Perl — Введение
Perl — это язык программирования общего назначения, изначально разработанный для работы с текстом, и теперь он используется для решения широкого круга задач, включая системное администрирование, веб-разработку, сетевое программирование, разработку графического интерфейса пользователя и многое другое.
Что такое Perl?
-
Perl — это стабильный кроссплатформенный язык программирования.
-
Хотя Perl официально не является аббревиатурой, но мало кто использовал его как Практическое извлечение и язык отчетов .
-
Он используется для критически важных проектов в государственном и частном секторах.
-
Perl — это программное обеспечение с открытым исходным кодом, лицензируемое по лицензии Artistic License или GNU General Public License (GPL) .
-
Perl был создан Ларри Уоллом.
-
Perl 1.0 был выпущен для alnet.comp.sources usenet в 1987 году.
-
На момент написания этого руководства последняя версия Perl была 5.16.2.
-
Perl указан в Оксфордском словаре английского языка .
Perl — это стабильный кроссплатформенный язык программирования.
Хотя Perl официально не является аббревиатурой, но мало кто использовал его как Практическое извлечение и язык отчетов .
Он используется для критически важных проектов в государственном и частном секторах.
Perl — это программное обеспечение с открытым исходным кодом, лицензируемое по лицензии Artistic License или GNU General Public License (GPL) .
Perl был создан Ларри Уоллом.
Perl 1.0 был выпущен для alnet.comp.sources usenet в 1987 году.
На момент написания этого руководства последняя версия Perl была 5.16.2.
Perl указан в Оксфордском словаре английского языка .
Журнал PC Magazine объявил Perl финалистом премии «Техническое совершенство» 1998 года в категории «Средства разработки».
Особенности Perl
-
Perl использует лучшие возможности других языков, таких как C, awk, sed, sh и BASIC.
-
Интерфейс интеграции базы данных Perls DBI поддерживает сторонние базы данных, включая Oracle, Sybase, Postgres, MySQL и другие.
-
Perl работает с HTML, XML и другими языками разметки.
-
Perl поддерживает Unicode.
-
Perl соответствует требованиям 2000 года.
-
Perl поддерживает как процедурное, так и объектно-ориентированное программирование.
-
Perl взаимодействует с внешними библиотеками C / C ++ через XS или SWIG.
-
Perl расширяемый. Существует более 20 000 сторонних модулей, доступных из всеобъемлющей сети архивов Perl ( CPAN ).
-
Интерпретатор Perl может быть встроен в другие системы.
Perl использует лучшие возможности других языков, таких как C, awk, sed, sh и BASIC.
Интерфейс интеграции базы данных Perls DBI поддерживает сторонние базы данных, включая Oracle, Sybase, Postgres, MySQL и другие.
Perl работает с HTML, XML и другими языками разметки.
Perl поддерживает Unicode.
Perl соответствует требованиям 2000 года.
Perl поддерживает как процедурное, так и объектно-ориентированное программирование.
Perl взаимодействует с внешними библиотеками C / C ++ через XS или SWIG.
Perl расширяемый. Существует более 20 000 сторонних модулей, доступных из всеобъемлющей сети архивов Perl ( CPAN ).
Интерпретатор Perl может быть встроен в другие системы.
Perl и Интернет
-
Perl был самым популярным языком веб-программирования из-за его возможностей манипулирования текстом и быстрого цикла разработки.
-
Perl широко известен как « клейкая лента Интернета ».
-
Perl может обрабатывать зашифрованные веб-данные, включая транзакции электронной торговли.
-
Perl может быть встроен в веб-серверы для ускорения обработки на 2000%.
-
Mod_perl в Perl позволяет веб-серверу Apache встраивать интерпретатор Perl.
-
Пакет Perl DBI облегчает интеграцию веб-базы данных.
Perl был самым популярным языком веб-программирования из-за его возможностей манипулирования текстом и быстрого цикла разработки.
Perl широко известен как « клейкая лента Интернета ».
Perl может обрабатывать зашифрованные веб-данные, включая транзакции электронной торговли.
Perl может быть встроен в веб-серверы для ускорения обработки на 2000%.
Mod_perl в Perl позволяет веб-серверу Apache встраивать интерпретатор Perl.
Пакет Perl DBI облегчает интеграцию веб-базы данных.
Perl интерпретируется
Perl является интерпретируемым языком, что означает, что ваш код может быть запущен как есть, без этапа компиляции, который создает непереносимую исполняемую программу.
Традиционные компиляторы конвертируют программы на машинный язык. Когда вы запускаете Perl-программу, она сначала компилируется в байт-код, который затем преобразуется (при запуске программы) в машинные инструкции. Так что это не совсем то же самое, что оболочки или Tcl, которые строго интерпретируются без промежуточного представления.
Это также не похоже на большинство версий C или C ++, которые компилируются непосредственно в машинно-зависимый формат. Это где-то посередине, вместе с Python и awk и файлами Eelcs .elc.
Perl — Окружающая среда
Прежде чем мы начнем писать наши программы на Perl, давайте разберемся, как настроить нашу среду Perl. Perl доступен на самых разных платформах —
- Unix (Solaris, Linux, FreeBSD, AIX, HP / UX, SunOS, IRIX и т. Д.)
- Win 9x / NT / 2000 /
- WinCE
- Макинтош (КПП, 68K)
- Солярис (x86, SPARC)
- OpenVMS
- Альфа (7.2 и позже)
- Symbian
- Debian GNU / kFreeBSD
- МирОС БСД
- И многое другое …
Это более вероятно, что на вашей системе будет установлен Perl. Просто попробуйте ввести в командной строке следующую команду:
$perl -v
Если на вашем компьютере установлен Perl, вы получите следующее сообщение:
This is perl 5, version 16, subversion 2 (v5.16.2) built for i686-linux Copyright 1987-2012, Larry Wall Perl may be copied only under the terms of either the Artistic License or the GNU General Public License, which may be found in the Perl 5 source kit. Complete documentation for Perl, including FAQ lists, should be found on this system using "man perl" or "perldoc perl". If you have access to the Internet, point your browser at http://www.perl.org/, the Perl Home Page.
Если Perl еще не установлен, перейдите к следующему разделу.
Получение установки Perl
Самый актуальный и актуальный исходный код, двоичные файлы, документация, новости и т. Д. Доступны на официальном сайте Perl.
Официальный сайт Perl — https://www.perl.org/
Вы можете скачать документацию по Perl со следующего сайта.
Веб-сайт документации Perl — https://perldoc.perl.org
Установить Perl
Распространение Perl доступно для самых разных платформ. Вам нужно скачать только двоичный код, подходящий для вашей платформы, и установить Perl.
Если двоичный код для вашей платформы недоступен, вам нужен компилятор C, чтобы скомпилировать исходный код вручную. Компиляция исходного кода обеспечивает большую гибкость с точки зрения выбора функций, которые требуются при установке.
Вот краткий обзор установки Perl на различных платформах.
Установка Unix и Linux
Вот простые шаги для установки Perl на машину Unix / Linux.
-
Откройте веб-браузер и перейдите по адресу https://www.perl.org/get.html.
-
Перейдите по ссылке, чтобы скачать сжатый исходный код, доступный для Unix / Linux.
-
Загрузите файл perl-5.xytar.gz и введите в командной строке следующие команды.
Откройте веб-браузер и перейдите по адресу https://www.perl.org/get.html.
Перейдите по ссылке, чтобы скачать сжатый исходный код, доступный для Unix / Linux.
Загрузите файл perl-5.xytar.gz и введите в командной строке следующие команды.
$tar -xzf perl-5.x.y.tar.gz $cd perl-5.x.y $./Configure -de $make $make test $make install
ПРИМЕЧАНИЕ. Здесь $ — это приглашение Unix, где вы вводите свою команду, поэтому убедитесь, что вы не вводите $ при вводе вышеупомянутых команд.
Это установит Perl в стандартном месте / usr / local / bin, а его библиотеки будут установлены в / usr / local / lib / perlXX , где XX — это версия Perl, которую вы используете.
Компиляция исходного кода после выполнения команды make займет некоторое время. После завершения установки вы можете выполнить команду perl -v в $ prompt, чтобы проверить установку perl. Если все хорошо, то будет отображаться сообщение, как мы показали выше.
Установка Windows
Вот шаги, чтобы установить Perl на машине Windows.
-
Перейдите по ссылке для установки Strawberry Perl в Windows http://strawberryperl.com
-
Загрузите 32-битную или 64-битную версию установки.
-
Запустите загруженный файл, дважды щелкнув его в проводнике Windows. Это вызывает мастер установки Perl, который действительно прост в использовании. Просто примите настройки по умолчанию, дождитесь окончания установки, и вы готовы к работе!
Перейдите по ссылке для установки Strawberry Perl в Windows http://strawberryperl.com
Загрузите 32-битную или 64-битную версию установки.
Запустите загруженный файл, дважды щелкнув его в проводнике Windows. Это вызывает мастер установки Perl, который действительно прост в использовании. Просто примите настройки по умолчанию, дождитесь окончания установки, и вы готовы к работе!
Установка Macintosh
Чтобы создать собственную версию Perl, вам понадобится make, который является частью инструментов разработчика Apples, обычно поставляемых с установочными DVD-дисками Mac OS. Вам не нужна последняя версия Xcode (за которую сейчас взимается плата) для установки make.
Вот простые шаги для установки Perl на компьютер Mac OS X.
-
Откройте веб-браузер и перейдите по адресу https://www.perl.org/get.html .
-
Перейдите по ссылке, чтобы загрузить сжатый исходный код, доступный для Mac OS X.
-
Загрузите файл perl-5.xytar.gz и введите в командной строке следующие команды.
Откройте веб-браузер и перейдите по адресу https://www.perl.org/get.html .
Перейдите по ссылке, чтобы загрузить сжатый исходный код, доступный для Mac OS X.
Загрузите файл perl-5.xytar.gz и введите в командной строке следующие команды.
$tar -xzf perl-5.x.y.tar.gz $cd perl-5.x.y $./Configure -de $make $make test $make install
Это установит Perl в стандартном месте / usr / local / bin, а его библиотеки будут установлены в / usr / local / lib / perlXX , где XX — это версия Perl, которую вы используете.
Запуск Perl
Ниже приведены различные способы запуска Perl.
Интерактивный переводчик
Вы можете ввести perl и сразу начать писать код в интерактивном интерпретаторе, запустив его из командной строки. Вы можете сделать это из Unix, DOS или любой другой системы, которая предоставляет вам интерпретатор командной строки или окно оболочки.
$perl -e <perl code> # Unix/Linux or C:>perl -e <perl code> # Windows/DOS
Вот список всех доступных параметров командной строки —
| Sr.No. | Вариант и описание |
|---|---|
| 1 |
-d [: отладчик] Запускает программу под отладчиком |
| 2 |
-Idirectory Определяет @ INC / # include каталог |
| 3 |
-T Позволяет портить чеки |
| 4 |
-t Позволяет портить предупреждения |
| 5 |
-U Позволяет небезопасные операции |
| 6 |
-w Включает много полезных предупреждений |
| 7 |
-W Включает все предупреждения |
| 8 |
-ИКС Отключает все предупреждения |
| 9 |
-э программа Запускает Perl-скрипт, отправленный как программа |
| 10 |
файл Запускает Perl-скрипт из заданного файла. |
-d [: отладчик]
Запускает программу под отладчиком
-Idirectory
Определяет @ INC / # include каталог
-T
Позволяет портить чеки
-t
Позволяет портить предупреждения
-U
Позволяет небезопасные операции
-w
Включает много полезных предупреждений
-W
Включает все предупреждения
-ИКС
Отключает все предупреждения
-э программа
Запускает Perl-скрипт, отправленный как программа
файл
Запускает Perl-скрипт из заданного файла.
Скрипт из командной строки
Скрипт Perl — это текстовый файл, в котором хранится код Perl, и его можно выполнить в командной строке, вызвав интерпретатор в вашем приложении, как показано ниже:
$perl script.pl # Unix/Linux or C:>perl script.pl # Windows/DOS
Интегрированная среда развития
Вы также можете запустить Perl из среды графического интерфейса пользователя (GUI). Все, что вам нужно, это приложение с графическим интерфейсом в вашей системе, которое поддерживает Perl. Вы можете скачать Padre, Perl IDE . Вы также можете использовать Eclipse Plugin EPIC — Perl Editor и IDE для Eclipse, если вы знакомы с Eclipse.
Прежде чем перейти к следующей главе, убедитесь, что ваша среда правильно настроена и работает идеально. Если вы не можете правильно настроить среду, вы можете обратиться за помощью к системному администратору.
Все примеры, приведенные в последующих главах, были выполнены с версией v5.16.2, доступной для разновидности CentOS в Linux.
Perl — обзор синтаксиса
Perl заимствует синтаксис и понятия из многих языков: awk, sed, C, Bourne Shell, Smalltalk, Lisp и даже английского. Однако между языками есть определенные различия. Эта глава предназначена для быстрого ознакомления с синтаксисом, ожидаемым в Perl.
Программа Perl состоит из последовательности объявлений и операторов, которые выполняются сверху вниз. Циклы, подпрограммы и другие управляющие структуры позволяют вам перемещаться внутри кода. Каждое простое утверждение должно заканчиваться точкой с запятой (;).
Perl — это язык свободной формы: вы можете форматировать и делать отступы так, как вам нравится. Пробельные символы служат в основном для разделения токенов, в отличие от таких языков, как Python, где он является важной частью синтаксиса, или Fortran, где он несущественен.
Первая Perl-программа
Программирование в интерактивном режиме
Вы можете использовать интерпретатор Perl с параметром -e в командной строке, который позволяет выполнять операторы Perl из командной строки. Давайте попробуем что-то в $ prompt следующим образом:
$perl -e 'print "Hello World\n"'
Это выполнение даст следующий результат —
Hello, world
Script Mode Программирование
Предполагая, что вы уже используете $ prompt, давайте откроем текстовый файл hello.pl с помощью редактора vi или vim и поместим следующие строки в ваш файл.
#!/usr/bin/perl # This will print "Hello, World" print "Hello, world\n";
Здесь / usr / bin / perl является действительным двоичным файлом интерпретатора perl. Перед выполнением сценария обязательно измените режим файла сценария и дайте ему привилегию на выполнение. Обычно настройка 0755 работает отлично, и, наконец, вы выполняете приведенный выше сценарий следующим образом:
$chmod 0755 hello.pl $./hello.pl
Это выполнение даст следующий результат —
Hello, world
Вы можете использовать скобки для аргументов функций или опустить их по своему вкусу. Они требуются только время от времени для выяснения вопросов приоритета. Следующие два утверждения дают одинаковый результат.
print("Hello, world\n"); print "Hello, world\n";
Расширение файла Perl
Скрипт Perl может быть создан внутри любой обычной программы простого текстового редактора. Для каждого типа платформы доступно несколько программ. Существует множество программ для программистов, доступных для скачивания в Интернете.
В соответствии с соглашением Perl файл Perl должен быть сохранен с расширением .pl или .PL, чтобы быть распознанным как работающий сценарий Perl. Имена файлов могут содержать цифры, символы и буквы, но не должны содержать пробелов. Используйте подчеркивание (_) в местах пробелов.
Комментарии в Perl
Комментарии на любом языке программирования являются друзьями разработчиков. Комментарии могут использоваться, чтобы сделать программу удобной для пользователя, и они просто пропускаются интерпретатором, не влияя на функциональность кода. Например, в приведенной выше программе строка, начинающаяся с hash #, является комментарием.
Проще говоря, комментарии в Perl начинаются с символа хеша и заканчиваются до конца строки —
# This is a comment in perl
Строки, начинающиеся с =, интерпретируются как начало раздела встроенной документации (pod), а все последующие строки до следующего = cut игнорируются компилятором. Ниже приведен пример —
#!/usr/bin/perl # This is a single line comment print "Hello, world\n"; =begin comment This is all part of multiline comment. You can use as many lines as you like These comments will be ignored by the compiler until the next =cut is encountered. =cut
Это даст следующий результат —
Hello, world
Пробелы в Perl
Программа Perl не заботится о пробелах. Следующая программа работает отлично —
#!/usr/bin/perl print "Hello, world\n";
Но если пробелы находятся внутри строк в кавычках, они будут напечатаны как есть. Например —
#!/usr/bin/perl # This would print with a line break in the middle print "Hello world\n";
Это даст следующий результат —
Hello
world
Все типы пробелов, такие как пробелы, символы табуляции, новые строки и т. Д., Эквивалентны для интерпретатора, если они используются вне кавычек. Строка, содержащая только пробел, возможно, с комментарием, называется пустой строкой, и Perl полностью игнорирует ее.
Одиночные и двойные кавычки в Perl
Вы можете использовать двойные или одинарные кавычки вокруг строк:
#!/usr/bin/perl print "Hello, world\n"; print 'Hello, world\n';
Это даст следующий результат —
Hello, world Hello, world\n$
Существует важное различие в одинарных и двойных кавычках. Только двойные кавычки интерполируют переменные и специальные символы, такие как символы новой строки \ n, тогда как одинарные кавычки не интерполируют никакие переменные или специальные символы. Ниже приведен пример, где мы используем $ a в качестве переменной для хранения значения и последующей печати этого значения —
#!/usr/bin/perl $a = 10; print "Value of a = $a\n"; print 'Value of a = $a\n';
Это даст следующий результат —
Value of a = 10 Value of a = $a\n$
«Здесь» Документы
Вы можете хранить или печатать многострочный текст с большим комфортом. Даже вы можете использовать переменные внутри документа «здесь». Ниже приведен простой синтаксис, внимательно проверьте, не должно быть пробелов между << и идентификатором.
Идентификатором может быть либо простое слово, либо какой-либо текст в кавычках, как мы использовали EOF ниже. Если идентификатор указан в кавычках, тип используемой вами цитаты определяет обработку текста внутри документа здесь, как и при обычном цитировании. Идентификатор без кавычек работает как двойные кавычки.
#!/usr/bin/perl $a = 10; $var = <<"EOF"; This is the syntax for here document and it will continue until it encounters a EOF in the first line. This is case of double quote so variable value will be interpolated. For example value of a = $a EOF print "$var\n"; $var = <<'EOF'; This is case of single quote so variable value will be interpolated. For example value of a = $a EOF print "$var\n";
Это даст следующий результат —
This is the syntax for here document and it will continue until it encounters a EOF in the first line. This is case of double quote so variable value will be interpolated. For example value of a = 10 This is case of single quote so variable value will be interpolated. For example value of a = $a
Убегающие персонажи
Perl использует символ обратной косой черты (\) для экранирования символов любого типа, которые могут помешать нашему коду. Давайте возьмем один пример, где мы хотим напечатать двойную кавычку и знак $ —
#!/usr/bin/perl $result = "This is \"number\""; print "$result\n"; print "\$result\n";
Это даст следующий результат —
This is "number" $result
Perl идентификаторы
Идентификатор Perl — это имя, используемое для идентификации переменной, функции, класса, модуля или другого объекта. Имя переменной Perl начинается с $, @ или%, за которыми следуют ноль или более букв, подчеркиваний и цифр (от 0 до 9).
Perl не допускает использование знаков препинания, таких как @, $ и% в идентификаторах. Perl — это чувствительный к регистру язык программирования. Таким образом, $ Manpower и $ manpower — это два разных идентификатора в Perl.
Perl — типы данных
Perl является свободно типизированным языком, и нет необходимости указывать тип для ваших данных при использовании в вашей программе. Интерпретатор Perl выберет тип на основе контекста самих данных.
В Perl есть три основных типа данных: скаляры, массивы скаляров и хэши скаляров, также известные как ассоциативные массивы. Вот небольшая деталь об этих типах данных.
| Sr.No. | Типы и описание |
|---|---|
| 1 |
скаляр Скаляры — это простые переменные. Им предшествует знак доллара ($). Скаляр — это либо число, либо строка, либо ссылка. Ссылка — это адрес переменной, который мы увидим в следующих главах. |
| 2 |
Массивы Массивы — это упорядоченные списки скаляров, к которым вы обращаетесь с помощью числового индекса, который начинается с 0. Им предшествует знак «at» (@). |
| 3 |
Хэш Хэши — это неупорядоченные наборы пар ключ / значение, к которым вы обращаетесь, используя ключи как подписки. Им предшествует знак процента (%). |
скаляр
Скаляры — это простые переменные. Им предшествует знак доллара ($). Скаляр — это либо число, либо строка, либо ссылка. Ссылка — это адрес переменной, который мы увидим в следующих главах.
Массивы
Массивы — это упорядоченные списки скаляров, к которым вы обращаетесь с помощью числового индекса, который начинается с 0. Им предшествует знак «at» (@).
Хэш
Хэши — это неупорядоченные наборы пар ключ / значение, к которым вы обращаетесь, используя ключи как подписки. Им предшествует знак процента (%).
Числовые литералы
Perl хранит все числа внутри себя как целые числа со знаком или значения с плавающей запятой двойной точности. Числовые литералы указываются в любом из следующих форматов с плавающей точкой или целых чисел —
| Тип | Значение |
|---|---|
| целое число | 1234 |
| Отрицательное целое число | -100 |
| Плавающая запятая | 2000 |
| Научная нотация | 16.12E14 |
| шестнадцатеричный | 0xffff |
| восьмеричный | 0577 |
Строковые литералы
Строки — это последовательности символов. Обычно это буквенно-цифровые значения, разделенные одинарными (‘) или двойными («) кавычками. Они работают так же, как кавычки оболочки UNIX, где можно использовать одинарные и двойные кавычки.
Строковые литералы в двойных кавычках допускают интерполяцию переменных, а строки в одинарных кавычках — нет. Существуют определенные символы, когда они обрабатываются обратной косой чертой, имеют особое значение и используются для представления, например, новой строки (\ n) или табуляции (\ t).
Вы можете встраивать символы новой строки или любую из следующих последовательностей Escape непосредственно в строки в двойных кавычках —
| Последовательность побега | Имея в виду |
|---|---|
| \\ | бэкслэш |
| \» | Одинарные цитаты |
| \» | Двойная цитата |
| \ а | Оповещение или звонок |
| \ б | возврат на одну позицию |
| \ е | Форма подачи |
| \ п | Новая линия |
| \р | Возврат каретки |
| \ т | Горизонтальная вкладка |
| \ v | Вертикальная вкладка |
| \ 0nn | Создает числа в формате Octal |
| \ Хпп | Создает числа в формате Hexideciamal |
| \ сХ | Управляет символами, x может быть любым символом |
| \ и | Переводит следующий символ в верхний регистр |
| \ л | Переводит следующий символ в нижний регистр |
| \ U | Переводит все последующие символы в верхний регистр |
| \ L | Заставляет все следующие символы в нижний регистр |
| \ Q | Обратная косая черта всех следующих не алфавитно-цифровых символов |
| \ E | Конец \ U, \ L или \ Q |
пример
Давайте еще раз посмотрим, как ведут себя строки с одинарными и двойными кавычками. Здесь мы будем использовать экранирование строк, упомянутое в приведенной выше таблице, и будем использовать скалярную переменную для назначения строковых значений.
#!/usr/bin/perl # This is case of interpolation. $str = "Welcome to \ntutorialspoint.com!"; print "$str\n"; # This is case of non-interpolation. $str = 'Welcome to \ntutorialspoint.com!'; print "$str\n"; # Only W will become upper case. $str = "\uwelcome to tutorialspoint.com!"; print "$str\n"; # Whole line will become capital. $str = "\UWelcome to tutorialspoint.com!"; print "$str\n"; # A portion of line will become capital. $str = "Welcome to \Ututorialspoint\E.com!"; print "$str\n"; # Backsalash non alpha-numeric including spaces. $str = "\QWelcome to tutorialspoint's family"; print "$str\n";
Это даст следующий результат —
Welcome to tutorialspoint.com! Welcome to \ntutorialspoint.com! Welcome to tutorialspoint.com! WELCOME TO TUTORIALSPOINT.COM! Welcome to TUTORIALSPOINT.com! Welcome\ to\ tutorialspoint\'s\ family
Perl — переменные
Переменные — это зарезервированные области памяти для хранения значений. Это означает, что когда вы создаете переменную, вы резервируете некоторое пространство в памяти.
На основе типа данных переменной интерпретатор выделяет память и решает, что можно сохранить в зарезервированной памяти. Поэтому, назначая переменным разные типы данных, вы можете хранить целые, десятичные или строковые значения в этих переменных.
Мы узнали, что Perl имеет следующие три основных типа данных:
- Скаляры
- Массивы
- Хэш
Соответственно, мы собираемся использовать три типа переменных в Perl. Скалярной переменной будет предшествовать знак доллара ($), и он может хранить число, строку или ссылку. Переменной массива будет предшествовать знак @, и он будет хранить упорядоченные списки скаляров. Наконец, переменная Hash будет предшествовать знаку% и будет использоваться для хранения наборов пар ключ / значение.
Perl поддерживает каждый тип переменной в отдельном пространстве имен. Таким образом, вы можете, не опасаясь конфликта, использовать одно и то же имя для скалярной переменной, массива или хэша. Это означает, что $ foo и @foo — две разные переменные.
Создание переменных
Переменные Perl не должны быть явно объявлены для резервирования пространства памяти. Объявление происходит автоматически, когда вы присваиваете значение переменной. Знак равенства (=) используется для присвоения значений переменным.
Имейте в виду, что объявить переменную обязательно, прежде чем мы ее используем, если в нашей программе используется оператор строгой инструкции.
Операнд слева от оператора = — это имя переменной, а операнд справа от оператора = — это значение, хранящееся в переменной. Например —
$age = 25; # An integer assignment $name = "John Paul"; # A string $salary = 1445.50; # A floating point
Здесь 25, «John Paul» и 1445.50 — значения, присвоенные переменным $ age , $ name и $ salary, соответственно. Вскоре мы увидим, как мы можем присваивать значения массивам и хэшам.
Скалярные переменные
Скаляр — это единица данных. Этими данными могут быть целое число, число с плавающей точкой, символ, строка, абзац или вся веб-страница. Просто сказать, что это может быть что угодно, но только одна вещь.
Вот простой пример использования скалярных переменных —
#!/usr/bin/perl $age = 25; # An integer assignment $name = "John Paul"; # A string $salary = 1445.50; # A floating point print "Age = $age\n"; print "Name = $name\n"; print "Salary = $salary\n";
Это даст следующий результат —
Age = 25 Name = John Paul Salary = 1445.5
Переменные массива
Массив — это переменная, в которой хранится упорядоченный список скалярных значений. Переменным массива предшествует знак «at» (@). Для ссылки на один элемент массива вы будете использовать знак доллара ($) с именем переменной, за которым следует индекс элемента в квадратных скобках.
Вот простой пример использования переменных массива —
#!/usr/bin/perl @ages = (25, 30, 40); @names = ("John Paul", "Lisa", "Kumar"); print "\$ages[0] = $ages[0]\n"; print "\$ages[1] = $ages[1]\n"; print "\$ages[2] = $ages[2]\n"; print "\$names[0] = $names[0]\n"; print "\$names[1] = $names[1]\n"; print "\$names[2] = $names[2]\n";
Здесь мы использовали escape-знак (\) перед знаком $, чтобы распечатать его. Другой Perl поймет это как переменную и напечатает ее значение. При выполнении это даст следующий результат —
$ages[0] = 25 $ages[1] = 30 $ages[2] = 40 $names[0] = John Paul $names[1] = Lisa $names[2] = Kumar
Хеш-переменные
Хеш — это набор пар ключ / значение . Хеш-переменным предшествует знак процента (%). Чтобы сослаться на один элемент хэша, вы будете использовать имя переменной хеша, за которым следует «ключ», связанный со значением в фигурных скобках.
Вот простой пример использования хеш-переменных:
#!/usr/bin/perl %data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40); print "\$data{'John Paul'} = $data{'John Paul'}\n"; print "\$data{'Lisa'} = $data{'Lisa'}\n"; print "\$data{'Kumar'} = $data{'Kumar'}\n";
Это даст следующий результат —
$data{'John Paul'} = 45
$data{'Lisa'} = 30
$data{'Kumar'} = 40
Переменный контекст
Perl обрабатывает одну и ту же переменную по-разному в зависимости от контекста, то есть ситуации, когда переменная используется. Давайте проверим следующий пример —
#!/usr/bin/perl @names = ('John Paul', 'Lisa', 'Kumar'); @copy = @names; $size = @names; print "Given names are : @copy\n"; print "Number of names are : $size\n";
Это даст следующий результат —
Given names are : John Paul Lisa Kumar Number of names are : 3
Здесь @names — это массив, который использовался в двух разных контекстах. Сначала мы скопировали его в любой другой массив, то есть в список, чтобы он возвращал все элементы, предполагая, что контекст является списочным контекстом. Затем мы использовали тот же массив и попытались сохранить этот массив в скаляре, поэтому в этом случае он вернул только количество элементов в этом массиве, предполагая, что контекст является скалярным контекстом. В следующей таблице перечислены различные контексты —
| Sr.No. | Контекст и описание |
|---|---|
| 1 |
скаляр Присвоение скалярной переменной оценивает правую часть в скалярном контексте. |
| 2 |
Список Присвоение массиву или хешу оценивает правую часть в контексте списка. |
| 3 |
логический Логический контекст — это просто любое место, где выражение оценивается, чтобы увидеть, является ли оно истинным или ложным. |
| 4 |
пустота Этот контекст не только не заботится о возвращаемом значении, он даже не хочет возвращаемого значения. |
| 5 |
интерпол Этот контекст происходит только внутри кавычек или вещей, которые работают как кавычки. |
скаляр
Присвоение скалярной переменной оценивает правую часть в скалярном контексте.
Список
Присвоение массиву или хешу оценивает правую часть в контексте списка.
логический
Логический контекст — это просто любое место, где выражение оценивается, чтобы увидеть, является ли оно истинным или ложным.
пустота
Этот контекст не только не заботится о возвращаемом значении, он даже не хочет возвращаемого значения.
интерпол
Этот контекст происходит только внутри кавычек или вещей, которые работают как кавычки.
Perl — Скаляры
Скаляр — это единица данных. Этими данными могут быть целое число, число с плавающей точкой, символ, строка, абзац или вся веб-страница.
Вот простой пример использования скалярных переменных —
#!/usr/bin/perl $age = 25; # An integer assignment $name = "John Paul"; # A string $salary = 1445.50; # A floating point print "Age = $age\n"; print "Name = $name\n"; print "Salary = $salary\n";
Это даст следующий результат —
Age = 25 Name = John Paul Salary = 1445.5
Числовые скаляры
Скаляр чаще всего представляет собой число или строку. Следующий пример демонстрирует использование различных типов числовых скаляров —
#!/usr/bin/perl $integer = 200; $negative = -300; $floating = 200.340; $bigfloat = -1.2E-23; # 377 octal, same as 255 decimal $octal = 0377; # FF hex, also 255 decimal $hexa = 0xff; print "integer = $integer\n"; print "negative = $negative\n"; print "floating = $floating\n"; print "bigfloat = $bigfloat\n"; print "octal = $octal\n"; print "hexa = $hexa\n";
Это даст следующий результат —
integer = 200 negative = -300 floating = 200.34 bigfloat = -1.2e-23 octal = 255 hexa = 255
Струнные скаляры
Следующий пример демонстрирует использование различных типов строковых скаляров. Обратите внимание на разницу между одиночными и двойными кавычками —
#!/usr/bin/perl $var = "This is string scalar!"; $quote = 'I m inside single quote - $var'; $double = "This is inside single quote - $var"; $escape = "This example of escape -\tHello, World!"; print "var = $var\n"; print "quote = $quote\n"; print "double = $double\n"; print "escape = $escape\n";
Это даст следующий результат —
var = This is string scalar! quote = I m inside single quote - $var double = This is inside single quote - This is string scalar! escape = This example of escape - Hello, World
Скалярные операции
Подробно о различных операторах, доступных в Perl, вы увидите в отдельной главе, но здесь мы собираемся перечислить несколько числовых и строковых операций.
#!/usr/bin/perl $str = "hello" . "world"; # Concatenates strings. $num = 5 + 10; # adds two numbers. $mul = 4 * 5; # multiplies two numbers. $mix = $str . $num; # concatenates string and number. print "str = $str\n"; print "num = $num\n"; print "mix = $mix\n";
Это даст следующий результат —
str = helloworld num = 15 mul = 20 mix = helloworld15
Многострочные строки
Если вы хотите ввести в свои программы многострочные строки, вы можете использовать стандартные одинарные кавычки, как показано ниже:
#!/usr/bin/perl $string = 'This is a multiline string'; print "$string\n";
Это даст следующий результат —
This is a multiline string
Вы можете также использовать синтаксис документа «здесь» для хранения или печати мультилиней, как показано ниже:
#!/usr/bin/perl print <<EOF; This is a multiline string EOF
Это также даст тот же результат —
This is a multiline string
V-образные Струны
Литерал вида v1.20.300.4000 анализируется как строка, состоящая из символов с указанными порядковыми номерами. Эта форма известна как v-строки.
V-строка обеспечивает альтернативный и более читаемый способ построения строк, вместо использования менее читаемой интерполяционной формы «\ x {1} \ x {14} \ x {12c} \ x {fa0}».
Это любой литерал, который начинается с av и сопровождается одним или несколькими элементами, разделенными точками. Например —
#!/usr/bin/perl $smile = v9786; $foo = v102.111.111; $martin = v77.97.114.116.105.110; print "smile = $smile\n"; print "foo = $foo\n"; print "martin = $martin\n";
Это также даст тот же результат —
smile = ☺ foo = foo martin = Martin Wide character in print at main.pl line 7.
Специальные литералы
Пока что вы должны иметь представление о скалярных скалярах и их объединении и интерполяции. Итак, позвольте мне рассказать вам о трех специальных литералах __FILE__, __LINE__ и __PACKAGE__, представляющих текущее имя файла, номер строки и имя пакета в этой точке вашей программы.
Они могут использоваться только как отдельные токены и не будут интерполироваться в строки. Проверьте приведенный ниже пример —
#!/usr/bin/perl print "File name ". __FILE__ . "\n"; print "Line Number " . __LINE__ ."\n"; print "Package " . __PACKAGE__ ."\n"; # they can not be interpolated print "__FILE__ __LINE__ __PACKAGE__\n";
Это даст следующий результат —
File name hello.pl Line Number 4 Package main __FILE__ __LINE__ __PACKAGE__
Perl — Массивы
Массив — это переменная, в которой хранится упорядоченный список скалярных значений. Переменным массива предшествует знак «at» (@). Для ссылки на один элемент массива вы будете использовать знак доллара ($) с именем переменной, за которым следует индекс элемента в квадратных скобках.
Вот простой пример использования переменных массива —
#!/usr/bin/perl @ages = (25, 30, 40); @names = ("John Paul", "Lisa", "Kumar"); print "\$ages[0] = $ages[0]\n"; print "\$ages[1] = $ages[1]\n"; print "\$ages[2] = $ages[2]\n"; print "\$names[0] = $names[0]\n"; print "\$names[1] = $names[1]\n"; print "\$names[2] = $names[2]\n";
Здесь мы использовали escape-знак (\) перед знаком $, чтобы распечатать его. Другой Perl поймет это как переменную и напечатает ее значение. При выполнении это даст следующий результат —
$ages[0] = 25 $ages[1] = 30 $ages[2] = 40 $names[0] = John Paul $names[1] = Lisa $names[2] = Kumar
В Perl, List и Array часто используются термины, как будто они взаимозаменяемы. Но список — это данные, а массив — это переменная.
Создание массива
Переменные массива начинаются со знака @ и заполняются круглыми скобками или оператором qw. Например —
@array = (1, 2, 'Hello'); @array = qw/This is an array/;
Во второй строке используется оператор qw //, который возвращает список строк, разделяя разделенную строку пробелом. В этом примере это приводит к массиву из четырех элементов; первый элемент — это, а последний (четвертый) — массив. Это означает, что вы можете использовать разные строки следующим образом:
@days = qw/Monday Tuesday ... Sunday/;
Вы также можете заполнить массив, присваивая каждое значение индивидуально следующим образом:
$array[0] = 'Monday'; ... $array[6] = 'Sunday';
Доступ к элементам массива
При доступе к отдельным элементам из массива вы должны поставить перед переменной знак доллара ($), а затем добавить индекс элемента в квадратных скобках после имени переменной. Например —
#!/usr/bin/perl @days = qw/Mon Tue Wed Thu Fri Sat Sun/; print "$days[0]\n"; print "$days[1]\n"; print "$days[2]\n"; print "$days[6]\n"; print "$days[-1]\n"; print "$days[-7]\n";
Это даст следующий результат —
Mon Tue Wed Sun Sun Mon
Индексы массива начинаются с нуля, поэтому для доступа к первому элементу необходимо указать 0 в качестве индексов. Вы также можете указать отрицательный индекс, в этом случае вы выбираете элемент из конца, а не из начала массива. Это означает следующее —
print $days[-1]; # outputs Sun print $days[-7]; # outputs Mon
Массивы последовательных номеров
Perl предлагает ярлык для последовательных чисел и букв. Вместо того, чтобы печатать каждый элемент при подсчете до 100, например, мы можем сделать что-то вроде следующего:
#!/usr/bin/perl @var_10 = (1..10); @var_20 = (10..20); @var_abc = (a..z); print "@var_10\n"; # Prints number from 1 to 10 print "@var_20\n"; # Prints number from 10 to 20 print "@var_abc\n"; # Prints number from a to z
Здесь двойная точка (..) называется оператором диапазона . Это даст следующий результат —
1 2 3 4 5 6 7 8 9 10 10 11 12 13 14 15 16 17 18 19 20 a b c d e f g h i j k l m n o p q r s t u v w x y z
Размер массива
Размер массива можно определить с помощью скалярного контекста массива — возвращаемое значение будет количеством элементов в массиве —
@array = (1,2,3); print "Size: ",scalar @array,"\n";
Возвращаемым значением всегда будет физический размер массива, а не количество допустимых элементов. Вы можете продемонстрировать это, и разница между скалярным @array и массивом $ #, используя этот фрагмент, заключается в следующем:
#!/usr/bin/perl @array = (1,2,3); $array[50] = 4; $size = @array; $max_index = $#array; print "Size: $size\n"; print "Max Index: $max_index\n";
Это даст следующий результат —
Size: 51 Max Index: 50
В массиве содержится только четыре элемента, которые содержат информацию, но длина массива составляет 51 элемент с максимальным индексом 50.
Добавление и удаление элементов в массиве
Perl предоставляет ряд полезных функций для добавления и удаления элементов в массиве. У вас может возникнуть вопрос, что такое функция? До сих пор вы использовали функцию печати для печати различных значений. Точно так же существуют различные другие функции или иногда называемые подпрограммами, которые могут использоваться для различных других функций.
| Sr.No. | Типы и описание |
|---|---|
| 1 |
нажмите @ ARRAY, LIST Выдвигает значения списка в конец массива. |
| 2 |
поп @ARRAY Выскакивает и возвращает последнее значение массива. |
| 3 |
сдвиг @ ARRAY Сдвигает первое значение массива и возвращает его, сокращая массив на 1 и перемещая все вниз. |
| 4 |
unshift @ARRAY, LIST Добавляет список в начало массива и возвращает количество элементов в новом массиве. |
нажмите @ ARRAY, LIST
Выдвигает значения списка в конец массива.
поп @ARRAY
Выскакивает и возвращает последнее значение массива.
сдвиг @ ARRAY
Сдвигает первое значение массива и возвращает его, сокращая массив на 1 и перемещая все вниз.
unshift @ARRAY, LIST
Добавляет список в начало массива и возвращает количество элементов в новом массиве.
#!/usr/bin/perl # create a simple array @coins = ("Quarter","Dime","Nickel"); print "1. \@coins = @coins\n"; # add one element at the end of the array push(@coins, "Penny"); print "2. \@coins = @coins\n"; # add one element at the beginning of the array unshift(@coins, "Dollar"); print "3. \@coins = @coins\n"; # remove one element from the last of the array. pop(@coins); print "4. \@coins = @coins\n"; # remove one element from the beginning of the array. shift(@coins); print "5. \@coins = @coins\n";
Это даст следующий результат —
1. @coins = Quarter Dime Nickel 2. @coins = Quarter Dime Nickel Penny 3. @coins = Dollar Quarter Dime Nickel Penny 4. @coins = Dollar Quarter Dime Nickel 5. @coins = Quarter Dime Nickel
Нарезка элементов массива
Вы также можете извлечь «фрагмент» из массива, то есть вы можете выбрать более одного элемента из массива, чтобы создать другой массив.
#!/usr/bin/perl @days = qw/Mon Tue Wed Thu Fri Sat Sun/; @weekdays = @days[3,4,5]; print "@weekdays\n";
Это даст следующий результат —
Thu Fri Sat
Спецификация для среза должна иметь список допустимых индексов, положительных или отрицательных, каждый из которых разделен запятой. Для скорости вы также можете использовать оператор диапазона.
#!/usr/bin/perl @days = qw/Mon Tue Wed Thu Fri Sat Sun/; @weekdays = @days[3..5]; print "@weekdays\n";
Это даст следующий результат —
Thu Fri Sat
Замена элементов массива
Теперь мы собираемся ввести еще одну функцию, называемую splice () , которая имеет следующий синтаксис:
splice @ARRAY, OFFSET [ , LENGTH [ , LIST ] ]
Эта функция удалит элементы @ARRAY, обозначенные OFFSET и LENGTH, и заменит их на LIST, если указано. Наконец, он возвращает элементы, удаленные из массива. Ниже приведен пример —
#!/usr/bin/perl @nums = (1..20); print "Before - @nums\n"; splice(@nums, 5, 5, 21..25); print "After - @nums\n";
Это даст следующий результат —
Before - 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 After - 1 2 3 4 5 21 22 23 24 25 11 12 13 14 15 16 17 18 19 20
Здесь фактическая замена начинается с 6-го числа, после чего пять элементов затем заменяются с 6 на 10 номерами 21, 22, 23, 24 и 25.
Преобразовать строки в массивы
Давайте рассмотрим еще одну функцию с именем split () , которая имеет следующий синтаксис:
split [ PATTERN [ , EXPR [ , LIMIT ] ] ]
Эта функция разбивает строку на массив строк и возвращает ее. Если указан LIMIT, разбивается на не более того количества полей. Если PATTERN опущен, разделяется на пробел. Ниже приведен пример —
#!/usr/bin/perl # define Strings $var_string = "Rain-Drops-On-Roses-And-Whiskers-On-Kittens"; $var_names = "Larry,David,Roger,Ken,Michael,Tom"; # transform above strings into arrays. @string = split('-', $var_string); @names = split(',', $var_names); print "$string[3]\n"; # This will print Roses print "$names[4]\n"; # This will print Michael
Это даст следующий результат —
Roses Michael
Преобразовать массивы в строки
Мы можем использовать функцию join (), чтобы воссоединить элементы массива и сформировать одну длинную скалярную строку. Эта функция имеет следующий синтаксис —
join EXPR, LIST
Эта функция объединяет отдельные строки LIST в одну строку с полями, разделенными значением EXPR, и возвращает строку. Ниже приведен пример —
#!/usr/bin/perl # define Strings $var_string = "Rain-Drops-On-Roses-And-Whiskers-On-Kittens"; $var_names = "Larry,David,Roger,Ken,Michael,Tom"; # transform above strings into arrays. @string = split('-', $var_string); @names = split(',', $var_names); $string1 = join( '-', @string ); $string2 = join( ',', @names ); print "$string1\n"; print "$string2\n";
Это даст следующий результат —
Rain-Drops-On-Roses-And-Whiskers-On-Kittens Larry,David,Roger,Ken,Michael,Tom
Сортировка массивов
Функция sort () сортирует каждый элемент массива в соответствии с числовыми стандартами ASCII. Эта функция имеет следующий синтаксис —
sort [ SUBROUTINE ] LIST
Эта функция сортирует LIST и возвращает значение отсортированного массива. Если указан SUBROUTINE, то указанная логика внутри SUBTROUTINE применяется при сортировке элементов.
#!/usr/bin/perl # define an array @foods = qw(pizza steak chicken burgers); print "Before: @foods\n"; # sort this array @foods = sort(@foods); print "After: @foods\n";
Это даст следующий результат —
Before: pizza steak chicken burgers After: burgers chicken pizza steak
Обратите внимание, что сортировка выполняется на основе ASCII числовых значений слов. Поэтому лучше всего сначала преобразовать каждый элемент массива в строчные буквы, а затем выполнить функцию сортировки.
$ [Специальная переменная
До сих пор вы видели простую переменную, которую мы определили в наших программах, и использовали ее для хранения и печати скалярных и массивных значений. Perl предоставляет множество специальных переменных, которые имеют предопределенное значение.
У нас есть специальная переменная, которая записывается как $ [ . Эта специальная переменная является скаляром, содержащим первый индекс всех массивов. Поскольку массивы Perl имеют индексирование с нуля, $ [почти всегда будет 0. Но если вы установите $ [1, то все ваши массивы будут использовать индексирование на основе. Рекомендуется не использовать любое другое индексирование, кроме нуля. Однако давайте возьмем один пример, чтобы показать использование $ [variable —
#!/usr/bin/perl # define an array @foods = qw(pizza steak chicken burgers); print "Foods: @foods\n"; # Let's reset first index of all the arrays. $[ = 1; print "Food at \@foods[1]: $foods[1]\n"; print "Food at \@foods[2]: $foods[2]\n";
Это даст следующий результат —
Foods: pizza steak chicken burgers Food at @foods[1]: pizza Food at @foods[2]: steak
Объединение массивов
Поскольку массив — это просто последовательность значений, разделенных запятыми, вы можете объединить их вместе, как показано ниже —
#!/usr/bin/perl @numbers = (1,3,(4,5,6)); print "numbers = @numbers\n";
Это даст следующий результат —
numbers = 1 3 4 5 6
Встроенные массивы просто становятся частью основного массива, как показано ниже —
#!/usr/bin/perl @odd = (1,3,5); @even = (2, 4, 6); @numbers = (@odd, @even); print "numbers = @numbers\n";
Это даст следующий результат —
numbers = 1 3 5 2 4 6
Выбор элементов из списков
Нотация списка идентична записи для массивов. Вы можете извлечь элемент из массива, добавив квадратные скобки в список и указав один или несколько индексов —
#!/usr/bin/perl $var = (5,4,3,2,1)[4]; print "value of var = $var\n"
Это даст следующий результат —
value of var = 1
Точно так же мы можем извлекать фрагменты, хотя без обязательного начального символа @ —
#!/usr/bin/perl @list = (5,4,3,2,1)[1..3]; print "Value of list = @list\n";
Это даст следующий результат —
Value of list = 4 3 2
Perl — Hashes
Хеш — это набор пар ключ / значение . Хеш-переменным предшествует знак процента (%). Чтобы сослаться на отдельный элемент хеша, вы будете использовать имя переменной хеша, перед которым стоит знак «$», а затем «ключ», связанный со значением в фигурных скобках.
Вот простой пример использования хеш-переменных:
#!/usr/bin/perl %data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40); print "\$data{'John Paul'} = $data{'John Paul'}\n"; print "\$data{'Lisa'} = $data{'Lisa'}\n"; print "\$data{'Kumar'} = $data{'Kumar'}\n";
Это даст следующий результат —
$data{'John Paul'} = 45
$data{'Lisa'} = 30
$data{'Kumar'} = 40
Создание хэшей
Хэши создаются одним из двух следующих способов. В первом методе вы присваиваете значение именованному ключу один за другим —
$data{'John Paul'} = 45; $data{'Lisa'} = 30; $data{'Kumar'} = 40;
Во втором случае вы используете список, который преобразуется путем взятия отдельных пар из списка: первый элемент пары используется в качестве ключа, а второй — в качестве значения. Например —
%data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40);
Для ясности вы можете использовать => в качестве псевдонима для обозначения пар ключ / значение следующим образом:
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
Вот еще один вариант вышеупомянутой формы, посмотрите на нее, здесь всем ключам предшествует дефис (-), и вокруг них не требуется никаких кавычек —
%data = (-JohnPaul => 45, -Lisa => 30, -Kumar => 40);
Но важно отметить, что существует одно слово, т. Е. Ключи без пробелов использовались в этой форме формирования хэша, и если вы создаете свой хэш таким образом, то ключи будут доступны с использованием дефиса, как показано ниже.
$val = %data{-JohnPaul} $val = %data{-Lisa}
Доступ к хеш-элементам
При доступе к отдельным элементам из хеша, вы должны поставить перед переменной знак доллара ($), а затем добавить ключ элемента в фигурных скобках после имени переменной. Например —
#!/usr/bin/perl %data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40); print "$data{'John Paul'}\n"; print "$data{'Lisa'}\n"; print "$data{'Kumar'}\n";
Это даст следующий результат —
45 30 40
Извлечение ломтиков
Вы можете извлечь фрагменты из хеша так же, как вы можете извлечь фрагменты из массива. Вам нужно будет использовать префикс @ для переменной, чтобы сохранить возвращаемое значение, потому что они будут списком значений —
#!/uer/bin/perl %data = (-JohnPaul => 45, -Lisa => 30, -Kumar => 40); @array = @data{-JohnPaul, -Lisa}; print "Array : @array\n";
Это даст следующий результат —
Array : 45 30
Извлечение ключей и значений
Вы можете получить список всех ключей из хеша, используя функцию keys , которая имеет следующий синтаксис:
keys %HASH
Эта функция возвращает массив всех ключей именованного хэша. Ниже приведен пример —
#!/usr/bin/perl %data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40); @names = keys %data; print "$names[0]\n"; print "$names[1]\n"; print "$names[2]\n";
Это даст следующий результат —
Lisa John Paul Kumar
Точно так же вы можете использовать функцию values, чтобы получить список всех значений. Эта функция имеет следующий синтаксис —
values %HASH
Эта функция возвращает обычный массив, состоящий из всех значений именованного хэша. Ниже приведен пример —
#!/usr/bin/perl %data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40); @ages = values %data; print "$ages[0]\n"; print "$ages[1]\n"; print "$ages[2]\n";
Это даст следующий результат —
30 45 40
Проверка на существование
Если вы попытаетесь получить доступ к паре ключ / значение из несуществующего хэша, вы обычно получите неопределенное значение, а если у вас включены предупреждения, то вы получите предупреждение, сгенерированное во время выполнения. Вы можете обойти это, используя функцию exist , которая возвращает true, если именованный ключ существует, независимо от его значения.
#!/usr/bin/perl %data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40); if( exists($data{'Lisa'} ) ) { print "Lisa is $data{'Lisa'} years old\n"; } else { print "I don't know age of Lisa\n"; }
Здесь мы ввели оператор IF … ELSE, который мы изучим в отдельной главе. А пока вы просто предполагаете, что часть if (условие) будет выполняться только тогда, когда данное условие истинно, иначе будет выполнена часть. Поэтому, когда мы выполняем вышеуказанную программу, она дает следующий результат, потому что здесь существует данное условие ($ data {‘Lisa’} возвращает true —
Lisa is 30 years old
Получение размера хэша
Вы можете получить размер, то есть количество элементов из хэша, используя скалярный контекст для ключей или значений. Проще говоря, сначала вы должны получить массив ключей или значений, а затем вы можете получить размер массива следующим образом:
#!/usr/bin/perl %data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40); @keys = keys %data; $size = @keys; print "1 - Hash size: is $size\n"; @values = values %data; $size = @values; print "2 - Hash size: is $size\n";
Это даст следующий результат —
1 - Hash size: is 3 2 - Hash size: is 3
Добавить и удалить элементы в хэшах
Добавление новой пары ключ / значение можно выполнить с помощью одной строки кода, используя простой оператор присваивания. Но чтобы удалить элемент из хеша, вам нужно использовать функцию удаления, как показано ниже в примере —
#!/usr/bin/perl %data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40); @keys = keys %data; $size = @keys; print "1 - Hash size: is $size\n"; # adding an element to the hash; $data{'Ali'} = 55; @keys = keys %data; $size = @keys; print "2 - Hash size: is $size\n"; # delete the same element from the hash; delete $data{'Ali'}; @keys = keys %data; $size = @keys; print "3 - Hash size: is $size\n";
Это даст следующий результат —
1 - Hash size: is 3 2 - Hash size: is 4 3 - Hash size: is 3
Perl Условные операторы — ЕСЛИ … ДАЛЕЕ
Условные операторы Perl помогают в принятии решений, которые требуют, чтобы программист указал одно или несколько условий, которые должны быть оценены или протестированы программой, а также оператор или операторы, которые должны быть выполнены, если условие определено как истинное, и, необязательно, другое заявления должны быть выполнены, если условие определено как ложное.
Ниже приводится общее описание типичной структуры принятия решений, встречающейся в большинстве языков программирования.
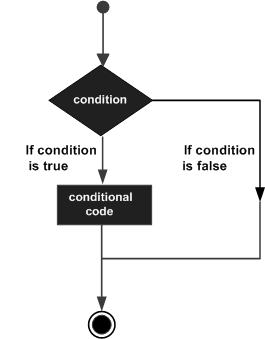
Число 0, строки «0» и «», пустой список () и undef все ложно в логическом контексте, а все остальные значения имеют значение true . Отрицание истинного значения ! or not возвращает специальное ложное значение.
Язык программирования Perl предоставляет следующие типы условных операторов.
| Sr.No. | Заявление и описание |
|---|---|
| 1 | если заявление
Оператор if состоит из логического выражения, за которым следует одно или несколько операторов. |
| 2 | если … еще заявление
За оператором if может следовать необязательный оператор else . |
| 3 | если … эльсиф … еще заявление
За оператором if может следовать необязательный оператор elsif, а затем необязательный оператор else . |
| 4 | если только заявление
Оператор исключением состоит из логического выражения, за которым следует одно или несколько операторов. |
| 5 | если … еще заявление
За оператором NOT может следовать необязательный оператор else . |
| 6 | если только … elsif..else заявление
За оператором NOT может следовать необязательный оператор elsif, а затем необязательный оператор else . |
| 7 | заявление о переключении
В последних версиях Perl вы можете использовать оператор switch . который позволяет простой способ сравнения значения переменной с различными условиями. |
Оператор if состоит из логического выражения, за которым следует одно или несколько операторов.
За оператором if может следовать необязательный оператор else .
За оператором if может следовать необязательный оператор elsif, а затем необязательный оператор else .
Оператор исключением состоит из логического выражения, за которым следует одно или несколько операторов.
За оператором NOT может следовать необязательный оператор else .
За оператором NOT может следовать необязательный оператор elsif, а затем необязательный оператор else .
В последних версиях Perl вы можете использовать оператор switch . который позволяет простой способ сравнения значения переменной с различными условиями.
? : Оператор
Давайте проверим условный оператор? : который можно использовать для замены операторов if … else . Он имеет следующую общую форму —
Exp1 ? Exp2 : Exp3;
Где Exp1, Exp2 и Exp3 являются выражениями. Обратите внимание на использование и размещение толстой кишки.
Значение? Выражение определяется следующим образом: Exp1 оценивается. Если это правда, то Exp2 оценивается и становится значением целого? выражение. Если Exp1 имеет значение false, то Exp3 оценивается, и его значение становится значением выражения. Ниже приведен простой пример использования этого оператора:
#!/usr/local/bin/perl $name = "Ali"; $age = 10; $status = ($age > 60 )? "A senior citizen" : "Not a senior citizen"; print "$name is - $status\n";
Это даст следующий результат —
Ali is - Not a senior citizen
Perl — Петли
Может возникнуть ситуация, когда вам нужно выполнить блок кода несколько раз. В общем случае операторы выполняются последовательно: первый оператор в функции выполняется первым, затем второй и так далее.
Языки программирования предоставляют различные управляющие структуры, которые допускают более сложные пути выполнения.
Оператор цикла позволяет нам выполнять оператор или группу операторов несколько раз, и в большинстве языков программирования ниже приводится общая форма инструкции цикла.
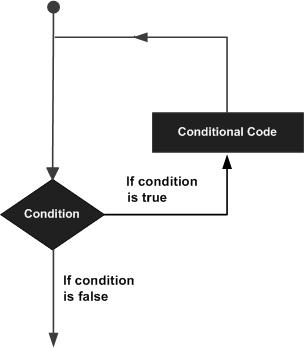
Язык программирования Perl предоставляет следующие типы циклов для обработки требований циклов.
| Sr.No. | Тип и описание петли |
|---|---|
| 1 | в то время как цикл
Повторяет оператор или группу операторов, пока данное условие выполняется. Он проверяет условие перед выполнением тела цикла. |
| 2 | до цикла
Повторяет оператор или группу операторов, пока данное условие не станет истинным. Он проверяет условие перед выполнением тела цикла. |
| 3 | для цикла
Выполняет последовательность операторов несколько раз и сокращает код, который управляет переменной цикла. |
| 4 | цикл foreach
Цикл foreach выполняет итерацию по обычному значению списка и устанавливает переменную VAR для каждого элемента списка по очереди. |
| 5 | делать … пока цикл
Как оператор while, за исключением того, что он проверяет условие в конце тела цикла |
| 6 | вложенные циклы
Вы можете использовать один или несколько циклов внутри любого другого цикла while, for или do.. while. |
Повторяет оператор или группу операторов, пока данное условие выполняется. Он проверяет условие перед выполнением тела цикла.
Повторяет оператор или группу операторов, пока данное условие не станет истинным. Он проверяет условие перед выполнением тела цикла.
Выполняет последовательность операторов несколько раз и сокращает код, который управляет переменной цикла.
Цикл foreach выполняет итерацию по обычному значению списка и устанавливает переменную VAR для каждого элемента списка по очереди.
Как оператор while, за исключением того, что он проверяет условие в конце тела цикла
Вы можете использовать один или несколько циклов внутри любого другого цикла while, for или do.. while.
Заявления о контроле цикла
Операторы управления циклом изменяют выполнение от его нормальной последовательности. Когда выполнение покидает область действия, все автоматические объекты, созданные в этой области, уничтожаются.
Perl поддерживает следующие операторы управления. Нажмите на следующие ссылки, чтобы проверить их детали.
| Sr.No. | Контрольное заявление и описание |
|---|---|
| 1 | следующее заявление
Заставляет петлю пропускать оставшуюся часть своего тела и немедленно проверять свое состояние перед повторением. |
| 2 | последнее заявление
Завершает оператор цикла и передает выполнение в оператор, следующий сразу за циклом. |
| 3 | продолжить заявление
Продолжение BLOCK, оно всегда выполняется непосредственно перед тем, как условная оценка собирается снова быть оценена. |
| 4 | повторить заявление
Команда redo перезапускает блок цикла без повторной оценки условия. Блок продолжения, если он есть, не выполняется. |
| 5 | Перейти к заявлению
Perl поддерживает команду goto в трех формах: метка goto, выражение goto и goto & name. |
Заставляет петлю пропускать оставшуюся часть своего тела и немедленно проверять свое состояние перед повторением.
Завершает оператор цикла и передает выполнение в оператор, следующий сразу за циклом.
Продолжение BLOCK, оно всегда выполняется непосредственно перед тем, как условная оценка собирается снова быть оценена.
Команда redo перезапускает блок цикла без повторной оценки условия. Блок продолжения, если он есть, не выполняется.
Perl поддерживает команду goto в трех формах: метка goto, выражение goto и goto & name.
Бесконечный цикл
Цикл становится бесконечным, если условие никогда не становится ложным. Цикл for традиционно используется для этой цели. Поскольку ни одно из трех выражений, образующих цикл for, не требуется, вы можете создать бесконечный цикл, оставив условное выражение пустым.
#!/usr/local/bin/perl for( ; ; ) { printf "This loop will run forever.\n"; }
Вы можете завершить описанный выше бесконечный цикл, нажав клавиши Ctrl + C.
Когда условное выражение отсутствует, оно считается истинным. Вы можете иметь инициализационное и инкрементное выражение, но программист чаще использует конструкцию for (;;) для обозначения бесконечного цикла.
Perl — Операторы
Что такое оператор?
Простой ответ можно дать с помощью выражения 4 + 5, равного 9 . Здесь 4 и 5 называются операндами, а + называется оператором. Язык Perl поддерживает множество типов операторов, но ниже приведен список важных и наиболее часто используемых операторов:
- Арифметические Операторы
- Операторы равенства
- Логические Операторы
- Операторы присваивания
- Битовые операторы
- Логические Операторы
- Операторы, подобные цитате
- Разные операторы
Давайте посмотрим на всех операторов по одному.
Perl Арифметические Операторы
Предположим, что переменная $ a содержит 10, а переменная $ b содержит 20, а затем следующие арифметические операторы Perl:
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
+ (Дополнение) Добавляет значения по обе стороны от оператора Пример — $ a + $ b даст 30 |
| 2 |
— (вычитание) Вычитает правый операнд из левого операнда Пример — $ a — $ b даст -10 |
| 3 |
* (Умножение) Умножает значения по обе стороны от оператора Пример — $ a * $ b даст 200 |
| 4 |
/ (Отдел) Делит левый операнд на правый операнд Пример — $ b / $ a даст 2 |
| 5 |
% (Модуль) Делит левый операнд на правый и возвращает остаток Пример — $ b% $ a даст 0 |
| 6 |
** (экспонента) Выполняет экспоненциальный (силовой) расчет по операторам Пример — $ a ** $ b даст 10 степени 20 |
+ (Дополнение)
Добавляет значения по обе стороны от оператора
Пример — $ a + $ b даст 30
— (вычитание)
Вычитает правый операнд из левого операнда
Пример — $ a — $ b даст -10
* (Умножение)
Умножает значения по обе стороны от оператора
Пример — $ a * $ b даст 200
/ (Отдел)
Делит левый операнд на правый операнд
Пример — $ b / $ a даст 2
% (Модуль)
Делит левый операнд на правый и возвращает остаток
Пример — $ b% $ a даст 0
** (экспонента)
Выполняет экспоненциальный (силовой) расчет по операторам
Пример — $ a ** $ b даст 10 степени 20
Perl операторы равенства
Они также называются реляционными операторами. Предположим, что переменная $ a содержит 10, а переменная $ b содержит 20, поэтому давайте проверим следующие операторы числового равенства:
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
== (равно) Проверяет, равны ли значения двух операндов или нет, если да, тогда условие становится истинным. Пример — ($ a == $ b) не соответствует действительности. |
| 2 |
!= (Не равно) Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным. Пример — ($ a! = $ B) верно. |
| 3 |
<=> Проверяет, равны ли значения двух операндов или нет, и возвращает -1, 0 или 1 в зависимости от того, числовой аргумент левого аргумента меньше, равен или больше правого аргумента. Пример — ($ a <=> $ b) возвращает -1. |
| 4 |
> (больше чем) Проверяет, больше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. Пример — ($ a> $ b) не соответствует действительности. |
| 5 |
<(меньше чем) Проверяет, меньше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. Пример — ($ a <$ b) верно. |
| 6 |
> = (больше или равно) Проверяет, больше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. Пример — ($ a> = $ b) не соответствует действительности. |
| 7 |
<= (меньше или равно) Проверяет, меньше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. Пример — ($ a <= $ b) верно. |
== (равно)
Проверяет, равны ли значения двух операндов или нет, если да, тогда условие становится истинным.
Пример — ($ a == $ b) не соответствует действительности.
!= (Не равно)
Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным.
Пример — ($ a! = $ B) верно.
<=>
Проверяет, равны ли значения двух операндов или нет, и возвращает -1, 0 или 1 в зависимости от того, числовой аргумент левого аргумента меньше, равен или больше правого аргумента.
Пример — ($ a <=> $ b) возвращает -1.
> (больше чем)
Проверяет, больше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным.
Пример — ($ a> $ b) не соответствует действительности.
<(меньше чем)
Проверяет, меньше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным.
Пример — ($ a <$ b) верно.
> = (больше или равно)
Проверяет, больше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным.
Пример — ($ a> = $ b) не соответствует действительности.
<= (меньше или равно)
Проверяет, меньше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным.
Пример — ($ a <= $ b) верно.
Ниже приведен список операторов акций. Предположим, что переменная $ a содержит «abc», а переменная $ b содержит «xyz», поэтому давайте проверим следующие операторы равенства строк:
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
л Возвращает истину, если левый аргумент по строкам меньше правого аргумента. Пример — ($ a lt $ b) верно. |
| 2 |
GT Возвращает true, если левый аргумент по строкам больше правого аргумента. Пример — ($ a gt $ b) неверно. |
| 3 |
ле Возвращает истину, если левый аргумент по строкам меньше или равен правому аргументу. Пример — ($ a le $ b) верно. |
| 4 |
GE Возвращает истину, если левый аргумент по строкам больше или равен правому аргументу. Пример — ($ a ge $ b) неверно. |
| 5 |
уравнение Возвращает истину, если левый аргумент по строкам равен правому аргументу. Пример — ($ a eq $ b) неверно. |
| 6 |
Небраска Возвращает true, если левый аргумент по строкам не равен правому аргументу. Пример — ($ a ne $ b) верно. |
| 7 |
CMP Возвращает -1, 0 или 1 в зависимости от того, является ли левый аргумент по строкам меньше, равен или больше правого аргумента. Пример — ($ a cmp $ b) равно -1. |
л
Возвращает истину, если левый аргумент по строкам меньше правого аргумента.
Пример — ($ a lt $ b) верно.
GT
Возвращает true, если левый аргумент по строкам больше правого аргумента.
Пример — ($ a gt $ b) неверно.
ле
Возвращает истину, если левый аргумент по строкам меньше или равен правому аргументу.
Пример — ($ a le $ b) верно.
GE
Возвращает истину, если левый аргумент по строкам больше или равен правому аргументу.
Пример — ($ a ge $ b) неверно.
уравнение
Возвращает истину, если левый аргумент по строкам равен правому аргументу.
Пример — ($ a eq $ b) неверно.
Небраска
Возвращает true, если левый аргумент по строкам не равен правому аргументу.
Пример — ($ a ne $ b) верно.
CMP
Возвращает -1, 0 или 1 в зависимости от того, является ли левый аргумент по строкам меньше, равен или больше правого аргумента.
Пример — ($ a cmp $ b) равно -1.
Операторы присваивания Perl
Предположим, что переменная $ a содержит 10, а переменная $ b содержит 20, тогда ниже приведены операторы присваивания, доступные в Perl, и их использование —
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
знак равно Простой оператор присваивания, присваивает значения от правых операндов к левому операнду Пример — $ c = $ a + $ b присвоит значение $ a + $ b в $ c |
| 2 |
+ = Добавить оператор присваивания И, он добавляет правый операнд к левому операнду и присваивает результат левому операнду Пример — $ c + = $ a эквивалентно $ c = $ c + $ a |
| 3 |
знак равно Вычитание И оператор присваивания, вычитает правый операнд из левого операнда и присваивает результат левому операнду Пример — $ c — = $ a эквивалентно $ c = $ c — $ a |
| 4 |
знак равно Оператор присваивания умножения И, умножает правый операнд на левый операнд и присваивает результат левому операнду Пример — $ c * = $ a эквивалентно $ c = $ c * $ a |
| 5 |
знак равно Оператор деления И присваивания, делит левый операнд на правый операнд и присваивает результат левому операнду Пример — $ c / = $ a эквивалентно $ c = $ c / $ a |
| 6 |
знак равно Модуль и оператор присваивания, принимает модуль с использованием двух операндов и присваивает результат левому операнду Пример — $ c% = $ a эквивалентно $ c = $ c% a |
| 7 |
знак равно Оператор экспоненты И присваивания, выполняет экспоненциальный (силовой) расчет операторов и присваивает значение левому операнду Пример — $ c ** = $ a эквивалентно $ c = $ c ** $ a |
знак равно
Простой оператор присваивания, присваивает значения от правых операндов к левому операнду
Пример — $ c = $ a + $ b присвоит значение $ a + $ b в $ c
+ =
Добавить оператор присваивания И, он добавляет правый операнд к левому операнду и присваивает результат левому операнду
Пример — $ c + = $ a эквивалентно $ c = $ c + $ a
знак равно
Вычитание И оператор присваивания, вычитает правый операнд из левого операнда и присваивает результат левому операнду
Пример — $ c — = $ a эквивалентно $ c = $ c — $ a
знак равно
Оператор присваивания умножения И, умножает правый операнд на левый операнд и присваивает результат левому операнду
Пример — $ c * = $ a эквивалентно $ c = $ c * $ a
знак равно
Оператор деления И присваивания, делит левый операнд на правый операнд и присваивает результат левому операнду
Пример — $ c / = $ a эквивалентно $ c = $ c / $ a
знак равно
Модуль и оператор присваивания, принимает модуль с использованием двух операндов и присваивает результат левому операнду
Пример — $ c% = $ a эквивалентно $ c = $ c% a
знак равно
Оператор экспоненты И присваивания, выполняет экспоненциальный (силовой) расчет операторов и присваивает значение левому операнду
Пример — $ c ** = $ a эквивалентно $ c = $ c ** $ a
Битовые операторы Perl
Побитовый оператор работает с битами и выполняет побитовую операцию. Предположим, если $ a = 60; и $ b = 13; Теперь в двоичном формате они будут выглядеть следующим образом —
$ a = 0011 1100
$ b = 0000 1101
——————
$ a & $ b = 0000 1100
$ a | $ b = 0011 1101
$ a ^ $ b = 0011 0001
~ $ a = 1100 0011
Существуют следующие побитовые операторы, поддерживаемые языком Perl, допустим, если $ a = 60; и $ b = 13
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
& Двоичный оператор AND немного копирует результат, если он существует в обоих операндах. Пример — ($ a & $ b) даст 12, что равно 0000 1100 |
| 2 |
| Оператор двоичного ИЛИ копирует немного, если он существует в другом операнде. Пример — ($ a | $ b) даст 61, что равно 0011 1101 |
| 3 |
^ Двоичный оператор XOR копирует бит, если он установлен в одном операнде, но не в обоих. Пример — ($ a ^ $ b) даст 49, что равно 0011 0001 |
| 4 |
~ Оператор дополнения двоичных единиц является унарным и имеет эффект «переворачивания» битов. Пример — (~ $ a) даст -61, что равно 1100 0011 в форме дополнения 2 из-за двоичного числа со знаком. |
| 5 |
<< Двоичный оператор левого сдвига. Значение левого операнда перемещается влево на количество битов, указанное правым операндом. Пример — $ a << 2 даст 240, что равно 1111 0000 |
| 6 |
>> Оператор двоичного правого сдвига. Значение левого операнда перемещается вправо на количество битов, указанное правым операндом. Пример — $ a >> 2 даст 15, что равно 0000 1111 |
&
Двоичный оператор AND немного копирует результат, если он существует в обоих операндах.
Пример — ($ a & $ b) даст 12, что равно 0000 1100
|
Оператор двоичного ИЛИ копирует немного, если он существует в другом операнде.
Пример — ($ a | $ b) даст 61, что равно 0011 1101
^
Двоичный оператор XOR копирует бит, если он установлен в одном операнде, но не в обоих.
Пример — ($ a ^ $ b) даст 49, что равно 0011 0001
~
Оператор дополнения двоичных единиц является унарным и имеет эффект «переворачивания» битов.
Пример — (~ $ a) даст -61, что равно 1100 0011 в форме дополнения 2 из-за двоичного числа со знаком.
<<
Двоичный оператор левого сдвига. Значение левого операнда перемещается влево на количество битов, указанное правым операндом.
Пример — $ a << 2 даст 240, что равно 1111 0000
>>
Оператор двоичного правого сдвига. Значение левого операнда перемещается вправо на количество битов, указанное правым операндом.
Пример — $ a >> 2 даст 15, что равно 0000 1111
Perl Logical Operators
В языке Perl поддерживаются следующие логические операторы. Предположим, что переменная $ a имеет значение true, а переменная $ b содержит значение false тогда —
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
а также Называется логический оператор И. Если оба операнда имеют значение true, тогда условие становится истинным. Пример — ($ a и $ b) неверно. |
| 2 |
&& Оператор логического И в стиле С немного копирует результат, если он существует в обоих операндах. Пример — ($ a && $ b) неверно. |
| 3 |
или же Вызывается логическим оператором ИЛИ. Если любой из двух операндов не равен нулю, тогда условие становится истинным. Пример — ($ a или $ b) верно. |
| 4 |
|| Оператор логического ИЛИ в стиле С немного копирует, если он существует в другом операнде. Пример — ($ a || $ b) верно. |
| 5 |
не Вызывается логическим оператором НЕ. Используйте для изменения логического состояния своего операнда. Если условие истинно, то оператор Логический НЕ будет делать ложь. Пример — нет ($ a и $ b) верно. |
а также
Называется логический оператор И. Если оба операнда имеют значение true, тогда условие становится истинным.
Пример — ($ a и $ b) неверно.
&&
Оператор логического И в стиле С немного копирует результат, если он существует в обоих операндах.
Пример — ($ a && $ b) неверно.
или же
Вызывается логическим оператором ИЛИ. Если любой из двух операндов не равен нулю, тогда условие становится истинным.
Пример — ($ a или $ b) верно.
||
Оператор логического ИЛИ в стиле С немного копирует, если он существует в другом операнде.
Пример — ($ a || $ b) верно.
не
Вызывается логическим оператором НЕ. Используйте для изменения логического состояния своего операнда. Если условие истинно, то оператор Логический НЕ будет делать ложь.
Пример — нет ($ a и $ b) верно.
Операторы, подобные цитате
Существуют следующие операторы типа «цитата», поддерживаемые языком Perl. В следующей таблице {} представляет любую пару разделителей, которую вы выберете.
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
q {} Заключает строку в одинарные кавычки Пример — q {abcd} дает ‘abcd’ |
| 2 |
qq {} Заключает строку в двойные кавычки Пример — qq {abcd} дает «abcd» |
| 3 |
qx {} Содержит строку с инвертированными кавычками Пример — qx {abcd} дает `abcd` |
q {}
Заключает строку в одинарные кавычки
Пример — q {abcd} дает ‘abcd’
qq {}
Заключает строку в двойные кавычки
Пример — qq {abcd} дает «abcd»
qx {}
Содержит строку с инвертированными кавычками
Пример — qx {abcd} дает `abcd`
Разные операторы
Существуют следующие разные операторы, поддерживаемые языком Perl. Предположим, что переменная a содержит 10, а переменная b содержит 20, тогда —
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
, Двоичный оператор точка (.) Объединяет две строки. Пример — если $ a = «abc», $ b = «def», то $ a. $ B выдаст «abcdef» |
| 2 |
Икс Оператор повторения x возвращает строку, состоящую из левого операнда, повторяемого количество раз, указанное правым операндом. Пример — (‘-‘ x 3) даст —. |
| 3 |
.. Оператор диапазона .. возвращает список значений, начиная с левого значения до правого значения Пример — (2..5) даст (2, 3, 4, 5) |
| 4 |
++ Оператор автоинкремента увеличивает целочисленное значение на единицу Пример — $ a ++ даст 11 |
| 5 |
— Оператор автоматического декремента уменьшает целочисленное значение на единицу Пример — $ a— даст 9 |
| 6 |
-> Оператор стрелки в основном используется при разыменовании метода или переменной из объекта или имени класса Пример — $ obj -> $ a является примером доступа к переменной $ a из объекта $ obj. |
,
Двоичный оператор точка (.) Объединяет две строки.
Пример — если $ a = «abc», $ b = «def», то $ a. $ B выдаст «abcdef»
Икс
Оператор повторения x возвращает строку, состоящую из левого операнда, повторяемого количество раз, указанное правым операндом.
Пример — (‘-‘ x 3) даст —.
..
Оператор диапазона .. возвращает список значений, начиная с левого значения до правого значения
Пример — (2..5) даст (2, 3, 4, 5)
++
Оператор автоинкремента увеличивает целочисленное значение на единицу
Пример — $ a ++ даст 11
—
Оператор автоматического декремента уменьшает целочисленное значение на единицу
Пример — $ a— даст 9
->
Оператор стрелки в основном используется при разыменовании метода или переменной из объекта или имени класса
Пример — $ obj -> $ a является примером доступа к переменной $ a из объекта $ obj.
Приоритет Perl-операторов
В следующей таблице перечислены все операторы от наивысшего приоритета к низшему.
left terms and list operators (leftward) left -> nonassoc ++ -- right ** right ! ~ \ and unary + and - left =~ !~ left * / % x left + - . left << >> nonassoc named unary operators nonassoc < > <= >= lt gt le ge nonassoc == != <=> eq ne cmp ~~ left & left | ^ left && left || // nonassoc .. ... right ?: right = += -= *= etc. left , => nonassoc list operators (rightward) right not left and left or xor
Perl — дата и время
Эта глава даст вам базовое понимание того, как обрабатывать и манипулировать датами и временем в Perl.
Текущая дата и время
Давайте начнем с функции localtime () , которая возвращает значения для текущей даты и времени, если не задано никаких аргументов. Ниже приведен список из 9 элементов, возвращаемый функцией localtime при использовании в контексте списка:
sec, # seconds of minutes from 0 to 61 min, # minutes of hour from 0 to 59 hour, # hours of day from 0 to 24 mday, # day of month from 1 to 31 mon, # month of year from 0 to 11 year, # year since 1900 wday, # days since sunday yday, # days since January 1st isdst # hours of daylight savings time
Попробуйте в следующем примере напечатать различные элементы, возвращаемые функцией localtime () —
#!/usr/local/bin/perl @months = qw( Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec ); @days = qw(Sun Mon Tue Wed Thu Fri Sat Sun); ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(); print "$mday $months[$mon] $days[$wday]\n";
Когда приведенный выше код выполняется, он дает следующий результат —
16 Feb Sat
Если вы будете использовать функцию localtime () в скалярном контексте, она будет возвращать дату и время из текущего часового пояса, установленного в системе. Попробуйте следующий пример, чтобы напечатать текущую дату и время в полном формате —
#!/usr/local/bin/perl $datestring = localtime(); print "Local date and time $datestring\n";
Когда приведенный выше код выполняется, он дает следующий результат —
Local date and time Sat Feb 16 06:50:45 2013
Время по Гринвичу
Функция gmtime () работает так же, как функция localtime (), но возвращаемые значения локализованы для стандартного часового пояса Гринвича. Когда вызывается в контексте списка, $ isdst, последнее значение, возвращаемое gmtime, всегда равно 0. Летнее время по Гринвичу отсутствует.
Вы должны обратить внимание на тот факт, что localtime () вернет текущее местное время на машине, на которой выполняется скрипт, а gmtime () вернет универсальное среднее время по Гринвичу, или GMT (или UTC).
Попробуйте следующий пример, чтобы напечатать текущую дату и время, но в масштабе GMT -
#!/usr/local/bin/perl $datestring = gmtime(); print "GMT date and time $datestring\n";
Когда приведенный выше код выполняется, он дает следующий результат —
GMT date and time Sat Feb 16 13:50:45 2013
Формат даты и времени
Вы можете использовать функцию localtime () для получения списка из 9 элементов, а позже вы можете использовать функцию printf () для форматирования даты и времени на основе ваших требований следующим образом:
#!/usr/local/bin/perl ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(); printf("Time Format - HH:MM:SS\n"); printf("%02d:%02d:%02d", $hour, $min, $sec);
Когда приведенный выше код выполняется, он дает следующий результат —
Time Format - HH:MM:SS 06:58:52
Время эпохи
Вы можете использовать функцию time () для получения времени эпохи, т. Е. Количества секунд, прошедших с указанной даты, в Unix это 1 января 1970 года.
#!/usr/local/bin/perl $epoc = time(); print "Number of seconds since Jan 1, 1970 - $epoc\n";
Когда приведенный выше код выполняется, он дает следующий результат —
Number of seconds since Jan 1, 1970 - 1361022130
Вы можете преобразовать заданное количество секунд в строку даты и времени следующим образом:
#!/usr/local/bin/perl $datestring = localtime(); print "Current date and time $datestring\n"; $epoc = time(); $epoc = $epoc - 24 * 60 * 60; # one day before of current date. $datestring = localtime($epoc); print "Yesterday's date and time $datestring\n";
Когда приведенный выше код выполняется, он дает следующий результат —
Current date and time Tue Jun 5 05:54:43 2018 Yesterday's date and time Mon Jun 4 05:54:43 2018
Функция POSIX strftime ()
Вы можете использовать функцию POSIX strftime () для форматирования даты и времени с помощью следующей таблицы. Обратите внимание, что спецификаторы, отмеченные звездочкой (*), зависят от локали.
| Тендерный | Заменен на | пример |
|---|---|---|
%a |
Сокращенное название дня недели * | Thu |
%A |
Полное название дня недели * | Thursday |
%b |
Сокращенное название месяца * | Aug |
%B |
Полное название месяца * | August |
%c |
Дата и время представления * | Thu Aug 23 14:55:02 2001 |
%C |
Год делится на 100 и усекается до целого числа ( 00-99 ) |
20 |
%d |
День месяца, дополненный нулями ( 01-31 ) |
23 |
%D |
Короткая дата MM/DD/YY , эквивалентная %m/%d/%y |
08/23/01 |
%e |
День месяца, дополненный пробелами ( 1-31 ) |
23 |
%F |
Короткая дата YYYY-MM-DD , эквивалентная %Y-%m-%d |
2001-08-23 |
%g |
Недельный год, последние две цифры ( 00-99 ) |
01 |
%G |
Недельный год | 2001 |
%h |
Сокращенное название месяца * (аналогично %b ) |
Aug |
%H |
Час в 24-часовом формате ( 00-23 ) |
14 |
%I |
Час в 12-часовом формате ( 01-12 ) |
02 |
%j |
День года ( 001-366 ) |
235 |
%m |
Месяц как десятичное число ( 01-12 ) |
08 |
%M |
Минута ( 00-59 ) |
55 |
%n |
Символ новой строки ( '\n' ) |
|
%p |
Обозначение AM или PM | PM |
%r |
Время 12 часов * | 02:55:02 pm |
%R |
24-часовой HH:MM , эквивалентный %H:%M |
14:55 |
%S |
Второй ( 00-61 ) |
02 |
%t |
Горизонтальный символ табуляции ( '\t' ) |
|
%T |
Формат времени ISO 8601 ( HH:MM:SS ), эквивалентный %H:%M:%S |
14:55 |
%u |
ISO 8601 — будний день, номер понедельника — 1 ( 1-7 ). |
4 |
%U |
Номер недели с первым воскресеньем в качестве первого дня первой недели ( 00-53 ) |
33 |
%V |
Номер недели ISO 8601 ( 00-53 ) |
34 |
%w |
День недели как десятичное число с воскресеньем 0 ( 0-6 ) |
4 |
%W |
Номер недели с первым понедельником в качестве первого дня первой недели ( 00-53 ) |
34 |
%x |
Дата представления * | 08/23/01 |
%X |
Время представления * | 14:55:02 |
%y |
Год, последние две цифры ( 00-99 ) |
01 |
%Y |
Год | 2001 |
%z |
ISO 8601 смещение от UTC в часовом поясе (1 минута = 1, 1 час = 100) Если часовой пояс не может быть удален, нет символов |
+100 |
%Z |
Название или аббревиатура часового пояса * Если часовой пояс не может быть удален, нет символов |
CDT |
%% |
Знак % |
% |
ISO 8601 смещение от UTC в часовом поясе (1 минута = 1, 1 час = 100)
Если часовой пояс не может быть удален, нет символов
Название или аббревиатура часового пояса *
Если часовой пояс не может быть удален, нет символов
Давайте проверим следующий пример, чтобы понять использование —
#!/usr/local/bin/perl use POSIX qw(strftime); $datestring = strftime "%a %b %e %H:%M:%S %Y", localtime; printf("date and time - $datestring\n"); # or for GMT formatted appropriately for your locale: $datestring = strftime "%a %b %e %H:%M:%S %Y", gmtime; printf("date and time - $datestring\n");
Когда приведенный выше код выполняется, он дает следующий результат —
date and time - Sat Feb 16 07:10:23 2013 date and time - Sat Feb 16 14:10:23 2013
Perl — подпрограммы
Подпрограмма или функция Perl — это группа операторов, которые вместе выполняют задачу. Вы можете разделить ваш код на отдельные подпрограммы. Как вы делите свой код между различными подпрограммами, зависит только от вас, но логически разделение обычно так, что каждая функция выполняет определенную задачу.
Perl использует термины подпрограмма, метод и функция взаимозаменяемо.
Определить и вызвать подпрограмму
Общая форма определения подпрограммы в языке программирования Perl выглядит следующим образом:
sub subroutine_name {
body of the subroutine
}
Типичный способ вызова этой подпрограммы Perl следующий:
subroutine_name( list of arguments );
В версиях Perl до 5.0 синтаксис для вызова подпрограмм немного отличался, как показано ниже. Это по-прежнему работает в новейших версиях Perl, но это не рекомендуется, поскольку оно обходит прототипы подпрограмм.
&subroutine_name( list of arguments );
Давайте посмотрим на следующий пример, который определяет простую функцию, а затем вызываем ее. Поскольку Perl компилирует вашу программу перед ее выполнением, не имеет значения, где вы объявляете свою подпрограмму.
#!/usr/bin/perl # Function definition sub Hello { print "Hello, World!\n"; } # Function call Hello();
Когда вышеуказанная программа выполняется, она дает следующий результат —
Hello, World!
Передача аргументов в подпрограмму
Вы можете передавать различные аргументы подпрограмме, как это делается на любом другом языке программирования, и они могут быть доступны внутри функции с помощью специального массива @_. Таким образом, первый аргумент функции находится в $ _ [0], второй — в $ _ [1] и так далее.
Вы можете передавать массивы и хэши в качестве аргументов, как и любой скаляр, но передача более одного массива или хэша обычно приводит к потере их отдельных идентификаторов. Поэтому мы будем использовать ссылки (объясненные в следующей главе) для передачи любого массива или хэша.
Давайте попробуем следующий пример, который берет список чисел и затем печатает их среднее значение —
#!/usr/bin/perl # Function definition sub Average { # get total number of arguments passed. $n = scalar(@_); $sum = 0; foreach $item (@_) { $sum += $item; } $average = $sum / $n; print "Average for the given numbers : $average\n"; } # Function call Average(10, 20, 30);
Когда вышеуказанная программа выполняется, она дает следующий результат —
Average for the given numbers : 20
Передача списков в подпрограммы
Поскольку переменная @_ является массивом, ее можно использовать для предоставления списков подпрограмме. Однако из-за того, как Perl принимает и анализирует списки и массивы, может быть трудно извлечь отдельные элементы из @_. Если вам нужно передать список вместе с другими скалярными аргументами, то сделайте список последним аргументом, как показано ниже —
#!/usr/bin/perl # Function definition sub PrintList { my @list = @_; print "Given list is @list\n"; } $a = 10; @b = (1, 2, 3, 4); # Function call with list parameter PrintList($a, @b);
Когда вышеуказанная программа выполняется, она дает следующий результат —
Given list is 10 1 2 3 4
Передача хешей в подпрограммы
Когда вы предоставляете хеш для подпрограммы или оператора, который принимает список, тогда хеш автоматически переводится в список пар ключ / значение. Например —
#!/usr/bin/perl # Function definition sub PrintHash { my (%hash) = @_; foreach my $key ( keys %hash ) { my $value = $hash{$key}; print "$key : $value\n"; } } %hash = ('name' => 'Tom', 'age' => 19); # Function call with hash parameter PrintHash(%hash);
Когда вышеуказанная программа выполняется, она дает следующий результат —
name : Tom age : 19
Возвращаемое значение из подпрограммы
Вы можете вернуть значение из подпрограммы, как и на любом другом языке программирования. Если вы не возвращаете значение из подпрограммы, то любое вычисление, которое в последний раз выполнялось в подпрограмме, автоматически также будет возвращаемым значением.
Вы можете возвращать массивы и хэши из подпрограммы, как и любой скаляр, но возвращая более одного массива или хеша, обычно они теряют свои отдельные идентификаторы. Поэтому мы будем использовать ссылки (объясненные в следующей главе), чтобы вернуть любой массив или хеш из функции.
Давайте попробуем следующий пример, который берет список чисел, а затем возвращает их среднее значение —
#!/usr/bin/perl # Function definition sub Average { # get total number of arguments passed. $n = scalar(@_); $sum = 0; foreach $item (@_) { $sum += $item; } $average = $sum / $n; return $average; } # Function call $num = Average(10, 20, 30); print "Average for the given numbers : $num\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Average for the given numbers : 20
Частные переменные в подпрограмме
По умолчанию все переменные в Perl являются глобальными переменными, что означает, что к ним можно получить доступ из любой точки программы. Но вы можете в любое время создавать частные переменные, называемые лексическими переменными, с помощью оператора my .
Оператор my ограничивает переменную определенной областью кода, в которой она может использоваться и доступна. За пределами этого региона эта переменная не может быть использована или доступна. Этот регион называется его областью применения. Лексическая область видимости обычно представляет собой блок кода с набором фигурных скобок вокруг него, таких как те, которые определяют тело подпрограммы или те, которые отмечают блоки кода операторов if, while, for, foreach и eval .
Ниже приведен пример, показывающий, как определить одну или несколько частных переменных с помощью оператора my —
sub somefunc { my $variable; # $variable is invisible outside somefunc() my ($another, @an_array, %a_hash); # declaring many variables at once }
Давайте проверим следующий пример, чтобы различить глобальные и частные переменные:
#!/usr/bin/perl # Global variable $string = "Hello, World!"; # Function definition sub PrintHello { # Private variable for PrintHello function my $string; $string = "Hello, Perl!"; print "Inside the function $string\n"; } # Function call PrintHello(); print "Outside the function $string\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Inside the function Hello, Perl! Outside the function Hello, World!
Временные значения через local ()
Локальное в основном используется, когда текущее значение переменной должно быть видимым для вызываемых подпрограмм. Локальный просто дает временные значения глобальным (то есть пакет) переменным. Это известно как динамическое определение объема . С помощью my выполняется лексическая область видимости, которая больше похожа на автоматические объявления Си.
Если для локальной переменной задано более одной переменной или выражения, они должны быть заключены в скобки. Этот оператор работает, сохраняя текущие значения этих переменных в своем списке аргументов в скрытом стеке и восстанавливая их при выходе из блока, подпрограммы или eval.
Давайте проверим следующий пример, чтобы различать глобальные и локальные переменные —
#!/usr/bin/perl # Global variable $string = "Hello, World!"; sub PrintHello { # Private variable for PrintHello function local $string; $string = "Hello, Perl!"; PrintMe(); print "Inside the function PrintHello $string\n"; } sub PrintMe { print "Inside the function PrintMe $string\n"; } # Function call PrintHello(); print "Outside the function $string\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Inside the function PrintMe Hello, Perl! Inside the function PrintHello Hello, Perl! Outside the function Hello, World!
Переменные состояния через state ()
Есть еще один тип лексических переменных, которые похожи на частные переменные, но они поддерживают свое состояние и не инициализируются повторно при множественных вызовах подпрограмм. Эти переменные определяются с помощью оператора состояния и доступны начиная с Perl 5.9.4.
Давайте проверим следующий пример, чтобы продемонстрировать использование переменных состояния —
#!/usr/bin/perl use feature 'state'; sub PrintCount { state $count = 0; # initial value print "Value of counter is $count\n"; $count++; } for (1..5) { PrintCount(); }
Когда вышеуказанная программа выполняется, она дает следующий результат —
Value of counter is 0 Value of counter is 1 Value of counter is 2 Value of counter is 3 Value of counter is 4
До Perl 5.10 вы должны были бы написать это так:
#!/usr/bin/perl { my $count = 0; # initial value sub PrintCount { print "Value of counter is $count\n"; $count++; } } for (1..5) { PrintCount(); }
Контекст вызова подпрограммы
Контекст подпрограммы или оператора определяется как ожидаемый тип возвращаемого значения. Это позволяет использовать одну функцию, которая возвращает разные значения в зависимости от того, что пользователь ожидает получить. Например, следующий localtime () возвращает строку, когда она вызывается в скалярном контексте, но возвращает список, когда она вызывается в контексте списка.
my $datestring = localtime( time );
В этом примере значение $ timestr теперь является строкой, состоящей из текущей даты и времени, например, чт 30 ноября 15:21:33 2000. И наоборот —
($sec,$min,$hour,$mday,$mon, $year,$wday,$yday,$isdst) = localtime(time);
Теперь отдельные переменные содержат соответствующие значения, возвращаемые функцией localtime ().
Perl — Ссылки
Ссылка Perl — это скалярный тип данных, который содержит местоположение другого значения, которое может быть скалярным, массивом или хэшем. Из-за своей скалярной природы, ссылка может использоваться везде, где можно использовать скаляр.
Вы можете создавать списки, содержащие ссылки на другие списки, которые могут содержать ссылки на хэши и т. Д. Вот как встроенные структуры данных строятся в Perl.
Создать ссылки
Ссылку для любой переменной, подпрограммы или значения легко создать, добавив к ней обратную косую черту следующим образом:
$scalarref = \$foo; $arrayref = \@ARGV; $hashref = \%ENV; $coderef = \&handler; $globref = \*foo;
Вы не можете создать ссылку на дескриптор ввода / вывода (дескриптор файла или dirhandle), используя оператор обратной косой черты, но ссылку на анонимный массив можно создать с помощью квадратных скобок следующим образом:
$arrayref = [1, 2, ['a', 'b', 'c']];
Аналогичным образом вы можете создать ссылку на анонимный хеш, используя фигурные скобки следующим образом:
$hashref = { 'Adam' => 'Eve', 'Clyde' => 'Bonnie', };
Ссылка на анонимную подпрограмму может быть создана с использованием sub без имени:
$coderef = sub { print "Boink!\n" };
Разыменование
Разыменование возвращает значение из контрольной точки в местоположение. Для разыменования ссылки просто используйте $, @ или% в качестве префикса ссылочной переменной в зависимости от того, указывает ли ссылка на скаляр, массив или хэш. Ниже приведен пример для объяснения концепции:
#!/usr/bin/perl $var = 10; # Now $r has reference to $var scalar. $r = \$var; # Print value available at the location stored in $r. print "Value of $var is : ", $$r, "\n"; @var = (1, 2, 3); # Now $r has reference to @var array. $r = \@var; # Print values available at the location stored in $r. print "Value of @var is : ", @$r, "\n"; %var = ('key1' => 10, 'key2' => 20); # Now $r has reference to %var hash. $r = \%var; # Print values available at the location stored in $r. print "Value of %var is : ", %$r, "\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Value of 10 is : 10 Value of 1 2 3 is : 123 Value of %var is : key220key110
Если вы не уверены в типе переменной, то легко узнать ее тип, используя ref , который возвращает одну из следующих строк, если ее аргумент является ссылкой. В противном случае возвращается false —
SCALAR ARRAY HASH CODE GLOB REF
Давайте попробуем следующий пример —
#!/usr/bin/perl $var = 10; $r = \$var; print "Reference type in r : ", ref($r), "\n"; @var = (1, 2, 3); $r = \@var; print "Reference type in r : ", ref($r), "\n"; %var = ('key1' => 10, 'key2' => 20); $r = \%var; print "Reference type in r : ", ref($r), "\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Reference type in r : SCALAR Reference type in r : ARRAY Reference type in r : HASH
Циркулярные ссылки
Циркулярная ссылка возникает, когда две ссылки содержат ссылку друг на друга. При создании ссылок вы должны быть осторожны, иначе круговая ссылка может привести к утечкам памяти. Ниже приведен пример —
#!/usr/bin/perl my $foo = 100; $foo = \$foo; print "Value of foo is : ", $$foo, "\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Value of foo is : REF(0x9aae38)
Ссылки на функции
Это может произойти, если вам нужно создать обработчик сигнала, чтобы вы могли создать ссылку на функцию, поставив перед ней имя функции \ & и разыменовав эту ссылку, вам просто нужно добавить префикс ссылки к переменной с помощью амперсанда &. Ниже приведен пример —
#!/usr/bin/perl # Function definition sub PrintHash { my (%hash) = @_; foreach $item (%hash) { print "Item : $item\n"; } } %hash = ('name' => 'Tom', 'age' => 19); # Create a reference to above function. $cref = \&PrintHash; # Function call using reference. &$cref(%hash);
Когда вышеуказанная программа выполняется, она дает следующий результат —
Item : name Item : Tom Item : age Item : 19
Perl — форматы
Perl использует шаблон письма, называемый «формат», для вывода отчетов. Чтобы использовать функцию форматирования Perl, вы должны сначала определить формат, а затем вы можете использовать этот формат для записи отформатированных данных.
Определить формат
Ниже приведен синтаксис для определения формата Perl:
format FormatName = fieldline value_one, value_two, value_three fieldline value_one, value_two .
Здесь FormatName представляет название формата. Поле представляет собой определенный способ, данные должны быть отформатированы. Строки значений представляют значения, которые будут введены в строку поля. Вы заканчиваете формат с одним периодом.
Следующая полевая строка может содержать любой текст или держатели полей. Владельцы полей содержат место для данных, которые будут размещены там позже. Полевой держатель имеет формат —
@<<<<
Этот держатель поля выровнен по левому краю с пробелом поля 5. Вы должны посчитать знак @ и знак <, чтобы узнать количество пробелов в поле. Другие владельцы поля включают в себя —
@>>>> right-justified @|||| centered @####.## numeric field holder @* multiline field holder
Примерный формат будет —
format EMPLOYEE = =================================== @<<<<<<<<<<<<<<<<<<<<<< @<< $name $age @#####.## $salary =================================== .
В этом примере $ name будет записано как выравнивание по левому краю в пределах 22 пробелов, а после этого возраста будет записано в двух пробелах.
Использование формата
Чтобы вызвать это объявление формата, мы использовали бы ключевое слово write —
write EMPLOYEE;
Проблема заключается в том, что именем формата обычно является имя дескриптора открытого файла, и оператор write отправит выходные данные в этот дескриптор файла. Поскольку мы хотим, чтобы данные отправлялись в STDOUT, мы должны связать EMPLOYEE с дескриптором файла STDOUT. Сначала, однако, мы должны убедиться, что STDOUT — наш дескриптор выбранного файла, используя функцию select ().
select(STDOUT);
Затем мы связали бы EMPLOYEE с STDOUT, установив имя нового формата с STDOUT, используя специальную переменную $ ~ или $ FORMAT_NAME следующим образом:
$~ = "EMPLOYEE";
Когда мы сейчас делаем write (), данные будут отправлены в STDOUT. Помните: если вы собираетесь написать свой отчет в любом другом дескрипторе файла вместо STDOUT, тогда вы можете использовать функцию select (), чтобы выбрать этот дескриптор файла, а остальная логика останется прежней.
Давайте возьмем следующий пример. Здесь у нас есть жестко закодированные значения только для демонстрации использования. При фактическом использовании вы будете считывать значения из файла или базы данных для создания реальных отчетов, и вам может потребоваться снова записать окончательный отчет в файл.
#!/usr/bin/perl format EMPLOYEE = =================================== @<<<<<<<<<<<<<<<<<<<<<< @<< $name $age @#####.## $salary =================================== . select(STDOUT); $~ = EMPLOYEE; @n = ("Ali", "Raza", "Jaffer"); @a = (20,30, 40); @s = (2000.00, 2500.00, 4000.000); $i = 0; foreach (@n) { $name = $_; $age = $a[$i]; $salary = $s[$i++]; write; }
При выполнении это даст следующий результат —
=================================== Ali 20 2000.00 =================================== =================================== Raza 30 2500.00 =================================== =================================== Jaffer 40 4000.00 ===================================
Определить заголовок отчета
Все выглядит хорошо. Но вам будет интересно добавить заголовок в ваш отчет. Этот заголовок будет напечатан в верхней части каждой страницы. Это очень просто сделать. Помимо определения шаблона вам нужно будет определить заголовок и назначить его переменной $ ^ или $ FORMAT_TOP_NAME —
#!/usr/bin/perl format EMPLOYEE = =================================== @<<<<<<<<<<<<<<<<<<<<<< @<< $name $age @#####.## $salary =================================== . format EMPLOYEE_TOP = =================================== Name Age =================================== . select(STDOUT); $~ = EMPLOYEE; $^ = EMPLOYEE_TOP; @n = ("Ali", "Raza", "Jaffer"); @a = (20,30, 40); @s = (2000.00, 2500.00, 4000.000); $i = 0; foreach (@n) { $name = $_; $age = $a[$i]; $salary = $s[$i++]; write; }
Теперь ваш отчет будет выглядеть так:
=================================== Name Age =================================== =================================== Ali 20 2000.00 =================================== =================================== Raza 30 2500.00 =================================== =================================== Jaffer 40 4000.00 ===================================
Определить пагинацию
Что делать, если ваш отчет занимает более одной страницы? У вас есть решение для этого, просто используйте $% или $ FORMAT_PAGE_NUMBER vairable вместе с заголовком следующим образом:
format EMPLOYEE_TOP =
===================================
Name Age Page @<
$%
===================================
.
Теперь ваш вывод будет выглядеть следующим образом —
=================================== Name Age Page 1 =================================== =================================== Ali 20 2000.00 =================================== =================================== Raza 30 2500.00 =================================== =================================== Jaffer 40 4000.00 ===================================
Количество строк на странице
Вы можете установить количество строк на странице, используя специальную переменную $ = (или $ FORMAT_LINES_PER_PAGE), по умолчанию $ = будет 60.
Определить нижний колонтитул отчета
Хотя $ ^ или $ FORMAT_TOP_NAME содержит имя текущего формата заголовка, не существует соответствующего механизма, который автоматически делал бы то же самое для нижнего колонтитула. Если у вас есть нижний колонтитул фиксированного размера, вы можете получить нижние колонтитулы, проверяя переменную $ — или $ FORMAT_LINES_LEFT перед каждой записью () и, при необходимости, печатать нижний колонтитул самостоятельно, используя другой формат, определенный следующим образом:
format EMPLOYEE_BOTTOM = End of Page @< $% .
Полный набор переменных, связанных с форматированием, см. В разделе « Специальные переменные Perl ».
Perl — File I / O
Основы обработки файлов просты: вы связываете дескриптор файла с внешним объектом (обычно файлом), а затем используете различные операторы и функции в Perl для чтения и обновления данных, хранящихся в потоке данных, связанных с дескриптором файла.
Файловый дескриптор — это именованная внутренняя структура Perl, которая связывает физический файл с именем. Все файловые дескрипторы имеют доступ для чтения / записи, поэтому вы можете читать и обновлять любой файл или устройство, связанное с файловым дескриптором. Однако, когда вы связываете файловый дескриптор, вы можете указать режим, в котором открывается файловый дескриптор.
Три основных файловых дескриптора — STDIN , STDOUT и STDERR, которые представляют стандартный ввод, стандартный вывод и стандартные устройства ошибок соответственно.
Открытие и закрытие файлов
Ниже приведены две функции с несколькими формами, которые можно использовать для открытия любого нового или существующего файла в Perl.
open FILEHANDLE, EXPR open FILEHANDLE sysopen FILEHANDLE, FILENAME, MODE, PERMS sysopen FILEHANDLE, FILENAME, MODE
Здесь FILEHANDLE — дескриптор файла, возвращаемый функцией open, а EXPR — выражение, имеющее имя файла и режим открытия файла.
Открытая функция
Ниже приведен синтаксис для открытия файла file.txt в режиме только для чтения. Здесь знак «<» означает, что файл должен быть открыт в режиме только для чтения.
open(DATA, "<file.txt");
Здесь DATA — дескриптор файла, который будет использоваться для чтения файла. Вот пример, который откроет файл и напечатает его содержимое на экране.
#!/usr/bin/perl open(DATA, "<file.txt") or die "Couldn't open file file.txt, $!"; while(<DATA>) { print "$_"; }
Ниже приведен синтаксис для открытия файла file.txt в режиме записи. Здесь знак «меньше» означает, что файл должен быть открыт в режиме записи.
open(DATA, ">file.txt") or die "Couldn't open file file.txt, $!";
Этот пример фактически обрезает (очищает) файл перед тем, как открыть его для записи, что может не иметь желаемого эффекта. Если вы хотите открыть файл для чтения и записи, вы можете поставить знак плюс перед символами> или <.
Например, чтобы открыть файл для обновления, не обрезая его —
open(DATA, "+<file.txt"); or die "Couldn't open file file.txt, $!";
Чтобы сначала обрезать файл —
open DATA, "+>file.txt" or die "Couldn't open file file.txt, $!";
Вы можете открыть файл в режиме добавления. В этом режиме точка записи будет установлена в конец файла.
open(DATA,">>file.txt") || die "Couldn't open file file.txt, $!";
Двойной >> открывает файл для добавления, помещая указатель файла в конце, чтобы вы могли немедленно начать добавлять информацию. Тем не менее, вы не можете читать с него, если вы не ставите знак плюс перед ним —
open(DATA,"+>>file.txt") || die "Couldn't open file file.txt, $!";
Ниже приведена таблица, в которой приведены возможные значения различных режимов.
| Sr.No. | Сущности и определения |
|---|---|
| 1 |
<или r Доступ только для чтения |
| 2 |
> или ш Создает, пишет и усекает |
| 3 |
>> или Пишет, добавляет и создает |
| 4 |
+ <или r + Читает и пишет |
| 5 |
+> или w + Читает, пишет, создает и усекает |
| 6 |
+ >> или + Читает, пишет, добавляет и создает |
<или r
Доступ только для чтения
> или ш
Создает, пишет и усекает
>> или
Пишет, добавляет и создает
+ <или r +
Читает и пишет
+> или w +
Читает, пишет, создает и усекает
+ >> или +
Читает, пишет, добавляет и создает
Функция Sysopen
Функция sysopen похожа на основную функцию open, за исключением того, что она использует функцию system open () , используя параметры, предоставленные ей в качестве параметров для системной функции —
Например, чтобы открыть файл для обновления, эмулируя формат + <имя файла из open —
sysopen(DATA, "file.txt", O_RDWR);
Или обрезать файл перед обновлением —
sysopen(DATA, "file.txt", O_RDWR|O_TRUNC );
Вы можете использовать O_CREAT для создания нового файла и O_WRONLY — для открытия файла в режиме только для записи, а O_RDONLY — для открытия файла в режиме только для чтения.
Аргумент PERMS определяет права доступа к файлу для указанного файла, если он должен быть создан. По умолчанию это занимает 0x666 .
Ниже приведена таблица, в которой приведены возможные значения MODE.
| Sr.No. | Сущности и определения |
|---|---|
| 1 |
O_RDWR Прочти и напиши |
| 2 |
O_RDONLY Только чтение |
| 3 |
O_WRONLY Только запись |
| 4 |
O_CREAT Создать файл |
| 5 |
O_APPEND Добавить файл |
| 6 |
O_TRUNC Усекать файл |
| 7 |
O_EXCL Останавливается, если файл уже существует |
| 8 |
O_NONBLOCK Неблокирующее удобство использования |
O_RDWR
Прочти и напиши
O_RDONLY
Только чтение
O_WRONLY
Только запись
O_CREAT
Создать файл
O_APPEND
Добавить файл
O_TRUNC
Усекать файл
O_EXCL
Останавливается, если файл уже существует
O_NONBLOCK
Неблокирующее удобство использования
Функция закрытия
Чтобы закрыть дескриптор файла и, следовательно, отсоединить дескриптор файла от соответствующего файла, используйте функцию закрытия . Это очищает буферы файлового дескриптора и закрывает файловый дескриптор системы.
close FILEHANDLE close
Если FILEHANDLE не указан, он закрывает текущий выбранный дескриптор файла. Он возвращает true, только если он может успешно очистить буферы и закрыть файл.
close(DATA) || die "Couldn't close file properly";
Чтение и запись файлов
Когда у вас есть открытый файловый дескриптор, вы должны иметь возможность читать и записывать информацию. Существует несколько различных способов чтения и записи данных в файл.
Оператор <FILEHANDL>
Основным методом чтения информации из открытого дескриптора файла является оператор <FILEHANDLE>. В скалярном контексте он возвращает одну строку из дескриптора файла. Например —
#!/usr/bin/perl print "What is your name?\n"; $name = <STDIN>; print "Hello $name\n";
Когда вы используете оператор <FILEHANDLE> в контексте списка, он возвращает список строк из указанного дескриптора файла. Например, чтобы импортировать все строки из файла в массив —
#!/usr/bin/perl open(DATA,"<import.txt") or die "Can't open data"; @lines = <DATA>; close(DATA);
Функция getc
Функция getc возвращает один символ из указанного FILEHANDLE или STDIN, если ни один не указан —
getc FILEHANDLE
getc
Если произошла ошибка или дескриптор файла находится в конце файла, вместо него возвращается undef.
Функция чтения
Функция чтения считывает блок информации из буферизованного дескриптора файла: эта функция используется для чтения двоичных данных из файла.
read FILEHANDLE, SCALAR, LENGTH, OFFSET read FILEHANDLE, SCALAR, LENGTH
Длина считываемых данных определяется как LENGTH, и данные помещаются в начало SCALAR, если не указано OFFSET. В противном случае данные помещаются после байтов OFFSET в SCALAR. Функция возвращает количество байтов, прочитанных в случае успеха, ноль в конце файла или undef, если произошла ошибка.
Функция печати
Для всех различных методов, используемых для чтения информации из файловых дескрипторов, основной функцией для записи информации является функция печати.
print FILEHANDLE LIST print LIST print
Функция печати печатает оцененное значение LIST в FILEHANDLE или в текущий дескриптор выходного файла (по умолчанию STDOUT). Например —
print "Hello World!\n";
Копирование файлов
Вот пример, который открывает существующий файл file1.txt и читает его построчно и генерирует еще один файл копии file2.txt.
#!/usr/bin/perl # Open file to read open(DATA1, "<file1.txt"); # Open new file to write open(DATA2, ">file2.txt"); # Copy data from one file to another. while(<DATA1>) { print DATA2 $_; } close( DATA1 ); close( DATA2 );
Переименование файла
Вот пример, который показывает, как мы можем переименовать файл file1.txt в file2.txt. Предполагая, что файл доступен в каталоге / usr / test.
#!/usr/bin/perl rename ("/usr/test/file1.txt", "/usr/test/file2.txt" );
Эта функция переименовывает принимает два аргумента и просто переименовывает существующий файл.
Удаление существующего файла
Вот пример, который показывает, как удалить файл file1.txt с помощью функции unlink .
#!/usr/bin/perl unlink ("/usr/test/file1.txt");
Позиционирование внутри файла
Вы можете использовать функцию сказать, чтобы узнать текущую позицию файла и искать функцию, чтобы указать определенную позицию внутри файла.
Функция сказать
Первое требование — найти вашу позицию в файле, что вы делаете с помощью функции Tell —
tell FILEHANDLE
tell
Это возвращает позицию указателя файла в байтах внутри FILEHANDLE, если он указан, или текущего выбранного по умолчанию дескриптора файла, если ни один не указан.
Функция поиска
Функция поиска позиционирует указатель файла на указанное количество байтов в файле —
seek FILEHANDLE, POSITION, WHENCE
Функция использует системную функцию fseek, и у вас есть такая же возможность позиционирования относительно трех разных точек: начала, конца и текущей позиции. Вы делаете это, указав значение для WHENCE.
Ноль устанавливает положение относительно начала файла. Например, строка устанавливает указатель файла на 256-й байт в файле.
seek DATA, 256, 0;
Информация о файле
Вы можете очень быстро протестировать некоторые функции в Perl, используя серию тестовых операторов, известных как -X тесты. Например, чтобы выполнить быструю проверку различных прав доступа к файлу, вы можете использовать такой скрипт:
#/usr/bin/perl my $file = "/usr/test/file1.txt"; my (@description, $size); if (-e $file) { push @description, 'binary' if (-B _); push @description, 'a socket' if (-S _); push @description, 'a text file' if (-T _); push @description, 'a block special file' if (-b _); push @description, 'a character special file' if (-c _); push @description, 'a directory' if (-d _); push @description, 'executable' if (-x _); push @description, (($size = -s _)) ? "$size bytes" : 'empty'; print "$file is ", join(', ',@description),"\n"; }
Вот список функций, которые вы можете проверить для файла или каталога —
| Sr.No. | Оператор и определение |
|---|---|
| 1 |
-А Время запуска скрипта минус время последнего обращения к файлу, в днях. |
| 2 |
-B Это бинарный файл? |
| 3 |
-С Время запуска скрипта минус время последнего изменения файла inode, в днях. |
| 3 |
-М Время запуска скрипта минус время модификации файла, в днях. |
| 4 |
-О Принадлежит ли файл реальному идентификатору пользователя? |
| 5 |
-Р Является ли файл читаемым по реальному идентификатору пользователя или реальной группе? |
| 6 |
-S Является ли файл сокетом? |
| 7 |
-T Это текстовый файл? |
| 8 |
-W Является ли файл доступным для записи по реальному идентификатору пользователя или реальной группе? |
| 9 |
-ИКС Выполняется ли файл с помощью реального идентификатора пользователя или реальной группы? |
| 10 |
-b Это специальный файл блока? |
| 11 |
-с Это специальный символьный файл? |
| 12 |
-d Является ли файл каталогом? |
| 13 |
-e Файл существует? |
| 14 |
-f Это простой файл? |
| 15 |
-г В файле установлен бит setgid? |
| 16 |
-k В файле установлен бит? |
| 17 |
-l Является ли файл символической ссылкой? |
| 18 |
-о Владеет ли файл эффективным идентификатором пользователя? |
| 19 |
-п Является ли файл именованным каналом? |
| 20 |
-р Является ли файл читаемым по эффективному идентификатору пользователя или группы? |
| 21 |
-s Возвращает размер файла, нулевой размер = пустой файл. |
| 22 |
-t Файл-дескриптор открыт TTY (терминалом)? |
| 23 |
-u В файле установлен бит setuid? |
| 24 |
-w Является ли файл доступным для записи по эффективному идентификатору пользователя или группы? |
| 25 |
-Икс Выполняется ли файл по эффективному идентификатору пользователя или группы? |
| 26 |
-z Размер файла равен нулю? |
-А
Время запуска скрипта минус время последнего обращения к файлу, в днях.
-B
Это бинарный файл?
-С
Время запуска скрипта минус время последнего изменения файла inode, в днях.
-М
Время запуска скрипта минус время модификации файла, в днях.
-О
Принадлежит ли файл реальному идентификатору пользователя?
-Р
Является ли файл читаемым по реальному идентификатору пользователя или реальной группе?
-S
Является ли файл сокетом?
-T
Это текстовый файл?
-W
Является ли файл доступным для записи по реальному идентификатору пользователя или реальной группе?
-ИКС
Выполняется ли файл с помощью реального идентификатора пользователя или реальной группы?
-b
Это специальный файл блока?
-с
Это специальный символьный файл?
-d
Является ли файл каталогом?
-e
Файл существует?
-f
Это простой файл?
-г
В файле установлен бит setgid?
-k
В файле установлен бит?
-l
Является ли файл символической ссылкой?
-о
Владеет ли файл эффективным идентификатором пользователя?
-п
Является ли файл именованным каналом?
-р
Является ли файл читаемым по эффективному идентификатору пользователя или группы?
-s
Возвращает размер файла, нулевой размер = пустой файл.
-t
Файл-дескриптор открыт TTY (терминалом)?
-u
В файле установлен бит setuid?
-w
Является ли файл доступным для записи по эффективному идентификатору пользователя или группы?
-Икс
Выполняется ли файл по эффективному идентификатору пользователя или группы?
-z
Размер файла равен нулю?
Perl — каталоги
Ниже приведены стандартные функции, используемые для работы с каталогами.
opendir DIRHANDLE, EXPR # To open a directory readdir DIRHANDLE # To read a directory rewinddir DIRHANDLE # Positioning pointer to the begining telldir DIRHANDLE # Returns current position of the dir seekdir DIRHANDLE, POS # Pointing pointer to POS inside dir closedir DIRHANDLE # Closing a directory.
Показать все файлы
Существуют различные способы перечисления всех файлов, доступных в определенном каталоге. Сначала давайте воспользуемся простым способом получить и вывести список всех файлов с помощью оператора glob.
#!/usr/bin/perl # Display all the files in /tmp directory. $dir = "/tmp/*"; my @files = glob( $dir ); foreach (@files ) { print $_ . "\n"; } # Display all the C source files in /tmp directory. $dir = "/tmp/*.c"; @files = glob( $dir ); foreach (@files ) { print $_ . "\n"; } # Display all the hidden files. $dir = "/tmp/.*"; @files = glob( $dir ); foreach (@files ) { print $_ . "\n"; } # Display all the files from /tmp and /home directories. $dir = "/tmp/* /home/*"; @files = glob( $dir ); foreach (@files ) { print $_ . "\n"; }
Вот еще один пример, который открывает каталог и перечисляет все файлы, доступные в этом каталоге.
#!/usr/bin/perl opendir (DIR, '.') or die "Couldn't open directory, $!"; while ($file = readdir DIR) { print "$file\n"; } closedir DIR;
Еще один пример распечатки списка исходных файлов C, который вы можете использовать:
#!/usr/bin/perl opendir(DIR, '.') or die "Couldn't open directory, $!"; foreach (sort grep(/^.*\.c$/,readdir(DIR))) { print "$_\n"; } closedir DIR;
Создать новый каталог
Вы можете использовать функцию mkdir для создания нового каталога. Вам нужно будет иметь необходимые разрешения для создания каталога.
#!/usr/bin/perl $dir = "/tmp/perl"; # This creates perl directory in /tmp directory. mkdir( $dir ) or die "Couldn't create $dir directory, $!"; print "Directory created successfully\n";
Удалить каталог
Вы можете использовать функцию rmdir для удаления каталога. Вам нужно будет иметь необходимые разрешения для удаления каталога. Кроме того, этот каталог должен быть пустым, прежде чем пытаться удалить его.
#!/usr/bin/perl $dir = "/tmp/perl"; # This removes perl directory from /tmp directory. rmdir( $dir ) or die "Couldn't remove $dir directory, $!"; print "Directory removed successfully\n";
Изменить каталог
Вы можете использовать функцию chdir, чтобы изменить каталог и перейти на новое место. Вам нужно будет иметь необходимое разрешение, чтобы изменить каталог и зайти в новый каталог.
#!/usr/bin/perl $dir = "/home"; # This changes perl directory and moves you inside /home directory. chdir( $dir ) or die "Couldn't go inside $dir directory, $!"; print "Your new location is $dir\n";
Perl — обработка ошибок
Выполнение и ошибки всегда идут вместе. Если вы открываете файл, который не существует. тогда, если вы не справились с этой ситуацией должным образом, значит, ваша программа плохого качества.
Программа останавливается, если происходит ошибка. Таким образом, правильная обработка ошибок используется для обработки различных типов ошибок, которые могут возникнуть во время выполнения программы, и предпринять соответствующие действия вместо полной остановки программы.
Вы можете определить и уловить ошибку несколькими различными способами. Очень легко отлавливать ошибки в Perl и затем правильно их обрабатывать. Вот несколько методов, которые можно использовать.
Оператор if
Оператор if является очевидным выбором, когда вам нужно проверить возвращаемое значение из оператора; например —
if(open(DATA, $file)) { ... } else { die "Error: Couldn't open the file - $!"; }
Здесь переменная $! возвращает фактическое сообщение об ошибке. В качестве альтернативы, мы можем сократить выражение до одной строки в ситуациях, когда это имеет смысл сделать; например —
open(DATA, $file) || die "Error: Couldn't open the file $!";
Функция разве что
Функция разве является логической противоположностью операторам if: они могут полностью обойти статус успеха и выполняться только в том случае, если выражение возвращает false. Например —
unless(chdir("/etc")) { die "Error: Can't change directory - $!"; }
Оператор Тогда лучше всего использовать, когда вы хотите вызвать ошибку или альтернативу, только если выражение не выполнено. Это утверждение также имеет смысл, когда используется в однострочном утверждении —
die "Error: Can't change directory!: $!" unless(chdir("/etc"));
Здесь мы умираем только в случае сбоя операции chdir, и она хорошо читается.
Троичный оператор
Для очень коротких тестов вы можете использовать условный оператор ?:
print(exists($hash{value}) ? 'There' : 'Missing',"\n");
Здесь не совсем понятно, чего мы пытаемся достичь, но эффект такой же, как при использовании оператора if или else . Условный оператор лучше всего использовать, когда вы хотите быстро вернуть одно из двух значений в выражении или операторе.
Функция предупреждения
Функция warn только выдает предупреждение, сообщение выводится в STDERR, но никаких дальнейших действий не предпринимается. Таким образом, это более полезно, если вы просто хотите напечатать предупреждение для пользователя и продолжить работу —
chdir('/etc') or warn "Can't change directory";
Функция умирает
Функция die работает так же, как warn, за исключением того, что она также вызывает exit. В обычном скрипте эта функция немедленно прекращает выполнение. Вы должны использовать эту функцию, если она бесполезна, если в программе есть ошибка —
chdir('/etc') or die "Can't change directory";
Ошибки внутри модулей
Есть две разные ситуации, с которыми мы должны справиться —
-
Сообщение об ошибке в модуле, которая указывает имя файла и номер строки модуля — это полезно при отладке модуля или когда вы специально хотите вызвать ошибку, связанную с модулем, а не со сценарием.
-
Сообщение об ошибке в модуле, который цитирует информацию о вызывающем абоненте, чтобы вы могли отладить строку в скрипте, вызвавшем ошибку. Ошибки, возникающие таким образом, полезны для конечного пользователя, потому что они выделяют ошибку по отношению к исходной строке вызывающего скрипта.
Сообщение об ошибке в модуле, которая указывает имя файла и номер строки модуля — это полезно при отладке модуля или когда вы специально хотите вызвать ошибку, связанную с модулем, а не со сценарием.
Сообщение об ошибке в модуле, который цитирует информацию о вызывающем абоненте, чтобы вы могли отладить строку в скрипте, вызвавшем ошибку. Ошибки, возникающие таким образом, полезны для конечного пользователя, потому что они выделяют ошибку по отношению к исходной строке вызывающего скрипта.
Функции warn и die работают немного иначе, чем вы ожидаете при вызове из модуля. Например, простой модуль —
package T; require Exporter; @ISA = qw/Exporter/; @EXPORT = qw/function/; use Carp; sub function { warn "Error in module!"; } 1;
Когда вызывается из скрипта, как показано ниже —
use T; function();
Это даст следующий результат —
Error in module! at T.pm line 9.
Это более или менее то, что вы могли ожидать, но не обязательно то, что вы хотите. С точки зрения программиста модуля, информация полезна, потому что она помогает указать на ошибку в самом модуле. Для конечного пользователя предоставленная информация довольно бесполезна, а для всех, кроме опытного программиста, она абсолютно бессмысленна.
Решением для таких проблем является модуль Carp, который предоставляет упрощенный метод для сообщения об ошибках в модулях, которые возвращают информацию о вызывающем скрипте. Модуль Carp предоставляет четыре функции: карп, cluck, croak и confess. Эти функции обсуждаются ниже.
Функция карпа
Функция carp является основным эквивалентом warn и печатает сообщение в STDERR без фактического выхода из сценария и печати имени сценария.
package T; require Exporter; @ISA = qw/Exporter/; @EXPORT = qw/function/; use Carp; sub function { carp "Error in module!"; } 1;
Когда вызывается из скрипта, как показано ниже —
use T; function();
Это даст следующий результат —
Error in module! at test.pl line 4
Функция щелчка
Функция cluck — это своего рода карп с наддувом, она следует тому же базовому принципу, но также печатает трассировку стека всех модулей, которые привели к вызову функции, включая информацию об исходном скрипте.
package T; require Exporter; @ISA = qw/Exporter/; @EXPORT = qw/function/; use Carp qw(cluck); sub function { cluck "Error in module!"; } 1;
Когда вызывается из скрипта, как показано ниже —
use T; function();
Это даст следующий результат —
Error in module! at T.pm line 9 T::function() called at test.pl line 4
Функция квака
Функция квака эквивалентна смерти , за исключением того, что она сообщает вызывающему на один уровень выше. Как и die, эта функция также выходит из сценария после сообщения об ошибке в STDERR —
package T; require Exporter; @ISA = qw/Exporter/; @EXPORT = qw/function/; use Carp; sub function { croak "Error in module!"; } 1;
Когда вызывается из скрипта, как показано ниже —
use T; function();
Это даст следующий результат —
Error in module! at test.pl line 4
Как и в случае с карпом, применяются те же основные правила, что и в отношении информации о строках и файлах, в соответствии с функциями warn и die.
Функция признания
Функция признания похожа на щелчок ; он вызывает die, а затем печатает трассировку стека вплоть до исходного сценария.
package T; require Exporter; @ISA = qw/Exporter/; @EXPORT = qw/function/; use Carp; sub function { confess "Error in module!"; } 1;
Когда вызывается из скрипта, как показано ниже —
use T; function();
Это даст следующий результат —
Error in module! at T.pm line 9 T::function() called at test.pl line 4
Perl — специальные переменные
Есть некоторые переменные, которые имеют предопределенное и специальное значение в Perl. Это переменные, которые используют знаки пунктуации после обычного индикатора переменной ($, @ или%), такого как $ _ (объяснено ниже).
Большинство специальных переменных имеют английское длинное имя, например переменная ошибки операционной системы $! может быть записано как $ OS_ERROR. Но если вы собираетесь использовать имена, похожие на английский, то вам придется поставить одну строку, используя английский; в верхней части файла вашей программы. Это помогает интерпретатору точно определить значение переменной.
Наиболее часто используемая специальная переменная — это $ _, которая содержит строку ввода и строку поиска по умолчанию. Например, в следующих строках —
#!/usr/bin/perl foreach ('hickory','dickory','doc') { print $_; print "\n"; }
При выполнении это даст следующий результат —
hickory dickory doc
Опять же, давайте проверим тот же пример без явного использования переменной $ _ —
#!/usr/bin/perl foreach ('hickory','dickory','doc') { print; print "\n"; }
При выполнении это также даст следующий результат —
hickory dickory doc
При первом выполнении цикла выводится «гикори». Во второй раз печатается «dickory», а в третий раз печатается «doc». Это потому, что в каждой итерации цикла текущая строка помещается в $ _ и используется по умолчанию для печати. Вот места, где Perl примет $ _, даже если вы не укажете его —
-
Различные унарные функции, включая такие функции, как ord и int, а также все тесты файлов (-f, -d), за исключением -t, который по умолчанию равен STDIN.
-
Различные функции списка, такие как печать и отмена связи.
-
Операции сопоставления с образцом m //, s /// и tr /// при использовании без оператора = ~.
-
Переменная итератора по умолчанию в цикле foreach, если не указана другая переменная.
-
Неявная переменная итератора в функциях grep и map.
-
Место по умолчанию для ввода входной записи, когда результат операции линейного ввода проверяется сам по себе как единственный критерий теста while (т. Е.). Обратите внимание, что вне времени теста это не произойдет.
Различные унарные функции, включая такие функции, как ord и int, а также все тесты файлов (-f, -d), за исключением -t, который по умолчанию равен STDIN.
Различные функции списка, такие как печать и отмена связи.
Операции сопоставления с образцом m //, s /// и tr /// при использовании без оператора = ~.
Переменная итератора по умолчанию в цикле foreach, если не указана другая переменная.
Неявная переменная итератора в функциях grep и map.
Место по умолчанию для ввода входной записи, когда результат операции линейного ввода проверяется сам по себе как единственный критерий теста while (т. Е.). Обратите внимание, что вне времени теста это не произойдет.
Специальные типы переменных
На основании использования и характера специальных переменных мы можем классифицировать их по следующим категориям:
- Глобальные скалярные специальные переменные.
- Global Array Специальные переменные.
- Global Hash Специальные Переменные.
- Глобальные специальные файловые дескрипторы.
- Глобальные специальные константы.
- Регулярные выражения Специальные переменные.
- Filehandle Специальные Переменные.
Глобальные скалярные специальные переменные
Вот список всех скалярных специальных переменных. Мы перечислили соответствующие английские похожие имена вместе с символическими именами.
| $ _ | Вход по умолчанию и пространство для поиска по шаблону. |
| $ ARG | |
| $. | Текущий номер строки ввода последнего дескриптора файла, который был прочитан. Явное закрытие на дескрипторе файла сбрасывает номер строки. |
| $ NR | |
| $ / | Разделитель входной записи; новая строка по умолчанию. Если задана нулевая строка, пустые строки рассматриваются как разделители. |
| $ RS | |
| $, | Разделитель выходного поля для оператора печати. |
| $ OFS | |
| $ \ | Разделитель выходных записей для оператора печати. |
| $ ORS | |
| $» | Как и «$», за исключением того, что он применяется к списочным значениям, интерполированным в строку в двойных кавычках (или аналогичную интерпретируемую строку). По умолчанию это пробел. |
| $ LIST_SEPARATOR | |
| $; | Индексный разделитель для эмуляции многомерного массива. По умолчанию «\ 034». |
| $ SUBSCRIPT_SEPARATOR | |
| $ ^ L | Какой формат выводит для выполнения формы подачи. По умолчанию «\ f». |
| $ FORMAT_FORMFEED | |
| $: | Текущий набор символов, после которого строка может быть разбита для заполнения полей продолжения (начиная с ^) в формате. По умолчанию «\ n» «. |
| $ FORMAT_LINE_BREAK_CHARACTERS | |
| $ ^ А | Текущее значение аккумулятора записи для строк формата. |
| $ ACCUMULATOR | |
| $ # | Содержит формат вывода для напечатанных чисел (не рекомендуется). |
| $ OFMT | |
| $? | Статус, возвращаемый последней командой закрытия канала, командой backtick («) или системным оператором. |
| $ CHILD_ERROR | |
| $! | Если используется в числовом контексте, возвращает текущее значение переменной errno, определяющее ошибку последнего системного вызова. Если используется в строковом контексте, выдает соответствующую строку системной ошибки. |
| $ OS_ERROR или $ ERRNO | |
| $ @ | Сообщение об ошибке синтаксиса Perl из последней команды eval. |
| $ EVAL_ERROR | |
| $$ | PID процесса Perl, выполняющего этот скрипт. |
| $ PROCESS_ID или $ PID | |
| $ < | Реальный идентификатор пользователя (uid) этого процесса. |
| $ REAL_USER_ID или $ UID | |
| $> | Эффективный идентификатор пользователя этого процесса. |
| $ EFFECTIVE_USER_ID или $ EUID | |
| $ ( | Реальный идентификатор группы (gid) этого процесса. |
| $ REAL_GROUP_ID или $ GID | |
| $) | Эффективный гид этого процесса. |
| $ EFFECTIVE_GROUP_ID или $ EGID | |
| $ 0 | Содержит имя файла, содержащего исполняемый скрипт Perl. |
| $ program_name | |
| $ [ | Индекс первого элемента в массиве и первого символа в подстроке. По умолчанию 0. |
| $] | Возвращает версию плюс уровень патча, разделенный на 1000. |
| $ PERL_VERSION | |
| $ ^ D | Текущее значение флагов отладки. |
| $ DEBUGGING | |
| $ ^ E | Расширенное сообщение об ошибке на некоторых платформах. |
| $ EXTENDED_OS_ERROR | |
| $ ^ F | Максимальный системный дескриптор файла, обычно 2. |
| $ SYSTEM_FD_MAX | |
| $ ^ H | Содержит внутренние подсказки компилятора, включенные некоторыми прагматическими модулями. |
| $ ^ I | Текущее значение расширения редактирования на месте. Используйте undef, чтобы отключить редактирование на месте. |
| $ INPLACE_EDIT | |
| $ ^ M | Содержимое $ M можно использовать в качестве пула аварийной памяти на случай, если Perl умрет с ошибкой нехватки памяти. Использование $ M требует специальной компиляции Perl. См. Документ INSTALL для получения дополнительной информации. |
| $ ^ O | Содержит имя операционной системы, для которой был скомпилирован текущий двоичный файл Perl. |
| $ OSNAME | |
| $ ^ P | Внутренний флаг, который отладчик очищает, чтобы он не отлаживал себя. |
| $ PERLDB | |
| $ ^ T | Время начала работы скрипта в секундах с начала эпохи. |
| $ BASETIME | |
| $ ^ W | Текущее значение переключателя предупреждения, истина или ложь. |
| $ ВНИМАНИЕ | |
| $ ^ X | Имя, под которым исполняется двоичный файл Perl. |
| $ EXECUTABLE_NAME | |
| $ ARGV | Содержит имя текущего файла при чтении из <ARGV>. |
Global Array Специальные переменные
| @ARGV | Массив, содержащий аргументы командной строки, предназначенные для скрипта. |
| @INC | Массив, содержащий список мест для поиска сценариев Perl, которые будут оцениваться конструкциями do, require или use. |
| @F | Массив, на который разделяются входные строки, когда задан ключ командной строки -a. |
Global Hash Специальные Переменные
| % INC | Хеш, содержащий записи для имени файла каждого файла, который был включен с помощью do или require. |
| % ENV | Хеш, содержащий ваше текущее окружение. |
| % SIG | Хеш используется для установки обработчиков сигналов для различных сигналов. |
Глобальные специальные файловые дескрипторы
| ARGV | Специальный дескриптор файла, который перебирает имена файлов командной строки в @ARGV. Обычно пишется как нулевой дескриптор файла в <>. |
| STDERR | Специальный дескриптор файла для стандартной ошибки в любом пакете. |
| STDIN | Специальный дескриптор файла для стандартного ввода в любой пакет. |
| STDOUT | Специальный дескриптор файла для стандартного вывода в любой упаковке. |
| ДАННЫЕ | Специальный дескриптор файла, который ссылается на что-либо после токена __END__ в файле, содержащем скрипт. Или специальный файловый дескриптор для чего-либо, следующего за маркером __DATA__ в требуемом файле, если вы читаете данные в том же пакете, в котором был найден __DATA__. |
| _ (нижнее подчеркивание) | Специальный файловый дескриптор, используемый для кэширования информации от последнего оператора stat, lstat или оператора тестирования файла. |
Глобальные специальные константы
| __КОНЕЦ__ | Указывает на логический конец вашей программы. Любой следующий текст игнорируется, но может быть прочитан через файловый дескриптор DATA. |
| __ФАЙЛ__ | Представляет имя файла в той точке вашей программы, где оно используется. Не интерполируется в строки. |
| __ЛИНИЯ__ | Представляет текущий номер строки. Не интерполируется в строки. |
| __PACKAGE__ | Представляет имя текущего пакета во время компиляции или не определено, если текущего пакета нет. Не интерполируется в строки. |
Специальные Переменные Регулярного Выражения
| $ значный | Содержит текст, соответствующий соответствующему набору скобок в последнем сопоставленном шаблоне. Например, $ 1 соответствует тому, что содержалось в первом наборе скобок в предыдущем регулярном выражении. |
| $ & | Строка, соответствующая последнему успешному совпадению с образцом. |
| $ MATCH | |
| $ ` | Строка, предшествующая тому, что было найдено последним успешным совпадением с образцом. |
| $ PREMATCH | |
| $» | Строка, следующая за тем, что совпало с последним успешным совпадением с образцом. |
| $ POSTMATCH | |
| $ + | Последняя скобка соответствует последнему шаблону поиска. Это полезно, если вы не знаете, какой из набора альтернативных шаблонов был сопоставлен. Например: / Version: (. *) | Редакция: (. *) / && ($ rev = $ +); |
| $ LAST_PAREN_MATCH |
Специальные переменные дескриптора файла
| $ | | Если установлено значение, отличное от нуля, форсирует fflush (3) после каждой записи или печати на выбранном в данный момент выходном канале. |
| $ OUTPUT_AUTOFLUSH | |
| $% | Номер текущей страницы выбранного в данный момент выходного канала. |
| $ FORMAT_PAGE_NUMBER | |
| $ = | Текущая длина страницы (печатаемые строки) текущего выбранного выходного канала. По умолчанию это 60. |
| $ FORMAT_LINES_PER_PAGE | |
| $ — | Количество строк, оставшихся на странице выбранного в данный момент выходного канала. |
| $ FORMAT_LINES_LEFT | |
| $ ~ | Имя текущего формата отчета для текущего выбранного выходного канала. По умолчанию это имя дескриптора файла. |
| $ FORMAT_NAME | |
| $ ^ | Имя текущего формата верхней части страницы для текущего выбранного выходного канала. По умолчанию это имя дескриптора файла с добавленным _TOP. |
| $ FORMAT_TOP_NAME |
Perl — стандарт кодирования
Каждый программист, конечно, будет иметь свои собственные предпочтения в отношении форматирования, но есть некоторые общие рекомендации, которые облегчат чтение, понимание и поддержку ваших программ.
Самое главное, чтобы ваши программы всегда запускались под флагом -w. Вы можете отключить его явно для определенных частей кода с помощью прагмы no warnings или переменной $ ^ W, если необходимо. Вы также должны всегда использовать строгие правила или знать причину, почему нет. Использование sigtrap и даже использование диагностических прагм также может оказаться полезным.
Что касается эстетики разметки кода, то единственное, что сильно волнует Ларри, это то, что закрывающая фигурная скобка многострочного BLOCK должна совпадать с ключевым словом, с которого начинается конструкция. Помимо этого, у него есть другие предпочтения, которые не так сильны —
- Отступ в 4 столбца.
- Открытие фигурных на той же строке, что и ключевое слово, если это возможно, в противном случае выстраиваются в линию.
- Пробел перед открытием фигурного многострочного блока.
- Однострочный БЛОК может быть помещен в одну строку, включая кудри.
- Без точки с запятой.
- Точка с запятой опускается в «короткий» однострочный БЛОК.
- Пространство вокруг большинства операторов.
- Пробел вокруг «сложного» индекса (внутри скобок).
- Пустые строки между кусками, которые делают разные вещи.
- Непослушные остальные.
- Нет пробела между именем функции и открывающей скобкой.
- Пробел после каждой запятой.
- Длинные строки разбиты после оператора (кроме и и или).
- Пробел после последнего совпадения скобок в текущей строке.
- Выровняйте соответствующие элементы по вертикали.
- Опускайте лишнюю пунктуацию, пока ясность не страдает.
Вот некоторые другие более существенные проблемы стиля, о которых нужно подумать: просто потому, что вы МОЖЕТЕ делать что-то определенным образом, не означает, что вы ДОЛЖНЫ делать это таким образом. Perl разработан, чтобы дать вам несколько способов сделать что-нибудь, поэтому подумайте о выборе наиболее читабельного. Например —
open(FOO,$foo) || die "Can't open $foo: $!";
Лучше чем —
die "Can't open $foo: $!" unless open(FOO,$foo);
Потому что второй способ скрывает основной смысл утверждения в модификаторе. С другой стороны,
print "Starting analysis\n" if $verbose;
Лучше чем —
$verbose && print "Starting analysis\n";
Потому что главное не в том, набрал ли пользователь -v или нет.
Не делайте глупых искажений, чтобы выйти из цикла сверху или снизу, когда Perl предоставляет последний оператор, чтобы вы могли выйти посередине. Просто немного «обошли», чтобы сделать его более заметным —
LINE: for (;;) { statements; last LINE if $foo; next LINE if /^#/; statements; }
Давайте посмотрим еще несколько важных моментов —
-
Не бойтесь использовать метки циклов — они предназначены для улучшения читабельности, а также для разрешения многоуровневых разрывов циклов. Смотрите предыдущий пример.
-
Избегайте использования grep () (или map ()) или `backticks` в пустом контексте, то есть когда вы просто отбрасываете их возвращаемые значения. Все эти функции имеют возвращаемые значения, поэтому используйте их. В противном случае используйте вместо этого цикл foreach () или функцию system ().
-
Для мобильности, при использовании функций, которые могут быть реализованы не на каждой машине, протестируйте конструкцию в eval, чтобы увидеть, не сработает ли она. Если вы знаете, в какой версии или уровне исправления была реализована конкретная функция, вы можете проверить $] ($ PERL_VERSION на английском языке), чтобы увидеть, будет ли она там. Модуль Config также позволяет запрашивать значения, определенные программой Configure при установке Perl.
-
Выберите мнемонические идентификаторы. Если вы не можете вспомнить, что означает мнемоника, у вас есть проблема.
-
Хотя короткие идентификаторы, такие как $ gotit, вероятно, подходят, используйте подчеркивание для разделения слов в более длинных идентификаторах. Как правило, легче читать $ var_names_like_this, чем $ VarNamesLikeThis, особенно для не носителей английского языка. Это также простое правило, которое работает в соответствии с VAR_NAMES_LIKE_THIS.
-
Имена пакетов иногда являются исключением из этого правила. Perl неофициально резервирует имена модулей в нижнем регистре для таких «прагматических» модулей, как integer и strict. Другие модули должны начинаться с заглавной буквы и использовать смешанный регистр, но, вероятно, без подчеркивания из-за ограничений в представлениях примитивных файловых систем имен модулей в виде файлов, которые должны вмещаться в несколько разреженных байтов.
-
Если у вас по-настоящему волосатое регулярное выражение, используйте модификатор / x и вставьте несколько пробелов, чтобы оно выглядело чуть менее как шум строки. Не используйте косую черту в качестве разделителя, если ваше регулярное выражение имеет косую черту или обратную косую черту.
-
Всегда проверяйте коды возврата системных вызовов. Хорошие сообщения об ошибках должны отправляться в STDERR, в том числе указывать, какая программа вызвала проблему, какими были сбойный системный вызов и аргументы, и (ОЧЕНЬ ВАЖНО) должно содержать стандартное системное сообщение об ошибке, указывающее, что произошло не так. Вот простой, но достаточный пример —
Не бойтесь использовать метки циклов — они предназначены для улучшения читабельности, а также для разрешения многоуровневых разрывов циклов. Смотрите предыдущий пример.
Избегайте использования grep () (или map ()) или `backticks` в пустом контексте, то есть когда вы просто отбрасываете их возвращаемые значения. Все эти функции имеют возвращаемые значения, поэтому используйте их. В противном случае используйте вместо этого цикл foreach () или функцию system ().
Для мобильности, при использовании функций, которые могут быть реализованы не на каждой машине, протестируйте конструкцию в eval, чтобы увидеть, не сработает ли она. Если вы знаете, в какой версии или уровне исправления была реализована конкретная функция, вы можете проверить $] ($ PERL_VERSION на английском языке), чтобы увидеть, будет ли она там. Модуль Config также позволяет запрашивать значения, определенные программой Configure при установке Perl.
Выберите мнемонические идентификаторы. Если вы не можете вспомнить, что означает мнемоника, у вас есть проблема.
Хотя короткие идентификаторы, такие как $ gotit, вероятно, подходят, используйте подчеркивание для разделения слов в более длинных идентификаторах. Как правило, легче читать $ var_names_like_this, чем $ VarNamesLikeThis, особенно для не носителей английского языка. Это также простое правило, которое работает в соответствии с VAR_NAMES_LIKE_THIS.
Имена пакетов иногда являются исключением из этого правила. Perl неофициально резервирует имена модулей в нижнем регистре для таких «прагматических» модулей, как integer и strict. Другие модули должны начинаться с заглавной буквы и использовать смешанный регистр, но, вероятно, без подчеркивания из-за ограничений в представлениях примитивных файловых систем имен модулей в виде файлов, которые должны вмещаться в несколько разреженных байтов.
Если у вас по-настоящему волосатое регулярное выражение, используйте модификатор / x и вставьте несколько пробелов, чтобы оно выглядело чуть менее как шум строки. Не используйте косую черту в качестве разделителя, если ваше регулярное выражение имеет косую черту или обратную косую черту.
Всегда проверяйте коды возврата системных вызовов. Хорошие сообщения об ошибках должны отправляться в STDERR, в том числе указывать, какая программа вызвала проблему, какими были сбойный системный вызов и аргументы, и (ОЧЕНЬ ВАЖНО) должно содержать стандартное системное сообщение об ошибке, указывающее, что произошло не так. Вот простой, но достаточный пример —
opendir(D, $dir) or die "can't opendir $dir: $!";
-
Подумайте о возможности повторного использования. Зачем тратить мозги на один выстрел, если вам захочется сделать что-то подобное снова? Подумайте об обобщении вашего кода. Попробуйте написать модуль или класс объектов. Подумайте над тем, чтобы ваш код выполнялся чисто с использованием строгих правил и с использованием предупреждений (или -w). Подумайте о том, чтобы отдать свой код. Подумайте об изменении вашего взгляда на мир. Подумай … о, неважно.
-
Быть последовательным.
-
Будь милым
Подумайте о возможности повторного использования. Зачем тратить мозги на один выстрел, если вам захочется сделать что-то подобное снова? Подумайте об обобщении вашего кода. Попробуйте написать модуль или класс объектов. Подумайте над тем, чтобы ваш код выполнялся чисто с использованием строгих правил и с использованием предупреждений (или -w). Подумайте о том, чтобы отдать свой код. Подумайте об изменении вашего взгляда на мир. Подумай … о, неважно.
Быть последовательным.
Будь милым
Perl — регулярные выражения
Регулярное выражение — это строка символов, которая определяет шаблон или шаблоны, которые вы просматриваете. Синтаксис регулярных выражений в Perl очень похож на тот, который вы найдете в других программах, поддерживающих регулярные выражения, таких как sed , grep и awk .
Основной метод применения регулярного выражения — использовать операторы привязки к шаблону = ~ и ! ~. Первый оператор — это оператор тестирования и присваивания.
В Perl есть три оператора регулярных выражений.
- Соответствие регулярному выражению — m //
- Заменить регулярное выражение — s ///
- Транслитерационное регулярное выражение — tr ///
Прямая косая черта в каждом случае действует как разделитель для заданного вами регулярного выражения (регулярное выражение). Если вас устраивает любой другой разделитель, то вы можете использовать вместо косой черты.
Оператор матча
Оператор соответствия m // используется для сопоставления строки или оператора с регулярным выражением. Например, чтобы сопоставить последовательность символов «foo» со скалярным $ bar, вы можете использовать выражение вроде этого —
#!/usr/bin/perl $bar = "This is foo and again foo"; if ($bar =~ /foo/) { print "First time is matching\n"; } else { print "First time is not matching\n"; } $bar = "foo"; if ($bar =~ /foo/) { print "Second time is matching\n"; } else { print "Second time is not matching\n"; }
Когда вышеуказанная программа выполняется, она дает следующий результат —
First time is matching Second time is matching
На самом деле m // работает так же, как оператор серии q //. Вы можете использовать любую комбинацию естественно совпадающих символов, чтобы действовать в качестве разделителей для выражения. Например, m {}, m () и m> <являются действительными. Таким образом, приведенный выше пример можно переписать следующим образом:
#!/usr/bin/perl $bar = "This is foo and again foo"; if ($bar =~ m[foo]) { print "First time is matching\n"; } else { print "First time is not matching\n"; } $bar = "foo"; if ($bar =~ m{foo}) { print "Second time is matching\n"; } else { print "Second time is not matching\n"; }
Вы можете опустить m из m //, если разделители являются косыми чертами, но для всех других разделителей вы должны использовать префикс m.
Обратите внимание, что все выражение соответствия, то есть выражение слева от = ~ или! ~ И оператор соответствия, возвращает true (в скалярном контексте), если выражение соответствует. Поэтому утверждение —
$true = ($foo =~ m/foo/);
установит $ true в 1, если $ foo соответствует регулярному выражению, или 0, если совпадение не удастся. В контексте списка совпадение возвращает содержимое любых сгруппированных выражений. Например, при извлечении часов, минут и секунд из строки времени мы можем использовать —
my ($hours, $minutes, $seconds) = ($time =~ m/(\d+):(\d+):(\d+)/);
Модификаторы Оператора Матча
Оператор соответствия поддерживает свой собственный набор модификаторов. Модификатор / g допускает глобальное сопоставление. Модификатор / i сделает регистр нечувствительным к регистру. Вот полный список модификаторов
| Sr.No. | Модификатор и описание |
|---|---|
| 1 |
я Делает регистр нечувствительным к регистру. |
| 2 |
м Указывает, что если строка содержит символы новой строки или возврата каретки, операторы ^ и $ теперь будут сопоставляться с границей новой строки вместо границы строки. |
| 3 |
о Оценивает выражение только один раз. |
| 4 |
s Позволяет использовать. соответствовать символу новой строки. |
| 5 |
Икс Позволяет вам использовать пробел в выражении для ясности. |
| 6 |
г Глобально находит все совпадения. |
| 7 |
CG Позволяет продолжить поиск даже после сбоя глобального сопоставления. |
я
Делает регистр нечувствительным к регистру.
м
Указывает, что если строка содержит символы новой строки или возврата каретки, операторы ^ и $ теперь будут сопоставляться с границей новой строки вместо границы строки.
о
Оценивает выражение только один раз.
s
Позволяет использовать. соответствовать символу новой строки.
Икс
Позволяет вам использовать пробел в выражении для ясности.
г
Глобально находит все совпадения.
CG
Позволяет продолжить поиск даже после сбоя глобального сопоставления.
Соответствует только один раз
Существует также более простая версия оператора сопоставления — «PATTERN». оператор. Это в основном идентично оператору m //, за исключением того, что оно совпадает только один раз в строке, которую вы ищете между каждым вызовом reset.
Например, вы можете использовать это, чтобы получить первый и последний элементы в списке —
#!/usr/bin/perl @list = qw/food foosball subeo footnote terfoot canic footbrdige/; foreach (@list) { $first = $1 if /(foo.*?)/; $last = $1 if /(foo.*)/; } print "First: $first, Last: $last\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
First: foo, Last: footbrdige
Переменные регулярного выражения
Переменные регулярного выражения включают в себя $ , который содержит все совпадения последнего совпадения группировки; $ & , который содержит всю совпавшую строку; $ ` , который содержит все перед соответствующей строкой; и $ ‘ , который содержит все после соответствующей строки. Следующий код демонстрирует результат —
#!/usr/bin/perl $string = "The food is in the salad bar"; $string =~ m/foo/; print "Before: $`\n"; print "Matched: $&\n"; print "After: $'\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Before: The Matched: foo After: d is in the salad bar
Оператор замещения
Оператор подстановки, s ///, на самом деле является просто расширением оператора сопоставления, который позволяет заменить сопоставляемый текст новым текстом. Основная форма оператора —
s/PATTERN/REPLACEMENT/;
PATTERN — это регулярное выражение для текста, который мы ищем. REPLACEMENT — это спецификация для текста или регулярного выражения, которую мы хотим использовать для замены найденного текста. Например, мы можем заменить все вхождения собаки на кошку, используя следующее регулярное выражение —
#/user/bin/perl $string = "The cat sat on the mat"; $string =~ s/cat/dog/; print "$string\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
The dog sat on the mat
Модификаторы оператора замещения
Вот список всех модификаторов, используемых с оператором подстановки.
| Sr.No. | Модификатор и описание |
|---|---|
| 1 |
я Делает регистр нечувствительным к регистру. |
| 2 |
м Указывает, что если строка содержит символы новой строки или возврата каретки, операторы ^ и $ теперь будут сопоставляться с границей новой строки вместо границы строки. |
| 3 |
о Оценивает выражение только один раз. |
| 4 |
s Позволяет использовать. соответствовать символу новой строки. |
| 5 |
Икс Позволяет вам использовать пробел в выражении для ясности. |
| 6 |
г Заменяет все вхождения найденного выражения текстом замены. |
| 7 |
е Оценивает замену, как если бы это был оператор Perl, и использует возвращаемое значение в качестве текста замены. |
я
Делает регистр нечувствительным к регистру.
м
Указывает, что если строка содержит символы новой строки или возврата каретки, операторы ^ и $ теперь будут сопоставляться с границей новой строки вместо границы строки.
о
Оценивает выражение только один раз.
s
Позволяет использовать. соответствовать символу новой строки.
Икс
Позволяет вам использовать пробел в выражении для ясности.
г
Заменяет все вхождения найденного выражения текстом замены.
е
Оценивает замену, как если бы это был оператор Perl, и использует возвращаемое значение в качестве текста замены.
Оператор перевода
Перевод аналогичен, но не идентичен принципам замещения, но в отличие от замещения, перевод (или транслитерация) не использует регулярные выражения для поиска значений замены. Операторы перевода —
tr/SEARCHLIST/REPLACEMENTLIST/cds y/SEARCHLIST/REPLACEMENTLIST/cds
Перевод заменяет все вхождения символов в SEARCHLIST на соответствующие символы в REPLACEMENTLIST. Например, используя «Кошка села на коврик». Строка, которую мы использовали в этой главе —
#/user/bin/perl $string = 'The cat sat on the mat'; $string =~ tr/a/o/; print "$string\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
The cot sot on the mot.
Также можно использовать стандартные диапазоны Perl, что позволяет указывать диапазоны символов либо по буквам, либо по числовым значениям. Чтобы изменить регистр строки, вы можете использовать следующий синтаксис вместо функции uc .
$string =~ tr/a-z/A-Z/;
Модификаторы оператора перевода
Ниже приведен список операторов, связанных с переводом.
| Sr.No. | Модификатор и описание |
|---|---|
| 1 |
с Дополняет ПОИСК. |
| 2 |
d Удаляет найденные, но не замененные символы. |
| 3 |
s Сквош дублирует замененные символы. |
с
Дополняет ПОИСК.
d
Удаляет найденные, но не замененные символы.
s
Сквош дублирует замененные символы.
Модификатор / d удаляет символы, соответствующие SEARCHLIST, для которых нет соответствующей записи в REPLACEMENTLIST. Например —
#!/usr/bin/perl $string = 'the cat sat on the mat.'; $string =~ tr/a-z/b/d; print "$string\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
b b b.
Последний модификатор, / s, удаляет повторяющиеся последовательности символов, которые были заменены, поэтому —
#!/usr/bin/perl $string = 'food'; $string = 'food'; $string =~ tr/a-z/a-z/s; print "$string\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
fod
Более сложные регулярные выражения
Вам не нужно просто сопоставлять фиксированные строки. Фактически, вы можете сопоставить практически все, о чем мечтали, используя более сложные регулярные выражения. Вот быстрый шпаргалка —
В следующей таблице приведен синтаксис регулярного выражения, доступный в Python.
| Sr.No. | Шаблон и описание |
|---|---|
| 1 |
^ Соответствует началу строки. |
| 2 |
$ Соответствует концу строки. |
| 3 |
, Соответствует любому отдельному символу, кроме новой строки. Использование опции m позволяет ему соответствовать новой строке. |
| 4 |
[…] Соответствует любому отдельному символу в скобках. |
| 5 |
[^ …] Соответствует любому отдельному символу не в скобках. |
| 6 |
* Соответствует 0 или более вхождений предыдущего выражения. |
| 7 |
+ Соответствует 1 или более вхождению предыдущего выражения. |
| 8 |
? Соответствует 0 или 1 вхождению предыдущего выражения. |
| 9 |
{n} Совпадает ровно с числом вхождений предыдущего выражения. |
| 10 |
{п,} Соответствует n или более вхождений предыдущего выражения. |
| 11 |
{п, м} Соответствует не менее n и не более m вхождений предшествующего выражения. |
| 12 |
| б Соответствует либо a, либо b. |
| 13 |
\ ш Соответствует символам слова. |
| 14 |
\ W Соответствует несловесным персонажам. |
| 15 |
\ s Соответствует пробелу. Эквивалентно [\ t \ n \ r \ f]. |
| 16 |
\ S Соответствует непробельному пространству. |
| 17 |
\ d Соответствует цифрам. Эквивалентно [0-9]. |
| 18 |
\ D Соответствует нецифровым значениям. |
| 19 |
\ A Соответствует началу строки. |
| 20 |
\ Z Соответствует концу строки. Если новая строка существует, она совпадает непосредственно перед новой строкой. |
| 21 |
\ г Соответствует концу строки. |
| 22 |
\Г Точки совпадений, где последний матч закончился. |
| 23 |
\ б Соответствует границам слов, когда они выходят за скобки. Соответствует Backspace (0x08) внутри скобок. |
| 24 |
\ B Соответствует безсловным границам. |
| 25 |
\ n, \ t и т. д. Сопоставляет переводы строк, возврат каретки, вкладки и т. Д. |
| 26 |
\ 1 … \ 9 Соответствует n-му сгруппированному подвыражению. |
| 27 |
\ 10 Соответствует n-му сгруппированному подвыражению, если оно уже найдено. В противном случае относится к восьмеричному представлению кода символа. |
| 28 |
[AEIOU] Соответствует одному символу в данном наборе |
| 29 |
[^ AEIOU] Соответствует одному символу за пределами данного набора |
^
Соответствует началу строки.
$
Соответствует концу строки.
,
Соответствует любому отдельному символу, кроме новой строки. Использование опции m позволяет ему соответствовать новой строке.
[…]
Соответствует любому отдельному символу в скобках.
[^ …]
Соответствует любому отдельному символу не в скобках.
*
Соответствует 0 или более вхождений предыдущего выражения.
+
Соответствует 1 или более вхождению предыдущего выражения.
?
Соответствует 0 или 1 вхождению предыдущего выражения.
{n}
Совпадает ровно с числом вхождений предыдущего выражения.
{п,}
Соответствует n или более вхождений предыдущего выражения.
{п, м}
Соответствует не менее n и не более m вхождений предшествующего выражения.
| б
Соответствует либо a, либо b.
\ ш
Соответствует символам слова.
\ W
Соответствует несловесным персонажам.
\ s
Соответствует пробелу. Эквивалентно [\ t \ n \ r \ f].
\ S
Соответствует непробельному пространству.
\ d
Соответствует цифрам. Эквивалентно [0-9].
\ D
Соответствует нецифровым значениям.
\ A
Соответствует началу строки.
\ Z
Соответствует концу строки. Если новая строка существует, она совпадает непосредственно перед новой строкой.
\ г
Соответствует концу строки.
\Г
Точки совпадений, где последний матч закончился.
\ б
Соответствует границам слов, когда они выходят за скобки. Соответствует Backspace (0x08) внутри скобок.
\ B
Соответствует безсловным границам.
\ n, \ t и т. д.
Сопоставляет переводы строк, возврат каретки, вкладки и т. Д.
\ 1 … \ 9
Соответствует n-му сгруппированному подвыражению.
\ 10
Соответствует n-му сгруппированному подвыражению, если оно уже найдено. В противном случае относится к восьмеричному представлению кода символа.
[AEIOU]
Соответствует одному символу в данном наборе
[^ AEIOU]
Соответствует одному символу за пределами данного набора
Метасимвол ^ соответствует началу строки, а метасимвол $ соответствует концу строки. Вот несколько кратких примеров.
# nothing in the string (start and end are adjacent) /^$/ # a three digits, each followed by a whitespace # character (eg "3 4 5 ") /(\d\s) {3}/ # matches a string in which every # odd-numbered letter is a (eg "abacadaf") /(a.)+/ # string starts with one or more digits /^\d+/ # string that ends with one or more digits /\d+$/
Давайте посмотрим на другой пример.
#!/usr/bin/perl $string = "Cats go Catatonic\nWhen given Catnip"; ($start) = ($string =~ /\A(.*?) /); @lines = $string =~ /^(.*?) /gm; print "First word: $start\n","Line starts: @lines\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
First word: Cats Line starts: Cats When
Соответствующие границы
\ B соответствует любой границе слова, как это определено разницей между классом \ w и классом \ W. Поскольку \ w включает символы для слова, а \ W наоборот, это обычно означает завершение слова. Утверждение \ B соответствует любой позиции, которая не является границей слова. Например —
/\bcat\b/ # Matches 'the cat sat' but not 'cat on the mat' /\Bcat\B/ # Matches 'verification' but not 'the cat on the mat' /\bcat\B/ # Matches 'catatonic' but not 'polecat' /\Bcat\b/ # Matches 'polecat' but not 'catatonic'
Выбор альтернатив
| символ такой же, как стандартный или побитовый ИЛИ в Perl. Он определяет альтернативные совпадения внутри регулярного выражения или группы. Например, чтобы соответствовать «коту» или «собаке» в выражении, вы можете использовать это —
if ($string =~ /cat|dog/)
Вы можете сгруппировать отдельные элементы выражения вместе, чтобы поддерживать сложные совпадения. Поиск имен двух людей можно выполнить с помощью двух отдельных тестов, например:
if (($string =~ /Martin Brown/) || ($string =~ /Sharon Brown/)) This could be written as follows if ($string =~ /(Martin|Sharon) Brown/)
Группировка соответствия
С точки зрения регулярного выражения, нет никакой разницы между, за исключением, возможно, того, что первое немного яснее.
$string =~ /(\S+)\s+(\S+)/; and $string =~ /\S+\s+\S+/;
Однако преимущество группировки заключается в том, что она позволяет нам извлекать последовательность из регулярного выражения. Группировки возвращаются в виде списка в порядке их появления в оригинале. Например, в следующем фрагменте мы извлекли часы, минуты и секунды из строки.
my ($hours, $minutes, $seconds) = ($time =~ m/(\d+):(\d+):(\d+)/);
Как и этот прямой метод, соответствующие группы также доступны в специальных переменных $ x, где x — номер группы в регулярном выражении. Поэтому мы могли бы переписать предыдущий пример следующим образом:
#!/usr/bin/perl $time = "12:05:30"; $time =~ m/(\d+):(\d+):(\d+)/; my ($hours, $minutes, $seconds) = ($1, $2, $3); print "Hours : $hours, Minutes: $minutes, Second: $seconds\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Hours : 12, Minutes: 05, Second: 30
Когда группы используются в выражениях подстановки, в тексте замены можно использовать синтаксис $ x. Таким образом, мы могли бы переформатировать строку даты, используя это —
#!/usr/bin/perl $date = '03/26/1999'; $date =~ s#(\d+)/(\d+)/(\d+)#$3/$1/$2#; print "$date\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
1999/03/26
Утверждение \ G
Утверждение \ G позволяет вам продолжить поиск с того места, где произошло последнее совпадение. Например, в следующем коде мы использовали \ G, чтобы мы могли искать в правильной позиции и затем извлекать некоторую информацию, не создавая более сложного единственного регулярного выражения —
#!/usr/bin/perl $string = "The time is: 12:31:02 on 4/12/00"; $string =~ /:\s+/g; ($time) = ($string =~ /\G(\d+:\d+:\d+)/); $string =~ /.+\s+/g; ($date) = ($string =~ m{\G(\d+/\d+/\d+)}); print "Time: $time, Date: $date\n";
Когда вышеуказанная программа выполняется, она дает следующий результат —
Time: 12:31:02, Date: 4/12/00
Утверждение \ G на самом деле является метасимволом эквивалента функции pos, поэтому между вызовами регулярного выражения вы можете продолжать использовать pos и даже изменить значение pos (и, следовательно, \ G), используя pos в качестве подпрограммы lvalue.
Примеры регулярных выражений
Буквальные символы
| Sr.No. | Пример и описание |
|---|---|
| 1 |
Perl Матч «Перл». |
Perl
Матч «Перл».
Классы персонажей
| Sr.No. | Пример и описание |
|---|---|
| 1 |
[Рр] ython Соответствует «Python» или «Python» |
| 2 |
руб [вы] Совпадает «рубин» или «рубин» |
| 3 |
[AEIOU] Соответствует любой строчной гласной |
| 4 |
[0-9] Соответствует любой цифре; такой же как [0123456789] |
| 5 |
[AZ] Соответствует любой строчной букве ASCII |
| 6 |
[AZ] Соответствует любой прописной букве ASCII |
| 7 |
[A-Za-Z0-9] Соответствует любому из вышеперечисленного |
| 8 |
[^ AEIOU] Совпадает с чем угодно, кроме строчной гласной |
| 9 |
[^ 0-9] Совпадает с чем угодно, кроме цифры |
[Рр] ython
Соответствует «Python» или «Python»
руб [вы]
Совпадает «рубин» или «рубин»
[AEIOU]
Соответствует любой строчной гласной
[0-9]
Соответствует любой цифре; такой же как [0123456789]
[AZ]
Соответствует любой строчной букве ASCII
[AZ]
Соответствует любой прописной букве ASCII
[A-Za-Z0-9]
Соответствует любому из вышеперечисленного
[^ AEIOU]
Совпадает с чем угодно, кроме строчной гласной
[^ 0-9]
Совпадает с чем угодно, кроме цифры
Классы специальных символов
| Sr.No. | Пример и описание |
|---|---|
| 1 |
, Соответствует любому символу, кроме новой строки |
| 2 |
\ d Соответствует цифре: [0-9] |
| 3 |
\ D Совпадает с нецифровой цифрой: [^ 0-9] |
| 4 |
\ s Соответствует пробелу: [\ t \ r \ n \ f] |
| 5 |
\ S Совпадает с незаполненными пробелами: [^ \ t \ r \ n \ f] |
| 6 |
\ ш Соответствует отдельному слову: [A-Za-z0-9_] |
| 7 |
\ W Соответствует несловесному символу: [^ A-Za-z0-9_] |
,
Соответствует любому символу, кроме новой строки
\ d
Соответствует цифре: [0-9]
\ D
Совпадает с нецифровой цифрой: [^ 0-9]
\ s
Соответствует пробелу: [\ t \ r \ n \ f]
\ S
Совпадает с незаполненными пробелами: [^ \ t \ r \ n \ f]
\ ш
Соответствует отдельному слову: [A-Za-z0-9_]
\ W
Соответствует несловесному символу: [^ A-Za-z0-9_]
Случаи повторения
| Sr.No. | Пример и описание |
|---|---|
| 1 |
Рубин? Совпадает с «rub» или «ruby»: y является необязательным |
| 2 |
Рубин* Совпадения «руб» плюс 0 или более лет |
| 3 |
рубин + Совпадения «руб» плюс 1 или более лет |
| 4 |
\ д {3} Точно соответствует 3 цифрам |
| 5 |
\ д {3} Соответствует 3 или более цифрам |
| 6. |
\ д {3,5} Соответствует 3, 4 или 5 цифрам |
Рубин?
Совпадает с «rub» или «ruby»: y является необязательным
Рубин*
Совпадения «руб» плюс 0 или более лет
рубин +
Совпадения «руб» плюс 1 или более лет
\ д {3}
Точно соответствует 3 цифрам
\ д {3}
Соответствует 3 или более цифрам
\ д {3,5}
Соответствует 3, 4 или 5 цифрам
Нечестивое Повторение
Это соответствует наименьшему количеству повторений —
| Sr.No. | Пример и описание |
|---|---|
| 1 |
<. *> Жадное повторение: соответствует «<python> perl>» |
| 2 |
<. *?> Nongreedy: соответствует «<python>» в «<python> perl>» |
<. *>
Жадное повторение: соответствует «<python> perl>»
<. *?>
Nongreedy: соответствует «<python>» в «<python> perl>»
Группировка с круглыми скобками
| Sr.No. | Пример и описание |
|---|---|
| 1 |
\ D \ D + Нет группы: + повторяется \ d |
| 2 |
(\ D \ d) + Сгруппировано: + повторяет \ D \ d пару |
| 3 |
([Pp] ython (,)?) + Совпадение «Питон», «Питон, питон, питон» и т. Д. |
\ D \ D +
Нет группы: + повторяется \ d
(\ D \ d) +
Сгруппировано: + повторяет \ D \ d пару
([Pp] ython (,)?) +
Совпадение «Питон», «Питон, питон, питон» и т. Д.
Обратные
Это снова соответствует ранее подобранной группе —
| Sr.No. | Пример и описание |
|---|---|
| 1 |
([Рр]) ython & \ 1ails Соответствует питону и ведрам или питону и ведрам |
| 2 |
([ ‘ «]) [^ \ 1] * \ 1 Строка в одинарных или двойных кавычках. \ 1 соответствует любому совпадению 1-й группы. \ 2 соответствует любому совпадению 2-й группы и т. Д. |
([Рр]) ython & \ 1ails
Соответствует питону и ведрам или питону и ведрам
([ ‘ «]) [^ \ 1] * \ 1
Строка в одинарных или двойных кавычках. \ 1 соответствует любому совпадению 1-й группы. \ 2 соответствует любому совпадению 2-й группы и т. Д.
альтернативы
| Sr.No. | Пример и описание |
|---|---|
| 1 |
питон | Perl Соответствует «python» или «perl» |
| 2 |
руб (у | ль)) Совпадает «рубин» или «рубль» |
| 3 |
Python (+ |!? \) «Питон», за которым следует один или несколько! или один? |
питон | Perl
Соответствует «python» или «perl»
руб (у | ль))
Совпадает «рубин» или «рубль»
Python (+ |!? \)
«Питон», за которым следует один или несколько! или один?
Якоря
Для этого нужно указать совпадающие позиции.
| Sr.No. | Пример и описание |
|---|---|
| 1 |
^ Python Соответствует «Python» в начале строки или внутренней строки |
| 2 |
Python $ Соответствует «Python» в конце строки или строки |
| 3 |
\ APython Соответствует «Python» в начале строки |
| 4 |
Python \ Z Соответствует «Python» в конце строки |
| 5 |
\ bPython \ б Соответствует «Python» на границе слова |
| 6 |
\ brub \ B \ B является границей без слов: соответствует «rub» в «rube» и «ruby», но не в одиночку |
| 7 |
Python (?! =) Соответствует «Python», если после него стоит восклицательный знак |
| 8 |
Python (? !!) Соответствует «Python», если после него не стоит восклицательный знак |
^ Python
Соответствует «Python» в начале строки или внутренней строки
Python $
Соответствует «Python» в конце строки или строки
\ APython
Соответствует «Python» в начале строки
Python \ Z
Соответствует «Python» в конце строки
\ bPython \ б
Соответствует «Python» на границе слова
\ brub \ B
\ B является границей без слов: соответствует «rub» в «rube» и «ruby», но не в одиночку
Python (?! =)
Соответствует «Python», если после него стоит восклицательный знак
Python (? !!)
Соответствует «Python», если после него не стоит восклицательный знак
Специальный синтаксис с круглыми скобками
| Sr.No. | Пример и описание |
|---|---|
| 1 |
R (? # Комментарий) Спички «R». Все остальное — комментарий |
| 2 |
R (? Я) убий Учитывает регистр при сопоставлении «uby» |
| 3 |
R (I: убий) То же, что и выше |
| 4 |
руб: |) (у ля?) Группировать только без создания \ 1 обратной ссылки |
R (? # Комментарий)
Спички «R». Все остальное — комментарий
R (? Я) убий
Учитывает регистр при сопоставлении «uby»
R (I: убий)
То же, что и выше
руб: |) (у ля?)
Группировать только без создания \ 1 обратной ссылки
Perl — отправка электронной почты
Использование утилиты sendmail
Отправка простого сообщения
Если вы работаете на Linux / Unix-машине, вы можете просто использовать утилиту sendmail внутри вашей Perl-программы для отправки электронной почты. Вот пример сценария, который может отправить электронное письмо на указанный идентификатор электронной почты. Просто убедитесь, что указан правильный путь для утилиты sendmail. Это может отличаться для вашей машины Linux / Unix.
#!/usr/bin/perl $to = 'abcd@gmail.com'; $from = 'webmaster@yourdomain.com'; $subject = 'Test Email'; $message = 'This is test email sent by Perl Script'; open(MAIL, "|/usr/sbin/sendmail -t"); # Email Header print MAIL "To: $to\n"; print MAIL "From: $from\n"; print MAIL "Subject: $subject\n\n"; # Email Body print MAIL $message; close(MAIL); print "Email Sent Successfully\n";
На самом деле, приведенный выше скрипт является клиентским почтовым скриптом, который будет чертить электронную почту и отправлять ее на сервер, работающий локально на вашем компьютере с Linux / Unix. Этот скрипт не будет нести ответственность за отправку электронной почты в фактическое место назначения. Таким образом, вы должны убедиться, что почтовый сервер правильно настроен и работает на вашем компьютере, чтобы отправлять электронную почту на указанный электронный адрес.
Отправка сообщения HTML
Если вы хотите отправлять электронную почту в формате HTML с использованием sendmail, вам просто нужно добавить Content-type: text / html \ n в часть заголовка письма следующим образом:
#!/usr/bin/perl $to = 'abcd@gmail.com'; $from = 'webmaster@yourdomain.com'; $subject = 'Test Email'; $message = '<h1>This is test email sent by Perl Script</h1>'; open(MAIL, "|/usr/sbin/sendmail -t"); # Email Header print MAIL "To: $to\n"; print MAIL "From: $from\n"; print MAIL "Subject: $subject\n\n"; print MAIL "Content-type: text/html\n"; # Email Body print MAIL $message; close(MAIL); print "Email Sent Successfully\n";
Использование модуля MIME :: Lite
Если вы работаете на машине с Windows, то у вас не будет доступа к утилите sendmail. Но у вас есть альтернатива написать свой собственный почтовый клиент, используя модуль Perl MIME: Lite. Вы можете скачать этот модуль с MIME-Lite-3.01.tar.gz и установить его на свой компьютер Windows или Linux / Unix. Чтобы установить его, следуйте простым шагам —
$tar xvfz MIME-Lite-3.01.tar.gz $cd MIME-Lite-3.01 $perl Makefile.PL $make $make install
Вот и все, и у вас будет установлен модуль MIME :: Lite на вашем компьютере. Теперь вы готовы отправить свое письмо с помощью простых сценариев, описанных ниже.
Отправка простого сообщения
Теперь следующий скрипт, который позаботится об отправке электронной почты на указанный адрес электронной почты —
#!/usr/bin/perl use MIME::Lite; $to = 'abcd@gmail.com'; $cc = 'efgh@mail.com'; $from = 'webmaster@yourdomain.com'; $subject = 'Test Email'; $message = 'This is test email sent by Perl Script'; $msg = MIME::Lite->new( From => $from, To => $to, Cc => $cc, Subject => $subject, Data => $message ); $msg->send; print "Email Sent Successfully\n";
Отправка сообщения HTML
Если вы хотите отправлять электронную почту в формате HTML с помощью sendmail, вам просто нужно добавить Content-type: text / html \ n в заголовочную часть письма. Ниже приведен сценарий, который позаботится об отправке электронной почты в формате HTML.
#!/usr/bin/perl use MIME::Lite; $to = 'abcd@gmail.com'; $cc = 'efgh@mail.com'; $from = 'webmaster@yourdomain.com'; $subject = 'Test Email'; $message = '<h1>This is test email sent by Perl Script</h1>'; $msg = MIME::Lite->new( From => $from, To => $to, Cc => $cc, Subject => $subject, Data => $message ); $msg->attr("content-type" => "text/html"); $msg->send; print "Email Sent Successfully\n";
Отправка вложения
Если вы хотите отправить вложение, то следующий скрипт служит цели —
#!/usr/bin/perl use MIME::Lite; $to = 'abcd@gmail.com'; $cc = 'efgh@mail.com'; $from = 'webmaster@yourdomain.com'; $subject = 'Test Email'; $message = 'This is test email sent by Perl Script'; $msg = MIME::Lite-=>new( From => $from, To => $to, Cc => $cc, Subject => $subject, Type => 'multipart/mixed' ); # Add your text message. $msg->attach(Type => 'text', Data => $message ); # Specify your file as attachement. $msg->attach(Type => 'image/gif', Path => '/tmp/logo.gif', Filename => 'logo.gif', Disposition => 'attachment' ); $msg->send; print "Email Sent Successfully\n";
Вы можете прикрепить столько файлов, сколько захотите в своем электронном письме, используя метод attach ().
Использование SMTP-сервера
Если на вашем компьютере не работает почтовый сервер, вы можете использовать любой другой почтовый сервер, доступный в удаленном месте. Но для использования любого другого почтового сервера вам понадобится идентификатор, пароль, URL и т. Д. Получив всю необходимую информацию, вы просто должны предоставить эту информацию в методе send () следующим образом:
$msg->send('smtp', "smtp.myisp.net", AuthUser=>"id", AuthPass=>"password" );
Вы можете связаться с администратором своего почтового сервера, чтобы получить указанную выше информацию, и если идентификатор пользователя и пароль еще не доступны, ваш администратор может создать их за считанные минуты.
Perl — Socket Программирование
Что такое сокет?
Socket — это механизм Berkeley UNIX для создания виртуального дуплексного соединения между различными процессами. Позже это было перенесено на каждую известную ОС, обеспечивающую связь между системами в разных географических точках, работающих на разных ОС. Если бы не сокет, большая часть сетевого взаимодействия между системами никогда бы не произошла.
Приглядеться; типичная компьютерная система в сети получает и отправляет информацию по желанию различных приложений, работающих в ней. Эта информация направляется в систему, поскольку ей назначается уникальный IP-адрес. В системе эта информация передается соответствующим приложениям, которые прослушивают разные порты. Например, интернет-браузер прослушивает через порт 80 информацию, полученную с веб-сервера. Также мы можем написать наши пользовательские приложения, которые могут прослушивать и отправлять / получать информацию о конкретном номере порта.
А пока давайте подведем итог, что сокет — это IP-адрес и порт, позволяющий соединению отправлять и получать данные по сети.
Чтобы объяснить вышеупомянутую концепцию сокетов, мы возьмем пример программирования клиент-сервер с использованием Perl. Чтобы завершить архитектуру клиент-сервер, нам нужно пройти следующие шаги:
Создать сервер
-
Создайте сокет с помощью вызова сокета .
-
Свяжите сокет с адресом порта, используя вызов связывания .
-
Прослушивание сокета по адресу порта с помощью прослушивания вызова.
-
Примите клиентские соединения, используя принять вызов.
Создайте сокет с помощью вызова сокета .
Свяжите сокет с адресом порта, используя вызов связывания .
Прослушивание сокета по адресу порта с помощью прослушивания вызова.
Примите клиентские соединения, используя принять вызов.
Создать клиента
-
Создайте сокет с вызовом сокета .
-
Соединитесь (сокет) с сервером, используя вызов connect .
Создайте сокет с вызовом сокета .
Соединитесь (сокет) с сервером, используя вызов connect .
Следующая диаграмма показывает полную последовательность вызовов, используемых Клиентом и Сервером для связи друг с другом —
Звонки на стороне сервера
Вызов сокета ()
Вызов socket () является первым вызовом, при установлении сетевого соединения создается сокет. Этот вызов имеет следующий синтаксис —
socket( SOCKET, DOMAIN, TYPE, PROTOCOL );
Вышеуказанный вызов создает SOCKET, а остальные три аргумента являются целыми числами, которые должны иметь следующие значения для соединений TCP / IP.
-
ДОМЕН должен быть PF_INET. Это вероятно 2 на вашем компьютере.
-
TYPE должен быть SOCK_STREAM для соединения TCP / IP.
-
PROTOCOL должен быть (getprotobyname (‘tcp’)) [2] . Это особый протокол, такой как TCP, который будет передаваться через сокет.
ДОМЕН должен быть PF_INET. Это вероятно 2 на вашем компьютере.
TYPE должен быть SOCK_STREAM для соединения TCP / IP.
PROTOCOL должен быть (getprotobyname (‘tcp’)) [2] . Это особый протокол, такой как TCP, который будет передаваться через сокет.
Поэтому вызов функции сокета, выдаваемый сервером, будет выглядеть примерно так:
use Socket # This defines PF_INET and SOCK_STREAM socket(SOCKET,PF_INET,SOCK_STREAM,(getprotobyname('tcp'))[2]);
Вызов bind ()
Сокеты, созданные вызовом socket (), бесполезны, пока они не привязаны к имени хоста и номеру порта. Сервер использует следующую функцию bind () для указания порта, на котором они будут принимать подключения от клиентов.
bind( SOCKET, ADDRESS );
Здесь SOCKET — дескриптор, возвращаемый вызовом socket (), а ADDRESS — адрес сокета (для TCP / IP), содержащий три элемента:
-
Семейство адресов (для TCP / IP это AF_INET, вероятно, 2 в вашей системе).
-
Номер порта (например, 21).
-
Интернет-адрес компьютера (например, 10.12.12.168).
Семейство адресов (для TCP / IP это AF_INET, вероятно, 2 в вашей системе).
Номер порта (например, 21).
Интернет-адрес компьютера (например, 10.12.12.168).
Поскольку bind () используется сервером, которому не нужно знать собственный адрес, список аргументов выглядит следующим образом:
use Socket # This defines PF_INET and SOCK_STREAM $port = 12345; # The unique port used by the sever to listen requests $server_ip_address = "10.12.12.168"; bind( SOCKET, pack_sockaddr_in($port, inet_aton($server_ip_address))) or die "Can't bind to port $port! \n";
Предложение or die очень важно, потому что, если сервер умирает без ожидающих соединений, порт не будет немедленно повторно использован, если вы не используете опцию SO_REUSEADDR с помощью функции setsockopt () . Здесь функция pack_sockaddr_in () используется для упаковки порта и IP-адреса в двоичный формат.
Слушай () вызов
Если это серверная программа, то необходимо выполнить вызов listen () на указанном порту для прослушивания, т. Е. Дождаться входящих запросов. Этот вызов имеет следующий синтаксис —
listen( SOCKET, QUEUESIZE );
Вышеупомянутый вызов использует дескриптор SOCKET, возвращаемый вызовом socket (), а QUEUESIZE — это максимальное количество ожидающих запросов на соединение, разрешенных одновременно.
Принять () вызов
Если это серверная программа, то необходимо выполнить вызов функции access (), чтобы принять входящие соединения. Этот вызов имеет следующий синтаксис —
accept( NEW_SOCKET, SOCKET );
Прием вызова принимает дескриптор SOCKET, возвращаемый функцией socket (), и после успешного завершения возвращается новый дескриптор сокета NEW_SOCKET для всей будущей связи между клиентом и сервером. Если вызов access () не удался, он возвращает FLASE, который определен в модуле Socket, который мы использовали изначально.
Обычно accept () используется в бесконечном цикле. Как только приходит одно соединение, сервер либо создает дочерний процесс для его обработки, либо обслуживает его сам, а затем возвращается, чтобы прослушать другие соединения.
while(1) { accept( NEW_SOCKET, SOCKT ); ....... }
Теперь все вызовы, связанные с сервером, завершены, и давайте посмотрим вызов, который потребуется клиенту.
Звонки на стороне клиента
Вызов connect ()
Если вы собираетесь подготовить клиентскую программу, то сначала вы будете использовать вызов socket () для создания сокета, а затем вам придется использовать вызов connect () для подключения к серверу. Вы уже видели синтаксис вызова socket (), и он останется похожим на вызов сервера socket (), но вот синтаксис для вызова connect () —
connect( SOCKET, ADDRESS );
Здесь SCOKET — дескриптор сокета, возвращаемый вызовом socket (), выданным клиентом, а ADDRESS — адрес сокета, похожий на вызов связывания , за исключением того, что он содержит IP-адрес удаленного сервера.
$port = 21; # For example, the ftp port $server_ip_address = "10.12.12.168"; connect( SOCKET, pack_sockaddr_in($port, inet_aton($server_ip_address))) or die "Can't connect to port $port! \n";
Если вы успешно подключитесь к серверу, вы можете начать посылать свои команды на сервер, используя дескриптор SOCKET, иначе ваш клиент выйдет с сообщением об ошибке.
Пример клиент-сервер
Ниже приведен код на Perl для реализации простой клиент-серверной программы с использованием сокета Perl. Здесь сервер прослушивает входящие запросы и, как только соединение установлено, он просто отвечает Smile с сервера . Клиент читает это сообщение и печатает на экране. Давайте посмотрим, как это было сделано, если предположить, что наш сервер и клиент находятся на одной машине.
Скрипт для создания сервера
#!/usr/bin/perl -w # Filename : server.pl use strict; use Socket; # use port 7890 as default my $port = shift || 7890; my $proto = getprotobyname('tcp'); my $server = "localhost"; # Host IP running the server # create a socket, make it reusable socket(SOCKET, PF_INET, SOCK_STREAM, $proto) or die "Can't open socket $!\n"; setsockopt(SOCKET, SOL_SOCKET, SO_REUSEADDR, 1) or die "Can't set socket option to SO_REUSEADDR $!\n"; # bind to a port, then listen bind( SOCKET, pack_sockaddr_in($port, inet_aton($server))) or die "Can't bind to port $port! \n"; listen(SOCKET, 5) or die "listen: $!"; print "SERVER started on port $port\n"; # accepting a connection my $client_addr; while ($client_addr = accept(NEW_SOCKET, SOCKET)) { # send them a message, close connection my $name = gethostbyaddr($client_addr, AF_INET ); print NEW_SOCKET "Smile from the server"; print "Connection recieved from $name\n"; close NEW_SOCKET; }
Чтобы запустить сервер в фоновом режиме, введите в командной строке Unix следующую команду —
$perl sever.pl&
Скрипт для создания клиента
!/usr/bin/perl -w # Filename : client.pl use strict; use Socket; # initialize host and port my $host = shift || 'localhost'; my $port = shift || 7890; my $server = "localhost"; # Host IP running the server # create the socket, connect to the port socket(SOCKET,PF_INET,SOCK_STREAM,(getprotobyname('tcp'))[2]) or die "Can't create a socket $!\n"; connect( SOCKET, pack_sockaddr_in($port, inet_aton($server))) or die "Can't connect to port $port! \n"; my $line; while ($line = <SOCKET>) { print "$line\n"; } close SOCKET or die "close: $!";
Теперь давайте запустим наш клиент из командной строки, который подключится к серверу и прочитает сообщение, отправленное сервером, и отобразит его на экране следующим образом:
$perl client.pl Smile from the server
ПРИМЕЧАНИЕ. — Если вы указываете фактический IP-адрес в точечной нотации, рекомендуется указывать IP-адрес в одном и том же формате как на клиенте, так и на сервере, чтобы избежать путаницы.
Объектно-ориентированное программирование в PERL
Мы уже изучали ссылки на анонимные массивы и хэши Perl и Perl. Объектно-ориентированная концепция в Perl во многом основана на ссылках, анонимных массивах и хешах. Давайте начнем изучать основные понятия объектно-ориентированного Perl.
Основы объекта
Есть три основных термина, объясненных с точки зрения того, как Perl обрабатывает объекты. Термины объект, класс и метод.
-
Объект в Perl — это просто ссылка на тип данных, который знает, к какому классу он принадлежит. Объект хранится в виде ссылки в скалярной переменной. Поскольку скаляр содержит только ссылку на объект, один и тот же скаляр может содержать разные объекты в разных классах.
-
Класс в Perl — это пакет, который содержит соответствующие методы, необходимые для создания объектов и управления ими.
-
Метод в Perl — это подпрограмма, определенная пакетом. Первым аргументом метода является ссылка на объект или имя пакета, в зависимости от того, влияет ли метод на текущий объект или класс.
Объект в Perl — это просто ссылка на тип данных, который знает, к какому классу он принадлежит. Объект хранится в виде ссылки в скалярной переменной. Поскольку скаляр содержит только ссылку на объект, один и тот же скаляр может содержать разные объекты в разных классах.
Класс в Perl — это пакет, который содержит соответствующие методы, необходимые для создания объектов и управления ими.
Метод в Perl — это подпрограмма, определенная пакетом. Первым аргументом метода является ссылка на объект или имя пакета, в зависимости от того, влияет ли метод на текущий объект или класс.
Perl предоставляет функцию bless () , которая используется для возврата ссылки, которая в конечном итоге становится объектом.
Определение класса
Определить класс в Perl очень просто. Класс соответствует Пакету Perl в его самой простой форме. Чтобы создать класс в Perl, мы сначала собираем пакет.
Пакет — это автономная единица пользовательских переменных и подпрограмм, которые можно использовать снова и снова.
Пакеты Perl предоставляют отдельное пространство имен в программе Perl, в котором подпрограммы и переменные не зависят от конфликтующих с другими пакетами.
Чтобы объявить класс с именем Person в Perl, мы делаем —
package Person;
Область определения пакета распространяется до конца файла или до тех пор, пока не встретится другое ключевое слово пакета.
Создание и использование объектов
Для создания экземпляра класса (объекта) нам нужен конструктор объекта. Этот конструктор является методом, определенным в пакете. Большинство программистов предпочитают называть этот метод конструктора объекта новым, но в Perl вы можете использовать любое имя.
Вы можете использовать любой тип переменной Perl в качестве объекта в Perl. Большинство программистов на Perl выбирают либо ссылки на массивы, либо хэши.
Давайте создадим наш конструктор для нашего класса Person, используя ссылку на хеш Perl. При создании объекта вам необходимо предоставить конструктор, который является подпрограммой в пакете, который возвращает ссылку на объект. Ссылка на объект создается путем благословения ссылки на класс пакета. Например —
package Person; sub new { my $class = shift; my $self = { _firstName => shift, _lastName => shift, _ssn => shift, }; # Print all the values just for clarification. print "First Name is $self->{_firstName}\n"; print "Last Name is $self->{_lastName}\n"; print "SSN is $self->{_ssn}\n"; bless $self, $class; return $self; }
Теперь давайте посмотрим, как создать объект.
$object = new Person( "Mohammad", "Saleem", 23234345);
Вы можете использовать простой хеш в вашем констуркторе, если вы не хотите присваивать какое-либо значение какой-либо переменной класса. Например —
package Person; sub new { my $class = shift; my $self = {}; bless $self, $class; return $self; }
Определение методов
Другие объектно-ориентированные языки имеют концепцию безопасности данных для предотвращения непосредственного изменения программистом данных объекта и предоставляют методы доступа для изменения данных объекта. Perl не имеет закрытых переменных, но мы все еще можем использовать концепцию вспомогательных методов для манипулирования данными объекта.
Давайте определим вспомогательный метод, чтобы получить имя человека —
sub getFirstName { return $self->{_firstName}; }
Еще одна вспомогательная функция для установки имени человека —
sub setFirstName { my ( $self, $firstName ) = @_; $self->{_firstName} = $firstName if defined($firstName); return $self->{_firstName}; }
Теперь давайте рассмотрим полный пример: сохраните пакет Person и вспомогательные функции в файле Person.pm.
#!/usr/bin/perl package Person; sub new { my $class = shift; my $self = { _firstName => shift, _lastName => shift, _ssn => shift, }; # Print all the values just for clarification. print "First Name is $self->{_firstName}\n"; print "Last Name is $self->{_lastName}\n"; print "SSN is $self->{_ssn}\n"; bless $self, $class; return $self; } sub setFirstName { my ( $self, $firstName ) = @_; $self->{_firstName} = $firstName if defined($firstName); return $self->{_firstName}; } sub getFirstName { my( $self ) = @_; return $self->{_firstName}; } 1;
Теперь давайте используем объект Person в файле employee.pl следующим образом:
#!/usr/bin/perl use Person; $object = new Person( "Mohammad", "Saleem", 23234345); # Get first name which is set using constructor. $firstName = $object->getFirstName(); print "Before Setting First Name is : $firstName\n"; # Now Set first name using helper function. $object->setFirstName( "Mohd." ); # Now get first name set by helper function. $firstName = $object->getFirstName(); print "Before Setting First Name is : $firstName\n";
Когда мы выполняем вышеуказанную программу, она выдает следующий результат —
First Name is Mohammad Last Name is Saleem SSN is 23234345 Before Setting First Name is : Mohammad Before Setting First Name is : Mohd.
наследование
У объектно-ориентированного программирования есть очень хорошая и полезная концепция, называемая наследованием. Наследование просто означает, что свойства и методы родительского класса будут доступны дочерним классам. Таким образом, вам не нужно писать один и тот же код снова и снова, вы можете просто наследовать родительский класс.
Например, у нас может быть класс Employee, который наследуется от Person. Это называется отношениями isa, потому что работник — это человек. В Perl есть специальная переменная @ISA, чтобы помочь с этим. @ISA регулирует (метод) наследования.
Ниже приведены важные моменты, которые следует учитывать при использовании наследования:
-
Perl ищет в классе указанного объекта данный метод или атрибут, т. Е. Переменную.
-
Perl ищет классы, определенные в массиве @ISA класса объекта.
-
Если в шагах 1 или 2 метод не найден, Perl использует подпрограмму AUTOLOAD, если она найдена в дереве @ISA.
-
Если соответствующий метод все еще не может быть найден, то Perl ищет метод в классе (пакете) UNIVERSAL, который входит в состав стандартной библиотеки Perl.
-
Если метод все еще не найден, Perl сдается и вызывает исключение времени выполнения.
Perl ищет в классе указанного объекта данный метод или атрибут, т. Е. Переменную.
Perl ищет классы, определенные в массиве @ISA класса объекта.
Если в шагах 1 или 2 метод не найден, Perl использует подпрограмму AUTOLOAD, если она найдена в дереве @ISA.
Если соответствующий метод все еще не может быть найден, то Perl ищет метод в классе (пакете) UNIVERSAL, который входит в состав стандартной библиотеки Perl.
Если метод все еще не найден, Perl сдается и вызывает исключение времени выполнения.
Поэтому, чтобы создать новый класс Employee, который будет наследовать методы и атрибуты от нашего класса Person, мы просто кодируем следующим образом: Сохраните этот код в Employee.pm.
#!/usr/bin/perl package Employee; use Person; use strict; our @ISA = qw(Person); # inherits from Person
Теперь класс Employee имеет все методы и атрибуты, унаследованные от класса Person, и вы можете использовать их следующим образом: Используйте файл main.pl для его проверки —
#!/usr/bin/perl use Employee; $object = new Employee( "Mohammad", "Saleem", 23234345); # Get first name which is set using constructor. $firstName = $object->getFirstName(); print "Before Setting First Name is : $firstName\n"; # Now Set first name using helper function. $object->setFirstName( "Mohd." ); # Now get first name set by helper function. $firstName = $object->getFirstName(); print "After Setting First Name is : $firstName\n";
Когда мы выполняем вышеуказанную программу, она выдает следующий результат —
First Name is Mohammad Last Name is Saleem SSN is 23234345 Before Setting First Name is : Mohammad Before Setting First Name is : Mohd.
Переопределение метода
Дочерний класс Employee наследует все методы родительского класса Person. Но если вы хотите переопределить эти методы в своем дочернем классе, вы можете сделать это, предоставив собственную реализацию. Вы можете добавить свои дополнительные функции в дочерний класс или добавить или изменить функциональность существующих методов в его родительском классе. Это можно сделать следующим образом: изменить файл Employee.pm.
#!/usr/bin/perl package Employee; use Person; use strict; our @ISA = qw(Person); # inherits from Person # Override constructor sub new { my ($class) = @_; # Call the constructor of the parent class, Person. my $self = $class->SUPER::new( $_[1], $_[2], $_[3] ); # Add few more attributes $self->{_id} = undef; $self->{_title} = undef; bless $self, $class; return $self; } # Override helper function sub getFirstName { my( $self ) = @_; # This is child class function. print "This is child class helper function\n"; return $self->{_firstName}; } # Add more methods sub setLastName{ my ( $self, $lastName ) = @_; $self->{_lastName} = $lastName if defined($lastName); return $self->{_lastName}; } sub getLastName { my( $self ) = @_; return $self->{_lastName}; } 1;
Теперь давайте снова попробуем использовать объект Employee в нашем файле main.pl и выполнить его.
#!/usr/bin/perl use Employee; $object = new Employee( "Mohammad", "Saleem", 23234345); # Get first name which is set using constructor. $firstName = $object->getFirstName(); print "Before Setting First Name is : $firstName\n"; # Now Set first name using helper function. $object->setFirstName( "Mohd." ); # Now get first name set by helper function. $firstName = $object->getFirstName(); print "After Setting First Name is : $firstName\n";
Когда мы выполняем вышеуказанную программу, она выдает следующий результат —
First Name is Mohammad Last Name is Saleem SSN is 23234345 This is child class helper function Before Setting First Name is : Mohammad This is child class helper function After Setting First Name is : Mohd.
Автозагрузка по умолчанию
Perl предлагает функцию, которую вы не найдете ни в одном другом языке программирования: подпрограмма по умолчанию. Это означает, что если вы определяете функцию с именем AUTOLOAD (), то любые вызовы неопределенных подпрограмм будут автоматически вызывать функцию AUTOLOAD (). Имя отсутствующей подпрограммы доступно в этой подпрограмме как $ AUTOLOAD.
Функция автозагрузки по умолчанию очень полезна для обработки ошибок. Вот пример реализации AUTOLOAD, вы можете реализовать эту функцию по-своему.
sub AUTOLOAD { my $self = shift; my $type = ref ($self) || croak "$self is not an object"; my $field = $AUTOLOAD; $field =~ s/.*://; unless (exists $self->{$field}) { croak "$field does not exist in object/class $type"; } if (@_) { return $self->($name) = shift; } else { return $self->($name); } }
Деструкторы и сборщик мусора
Если вы программировали с использованием объектно-ориентированного программирования ранее, то вы будете знать о необходимости создания деструктора, чтобы освободить память, выделенную для объекта, когда вы закончили его использовать. Perl делает это автоматически для вас, как только объект выходит из области видимости.
Если вы хотите реализовать свой деструктор, который должен позаботиться о закрытии файлов или о дополнительной обработке, вам нужно определить специальный метод, называемый DESTROY . Этот метод будет вызван для объекта непосредственно перед тем, как Perl освободит выделенную ему память. В остальном метод DESTROY такой же, как и любой другой метод, и вы можете реализовать любую логику внутри этого метода.
Метод деструктора — это просто функция-член (подпрограмма) с именем DESTROY, которая будет вызываться автоматически в следующих случаях:
- Когда переменная ссылки на объект выходит из области видимости.
- Когда переменная ссылки на объект не определена.
- Когда скрипт заканчивается
- Когда Perl-интерпретатор завершает работу
Например, вы можете просто поместить следующий метод DESTROY в ваш класс —
package MyClass; ... sub DESTROY { print "MyClass::DESTROY called\n"; }
Пример объектно-ориентированного Perl
Вот еще один хороший пример, который поможет вам понять объектно-ориентированные концепции Perl. Поместите этот исходный код в любой файл perl и выполните его.
#!/usr/bin/perl # Following is the implementation of simple Class. package MyClass; sub new { print "MyClass::new called\n"; my $type = shift; # The package/type name my $self = {}; # Reference to empty hash return bless $self, $type; } sub DESTROY { print "MyClass::DESTROY called\n"; } sub MyMethod { print "MyClass::MyMethod called!\n"; } # Following is the implemnetation of Inheritance. package MySubClass; @ISA = qw( MyClass ); sub new { print "MySubClass::new called\n"; my $type = shift; # The package/type name my $self = MyClass->new; # Reference to empty hash return bless $self, $type; } sub DESTROY { print "MySubClass::DESTROY called\n"; } sub MyMethod { my $self = shift; $self->SUPER::MyMethod(); print " MySubClass::MyMethod called!\n"; } # Here is the main program using above classes. package main; print "Invoke MyClass method\n"; $myObject = MyClass->new(); $myObject->MyMethod(); print "Invoke MySubClass method\n"; $myObject2 = MySubClass->new(); $myObject2->MyMethod(); print "Create a scoped object\n"; { my $myObject2 = MyClass->new(); } # Destructor is called automatically here print "Create and undef an object\n"; $myObject3 = MyClass->new(); undef $myObject3; print "Fall off the end of the script...\n"; # Remaining destructors are called automatically here
Когда мы выполняем вышеуказанную программу, она выдает следующий результат —
Invoke MyClass method MyClass::new called MyClass::MyMethod called! Invoke MySubClass method MySubClass::new called MyClass::new called MyClass::MyMethod called! MySubClass::MyMethod called! Create a scoped object MyClass::new called MyClass::DESTROY called Create and undef an object MyClass::new called MyClass::DESTROY called Fall off the end of the script... MyClass::DESTROY called MySubClass::DESTROY called
Perl — доступ к базе данных
В этой главе вы узнаете, как получить доступ к базе данных внутри вашего скрипта Perl. Начиная с Perl 5 стало очень легко писать приложения баз данных с использованием модуля DBI . DBI означает независимый от базы данных интерфейс для Perl, что означает, что DBI обеспечивает уровень абстракции между кодом Perl и базовой базой данных, позволяя вам действительно легко переключать реализации базы данных.
DBI — это модуль доступа к базе данных для языка программирования Perl. Он предоставляет набор методов, переменных и соглашений, которые обеспечивают согласованный интерфейс базы данных, независимо от фактической используемой базы данных.
Архитектура приложения DBI
DBI не зависит от любой базы данных, доступной в бэкэнде. Вы можете использовать DBI независимо от того, работаете ли вы с Oracle, MySQL или Informix и т. Д. Это ясно из следующей диаграммы архитектуры.
Здесь DBI отвечает за принятие всех команд SQL через API (т. Е. Интерфейс прикладного программирования) и за отправку их соответствующему драйверу для фактического выполнения. И, наконец, DBI отвечает за получение результатов от драйвера и возврат их вызывающему скрипту.
Обозначения и условные обозначения
В этой главе будут использоваться следующие обозначения, и рекомендуется также придерживаться того же соглашения.
$dsn Database source name $dbh Database handle object $sth Statement handle object $h Any of the handle types above ($dbh, $sth, or $drh) $rc General Return Code (boolean: true=ok, false=error) $rv General Return Value (typically an integer) @ary List of values returned from the database. $rows Number of rows processed (if available, else -1) $fh A filehandle undef NULL values are represented by undefined values in Perl \%attr Reference to a hash of attribute values passed to methods
Подключение к базе данных
Предполагая, что мы собираемся работать с базой данных MySQL. Перед подключением к базе данных убедитесь в следующем. Вы можете воспользоваться помощью нашего учебника по MySQL, если вы не знаете, как создать базу данных и таблицы в базе данных MySQL.
-
Вы создали базу данных с именем TESTDB.
-
Вы создали таблицу с именем TEST_TABLE в TESTDB.
-
В этой таблице есть поля FIRST_NAME, LAST_NAME, AGE, SEX и INCOME.
-
Идентификатор пользователя «testuser» и пароль «test123» установлены для доступа к TESTDB.
-
Perl Module DBI правильно установлен на вашем компьютере.
-
Вы прошли учебник по MySQL, чтобы понять основы MySQL.
Вы создали базу данных с именем TESTDB.
Вы создали таблицу с именем TEST_TABLE в TESTDB.
В этой таблице есть поля FIRST_NAME, LAST_NAME, AGE, SEX и INCOME.
Идентификатор пользователя «testuser» и пароль «test123» установлены для доступа к TESTDB.
Perl Module DBI правильно установлен на вашем компьютере.
Вы прошли учебник по MySQL, чтобы понять основы MySQL.
Ниже приведен пример соединения с базой данных MySQL «TESTDB» —
#!/usr/bin/perl use DBI use strict; my $driver = "mysql"; my $database = "TESTDB"; my $dsn = "DBI:$driver:database=$database"; my $userid = "testuser"; my $password = "test123"; my $dbh = DBI->connect($dsn, $userid, $password ) or die $DBI::errstr;
Если соединение с источником данных установлено, то дескриптор базы данных возвращается и сохраняется в $ dbh для дальнейшего использования, в противном случае $ dbh устанавливается в значение undef, а $ DBI :: errstr возвращает строку ошибки.
ВСТАВИТЬ Операция
Операция INSERT требуется, когда вы хотите создать несколько записей в таблице. Здесь мы используем таблицу TEST_TABLE для создания наших записей. Поэтому, когда наше соединение с базой данных установлено, мы готовы создавать записи в TEST_TABLE. Ниже приведена процедура для создания отдельной записи в TEST_TABLE. Вы можете создать столько записей, сколько захотите, используя одну и ту же концепцию.
Создание записи включает следующие шаги:
-
Подготовка оператора SQL с оператором INSERT. Это будет сделано с использованием API prepare () .
-
Выполнение запроса SQL для выбора всех результатов из базы данных. Это будет сделано с помощью execute () API.
-
Отпустив ручку уставки. Это будет сделано с использованием API finish () .
-
Если все в порядке, передайте эту операцию, иначе вы можете откатить завершенную транзакцию. Фиксация и откат описаны в следующих разделах.
Подготовка оператора SQL с оператором INSERT. Это будет сделано с использованием API prepare () .
Выполнение запроса SQL для выбора всех результатов из базы данных. Это будет сделано с помощью execute () API.
Отпустив ручку уставки. Это будет сделано с использованием API finish () .
Если все в порядке, передайте эту операцию, иначе вы можете откатить завершенную транзакцию. Фиксация и откат описаны в следующих разделах.
my $sth = $dbh->prepare("INSERT INTO TEST_TABLE (FIRST_NAME, LAST_NAME, SEX, AGE, INCOME ) values ('john', 'poul', 'M', 30, 13000)"); $sth->execute() or die $DBI::errstr; $sth->finish(); $dbh->commit or die $DBI::errstr;
Использование значений привязки
Возможен случай, когда вводимые значения не указаны заранее. Таким образом, вы можете использовать переменные связывания, которые будут принимать необходимые значения во время выполнения. Модули Perl DBI используют знак вопроса вместо фактического значения, а затем фактические значения передаются через API execute () во время выполнения. Ниже приведен пример —
my $first_name = "john"; my $last_name = "poul"; my $sex = "M"; my $income = 13000; my $age = 30; my $sth = $dbh->prepare("INSERT INTO TEST_TABLE (FIRST_NAME, LAST_NAME, SEX, AGE, INCOME ) values (?,?,?,?)"); $sth->execute($first_name,$last_name,$sex, $age, $income) or die $DBI::errstr; $sth->finish(); $dbh->commit or die $DBI::errstr;
ЧИТАЙТЕ Операцию
Операция READ для любого блока данных означает получение некоторой полезной информации из базы данных, то есть одной или нескольких записей из одной или нескольких таблиц. Поэтому, когда наше соединение с базой данных установлено, мы готовы сделать запрос в эту базу данных. Ниже приведена процедура для запроса всех записей, имеющих возраст больше 20. Это будет состоять из четырех шагов:
-
Подготовка запроса SQL SELECT на основе необходимых условий. Это будет сделано с использованием API prepare () .
-
Выполнение запроса SQL для выбора всех результатов из базы данных. Это будет сделано с помощью execute () API.
-
Извлечение всех результатов по одному и печать этих результатов. Это будет сделано с помощью API fetchrow_array () .
-
Отпустив ручку уставки. Это будет сделано с использованием API finish () .
Подготовка запроса SQL SELECT на основе необходимых условий. Это будет сделано с использованием API prepare () .
Выполнение запроса SQL для выбора всех результатов из базы данных. Это будет сделано с помощью execute () API.
Извлечение всех результатов по одному и печать этих результатов. Это будет сделано с помощью API fetchrow_array () .
Отпустив ручку уставки. Это будет сделано с использованием API finish () .
my $sth = $dbh->prepare("SELECT FIRST_NAME, LAST_NAME FROM TEST_TABLE WHERE AGE > 20"); $sth->execute() or die $DBI::errstr; print "Number of rows found :" + $sth->rows; while (my @row = $sth->fetchrow_array()) { my ($first_name, $last_name ) = @row; print "First Name = $first_name, Last Name = $last_name\n"; } $sth->finish();
Использование значений привязки
Возможен случай, когда условие не указано заранее. Таким образом, вы можете использовать переменные связывания, которые будут принимать необходимые значения во время выполнения. Модули Perl DBI используют знак вопроса вместо фактического значения, а затем фактические значения передаются через API execute () во время выполнения. Ниже приведен пример —
$age = 20; my $sth = $dbh->prepare("SELECT FIRST_NAME, LAST_NAME FROM TEST_TABLE WHERE AGE > ?"); $sth->execute( $age ) or die $DBI::errstr; print "Number of rows found :" + $sth->rows; while (my @row = $sth->fetchrow_array()) { my ($first_name, $last_name ) = @row; print "First Name = $first_name, Last Name = $last_name\n"; } $sth->finish();
ОБНОВЛЕНИЕ Операция
ОБНОВЛЕНИЕ Операция над любой базой данных означает обновление одной или нескольких записей, уже доступных в таблицах базы данных. Ниже приведена процедура обновления всех записей, имеющих SEX как «M». Здесь мы увеличим ВОЗРАСТ всех мужчин на один год. Это займет три шага —
-
Подготовка SQL-запроса на основе обязательных условий. Это будет сделано с использованием API prepare () .
-
Выполнение запроса SQL для выбора всех результатов из базы данных. Это будет сделано с помощью execute () API.
-
Отпустив ручку уставки. Это будет сделано с использованием API finish () .
-
Если все в порядке, передайте эту операцию, иначе вы можете откатить завершенную транзакцию. В следующем разделе приведены API для фиксации и отката.
Подготовка SQL-запроса на основе обязательных условий. Это будет сделано с использованием API prepare () .
Выполнение запроса SQL для выбора всех результатов из базы данных. Это будет сделано с помощью execute () API.
Отпустив ручку уставки. Это будет сделано с использованием API finish () .
Если все в порядке, передайте эту операцию, иначе вы можете откатить завершенную транзакцию. В следующем разделе приведены API для фиксации и отката.
my $sth = $dbh->prepare("UPDATE TEST_TABLE SET AGE = AGE + 1 WHERE SEX = 'M'"); $sth->execute() or die $DBI::errstr; print "Number of rows updated :" + $sth->rows; $sth->finish(); $dbh->commit or die $DBI::errstr;
Использование значений привязки
Возможен случай, когда условие не указано заранее. Таким образом, вы можете использовать переменные связывания, которые будут принимать необходимые значения во время выполнения. Модули Perl DBI используют знак вопроса вместо фактического значения, а затем фактические значения передаются через API execute () во время выполнения. Ниже приведен пример —
$sex = 'M'; my $sth = $dbh->prepare("UPDATE TEST_TABLE SET AGE = AGE + 1 WHERE SEX = ?"); $sth->execute('$sex') or die $DBI::errstr; print "Number of rows updated :" + $sth->rows; $sth->finish(); $dbh->commit or die $DBI::errstr;
В некоторых случаях вы хотели бы установить значение, которое не указано заранее, поэтому вы можете использовать значение привязки следующим образом. В этом примере доход всех мужчин будет установлен на 10000.
$sex = 'M'; $income = 10000; my $sth = $dbh->prepare("UPDATE TEST_TABLE SET INCOME = ? WHERE SEX = ?"); $sth->execute( $income, '$sex') or die $DBI::errstr; print "Number of rows updated :" + $sth->rows; $sth->finish();
УДАЛЕНИЕ Операция
Операция DELETE требуется, когда вы хотите удалить некоторые записи из вашей базы данных. Ниже приведена процедура удаления всех записей из TEST_TABLE, где AGE равно 30. Эта операция будет выполнять следующие шаги.
-
Подготовка SQL-запроса на основе обязательных условий. Это будет сделано с использованием API prepare () .
-
Выполнение SQL-запроса для удаления необходимых записей из базы данных. Это будет сделано с помощью execute () API.
-
Отпустив ручку уставки. Это будет сделано с использованием API finish () .
-
Если все в порядке, передайте эту операцию, иначе вы можете откатить завершенную транзакцию.
Подготовка SQL-запроса на основе обязательных условий. Это будет сделано с использованием API prepare () .
Выполнение SQL-запроса для удаления необходимых записей из базы данных. Это будет сделано с помощью execute () API.
Отпустив ручку уставки. Это будет сделано с использованием API finish () .
Если все в порядке, передайте эту операцию, иначе вы можете откатить завершенную транзакцию.
$age = 30; my $sth = $dbh->prepare("DELETE FROM TEST_TABLE WHERE AGE = ?"); $sth->execute( $age ) or die $DBI::errstr; print "Number of rows deleted :" + $sth->rows; $sth->finish(); $dbh->commit or die $DBI::errstr;
Использование do Statement
Если вы выполняете UPDATE, INSERT или DELETE, данные не возвращаются из базы данных, поэтому существует быстрый путь для выполнения этой операции. Вы можете использовать оператор do для выполнения любой команды следующим образом.
$dbh->do('DELETE FROM TEST_TABLE WHERE age =30');
do возвращает истинное значение, если это удалось, и ложное значение, если это не удалось. Фактически, если это успешно, это возвращает число затронутых рядов. В этом примере будет возвращено количество фактически удаленных строк.
Операция COMMIT
Фиксация — это операция, которая дает зеленый сигнал базе данных для завершения изменений, и после этой операции никакие изменения не могут быть возвращены в исходное положение.
Вот простой пример вызова commit API.
$dbh->commit or die $dbh->errstr;
ROLLBACK Операция
Если вы не удовлетворены всеми изменениями или вы столкнулись с ошибкой между операциями, вы можете отменить эти изменения, чтобы использовать API отката .
Вот простой пример вызова API отката .
$dbh->rollback or die $dbh->errstr;
Начать транзакцию
Многие базы данных поддерживают транзакции. Это означает, что вы можете сделать целую кучу запросов, которые изменили бы базы данных, но на самом деле ни одно из этих изменений не было сделано. Затем в конце вы выдаете специальный SQL-запрос COMMIT , и все изменения вносятся одновременно. В качестве альтернативы вы можете выполнить запрос ROLLBACK, и в этом случае все изменения будут отброшены, а база данных останется неизменной.
Модуль Perl DBI предоставил API begin_work , который разрешает транзакции (отключая AutoCommit) до следующего вызова для фиксации или отката. После следующей фиксации или отката AutoCommit автоматически включится снова.
$rc = $dbh->begin_work or die $dbh->errstr;
Опция AutoCommit
Если ваши транзакции просты, вы можете избавить себя от необходимости совершать много коммитов. Когда вы делаете вызов connect, вы можете указать опцию AutoCommit, которая будет выполнять операцию автоматической фиксации после каждого успешного запроса. Вот как это выглядит —
my $dbh = DBI->connect($dsn, $userid, $password, {AutoCommit => 1}) or die $DBI::errstr;
Здесь AutoCommit может принимать значение 1 или 0, где 1 означает, что AutoCommit включен, а 0 означает, что AutoCommit выключен.
Автоматическая обработка ошибок
Когда вы делаете вызов Connect, вы можете указать опцию RaiseErrors, которая автоматически обрабатывает ошибки. При возникновении ошибки DBI прерывает вашу программу, а не возвращает код ошибки. Если все, что вам нужно, это прервать программу из-за ошибки, это может быть удобно. Вот как это выглядит —
my $dbh = DBI->connect($dsn, $userid, $password, {RaiseError => 1}) or die $DBI::errstr;
Здесь RaiseError может принимать значение 1 или 0.
Отключение базы данных
Чтобы отключить соединение с базой данных, используйте API отключения следующим образом:
$rc = $dbh->disconnect or warn $dbh->errstr;
Поведение транзакции метода отсоединения, к сожалению, не определено. Некоторые системы баз данных (такие как Oracle и Ingres) будут автоматически фиксировать любые ожидающие изменения, но другие (такие как Informix) будут откатывать любые ожидающие изменения. Приложения, не использующие AutoCommit, должны явно вызывать commit или rollback перед вызовом connect.
Использование значений NULL
Неопределенные значения или undef используются для обозначения значений NULL. Вы можете вставлять и обновлять столбцы со значением NULL, как если бы они отличались от NULL. Эти примеры вставляют и обновляют возраст столбца со значением NULL —
$sth = $dbh->prepare(qq { INSERT INTO TEST_TABLE (FIRST_NAME, AGE) VALUES (?, ?) }); $sth->execute("Joe", undef);
Здесь qq {} используется для возврата строки в кавычках для подготовки API. Однако следует соблюдать осторожность при попытке использовать значения NULL в предложении WHERE. Рассмотрим —
SELECT FIRST_NAME FROM TEST_TABLE WHERE age = ?
Привязка undef (NULL) к заполнителю не будет выбирать строки с нулевым возрастом! По крайней мере, для баз данных, которые соответствуют стандарту SQL. По причинам этого обратитесь к руководству по SQL для вашего движка базы данных или к любой книге по SQL. Чтобы явно выбрать NULL, вы должны сказать «ГДЕ возраст NULL».
Распространенной проблемой является наличие фрагмента кода для обработки значения, которое может быть определено или не определено (не NULL или NULL) во время выполнения. Простой метод состоит в том, чтобы подготовить соответствующее утверждение по мере необходимости и заменить заполнитель для случаев, отличных от NULL.
$sql_clause = defined $age? "age = ?" : "age IS NULL"; $sth = $dbh->prepare(qq { SELECT FIRST_NAME FROM TEST_TABLE WHERE $sql_clause }); $sth->execute(defined $age ? $age : ());
Некоторые другие функции DBI
available_drivers
@ary = DBI->available_drivers; @ary = DBI->available_drivers($quiet);
Возвращает список всех доступных драйверов путем поиска модулей DBD :: * по каталогам в @INC. По умолчанию выдается предупреждение, если некоторые драйверы скрыты другими с таким же именем в более ранних каталогах. Передача истинного значения $ quiet запретит предупреждение.
installed_drivers
%drivers = DBI->installed_drivers();
Возвращает список пар имени драйвера и дескриптора драйвера для всех драйверов, «установленных» (загруженных) в текущий процесс. Имя драйвера не включает префикс «DBD ::».
источники данных
@ary = DBI->data_sources($driver);
Возвращает список источников данных (баз данных), доступных через указанный драйвер. Если $ driver пуст или undef, то используется значение переменной среды DBI_DRIVER.
котировка
$sql = $dbh->quote($value); $sql = $dbh->quote($value, $data_type);
Заключите в кавычки строковый литерал для использования в качестве литерального значения в инструкции SQL, экранируя любые специальные символы (такие как кавычки), содержащиеся в строке, и добавляя требуемый тип внешних кавычек.
$sql = sprintf "SELECT foo FROM bar WHERE baz = %s", $dbh->quote("Don't");
Для большинства типов баз данных цитата будет возвращать «Не делай» (включая внешние кавычки). Для метода quote () допустимо возвращать выражение SQL, которое вычисляется в нужную строку. Например —
$quoted = $dbh->quote("one\ntwo\0three") may produce results which will be equivalent to CONCAT('one', CHAR(12), 'two', CHAR(0), 'three')
Методы, общие для всех дескрипторов
заблуждаться
$rv = $h->err; or $rv = $DBI::err or $rv = $h->err
Возвращает собственный код ошибки ядра базы данных из последнего вызванного метода драйвера. Код обычно является целым числом, но вы не должны предполагать это. Это эквивалентно $ DBI :: err или $ h-> err.
ErrStr
$str = $h->errstr; or $str = $DBI::errstr or $str = $h->errstr
Возвращает собственное сообщение об ошибке ядра базы данных из последнего вызванного метода DBI. Это имеет те же проблемы с продолжительностью жизни, что и описанный выше метод «err». Это эквивалентно $ DBI :: errstr или $ h-> errstr.
строки
$rv = $h->rows; or $rv = $DBI::rows
Это возвращает количество строк, на которые воздействовал предыдущий оператор SQL, и эквивалентно $ DBI :: row.
след
$h->trace($trace_settings);
DBI обладает чрезвычайно полезной способностью генерировать информацию трассировки во время выполнения того, что он делает, что может значительно сэкономить время при попытке отследить странные проблемы в ваших программах DBI. Вы можете использовать разные значения, чтобы установить уровень трассировки. Эти значения варьируются от 0 до 4. Значение 0 означает отключить трассировку, а 4 означает генерацию полной трассировки.
Интерполированные заявления запрещены
Настоятельно рекомендуется не использовать интерполированные операторы следующим образом:
while ($first_name = <>) { my $sth = $dbh->prepare("SELECT * FROM TEST_TABLE WHERE FIRST_NAME = '$first_name'"); $sth->execute(); # and so on ... }
Поэтому не используйте интерполированный оператор, вместо этого используйте значение связывания для подготовки динамического оператора SQL.
Perl — CGI Программирование
Что такое CGI?
-
Общий интерфейс шлюза, или CGI, представляет собой набор стандартов, определяющих, каким образом осуществляется обмен информацией между веб-сервером и пользовательским сценарием.
-
Спецификации CGI в настоящее время поддерживаются NCSA, и NCSA определяет CGI следующим образом:
-
Common Gateway Interface, или CGI, является стандартом для внешних программ-шлюзов для взаимодействия с информационными серверами, такими как HTTP-серверы.
-
Текущая версия — CGI / 1.1, а CGI / 1.2 находится в стадии разработки.
Общий интерфейс шлюза, или CGI, представляет собой набор стандартов, определяющих, каким образом осуществляется обмен информацией между веб-сервером и пользовательским сценарием.
Спецификации CGI в настоящее время поддерживаются NCSA, и NCSA определяет CGI следующим образом:
Common Gateway Interface, или CGI, является стандартом для внешних программ-шлюзов для взаимодействия с информационными серверами, такими как HTTP-серверы.
Текущая версия — CGI / 1.1, а CGI / 1.2 находится в стадии разработки.
Просмотр веб-страниц
Чтобы понять концепцию CGI, давайте посмотрим, что происходит, когда мы нажимаем гиперссылку, доступную на веб-странице, для просмотра определенной веб-страницы или URL-адреса.
-
Ваш браузер связывается с веб-сервером по протоколу HTTP и запрашивает URL-адрес, то есть имя файла веб-страницы.
-
Веб-сервер проверит URL и найдет запрошенное имя файла. Если веб-сервер находит этот файл, он отправляет файл обратно в браузер без дальнейшего выполнения, в противном случае отправляется сообщение об ошибке, указывающее, что вы запросили неправильный файл.
-
Веб-браузер принимает ответ от веб-сервера и отображает либо полученное содержимое файла, либо сообщение об ошибке, если файл не найден.
Ваш браузер связывается с веб-сервером по протоколу HTTP и запрашивает URL-адрес, то есть имя файла веб-страницы.
Веб-сервер проверит URL и найдет запрошенное имя файла. Если веб-сервер находит этот файл, он отправляет файл обратно в браузер без дальнейшего выполнения, в противном случае отправляется сообщение об ошибке, указывающее, что вы запросили неправильный файл.
Веб-браузер принимает ответ от веб-сервера и отображает либо полученное содержимое файла, либо сообщение об ошибке, если файл не найден.
Однако можно настроить HTTP-сервер таким образом, чтобы при каждом запросе файла в определенном каталоге этот файл не отправлялся обратно; вместо этого он выполняется как программа, и все, что эта программа выводит в результате, отправляется обратно в браузер для отображения. Это можно сделать с помощью специальной функциональности, доступной на веб-сервере, и она называется Common Gateway Interface или CGI, а такие программы, которые выполняются сервером для получения окончательного результата, называются CGI-скриптами. Этими CGI-программами могут быть Perl Script, Shell Script, C или C ++ и т. Д.
Диаграмма архитектуры CGI
Поддержка и настройка веб-сервера
Прежде чем приступить к программированию CGI, убедитесь, что ваш веб-сервер поддерживает функциональность CGI и настроен на обработку программ CGI. Все программы CGI, которые должны выполняться веб-сервером, хранятся в предварительно настроенном каталоге. Этот каталог называется CGI-каталогом и по соглашению называется / cgi-bin. По соглашению файлы Perl CGI будут иметь расширение .cgi .
Первая программа CGI
Вот простая ссылка, которая связана с CGI-скриптом, который называется hello.cgi . Этот файл хранится в каталоге / cgi-bin / и содержит следующее содержимое. Перед запуском программы CGI убедитесь, что у вас есть режим изменения файла, используя команду UNIX chmod 755 hello.cgi .
#!/usr/bin/perl print "Content-type:text/html\r\n\r\n"; print '<html>'; print '<head>'; print '<title>Hello Word - First CGI Program</title>'; print '</head>'; print '<body>'; print '<h2>Hello Word! This is my first CGI program</h2>'; print '</body>'; print '</html>'; 1;
Теперь, если вы щелкнете по ссылке hello.cgi, то запрос отправляется на веб-сервер, который ищет hello.cgi в каталоге / cgi-bin, выполняет его, и какой бы результат не был сгенерирован, веб-сервер отправляет этот результат обратно в веб-браузер, что выглядит следующим образом —
Hello Word! This is my first CGI program
Этот сценарий hello.cgi представляет собой простой сценарий Perl, который записывает свой вывод в файл STDOUT, то есть на экран. Существует одна важная и дополнительная функция, которая должна быть напечатана в первой строке. Тип содержимого: text / html \ r \ n \ r \ n . Эта строка отправляется обратно в браузер и указывает тип контента, который будет отображаться на экране браузера. Теперь вы должны понимать основную концепцию CGI, и вы можете написать множество сложных CGI-программ на Perl. Этот скрипт может взаимодействовать с любой другой внешней системой также для обмена информацией, такой как база данных, веб-сервисы или любые другие сложные интерфейсы.
Понимание заголовка HTTP
Самая первая строка Content-type: text / html \ r \ n \ r \ n является частью заголовка HTTP, который отправляется браузеру, чтобы браузер мог понимать входящий контент со стороны сервера. Весь заголовок HTTP будет в следующей форме —
HTTP Field Name: Field Content
Например —
Content-type: text/html\r\n\r\n
Есть несколько других важных заголовков HTTP, которые вы будете часто использовать в программировании CGI.
| Sr.No. | Заголовок и описание |
|---|---|
| 1 |
Тип содержимого: Строка Строка MIME, определяющая формат возвращаемого содержимого. Примером является Content-type: text / html |
| 2 |
Истекает: Дата Строка Дата, когда информация становится недействительной. Это должно использоваться браузером, чтобы решить, когда страница должна быть обновлена. Допустимая строка даты должна быть в формате 01 января 1998 12:00:00 по Гринвичу. |
| 3 |
Расположение: URL-строка URL, который должен быть возвращен вместо запрошенного URL. Вы можете использовать это поле для перенаправления запроса в любое другое место. |
| 4 |
Последнее изменение: строка Дата последней модификации файла. |
| 5 |
Длина содержимого: Строка Длина в байтах возвращаемых данных. Браузер использует это значение, чтобы сообщить примерное время загрузки файла. |
| 6 |
Набор Cookie: Строка Установить куки, пропущенные через строку |
Тип содержимого: Строка
Строка MIME, определяющая формат возвращаемого содержимого. Примером является Content-type: text / html
Истекает: Дата Строка
Дата, когда информация становится недействительной. Это должно использоваться браузером, чтобы решить, когда страница должна быть обновлена. Допустимая строка даты должна быть в формате 01 января 1998 12:00:00 по Гринвичу.
Расположение: URL-строка
URL, который должен быть возвращен вместо запрошенного URL. Вы можете использовать это поле для перенаправления запроса в любое другое место.
Последнее изменение: строка
Дата последней модификации файла.
Длина содержимого: Строка
Длина в байтах возвращаемых данных. Браузер использует это значение, чтобы сообщить примерное время загрузки файла.
Набор Cookie: Строка
Установить куки, пропущенные через строку
Переменные среды CGI
Все программы CGI будут иметь доступ к следующим переменным среды. Эти переменные играют важную роль при написании любой CGI-программы.
| Sr.No. | Имена и описание переменных |
|---|---|
| 1 |
ТИП СОДЕРЖИМОГО Тип данных контента. Используется, когда клиент отправляет вложенный контент на сервер. Например, загрузка файла и т. Д. |
| 2 |
CONTENT_LENGTH Длина запроса информации. Доступно только для POST-запросов. |
| 3 |
HTTP_COOKIE Возвращает установленные куки в виде пары ключ-значение. |
| 4 |
HTTP_USER_AGENT Поле заголовка запроса User-Agent содержит информацию о пользовательском агенте, создавшем запрос. Его название веб-браузера. |
| 5 |
PATH_INFO Путь для скрипта CGI. |
| 6 |
СТРОКА ЗАПРОСА Информация в кодировке URL, отправляемая с запросом метода GET. |
| 7 |
REMOTE_ADDR IP-адрес удаленного хоста, отправляющего запрос. Это может быть полезно для регистрации или для аутентификации. |
| 8 |
УДАЛЕННЫЙ УЗЕЛ Полное имя хоста, сделавшего запрос. Если эта информация недоступна, тогда REMOTE_ADDR может использоваться для получения IR-адреса. |
| 9 |
REQUEST_METHOD Метод, использованный для запроса. Наиболее распространенными методами являются GET и POST. |
| 10 |
SCRIPT_FILENAME Полный путь к скрипту CGI. |
| 11 |
SCRIPT_NAME Название скрипта CGI. |
| 12 |
НАЗВАНИЕ СЕРВЕРА Имя хоста или IP-адрес сервера. |
| 13 |
SERVER_SOFTWARE Название и версия программного обеспечения, на котором работает сервер. |
ТИП СОДЕРЖИМОГО
Тип данных контента. Используется, когда клиент отправляет вложенный контент на сервер. Например, загрузка файла и т. Д.
CONTENT_LENGTH
Длина запроса информации. Доступно только для POST-запросов.
HTTP_COOKIE
Возвращает установленные куки в виде пары ключ-значение.
HTTP_USER_AGENT
Поле заголовка запроса User-Agent содержит информацию о пользовательском агенте, создавшем запрос. Его название веб-браузера.
PATH_INFO
Путь для скрипта CGI.
СТРОКА ЗАПРОСА
Информация в кодировке URL, отправляемая с запросом метода GET.
REMOTE_ADDR
IP-адрес удаленного хоста, отправляющего запрос. Это может быть полезно для регистрации или для аутентификации.
УДАЛЕННЫЙ УЗЕЛ
Полное имя хоста, сделавшего запрос. Если эта информация недоступна, тогда REMOTE_ADDR может использоваться для получения IR-адреса.
REQUEST_METHOD
Метод, использованный для запроса. Наиболее распространенными методами являются GET и POST.
SCRIPT_FILENAME
Полный путь к скрипту CGI.
SCRIPT_NAME
Название скрипта CGI.
НАЗВАНИЕ СЕРВЕРА
Имя хоста или IP-адрес сервера.
SERVER_SOFTWARE
Название и версия программного обеспечения, на котором работает сервер.
Вот небольшая программа CGI, в которой перечислены все переменные CGI, поддерживаемые вашим веб-сервером. Нажмите на эту ссылку, чтобы увидеть результат Получить среду
#!/usr/bin/perl print "Content-type: text/html\n\n"; print "<font size=+1>Environment</font>\n"; foreach (sort keys %ENV) { print "<b>$_</b>: $ENV{$_}<br>\n"; } 1;
Поднять диалоговое окно «Загрузка файла»?
Иногда желательно, чтобы вы указали опцию, в которой пользователь щелкает ссылку, и вместо всплывающего окна отображается всплывающее диалоговое окно «Загрузка файла». Это очень просто и будет достигнуто через HTTP-заголовок.
Этот HTTP-заголовок будет отличаться от заголовка, упомянутого в предыдущем разделе. Например, если вы хотите сделать файл FileName загружаемым по заданной ссылке, его синтаксис будет следующим:
#!/usr/bin/perl # HTTP Header print "Content-Type:application/octet-stream; name = \"FileName\"\r\n"; print "Content-Disposition: attachment; filename = \"FileName\"\r\n\n"; # Actual File Content will go hear. open( FILE, "<FileName" ); while(read(FILE, $buffer, 100) ) { print("$buffer"); }
GET и POST методы
Вы, должно быть, сталкивались со многими ситуациями, когда вам нужно было передать некоторую информацию из вашего браузера на веб-сервер и, в конечном счете, в вашу CGI-программу для обработки ваших запросов. Чаще всего браузер использует два метода для передачи этой информации на веб-сервер. Это методы GET и POST . Давайте проверим их по одному.
Передача информации с использованием метода GET
Метод GET отправляет закодированную информацию о пользователе, добавленную к самому URL страницы. Страница и закодированная информация разделены знаком? персонаж следующим образом —
http://www.test.com/cgi-bin/hello.cgi?key1=value1&key2=value2
Метод GET является методом по умолчанию для передачи информации из браузера на веб-сервер, и он создает длинную строку, которая появляется в поле «Местоположение:» вашего браузера. Вы никогда не должны использовать метод GET, если у вас есть пароль или другая конфиденциальная информация для передачи на сервер. Метод GET имеет ограничение по размеру: в строку запроса можно передать только 1024 символа.
Эта информация передается с использованием заголовка QUERY_STRING и будет доступна в вашей CGI-программе через переменную среды QUERY_STRING, которую вы можете анализировать и использовать в вашей CGI-программе.
Вы можете передавать информацию, просто объединяя пары ключ-значение с любым URL-адресом или используя HTML-теги <FORM> для передачи информации, используя метод GET.
Пример простого URL: метод Get
Вот простой URL, который передаст два значения программе hello_get.cgi с помощью метода GET.
http://www.tutorialspoint.com/cgi-bin/hello_get.cgi?first_name=ZARA&last_name=ALI
Ниже приведен скрипт hello_get.cgi для обработки входных данных, данных веб-браузером.
#!/usr/bin/perl local ($buffer, @pairs, $pair, $name, $value, %FORM); # Read in text $ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/; if ($ENV{'REQUEST_METHOD'} eq "GET") { $buffer = $ENV{'QUERY_STRING'}; } # Split information into name/value pairs @pairs = split(/&/, $buffer); foreach $pair (@pairs) { ($name, $value) = split(/=/, $pair); $value =~ tr/+/ /; $value =~ s/%(..)/pack("C", hex($1))/eg; $FORM{$name} = $value; } $first_name = $FORM{first_name}; $last_name = $FORM{last_name}; print "Content-type:text/html\r\n\r\n"; print "<html>"; print "<head>"; print "<title>Hello - Second CGI Program</title>"; print "</head>"; print "<body>"; print "<h2>Hello $first_name $last_name - Second CGI Program</h2>"; print "</body>"; print "</html>"; 1;
Пример простой формы: метод GET
Вот простой пример, который передает два значения, используя HTML FORM и кнопку отправки. Мы будем использовать тот же сценарий CGI hello_get.cgi для обработки этого ввода.
<FORM action = "/cgi-bin/hello_get.cgi" method = "GET"> First Name: <input type = "text" name = "first_name"> <br> Last Name: <input type = "text" name = "last_name"> <input type = "submit" value = "Submit"> </FORM>
Вот фактический результат вышеприведенного кодирования формы. Теперь вы можете ввести имя и фамилию, а затем нажать кнопку «Отправить», чтобы увидеть результат.
Передача информации с использованием метода POST
Более надежным методом передачи информации в CGI-программу является метод POST . Это упаковывает информацию точно так же, как методы GET, но вместо отправки ее в виде текстовой строки после символа ? в URL он отправляет его как отдельное сообщение как часть заголовка HTTP. Веб-сервер предоставляет это сообщение сценарию CGI в форме стандартного ввода.
Ниже приведен модифицированный скрипт hello_post.cgi для обработки входных данных, данных веб-браузером. Этот скрипт будет обрабатывать GET, а также метод POST.
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$first_name = $FORM{first_name};
$last_name = $FORM{last_name};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Hello - Second CGI Program</title>";
print "</head>";
print "<body>";
print "<h2>Hello $first_name $last_name - Second CGI Program</h2>";
print "</body>";
print "</html>";
1;
Давайте снова возьмем тот же пример, что и выше, который передает два значения, используя HTML FORM и кнопку submit. Мы собираемся использовать скрипт CGI hello_post.cgi для обработки этого ввода.
<FORM action = "/cgi-bin/hello_post.cgi" method = "POST"> First Name: <input type = "text" name = "first_name"> <br> Last Name: <input type = "text" name = "last_name"> <input type = "submit" value = "Submit"> </FORM>
Вот фактический результат вышеприведенного кодирования формы. Вы вводите Имя и Фамилию и затем нажимаете кнопку отправки, чтобы увидеть результат.
Передача данных флажка в программу CGI
Флажки используются, когда требуется выбрать более одной опции. Вот пример HTML-кода для формы с двумя флажками.
<form action = "/cgi-bin/checkbox.cgi" method = "POST" target = "_blank"> <input type = "checkbox" name = "maths" value = "on"> Maths <input type = "checkbox" name = "physics" value = "on"> Physics <input type = "submit" value = "Select Subject"> </form>
Результатом этого кода является следующая форма —
Ниже приведен скрипт checkbox.cgi для обработки ввода, заданного веб-браузером для переключателя.
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
if( $FORM{maths} ) {
$maths_flag ="ON";
} else {
$maths_flag ="OFF";
}
if( $FORM{physics} ) {
$physics_flag ="ON";
} else {
$physics_flag ="OFF";
}
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Checkbox - Third CGI Program</title>";
print "</head>";
print "<body>";
print "<h2> CheckBox Maths is : $maths_flag</h2>";
print "<h2> CheckBox Physics is : $physics_flag</h2>";
print "</body>";
print "</html>";
1;
Передача данных переключателей в программу CGI
Радиокнопки используются, когда требуется выбрать только одну опцию. Вот пример HTML-кода для формы с двумя переключателями —
<form action = "/cgi-bin/radiobutton.cgi" method = "POST" target = "_blank"> <input type = "radio" name = "subject" value = "maths"> Maths <input type = "radio" name = "subject" value = "physics"> Physics <input type = "submit" value = "Select Subject"> </form>
Результатом этого кода является следующая форма —
Ниже приведен скрипт radiobutton.cgi для обработки ввода, заданного веб-браузером для переключателя.
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$subject = $FORM{subject};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Radio - Fourth CGI Program</title>";
print "</head>";
print "<body>";
print "<h2> Selected Subject is $subject</h2>";
print "</body>";
print "</html>";
1;
Передача данных текстовой области в программу CGI
Элемент textarea используется, когда многострочный текст должен быть передан в программу CGI. Вот пример HTML-кода для формы с полем TEXTAREA —
<form action = "/cgi-bin/textarea.cgi" method = "POST" target = "_blank"> <textarea name = "textcontent" cols = 40 rows = 4> Type your text here... </textarea> <input type = "submit" value = "Submit"> </form>
Результатом этого кода является следующая форма —
Ниже приведен скрипт textarea.cgi для обработки входных данных, данных веб-браузером.
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$text_content = $FORM{textcontent};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Text Area - Fifth CGI Program</title>";
print "</head>";
print "<body>";
print "<h2> Entered Text Content is $text_content</h2>";
print "</body>";
print "</html>";
1;
Передача данных выпадающего списка в программу CGI
Раскрывающийся список используется, когда у нас есть много доступных вариантов, но будет выбран только один или два. Вот пример HTML-кода для формы с одним выпадающим списком
<form action = "/cgi-bin/dropdown.cgi" method = "POST" target = "_blank"> <select name = "dropdown"> <option value = "Maths" selected>Maths</option> <option value = "Physics">Physics</option> </select> <input type = "submit" value = "Submit"> </form>
Результатом этого кода является следующая форма —
Ниже приведен скрипт dropdown.cgi для обработки входных данных, данных веб-браузером.
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$subject = $FORM{dropdown};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Dropdown Box - Sixth CGI Program</title>";
print "</head>";
print "<body>";
print "<h2> Selected Subject is $subject</h2>";
print "</body>";
print "</html>";
1;
Использование Cookies в CGI
Протокол HTTP — это протокол без сохранения состояния. Но для коммерческого веб-сайта требуется поддерживать информацию о сеансе на разных страницах. Например, одна регистрация пользователя заканчивается после транзакции, которая охватывает много страниц. Но как сохранить информацию о сеансе пользователя на всех веб-страницах?
Во многих ситуациях использование файлов cookie является наиболее эффективным способом запоминания и отслеживания предпочтений, покупок, комиссий и другой информации, необходимой для лучшего восприятия посетителями сайта или статистики сайта.
Как это устроено
Ваш сервер отправляет некоторые данные в браузер посетителя в виде файла cookie. Браузер может принять куки. Если это так, он сохраняется в виде простой текстовой записи на жестком диске посетителя. Теперь, когда посетитель заходит на другую страницу вашего сайта, файл cookie становится доступным для поиска. После получения ваш сервер знает / запоминает, что было сохранено.
Cookies — это запись данных в виде простого текста из 5 полей переменной длины —
-
Истекает — дата окончания срока действия куки. Если это поле пустое, срок действия файла cookie истечет, когда посетитель выйдет из браузера.
-
Домен — доменное имя вашего сайта.
-
Путь — путь к каталогу или веб-странице, на которой установлен файл cookie. Это может быть пустым, если вы хотите получить куки из любого каталога или страницы.
-
Безопасный — если в этом поле содержится слово «безопасный», тогда cookie может быть получен только с безопасного сервера. Если это поле пустое, такого ограничения не существует.
-
Имя = значение — файлы cookie устанавливаются и пересматриваются в форме пар ключ-значение.
Истекает — дата окончания срока действия куки. Если это поле пустое, срок действия файла cookie истечет, когда посетитель выйдет из браузера.
Домен — доменное имя вашего сайта.
Путь — путь к каталогу или веб-странице, на которой установлен файл cookie. Это может быть пустым, если вы хотите получить куки из любого каталога или страницы.
Безопасный — если в этом поле содержится слово «безопасный», тогда cookie может быть получен только с безопасного сервера. Если это поле пустое, такого ограничения не существует.
Имя = значение — файлы cookie устанавливаются и пересматриваются в форме пар ключ-значение.
Настройка Cookies
Отправить куки в браузер очень просто. Эти куки будут отправлены вместе с заголовком HTTP. Предполагая, что вы хотите установить идентификатор пользователя и пароль в качестве файлов cookie. Так будет сделано следующим образом —
#!/usr/bin/perl print "Set-Cookie:UserID = XYZ;\n"; print "Set-Cookie:Password = XYZ123;\n"; print "Set-Cookie:Expires = Tuesday, 31-Dec-2007 23:12:40 GMT";\n"; print "Set-Cookie:Domain = www.tutorialspoint.com;\n"; print "Set-Cookie:Path = /perl;\n"; print "Content-type:text/html\r\n\r\n"; ...........Rest of the HTML Content goes here....
Здесь мы использовали HTTP-заголовок Set-Cookie для установки файлов cookie. Необязательно устанавливать атрибуты cookie, такие как Expires, Domain и Path. Важно отметить, что куки устанавливаются перед отправкой волшебной строки «Content-type: text / html \ r \ n \ r \ n .
Получение куки
Получить все установленные куки очень просто. Файлы cookie хранятся в переменной среды CGI HTTP_COOKIE и имеют следующую форму.
key1 = value1;key2 = value2;key3 = value3....
Вот пример того, как получить куки.
#!/usr/bin/perl
$rcvd_cookies = $ENV{'HTTP_COOKIE'};
@cookies = split /;/, $rcvd_cookies;
foreach $cookie ( @cookies ) {
($key, $val) = split(/=/, $cookie); # splits on the first =.
$key =~ s/^\s+//;
$val =~ s/^\s+//;
$key =~ s/\s+$//;
$val =~ s/\s+$//;
if( $key eq "UserID" ) {
$user_id = $val;
} elsif($key eq "Password") {
$password = $val;
}
}
print "User ID = $user_id\n";
print "Password = $password\n";
Это даст следующий результат, при условии, что вышеупомянутые куки были установлены до вызова сценария поисковых куки.
User ID = XYZ Password = XYZ123
CGI Модули и Библиотеки
Вы найдете много встроенных модулей через Интернет, которые предоставляют вам прямые функции для использования в вашей программе CGI. Ниже приведены важные когда-то.
Perl — пакеты и модули
Что такое пакеты?
Инструкция пакета переключает текущий контекст именования в указанное пространство имен (таблица символов). Таким образом —
-
Пакет — это набор кода, который находится в своем собственном пространстве имен.
-
Пространство имен — это именованная коллекция уникальных имен переменных (также называемая таблицей символов).
-
Пространства имен предотвращают конфликты имен переменных между пакетами.
-
Пакеты позволяют создавать модули, которые при использовании не будут перекрывать переменные и функции вне собственного пространства имен модулей.
-
Пакет остается в силе до тех пор, пока не будет вызван другой оператор пакета, или до конца текущего блока или файла.
-
Вы можете явно ссылаться на переменные в пакете, используя спецификатор :: package.
Пакет — это набор кода, который находится в своем собственном пространстве имен.
Пространство имен — это именованная коллекция уникальных имен переменных (также называемая таблицей символов).
Пространства имен предотвращают конфликты имен переменных между пакетами.
Пакеты позволяют создавать модули, которые при использовании не будут перекрывать переменные и функции вне собственного пространства имен модулей.
Пакет остается в силе до тех пор, пока не будет вызван другой оператор пакета, или до конца текущего блока или файла.
Вы можете явно ссылаться на переменные в пакете, используя спецификатор :: package.
Ниже приведен пример, содержащий пакеты main и Foo в файле. Здесь для печати имени пакета используется специальная переменная __PACKAGE__.
#!/usr/bin/perl # This is main package $i = 1; print "Package name : " , __PACKAGE__ , " $i\n"; package Foo; # This is Foo package $i = 10; print "Package name : " , __PACKAGE__ , " $i\n"; package main; # This is again main package $i = 100; print "Package name : " , __PACKAGE__ , " $i\n"; print "Package name : " , __PACKAGE__ , " $Foo::i\n"; 1;
Когда приведенный выше код выполняется, он дает следующий результат —
Package name : main 1 Package name : Foo 10 Package name : main 100 Package name : main 10
Начало и конец блоков
Вы можете определить любое количество блоков кода с именами BEGIN и END, которые действуют как конструкторы и деструкторы соответственно.
BEGIN { ... }
END { ... }
BEGIN { ... }
END { ... }
-
Каждый блок BEGIN выполняется после загрузки и компиляции сценария perl, но перед выполнением любого другого оператора.
-
Каждый блок END выполняется непосредственно перед выходом из интерпретатора perl.
-
Блоки BEGIN и END особенно полезны при создании модулей Perl.
Каждый блок BEGIN выполняется после загрузки и компиляции сценария perl, но перед выполнением любого другого оператора.
Каждый блок END выполняется непосредственно перед выходом из интерпретатора perl.
Блоки BEGIN и END особенно полезны при создании модулей Perl.
Следующий пример показывает его использование —
#!/usr/bin/perl
package Foo;
print "Begin and Block Demo\n";
BEGIN {
print "This is BEGIN Block\n"
}
END {
print "This is END Block\n"
}
1;
Когда приведенный выше код выполняется, он дает следующий результат —
This is BEGIN Block Begin and Block Demo This is END Block
Что такое Perl-модули?
Модуль Perl — это повторно используемый пакет, определенный в библиотечном файле, имя которого совпадает с именем пакета с расширением .pm.
Файл модуля Perl с именем Foo.pm может содержать такие выражения.
#!/usr/bin/perl
package Foo;
sub bar {
print "Hello $_[0]\n"
}
sub blat {
print "World $_[0]\n"
}
1;
Несколько важных моментов о модулях Perl
-
Функции требуют и используют загрузит модуль.
-
Оба используют список путей поиска в @INC, чтобы найти модуль.
-
Обе функции требуют и используют функцию eval для обработки кода.
-
1; в нижней части приводит к тому, что eval оценивается как TRUE (и, следовательно, не терпит неудачу)
Функции требуют и используют загрузит модуль.
Оба используют список путей поиска в @INC, чтобы найти модуль.
Обе функции требуют и используют функцию eval для обработки кода.
1; в нижней части приводит к тому, что eval оценивается как TRUE (и, следовательно, не терпит неудачу)
Требуемая функция
Модуль можно загрузить, вызвав функцию require следующим образом:
#!/usr/bin/perl require Foo; Foo::bar( "a" ); Foo::blat( "b" );
Вы, должно быть, заметили, что имена подпрограмм должны быть полностью квалифицированы для их вызова. Было бы неплохо разрешить импорт подпрограммы и blat в наше собственное пространство имен, чтобы нам не пришлось использовать квалификатор Foo ::.
Функция использования
Модуль можно загрузить, вызвав функцию use .
#!/usr/bin/perl use Foo; bar( "a" ); blat( "b" );
Обратите внимание, что нам не нужно было полностью определять имена функций пакета. Функция use экспортирует список символов из модуля с учетом нескольких добавленных операторов внутри модуля.
require Exporter; @ISA = qw(Exporter);
Затем предоставьте список символов (скаляры, списки, хэши, подпрограммы и т. Д.), Заполнив переменную списка с именем @EXPORT : Например —
package Module;
require Exporter;
@ISA = qw(Exporter);
@EXPORT = qw(bar blat);
sub bar { print "Hello $_[0]\n" }
sub blat { print "World $_[0]\n" }
sub splat { print "Not $_[0]\n" } # Not exported!
1;
Создайте дерево модулей Perl
Когда вы будете готовы отправить свой модуль Perl, тогда существует стандартный способ создания дерева модулей Perl. Это делается с помощью утилиты h2xs . Эта утилита поставляется вместе с Perl. Вот синтаксис для использования h2xs —
$h2xs -AX -n ModuleName
Например, если ваш модуль доступен в файле Person.pm , просто введите следующую команду:
$h2xs -AX -n Person
Это даст следующий результат —
Writing Person/lib/Person.pm Writing Person/Makefile.PL Writing Person/README Writing Person/t/Person.t Writing Person/Changes Writing Person/MANIFEST
Вот описание этих опций —
-
-A пропускает код автозагрузчика (лучше всего используется модулями, которые определяют большое количество редко используемых подпрограмм).
-
-X пропускает элементы XS (подпрограмма eXternal, где eXternal означает внешний по отношению к Perl, т. Е. C).
-
-n указывает имя модуля.
-A пропускает код автозагрузчика (лучше всего используется модулями, которые определяют большое количество редко используемых подпрограмм).
-X пропускает элементы XS (подпрограмма eXternal, где eXternal означает внешний по отношению к Perl, т. Е. C).
-n указывает имя модуля.
Таким образом, команда выше создает следующую структуру внутри директории Person. Фактический результат показан выше.
- изменения
- Makefile.PL
- MANIFEST (содержит список всех файлов в пакете)
- ПРОЧТИ МЕНЯ
- т / (тестовые файлы)
- lib / (Актуальный исходный код находится здесь
Итак, наконец, вы упаковываете эту структуру каталогов в файл Person.tar.gz и можете отправить его. Вам нужно будет обновить файл README с соответствующими инструкциями. Вы также можете предоставить некоторые примеры тестовых файлов в каталоге t.
Установка модуля Perl
Загрузите модуль Perl в виде файла tar.gz. Используйте следующую последовательность, чтобы установить любой Perl Module Person.pm, который был загружен в виде файла Person.tar.gz .
tar xvfz Person.tar.gz cd Person perl Makefile.PL make make install
Интерпретатор Perl имеет список каталогов, в которых он ищет модули (глобальный массив @INC).
Perl — Управление процессами
Вы можете использовать Perl различными способами для создания новых процессов в соответствии с вашими требованиями. В этом руководстве будет перечислено несколько важных и наиболее часто используемых методов создания и управления процессами Perl.
-
Вы можете использовать специальные переменные $$ или $ PROCESS_ID, чтобы получить текущий идентификатор процесса.
-
Каждый процесс, созданный с помощью любого из упомянутых методов, поддерживает свою собственную виртуальную среду с переменной % ENV .
-
Функция exit () всегда выходит только из дочернего процесса, который выполняет эту функцию, и основной процесс в целом не завершится, если не завершены все запущенные дочерние процессы.
-
Все открытые дескрипторы дублируются в дочерних процессах, поэтому закрытие любых дескрипторов в одном процессе не влияет на другие.
Вы можете использовать специальные переменные $$ или $ PROCESS_ID, чтобы получить текущий идентификатор процесса.
Каждый процесс, созданный с помощью любого из упомянутых методов, поддерживает свою собственную виртуальную среду с переменной % ENV .
Функция exit () всегда выходит только из дочернего процесса, который выполняет эту функцию, и основной процесс в целом не завершится, если не завершены все запущенные дочерние процессы.
Все открытые дескрипторы дублируются в дочерних процессах, поэтому закрытие любых дескрипторов в одном процессе не влияет на другие.
Оператор Backstick
Этот самый простой способ выполнения любой команды Unix — с помощью оператора backstick. Вы просто помещаете свою команду внутри оператора backstick, что приведет к ее выполнению и вернет ее результат, который можно сохранить следующим образом:
#!/usr/bin/perl
@files = `ls -l`;
foreach $file (@files) {
print $file;
}
1;
Когда приведенный выше код выполняется, он перечисляет все файлы и каталоги, доступные в текущем каталоге —
drwxr-xr-x 3 root root 4096 Sep 14 06:46 9-14 drwxr-xr-x 4 root root 4096 Sep 13 07:54 android -rw-r--r-- 1 root root 574 Sep 17 15:16 index.htm drwxr-xr-x 3 544 401 4096 Jul 6 16:49 MIME-Lite-3.01 -rw-r--r-- 1 root root 71 Sep 17 15:16 test.pl drwx------ 2 root root 4096 Sep 17 15:11 vAtrJdy
Функция system ()
Вы также можете использовать функцию system () для выполнения любой команды Unix, чей вывод будет отправлен на вывод сценария perl. По умолчанию это экран, т. Е. STDOUT, но вы можете перенаправить его в любой файл, используя оператор перенаправления> —
#!/usr/bin/perl system( "ls -l") 1;
Когда приведенный выше код выполняется, он перечисляет все файлы и каталоги, доступные в текущем каталоге —
drwxr-xr-x 3 root root 4096 Sep 14 06:46 9-14 drwxr-xr-x 4 root root 4096 Sep 13 07:54 android -rw-r--r-- 1 root root 574 Sep 17 15:16 index.htm drwxr-xr-x 3 544 401 4096 Jul 6 16:49 MIME-Lite-3.01 -rw-r--r-- 1 root root 71 Sep 17 15:16 test.pl drwx------ 2 root root 4096 Sep 17 15:11 vAtrJdy
Будьте осторожны, когда ваша команда содержит переменные среды оболочки, такие как $ PATH или $ HOME. Попробуйте следующие три сценария —
#!/usr/bin/perl
$PATH = "I am Perl Variable";
system('echo $PATH'); # Treats $PATH as shell variable
system("echo $PATH"); # Treats $PATH as Perl variable
system("echo \$PATH"); # Escaping $ works.
1;
Когда приведенный выше код выполняется, он дает следующий результат в зависимости от того, что установлено в переменной оболочки $ PATH.
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin I am Perl Variable /usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin
Функция fork ()
Perl предоставляет функцию fork (), которая соответствует системному вызову Unix с тем же именем. На большинстве Unix-подобных платформ, где доступен системный вызов fork (), Perl fork () просто вызывает его. На некоторых платформах, таких как Windows, где системный вызов fork () недоступен, Perl может быть построен для эмуляции fork () на уровне интерпретатора.
Функция fork () используется для клонирования текущего процесса. Этот вызов создает новый процесс, выполняющий ту же программу в той же точке. Он возвращает дочерний pid родительскому процессу, 0 — дочернему процессу или undef, если ответвление не выполнено.
Вы можете использовать функцию exec () внутри процесса для запуска запрошенного исполняемого файла, который будет выполняться в отдельной области процесса, и exec () будет ожидать его завершения, прежде чем завершить работу с тем же состоянием выхода, что и у этого процесса.
#!/usr/bin/perl
if(!defined($pid = fork())) {
# fork returned undef, so unsuccessful
die "Cannot fork a child: $!";
} elsif ($pid == 0) {
print "Printed by child process\n";
exec("date") || die "can't exec date: $!";
} else {
# fork returned 0 nor undef
# so this branch is parent
print "Printed by parent process\n";
$ret = waitpid($pid, 0);
print "Completed process id: $ret\n";
}
1;
Когда приведенный выше код выполняется, он дает следующий результат —
Printed by parent process Printed by child process Tue Sep 17 15:41:08 CDT 2013 Completed process id: 17777
Wait () и waitpid () могут быть переданы как идентификатор псевдопроцесса, возвращаемый fork (). Эти вызовы будут должным образом ожидать завершения псевдопроцесса и возвращать его статус. Если вы разветвляетесь, не дожидаясь своих детей, используя функцию waitpid () , вы будете накапливать зомби. В системах Unix вы можете избежать этого, установив для $ SIG {CHLD} значение «IGNORE» следующим образом:
#!/usr/bin/perl
local $SIG{CHLD} = "IGNORE";
if(!defined($pid = fork())) {
# fork returned undef, so unsuccessful
die "Cannot fork a child: $!";
} elsif ($pid == 0) {
print "Printed by child process\n";
exec("date") || die "can't exec date: $!";
} else {
# fork returned 0 nor undef
# so this branch is parent
print "Printed by parent process\n";
$ret = waitpid($pid, 0);
print "Completed process id: $ret\n";
}
1;
Когда приведенный выше код выполняется, он дает следующий результат —
Printed by parent process Printed by child process Tue Sep 17 15:44:07 CDT 2013 Completed process id: -1
Функция kill ()
Функция Perl kill (‘KILL’, (Process List)) может быть использована для завершения псевдопроцесса путем передачи ему идентификатора, возвращаемого fork ().
Обратите внимание, что использование kill (‘KILL’, (Process List)) в псевдопроцессе () может обычно вызывать утечки памяти, поскольку поток, реализующий псевдопроцесс, не получает возможности очистить свои ресурсы.
Вы можете использовать функцию kill () для отправки любого другого сигнала целевым процессам, например, следующая команда отправит SIGINT идентификаторам процессов 104 и 102 —
#!/usr/bin/perl
kill('INT', 104, 102);
1;
Perl — встроенная документация
Вы можете встроить документацию Pod (Plain Old Text) в свои модули и скрипты Perl. Ниже приведено правило для использования встроенной документации в вашем коде Perl.
Начните документацию с пустой строки, команды a = head1 в начале, и завершите ее с помощью = cut
Perl будет игнорировать текст Pod, который вы ввели в коде. Ниже приведен простой пример использования встроенной документации внутри вашего кода Perl:
#!/usr/bin/perl print "Hello, World\n"; =head1 Hello, World Example This example demonstrate very basic syntax of Perl. =cut print "Hello, Universe\n";
Когда приведенный выше код выполняется, он дает следующий результат —
Hello, World Hello, Universe
Если вы собираетесь поместить свой Pod в конец файла и используете метку вырезания __END__ или __DATA__, обязательно поставьте пустую строку перед первой командой Pod следующим образом, в противном случае перед пустой строкой = head1 , многие переводчики не распознали бы = head1 как начало блока Pod.
#!/usr/bin/perl
print "Hello, World\n";
while(<DATA>) {
print $_;
}
__END__
=head1 Hello, World Example
This example demonstrate very basic syntax of Perl.
print "Hello, Universe\n";
Когда приведенный выше код выполняется, он дает следующий результат —
Hello, World =head1 Hello, World Example This example demonstrate very basic syntax of Perl. print "Hello, Universe\n";
Давайте возьмем еще один пример для того же кода без чтения части DATA —
#! / USR / бен / Perl print "Hello, World \ n"; __КОНЕЦ__ = head1 Привет, пример мира Этот пример демонстрирует очень простой синтаксис Perl. print "Привет, Вселенная \ n";
Когда приведенный выше код выполняется, он дает следующий результат —
Hello, World
Что такое POD?
Pod — это простой в использовании язык разметки, используемый для написания документации для Perl, программ Perl и модулей Perl. Существуют различные переводчики для преобразования Pod в различные форматы, такие как простой текст, HTML, справочные страницы и многое другое. Стручковая разметка состоит из трех основных видов абзацев —
-
Обычный абзац — Вы можете использовать коды форматирования в обычных абзацах, для полужирного, курсива, стиля кода, гиперссылок и многого другого.
-
Дословный абзац. Дословные абзацы обычно используются для представления кодового блока или другого текста, который не требует какого-либо специального анализа или форматирования и который не следует переносить.
-
Командный абзац — командный абзац используется для специальной обработки целых кусков текста, обычно как заголовков или частей списков. Все абзацы команды начинаются с =, за которым следует идентификатор, за которым следует произвольный текст, который команда может использовать по своему усмотрению. В настоящее время признаны команды —
Обычный абзац — Вы можете использовать коды форматирования в обычных абзацах, для полужирного, курсива, стиля кода, гиперссылок и многого другого.
Дословный абзац. Дословные абзацы обычно используются для представления кодового блока или другого текста, который не требует какого-либо специального анализа или форматирования и который не следует переносить.
Командный абзац — командный абзац используется для специальной обработки целых кусков текста, обычно как заголовков или частей списков. Все абзацы команды начинаются с =, за которым следует идентификатор, за которым следует произвольный текст, который команда может использовать по своему усмотрению. В настоящее время признаны команды —
=pod =head1 Heading Text =head2 Heading Text =head3 Heading Text =head4 Heading Text =over indentlevel =item stuff =back =begin format =end format =for format text... =encoding type =cut
Примеры POD
Рассмотрим следующий POD —
=head1 SYNOPSIS Copyright 2005 [TUTORIALSOPOINT]. =cut
Вы можете использовать утилиту pod2html, доступную в Linux, для преобразования вышеупомянутого POD в HTML, поэтому она даст следующий результат:
Copyright 2005 [TUTORIALSOPOINT].
Далее рассмотрим следующий пример —
=head2 An Example List =over 4 =item * This is a bulleted list. =item * Here's another item. =back =begin html <p> Here's some embedded HTML. In this block I can include images, apply <span style="color: green"> styles</span>, or do anything else I can do with HTML. pod parsers that aren't outputting HTML will completely ignore it. </p> =end html
Когда вы преобразуете POD в HTML с помощью pod2html, он даст следующий результат —
An Example List This is a bulleted list. Here's another item. Here's some embedded HTML. In this block I can include images, apply styles, or do anything else I can do with HTML. pod parsers that aren't outputting HTML will completely ignore it.
Perl — Функции Ссылки
Вот список всех важных функций, поддерживаемых стандартным Perl.
abs — функция абсолютного значения
принять — принять входящий сокет
будильник — график SIGALRM
atan2 — арктангенс Y / X в диапазоне от -PI до PI
bind — привязывает адрес к сокету
binmode — подготовить двоичные файлы для ввода / вывода
благослови — создай объект
caller — получить контекст текущего вызова подпрограммы
chdir — изменить текущий рабочий каталог
chmod — меняет права доступа к списку файлов
chomp — удалить разделитель конечных записей из строки
chop — удалить последний символ из строки
chown — изменить принадлежность списка файлов
chr — получить символ, который представляет это число
chroot — сделать каталог новым корнем для поиска пути
close — закрыть файл (или трубу или сокет) дескриптор
closedir — закрывать дескриптор каталога
подключиться — подключиться к удаленной розетке
продолжить — дополнительный трейлинг-блок через некоторое время или foreach
функция кос — косинус
crypt — одностороннее шифрование в стиле passwd
dbmclose — прерывает привязку к связанному файлу dbm
dbmopen — создать привязку к связанному файлу dbm
определенный — проверить, определено ли значение, переменная или функция или нет
удалить — удаляет значение из хеша
умереть — вызвать исключение или выручить
сделать — превратить блок в срок
dump — создать немедленный дамп ядра
each — получить следующую пару ключ / значение из хеша
endgrent — сделать с помощью группового файла
endhostent — выполняется с помощью файла hosts
endnetent — сделать с помощью сетевого файла
endprotoent — сделать с помощью файла протоколов
endpwent — сделать с помощью файла passwd
endservent — сделать с помощью файла служб
eof — проверить дескриптор файла на его конец
eval — ловить исключения или компилировать и запускать код
exec — откажитесь от этой программы, чтобы запустить другую
существует — проверить, присутствует ли хэш-ключ
выход — прекратить эту программу
опыт — поднять я
fcntl — системный вызов управления файлами
fileno — возвращает дескриптор файла из дескриптора файла
flock — заблокировать весь файл с помощью консультативной блокировки
fork — создайте новый процесс, как этот
format — объявить формат изображения с использованием функции write ()
formline — внутренняя функция, используемая для форматов
getc — получить следующий символ из дескриптора файла
getgrent — получить следующую запись группы
getgrgid — получить групповую запись с указанным идентификатором пользователя группы
getgrnam — получить запись группы по названию группы
gethostbyaddr — получить запись хоста по его адресу
gethostbyname — получить имя хоста с указанным именем
gethostent — получить следующую запись хостов
getlogin — вернуть кто залогинился на этом tty
getnetbyaddr — получить сетевую запись по ее адресу
getnetbyname — получить сетевую запись с указанным именем
getnetent — получить следующую запись сети
getpeername — находит другой конец сокетного соединения
getpgrp — получить группу процессов
getppid — получить идентификатор родительского процесса
getpriority — получить текущее значение
getprotobyname — получить запись протокола с указанным именем
getprotobynumber — получить номер протокола протокола
getprotoent — получить следующую запись протокола
getpwent — получить следующую запись passwd
getpwnam — получить запись passwd с указанным логином
getpwuid — получает запись passwd с указанным идентификатором пользователя.
getservbyname — получить запись сервисов по названию
getservbyport — получает сервисную запись с указанным числовым портом
getservent — получить следующую запись сервиса
getsockname — получить sockaddr для данного сокета
getsockopt — получить параметры сокета для данного сокета
glob — расширяет имена файлов, используя подстановочные знаки
gmtime — конвертировать время UNIX в запись или строку, используя формат времени по Гринвичу.
Перейти — создать код спагетти
grep — найти элементы в проверке списка на соответствие заданному критерию
hex — преобразовать строку в шестнадцатеричное число
import — патч пространства имен модуля в свой
index — найти подстроку в строке
int — получить целую часть числа
ioctl — системно-зависимое устройство управления системным вызовом
join — объединить список в строку, используя разделитель
keys — получить список индексов из хеша
kill — отправить сигнал процессу или группе процессов
последний — выйти из блока преждевременно
lc — вернуть строчную версию строки
lcfirst — возвращает строку со следующей буквой в нижнем регистре
длина — возвращает количество байтов в строке
ссылка — создать жесткую ссылку в файловой системе
слушай — зарегистрируй свой сокет как сервер
local — создать временное значение для глобальной переменной (динамическая область видимости)
localtime — конвертировать время UNIX в запись или строку, используя местное время
lock — получить блокировку потока для переменной, подпрограммы или метода
log — получить натуральный логарифм для числа
lstat — stat символическая ссылка
m — сопоставить строку с шаблоном регулярного выражения
карта — применить изменение к списку, чтобы получить новый список с изменениями
mkdir — создать каталог
msgctl — операции управления сообщениями SysV IPC
msgget — получить очередь сообщений SysV IPC
msgrcv — получить сообщение SysV IPC из очереди сообщений
msgsnd — отправить сообщение SysV IPC в очередь сообщений
my — объявить и назначить локальную переменную (лексическая область видимости)
следующий — итерация блока преждевременно
нет — не импортировать некоторые символы модуля или семантику во время компиляции
oct — преобразовать строку в восьмеричное число
open — открыть файл, канал или дескриптор
opendir — открыть каталог
ord — найти числовое представление персонажа
our — объявить и назначить переменную пакета (лексическая область видимости)
pack — преобразовать список в двоичное представление
package — объявить отдельное глобальное пространство имен
pipe — открыть пару связанных файловых дескрипторов
pop — удалить последний элемент из массива и вернуть его
pos — найти или установить смещение для последнего / следующего поиска m // g
print — вывести список в дескриптор файла
printf — вывести отформатированный список в дескриптор файла
prototype — получить прототип (если есть) подпрограммы
push — добавить один или несколько элементов в массив
q — одиночная кавычка строки
qq — вдвойне цитируй строку
qr — шаблон компиляции
quotemeta — цитирует регулярное выражение магических символов
qw — процитировать список слов
qx — обратная кавычка цитата строка
rand — получить следующее псевдослучайное число
read — буферизованный ввод фиксированной длины из дескриптора файла
readdir — получить каталог из дескриптора каталога
readline — извлечь запись из файла
readlink — определить, куда указывает символическая ссылка
readpipe — выполнить системную команду и собрать стандартный вывод
recv — получить сообщение через сокет
повторить — начать этот цикл снова
ref — узнать тип вещи, на которую ссылаются
переименовать — изменить имя файла
require — загружать внешние функции из библиотеки во время выполнения
сброс — очистить все переменные с заданным именем
return — рано выходить из функции
перевернуть — перевернуть строку или список
rewinddir — сбросить дескриптор каталога
rindex — поиск подстроки справа налево
rmdir — удалить каталог
s — заменить шаблон на строку
scalar — форсирует скалярный контекст
seek — переместить указатель файла для ввода-вывода с произвольным доступом
seekdir — перемещать указатель каталога
выберите — сбросить выход по умолчанию или сделать мультиплексирование ввода / вывода
semctl — операции управления семафором SysV
semget — получить набор семафоров SysV
semop — операции семафора SysV
отправить — отправить сообщение через сокет
setgrent — подготовить файл группы для использования
sethostent — подготовить файл hosts для использования
setnetent — подготовить файл сети для использования
setpgrp — установить группу процессов для процесса
setpriority — установить приятное значение процесса
setprotoent — подготовить файл протоколов для использования
setpwent — подготовить файл passwd для использования
setservent — подготовить файл сервисов для использования
setsockopt — установить некоторые параметры сокета
shift — удалить первый элемент массива и вернуть его
shmctl — операции с разделяемой памятью SysV
shmget — получить идентификатор сегмента разделяемой памяти SysV
shmread — читает общую память SysV
shmwrite — записать SysV в общую память
выключение — закройте только половину разъема
грех — вернуть синус числа
sleep — блокировать на некоторое количество секунд
сокет — создать сокет
socketpair — создайте пару сокетов
sort — сортировка списка значений
splice — добавлять или удалять элементы в любом месте массива
split — разделить строку, используя разделитель регулярных выражений
sprintf — форматированная печать в строку
sqrt — функция квадратного корня
srand — засеять генератор случайных чисел
stat — получить информацию о статусе файла
исследование — оптимизировать входные данные для повторных поисков
суб- объявить подпрограмму, возможно, анонимно
substr — получить или изменить порцию перемешивания
символическая ссылка — создать символическую ссылку на файл
syscall — выполнить произвольный системный вызов
sysopen — открыть файл, канал или дескриптор.
sysread — небуферизованный ввод фиксированной длины из дескриптора файла
sysseek — позиционировать указатель ввода / вывода на дескрипторе, используемом с sysread и syswrite
система — запустить отдельную программу
syswrite — небуферизованный вывод фиксированной длины в дескриптор файла
сказать — получить текущий searchpointer на файловый дескриптор
telldir — получить текущий указатель на указатель каталога
tie — связать переменную с классом объекта
tied — получить ссылку на объект, лежащий в основе связанной переменной
время — возвращаемое количество секунд с 1970 года
times — вернуть прошедшее время для себя и дочерних процессов
tr — транслитерировать строку
усекать — сокращать файл
uc — возвращает строку в верхнем регистре
ucfirst — возвращает строку со следующей буквой в верхнем регистре
umask — установить маску режима создания файла
undef — удалить определение переменной или функции
unlink — удалить одну ссылку на файл
unpack — преобразовать двоичную структуру в обычные переменные perl
unshift — добавить больше элементов в начало списка
untie — разорвать связь с переменной
use — загрузить модуль во время компиляции
utime — установить последний доступ к файлу и изменить время
values — возвращает список значений в хэше
vec — проверить или установить определенные биты в строке
подождите — дождитесь смерти любого дочернего процесса
waitpid — дождаться смерти определенного дочернего процесса
wantarray — получить void vs скалярный vs контекст списка текущего вызова подпрограммы
warn — распечатать отладочную информацию
написать — распечатать запись
-X — проверка файла (-r, -x и т. Д.)
y — транслитерировать строку