В контексте хранения данных сериализация — это процесс преобразования структур данных или состояния объекта в формат, который может быть сохранен (например, в буфере файла или памяти) или передан и восстановлен позже.
При сериализации объект преобразуется в формат, который можно сохранить, чтобы иметь возможность десериализовать его позже и воссоздать исходный объект из сериализованного формата.
Соленый огурец
Pickling — это процесс, посредством которого иерархия объектов Python преобразуется в поток байтов (обычно не читаемый человеком) для записи в файл, это также называется сериализацией. Разборка — обратная операция, при которой поток байтов преобразуется обратно в рабочую иерархию объектов Python.
Рассол — это самый простой в эксплуатации способ хранения объекта. Модуль Python Pickle — это объектно-ориентированный способ хранения объектов непосредственно в специальном формате хранения.
Что оно может делать?
- Pickle может очень легко хранить и воспроизводить словари и списки.
- Сохраняет атрибуты объекта и восстанавливает их обратно в то же состояние.
Что рассол не может сделать?
- Это не сохраняет код объекта. Только это атрибуты значений.
- Он не может хранить файловые дескрипторы или сокеты подключения.
Короче говоря, можно сказать, что выборка — это способ хранения и извлечения переменных данных в файлы и из них, где переменные могут быть списками, классами и т. Д.
Чтобы засолить что-то, вы должны —
- импортный рассол
- Записать переменную в файл, что-то вроде
pickle.dump(mystring, outfile, protocol),
где протокол 3-го аргумента является необязательным.
Импортный рассол
Записать переменную в файл, что-то вроде
myString = pickle.load(inputfile)
методы
Интерфейс pickle предоставляет четыре различных метода.
-
dump () — Метод dump () сериализуется в открытый файл (файлоподобный объект).
-
dumps () — Сериализует в строку
-
load () — Десериализуется из открытого объекта.
-
load () — Десериализует из строки.
dump () — Метод dump () сериализуется в открытый файл (файлоподобный объект).
dumps () — Сериализует в строку
load () — Десериализуется из открытого объекта.
load () — Десериализует из строки.
На основе вышеописанной процедуры ниже приведен пример «травления».
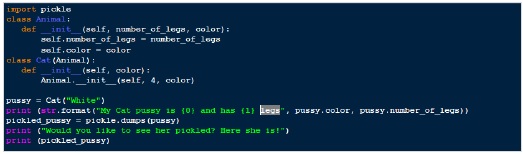
Выход
My Cat pussy is White and has 4 legs Would you like to see her pickled? Here she is! b'\x80\x03c__main__\nCat\nq\x00)\x81q\x01}q\x02(X\x0e\x00\x00\x00number_of_legsq\x03K\x04X\x05\x00\x00\x00colorq\x04X\x05\x00\x00\x00Whiteq\x05ub.'
Итак, в приведенном выше примере мы создали экземпляр класса Cat, а затем выбрали его, преобразовав наш экземпляр «Cat» в простой массив байтов.
Таким образом, мы можем легко сохранить массив байтов в двоичном файле или в поле базы данных и позже восстановить его обратно в исходную форму из нашей поддержки хранилища.
Также, если вы хотите создать файл с засоленным объектом, вы можете использовать метод dump () (вместо dumps * () * one), передавая также открытый двоичный файл, и результат засоления будет автоматически сохраняться в файле.
[….] binary_file = open(my_pickled_Pussy.bin', mode='wb') my_pickled_Pussy = pickle.dump(Pussy, binary_file) binary_file.close()
Unpickling
Процесс, который принимает двоичный массив и преобразует его в иерархию объектов, называется расщеплением.
Процесс расщепления выполняется с помощью функции load () модуля pickle и возвращает полную иерархию объектов из простого массива байтов.
Давайте использовать функцию загрузки в нашем предыдущем примере.
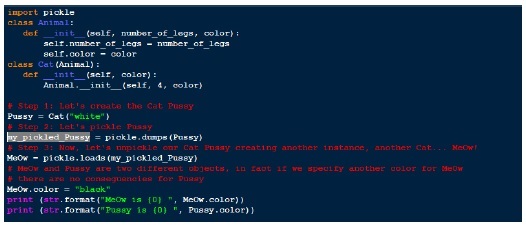
Выход
MeOw is black Pussy is white
JSON
JSON (JavaScript Object Notation) является частью стандартной библиотеки Python и представляет собой легкий формат обмена данными. Людям легко читать и писать. Это легко разобрать и сгенерировать.
Из-за своей простоты JSON — это способ, которым мы храним и обмениваемся данными, что достигается с помощью синтаксиса JSON и используется во многих веб-приложениях. Так как он находится в удобочитаемом формате, и это может быть одной из причин его использования при передаче данных, в дополнение к его эффективности при работе с API.
Пример данных в формате JSON:
{"EmployID": 40203, "Name": "Zack", "Age":54, "isEmployed": True}
Python упрощает работу с файлами Json. Для этой цели используется модуль JSON. Этот модуль должен быть включен (встроен) в вашу установку Python.
Итак, давайте посмотрим, как мы можем преобразовать словарь Python в JSON и записать его в текстовый файл.
JSON в Python
Чтение JSON означает преобразование JSON в значение (объект) Python. Библиотека json анализирует JSON в словарь или список в Python. Для этого мы используем функцию load () (загрузка из строки) следующим образом:

Выход

Ниже приведен пример файла JSON,
data1.json {"menu": { "id": "file", "value": "File", "popup": { "menuitem": [ {"value": "New", "onclick": "CreateNewDoc()"}, {"value": "Open", "onclick": "OpenDoc()"}, {"value": "Close", "onclick": "CloseDoc()"} ] } }}
Выше контент (Data1.json) выглядит как обычный словарь. Мы можем использовать pickle для хранения этого файла, но вывод его не в удобочитаемой форме.
JSON (Java Script Object Notification) — очень простой формат, и это одна из причин его популярности. Теперь давайте посмотрим на вывод json через программу ниже.
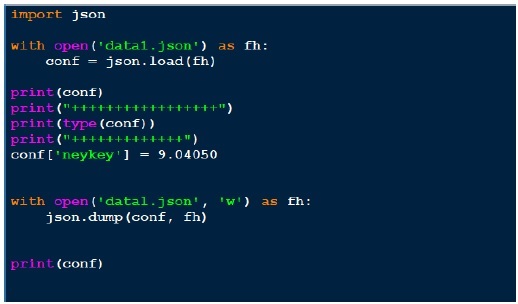
Выход
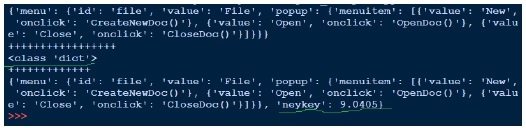
Выше мы открываем файл json (data1.json) для чтения, получаем обработчик файла и переходим к json.load и возвращаем объект. Когда мы пытаемся напечатать вывод объекта, он такой же, как файл json. Хотя типом объекта является словарь, он выступает в качестве объекта Python. Запись в JSON проста, как мы видели этот рассол. Выше мы загружаем файл json, добавляем еще одну пару ключ-значение и записываем ее обратно в тот же файл json. Теперь, если мы видим data1.json, он выглядит иначе. То есть не в том формате, в котором мы видели ранее.
Чтобы наш вывод выглядел одинаково (удобочитаемый формат), добавьте пару аргументов в нашу последнюю строку программы,
json.dump(conf, fh, indent = 4, separators = (‘,’, ‘: ‘))
Так же, как и pickle, мы можем напечатать строку с дампами и загрузить с нагрузками. Ниже приведен пример этого,
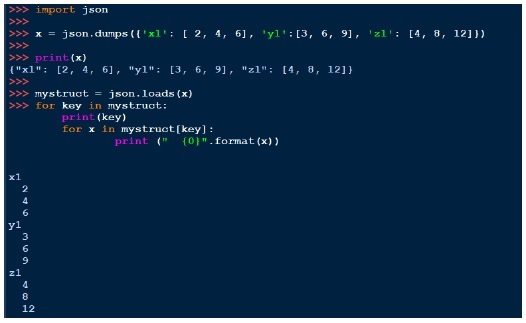
YAML
YAML может быть наиболее дружественным стандартом сериализации данных для всех языков программирования.
Python модуль yaml называется pyaml
YAML является альтернативой JSON —
-
Читаемый человеком код — YAML настолько удобочитаемый формат, что даже его содержание на первой странице отображается в YAML, чтобы подчеркнуть это.
-
Компактный код — в YAML мы используем отступы для пробелов, чтобы обозначить структуру, а не скобки.
-
Синтаксис для реляционных данных — для внутренних ссылок мы используем якоря (&) и псевдонимы (*).
-
Одной из областей, где он широко используется, является просмотр / редактирование структур данных — например, файлов конфигурации, дампов во время отладки и заголовков документов.
Читаемый человеком код — YAML настолько удобочитаемый формат, что даже его содержание на первой странице отображается в YAML, чтобы подчеркнуть это.
Компактный код — в YAML мы используем отступы для пробелов, чтобы обозначить структуру, а не скобки.
Синтаксис для реляционных данных — для внутренних ссылок мы используем якоря (&) и псевдонимы (*).
Одной из областей, где он широко используется, является просмотр / редактирование структур данных — например, файлов конфигурации, дампов во время отладки и заголовков документов.
Установка YAML
Поскольку yaml не является встроенным модулем, мы должны установить его вручную. Лучший способ установить yaml на Windows-машину — через pip. Запустите команду ниже на вашем терминале Windows, чтобы установить yaml,
pip install pyaml (Windows machine) sudo pip install pyaml (*nix and Mac)
При выполнении команды выше, на экране отобразится что-то вроде ниже, в зависимости от текущей последней версии.
Collecting pyaml Using cached pyaml-17.12.1-py2.py3-none-any.whl Collecting PyYAML (from pyaml) Using cached PyYAML-3.12.tar.gz Installing collected packages: PyYAML, pyaml Running setup.py install for PyYAML ... done Successfully installed PyYAML-3.12 pyaml-17.12.1
Чтобы проверить это, перейдите в оболочку Python и импортируйте модуль yaml, импортируйте yaml, если ошибки не обнаружены, мы можем сказать, что установка прошла успешно.
После установки pyaml, давайте посмотрим на код ниже,
script_yaml1.py
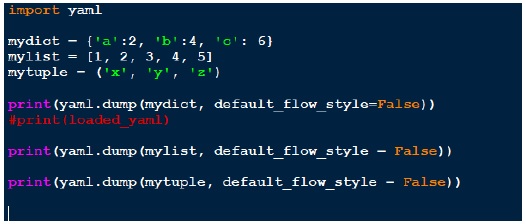
Выше мы создали три разные структуры данных, словарь, список и кортеж. На каждой структуре мы делаем yaml.dump. Важным моментом является то, как вывод отображается на экране.
Выход
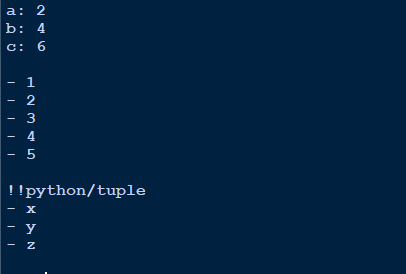
Вывод словаря выглядит чисто .ie. ключ: значение.
Пустое пространство для разделения разных объектов.
Список помечается тире (-)
Кортеж указывается сначала с помощью !! Python / tuple, а затем в том же формате, что и списки.
Загрузка файла yaml
Допустим, у меня есть один файл yaml, который содержит
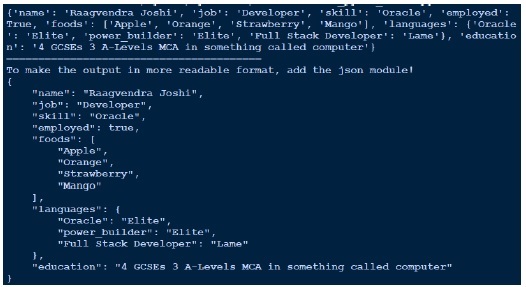
--- # An employee record name: Raagvendra Joshi job: Developer skill: Oracle employed: True foods: - Apple - Orange - Strawberry - Mango languages: Oracle: Elite power_builder: Elite Full Stack Developer: Lame education: 4 GCSEs 3 A-Levels MCA in something called com
Теперь давайте напишем код для загрузки этого файла yaml через функцию yaml.load. Ниже приведен код для того же.
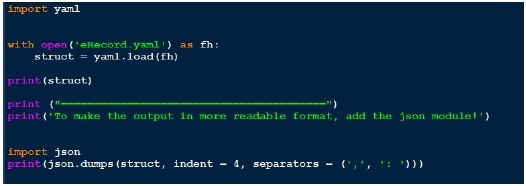
Поскольку выходные данные не выглядят так хорошо читаемыми, я в конце их преттифицирую, используя json. Сравните полученный результат и реальный файл yaml, который у нас есть.
Выход
Одним из наиболее важных аспектов разработки программного обеспечения является отладка. В этом разделе мы увидим различные способы отладки Python с помощью встроенного отладчика или сторонних отладчиков.
PDB — отладчик Python
Модуль PDB поддерживает настройку точек останова. Точка останова — это намеренная пауза программы, где вы можете получить больше информации о состоянии программы.
Чтобы установить точку останова, вставьте строку
pdb.set_trace()
пример
pdb_example1.py import pdb x = 9 y = 7 pdb.set_trace() total = x + y pdb.set_trace()
Мы вставили несколько точек останова в эту программу. Программа будет останавливаться на каждой точке останова (pdb.set_trace ()). Для просмотра содержимого переменных просто введите имя переменной.
c:\Python\Python361>Python pdb_example1.py > c:\Python\Python361\pdb_example1.py(8)<module>() -> total = x + y (Pdb) x 9 (Pdb) y 7 (Pdb) total *** NameError: name 'total' is not defined (Pdb)
Нажмите c или продолжите, чтобы продолжить выполнение программ до следующей точки останова.
(Pdb) c --Return-- > c:\Python\Python361\pdb_example1.py(8)<module>()->None -> total = x + y (Pdb) total 16
В конце концов вам нужно будет отлаживать гораздо большие программы — программы, которые используют подпрограммы. И иногда проблема, которую вы пытаетесь найти, лежит внутри подпрограммы. Рассмотрим следующую программу.
import pdb def squar(x, y): out_squared = x^2 + y^2 return out_squared if __name__ == "__main__": #pdb.set_trace() print (squar(4, 5))
Теперь при запуске вышеуказанной программы,
c:\Python\Python361>Python pdb_example2.py > c:\Python\Python361\pdb_example2.py(10)<module>() -> print (squar(4, 5)) (Pdb)
Мы можем использовать ? чтобы получить помощь, но стрелка указывает строку, которая должна быть выполнена. На этом этапе полезно нажать s, чтобы перейти в эту строку.
(Pdb) s --Call-- >c:\Python\Python361\pdb_example2.py(3)squar() -> def squar(x, y):
Это вызов функции. Если вы хотите узнать, где вы находитесь в вашем коде, попробуйте l —
(Pdb) l 1 import pdb 2 3 def squar(x, y): 4 -> out_squared = x^2 + y^2 5 6 return out_squared 7 8 if __name__ == "__main__": 9 pdb.set_trace() 10 print (squar(4, 5)) [EOF] (Pdb)
Вы можете нажать n, чтобы перейти к следующей строке. На данный момент вы находитесь внутри метода out_squared и имеете доступ к переменной, объявленной внутри функций .ie x и y.
(Pdb) x 4 (Pdb) y 5 (Pdb) x^2 6 (Pdb) y^2 7 (Pdb) x**2 16 (Pdb) y**2 25 (Pdb)
Таким образом, мы видим, что оператор ^ — это не то, что нам нужно, вместо этого нам нужно использовать оператор **, чтобы делать квадраты.
Таким образом, мы можем отлаживать нашу программу внутри функций / методов.
логирование
Модуль регистрации был частью стандартной библиотеки Python начиная с версии 2.3. Поскольку это встроенный модуль, все модули Python могут участвовать в ведении журнала, поэтому журнал нашего приложения может включать ваше собственное сообщение, интегрированное с сообщениями от стороннего модуля. Это обеспечивает большую гибкость и функциональность.
Преимущества ведения журнала
-
Ведение журнала диагностики — записывает события, связанные с работой приложения.
-
Журнал аудита — записывает события для бизнес-анализа.
Ведение журнала диагностики — записывает события, связанные с работой приложения.
Журнал аудита — записывает события для бизнес-анализа.
Сообщения пишутся и регистрируются на уровнях «серьезность» и минут
-
DEBUG (debug ()) — диагностические сообщения для разработки.
-
INFO (info ()) — стандартные сообщения о прогрессе.
-
WARNING (warning ()) — обнаружена несерьезная проблема.
-
ОШИБКА (error ()) — обнаружена ошибка, возможно, серьезная.
-
КРИТИЧЕСКИЙ (критический ()) — обычно фатальная ошибка (программа останавливается).
DEBUG (debug ()) — диагностические сообщения для разработки.
INFO (info ()) — стандартные сообщения о прогрессе.
WARNING (warning ()) — обнаружена несерьезная проблема.
ОШИБКА (error ()) — обнаружена ошибка, возможно, серьезная.
КРИТИЧЕСКИЙ (критический ()) — обычно фатальная ошибка (программа останавливается).
Давайте рассмотрим ниже простую программу,
import logging logging.basicConfig(level=logging.INFO) logging.debug('this message will be ignored') # This will not print logging.info('This should be logged') # it'll print logging.warning('And this, too') # It'll print
Выше мы регистрируем сообщения на уровне серьезности. Сначала мы импортируем модуль, вызываем basicConfig и устанавливаем уровень ведения журнала. Уровень, который мы установили выше, это ИНФО. Тогда у нас есть три различных оператора: оператор отладки, оператор информации и оператор предупреждения.
Вывод logging1.py
INFO:root:This should be logged WARNING:root:And this, too
Поскольку оператор info находится ниже оператора debug, мы не можем увидеть сообщение отладки. Чтобы получить оператор debug также в терминале вывода, все, что нам нужно изменить, — это уровень basicConfig.
logging.basicConfig(level = logging.DEBUG)
И в выводе мы можем видеть,
DEBUG:root:this message will be ignored INFO:root:This should be logged WARNING:root:And this, too
Также поведение по умолчанию означает, что если мы не установим какой-либо уровень ведения журнала, это предупреждение. Просто закомментируйте вторую строку из вышеприведенной программы и запустите код.
#logging.basicConfig(level = logging.DEBUG)
Выход
WARNING:root:And this, too
Python, встроенный в уровень ведения журнала, на самом деле является целым числом.
>>> import logging >>> >>> logging.DEBUG 10 >>> logging.CRITICAL 50 >>> logging.WARNING 30 >>> logging.INFO 20 >>> logging.ERROR 40 >>>
Мы также можем сохранить сообщения журнала в файл.
logging.basicConfig(level = logging.DEBUG, filename = 'logging.log')
Теперь все сообщения журнала будут отправляться в файл (logging.log) в текущем рабочем каталоге, а не на экран. Это гораздо лучший подход, так как он позволяет нам проводить пост-анализ полученных сообщений.
Мы также можем установить отметку даты с нашим сообщением журнала.
logging.basicConfig(level=logging.DEBUG, format = '%(asctime)s %(levelname)s:%(message)s')
Выход получится примерно так:
2018-03-08 19:30:00,066 DEBUG:this message will be ignored 2018-03-08 19:30:00,176 INFO:This should be logged 2018-03-08 19:30:00,201 WARNING:And this, too
Бенчмаркинг
Тестирование или профилирование в основном для проверки того, насколько быстро выполняется ваш код и где узкие места? Основная причина сделать это для оптимизации.
timeit
Python поставляется со встроенным модулем под названием timeit. Вы можете использовать его для определения времени небольших фрагментов кода. Модуль timeit использует функции времени, специфичные для платформы, так что вы получите максимально точные сроки.
Таким образом, это позволяет нам сравнивать две партии кода, взятые каждым, а затем оптимизировать сценарии для повышения производительности.
Модуль timeit имеет интерфейс командной строки, но его также можно импортировать.
Есть два способа вызвать скрипт. Давайте сначала воспользуемся сценарием, для этого запустим приведенный ниже код и увидим вывод.
import timeit
print ( 'by index: ', timeit.timeit(stmt = "mydict['c']", setup = "mydict = {'a':5, 'b':10, 'c':15}", number = 1000000))
print ( 'by get: ', timeit.timeit(stmt = 'mydict.get("c")', setup = 'mydict = {"a":5, "b":10, "c":15}', number = 1000000))
Выход
by index: 0.1809192126703489 by get: 0.6088525265034692
Выше мы используем два разных метода .ie by subscript и получаем доступ к значению ключа словаря. Мы выполняем оператор 1 миллион раз, поскольку он выполняется слишком быстро для очень маленьких данных. Теперь мы можем видеть доступ к индексу намного быстрее по сравнению с get. Мы можем запустить код многократно, и время выполнения будет немного отличаться, чтобы лучше понять.
Другой способ — запустить вышеуказанный тест в командной строке. Давай сделаем это,
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict['c']" 1000000 loops, best of 3: 0.187 usec per loop c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict.get('c')" 1000000 loops, best of 3: 0.659 usec per loop
Вышеуказанные выходные данные могут отличаться в зависимости от аппаратного обеспечения вашей системы и от того, какие приложения в настоящее время работают в вашей системе.
Ниже мы можем использовать модуль timeit, если мы хотим вызвать функцию. Как мы можем добавить несколько операторов внутри функции для тестирования.