Чанкинг — это процесс группировки похожих слов в зависимости от природы слова. В приведенном ниже примере мы определяем грамматику, по которой должен генерироваться фрагмент. Грамматика предлагает последовательность фраз, таких как существительные и прилагательные и т. Д., Которые будут использоваться при создании фрагментов. Графический вывод кусков показан ниже.
import nltk sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"), ("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")] grammar = "NP: {? * }" cp = nltk.RegexpParser(grammar) result = cp.parse(sentence) print(result) result.draw()
Когда мы запускаем вышеуказанную программу, мы получаем следующий вывод:
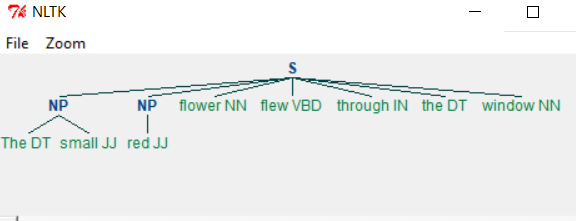
Изменяя грамматику, мы получаем другой вывод, как показано ниже.
import nltk sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"), ("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")] grammar = "NP: {
chunkprofile
= nltk.RegexpParser(grammar)result = chunkprofile.parse(sentence)
print(result)
result.draw()
Когда мы запускаем вышеуказанную программу, мы получаем следующий вывод:
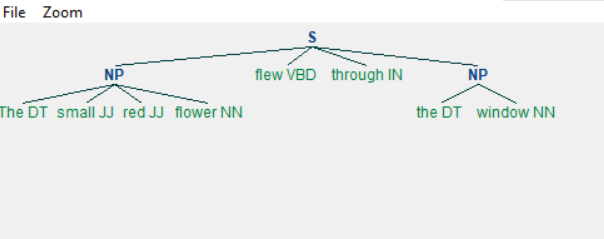
судорожно кашляющий
Chinking — это процесс удаления последовательности токенов из чанка. Если последовательность токенов появляется в середине фрагмента, эти маркеры удаляются, оставляя два фрагмента там, где они уже присутствовали.
import nltk sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"), ("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")] grammar = r""" NP: {<.*>+} # Chunk everything }+{ # Chink sequences of JJ and NN """ chunkprofile = nltk.RegexpParser(grammar) result = chunkprofile.parse(sentence) print(result) result.draw()
Когда мы запускаем вышеуказанную программу, мы получаем следующий вывод:
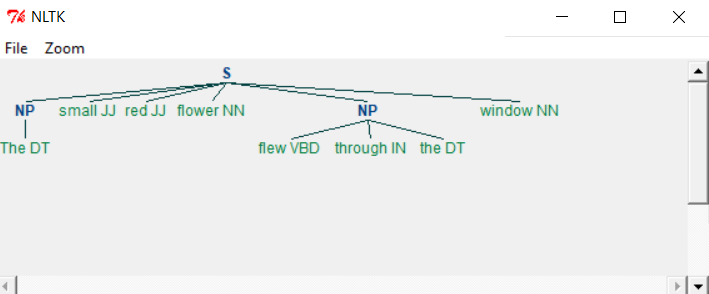
Как вы можете видеть, части, соответствующие критериям в грамматике, исключены из фраз существительных как отдельные куски. Этот процесс извлечения текста, не входящего в требуемый блок, называется циклом.