PySpark — Введение
В этой главе мы познакомимся с тем, что такое Apache Spark и как был разработан PySpark.
Spark — Обзор
Apache Spark — это молниеносная среда обработки в реальном времени. Он выполняет вычисления в памяти для анализа данных в режиме реального времени. Это стало очевидным, поскольку Apache Hadoop MapReduce выполнял только пакетную обработку и не имел функции обработки в реальном времени. Поэтому был представлен Apache Spark, поскольку он может выполнять потоковую обработку в режиме реального времени, а также может выполнять пакетную обработку.
Помимо обработки в реальном времени и пакетной обработки, Apache Spark поддерживает интерактивные запросы и итерационные алгоритмы. Apache Spark имеет свой собственный менеджер кластеров, где он может разместить свое приложение. Он использует Apache Hadoop для хранения и обработки. Он использует HDFS (распределенную файловую систему Hadoop) для хранения и может также запускать приложения Spark на YARN .
PySpark — Обзор
Apache Spark написан на языке программирования Scala . Для поддержки Python с помощью Spark сообщество Apache Spark выпустило инструмент PySpark. Используя PySpark, вы также можете работать с RDD на языке программирования Python. Именно благодаря библиотеке под названием Py4j они могут достичь этого.
PySpark предлагает PySpark Shell, который связывает Python API с ядром искры и инициализирует контекст Spark. Большинство исследователей данных и аналитиков сегодня используют Python из-за его богатого набора библиотек. Интеграция Python с Spark является благом для них.
PySpark — настройка среды
В этой главе мы разберемся с настройкой среды PySpark.
Примечание. Это означает, что на вашем компьютере установлены Java и Scala.
Давайте теперь загрузим и настроим PySpark со следующими шагами.
Шаг 1 — Перейдите на официальную страницу загрузки Apache Spark и загрузите последнюю версию Apache Spark, доступную там. В этом уроке мы используем spark-2.1.0-bin-hadoop2.7 .
Шаг 2 — Теперь распакуйте скачанный файл Spark tar. По умолчанию он будет загружен в каталог загрузок.
# tar -xvf Downloads/spark-2.1.0-bin-hadoop2.7.tgz
Это создаст каталог spark-2.1.0-bin-hadoop2.7 . Перед запуском PySpark необходимо установить следующие среды, чтобы задать путь Spark и путь Py4j .
export SPARK_HOME = /home/hadoop/spark-2.1.0-bin-hadoop2.7 export PATH = $PATH:/home/hadoop/spark-2.1.0-bin-hadoop2.7/bin export PYTHONPATH = $SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH export PATH = $SPARK_HOME/python:$PATH
Или, чтобы установить вышеуказанные среды глобально, поместите их в файл .bashrc . Затем выполните следующую команду, чтобы среды работали.
# source .bashrc
Теперь, когда все среды установлены, давайте перейдем в каталог Spark и вызовем оболочку PySpark, выполнив следующую команду:
# ./bin/pyspark
Это запустит вашу оболочку PySpark.
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Python version 2.7.12 (default, Nov 19 2016 06:48:10)
SparkSession available as 'spark'.
<<<
PySpark — SparkContext
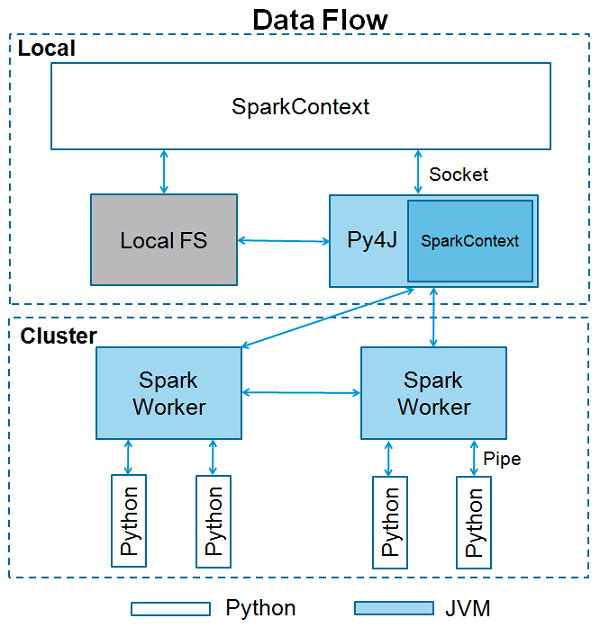
SparkContext — это точка входа в любую функциональность искры. Когда мы запускаем любое приложение Spark, запускается программа драйвера, которая выполняет основную функцию, и здесь запускается ваш SparkContext. Затем программа драйвера запускает операции внутри исполнителей на рабочих узлах.
SparkContext использует Py4J для запуска JVM и создает JavaSparkContext . По умолчанию в PySpark SparkContext доступен как ‘sc’ , поэтому создание нового SparkContext не будет работать.
В следующем блоке кода содержатся сведения о классе PySpark и параметрах, которые может принимать SparkContext.
class pyspark.SparkContext ( master = None, appName = None, sparkHome = None, pyFiles = None, environment = None, batchSize = 0, serializer = PickleSerializer(), conf = None, gateway = None, jsc = None, profiler_cls = <class 'pyspark.profiler.BasicProfiler'> )
параметры
Ниже приведены параметры SparkContext.
-
Мастер — это URL кластера, к которому он подключается.
-
appName — название вашей работы.
-
sparkHome — каталог установки Spark.
-
pyFiles — файлы .zip или .py для отправки в кластер и добавления в PYTHONPATH.
-
Среда — рабочие узлы переменных среды.
-
batchSize — количество объектов Python, представленных в виде одного объекта Java. Установите 1, чтобы отключить пакетную обработку, 0, чтобы автоматически выбирать размер партии на основе размеров объекта, или -1, чтобы использовать неограниченный размер партии.
-
Сериализатор — RDD сериализатор.
-
Conf — Объект L {SparkConf} для установки всех свойств Spark.
-
Шлюз — используйте существующий шлюз и JVM, в противном случае инициализируйте новую JVM.
-
JSC — экземпляр JavaSparkContext.
-
profiler_cls — класс пользовательского профилировщика, используемый для профилирования (по умолчанию это pyspark.profiler.BasicProfiler).
Мастер — это URL кластера, к которому он подключается.
appName — название вашей работы.
sparkHome — каталог установки Spark.
pyFiles — файлы .zip или .py для отправки в кластер и добавления в PYTHONPATH.
Среда — рабочие узлы переменных среды.
batchSize — количество объектов Python, представленных в виде одного объекта Java. Установите 1, чтобы отключить пакетную обработку, 0, чтобы автоматически выбирать размер партии на основе размеров объекта, или -1, чтобы использовать неограниченный размер партии.
Сериализатор — RDD сериализатор.
Conf — Объект L {SparkConf} для установки всех свойств Spark.
Шлюз — используйте существующий шлюз и JVM, в противном случае инициализируйте новую JVM.
JSC — экземпляр JavaSparkContext.
profiler_cls — класс пользовательского профилировщика, используемый для профилирования (по умолчанию это pyspark.profiler.BasicProfiler).
Среди вышеперечисленных параметров в основном используются master и appname . Первые две строки любой программы PySpark выглядят так, как показано ниже —
from pyspark import SparkContext
sc = SparkContext("local", "First App")
Пример SparkContext — PySpark Shell
Теперь, когда вы достаточно знаете о SparkContext, давайте запустим простой пример оболочки PySpark. В этом примере мы будем считать количество строк с символом «a» или «b» в файле README.md . Итак, допустим, если в файле 5 строк, а 3 строки имеют символ «a», то результатом будет → Строка с a: 3 . То же самое будет сделано для символа «б».
Примечание. Мы не создаем никакой объект SparkContext в следующем примере, потому что по умолчанию Spark автоматически создает объект SparkContext с именем sc, когда запускается оболочка PySpark. Если вы попытаетесь создать другой объект SparkContext, вы получите следующую ошибку — «ValueError: Невозможно запустить несколько SparkContexts одновременно».
<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md" <<< logData = sc.textFile(logFile).cache() <<< numAs = logData.filter(lambda s: 'a' in s).count() <<< numBs = logData.filter(lambda s: 'b' in s).count() <<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs) Lines with a: 62, lines with b: 30
Пример SparkContext — Программа Python
Давайте запустим тот же пример, используя программу на Python. Создайте файл Python с именем firstapp.py и введите следующий код в этот файл.
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------
Затем мы выполним следующую команду в терминале, чтобы запустить этот файл Python. Мы получим тот же результат, что и выше.
$SPARK_HOME/bin/spark-submit firstapp.py Output: Lines with a: 62, lines with b: 30
PySpark — RDD
Теперь, когда мы установили и настроили PySpark в нашей системе, мы можем программировать на Python для Apache Spark. Однако, прежде чем сделать это, давайте разберемся с фундаментальной концепцией Spark — RDD.
СДР обозначает Resilient Distributed Dataset , это элементы, которые работают и работают на нескольких узлах для параллельной обработки в кластере. СДР являются неизменяемыми элементами, что означает, что после создания СДР вы не сможете их изменить. СДР также являются отказоустойчивыми, поэтому в случае любого сбоя они восстанавливаются автоматически. Вы можете применить несколько операций к этим СДР для достижения определенной задачи.
Чтобы применить операции к этим RDD, есть два способа:
- Преобразование и
- действие
Позвольте нам понять эти два способа в деталях.
Преобразование — это операции, которые применяются к СДР для создания нового СДР. Filter, groupBy и map являются примерами преобразований.
Действие — это операции, которые применяются к RDD, который инструктирует Spark выполнять вычисления и отправлять результат обратно драйверу.
Чтобы применить любую операцию в PySpark, нам нужно сначала создать PyDpark RDD . Следующий блок кода содержит подробности класса PyDpark RDD —
class pyspark.RDD ( jrdd, ctx, jrdd_deserializer = AutoBatchedSerializer(PickleSerializer()) )
Давайте посмотрим, как выполнить несколько основных операций с помощью PySpark. Следующий код в файле Python создает слова RDD, в которых хранится упомянутый набор слов.
words = sc.parallelize ( ["scala", "java", "hadoop", "spark", "akka", "spark vs hadoop", "pyspark", "pyspark and spark"] )
Теперь мы выполним несколько операций над словами.
кол-()
Количество элементов в СДР возвращается.
----------------------------------------count.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
counts = words.count()
print "Number of elements in RDD -> %i" % (counts)
----------------------------------------count.py---------------------------------------
Команда — Команда для count () является —
$SPARK_HOME/bin/spark-submit count.py
Выходные данные — выход для вышеуказанной команды —
Number of elements in RDD → 8
собирать ()
Все элементы в СДР возвращаются.
----------------------------------------collect.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Collect app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
coll = words.collect()
print "Elements in RDD -> %s" % (coll)
----------------------------------------collect.py---------------------------------------
Command — команда для collect () —
$SPARK_HOME/bin/spark-submit collect.py
Выходные данные — выход для вышеуказанной команды —
Elements in RDD -> [ 'scala', 'java', 'hadoop', 'spark', 'akka', 'spark vs hadoop', 'pyspark', 'pyspark and spark' ]
Еогеасп (е)
Возвращает только те элементы, которые удовлетворяют условию функции внутри foreach. В следующем примере мы вызываем функцию print в foreach, которая печатает все элементы в RDD.
----------------------------------------foreach.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "ForEach app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
def f(x): print(x)
fore = words.foreach(f)
----------------------------------------foreach.py---------------------------------------
Команда — команда для foreach (f) —
$SPARK_HOME/bin/spark-submit foreach.py
Выходные данные — выход для вышеуказанной команды —
scala java hadoop spark akka spark vs hadoop pyspark pyspark and spark
фильтр (F)
Возвращается новый RDD, содержащий элементы, которые удовлетворяют функции внутри фильтра. В следующем примере мы отфильтровываем строки, содержащие искру.
----------------------------------------filter.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Filter app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.collect()
print "Fitered RDD -> %s" % (filtered)
----------------------------------------filter.py----------------------------------------
Команда — Команда для фильтра (f) —
$SPARK_HOME/bin/spark-submit filter.py
Выходные данные — выход для вышеуказанной команды —
Fitered RDD -> [ 'spark', 'spark vs hadoop', 'pyspark', 'pyspark and spark' ]
карта (f, preservePartitioning = False)
Новый RDD возвращается путем применения функции к каждому элементу в RDD. В следующем примере мы формируем пару ключ-значение и сопоставляем каждую строку со значением 1.
----------------------------------------map.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Map app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_map = words.map(lambda x: (x, 1))
mapping = words_map.collect()
print "Key value pair -> %s" % (mapping)
----------------------------------------map.py---------------------------------------
Команда — Команда для карты (f, preservePartitioning = False) —
$SPARK_HOME/bin/spark-submit map.py
Выходные данные — выходные данные вышеупомянутой команды —
Key value pair -> [
('scala', 1),
('java', 1),
('hadoop', 1),
('spark', 1),
('akka', 1),
('spark vs hadoop', 1),
('pyspark', 1),
('pyspark and spark', 1)
]
уменьшить (е)
После выполнения указанной коммутативной и ассоциативной двоичной операции возвращается элемент в СДР. В следующем примере мы импортируем пакет add из оператора и применяем его к ‘num’, чтобы выполнить простую операцию добавления.
----------------------------------------reduce.py---------------------------------------
from pyspark import SparkContext
from operator import add
sc = SparkContext("local", "Reduce app")
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print "Adding all the elements -> %i" % (adding)
----------------------------------------reduce.py---------------------------------------
Команда — Команда для уменьшения (f) —
$SPARK_HOME/bin/spark-submit reduce.py
Выходные данные — выходные данные вышеупомянутой команды —
Adding all the elements -> 15
присоединиться (другое, numPartitions = Нет)
Он возвращает RDD с парой элементов с соответствующими ключами и всеми значениями для этого конкретного ключа. В следующем примере есть две пары элементов в двух разных RDD. После объединения этих двух RDD мы получаем RDD с элементами, имеющими совпадающие ключи и их значения.
----------------------------------------join.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Join app")
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print "Join RDD -> %s" % (final)
----------------------------------------join.py---------------------------------------
Команда — Команда для объединения (другое, numPartitions = None) является —
$SPARK_HOME/bin/spark-submit join.py
Выходные данные — выход для вышеуказанной команды —
Join RDD -> [
('spark', (1, 2)),
('hadoop', (4, 5))
]
Кэш ()
Сохраните этот RDD с уровнем хранения по умолчанию (MEMORY_ONLY). Вы также можете проверить, кэшируется ли RDD или нет.
----------------------------------------cache.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Cache app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words.cache()
caching = words.persist().is_cached
print "Words got chached > %s" % (caching)
----------------------------------------cache.py---------------------------------------
Команда — команда для cache () —
$SPARK_HOME/bin/spark-submit cache.py
Выходные данные — выход для вышеуказанной программы —
Words got cached -> True
Это были некоторые из наиболее важных операций, выполняемых в PySpark RDD.
PySpark — Трансляция и Аккумулятор
Для параллельной обработки Apache Spark использует общие переменные. Копия общей переменной отправляется на каждый узел кластера, когда драйвер отправляет задачу исполнителю в кластере, чтобы ее можно было использовать для выполнения задач.
Apache Spark поддерживает два типа общих переменных:
- Broadcast
- аккумуляторный
Позвольте нам понять их в деталях.
Broadcast
Широковещательные переменные используются для сохранения копии данных на всех узлах. Эта переменная кэшируется на всех машинах и не отправляется на машины с задачами. Следующий блок кода содержит подробные данные о классе Broadcast для PySpark.
class pyspark.Broadcast ( sc = None, value = None, pickle_registry = None, path = None )
В следующем примере показано, как использовать переменную Broadcast. Переменная Broadcast имеет атрибут value, который хранит данные и используется для возврата широковещательного значения.
----------------------------------------broadcast.py--------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Broadcast app")
words_new = sc.broadcast(["scala", "java", "hadoop", "spark", "akka"])
data = words_new.value
print "Stored data -> %s" % (data)
elem = words_new.value[2]
print "Printing a particular element in RDD -> %s" % (elem)
----------------------------------------broadcast.py--------------------------------------
Команда — Команда для широковещательной переменной выглядит следующим образом —
$SPARK_HOME/bin/spark-submit broadcast.py
Выход — Выход для следующей команды приведен ниже.
Stored data -> [ 'scala', 'java', 'hadoop', 'spark', 'akka' ] Printing a particular element in RDD -> hadoop
аккумуляторный
Аккумуляторные переменные используются для агрегирования информации посредством ассоциативных и коммутативных операций. Например, вы можете использовать аккумулятор для операции с суммой или счетчиков (в MapReduce). В следующем блоке кода содержатся сведения о классе Accumulator для PySpark.
class pyspark.Accumulator(aid, value, accum_param)
В следующем примере показано, как использовать переменную Accumulator. У переменной Accumulator есть атрибут с именем value, аналогичный тому, который имеет широковещательная переменная. Он хранит данные и используется для возврата значения аккумулятора, но может использоваться только в программе драйвера.
В этом примере переменная аккумулятора используется несколькими рабочими и возвращает накопленное значение.
----------------------------------------accumulator.py------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Accumulator app")
num = sc.accumulator(10)
def f(x):
global num
num+=x
rdd = sc.parallelize([20,30,40,50])
rdd.foreach(f)
final = num.value
print "Accumulated value is -> %i" % (final)
----------------------------------------accumulator.py------------------------------------
Команда — Команда для переменной аккумулятора выглядит следующим образом:
$SPARK_HOME/bin/spark-submit accumulator.py
Выходные данные — выходные данные для вышеуказанной команды приведены ниже.
Accumulated value is -> 150
PySpark — SparkConf
Чтобы запустить приложение Spark на локальном / кластере, вам нужно установить несколько конфигураций и параметров, в этом SparkConf помогает. Он предоставляет конфигурации для запуска приложения Spark. Следующий блок кода содержит подробную информацию о классе SparkConf для PySpark.
class pyspark.SparkConf ( loadDefaults = True, _jvm = None, _jconf = None )
Сначала мы создадим объект SparkConf с помощью SparkConf (), который будет загружать значения из spark. * Свойства системы Java также. Теперь вы можете устанавливать различные параметры, используя объект SparkConf, и их параметры будут иметь приоритет над системными свойствами.
В классе SparkConf есть методы установки, которые поддерживают цепочку. Например, вы можете написать conf.setAppName («Приложение PySpark»). SetMaster («локальный») . Как только мы передаем объект SparkConf в Apache Spark, он не может быть изменен любым пользователем.
Ниже приведены некоторые из наиболее часто используемых атрибутов SparkConf.
-
set (ключ, значение) — установить свойство конфигурации.
-
setMaster (значение) — установить главный URL.
-
setAppName (значение) — установить имя приложения.
-
get (key, defaultValue = None) — получить значение конфигурации ключа.
-
setSparkHome (value) — установить путь установки Spark на рабочих узлах.
set (ключ, значение) — установить свойство конфигурации.
setMaster (значение) — установить главный URL.
setAppName (значение) — установить имя приложения.
get (key, defaultValue = None) — получить значение конфигурации ключа.
setSparkHome (value) — установить путь установки Spark на рабочих узлах.
Давайте рассмотрим следующий пример использования SparkConf в программе PySpark. В этом примере мы устанавливаем имя приложения spark как PySpark App и задаем основной URL-адрес для приложения spark → spark: // master: 7077 .
Следующий блок кода содержит строки: когда они добавляются в файл Python, он устанавливает основные конфигурации для запуска приложения PySpark.
---------------------------------------------------------------------------------------
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("PySpark App").setMaster("spark://master:7077")
sc = SparkContext(conf=conf)
---------------------------------------------------------------------------------------
PySpark — SparkFiles
В Apache Spark вы можете загружать свои файлы с помощью sc.addFile (sc — ваш SparkContext по умолчанию) и получать путь к работнику с помощью SparkFiles.get . Таким образом, SparkFiles разрешает пути к файлам, добавляемым через SparkContext.addFile () .
SparkFiles содержат следующие методы класса —
- получить (имя файла)
- getrootdirectory ()
Позвольте нам понять их в деталях.
получить (имя файла)
Он указывает путь к файлу, который добавляется через SparkContext.addFile ().
getrootdirectory ()
Он указывает путь к корневому каталогу, который содержит файл, который добавляется через SparkContext.addFile ().
----------------------------------------sparkfile.py------------------------------------
from pyspark import SparkContext
from pyspark import SparkFiles
finddistance = "/home/hadoop/examples_pyspark/finddistance.R"
finddistancename = "finddistance.R"
sc = SparkContext("local", "SparkFile App")
sc.addFile(finddistance)
print "Absolute Path -> %s" % SparkFiles.get(finddistancename)
----------------------------------------sparkfile.py------------------------------------
Команда — Команда выглядит следующим образом —
$SPARK_HOME/bin/spark-submit sparkfiles.py
Выходные данные — выход для вышеуказанной команды —
Absolute Path -> /tmp/spark-f1170149-af01-4620-9805-f61c85fecee4/userFiles-641dfd0f-240b-4264-a650-4e06e7a57839/finddistance.R
PySpark — StorageLevel
StorageLevel решает, как следует хранить RDD. В Apache Spark StorageLevel решает, должен ли RDD храниться в памяти или на диске, или и то, и другое. Он также решает, следует ли сериализовать RDD и реплицировать ли разделы RDD.
Следующий блок кода имеет определение класса StorageLevel —
class pyspark.StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication = 1)
Теперь, чтобы выбрать хранилище RDD, существуют разные уровни хранения, которые приведены ниже:
-
DISK_ONLY = StorageLevel (True, False, False, False, 1)
-
DISK_ONLY_2 = StorageLevel (True, False, False, False, 2)
-
MEMORY_AND_DISK = StorageLevel (True, True, False, False, 1)
-
MEMORY_AND_DISK_2 = StorageLevel (True, True, False, False, 2)
-
MEMORY_AND_DISK_SER = StorageLevel (True, True, False, False, 1)
-
MEMORY_AND_DISK_SER_2 = StorageLevel (True, True, False, False, 2)
-
MEMORY_ONLY = StorageLevel (False, True, False, False, 1)
-
MEMORY_ONLY_2 = StorageLevel (False, True, False, False, 2)
-
MEMORY_ONLY_SER = StorageLevel (False, True, False, False, 1)
-
MEMORY_ONLY_SER_2 = StorageLevel (False, True, False, False, 2)
-
OFF_HEAP = StorageLevel (True, True, True, False, 1)
DISK_ONLY = StorageLevel (True, False, False, False, 1)
DISK_ONLY_2 = StorageLevel (True, False, False, False, 2)
MEMORY_AND_DISK = StorageLevel (True, True, False, False, 1)
MEMORY_AND_DISK_2 = StorageLevel (True, True, False, False, 2)
MEMORY_AND_DISK_SER = StorageLevel (True, True, False, False, 1)
MEMORY_AND_DISK_SER_2 = StorageLevel (True, True, False, False, 2)
MEMORY_ONLY = StorageLevel (False, True, False, False, 1)
MEMORY_ONLY_2 = StorageLevel (False, True, False, False, 2)
MEMORY_ONLY_SER = StorageLevel (False, True, False, False, 1)
MEMORY_ONLY_SER_2 = StorageLevel (False, True, False, False, 2)
OFF_HEAP = StorageLevel (True, True, True, False, 1)
Давайте рассмотрим следующий пример StorageLevel, где мы используем уровень хранения MEMORY_AND_DISK_2, что означает , что разделы RDD будут иметь репликацию 2.
------------------------------------storagelevel.py------------------------------------- from pyspark import SparkContext import pyspark sc = SparkContext ( "local", "storagelevel app" ) rdd1 = sc.parallelize([1,2]) rdd1.persist( pyspark.StorageLevel.MEMORY_AND_DISK_2 ) rdd1.getStorageLevel() print(rdd1.getStorageLevel()) ------------------------------------storagelevel.py-------------------------------------
Команда — Команда выглядит следующим образом —
$SPARK_HOME/bin/spark-submit storagelevel.py
Выходные данные — выходные данные для вышеуказанной команды приведены ниже —
Disk Memory Serialized 2x Replicated
PySpark — MLlib
Apache Spark предлагает API для машинного обучения под названием MLlib . PySpark также имеет этот API машинного обучения на Python. Он поддерживает различные виды алгоритмов, которые упомянуты ниже —
-
mllib.classification — пакет spark.mllib поддерживает различные методы для двоичной классификации, мультиклассовой классификации и регрессионного анализа. Некоторые из самых популярных алгоритмов в классификации — Случайный Лес, Наивный Байес, Дерево Решений и т. Д.
-
mllib.clustering — кластеризация — это проблема обучения без присмотра, при которой вы стремитесь группировать подмножества сущностей друг с другом, основываясь на некотором понятии сходства.
-
mllib.fpm — Частое сопоставление с образцом — это добыча частых элементов, наборов элементов, подпоследовательностей или других подструктур, которые обычно являются одними из первых шагов для анализа крупномасштабного набора данных. Это была активная тема исследования в области интеллектуального анализа данных в течение многих лет.
-
mllib.linalg — MLlib утилиты для линейной алгебры.
-
mllib.recommendation — Совместная фильтрация обычно используется для рекомендательных систем. Эти методы направлены на заполнение пропущенных записей в матрице ассоциации элементов пользователя.
-
spark.mllib — в настоящее время поддерживает совместную фильтрацию на основе моделей, в которой пользователи и продукты описываются небольшим набором скрытых факторов, которые можно использовать для прогнозирования пропущенных записей. spark.mllib использует алгоритм Alternating Least Squares (ALS) для изучения этих скрытых факторов.
-
mllib.regression — Линейная регрессия относится к семейству алгоритмов регрессии. Цель регрессии — найти взаимосвязи и зависимости между переменными. Интерфейс для работы с моделями линейной регрессии и сводками моделей аналогичен случаю логистической регрессии.
mllib.classification — пакет spark.mllib поддерживает различные методы для двоичной классификации, мультиклассовой классификации и регрессионного анализа. Некоторые из самых популярных алгоритмов в классификации — Случайный Лес, Наивный Байес, Дерево Решений и т. Д.
mllib.clustering — кластеризация — это проблема обучения без присмотра, при которой вы стремитесь группировать подмножества сущностей друг с другом, основываясь на некотором понятии сходства.
mllib.fpm — Частое сопоставление с образцом — это добыча частых элементов, наборов элементов, подпоследовательностей или других подструктур, которые обычно являются одними из первых шагов для анализа крупномасштабного набора данных. Это была активная тема исследования в области интеллектуального анализа данных в течение многих лет.
mllib.linalg — MLlib утилиты для линейной алгебры.
mllib.recommendation — Совместная фильтрация обычно используется для рекомендательных систем. Эти методы направлены на заполнение пропущенных записей в матрице ассоциации элементов пользователя.
spark.mllib — в настоящее время поддерживает совместную фильтрацию на основе моделей, в которой пользователи и продукты описываются небольшим набором скрытых факторов, которые можно использовать для прогнозирования пропущенных записей. spark.mllib использует алгоритм Alternating Least Squares (ALS) для изучения этих скрытых факторов.
mllib.regression — Линейная регрессия относится к семейству алгоритмов регрессии. Цель регрессии — найти взаимосвязи и зависимости между переменными. Интерфейс для работы с моделями линейной регрессии и сводками моделей аналогичен случаю логистической регрессии.
Существуют и другие алгоритмы, классы и функции, также входящие в состав пакета mllib. На данный момент давайте разберемся с демонстрацией на pyspark.mllib .
В следующем примере показана совместная фильтрация с использованием алгоритма ALS для построения модели рекомендаций и оценки ее по данным обучения.
Используется набор данных — test.data
1,1,5.0 1,2,1.0 1,3,5.0 1,4,1.0 2,1,5.0 2,2,1.0 2,3,5.0 2,4,1.0 3,1,1.0 3,2,5.0 3,3,1.0 3,4,5.0 4,1,1.0 4,2,5.0 4,3,1.0 4,4,5.0
--------------------------------------recommend.py----------------------------------------
from __future__ import print_function
from pyspark import SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
if __name__ == "__main__":
sc = SparkContext(appName="Pspark mllib Example")
data = sc.textFile("test.data")
ratings = data.map(lambda l: l.split(','))\
.map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
# Build the recommendation model using Alternating Least Squares
rank = 10
numIterations = 10
model = ALS.train(ratings, rank, numIterations)
# Evaluate the model on training data
testdata = ratings.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
ratesAndPreds = ratings.map(lambda r: ((r[0], r[1]), r[2])).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).mean()
print("Mean Squared Error = " + str(MSE))
# Save and load model
model.save(sc, "target/tmp/myCollaborativeFilter")
sameModel = MatrixFactorizationModel.load(sc, "target/tmp/myCollaborativeFilter")
--------------------------------------recommend.py----------------------------------------
Команда — Команда будет следующей —
$SPARK_HOME/bin/spark-submit recommend.py
Выходные данные — выходные данные вышеупомянутой команды будут —
Mean Squared Error = 1.20536041839e-05
PySpark — Сериализаторы
Сериализация используется для настройки производительности в Apache Spark. Все данные, которые отправляются по сети или записываются на диск или сохраняются в памяти, должны быть сериализованы. Сериализация играет важную роль в дорогостоящих операциях.
PySpark поддерживает пользовательские сериализаторы для настройки производительности. PySpark поддерживает следующие два сериализатора:
MarshalSerializer
Сериализует объекты, используя Python’s Marshal Serializer. Этот сериализатор работает быстрее, чем PickleSerializer, но поддерживает меньшее количество типов данных.
class pyspark.MarshalSerializer
PickleSerializer
Сериализует объекты с помощью Python Serializer. Этот сериализатор поддерживает практически любой объект Python, но может быть не так быстр, как более специализированные сериализаторы.
class pyspark.PickleSerializer
Давайте посмотрим на пример сериализации PySpark. Здесь мы сериализуем данные, используя MarshalSerializer.
--------------------------------------serializing.py-------------------------------------
from pyspark.context import SparkContext
from pyspark.serializers import MarshalSerializer
sc = SparkContext("local", "serialization app", serializer = MarshalSerializer())
print(sc.parallelize(list(range(1000))).map(lambda x: 2 * x).take(10))
sc.stop()
--------------------------------------serializing.py-------------------------------------
Команда — Команда выглядит следующим образом —
$SPARK_HOME/bin/spark-submit serializing.py
Выходные данные — выходные данные вышеупомянутой команды —