, будут игнорироваться.
Некоторые символы зарезервированы самим синтаксисом XML. Следовательно, они не могут быть использованы напрямую. Для их использования используются некоторые замещающие объекты, которые перечислены ниже:
| Не разрешенный персонаж | Запасной объект | Описание персонажа |
|---|---|---|
| < | & Lt; | меньше, чем |
| > | & GT; | лучше чем |
| & | & Амп; | амперсант |
| ‘ | & APOS; | апостроф |
| « | & Quot; | кавычка |
XML — документы
XML- документ — это базовая единица XML-информации, состоящая из элементов и другой разметки в упорядоченном пакете. XML- документ может содержать самые разные данные. Например, база данных чисел, чисел, представляющих молекулярную структуру или математическое уравнение.
Пример XML-документа
Простой документ показан в следующем примере:
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
На следующем рисунке изображены части документа XML.

Документ Пролог Раздел
Пролог документа идет вверху документа, перед корневым элементом. Этот раздел содержит —
- Декларация XML
- Декларация типа документа
Вы можете узнать больше о декларации XML в этой главе — Декларация XML
Раздел элементов документа
Элементы документа являются строительными блоками XML. Они делят документ на иерархию разделов, каждый из которых служит определенной цели. Вы можете разделить документ на несколько разделов, чтобы они могли отображаться по-разному или использоваться поисковой системой. Элементы могут быть контейнерами с комбинацией текста и других элементов.
Вы можете узнать больше об элементах XML в этой главе — Элементы XML
XML — декларация
Эта глава подробно описывает декларацию XML. Объявление XML содержит детали, которые подготавливают процессор XML к анализу документа XML. Это необязательно, но при использовании он должен отображаться в первой строке документа XML.
Синтаксис
Следующий синтаксис показывает объявление XML —
<?xml version = "version_number" encoding = "encoding_declaration" standalone = "standalone_status" ?>
Каждый параметр состоит из имени параметра, знака равенства (=) и значения параметра внутри кавычки. В следующей таблице приведен приведенный выше синтаксис в деталях —
| параметр | pARAMETER_VALUE | Parameter_description |
|---|---|---|
| Версия | 1,0 | Определяет версию используемого стандарта XML. |
| кодирование | UTF-8, UTF-16, ISO-10646-UCS-2, ISO-10646-UCS-4, ISO-8859-1 по ISO-8859-9, ISO-2022-JP, Shift_JIS, EUC-JP | Он определяет кодировку символов, используемую в документе. UTF-8 — используемая кодировка по умолчанию. |
| Standalone | да или нет | Он сообщает синтаксическому анализатору, использует ли документ информацию из внешнего источника, такого как определение типа внешнего документа (DTD), для своего содержимого. По умолчанию установлено значение no . Установка его в yes указывает процессору, что для синтаксического анализа документа не требуется никаких внешних объявлений. |
правила
Декларация XML должна соответствовать следующим правилам:
-
Если декларация XML присутствует в XML, она должна быть помещена в качестве первой строки в документе XML.
-
Если объявление XML включено, оно должно содержать атрибут номера версии.
-
Имена и значения параметров чувствительны к регистру.
-
Имена всегда в нижнем регистре.
-
Порядок размещения параметров важен. Правильный порядок: версия, кодировка и автономный.
-
Можно использовать как одинарные, так и двойные кавычки.
-
В декларации XML нет закрывающего тега, т. Е. </? Xml>
Если декларация XML присутствует в XML, она должна быть помещена в качестве первой строки в документе XML.
Если объявление XML включено, оно должно содержать атрибут номера версии.
Имена и значения параметров чувствительны к регистру.
Имена всегда в нижнем регистре.
Порядок размещения параметров важен. Правильный порядок: версия, кодировка и автономный.
Можно использовать как одинарные, так и двойные кавычки.
В декларации XML нет закрывающего тега, т. Е. </? Xml>
Примеры декларации XML
Ниже приведены несколько примеров объявлений XML:
XML декларация без параметров —
<?xml >
XML декларация с определением версии —
<?xml version = "1.0">
Декларация XML со всеми определенными параметрами —
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
Декларация XML со всеми параметрами, определенными в одинарных кавычках —
<?xml version = '1.0' encoding = 'iso-8859-1' standalone = 'no' ?>
XML — Теги
Давайте узнаем об одной из самых важных частей XML, тегах XML. XML-теги составляют основу XML. Они определяют область действия элемента в XML. Их также можно использовать для вставки комментариев, объявления настроек, необходимых для анализа среды, и для вставки специальных инструкций.
Мы можем широко классифицировать теги XML следующим образом:
Начать тег
Начало каждого непустого элемента XML помечается начальным тегом. Ниже приведен пример начального тега:
<address>
Конечный тег
Каждый элемент, имеющий начальный тег, должен заканчиваться конечным тегом. Ниже приведен пример конечного тега:
</address>
Обратите внимание, что конечные теги включают солидус («/») перед именем элемента.
Пустой тег
Текст, который появляется между начальным тегом и конечным тегом, называется контентом. Элемент, который не имеет содержимого, называется пустым. Пустой элемент может быть представлен двумя способами:
Начальная метка, за которой сразу следует конечная метка, как показано ниже —
<hr></hr>
Полный тег пустого элемента показан ниже:
<hr />
Теги пустого элемента могут использоваться для любого элемента, который не имеет содержимого.
Правила использования XML-тегов
Ниже приведены правила, которым необходимо следовать для использования тегов XML:
Правило 1
Теги XML чувствительны к регистру. Следующая строка кода является примером неправильного синтаксиса </ Address> из-за разницы в регистре в двух тегах, которая рассматривается как ошибочный синтаксис в XML.
<address>This is wrong syntax</Address>
Следующий код показывает правильный путь, где мы используем один и тот же регистр для именования начального и конечного тега.
<address>This is correct syntax</address>
Правило 2
Теги XML должны быть закрыты в соответствующем порядке, т. Е. Тег XML, открытый внутри другого элемента, должен быть закрыт до закрытия внешнего элемента. Например —
<outer_element>
<internal_element>
This tag is closed before the outer_element
</internal_element>
</outer_element>
XML — Элементы
Элементы XML могут быть определены как строительные блоки XML. Элементы могут вести себя как контейнеры для хранения текста, элементов, атрибутов, объектов мультимедиа или всего этого.
Каждый документ XML содержит один или несколько элементов, область действия которых ограничена начальным и конечным тегами или для пустых элементов — тегом пустого элемента.
Синтаксис
Ниже приведен синтаксис для написания элемента XML:
<element-name attribute1 attribute2> ....content </element-name>
где,
-
element-name — это имя элемента. Имя его регистра в начальных и конечных тегах должно совпадать.
-
attribute1, attribute2 — это атрибуты элемента, разделенные пробелами. Атрибут определяет свойство элемента. Он связывает имя со значением, которое представляет собой строку символов. Атрибут записывается как —
element-name — это имя элемента. Имя его регистра в начальных и конечных тегах должно совпадать.
attribute1, attribute2 — это атрибуты элемента, разделенные пробелами. Атрибут определяет свойство элемента. Он связывает имя со значением, которое представляет собой строку символов. Атрибут записывается как —
name = "value"
За именем следует знак = и строковое значение в двойных («») или одинарных (») кавычках.
Пустой элемент
Пустой элемент (элемент без содержимого) имеет следующий синтаксис —
<name attribute1 attribute2.../>
Ниже приведен пример документа XML с использованием различных элементов XML:
<?xml version = "1.0"?>
<contact-info>
<address category = "residence">
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</address>
</contact-info>
Правила XML-элементов
Следующие правила должны соблюдаться для элементов XML —
-
Имя элемента может содержать любые буквенно-цифровые символы. Единственные знаки препинания, допускаемые в именах, — это дефис (-), знак ниже (_) и точка (.).
-
Имена чувствительны к регистру. Например, Адрес, адрес и АДРЕС — это разные имена.
-
Начальный и конечный теги элемента должны быть идентичны.
-
Элемент, который является контейнером, может содержать текст или элементы, как видно из приведенного выше примера.
Имя элемента может содержать любые буквенно-цифровые символы. Единственные знаки препинания, допускаемые в именах, — это дефис (-), знак ниже (_) и точка (.).
Имена чувствительны к регистру. Например, Адрес, адрес и АДРЕС — это разные имена.
Начальный и конечный теги элемента должны быть идентичны.
Элемент, который является контейнером, может содержать текст или элементы, как видно из приведенного выше примера.
XML — Атрибуты
В этой главе описываются атрибуты XML . Атрибуты являются частью элементов XML. Элемент может иметь несколько уникальных атрибутов. Атрибут дает больше информации об элементах XML. Точнее, они определяют свойства элементов. Атрибут XML всегда является парой имя-значение.
Синтаксис
Атрибут XML имеет следующий синтаксис —
<element-name attribute1 attribute2 > ....content.. < /element-name>
где attribute1 и attribute2 имеет следующую форму —
name = "value"
значение должно быть в двойных («») или одинарных (») кавычках. Здесь attribute1 и attribute2 являются уникальными метками атрибутов.
Атрибуты используются для добавления уникальной метки к элементу, размещения метки в категории, добавления логического флага или иного связывания его с какой-либо строкой данных. Следующий пример демонстрирует использование атрибутов —
<?xml version = "1.0" encoding = "UTF-8"?> <!DOCTYPE garden [ <!ELEMENT garden (plants)*> <!ELEMENT plants (#PCDATA)> <!ATTLIST plants category CDATA #REQUIRED> ]> <garden> <plants category = "flowers" /> <plants category = "shrubs"> </plants> </garden>
Атрибуты используются для различения элементов с одинаковыми именами, когда вы не хотите создавать новый элемент для каждой ситуации. Следовательно, использование атрибута может добавить немного больше деталей при дифференциации двух или более похожих элементов.
В приведенном выше примере мы классифицировали растения, включая категорию атрибутов и присваивая различные значения каждому из элементов. Следовательно, у нас есть две категории растений , один цветы и другой цвет . Таким образом, у нас есть два растительных элемента с разными атрибутами.
Вы также можете заметить, что мы объявили этот атрибут в начале XML.
Типы атрибутов
В следующей таблице перечислены типы атрибутов —
| Тип атрибута | Описание |
|---|---|
| StringType | Он принимает любую буквенную строку в качестве значения. CDATA — это тип StringType. CDATA — это символьные данные. Это означает, что любая строка символов без разметки является законной частью атрибута. |
| TokenizedType |
Это более ограниченный тип. Ограничения достоверности, отмеченные в грамматике, применяются после нормализации значения атрибута. Атрибуты TokenizedType представлены как —
|
| EnumeratedType |
У этого есть список предопределенных значений в его объявлении. из которых он должен назначить одно значение. Существует два типа перечисляемых атрибутов:
|
Это более ограниченный тип. Ограничения достоверности, отмеченные в грамматике, применяются после нормализации значения атрибута. Атрибуты TokenizedType представлены как —
ID — используется для указания элемента как уникального.
IDREF — используется для ссылки на идентификатор, который был назван для другого элемента.
IDREFS — используется для ссылки на все идентификаторы элемента.
ENTITY — указывает, что атрибут будет представлять внешнюю сущность в документе.
ENTITIES — указывает, что атрибут будет представлять внешние объекты в документе.
NMTOKEN — это похоже на CDATA с ограничениями на то, какие данные могут быть частью атрибута.
NMTOKENS — Это похоже на CDATA с ограничениями на то, какие данные могут быть частью атрибута.
У этого есть список предопределенных значений в его объявлении. из которых он должен назначить одно значение. Существует два типа перечисляемых атрибутов:
NotationType — объявляет, что элемент будет ссылаться на NOTATION, объявленный где-то еще в документе XML.
Перечисление — Перечисление позволяет вам определить определенный список значений, которым должно соответствовать значение атрибута.
Правила атрибутов элемента
Ниже приведены правила, которые необходимо соблюдать для атрибутов:
-
Имя атрибута не должно появляться более одного раза в одном и том же начальном теге или теге пустого элемента.
-
Атрибут должен быть объявлен в определении типа документа (DTD) с помощью объявления списка атрибутов.
-
Значения атрибутов не должны содержать прямых или косвенных ссылок на сущности для внешних сущностей.
-
Текст замены любого объекта, на который прямо или косвенно ссылается значение атрибута, не должен содержать знак «меньше» ( < )
Имя атрибута не должно появляться более одного раза в одном и том же начальном теге или теге пустого элемента.
Атрибут должен быть объявлен в определении типа документа (DTD) с помощью объявления списка атрибутов.
Значения атрибутов не должны содержать прямых или косвенных ссылок на сущности для внешних сущностей.
Текст замены любого объекта, на который прямо или косвенно ссылается значение атрибута, не должен содержать знак «меньше» ( < )
XML — Комментарии
В этой главе объясняется, как работают комментарии в документах XML. Комментарии XML похожи на комментарии HTML. Комментарии добавляются в виде примечаний или строк для понимания цели XML-кода.
Комментарии могут быть использованы для включения связанных ссылок, информации и терминов. Они видны только в исходном коде; не в коде XML. Комментарии могут появляться в любом месте XML-кода.
Синтаксис
XML-комментарий имеет следующий синтаксис —
<!--Your comment-->
Комментарий начинается с <! — и заканчивается -> . Вы можете добавить текстовые заметки в качестве комментариев между персонажами. Вы не должны вкладывать один комментарий в другой.
пример
Следующий пример демонстрирует использование комментариев в документе XML —
<?xml version = "1.0" encoding = "UTF-8" ?>
<!--Students grades are uploaded by months-->
<class_list>
<student>
<name>Tanmay</name>
<grade>A</grade>
</student>
</class_list>
Любой текст между символами <! — и -> считается комментарием.
Правила XML-комментариев
Следующие правила должны соблюдаться для XML-комментариев —
- Комментарии не могут появляться до объявления XML.
- Комментарии могут появляться в любом месте документа.
- Комментарии не должны появляться в значениях атрибутов.
- Комментарии не могут быть вложены в другие комментарии.
XML — Персонажи
В этой главе описываются объекты символов XML. Прежде чем мы поймем символьные сущности, давайте сначала разберемся, что такое сущность XML.
В соответствии с консорциумом W3 определение сущности выглядит следующим образом:
«Сущность документа служит корнем дерева сущностей и отправной точкой для процессора XML».
Это означает, что сущности являются заполнителями в XML. Они могут быть объявлены в прологе документа или в DTD. Существуют различные типы сущностей, и в этой главе мы обсудим сущность персонажа.
Оба, HTML и XML, имеют некоторые символы, зарезервированные для их использования, которые нельзя использовать в качестве содержимого в коде XML. Например, знаки < и > используются для открытия и закрытия тегов XML. Для отображения этих специальных символов используются символьные объекты.
Есть несколько специальных символов или символов, которые не могут быть набраны непосредственно с клавиатуры. Символы также могут использоваться для отображения этих символов / специальных символов.
Типы персонажей
Есть три типа персонажей —
- Предопределенные персонажи
- Нумерованные персонажи
- Именованные персонажи
Предопределенные персонажи
Они введены, чтобы избежать неоднозначности при использовании некоторых символов. Например, неоднозначность наблюдается, когда символ угла меньше ( < ) или больше ( > ) используется с тегом угла ( <> ). Символьные объекты в основном используются для разделения тегов в XML. Ниже приведен список предварительно определенных символьных объектов из спецификации XML. Их можно использовать для выражения символов без двусмысленности.
-
Амперсанд — & amp;
-
Одинарная кавычка — & apos;
-
Больше чем — & gt;
-
Менее чем — & lt;
-
Двойная кавычка — & quot;
Амперсанд — & amp;
Одинарная кавычка — & apos;
Больше чем — & gt;
Менее чем — & lt;
Двойная кавычка — & quot;
Числовые символы
Числовая ссылка используется для ссылки на символьную сущность. Числовая ссылка может быть в десятичном или шестнадцатеричном формате. Поскольку доступны тысячи числовых ссылок, их немного сложно запомнить. Цифровая ссылка относится к символу по его номеру в наборе символов Unicode.
Общий синтаксис для десятичной числовой ссылки —
&# decimal number ;
Общий синтаксис шестнадцатеричной числовой ссылки —
&#x Hexadecimal number ;
В следующей таблице перечислены некоторые предопределенные символьные объекты с их числовыми значениями.
| Имя сущности | символ | Десятичная ссылка | Шестнадцатеричная ссылка |
|---|---|---|---|
| Quot | « | & # 34; | & # X22; |
| ампер | & | & # 38; | & # X26; |
| APOS | ‘ | & # 39; | & # X27; |
| л | < | & # 60; | & # X3C; |
| GT | > | & # 62; | & # X3e; |
Объект именованного персонажа
Поскольку трудно запомнить числовые символы, наиболее предпочтительным типом символьной сущности является именованная символьная сущность. Здесь каждый объект идентифицируется с именем.
Например —
-
«Aacute» представляет капитал
 персонаж с острым акцентом.
персонаж с острым акцентом. -
«Угроза» представляет маленький
с серьезным акцентом.
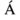
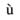
«Aacute» представляет капитал 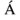 персонаж с острым акцентом.
персонаж с острым акцентом.
«Угроза» представляет маленький 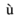 с серьезным акцентом.
с серьезным акцентом.
XML — разделы CDATA
В этой главе мы обсудим раздел XML CDATA . Термин CDATA означает «Персональные данные». CDATA определяется как блоки текста, которые не анализируются синтаксическим анализатором, но в противном случае распознаются как разметка.
Предопределенные объекты, такие как & lt ;, & gt; и & amp; требуют ввода и, как правило, их трудно прочитать в разметке. В таких случаях может использоваться раздел CDATA. Используя раздел CDATA, вы даете команду синтаксическому анализатору на то, что конкретный раздел документа не содержит разметки и должен рассматриваться как обычный текст.
Синтаксис
Ниже приводится синтаксис для раздела CDATA —
<![CDATA[ characters with markup ]]>
Приведенный выше синтаксис состоит из трех разделов:
-
Раздел CDATA Start — CDATA начинается с разделителя из девяти символов <! [CDATA [
-
Конечная секция CDATA — Секция CDATA оканчивается на ]]> разделитель.
-
Раздел CData — Символы между этими двумя вложениями интерпретируются как символы, а не как разметка. Этот раздел может содержать символы разметки (<,> и &), но они игнорируются процессором XML.
Раздел CDATA Start — CDATA начинается с разделителя из девяти символов <! [CDATA [
Конечная секция CDATA — Секция CDATA оканчивается на ]]> разделитель.
Раздел CData — Символы между этими двумя вложениями интерпретируются как символы, а не как разметка. Этот раздел может содержать символы разметки (<,> и &), но они игнорируются процессором XML.
пример
Следующий код разметки показывает пример CDATA. Здесь каждый символ, записанный в разделе CDATA, игнорируется анализатором.
<script>
<![CDATA[
<message> Welcome to TutorialsPoint </message>
]] >
</script >
В приведенном выше синтаксисе все между <message> и </ message> обрабатывается как символьные данные, а не как разметка.
Правила CDATA
Данные правила должны соблюдаться для XML CDATA —
- CDATA не может содержать строку «]]>» в любом месте XML-документа.
- Вложение в разделе CDATA не допускается.
XML — WhiteSpaces
В этой главе мы обсудим обработку пробелов в документах XML. Пробелы — это набор пробелов, вкладок и новых строк. Они обычно используются, чтобы сделать документ более читабельным.
XML-документ содержит два типа пробелов — значимые пробелы и незначимые пробелы. Оба объяснены ниже с примерами.
Значительный пробел
Значительный пробел встречается внутри элемента, который содержит текст и разметку, присутствующие вместе. Например —
<name>TanmayPatil</name>
а также
<name>Tanmay Patil</name>
Вышеупомянутые два элемента отличаются из-за расстояния между Tanmay и Patil . Любая программа, считывающая этот элемент в XML-файле, обязана поддерживать это различие.
Незначительный пробел
Незначительный пробел означает пространство, где разрешено только содержимое элемента. Например —
<address.category = "residence">
или же
<address....category = "..residence">
Приведенные выше примеры одинаковы. Здесь пространство представлено точками (.). В приведенном выше примере пространство между адресом и категорией незначительно.
Специальный атрибут с именем xml: space может быть присоединен к элементу. Это указывает на то, что пробел не должен быть удален для этого элемента приложением. Вы можете установить этот атрибут по умолчанию или сохранить, как показано в следующем примере —
<!ATTLIST address xml:space (default|preserve) 'preserve'>
Куда,
-
Значение default указывает на то, что стандартные режимы обработки пробелов в приложении приемлемы для этого элемента.
-
Значение preserve указывает, что приложение сохраняет все пробелы.
Значение default указывает на то, что стандартные режимы обработки пробелов в приложении приемлемы для этого элемента.
Значение preserve указывает, что приложение сохраняет все пробелы.
XML — обработка
В этой главе описываются инструкции по обработке (PI) . Как определено Рекомендацией XML 1.0,
«Инструкции обработки (PI) позволяют документам содержать инструкции для приложений. PI не являются частью символьных данных документа, но ДОЛЖНЫ передаваться приложению.
Инструкции по обработке (PI) могут использоваться для передачи информации приложениям. PI могут появляться в любом месте документа вне разметки. Они могут появляться в прологе, включая определение типа документа (DTD), в текстовом содержимом или после документа.
Синтаксис
Ниже приводится синтаксис PI —
<?target instructions?>
куда
-
target — определяет приложение, на которое направлена инструкция.
-
инструкция — символ, который описывает информацию для обработки приложения.
target — определяет приложение, на которое направлена инструкция.
инструкция — символ, который описывает информацию для обработки приложения.
PI начинается со специального тега <? и заканчивается ?> . Обработка содержимого заканчивается сразу после появления строки ?> .
пример
ИП редко используются. Они в основном используются для связи XML-документа с таблицей стилей. Ниже приведен пример —
<?xml-stylesheet href = "tutorialspointstyle.css" type = "text/css"?>
Здесь целью является xml-stylesheet . href = «tutorialspointstyle.css» и type = «text / css» — это данные или инструкции, которые целевое приложение будет использовать во время обработки данного XML-документа.
В этом случае браузер распознает цель, указав, что XML должен быть преобразован перед отображением; первый атрибут утверждает, что тип преобразования — XSL, а второй атрибут указывает на его местоположение.
Правила обработки инструкций
PI может содержать любые данные, кроме комбинации ?> , Которая интерпретируется как закрывающий разделитель. Вот два примера действительных ИП —
<?welcome to pg = 10 of tutorials point?> <?welcome?>
XML — Кодировка
Кодирование — это процесс преобразования символов Юникода в их эквивалентное двоичное представление. Когда процессор XML читает документ XML, он кодирует документ в зависимости от типа кодировки. Следовательно, нам нужно указать тип кодировки в декларации XML.
Типы кодирования
Есть в основном два типа кодирования —
- UTF-8,
- UTF-16
UTF обозначает формат преобразования UCS , а сама UCS означает универсальный набор символов . Число 8 или 16 относится к числу битов, используемых для представления символа. Они либо 8 (один байт), либо 16 (два байта). Для документов без информации о кодировке UTF-8 установлен по умолчанию.
Синтаксис
Тип кодирования включен в раздел пролога XML-документа. Синтаксис для кодировки UTF-8 следующий:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
Синтаксис для кодирования UTF-16 следующий:
<?xml version = "1.0" encoding = "UTF-16" standalone = "no" ?>
пример
Следующий пример показывает объявление кодировки —
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
В вышеприведенном примере encoding = «UTF-8» указывает, что 8-битные символы используются для представления символов. Для представления 16-битных символов может использоваться кодировка UTF-16 .
Файлы XML, закодированные с использованием UTF-8, имеют тенденцию быть меньше по размеру, чем файлы, закодированные с использованием формата UTF-16.
XML — проверка
Валидация — это процесс, с помощью которого документ XML проверяется. XML-документ считается действительным, если его содержимое соответствует элементам, атрибутам и декларации связанного типа документа (DTD) и если документ соответствует выраженным в нем ограничениям. Анализатор обрабатывается синтаксическим анализатором XML двумя способами. Они —
- Правильно оформленный XML-документ
- Допустимый документ XML
Правильно оформленный XML-документ
Говорят, что документ XML правильно сформирован, если он придерживается следующих правил:
-
XML-файлы без DTD должны использовать предопределенные символьные объекты для amp (&) , apos (одинарная кавычка) , gt (>) , lt (<) , quot (двойная кавычка) .
-
Он должен следовать порядку тега. т.е. внутренний тег должен быть закрыт до закрытия внешнего тега.
-
Каждый из его открывающих тегов должен иметь закрывающий тег, или он должен быть самозавершающимся тегом (<title> …. </ title> или <title />).
-
Он должен иметь только один атрибут в стартовом теге, который должен быть заключен в кавычки.
-
Объекты amp (&) , apos (одинарные кавычки) , gt (>) , lt (<) , quot (двойные кавычки) должны быть объявлены.
XML-файлы без DTD должны использовать предопределенные символьные объекты для amp (&) , apos (одинарная кавычка) , gt (>) , lt (<) , quot (двойная кавычка) .
Он должен следовать порядку тега. т.е. внутренний тег должен быть закрыт до закрытия внешнего тега.
Каждый из его открывающих тегов должен иметь закрывающий тег, или он должен быть самозавершающимся тегом (<title> …. </ title> или <title />).
Он должен иметь только один атрибут в стартовом теге, который должен быть заключен в кавычки.
Объекты amp (&) , apos (одинарные кавычки) , gt (>) , lt (<) , quot (двойные кавычки) должны быть объявлены.
пример
Ниже приведен пример правильно сформированного документа XML:
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
Говорят, что приведенный выше пример хорошо сформирован как —
-
Он определяет тип документа. Здесь тип документа — тип элемента .
-
Он включает в себя корневой элемент с именем как адрес .
-
Каждый из дочерних элементов, таких как имя, компания и телефон, заключен в понятный тег.
-
Порядок тегов поддерживается.
Он определяет тип документа. Здесь тип документа — тип элемента .
Он включает в себя корневой элемент с именем как адрес .
Каждый из дочерних элементов, таких как имя, компания и телефон, заключен в понятный тег.
Порядок тегов поддерживается.
Допустимый XML-документ
Если документ XML правильно сформирован и имеет ассоциированное объявление типа документа (DTD), то он считается действительным документом XML. Мы будем больше изучать DTD в главе XML — DTD .
XML — DTD
Объявление типа документа XML, обычно известное как DTD, является способом точного описания языка XML. DTD проверяют словарный запас и правильность структуры документов XML на соответствие грамматическим правилам соответствующего языка XML.
XML DTD может быть либо задан внутри документа, либо он может храниться в отдельном документе, а затем использоваться отдельно.
Синтаксис
Основной синтаксис DTD выглядит следующим образом —
<!DOCTYPE element DTD identifier [ declaration1 declaration2 ........ ]>
В приведенном выше синтаксисе,
-
DTD начинается с <! DOCTYPE delimiter.
-
Элемент указывает синтаксическому анализатору проанализировать документ из указанного корневого элемента.
-
DTD-идентификатор — это идентификатор для определения типа документа, который может быть путем к файлу в системе или URL-адресом к файлу в Интернете. Если DTD указывает на внешний путь, он называется External Subset.
-
Квадратные скобки [] заключают в себе необязательный список объявлений сущностей, который называется Internal Subset .
DTD начинается с <! DOCTYPE delimiter.
Элемент указывает синтаксическому анализатору проанализировать документ из указанного корневого элемента.
DTD-идентификатор — это идентификатор для определения типа документа, который может быть путем к файлу в системе или URL-адресом к файлу в Интернете. Если DTD указывает на внешний путь, он называется External Subset.
Квадратные скобки [] заключают в себе необязательный список объявлений сущностей, который называется Internal Subset .
Внутренний DTD
DTD называется внутренним DTD, если элементы объявлены в файлах XML. Чтобы обозначить его как внутренний DTD, автономный атрибут в объявлении XML должен быть установлен в yes . Это означает, что объявление работает независимо от внешнего источника.
Синтаксис
Ниже приводится синтаксис внутреннего DTD —
<!DOCTYPE root-element [element-declarations]>
где root-element — это имя корневого элемента, а element-объявлений — это место, где вы объявляете элементы.
пример
Ниже приведен простой пример внутреннего DTD —
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?> <!DOCTYPE address [ <!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)> ]> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
Давайте пройдемся по приведенному выше коду —
Начать объявление — Начните объявление XML со следующего утверждения.
<?xml version = "1.0" encoding = "UTF-8" standalone = "yes" ?>
DTD — Сразу после заголовка XML следует объявление типа документа , обычно называемое DOCTYPE —
<!DOCTYPE address [
Объявление DOCTYPE имеет восклицательный знак (!) В начале имени элемента. DOCTYPE сообщает анализатору, что DTD связан с этим документом XML.
Тело DTD — за объявлением DOCTYPE следует тело DTD, где вы объявляете элементы, атрибуты, сущности и нотации.
<!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone_no (#PCDATA)>
Здесь объявлено несколько элементов, которые составляют словарь документа <name>. <! ELEMENT name (#PCDATA)> определяет имя элемента типа «#PCDATA». Здесь #PCDATA означает анализируемые текстовые данные.
Завершение объявления — Наконец, раздел объявления DTD закрывается с помощью закрывающей скобки и закрывающей угловой скобки ( ]> ). Это эффективно завершает определение, и после этого документ XML следует сразу же.
правила
-
Объявление типа документа должно появляться в начале документа (с предшествующим только заголовком XML) — оно не разрешено где-либо еще в документе.
-
Подобно объявлению DOCTYPE, объявления элементов должны начинаться с восклицательного знака.
-
Имя в объявлении типа документа должно соответствовать типу элемента корневого элемента.
Объявление типа документа должно появляться в начале документа (с предшествующим только заголовком XML) — оно не разрешено где-либо еще в документе.
Подобно объявлению DOCTYPE, объявления элементов должны начинаться с восклицательного знака.
Имя в объявлении типа документа должно соответствовать типу элемента корневого элемента.
Внешний DTD
Во внешних DTD элементы объявляются вне XML-файла. Доступ к ним осуществляется путем указания системных атрибутов, которые могут быть либо легальным файлом .dtd, либо действительным URL-адресом. Чтобы обозначить его как внешнее DTD, автономный атрибут в объявлении XML должен быть установлен как no . Это означает, что декларация включает в себя информацию из внешнего источника.
Синтаксис
Ниже приводится синтаксис для внешнего DTD —
<!DOCTYPE root-element SYSTEM "file-name">
где file-name — это файл с расширением .dtd .
пример
В следующем примере показано использование внешнего DTD —
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?> <!DOCTYPE address SYSTEM "address.dtd"> <address> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </address>
Содержимое файла DTD address.dtd выглядит так:
<!ELEMENT address (name,company,phone)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (#PCDATA)> <!ELEMENT phone (#PCDATA)>
Типы
Вы можете обратиться к внешнему DTD, используя системные идентификаторы или публичные идентификаторы .
Системные идентификаторы
Системный идентификатор позволяет указать местоположение внешнего файла, содержащего объявления DTD. Синтаксис выглядит следующим образом —
<!DOCTYPE name SYSTEM "address.dtd" [...]>
Как видите, он содержит ключевое слово SYSTEM и ссылку URI, указывающую на местоположение документа.
Публичные идентификаторы
Открытые идентификаторы предоставляют механизм для определения местоположения ресурсов DTD и записываются следующим образом:
<!DOCTYPE name PUBLIC "-//Beginning XML//DTD Address Example//EN">
Как видите, он начинается с ключевого слова PUBLIC, за которым следует специальный идентификатор. Публичные идентификаторы используются для идентификации записи в каталоге. Публичные идентификаторы могут следовать любому формату, однако обычно используемый формат называется формальными общедоступными идентификаторами или FPI .
XML — схемы
Схема XML широко известна как определение схемы XML (XSD) . Он используется для описания и проверки структуры и содержания данных XML. Схема XML определяет элементы, атрибуты и типы данных. Элемент схемы поддерживает пространства имен. Это похоже на схему базы данных, которая описывает данные в базе данных.
Синтаксис
Вам необходимо объявить схему в своем XML-документе следующим образом:
пример
В следующем примере показано, как использовать схему —
<?xml version = "1.0" encoding = "UTF-8"?>
<xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema">
<xs:element name = "contact">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
Основная идея XML-схем заключается в том, что они описывают допустимый формат, который может принимать XML-документ.
элементы
Как мы видели в главе « Элементы XML» , элементы являются строительными блоками документа XML. Элемент может быть определен в XSD следующим образом:
<xs:element name = "x" type = "y"/>
Типы определения
Вы можете определить элементы схемы XML следующими способами:
Простой тип
Элемент простого типа используется только в контексте текста. Некоторые из предопределенных простых типов: xs: целое число, xs: логическое значение, xs: строка, xs: дата. Например —
<xs:element name = "phone_number" type = "xs:int" />
Комплексный тип
Сложный тип — это контейнер для других определений элементов. Это позволяет вам указать, какие дочерние элементы может содержать элемент, и предоставить некоторую структуру в ваших XML-документах. Например —
<xs:element name = "Address">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
<xs:element name = "phone" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
В приведенном выше примере элемент Address состоит из дочерних элементов. Это контейнер для других определений <xs: element> , который позволяет построить простую иерархию элементов в XML-документе.
Глобальные типы
С глобальным типом вы можете определить один тип в вашем документе, который может использоваться всеми другими ссылками. Например, предположим, что вы хотите обобщить человека и компанию для разных адресов компании. В таком случае вы можете определить общий тип следующим образом:
<xs:element name = "AddressType">
<xs:complexType>
<xs:sequence>
<xs:element name = "name" type = "xs:string" />
<xs:element name = "company" type = "xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
Теперь давайте используем этот тип в нашем примере следующим образом:
<xs:element name = "Address1">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone1" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name = "Address2">
<xs:complexType>
<xs:sequence>
<xs:element name = "address" type = "AddressType" />
<xs:element name = "phone2" type = "xs:int" />
</xs:sequence>
</xs:complexType>
</xs:element>
Вместо того, чтобы определять имя и компанию дважды (один раз для Address1 и один раз для Address2 ), теперь у нас есть одно определение. Это упрощает обслуживание, т. Е. Если вы решили добавить элементы «Почтовый индекс» к адресу, вам нужно добавить их только в одном месте.
Атрибуты
Атрибуты в XSD предоставляют дополнительную информацию внутри элемента. Атрибуты имеют свойство name и type, как показано ниже —
<xs:attribute name = "x" type = "y"/>
XML — древовидная структура
XML-документ всегда носит описательный характер. Древовидная структура часто называется XML-деревом и играет важную роль для простого описания любого XML-документа.
Древовидная структура содержит корневые (родительские) элементы, дочерние элементы и так далее. Используя древовидную структуру, вы можете узнать все последующие ветви и дочерние ветви, начиная с корня. Разбор начинается с корня, затем перемещается вниз по первой ветви к элементу, оттуда берется первая ветвь и так далее до конечных узлов.
пример
Следующий пример демонстрирует простую структуру дерева XML —
<?xml version = "1.0"?>
<Company>
<Employee>
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
<Address>
<City>Bangalore</City>
<State>Karnataka</State>
<Zip>560212</Zip>
</Address>
</Employee>
</Company>
Следующая древовидная структура представляет вышеуказанный документ XML —
На приведенной выше диаграмме есть корневой элемент с именем <company>. Внутри этого есть еще один элемент <Employee>. Внутри элемента employee есть пять ветвей с именами <FirstName>, <LastName>, <ContactNo>, <Email> и <Address>. Внутри элемента <Address> есть три дочерних ветви с именами <City> <State> и <Zip>.
XML — DOM
Объектная модель документа (DOM) является основой XML. XML-документы имеют иерархию информационных единиц, называемых узлами ; DOM — это способ описания этих узлов и отношений между ними.
Документ DOM — это набор узлов или фрагментов информации, организованных в иерархию. Эта иерархия позволяет разработчику перемещаться по дереву в поисках конкретной информации. Поскольку он основан на иерархии информации, DOM называется древовидным .
XML DOM, с другой стороны, также предоставляет API, который позволяет разработчику добавлять, редактировать, перемещать или удалять узлы в дереве в любой точке для создания приложения.
пример
В следующем примере (sample.htm) анализируется документ XML («address.xml») в объект DOM XML, а затем извлекается из него некоторая информация с помощью JavaScript.
<!DOCTYPE html>
<html>
<body>
<h1>TutorialsPoint DOM example </h1>
<div>
<b>Name:</b> <span id = "name"></span><br>
<b>Company:</b> <span id = "company"></span><br>
<b>Phone:</b> <span id = "phone"></span>
</div>
<script>
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/xml/address.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("name").innerHTML=
xmlDoc.getElementsByTagName("name")[0].childNodes[0].nodeValue;
document.getElementById("company").innerHTML=
xmlDoc.getElementsByTagName("company")[0].childNodes[0].nodeValue;
document.getElementById("phone").innerHTML=
xmlDoc.getElementsByTagName("phone")[0].childNodes[0].nodeValue;
</script>
</body>
</html>
Содержимое файла address.xml выглядит следующим образом:
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
Теперь давайте оставим эти два файла sample.htm и address.xml в одной директории / xml и запустим файл sample.htm , открыв его в любом браузере. Это должно привести к следующему выводу.

Здесь вы можете увидеть, как каждый из дочерних узлов извлекается для отображения своих значений.
XML — пространства имен
Пространство имен — это набор уникальных имен. Пространство имен — это механизм, с помощью которого элемент и имя атрибута могут быть назначены группе. Пространство имен идентифицируется URI (унифицированными идентификаторами ресурса).
Декларация пространства имен
Пространство имен объявляется с использованием зарезервированных атрибутов. Такое имя атрибута должно быть либо xmlns, либо начинаться с xmlns: показано ниже:
<element xmlns:name = "URL">
Синтаксис
-
Пространство имен начинается с ключевого слова xmlns .
-
Слово name — это префикс пространства имен.
-
URL является идентификатором пространства имен.
Пространство имен начинается с ключевого слова xmlns .
Слово name — это префикс пространства имен.
URL является идентификатором пространства имен.
пример
Пространство имен влияет только на ограниченную область в документе. Элемент, содержащий объявление и все его потомки, находится в области пространства имен. Ниже приведен простой пример пространства имен XML:
<?xml version = "1.0" encoding = "UTF-8"?> <cont:contact xmlns:cont = "www.tutorialspoint.com/profile"> <cont:name>Tanmay Patil</cont:name> <cont:company>TutorialsPoint</cont:company> <cont:phone>(011) 123-4567</cont:phone> </cont:contact>
Здесь префикс пространства имен — это продолжение , а идентификатор пространства имен (URI) — www.tutorialspoint.com/profile . Это означает, что имена элементов и имена атрибутов с префиксом cont (включая элемент contact) все принадлежат пространству имен www.tutorialspoint.com/profile .
XML — Базы данных
База данных XML используется для хранения огромного количества информации в формате XML. Поскольку использование XML увеличивается во всех областях, требуется безопасное место для хранения документов XML. Данные, хранящиеся в базе данных, можно запросить с помощью XQuery , сериализовать и экспортировать в желаемый формат.
Типы баз данных XML
Существует два основных типа баз данных XML:
- XML-включен
- Собственный XML (NXD)
XML — база данных включена
База данных с поддержкой XML — это не что иное, как расширение, предоставляемое для преобразования документа XML. Это реляционная база данных, где данные хранятся в таблицах, состоящих из строк и столбцов. Таблицы содержат набор записей, которые в свою очередь состоят из полей.
Собственная база данных XML
Собственная база данных XML основана на контейнере, а не на табличном формате. Он может хранить большое количество XML-документа и данных. Собственная база данных XML запрашивается выражениями XPath .
Собственная база данных XML имеет преимущество перед базой данных с поддержкой XML. Он обладает высокой способностью хранить, запрашивать и поддерживать документ XML, чем база данных с поддержкой XML.
пример
Следующий пример демонстрирует базу данных XML —
<?xml version = "1.0"?>
<contact-info>
<contact1>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact1>
<contact2>
<name>Manisha Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 789-4567</phone>
</contact2>
</contact-info>
Здесь создается таблица контактов, которая содержит записи контактов (contact1 и contact2), которая в свою очередь состоит из трех объектов — имени, компании и телефона .
XML — Зрители
В этой главе описываются различные методы просмотра XML-документа . Документ XML можно просмотреть с помощью простого текстового редактора или любого браузера. Большинство основных браузеров поддерживают XML. Файлы XML можно открыть в браузере, просто дважды щелкнув документ XML (если это локальный файл) или введя URL-адрес в адресной строке (если файл расположен на сервере), так же, как мы открываем другие файлы в браузере. Файлы XML сохраняются с расширением «.xml» .
Давайте рассмотрим различные методы, с помощью которых мы можем просматривать XML-файл. Следующий пример (sample.xml) используется для просмотра всех разделов этой главы.
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
Текстовые редакторы
Любой простой текстовый редактор, такой как Блокнот, TextPad или TextEdit, можно использовать для создания или просмотра документа XML, как показано ниже —
Браузер Firefox
Откройте приведенный выше код XML в Chrome, дважды щелкнув файл. Код XML отображает кодирование цветом, что делает код читабельным. Он показывает знак плюс (+) или минус (-) с левой стороны в элементе XML. Когда мы нажимаем знак минус (-), код скрывается. Когда мы нажимаем знак плюс (+), строки кода расширяются. Вывод в Firefox, как показано ниже —

Браузер Chrome
Откройте приведенный выше код XML в браузере Chrome. Код отображается как показано ниже —

Ошибки в XML-документе
Если в вашем XML-коде отсутствуют какие-либо теги, в браузере отображается сообщение. Давайте попробуем открыть следующий файл XML в Chrome —
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
В приведенном выше коде начальный и конечный теги не совпадают (см. Тег contact_info), поэтому браузер отображает сообщение об ошибке, как показано ниже:
XML — редакторы
XML Editor — это редактор языка разметки. Документы XML можно редактировать или создавать с использованием существующих редакторов, таких как Блокнот, WordPad или любой аналогичный текстовый редактор. Вы также можете найти профессиональный XML-редактор онлайн или для скачивания, который имеет более мощные функции редактирования, такие как —
- Он автоматически закрывает оставленные теги открытыми.
- Он строго проверяет синтаксис.
- Он выделяет синтаксис XML цветом для повышения читабельности.
- Это поможет вам написать правильный код XML.
- Он обеспечивает автоматическую проверку документов XML по DTD и схемам.
XML-редакторы с открытым исходным кодом
Ниже приведены некоторые XML-редакторы с открытым исходным кодом.
-
Онлайн XML Editor — это легкий XML редактор, который вы можете использовать онлайн.
-
Xerlin — Xerlin — это редактор XML с открытым исходным кодом для платформы Java 2, выпущенный по лицензии Apache. Это приложение для моделирования XML на основе Java, предназначенное для простого создания и редактирования файлов XML.
-
CAM — механизм сборки контента — CAM XML Editor поставляется с XML + JSON + SQL Open-XDX, спонсируемым Oracle.
Онлайн XML Editor — это легкий XML редактор, который вы можете использовать онлайн.
Xerlin — Xerlin — это редактор XML с открытым исходным кодом для платформы Java 2, выпущенный по лицензии Apache. Это приложение для моделирования XML на основе Java, предназначенное для простого создания и редактирования файлов XML.
CAM — механизм сборки контента — CAM XML Editor поставляется с XML + JSON + SQL Open-XDX, спонсируемым Oracle.
XML — парсеры
Анализатор XML — это программная библиотека или пакет, который предоставляет интерфейс для клиентских приложений для работы с документами XML. Он проверяет правильный формат документа XML, а также может проверять документы XML. Современные браузеры имеют встроенные парсеры XML.
Следующая диаграмма показывает, как синтаксический анализатор XML взаимодействует с документом XML:
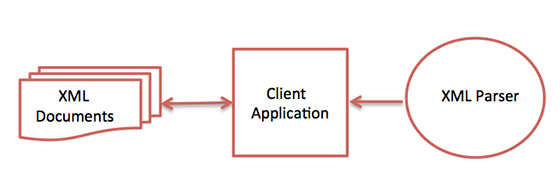
Цель парсера — преобразовать XML в читаемый код.
Чтобы упростить процесс синтаксического анализа, доступны некоторые коммерческие продукты, которые облегчают разбивку XML-документа и дают более надежные результаты.
Некоторые часто используемые парсеры перечислены ниже —
-
MSXML (Microsoft Core XML Services) — это стандартный набор инструментов XML от Microsoft, который включает в себя анализатор.
-
System.Xml.XmlDocument — этот класс является частью библиотеки .NET, которая содержит ряд различных классов, связанных с работой с XML.
-
Встроенный синтаксический анализатор Java — Библиотека Java имеет свой собственный анализатор. Библиотека спроектирована таким образом, что вы можете заменить встроенный парсер на внешнюю реализацию, такую как Xerces от Apache или Saxon.
-
Saxon — Saxon предлагает инструменты для синтаксического анализа, преобразования и запроса XML.
-
Xerces — Xerces реализован на Java и разработан известным Apache Software Foundation с открытым исходным кодом.
MSXML (Microsoft Core XML Services) — это стандартный набор инструментов XML от Microsoft, который включает в себя анализатор.
System.Xml.XmlDocument — этот класс является частью библиотеки .NET, которая содержит ряд различных классов, связанных с работой с XML.
Встроенный синтаксический анализатор Java — Библиотека Java имеет свой собственный анализатор. Библиотека спроектирована таким образом, что вы можете заменить встроенный парсер на внешнюю реализацию, такую как Xerces от Apache или Saxon.
Saxon — Saxon предлагает инструменты для синтаксического анализа, преобразования и запроса XML.
Xerces — Xerces реализован на Java и разработан известным Apache Software Foundation с открытым исходным кодом.
XML — Процессоры
Когда программа читает XML-документ и предпринимает соответствующие действия, это называется обработкой XML. Любая программа, которая может читать и обрабатывать документы XML, называется процессором XML . Процессор XML считывает файл XML и превращает его в структуры в памяти, к которым имеет доступ остальная часть программы.
Самый фундаментальный процессор XML читает документ XML и преобразует его во внутреннее представление для использования другими программами или подпрограммами. Это называется синтаксическим анализатором , и это важный компонент каждой программы обработки XML.
Процессор включает в себя обработку инструкций, которые можно изучить в главе Обработка инструкций .
Типы
Процессоры XML классифицируются как проверяющие или не проверяющие типы в зависимости от того, проверяют ли они документы XML на достоверность. Процессор, который обнаруживает ошибку достоверности, должен иметь возможность сообщить о ней, но может продолжить обычную обработку.
Несколько проверяющих парсеров: xml4c (IBM, на C ++), xml4j (IBM, на Java), MSXML (Microsoft, на Java), TclXML (TCL), xmlproc (Python), XML :: Parser (Perl), проект Java X (Солнце, на Яве).
Несколько неподтверждающих парсеров — OpenXML (Java), Lark (Java), xp (Java), AElfred (Java), expat (C), XParse (JavaScript), xmllib (Python).