Hibernate — Обзор ORM
JDBC расшифровывается как Java Database Connectivity . Он предоставляет набор API Java для доступа к реляционным базам данных из программы Java. Эти API Java позволяют программам Java выполнять операторы SQL и взаимодействовать с любой базой данных, совместимой с SQL.
JDBC предоставляет гибкую архитектуру для написания независимого от базы данных приложения, которое может работать на разных платформах и взаимодействовать с разными СУБД без каких-либо изменений.
Плюсы и минусы JDBC
| Плюсы JDBC | Минусы JDBC |
|---|---|
|
Чистая и простая обработка SQL Хорошая производительность с большими данными Очень хорошо для небольших приложений Простой синтаксис так легко выучить |
Сложный, если он используется в крупных проектах Большие накладные расходы на программирование Нет инкапсуляции Трудно реализовать концепцию MVC Запрос специфичен для СУБД |
Чистая и простая обработка SQL
Хорошая производительность с большими данными
Очень хорошо для небольших приложений
Простой синтаксис так легко выучить
Сложный, если он используется в крупных проектах
Большие накладные расходы на программирование
Нет инкапсуляции
Трудно реализовать концепцию MVC
Запрос специфичен для СУБД
Почему объектно-реляционное сопоставление (ORM)?
Когда мы работаем с объектно-ориентированной системой, существует несоответствие между объектной моделью и реляционной базой данных. СУБД представляют данные в табличном формате, тогда как объектно-ориентированные языки, такие как Java или C #, представляют их как взаимосвязанный граф объектов.
Рассмотрим следующий Java-класс с правильными конструкторами и связанной с ним публичной функцией —
public class Employee { private int id; private String first_name; private String last_name; private int salary; public Employee() {} public Employee(String fname, String lname, int salary) { this.first_name = fname; this.last_name = lname; this.salary = salary; } public int getId() { return id; } public String getFirstName() { return first_name; } public String getLastName() { return last_name; } public int getSalary() { return salary; } }
Учтите, что вышеперечисленные объекты должны быть сохранены и извлечены в следующую таблицу RDBMS:
create table EMPLOYEE ( id INT NOT NULL auto_increment, first_name VARCHAR(20) default NULL, last_name VARCHAR(20) default NULL, salary INT default NULL, PRIMARY KEY (id) );
Первая проблема: что если нам нужно изменить дизайн нашей базы данных после разработки нескольких страниц или нашего приложения? Во-вторых, загрузка и хранение объектов в реляционной базе данных подвергает нас следующим пяти проблемам несоответствия:
| Sr.No. | Несоответствие и описание |
|---|---|
| 1 |
Зернистость Иногда у вас будет объектная модель, которая имеет больше классов, чем количество соответствующих таблиц в базе данных. |
| 2 |
наследование СУБД не определяют ничего похожего на Inheritance, которая является естественной парадигмой в объектно-ориентированных языках программирования. |
| 3 |
тождественность СУБД определяет ровно одно понятие «сходство»: первичный ключ. Java, однако, определяет как идентичность объекта (a == b), так и равенство объектов (a.equals (b)). |
| 4 |
ассоциации Объектно-ориентированные языки представляют ассоциации с использованием объектных ссылок, тогда как СУБД представляет ассоциацию в виде столбца внешнего ключа. |
| 5 |
навигация Способы доступа к объектам в Java и в RDBMS принципиально различны. |
Зернистость
Иногда у вас будет объектная модель, которая имеет больше классов, чем количество соответствующих таблиц в базе данных.
наследование
СУБД не определяют ничего похожего на Inheritance, которая является естественной парадигмой в объектно-ориентированных языках программирования.
тождественность
СУБД определяет ровно одно понятие «сходство»: первичный ключ. Java, однако, определяет как идентичность объекта (a == b), так и равенство объектов (a.equals (b)).
ассоциации
Объектно-ориентированные языки представляют ассоциации с использованием объектных ссылок, тогда как СУБД представляет ассоциацию в виде столбца внешнего ключа.
навигация
Способы доступа к объектам в Java и в RDBMS принципиально различны.
Приложение O bject- R elational M (ORM) — это решение для обработки всех вышеуказанных несовпадений импеданса.
Что такое ORM?
ORM расшифровывается как O bject- R elational M apping (ORM) — это метод программирования для преобразования данных между реляционными базами данных и объектно-ориентированными языками программирования, такими как Java, C # и т. Д.
Система ORM имеет следующие преимущества перед простым JDBC:
| Sr.No. | преимущества |
|---|---|
| 1 | Давайте бизнес-кодам обращаться к объектам, а не к таблицам БД. |
| 2 | Скрывает детали SQL-запросов от ОО-логики. |
| 3 | По материалам JDBC «под капотом». |
| 4 | Не нужно заниматься реализацией базы данных. |
| 5 | Объекты, основанные на бизнес-концепциях, а не на структуре базы данных. |
| 6 | Управление транзакциями и автоматическая генерация ключей. |
| 7 | Быстрая разработка приложения. |
Решение ORM состоит из следующих четырех объектов:
| Sr.No. | Решения |
|---|---|
| 1 | API для выполнения основных операций CRUD над объектами постоянных классов. |
| 2 | Язык или API для указания запросов, которые ссылаются на классы и свойства классов. |
| 3 | Настраиваемое средство для указания метаданных отображения. |
| 4 | Техника взаимодействия с транзакционными объектами для выполнения грязной проверки, отложенной выборки ассоциаций и других функций оптимизации. |
Java ORM Frameworks
В Java есть несколько постоянных сред и опций ORM. Постоянная структура — это служба ORM, которая сохраняет и извлекает объекты в реляционную базу данных.
- Enterprise JavaBeans Entity Beans
- Объекты данных Java
- колесико
- TopLink
- Весна ДАО
- зимовать
- И многое другое
Hibernate — Обзор
Hibernate — это решение O bject- R elational M (ORM) для JAVA. Это постоянный фреймворк с открытым исходным кодом, созданный Гэвином Кингом в 2001 году. Это мощный высокопроизводительный сервис объектно-реляционной персистентности и запросов для любого Java-приложения.
Hibernate отображает классы Java в таблицы базы данных и из типов данных Java в типы данных SQL и освобождает разработчика от 95% общих задач программирования, связанных с сохранением данных.
Hibernate находится между традиционными объектами Java и сервером базы данных и выполняет все действия по сохранению этих объектов на основе соответствующих механизмов и шаблонов O / R.

Преимущества гибернации
-
Hibernate занимается отображением классов Java в таблицы базы данных с использованием файлов XML и без написания какой-либо строки кода.
-
Предоставляет простые API-интерфейсы для хранения и извлечения объектов Java непосредственно в базу данных и из нее.
-
Если в базе данных или в любой таблице произошли изменения, вам нужно изменить только свойства XML-файла.
-
Абстрагирует незнакомые типы SQL и предоставляет способ работы со знакомыми объектами Java.
-
Hibernate не требует сервера приложений для работы.
-
Управляет сложными ассоциациями объектов вашей базы данных.
-
Минимизирует доступ к базе данных с помощью умных стратегий извлечения.
-
Обеспечивает простой запрос данных.
Hibernate занимается отображением классов Java в таблицы базы данных с использованием файлов XML и без написания какой-либо строки кода.
Предоставляет простые API-интерфейсы для хранения и извлечения объектов Java непосредственно в базу данных и из нее.
Если в базе данных или в любой таблице произошли изменения, вам нужно изменить только свойства XML-файла.
Абстрагирует незнакомые типы SQL и предоставляет способ работы со знакомыми объектами Java.
Hibernate не требует сервера приложений для работы.
Управляет сложными ассоциациями объектов вашей базы данных.
Минимизирует доступ к базе данных с помощью умных стратегий извлечения.
Обеспечивает простой запрос данных.
Поддерживаемые базы данных
Hibernate поддерживает практически все основные СУБД. Ниже приведен список нескольких ядер баз данных, поддерживаемых Hibernate.
- HSQL Database Engine
- DB2 / NT
- MySQL
- PostgreSQL
- FrontBase
- оракул
- База данных Microsoft SQL Server
- Sybase SQL Server
- Informix Dynamic Server
Поддерживаемые технологии
Hibernate поддерживает множество других технологий, в том числе —
- XDoclet Spring
- J2EE
- Eclipse плагины
- специалист
Hibernate — Архитектура
Hibernate имеет многоуровневую архитектуру, которая помогает пользователю работать без знания базовых API. Hibernate использует базу данных и данные конфигурации для предоставления приложениям постоянных сервисов (и постоянных объектов).
Ниже приводится очень высокий уровень представления архитектуры приложений Hibernate.
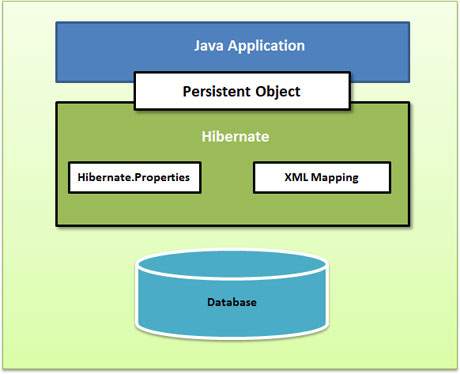
Ниже приведено подробное представление архитектуры приложений Hibernate с ее важными основными классами.
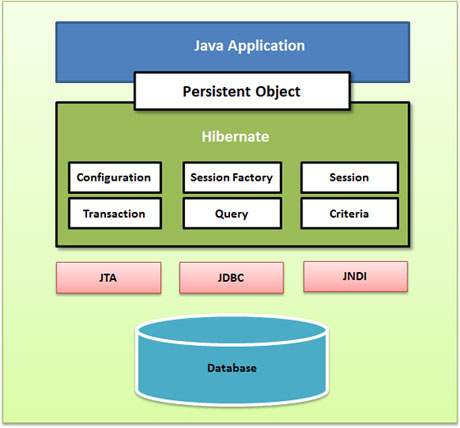
Hibernate использует различные существующие API Java, такие как JDBC, API транзакций Java (JTA) и интерфейс именования и каталогов Java (JNDI). JDBC обеспечивает элементарный уровень абстракции функциональности, общей для реляционных баз данных, что позволяет Hibernate поддерживать практически любую базу данных с драйвером JDBC. JNDI и JTA позволяют интегрировать Hibernate с серверами приложений J2EE.
В следующем разделе дается краткое описание каждого из объектов класса, участвующих в Hibernate Application Architecture.
Объект конфигурации
Объект конфигурации — это первый объект Hibernate, который вы создаете в любом приложении Hibernate. Обычно создается только один раз во время инициализации приложения. Он представляет файл конфигурации или свойств, требуемый Hibernate.
Объект конфигурации содержит два ключевых компонента:
-
Соединение с базой данных — это обрабатывается через один или несколько файлов конфигурации, поддерживаемых Hibernate. Это файлы hibernate.properties и hibernate.cfg.xml .
-
Настройка отображения классов — этот компонент создает связь между классами Java и таблицами базы данных.
Соединение с базой данных — это обрабатывается через один или несколько файлов конфигурации, поддерживаемых Hibernate. Это файлы hibernate.properties и hibernate.cfg.xml .
Настройка отображения классов — этот компонент создает связь между классами Java и таблицами базы данных.
SessionFactory Object
Объект конфигурации используется для создания объекта SessionFactory, который, в свою очередь, настраивает Hibernate для приложения, используя предоставленный файл конфигурации, и позволяет создавать экземпляр объекта Session. SessionFactory является потокобезопасным объектом и используется всеми потоками приложения.
SessionFactory — это тяжеловесный объект; обычно создается во время запуска приложения и сохраняется для последующего использования. Вам потребуется один объект SessionFactory для каждой базы данных с использованием отдельного файла конфигурации. Итак, если вы используете несколько баз данных, вам придется создать несколько объектов SessionFactory.
Объект сеанса
Сессия используется для получения физического соединения с базой данных. Объект Session является легким и предназначен для реализации каждый раз, когда необходимо взаимодействие с базой данных. Постоянные объекты сохраняются и извлекаются через объект Session.
Объекты сеанса не должны оставаться открытыми в течение длительного времени, потому что они обычно не являются потокобезопасными, и их следует создавать и уничтожать по мере необходимости.
Объект сделки
Транзакция представляет собой единицу работы с базой данных, и большинство СУБД поддерживает функциональность транзакций. Транзакции в Hibernate обрабатываются соответствующим менеджером транзакций и транзакциями (из JDBC или JTA).
Это необязательный объект, и приложения Hibernate могут не использовать этот интерфейс, а вместо этого управлять транзакциями в собственном коде приложения.
Объект запроса
Объекты запросов используют строку SQL или язык запросов Hibernate (HQL) для извлечения данных из базы данных и создания объектов. Экземпляр Query используется для привязки параметров запроса, ограничения количества результатов, возвращаемых запросом, и, наконец, для выполнения запроса.
Критерий Объект
Объекты критериев используются для создания и выполнения объектно-ориентированных запросов критериев для извлечения объектов.
Hibernate — Окружающая среда
В этой главе объясняется, как установить Hibernate и другие связанные пакеты для подготовки среды для приложений Hibernate. Мы поработаем с базой данных MySQL, чтобы поэкспериментировать с примерами Hibernate, поэтому убедитесь, что у вас уже есть настройка для базы данных MySQL. Для более подробной информации о MySQL, вы можете проверить наш учебник MySQL .
Скачивание Hibernate
Предполагается, что в вашей системе уже установлена последняя версия Java. Ниже приведены простые шаги для загрузки и установки Hibernate в вашей системе:
-
Выберите, хотите ли вы установить Hibernate в Windows или Unix, а затем перейдите к следующему шагу, чтобы загрузить .zip-файл для windows и .tz-файл для Unix.
-
Загрузите последнюю версию Hibernate с http://www.hibernate.org/downloads .
-
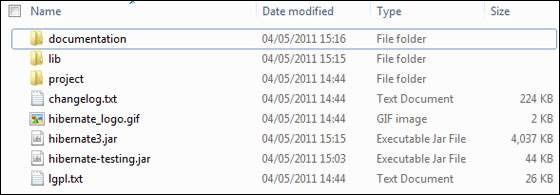
На момент написания этого руководства я скачал hibernate-distribution3.6.4.Final, и когда вы распакуете загруженный файл, он даст вам структуру каталогов, как показано на следующем рисунке
Выберите, хотите ли вы установить Hibernate в Windows или Unix, а затем перейдите к следующему шагу, чтобы загрузить .zip-файл для windows и .tz-файл для Unix.
Загрузите последнюю версию Hibernate с http://www.hibernate.org/downloads .
На момент написания этого руководства я скачал hibernate-distribution3.6.4.Final, и когда вы распакуете загруженный файл, он даст вам структуру каталогов, как показано на следующем рисунке
Установка Hibernate
После того, как вы загрузили и разархивировали последнюю версию установочного файла Hibernate, вам необходимо выполнить два простых шага. Убедитесь, что вы устанавливаете переменную CLASSPATH правильно, иначе вы столкнетесь с проблемой при компиляции приложения.
-
Теперь скопируйте все файлы библиотеки из / lib в ваш CLASSPATH и измените переменную classpath, чтобы включить все JAR —
-
Наконец, скопируйте файл hibernate3.jar в свой CLASSPATH. Этот файл находится в корневом каталоге установки и является основным JAR, который необходим Hibernate для своей работы.
Теперь скопируйте все файлы библиотеки из / lib в ваш CLASSPATH и измените переменную classpath, чтобы включить все JAR —
Наконец, скопируйте файл hibernate3.jar в свой CLASSPATH. Этот файл находится в корневом каталоге установки и является основным JAR, который необходим Hibernate для своей работы.
Необходимые условия гибернации
Ниже приведен список пакетов / библиотек, необходимых для Hibernate, и вам следует установить их перед началом работы с Hibernate. Чтобы установить эти пакеты, вам нужно будет скопировать файлы библиотеки из / lib в ваш CLASSPATH и соответственно изменить переменную CLASSPATH.
| Sr.No. | Пакеты / Библиотеки |
|---|---|
| 1 |
dom4j Синтаксический анализ XML www.dom4j.org/ |
| 2 |
Xalan XSLT-процессор https://xml.apache.org/xalan-j/ |
| 3 |
Xerces Анализатор Java Xerces https://xml.apache.org/xerces-j/ |
| 4 |
CGLIB Соответствующие изменения в классах Java во время выполнения http://cglib.sourceforge.net/ |
| 5 |
log4j Ведение журнала Faremwork https://logging.apache.org/log4j |
| 6 |
Commons Регистрация, электронная почта и т. Д. Https://jakarta.apache.org/commons |
| 7 |
SLF4J Фасад логирования для Java https://www.slf4j.org |
dom4j
Синтаксический анализ XML www.dom4j.org/
Xalan
XSLT-процессор https://xml.apache.org/xalan-j/
Xerces
Анализатор Java Xerces https://xml.apache.org/xerces-j/
CGLIB
Соответствующие изменения в классах Java во время выполнения http://cglib.sourceforge.net/
log4j
Ведение журнала Faremwork https://logging.apache.org/log4j
Commons
Регистрация, электронная почта и т. Д. Https://jakarta.apache.org/commons
SLF4J
Фасад логирования для Java https://www.slf4j.org
Hibernate — Конфигурация
Hibernate требует заранее знать — где найти информацию о сопоставлении, которая определяет, как ваши классы Java связаны с таблицами базы данных. Hibernate также требует набора параметров конфигурации, связанных с базой данных и других связанных параметров. Вся такая информация обычно предоставляется в виде стандартного файла свойств Java с именем hibernate.properties или в виде файла XML с именем hibernate.cfg.xml .
Я рассмотрю файл hibernate.cfg.xml в формате XML, чтобы указать необходимые свойства Hibernate в моих примерах. Большинство свойств принимают значения по умолчанию, и нет необходимости указывать их в файле свойств, если это действительно не требуется. Этот файл хранится в корневом каталоге пути к классу вашего приложения.
Спящие свойства
Ниже приведен список важных свойств, вам необходимо будет настроить для баз данных в автономной ситуации —
| Sr.No. | Свойства и описание |
|---|---|
| 1 |
hibernate.dialect Это свойство заставляет Hibernate генерировать соответствующий SQL для выбранной базы данных. |
| 2 |
hibernate.connection.driver_class Класс драйвера JDBC. |
| 3 |
hibernate.connection.url URL JDBC для экземпляра базы данных. |
| 4 |
hibernate.connection.username Имя пользователя базы данных. |
| 5 |
hibernate.connection.password Пароль базы данных. |
| 6 |
hibernate.connection.pool_size Ограничивает количество соединений, ожидающих в пуле соединений базы данных Hibernate. |
| 7 |
hibernate.connection.autocommit Позволяет использовать режим автоматической фиксации для соединения JDBC. |
hibernate.dialect
Это свойство заставляет Hibernate генерировать соответствующий SQL для выбранной базы данных.
hibernate.connection.driver_class
Класс драйвера JDBC.
hibernate.connection.url
URL JDBC для экземпляра базы данных.
hibernate.connection.username
Имя пользователя базы данных.
hibernate.connection.password
Пароль базы данных.
hibernate.connection.pool_size
Ограничивает количество соединений, ожидающих в пуле соединений базы данных Hibernate.
hibernate.connection.autocommit
Позволяет использовать режим автоматической фиксации для соединения JDBC.
Если вы используете базу данных вместе с сервером приложений и JNDI, вам придется настроить следующие свойства:
| Sr.No. | Свойства и описание |
|---|---|
| 1 |
hibernate.connection.datasource Имя JNDI, определенное в контексте сервера приложений, которое вы используете для приложения. |
| 2 |
hibernate.jndi.class Класс InitialContext для JNDI. |
| 3 |
hibernate.jndi. <JNDIpropertyname> Передает любое свойство JNDI, которое вам нравится, в InitialContext JNDI. |
| 4 |
hibernate.jndi.url Предоставляет URL для JNDI. |
| 5 |
hibernate.connection.username Имя пользователя базы данных. |
| 6 |
hibernate.connection.password Пароль базы данных. |
hibernate.connection.datasource
Имя JNDI, определенное в контексте сервера приложений, которое вы используете для приложения.
hibernate.jndi.class
Класс InitialContext для JNDI.
hibernate.jndi. <JNDIpropertyname>
Передает любое свойство JNDI, которое вам нравится, в InitialContext JNDI.
hibernate.jndi.url
Предоставляет URL для JNDI.
hibernate.connection.username
Имя пользователя базы данных.
hibernate.connection.password
Пароль базы данных.
Hibernate с базой данных MySQL
MySQL — одна из самых популярных систем баз данных с открытым исходным кодом, доступных сегодня. Давайте создадим файл конфигурации hibernate.cfg.xml и поместим его в корень пути к классу вашего приложения. Вы должны будете убедиться, что у вас есть база данных testdb, доступная в вашей базе данных MySQL, и у вас есть доступный пользовательский тест для доступа к базе данных.
Файл конфигурации XML должен соответствовать DTD конфигурации Hibernate 3, который доступен по адресу http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd .
<?xml version = "1.0" encoding = "utf-8"?> <!DOCTYPE hibernate-configuration SYSTEM "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> <property name = "hibernate.dialect"> org.hibernate.dialect.MySQLDialect </property> <property name = "hibernate.connection.driver_class"> com.mysql.jdbc.Driver </property> <!-- Assume test is the database name --> <property name = "hibernate.connection.url"> jdbc:mysql://localhost/test </property> <property name = "hibernate.connection.username"> root </property> <property name = "hibernate.connection.password"> root123 </property> <!-- List of XML mapping files --> <mapping resource = "Employee.hbm.xml"/> </session-factory> </hibernate-configuration>
Приведенный выше файл конфигурации содержит теги <mapping> , которые связаны с файлом hibernatemapping, и в следующей главе мы увидим, что такое файл отображения hibernate и как и почему мы его используем?
Ниже приведен список различных важных типов баз данных диалекта —
| Sr.No. | База данных и диалект собственности |
|---|---|
| 1 |
DB2 org.hibernate.dialect.DB2Dialect |
| 2 |
HSQLDB org.hibernate.dialect.HSQLDialect |
| 3 |
HypersonicSQL org.hibernate.dialect.HSQLDialect |
| 4 |
Informix org.hibernate.dialect.InformixDialect |
| 5 |
Энгр org.hibernate.dialect.IngresDialect |
| 6 |
Interbase org.hibernate.dialect.InterbaseDialect |
| 7 |
Microsoft SQL Server 2000 org.hibernate.dialect.SQLServerDialect |
| 8 |
Microsoft SQL Server 2005 org.hibernate.dialect.SQLServer2005Dialect |
| 9 |
Microsoft SQL Server 2008 org.hibernate.dialect.SQLServer2008Dialect |
| 10 |
MySQL org.hibernate.dialect.MySQLDialect |
| 11 |
Oracle (любая версия) org.hibernate.dialect.OracleDialect |
| 12 |
Oracle 11g org.hibernate.dialect.Oracle10gDialect |
| 13 |
Oracle 10g org.hibernate.dialect.Oracle10gDialect |
| 14 |
Oracle 9i org.hibernate.dialect.Oracle9iDialect |
| 15 |
PostgreSQL org.hibernate.dialect.PostgreSQLDialect |
| 16 |
Прогресс org.hibernate.dialect.ProgressDialect |
| 17 |
SAP DB org.hibernate.dialect.SAPDBDialect |
| 18 |
Sybase org.hibernate.dialect.SybaseDialect |
| 19 |
Sybase Anywhere org.hibernate.dialect.SybaseAnywhereDialect |
DB2
org.hibernate.dialect.DB2Dialect
HSQLDB
org.hibernate.dialect.HSQLDialect
HypersonicSQL
org.hibernate.dialect.HSQLDialect
Informix
org.hibernate.dialect.InformixDialect
Энгр
org.hibernate.dialect.IngresDialect
Interbase
org.hibernate.dialect.InterbaseDialect
Microsoft SQL Server 2000
org.hibernate.dialect.SQLServerDialect
Microsoft SQL Server 2005
org.hibernate.dialect.SQLServer2005Dialect
Microsoft SQL Server 2008
org.hibernate.dialect.SQLServer2008Dialect
MySQL
org.hibernate.dialect.MySQLDialect
Oracle (любая версия)
org.hibernate.dialect.OracleDialect
Oracle 11g
org.hibernate.dialect.Oracle10gDialect
Oracle 10g
org.hibernate.dialect.Oracle10gDialect
Oracle 9i
org.hibernate.dialect.Oracle9iDialect
PostgreSQL
org.hibernate.dialect.PostgreSQLDialect
Прогресс
org.hibernate.dialect.ProgressDialect
SAP DB
org.hibernate.dialect.SAPDBDialect
Sybase
org.hibernate.dialect.SybaseDialect
Sybase Anywhere
org.hibernate.dialect.SybaseAnywhereDialect
Hibernate — Сессии
Сессия используется для получения физического соединения с базой данных. Объект Session является легким и предназначен для реализации каждый раз, когда необходимо взаимодействие с базой данных. Постоянные объекты сохраняются и извлекаются через объект Session.
Объекты сеанса не должны оставаться открытыми в течение длительного времени, потому что они обычно не являются потокобезопасными, и их следует создавать и уничтожать по мере необходимости. Основная функция Session — предлагать, создавать, читать и удалять операции для экземпляров классов сопоставленных сущностей.
Экземпляры могут существовать в одном из следующих трех состояний в данный момент времени —
-
временный — новый экземпляр постоянного класса, который не связан с сеансом и не представлен в базе данных, а значение идентификатора не считается временным в Hibernate.
-
persistent — вы можете сделать временный экземпляр постоянным, связав его с сеансом. Постоянный экземпляр имеет представление в базе данных, значение идентификатора и связан с сеансом.
-
detached — после того, как мы закроем Hibernate Session, постоянный экземпляр станет отдельным экземпляром.
временный — новый экземпляр постоянного класса, который не связан с сеансом и не представлен в базе данных, а значение идентификатора не считается временным в Hibernate.
persistent — вы можете сделать временный экземпляр постоянным, связав его с сеансом. Постоянный экземпляр имеет представление в базе данных, значение идентификатора и связан с сеансом.
detached — после того, как мы закроем Hibernate Session, постоянный экземпляр станет отдельным экземпляром.
Экземпляр Session является сериализуемым, если его постоянные классы сериализуемы. Типичная транзакция должна использовать следующую идиому —
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
// do some work
...
tx.commit();
}
catch (Exception e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
Если сеанс вызывает исключение, транзакция должна быть откатана, а сеанс должен быть отменен.
Методы интерфейса сеанса
Существует несколько методов, предоставляемых интерфейсом Session , но я собираюсь перечислить только несколько важных методов, которые мы будем использовать в этом руководстве. Вы можете проверить документацию Hibernate для получения полного списка методов, связанных с Session и SessionFactory .
| Sr.No. | Методы и описание сессии |
|---|---|
| 1 |
Транзакция beginTransaction () Начните единицу работы и верните связанный объект транзакции. |
| 2 |
void cancelQuery () Отмените выполнение текущего запроса. |
| 3 |
void clear () Полностью очистить сессию. |
| 4 |
Соединение закрыто () Завершите сеанс, освободив соединение JDBC и очистив. |
| 5 |
Критерии createCriteria (Класс persistentClass) Создайте новый экземпляр Criteria для данного класса сущности или суперкласса класса сущности. |
| 6 |
Критерии createCriteria (String entityName) Создайте новый экземпляр Criteria для данного имени объекта. |
| 7 |
Сериализуемый getIdentifier (Объектный объект) Вернуть значение идентификатора данного объекта, связанного с этим сеансом. |
| 8 |
Запрос createFilter (Коллекция объектов, String queryString) Создайте новый экземпляр Query для данной коллекции и строку фильтра. |
| 9 |
Запрос createQuery (String queryString) Создайте новый экземпляр Query для заданной строки запроса HQL. |
| 10 |
SQLQuery createSQLQuery (String queryString) Создайте новый экземпляр SQLQuery для данной строки запроса SQL. |
| 11 |
void delete (объектный объект) Удалите постоянный экземпляр из хранилища данных. |
| 12 |
void delete (String entityName, Object object) Удалите постоянный экземпляр из хранилища данных. |
| 13 |
Сеанс get (String entityName, Serializable id) Вернуть постоянный экземпляр указанного именованного объекта с указанным идентификатором или значение NULL, если такого постоянного экземпляра нет. |
| 14 |
SessionFactory getSessionFactory () Получить фабрику сеансов, которая создала этот сеанс. |
| 15 |
void refresh (объектный объект) Перечитайте состояние данного экземпляра из базовой базы данных. |
| 16 |
Транзакция getTransaction () Получить экземпляр транзакции, связанный с этим сеансом. |
| 17 |
логическое isConnected () Проверьте, подключен ли сеанс в данный момент. |
| 18 |
логическое isDirty () Содержит ли этот сеанс какие-либо изменения, которые должны быть синхронизированы с базой данных? |
| 19 |
логическое isOpen () Проверьте, открыт ли сеанс. |
| 20 |
Сериализуемое сохранение (объектный объект) Сохраните данный временный экземпляр, сначала назначив сгенерированный идентификатор. |
| 21 |
void saveOrUpdate (Объектный объект) Сохраните (Object) или обновите (Object) данный экземпляр. |
| 22 |
void update (Объектный объект) Обновите постоянный экземпляр с помощью идентификатора данного отдельного экземпляра. |
| 23 |
void update (String entityName, Object object) Обновите постоянный экземпляр с помощью идентификатора данного отдельного экземпляра. |
Транзакция beginTransaction ()
Начните единицу работы и верните связанный объект транзакции.
void cancelQuery ()
Отмените выполнение текущего запроса.
void clear ()
Полностью очистить сессию.
Соединение закрыто ()
Завершите сеанс, освободив соединение JDBC и очистив.
Критерии createCriteria (Класс persistentClass)
Создайте новый экземпляр Criteria для данного класса сущности или суперкласса класса сущности.
Критерии createCriteria (String entityName)
Создайте новый экземпляр Criteria для данного имени объекта.
Сериализуемый getIdentifier (Объектный объект)
Вернуть значение идентификатора данного объекта, связанного с этим сеансом.
Запрос createFilter (Коллекция объектов, String queryString)
Создайте новый экземпляр Query для данной коллекции и строку фильтра.
Запрос createQuery (String queryString)
Создайте новый экземпляр Query для заданной строки запроса HQL.
SQLQuery createSQLQuery (String queryString)
Создайте новый экземпляр SQLQuery для данной строки запроса SQL.
void delete (объектный объект)
Удалите постоянный экземпляр из хранилища данных.
void delete (String entityName, Object object)
Удалите постоянный экземпляр из хранилища данных.
Сеанс get (String entityName, Serializable id)
Вернуть постоянный экземпляр указанного именованного объекта с указанным идентификатором или значение NULL, если такого постоянного экземпляра нет.
SessionFactory getSessionFactory ()
Получить фабрику сеансов, которая создала этот сеанс.
void refresh (объектный объект)
Перечитайте состояние данного экземпляра из базовой базы данных.
Транзакция getTransaction ()
Получить экземпляр транзакции, связанный с этим сеансом.
логическое isConnected ()
Проверьте, подключен ли сеанс в данный момент.
логическое isDirty ()
Содержит ли этот сеанс какие-либо изменения, которые должны быть синхронизированы с базой данных?
логическое isOpen ()
Проверьте, открыт ли сеанс.
Сериализуемое сохранение (объектный объект)
Сохраните данный временный экземпляр, сначала назначив сгенерированный идентификатор.
void saveOrUpdate (Объектный объект)
Сохраните (Object) или обновите (Object) данный экземпляр.
void update (Объектный объект)
Обновите постоянный экземпляр с помощью идентификатора данного отдельного экземпляра.
void update (String entityName, Object object)
Обновите постоянный экземпляр с помощью идентификатора данного отдельного экземпляра.
Hibernate — Постоянный класс
Вся концепция Hibernate состоит в том, чтобы взять значения из атрибутов класса Java и сохранить их в таблице базы данных. Документ сопоставления помогает Hibernate определить, как извлечь значения из классов и сопоставить их с таблицей и связанными полями.
Классы Java, чьи объекты или экземпляры будут храниться в таблицах базы данных, называются постоянными классами в Hibernate. Hibernate работает лучше всего, если эти классы следуют некоторым простым правилам, также известным как модель программирования Plain Old Java Object (POJO).
Существуют следующие основные правила постоянных классов, однако ни одно из этих правил не является жестким.
-
Все классы Java, которые будут сохранены, нуждаются в конструкторе по умолчанию.
-
Все классы должны содержать идентификатор, чтобы можно было легко идентифицировать ваши объекты в Hibernate и базе данных. Это свойство отображается в столбец первичного ключа таблицы базы данных.
-
Все атрибуты, которые будут сохранены, должны быть объявлены закрытыми и иметь методы getXXX и setXXX, определенные в стиле JavaBean.
-
Центральная особенность прокси-серверов Hibernate зависит от того, является ли постоянный класс не финальным, или от реализации интерфейса, который объявляет все открытые методы.
-
Все классы, которые не расширяют или не реализуют некоторые специализированные классы и интерфейсы, требуемые EJB-инфраструктурой.
Все классы Java, которые будут сохранены, нуждаются в конструкторе по умолчанию.
Все классы должны содержать идентификатор, чтобы можно было легко идентифицировать ваши объекты в Hibernate и базе данных. Это свойство отображается в столбец первичного ключа таблицы базы данных.
Все атрибуты, которые будут сохранены, должны быть объявлены закрытыми и иметь методы getXXX и setXXX, определенные в стиле JavaBean.
Центральная особенность прокси-серверов Hibernate зависит от того, является ли постоянный класс не финальным, или от реализации интерфейса, который объявляет все открытые методы.
Все классы, которые не расширяют или не реализуют некоторые специализированные классы и интерфейсы, требуемые EJB-инфраструктурой.
Имя POJO используется, чтобы подчеркнуть, что данный объект является обычным Java-объектом, а не специальным объектом и, в частности, не Enterprise JavaBean.
Простой пример POJO
Основываясь на нескольких правилах, упомянутых выше, мы можем определить класс POJO следующим образом:
public class Employee {
private int id;
private String firstName;
private String lastName;
private int salary;
public Employee() {}
public Employee(String fname, String lname, int salary) {
this.firstName = fname;
this.lastName = lname;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}
Hibernate — Файлы сопоставления
Объектные / реляционные отображения обычно определяются в документе XML. Этот файл отображения инструктирует Hibernate — как отобразить определенный класс или классы в таблицы базы данных?
Хотя многие пользователи Hibernate предпочитают писать XML вручную, существует целый ряд инструментов для создания документа сопоставления. К ним относятся XDoclet, Middlegen и AndroMDA для продвинутых пользователей Hibernate.
Давайте рассмотрим наш ранее определенный класс POJO, чьи объекты будут сохраняться в таблице, определенной в следующем разделе.
public class Employee {
private int id;
private String firstName;
private String lastName;
private int salary;
public Employee() {}
public Employee(String fname, String lname, int salary) {
this.firstName = fname;
this.lastName = lname;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}
Там будет одна таблица, соответствующая каждому объекту, который вы готовы предоставить постоянство. Рассмотрим выше объекты должны быть сохранены и извлечены в следующую таблицу RDBMS —
create table EMPLOYEE ( id INT NOT NULL auto_increment, first_name VARCHAR(20) default NULL, last_name VARCHAR(20) default NULL, salary INT default NULL, PRIMARY KEY (id) );
Основываясь на двух вышеуказанных сущностях, мы можем определить следующий файл сопоставления, который инструктирует Hibernate, как сопоставить определенный класс или классы с таблицами базы данных.
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name = "Employee" table = "EMPLOYEE">
<meta attribute = "class-description">
This class contains the employee detail.
</meta>
<id name = "id" type = "int" column = "id">
<generator class="native"/>
</id>
<property name = "firstName" column = "first_name" type = "string"/>
<property name = "lastName" column = "last_name" type = "string"/>
<property name = "salary" column = "salary" type = "int"/>
</class>
</hibernate-mapping>
Вы должны сохранить документ сопоставления в файле в формате <classname> .hbm.xml. Мы сохранили наш документ сопоставления в файле Employee.hbm.xml.
Давайте разберемся в деталях об элементах отображения, используемых в файле отображения —
-
Документ сопоставления представляет собой XML-документ, имеющий в качестве корневого элемента <hibernate-mapping> , который содержит все элементы <class> .
-
Элементы <class> используются для определения конкретных отображений из классов Java в таблицы базы данных. Имя класса Java указывается с помощью атрибута name элемента class, а имя таблицы базы данных указывается с помощью атрибута table.
-
Элемент <meta> является необязательным и может использоваться для создания описания класса.
-
Элемент <id> сопоставляет атрибут уникального идентификатора в классе с первичным ключом таблицы базы данных. Атрибут name элемента id ссылается на свойство в классе, а атрибут column ссылается на столбец в таблице базы данных. Атрибут type содержит тип отображения hibernate, при этом типы отображения преобразуются из Java в тип данных SQL.
-
Элемент <generator> в элементе id используется для автоматической генерации значений первичного ключа. Атрибут class элемента генератора установлен на native, чтобы позволить hibernate подобрать алгоритм идентичности, последовательности или hilo для создания первичного ключа в зависимости от возможностей базовой базы данных.
-
Элемент <property> используется для сопоставления свойства класса Java со столбцом в таблице базы данных. Атрибут имени элемента ссылается на свойство в классе, а атрибут столбца ссылается на столбец в таблице базы данных. Атрибут type содержит тип отображения hibernate, при этом типы отображения преобразуются из Java в тип данных SQL.
Документ сопоставления представляет собой XML-документ, имеющий в качестве корневого элемента <hibernate-mapping> , который содержит все элементы <class> .
Элементы <class> используются для определения конкретных отображений из классов Java в таблицы базы данных. Имя класса Java указывается с помощью атрибута name элемента class, а имя таблицы базы данных указывается с помощью атрибута table.
Элемент <meta> является необязательным и может использоваться для создания описания класса.
Элемент <id> сопоставляет атрибут уникального идентификатора в классе с первичным ключом таблицы базы данных. Атрибут name элемента id ссылается на свойство в классе, а атрибут column ссылается на столбец в таблице базы данных. Атрибут type содержит тип отображения hibernate, при этом типы отображения преобразуются из Java в тип данных SQL.
Элемент <generator> в элементе id используется для автоматической генерации значений первичного ключа. Атрибут class элемента генератора установлен на native, чтобы позволить hibernate подобрать алгоритм идентичности, последовательности или hilo для создания первичного ключа в зависимости от возможностей базовой базы данных.
Элемент <property> используется для сопоставления свойства класса Java со столбцом в таблице базы данных. Атрибут имени элемента ссылается на свойство в классе, а атрибут столбца ссылается на столбец в таблице базы данных. Атрибут type содержит тип отображения hibernate, при этом типы отображения преобразуются из Java в тип данных SQL.
Доступны другие атрибуты и элементы, которые будут использоваться в документе сопоставления, и я постараюсь охватить как можно больше при обсуждении других тем, связанных с Hibernate.
Спящий режим — Типы картографирования
Когда вы готовите документ отображения Hibernate, вы обнаруживаете, что сопоставляете типы данных Java с типами данных RDBMS. Типы, объявленные и используемые в файлах сопоставления, не являются типами данных Java; они также не являются типами баз данных SQL. Эти типы называются типами отображения Hibernate , которые могут переводиться из типов данных Java в SQL и наоборот.
В этой главе перечислены все основные, дата и время, крупный объект и различные другие типы встроенных отображений.
Примитивные типы
| Тип отображения | Тип Java | Тип ANSI SQL |
|---|---|---|
| целое число | int или java.lang.Integer | INTEGER |
| долго | длинный или java.lang.Long | BIGINT |
| короткая | короткий или java.lang.Short | SMALLINT |
| поплавок | плавать или java.lang.Float | FLOAT |
| двойной | double или java.lang. Double | DOUBLE |
| big_decimal | java.math.BigDecimal | NUMERIC |
| персонаж | java.lang.String | СИМ (1) |
| строка | java.lang.String | VARCHAR |
| байт | байт или java.lang.Byte | TINYINT |
| логический | логическое или java.lang. булево | НЕМНОГО |
| да нет | логическое или java.lang. булево | CHAR (1) («Y» или «N») |
| истина / ложь | логическое или java.lang. булево | CHAR (1) («T» или «F») |
Типы даты и времени
| Тип отображения | Тип Java | Тип ANSI SQL |
|---|---|---|
| Дата | java.util.Date или java.sql.Date | ДАТА |
| время | java.util.Date или java.sql.Time | ВРЕМЯ |
| отметка времени | java.util.Date или java.sql.Timestamp | TIMESTAMP |
| календарь | java.util.Calendar | TIMESTAMP |
| calendar_date | java.util.Calendar | ДАТА |
Двоичные и крупные типы объектов
| Тип отображения | Тип Java | Тип ANSI SQL |
|---|---|---|
| двоичный | байт[] | VARBINARY (или BLOB) |
| текст | java.lang.String | CLOB |
| сериализуемым | любой класс Java, который реализует java.io.Serializable | VARBINARY (или BLOB) |
| CLOB | java.sql.Clob | CLOB |
| капля | java.sql.Blob | большой двоичный объект |
JDK-связанные типы
| Тип отображения | Тип Java | Тип ANSI SQL |
|---|---|---|
| учебный класс | java.lang.Class | VARCHAR |
| место действия | java.util.Locale | VARCHAR |
| часовой пояс | java.util.TimeZone | VARCHAR |
| валюта | java.util.Currency | VARCHAR |
Hibernate — Примеры
Давайте теперь возьмем пример, чтобы понять, как мы можем использовать Hibernate для обеспечения персистентности Java в автономном приложении. Мы пройдем различные этапы создания приложения Java с использованием технологии Hibernate.
Создать классы POJO
Первым шагом в создании приложения является создание класса или классов Java POJO в зависимости от приложения, которое будет сохранено в базе данных. Давайте рассмотрим наш класс Employee с методами getXXX и setXXX, чтобы сделать его совместимым с JavaBeans классом.
POJO (обычный старый Java-объект) — это Java-объект, который не расширяет и не реализует некоторые специализированные классы и интерфейсы, требуемые инфраструктурой EJB соответственно. Все обычные объекты Java являются POJO.
Когда вы разрабатываете класс для сохранения в Hibernate, важно предоставить совместимый с JavaBeans код, а также один атрибут, который будет работать как индексный атрибут id в классе Employee.
public class Employee {
private int id;
private String firstName;
private String lastName;
private int salary;
public Employee() {}
public Employee(String fname, String lname, int salary) {
this.firstName = fname;
this.lastName = lname;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}
Создать таблицы базы данных
Вторым шагом будет создание таблиц в вашей базе данных. Там будет одна таблица, соответствующая каждому объекту, вы готовы предоставить постоянство. Рассмотрим выше объекты должны быть сохранены и извлечены в следующую таблицу RDBMS —
create table EMPLOYEE ( id INT NOT NULL auto_increment, first_name VARCHAR(20) default NULL, last_name VARCHAR(20) default NULL, salary INT default NULL, PRIMARY KEY (id) );
Создать файл конфигурации сопоставления
На этом этапе создается файл сопоставления, который инструктирует Hibernate, как сопоставить определенный класс или классы с таблицами базы данных.
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name = "Employee" table = "EMPLOYEE">
<meta attribute = "class-description">
This class contains the employee detail.
</meta>
<id name = "id" type = "int" column = "id">
<generator class="native"/>
</id>
<property name = "firstName" column = "first_name" type = "string"/>
<property name = "lastName" column = "last_name" type = "string"/>
<property name = "salary" column = "salary" type = "int"/>
</class>
</hibernate-mapping>
Вы должны сохранить документ сопоставления в файле в формате <classname> .hbm.xml. Мы сохранили наш документ сопоставления в файле Employee.hbm.xml. Давайте посмотрим немного подробнее о картографическом документе —
-
Документ сопоставления — это документ XML, имеющий в качестве корневого элемента <hibernate-mapping>, который содержит все элементы <class>.
-
Элементы <class> используются для определения конкретных отображений из классов Java в таблицы базы данных. Имя класса Java указывается с помощью атрибута name элемента class, а имя таблицы базы данных указывается с помощью атрибута table .
-
Элемент <meta> является необязательным и может использоваться для создания описания класса.
-
Элемент <id> сопоставляет атрибут уникального идентификатора в классе с первичным ключом таблицы базы данных. Атрибут name элемента id ссылается на свойство в классе, а атрибут column ссылается на столбец в таблице базы данных. Атрибут type содержит тип отображения hibernate, при этом типы отображения преобразуются из Java в тип данных SQL.
-
Элемент <generator> в элементе id используется для автоматической генерации значений первичного ключа. Атрибут class элемента генератора установлен на native, чтобы позволить hibernate подобрать алгоритм идентификации, последовательности или hilo для создания первичного ключа в зависимости от возможностей базовой базы данных.
-
Элемент <property> используется для сопоставления свойства класса Java со столбцом в таблице базы данных. Атрибут имени элемента ссылается на свойство в классе, а атрибут столбца ссылается на столбец в таблице базы данных. Атрибут type содержит тип отображения hibernate, при этом типы отображения преобразуются из Java в тип данных SQL.
Документ сопоставления — это документ XML, имеющий в качестве корневого элемента <hibernate-mapping>, который содержит все элементы <class>.
Элементы <class> используются для определения конкретных отображений из классов Java в таблицы базы данных. Имя класса Java указывается с помощью атрибута name элемента class, а имя таблицы базы данных указывается с помощью атрибута table .
Элемент <meta> является необязательным и может использоваться для создания описания класса.
Элемент <id> сопоставляет атрибут уникального идентификатора в классе с первичным ключом таблицы базы данных. Атрибут name элемента id ссылается на свойство в классе, а атрибут column ссылается на столбец в таблице базы данных. Атрибут type содержит тип отображения hibernate, при этом типы отображения преобразуются из Java в тип данных SQL.
Элемент <generator> в элементе id используется для автоматической генерации значений первичного ключа. Атрибут class элемента генератора установлен на native, чтобы позволить hibernate подобрать алгоритм идентификации, последовательности или hilo для создания первичного ключа в зависимости от возможностей базовой базы данных.
Элемент <property> используется для сопоставления свойства класса Java со столбцом в таблице базы данных. Атрибут имени элемента ссылается на свойство в классе, а атрибут столбца ссылается на столбец в таблице базы данных. Атрибут type содержит тип отображения hibernate, при этом типы отображения преобразуются из Java в тип данных SQL.
Доступны другие атрибуты и элементы, которые будут использоваться в документе сопоставления, и я постараюсь охватить как можно больше при обсуждении других тем, связанных с Hibernate.
Создать класс приложения
Наконец, мы создадим наш класс приложения с методом main () для запуска приложения. Мы будем использовать это приложение для сохранения нескольких записей сотрудника, а затем будем применять операции CRUD к этим записям.
import java.util.List;
import java.util.Date;
import java.util.Iterator;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.Transaction;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class ManageEmployee {
private static SessionFactory factory;
public static void main(String[] args) {
try {
factory = new Configuration().configure().buildSessionFactory();
} catch (Throwable ex) {
System.err.println("Failed to create sessionFactory object." + ex);
throw new ExceptionInInitializerError(ex);
}
ManageEmployee ME = new ManageEmployee();
/* Add few employee records in database */
Integer empID1 = ME.addEmployee("Zara", "Ali", 1000);
Integer empID2 = ME.addEmployee("Daisy", "Das", 5000);
Integer empID3 = ME.addEmployee("John", "Paul", 10000);
/* List down all the employees */
ME.listEmployees();
/* Update employee's records */
ME.updateEmployee(empID1, 5000);
/* Delete an employee from the database */
ME.deleteEmployee(empID2);
/* List down new list of the employees */
ME.listEmployees();
}
/* Method to CREATE an employee in the database */
public Integer addEmployee(String fname, String lname, int salary){
Session session = factory.openSession();
Transaction tx = null;
Integer employeeID = null;
try {
tx = session.beginTransaction();
Employee employee = new Employee(fname, lname, salary);
employeeID = (Integer) session.save(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
return employeeID;
}
/* Method to READ all the employees */
public void listEmployees( ){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
List employees = session.createQuery("FROM Employee").list();
for (Iterator iterator = employees.iterator(); iterator.hasNext();){
Employee employee = (Employee) iterator.next();
System.out.print("First Name: " + employee.getFirstName());
System.out.print(" Last Name: " + employee.getLastName());
System.out.println(" Salary: " + employee.getSalary());
}
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to UPDATE salary for an employee */
public void updateEmployee(Integer EmployeeID, int salary ){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
Employee employee = (Employee)session.get(Employee.class, EmployeeID);
employee.setSalary( salary );
session.update(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to DELETE an employee from the records */
public void deleteEmployee(Integer EmployeeID){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
Employee employee = (Employee)session.get(Employee.class, EmployeeID);
session.delete(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
}
Компиляция и выполнение
Вот шаги для компиляции и запуска вышеупомянутого приложения. Убедитесь, что вы правильно установили PATH и CLASSPATH, прежде чем приступить к компиляции и выполнению.
-
Создайте файл конфигурации hibernate.cfg.xml, как описано в главе о конфигурации.
-
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
-
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
-
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
-
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Создайте файл конфигурации hibernate.cfg.xml, как описано в главе о конфигурации.
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Вы получите следующий результат, и записи будут созданы в таблице EMPLOYEE.
$java ManageEmployee .......VARIOUS LOG MESSAGES WILL DISPLAY HERE........ First Name: Zara Last Name: Ali Salary: 1000 First Name: Daisy Last Name: Das Salary: 5000 First Name: John Last Name: Paul Salary: 10000 First Name: Zara Last Name: Ali Salary: 5000 First Name: John Last Name: Paul Salary: 10000
Если вы проверите свою таблицу EMPLOYEE, она должна иметь следующие записи:
mysql> select * from EMPLOYEE; +----+------------+-----------+--------+ | id | first_name | last_name | salary | +----+------------+-----------+--------+ | 29 | Zara | Ali | 5000 | | 31 | John | Paul | 10000 | +----+------------+-----------+--------+ 2 rows in set (0.00 sec mysql>
Hibernate — O / R Mappings
До сих пор мы видели очень простое отображение O / R, используя hibernate, но есть три наиболее важных темы отображения, которые мы должны изучить подробно.
Это —
- Составление карт коллекций,
- Отображение связей между классами сущностей и
- Сопоставления компонентов.
Коллекции сопоставлений
Если у сущности или класса есть коллекция значений для определенной переменной, то мы можем отобразить эти значения, используя любой из интерфейсов коллекции, доступных в Java. Hibernate может сохранять экземпляры java.util.Map, java.util.Set, java.util.SortedMap, java.util.SortedSet, java.util.List и любой массив постоянных сущностей или значений.
| Sr.No. | Тип коллекции и описание карт |
|---|---|
| 1 | java.util.Set
Это сопоставляется с элементом <set> и инициализируется с помощью java.util.HashSet. |
| 2 | java.util.SortedSet
Это отображается с помощью элемента <set> и инициализируется с помощью java.util.TreeSet. Атрибут sort может быть установлен как в компараторе, так и в естественном порядке. |
| 3 | java.util.List
Это сопоставляется с элементом <list> и инициализируется с помощью java.util.ArrayList |
| 4 | java.util.Collection
Это отображается с помощью элемента <bag> или <ibag> и инициализируется с помощью java.util.ArrayList |
| 5 | java.util.Map
Это сопоставляется с элементом <map> и инициализируется с помощью java.util.HashMap. |
| 6 | java.util.SortedMap
Это отображается с помощью элемента <map> и инициализируется с помощью java.util.TreeMap. Атрибут sort может быть установлен как в компараторе, так и в естественном порядке. |
Это сопоставляется с элементом <set> и инициализируется с помощью java.util.HashSet.
Это отображается с помощью элемента <set> и инициализируется с помощью java.util.TreeSet. Атрибут sort может быть установлен как в компараторе, так и в естественном порядке.
Это сопоставляется с элементом <list> и инициализируется с помощью java.util.ArrayList
Это отображается с помощью элемента <bag> или <ibag> и инициализируется с помощью java.util.ArrayList
Это сопоставляется с элементом <map> и инициализируется с помощью java.util.HashMap.
Это отображается с помощью элемента <map> и инициализируется с помощью java.util.TreeMap. Атрибут sort может быть установлен как в компараторе, так и в естественном порядке.
Hibernate поддерживает массивы с <primitive-array> для типов примитивных значений Java и <array> для всего остального. Однако они используются редко, поэтому я не буду обсуждать их в этом уроке.
Если вы хотите отобразить пользовательские интерфейсы коллекций, которые напрямую не поддерживаются Hibernate, вам нужно сообщить Hibernate о семантике ваших пользовательских коллекций, что не очень просто и не рекомендуется использовать.
Ассоциация сопоставлений
Отображение ассоциаций между классами сущностей и взаимосвязями между таблицами — это душа ORM. Ниже приведены четыре способа, которыми можно выразить кардинальность отношений между объектами. Отображение ассоциации может быть как однонаправленным, так и двунаправленным.
| Sr.No. | Тип отображения и описание |
|---|---|
| 1 | Многие-к-одному
Отображение отношений «многие к одному» с использованием Hibernate |
| 2 | Один к одному
Отображение отношений один-к-одному с помощью Hibernate |
| 3 | Один ко многим
Отображение отношения один ко многим с помощью Hibernate |
| 4 | Многие-ко-многим
Отображение отношений «многие ко многим» с использованием Hibernate |
Отображение отношений «многие к одному» с использованием Hibernate
Отображение отношений один-к-одному с помощью Hibernate
Отображение отношения один ко многим с помощью Hibernate
Отображение отношений «многие ко многим» с использованием Hibernate
Сопоставления компонентов
Очень возможно, что класс Entity может иметь ссылку на другой класс в качестве переменной-члена. Если указанный класс не имеет своего собственного жизненного цикла и полностью зависит от жизненного цикла класса сущности-владельца, следовательно, указанный класс, следовательно, называется классом Компонента .
Сопоставление коллекций компонентов также возможно аналогично сопоставлению обычных коллекций с небольшими различиями в конфигурации. Мы увидим эти два отображения подробно с примерами.
| Sr.No. | Тип отображения и описание |
|---|---|
| 1 | Сопоставления компонентов
Отображение для класса, имеющего ссылку на другой класс в качестве переменной-члена. |
Отображение для класса, имеющего ссылку на другой класс в качестве переменной-члена.
Спящий режим — Аннотации
До сих пор вы видели, как Hibernate использует файл сопоставления XML для преобразования данных из POJO в таблицы базы данных и наоборот. Hibernate аннотации являются новейшим способом определения сопоставлений без использования файла XML. Вы можете использовать аннотации в дополнение или в качестве замены метаданных отображения XML.
Аннотации в спящем режиме — это мощный способ предоставления метаданных для отображения объектов и реляционных таблиц. Все метаданные объединяются в Java-файл POJO вместе с кодом, это помогает пользователю одновременно понимать структуру таблицы и POJO во время разработки.
Если вы собираетесь сделать свое приложение переносимым на другие совместимые с EJB 3 приложения ORM, вы должны использовать аннотации для представления информации о сопоставлении, но, тем не менее, если вы хотите большей гибкости, вам следует использовать сопоставления на основе XML.
Настройка среды для спящего аннотации
Прежде всего вам необходимо убедиться, что вы используете JDK 5.0, в противном случае вам нужно обновить JDK до JDK 5.0, чтобы воспользоваться встроенной поддержкой аннотаций.
Во-вторых, вам нужно установить дистрибутив аннотаций Hibernate 3.x, доступный из sourceforge: ( Скачать аннотацию Hibernate ), и скопировать hibernate-annotations.jar, lib / hibernate-comons-annotations.jar и lib / ejb3-persistence. jar из дистрибутива Hibernate Annotations для вашего CLASSPATH.
Пример аннотированного класса
Как я упоминал выше при работе с Hibernate Annotation, все метаданные объединяются в Java-файл POJO вместе с кодом, это помогает пользователю одновременно понимать структуру таблицы и POJO во время разработки.
Предположим, мы собираемся использовать следующую таблицу EMPLOYEE для хранения наших объектов:
create table EMPLOYEE ( id INT NOT NULL auto_increment, first_name VARCHAR(20) default NULL, last_name VARCHAR(20) default NULL, salary INT default NULL, PRIMARY KEY (id) );
Ниже приведено сопоставление класса Employee с аннотациями для сопоставления объектов с определенной таблицей EMPLOYEE.
import javax.persistence.*;
@Entity
@Table(name = "EMPLOYEE")
public class Employee {
@Id @GeneratedValue
@Column(name = "id")
private int id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@Column(name = "salary")
private int salary;
public Employee() {}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}
Hibernate обнаруживает, что аннотация @Id находится в поле, и предполагает, что он должен обращаться к свойствам объекта напрямую через поля во время выполнения. Если вы поместите аннотацию @Id в метод getId (), вы по умолчанию разрешите доступ к свойствам через методы getter и setter. Следовательно, все остальные аннотации также размещаются в полях или методах получения в соответствии с выбранной стратегией.
Следующий раздел объяснит аннотации, используемые в вышеприведенном классе.
@Entity Annotation
Стандартные аннотации EJB 3 содержатся в пакете javax.persistence , поэтому мы импортируем этот пакет в качестве первого шага. Во-вторых, мы использовали аннотацию @Entity для класса Employee, который помечает этот класс как объектный компонент, поэтому он должен иметь конструктор без аргументов, видимый как минимум с защищенной областью действия.
@Table Annotation
Аннотация @Table позволяет вам указать детали таблицы, которая будет использоваться для сохранения сущности в базе данных.
Аннотация @Table предоставляет четыре атрибута, позволяющих переопределить имя таблицы, ее каталог и ее схему, а также применить уникальные ограничения для столбцов в таблице. На данный момент мы используем только имя таблицы, которая является EMPLOYEE.
Аннотации @Id и @GeneratedValue
Каждый объектный компонент будет иметь первичный ключ, который вы аннотируете в классе с помощью аннотации @Id . Первичный ключ может быть одним полем или комбинацией нескольких полей в зависимости от структуры таблицы.
По умолчанию аннотация @Id автоматически определяет наиболее подходящую стратегию генерации первичного ключа, но вы можете переопределить ее, применив аннотацию @GeneratedValue , которая использует стратегию с двумя параметрами и генератор, которые я не буду обсуждать здесь, поэтому давайте использовать только стратегию генерации ключей по умолчанию. Разрешение Hibernate определять, какой тип генератора использовать, делает ваш код переносимым между различными базами данных.
@ Колонка Аннотация
Аннотация @Column используется для указания сведений о столбце, в который будет отображаться поле или свойство. Вы можете использовать аннотацию столбца со следующими наиболее часто используемыми атрибутами:
-
Атрибут name позволяет явно указать имя столбца.
-
Атрибут length разрешает размер столбца, используемого для сопоставления значения, особенно для значения String.
-
Атрибут nullable позволяет пометить столбец NOT NULL при создании схемы.
-
Атрибут unique позволяет пометить столбец как содержащий только уникальные значения.
Атрибут name позволяет явно указать имя столбца.
Атрибут length разрешает размер столбца, используемого для сопоставления значения, особенно для значения String.
Атрибут nullable позволяет пометить столбец NOT NULL при создании схемы.
Атрибут unique позволяет пометить столбец как содержащий только уникальные значения.
Создать класс приложения
Наконец, мы создадим наш класс приложения с методом main () для запуска приложения. Мы будем использовать это приложение для сохранения нескольких записей сотрудника, а затем будем применять операции CRUD к этим записям.
import java.util.List;
import java.util.Date;
import java.util.Iterator;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.Transaction;
import org.hibernate.cfg.AnnotationConfiguration;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class ManageEmployee {
private static SessionFactory factory;
public static void main(String[] args) {
try {
factory = new AnnotationConfiguration().
configure().
//addPackage("com.xyz") //add package if used.
addAnnotatedClass(Employee.class).
buildSessionFactory();
} catch (Throwable ex) {
System.err.println("Failed to create sessionFactory object." + ex);
throw new ExceptionInInitializerError(ex);
}
ManageEmployee ME = new ManageEmployee();
/* Add few employee records in database */
Integer empID1 = ME.addEmployee("Zara", "Ali", 1000);
Integer empID2 = ME.addEmployee("Daisy", "Das", 5000);
Integer empID3 = ME.addEmployee("John", "Paul", 10000);
/* List down all the employees */
ME.listEmployees();
/* Update employee's records */
ME.updateEmployee(empID1, 5000);
/* Delete an employee from the database */
ME.deleteEmployee(empID2);
/* List down new list of the employees */
ME.listEmployees();
}
/* Method to CREATE an employee in the database */
public Integer addEmployee(String fname, String lname, int salary){
Session session = factory.openSession();
Transaction tx = null;
Integer employeeID = null;
try {
tx = session.beginTransaction();
Employee employee = new Employee();
employee.setFirstName(fname);
employee.setLastName(lname);
employee.setSalary(salary);
employeeID = (Integer) session.save(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
return employeeID;
}
/* Method to READ all the employees */
public void listEmployees( ){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
List employees = session.createQuery("FROM Employee").list();
for (Iterator iterator = employees.iterator(); iterator.hasNext();){
Employee employee = (Employee) iterator.next();
System.out.print("First Name: " + employee.getFirstName());
System.out.print(" Last Name: " + employee.getLastName());
System.out.println(" Salary: " + employee.getSalary());
}
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to UPDATE salary for an employee */
public void updateEmployee(Integer EmployeeID, int salary ){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
Employee employee = (Employee)session.get(Employee.class, EmployeeID);
employee.setSalary( salary );
session.update(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to DELETE an employee from the records */
public void deleteEmployee(Integer EmployeeID){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
Employee employee = (Employee)session.get(Employee.class, EmployeeID);
session.delete(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
}
Конфигурация базы данных
Теперь давайте создадим файл конфигурации hibernate.cfg.xml для определения параметров, связанных с базой данных.
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-configuration SYSTEM
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name = "hibernate.dialect">
org.hibernate.dialect.MySQLDialect
</property>
<property name = "hibernate.connection.driver_class">
com.mysql.jdbc.Driver
</property>
<!-- Assume students is the database name -->
<property name = "hibernate.connection.url">
jdbc:mysql://localhost/test
</property>
<property name = "hibernate.connection.username">
root
</property>
<property name = "hibernate.connection.password">
cohondob
</property>
</session-factory>
</hibernate-configuration>
Компиляция и выполнение
Вот шаги для компиляции и запуска вышеупомянутого приложения. Убедитесь, что вы правильно установили PATH и CLASSPATH, прежде чем приступить к компиляции и выполнению.
-
Удалите файл сопоставления Employee.hbm.xml из пути.
-
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
-
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
-
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Удалите файл сопоставления Employee.hbm.xml из пути.
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Вы получите следующий результат, и записи будут созданы в таблице EMPLOYEE.
$java ManageEmployee .......VARIOUS LOG MESSAGES WILL DISPLAY HERE........ First Name: Zara Last Name: Ali Salary: 1000 First Name: Daisy Last Name: Das Salary: 5000 First Name: John Last Name: Paul Salary: 10000 First Name: Zara Last Name: Ali Salary: 5000 First Name: John Last Name: Paul Salary: 10000
Если вы проверите свою таблицу EMPLOYEE, она должна иметь следующие записи:
mysql> select * from EMPLOYEE; +----+------------+-----------+--------+ | id | first_name | last_name | salary | +----+------------+-----------+--------+ | 29 | Zara | Ali | 5000 | | 31 | John | Paul | 10000 | +----+------------+-----------+--------+ 2 rows in set (0.00 sec mysql>
Hibernate — Язык запросов
Hibernate Query Language (HQL) — это объектно-ориентированный язык запросов, похожий на SQL, но вместо работы с таблицами и столбцами HQL работает с постоянными объектами и их свойствами. HQL-запросы преобразуются Hibernate в обычные SQL-запросы, которые, в свою очередь, выполняют действия с базой данных.
Хотя вы можете использовать операторы SQL непосредственно с Hibernate, используя Native SQL, но я бы порекомендовал использовать HQL, когда это возможно, чтобы избежать проблем с переносимостью баз данных и воспользоваться преимуществами стратегий генерации и кэширования SQL в Hibernate.
Ключевые слова, такие как SELECT, FROM, WHERE и т. Д., Не чувствительны к регистру, но такие свойства, как имена таблиц и столбцов, чувствительны к регистру в HQL.
ОТ клаузулы
Вы будете использовать предложение FROM , если хотите загрузить полностью постоянные объекты в память. Ниже приведен простой синтаксис использования предложения FROM —
String hql = "FROM Employee"; Query query = session.createQuery(hql); List results = query.list();
Если вам нужно полностью указать имя класса в HQL, просто укажите пакет и имя класса следующим образом:
String hql = "FROM com.hibernatebook.criteria.Employee"; Query query = session.createQuery(hql); List results = query.list();
AS пункт
Предложение AS можно использовать для назначения псевдонимов классам в ваших HQL-запросах, особенно если у вас длинные запросы. Например, наш предыдущий простой пример будет следующим:
String hql = "FROM Employee AS E"; Query query = session.createQuery(hql); List results = query.list();
Ключевое слово AS является необязательным, и вы также можете указать псевдоним непосредственно после имени класса, как показано ниже:
String hql = "FROM Employee E"; Query query = session.createQuery(hql); List results = query.list();
ВЫБРАТЬ пункт
Предложение SELECT обеспечивает больший контроль над результирующим набором, чем предложение from. Если вы хотите получить несколько свойств объектов вместо всего объекта, используйте предложение SELECT. Ниже приведен простой синтаксис использования предложения SELECT для получения только поля first_name объекта Employee.
String hql = "SELECT E.firstName FROM Employee E"; Query query = session.createQuery(hql); List results = query.list();
Следует отметить, что Employee.firstName является свойством объекта Employee, а не полем таблицы EMPLOYEE.
ГДЕ оговорка
Если вы хотите сузить конкретные объекты, которые возвращаются из хранилища, используйте предложение WHERE. Ниже приведен простой синтаксис использования предложения WHERE:
String hql = "FROM Employee E WHERE E.id = 10"; Query query = session.createQuery(hql); List results = query.list();
ЗАКАЗАТЬ по пункту
Чтобы отсортировать результаты вашего HQL-запроса, вам нужно использовать предложение ORDER BY . Вы можете упорядочить результаты по любому свойству объектов в наборе результатов по возрастанию (ASC) или по убыванию (DESC). Ниже приведен простой синтаксис использования предложения ORDER BY:
String hql = "FROM Employee E WHERE E.id > 10 ORDER BY E.salary DESC"; Query query = session.createQuery(hql); List results = query.list();
Если вы хотите отсортировать по более чем одному свойству, вы просто добавите дополнительные свойства в конец предложения по предложению, разделенные запятыми следующим образом:
String hql = "FROM Employee E WHERE E.id > 10 " +
"ORDER BY E.firstName DESC, E.salary DESC ";
Query query = session.createQuery(hql);
List results = query.list();
Предложение GROUP BY
Этот пункт позволяет Hibernate извлекать информацию из базы данных и группировать ее по значению атрибута и, как правило, использовать результат для включения совокупного значения. Ниже приведен простой синтаксис использования предложения GROUP BY —
String hql = "SELECT SUM(E.salary), E.firtName FROM Employee E " +
"GROUP BY E.firstName";
Query query = session.createQuery(hql);
List results = query.list();
Использование именованных параметров
Hibernate поддерживает именованные параметры в своих HQL-запросах. Это облегчает написание HQL-запросов, которые принимают ввод от пользователя, и вам не нужно защищаться от атак SQL-инъекций. Ниже приведен простой синтаксис использования именованных параметров —
String hql = "FROM Employee E WHERE E.id = :employee_id";
Query query = session.createQuery(hql);
query.setParameter("employee_id",10);
List results = query.list();
ОБНОВЛЕНИЕ
Массовые обновления являются новыми для HQL с Hibernate 3, и удаляют работу в Hibernate 3 иначе, чем в Hibernate 2. Интерфейс Query теперь содержит метод executeUpdate () для выполнения операторов HQL UPDATE или DELETE.
Предложение UPDATE может использоваться для обновления одного или нескольких свойств одного или нескольких объектов. Ниже приведен простой синтаксис использования предложения UPDATE —
String hql = "UPDATE Employee set salary = :salary " +
"WHERE id = :employee_id";
Query query = session.createQuery(hql);
query.setParameter("salary", 1000);
query.setParameter("employee_id", 10);
int result = query.executeUpdate();
System.out.println("Rows affected: " + result);
УДАЛИТЬ пункт
Предложение DELETE может использоваться для удаления одного или нескольких объектов. Ниже приведен простой синтаксис использования предложения DELETE:
String hql = "DELETE FROM Employee " +
"WHERE id = :employee_id";
Query query = session.createQuery(hql);
query.setParameter("employee_id", 10);
int result = query.executeUpdate();
System.out.println("Rows affected: " + result);
Вставить пункт
HQL поддерживает предложение INSERT INTO только тогда, когда записи могут быть вставлены из одного объекта в другой. Ниже приведен простой синтаксис использования предложения INSERT INTO:
String hql = "INSERT INTO Employee(firstName, lastName, salary)" +
"SELECT firstName, lastName, salary FROM old_employee";
Query query = session.createQuery(hql);
int result = query.executeUpdate();
System.out.println("Rows affected: " + result);
Агрегатные методы
HQL поддерживает ряд агрегатных методов, похожих на SQL. Они работают так же, как в HQL, так и в SQL, и ниже приведен список доступных функций:
| Sr.No. | Функции и описание |
|---|---|
| 1 |
avg (название объекта) Средняя стоимость имущества |
| 2 |
считать (имя свойства или *) Сколько раз свойство встречается в результатах |
| 3 |
max (имя свойства) Максимальное значение значения свойства |
| 4 |
мин (название объекта) Минимальное значение значения свойства |
| 5 |
сумма (название объекта) Общая сумма стоимости имущества |
avg (название объекта)
Средняя стоимость имущества
считать (имя свойства или *)
Сколько раз свойство встречается в результатах
max (имя свойства)
Максимальное значение значения свойства
мин (название объекта)
Минимальное значение значения свойства
сумма (название объекта)
Общая сумма стоимости имущества
Отдельное ключевое слово учитывает только уникальные значения в наборе строк. Следующий запрос вернет только уникальный счет —
String hql = "SELECT count(distinct E.firstName) FROM Employee E"; Query query = session.createQuery(hql); List results = query.list();
Нумерация страниц с использованием запроса
Существует два метода интерфейса Query для разбивки на страницы.
| Sr.No. | Метод и описание |
|---|---|
| 1 |
Запрос setFirstResult (int startPosition) Этот метод принимает целое число, представляющее первую строку в вашем наборе результатов, начиная со строки 0. |
| 2 |
Запрос setMaxResults (int maxResult) Этот метод сообщает Hibernate о получении фиксированного числа maxResults объектов. |
Запрос setFirstResult (int startPosition)
Этот метод принимает целое число, представляющее первую строку в вашем наборе результатов, начиная со строки 0.
Запрос setMaxResults (int maxResult)
Этот метод сообщает Hibernate о получении фиксированного числа maxResults объектов.
Используя два вышеупомянутых метода вместе, мы можем создать пейджинговый компонент в нашем веб-приложении или приложении Swing. Ниже приведен пример, который вы можете расширить, чтобы получить 10 строк за раз:
String hql = "FROM Employee"; Query query = session.createQuery(hql); query.setFirstResult(1); query.setMaxResults(10); List results = query.list();
Hibernate — Критерии Запросы
Hibernate предоставляет альтернативные способы управления объектами и, в свою очередь, данными, доступными в таблицах RDBMS. Одним из методов является Criteria API, который позволяет программно создавать объект запроса критериев, в котором можно применять правила фильтрации и логические условия.
Интерфейс Hibernate Session предоставляет метод createCriteria () , который можно использовать для создания объекта Criteria, который возвращает экземпляры класса объекта постоянства, когда ваше приложение выполняет запрос критерия.
Ниже приведен простейший пример критерия запроса, который просто возвращает каждый объект, соответствующий классу Employee.
Criteria cr = session.createCriteria(Employee.class); List results = cr.list();
Ограничения с критериями
Вы можете использовать метод add (), доступный для объекта Criteria, чтобы добавить ограничение для запроса критерия. Ниже приведен пример добавления ограничения для возврата записей с зарплатой, равной 2000 —
Criteria cr = session.createCriteria(Employee.class);
cr.add(Restrictions.eq("salary", 2000));
List results = cr.list();
Ниже приведены еще несколько примеров, охватывающих различные сценарии и могут использоваться в соответствии с требованием:
Criteria cr = session.createCriteria(Employee.class);
// To get records having salary more than 2000
cr.add(Restrictions.gt("salary", 2000));
// To get records having salary less than 2000
cr.add(Restrictions.lt("salary", 2000));
// To get records having fistName starting with zara
cr.add(Restrictions.like("firstName", "zara%"));
// Case sensitive form of the above restriction.
cr.add(Restrictions.ilike("firstName", "zara%"));
// To get records having salary in between 1000 and 2000
cr.add(Restrictions.between("salary", 1000, 2000));
// To check if the given property is null
cr.add(Restrictions.isNull("salary"));
// To check if the given property is not null
cr.add(Restrictions.isNotNull("salary"));
// To check if the given property is empty
cr.add(Restrictions.isEmpty("salary"));
// To check if the given property is not empty
cr.add(Restrictions.isNotEmpty("salary"));
Вы можете создать условия И или ИЛИ, используя ограничения LogicalExpression следующим образом:
Criteria cr = session.createCriteria(Employee.class);
Criterion salary = Restrictions.gt("salary", 2000);
Criterion name = Restrictions.ilike("firstNname","zara%");
// To get records matching with OR conditions
LogicalExpression orExp = Restrictions.or(salary, name);
cr.add( orExp );
// To get records matching with AND conditions
LogicalExpression andExp = Restrictions.and(salary, name);
cr.add( andExp );
List results = cr.list();
Хотя все вышеперечисленные условия могут быть использованы непосредственно с HQL, как описано в предыдущем уроке.
Нумерация страниц по критериям
Существует два метода интерфейса Criteria для разбивки на страницы.
| Sr.No. | Метод и описание |
|---|---|
| 1 |
общедоступные критерии setFirstResult (int firstResult) Этот метод принимает целое число, представляющее первую строку в вашем наборе результатов, начиная со строки 0. |
| 2 |
общедоступные критерии setMaxResults (int maxResults) Этот метод сообщает Hibernate о получении фиксированного числа maxResults объектов. |
общедоступные критерии setFirstResult (int firstResult)
Этот метод принимает целое число, представляющее первую строку в вашем наборе результатов, начиная со строки 0.
общедоступные критерии setMaxResults (int maxResults)
Этот метод сообщает Hibernate о получении фиксированного числа maxResults объектов.
Используя два вышеупомянутых метода вместе, мы можем создать пейджинговый компонент в нашем веб-приложении или приложении Swing. Ниже приведен пример, который вы можете расширить, чтобы получить 10 строк за раз:
Criteria cr = session.createCriteria(Employee.class); cr.setFirstResult(1); cr.setMaxResults(10); List results = cr.list();
Сортировка результатов
API Criteria предоставляет класс org.hibernate.criterion.Order для сортировки набора результатов в порядке возрастания или убывания в соответствии с одним из свойств вашего объекта. В этом примере показано, как использовать класс Order для сортировки набора результатов.
Criteria cr = session.createCriteria(Employee.class);
// To get records having salary more than 2000
cr.add(Restrictions.gt("salary", 2000));
// To sort records in descening order
cr.addOrder(Order.desc("salary"));
// To sort records in ascending order
cr.addOrder(Order.asc("salary"));
List results = cr.list();
Прогнозы и агрегаты
API Criteria предоставляет класс org.hibernate.criterion.Projection , который можно использовать для получения среднего, максимального или минимального значений свойств. Класс Projection аналогичен классу Restrictions в том, что он предоставляет несколько статических фабричных методов для получения экземпляров Projection .
Ниже приведены несколько примеров, охватывающих различные сценарии и могут использоваться в соответствии с требованиями:
Criteria cr = session.createCriteria(Employee.class);
// To get total row count.
cr.setProjection(Projections.rowCount());
// To get average of a property.
cr.setProjection(Projections.avg("salary"));
// To get distinct count of a property.
cr.setProjection(Projections.countDistinct("firstName"));
// To get maximum of a property.
cr.setProjection(Projections.max("salary"));
// To get minimum of a property.
cr.setProjection(Projections.min("salary"));
// To get sum of a property.
cr.setProjection(Projections.sum("salary"));
Пример критериев запросов
Рассмотрим следующий класс POJO —
public class Employee {
private int id;
private String firstName;
private String lastName;
private int salary;
public Employee() {}
public Employee(String fname, String lname, int salary) {
this.firstName = fname;
this.lastName = lname;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}
Давайте создадим следующую таблицу EMPLOYEE для хранения объектов Employee —
create table EMPLOYEE ( id INT NOT NULL auto_increment, first_name VARCHAR(20) default NULL, last_name VARCHAR(20) default NULL, salary INT default NULL, PRIMARY KEY (id) );
Ниже будет файл сопоставления.
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name = "Employee" table = "EMPLOYEE">
<meta attribute = "class-description">
This class contains the employee detail.
</meta>
<id name = "id" type = "int" column = "id">
<generator class="native"/>
</id>
<property name = "firstName" column = "first_name" type = "string"/>
<property name = "lastName" column = "last_name" type = "string"/>
<property name = "salary" column = "salary" type = "int"/>
</class>
</hibernate-mapping>
Наконец, мы создадим наш класс приложения с методом main () для запуска приложения, в котором мы будем использовать запросы Criteria.
import java.util.List;
import java.util.Date;
import java.util.Iterator;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.Transaction;
import org.hibernate.SessionFactory;
import org.hibernate.Criteria;
import org.hibernate.criterion.Restrictions;
import org.hibernate.criterion.Projections;
import org.hibernate.cfg.Configuration;
public class ManageEmployee {
private static SessionFactory factory;
public static void main(String[] args) {
try {
factory = new Configuration().configure().buildSessionFactory();
} catch (Throwable ex) {
System.err.println("Failed to create sessionFactory object." + ex);
throw new ExceptionInInitializerError(ex);
}
ManageEmployee ME = new ManageEmployee();
/* Add few employee records in database */
Integer empID1 = ME.addEmployee("Zara", "Ali", 2000);
Integer empID2 = ME.addEmployee("Daisy", "Das", 5000);
Integer empID3 = ME.addEmployee("John", "Paul", 5000);
Integer empID4 = ME.addEmployee("Mohd", "Yasee", 3000);
/* List down all the employees */
ME.listEmployees();
/* Print Total employee's count */
ME.countEmployee();
/* Print Total salary */
ME.totalSalary();
}
/* Method to CREATE an employee in the database */
public Integer addEmployee(String fname, String lname, int salary){
Session session = factory.openSession();
Transaction tx = null;
Integer employeeID = null;
try {
tx = session.beginTransaction();
Employee employee = new Employee(fname, lname, salary);
employeeID = (Integer) session.save(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
return employeeID;
}
/* Method to READ all the employees having salary more than 2000 */
public void listEmployees( ) {
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
Criteria cr = session.createCriteria(Employee.class);
// Add restriction.
cr.add(Restrictions.gt("salary", 2000));
List employees = cr.list();
for (Iterator iterator = employees.iterator(); iterator.hasNext();){
Employee employee = (Employee) iterator.next();
System.out.print("First Name: " + employee.getFirstName());
System.out.print(" Last Name: " + employee.getLastName());
System.out.println(" Salary: " + employee.getSalary());
}
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to print total number of records */
public void countEmployee(){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
Criteria cr = session.createCriteria(Employee.class);
// To get total row count.
cr.setProjection(Projections.rowCount());
List rowCount = cr.list();
System.out.println("Total Coint: " + rowCount.get(0) );
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to print sum of salaries */
public void totalSalary(){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
Criteria cr = session.createCriteria(Employee.class);
// To get total salary.
cr.setProjection(Projections.sum("salary"));
List totalSalary = cr.list();
System.out.println("Total Salary: " + totalSalary.get(0) );
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
}
Компиляция и выполнение
Вот шаги для компиляции и запуска вышеупомянутого приложения. Убедитесь, что вы правильно установили PATH и CLASSPATH, прежде чем приступить к компиляции и выполнению.
-
Создайте файл конфигурации hibernate.cfg.xml, как описано в главе о конфигурации.
-
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
-
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
-
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
-
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Создайте файл конфигурации hibernate.cfg.xml, как описано в главе о конфигурации.
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Вы получите следующий результат, и записи будут созданы в таблице EMPLOYEE.
$java ManageEmployee .......VARIOUS LOG MESSAGES WILL DISPLAY HERE........ First Name: Daisy Last Name: Das Salary: 5000 First Name: John Last Name: Paul Salary: 5000 First Name: Mohd Last Name: Yasee Salary: 3000 Total Coint: 4 Total Salary: 15000
Если вы проверите свою таблицу EMPLOYEE, она должна иметь следующие записи:
mysql> select * from EMPLOYEE; +----+------------+-----------+--------+ | id | first_name | last_name | salary | +----+------------+-----------+--------+ | 14 | Zara | Ali | 2000 | | 15 | Daisy | Das | 5000 | | 16 | John | Paul | 5000 | | 17 | Mohd | Yasee | 3000 | +----+------------+-----------+--------+ 4 rows in set (0.00 sec) mysql>
Hibernate — собственный SQL
Вы можете использовать собственный SQL для выражения запросов к базе данных, если хотите использовать специфичные для базы данных функции, такие как подсказки запросов или ключевое слово CONNECT в Oracle. Hibernate 3.x позволяет указывать рукописный SQL, включая хранимые процедуры, для всех операций создания, обновления, удаления и загрузки.
Ваше приложение создаст собственный запрос SQL из сеанса с помощью метода createSQLQuery () в интерфейсе сеанса —
public SQLQuery createSQLQuery(String sqlString) throws HibernateException
После передачи строки, содержащей запрос SQL, в метод createSQLQuery () можно связать результат SQL с существующей сущностью Hibernate, объединением или скалярным результатом, используя методы addEntity (), addJoin () и addScalar (). соответственно.
Скалярные Запросы
Самый простой запрос SQL — это получить список скаляров (значений) из одной или нескольких таблиц. Ниже приведен синтаксис использования собственного SQL для скалярных значений:
String sql = "SELECT first_name, salary FROM EMPLOYEE"; SQLQuery query = session.createSQLQuery(sql); query.setResultTransformer(Criteria.ALIAS_TO_ENTITY_MAP); List results = query.list();
Entity Queries
Все вышеперечисленные запросы касались возврата скалярных значений, в основном возвращая «сырые» значения из набора результатов. Ниже приведен синтаксис для получения объектов сущности в целом из собственного SQL-запроса с помощью addEntity ().
String sql = "SELECT * FROM EMPLOYEE"; SQLQuery query = session.createSQLQuery(sql); query.addEntity(Employee.class); List results = query.list();
Именованные SQL-запросы
Ниже приведен синтаксис для получения объектов сущности из собственного SQL-запроса с помощью addEntity () и использования именованного SQL-запроса.
String sql = "SELECT * FROM EMPLOYEE WHERE id = :employee_id";
SQLQuery query = session.createSQLQuery(sql);
query.addEntity(Employee.class);
query.setParameter("employee_id", 10);
List results = query.list();
Пример собственного SQL
Рассмотрим следующий класс POJO —
public class Employee {
private int id;
private String firstName;
private String lastName;
private int salary;
public Employee() {}
public Employee(String fname, String lname, int salary) {
this.firstName = fname;
this.lastName = lname;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}
Давайте создадим следующую таблицу EMPLOYEE для хранения объектов Employee —
create table EMPLOYEE ( id INT NOT NULL auto_increment, first_name VARCHAR(20) default NULL, last_name VARCHAR(20) default NULL, salary INT default NULL, PRIMARY KEY (id) );
Ниже будет файл сопоставления —
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name = "Employee" table = "EMPLOYEE">
<meta attribute = "class-description">
This class contains the employee detail.
</meta>
<id name = "id" type = "int" column = "id">
<generator class="native"/>
</id>
<property name = "firstName" column = "first_name" type = "string"/>
<property name = "lastName" column = "last_name" type = "string"/>
<property name = "salary" column = "salary" type = "int"/>
</class>
</hibernate-mapping>
Наконец, мы создадим наш класс приложения с методом main () для запуска приложения, в котором мы будем использовать собственные запросы SQL —
import java.util.*;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.Transaction;
import org.hibernate.SessionFactory;
import org.hibernate.SQLQuery;
import org.hibernate.Criteria;
import org.hibernate.Hibernate;
import org.hibernate.cfg.Configuration;
public class ManageEmployee {
private static SessionFactory factory;
public static void main(String[] args) {
try {
factory = new Configuration().configure().buildSessionFactory();
} catch (Throwable ex) {
System.err.println("Failed to create sessionFactory object." + ex);
throw new ExceptionInInitializerError(ex);
}
ManageEmployee ME = new ManageEmployee();
/* Add few employee records in database */
Integer empID1 = ME.addEmployee("Zara", "Ali", 2000);
Integer empID2 = ME.addEmployee("Daisy", "Das", 5000);
Integer empID3 = ME.addEmployee("John", "Paul", 5000);
Integer empID4 = ME.addEmployee("Mohd", "Yasee", 3000);
/* List down employees and their salary using Scalar Query */
ME.listEmployeesScalar();
/* List down complete employees information using Entity Query */
ME.listEmployeesEntity();
}
/* Method to CREATE an employee in the database */
public Integer addEmployee(String fname, String lname, int salary){
Session session = factory.openSession();
Transaction tx = null;
Integer employeeID = null;
try {
tx = session.beginTransaction();
Employee employee = new Employee(fname, lname, salary);
employeeID = (Integer) session.save(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
return employeeID;
}
/* Method to READ all the employees using Scalar Query */
public void listEmployeesScalar( ){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
String sql = "SELECT first_name, salary FROM EMPLOYEE";
SQLQuery query = session.createSQLQuery(sql);
query.setResultTransformer(Criteria.ALIAS_TO_ENTITY_MAP);
List data = query.list();
for(Object object : data) {
Map row = (Map)object;
System.out.print("First Name: " + row.get("first_name"));
System.out.println(", Salary: " + row.get("salary"));
}
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to READ all the employees using Entity Query */
public void listEmployeesEntity( ){
Session session = factory.openSession();
Transaction tx = null;
try {
tx = session.beginTransaction();
String sql = "SELECT * FROM EMPLOYEE";
SQLQuery query = session.createSQLQuery(sql);
query.addEntity(Employee.class);
List employees = query.list();
for (Iterator iterator = employees.iterator(); iterator.hasNext();){
Employee employee = (Employee) iterator.next();
System.out.print("First Name: " + employee.getFirstName());
System.out.print(" Last Name: " + employee.getLastName());
System.out.println(" Salary: " + employee.getSalary());
}
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
}
Компиляция и выполнение
Вот шаги для компиляции и запуска вышеупомянутого приложения. Убедитесь, что вы правильно установили PATH и CLASSPATH, прежде чем приступить к компиляции и выполнению.
-
Создайте файл конфигурации hibernate.cfg.xml, как описано в главе о конфигурации.
-
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
-
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
-
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
-
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Создайте файл конфигурации hibernate.cfg.xml, как описано в главе о конфигурации.
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Вы получите следующий результат, и записи будут созданы в таблице EMPLOYEE.
$java ManageEmployee .......VARIOUS LOG MESSAGES WILL DISPLAY HERE........ First Name: Zara, Salary: 2000 First Name: Daisy, Salary: 5000 First Name: John, Salary: 5000 First Name: Mohd, Salary: 3000 First Name: Zara Last Name: Ali Salary: 2000 First Name: Daisy Last Name: Das Salary: 5000 First Name: John Last Name: Paul Salary: 5000 First Name: Mohd Last Name: Yasee Salary: 3000
Если вы проверите свою таблицу EMPLOYEE, она должна иметь следующие записи:
mysql> select * from EMPLOYEE; +----+------------+-----------+--------+ | id | first_name | last_name | salary | +----+------------+-----------+--------+ | 26 | Zara | Ali | 2000 | | 27 | Daisy | Das | 5000 | | 28 | John | Paul | 5000 | | 29 | Mohd | Yasee | 3000 | +----+------------+-----------+--------+ 4 rows in set (0.00 sec) mysql>
Hibernate — Кэширование
Кэширование — это механизм повышения производительности системы. Это буферная память, которая лежит между приложением и базой данных. Кэш-память хранит недавно использованные элементы данных, чтобы максимально уменьшить количество обращений к базе данных.
Кеширование также важно для Hibernate. Он использует многоуровневую схему кэширования, как описано ниже —
Кэш первого уровня
Кэш первого уровня — это кэш сеанса, который является обязательным кешем, через который должны проходить все запросы. Объект Session держит объект в своих собственных полномочиях, прежде чем зафиксировать его в базе данных.
Если вы выпускаете несколько обновлений для объекта, Hibernate пытается отложить выполнение обновления как можно дольше, чтобы уменьшить количество выпущенных операторов SQL обновления. Если вы закроете сеанс, все кэшируемые объекты будут потеряны и сохранены или обновлены в базе данных.
Кэш второго уровня
Кэш второго уровня — это необязательный кеш, и к нему всегда обращаются, прежде чем предпринимать какие-либо попытки найти объект в кеше второго уровня. Кэш второго уровня может быть настроен для каждого класса и коллекции и в основном отвечает за кэширование объектов между сеансами.
Любой сторонний кеш может быть использован с Hibernate. Предоставляется интерфейс org.hibernate.cache.CacheProvider , который должен быть реализован, чтобы обеспечить Hibernate дескриптором реализации кэша.
Кэш на уровне запросов
Hibernate также реализует кеш для наборов результатов запросов, который тесно интегрируется с кешем второго уровня.
Это необязательная функция, для которой требуются две дополнительные области физического кэша, в которых хранятся результаты кэшированного запроса и отметки времени последнего обновления таблицы. Это полезно только для запросов, которые часто выполняются с одинаковыми параметрами.
Кэш второго уровня
Hibernate по умолчанию использует кэш первого уровня, и вам нечего делать, чтобы использовать кэш первого уровня. Давайте перейдем прямо к дополнительному кешу второго уровня. Не все классы получают выгоду от кэширования, поэтому важно иметь возможность отключить кэш второго уровня.
Кэш второго уровня Hibernate настраивается в два этапа. Сначала вы должны решить, какую стратегию параллелизма использовать. После этого вы настраиваете срок действия и физические атрибуты кеша с помощью провайдера кеша.
Стратегии параллелизма
Стратегия параллелизма — это посредник, который отвечает за хранение элементов данных в кэше и извлечение их из кэша. Если вы собираетесь включить кэш второго уровня, вам придется решить, для каждого постоянного класса и коллекции, какую стратегию параллельного использования кэша использовать.
-
Транзакционный. Используйте эту стратегию для данных, предназначенных главным образом для чтения, где важно предотвратить устаревшие данные в параллельных транзакциях в редких случаях обновления.
-
Чтение-запись — снова используйте эту стратегию для данных, предназначенных главным образом для чтения, где важно предотвратить устаревшие данные в параллельных транзакциях, в редких случаях обновления.
-
Nonstrict-read-write — эта стратегия не гарантирует согласованности между кешем и базой данных. Используйте эту стратегию, если данные почти никогда не изменяются и небольшая вероятность устаревших данных не является критической проблемой.
-
Только для чтения — стратегия параллелизма, подходящая для данных, которая никогда не изменяется. Используйте его только для справочных данных.
Транзакционный. Используйте эту стратегию для данных, предназначенных главным образом для чтения, где важно предотвратить устаревшие данные в параллельных транзакциях в редких случаях обновления.
Чтение-запись — снова используйте эту стратегию для данных, предназначенных главным образом для чтения, где важно предотвратить устаревшие данные в параллельных транзакциях, в редких случаях обновления.
Nonstrict-read-write — эта стратегия не гарантирует согласованности между кешем и базой данных. Используйте эту стратегию, если данные почти никогда не изменяются и небольшая вероятность устаревших данных не является критической проблемой.
Только для чтения — стратегия параллелизма, подходящая для данных, которая никогда не изменяется. Используйте его только для справочных данных.
Если мы собираемся использовать кэширование второго уровня для нашего класса Employee , добавим элемент отображения, необходимый для того, чтобы Hibernate кэшировал экземпляры Employee, используя стратегию чтения-записи.
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name = "Employee" table = "EMPLOYEE">
<meta attribute = "class-description">
This class contains the employee detail.
</meta>
<cache usage = "read-write"/>
<id name = "id" type = "int" column = "id">
<generator class="native"/>
</id>
<property name = "firstName" column = "first_name" type = "string"/>
<property name = "lastName" column = "last_name" type = "string"/>
<property name = "salary" column = "salary" type = "int"/>
</class>
</hibernate-mapping>
Атрибут use = «read-write» указывает Hibernate использовать стратегию параллельного чтения и записи для определенного кэша.
Поставщик кэша
Следующим шагом после рассмотрения стратегий параллелизма станет использование классов-кандидатов в кэш для выбора поставщика кеша. Hibernate заставляет вас выбирать одного поставщика кеша для всего приложения.
| Sr.No. | Имя и описание кэша |
|---|---|
| 1 |
EHCache Он может кэшироваться в памяти или на диске, а также в кластерном кэшировании и поддерживает дополнительный кэш результатов запроса Hibernate. |
| 2 |
OSCache Поддерживает кэширование в память и на диск в одной JVM с богатым набором политик истечения срока действия и поддержкой кэша запросов. |
| 3 |
warmCache Кластерный кеш на основе JGroups. Он использует кластеризованную аннулирование, но не поддерживает кэш запросов Hibernate. |
| 4 |
JBoss Cache Полностью транзакционный реплицируемый кластерный кеш, также основанный на многоадресной библиотеке JGroups. Он поддерживает репликацию или аннулирование, синхронную или асинхронную связь, а также оптимистическую и пессимистическую блокировки. Кеш запросов Hibernate поддерживается. |
EHCache
Он может кэшироваться в памяти или на диске, а также в кластерном кэшировании и поддерживает дополнительный кэш результатов запроса Hibernate.
OSCache
Поддерживает кэширование в память и на диск в одной JVM с богатым набором политик истечения срока действия и поддержкой кэша запросов.
warmCache
Кластерный кеш на основе JGroups. Он использует кластеризованную аннулирование, но не поддерживает кэш запросов Hibernate.
JBoss Cache
Полностью транзакционный реплицируемый кластерный кеш, также основанный на многоадресной библиотеке JGroups. Он поддерживает репликацию или аннулирование, синхронную или асинхронную связь, а также оптимистическую и пессимистическую блокировки. Кеш запросов Hibernate поддерживается.
Каждый поставщик кэша не совместим с любой стратегией параллелизма. Следующая матрица совместимости поможет вам выбрать подходящую комбинацию.
| Стратегия / Provider | Только для чтения | Nonstrictread-записи | Читай пиши | транзакционный |
|---|---|---|---|---|
| EHCache | Икс | Икс | Икс | |
| OSCache | Икс | Икс | Икс | |
| SwarmCache | Икс | Икс | ||
| JBoss Cache | Икс | Икс |
Вы будете указывать поставщика кеша в файле конфигурации hibernate.cfg.xml. Мы выбираем EHCache в качестве нашего поставщика кэша второго уровня —
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-configuration SYSTEM
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name = "hibernate.dialect">
org.hibernate.dialect.MySQLDialect
</property>
<property name = "hibernate.connection.driver_class">
com.mysql.jdbc.Driver
</property>
<!-- Assume students is the database name -->
<property name = "hibernate.connection.url">
jdbc:mysql://localhost/test
</property>
<property name = "hibernate.connection.username">
root
</property>
<property name = "hibernate.connection.password">
root123
</property>
<property name = "hibernate.cache.provider_class">
org.hibernate.cache.EhCacheProvider
</property>
<!-- List of XML mapping files -->
<mapping resource = "Employee.hbm.xml"/>
</session-factory>
</hibernate-configuration>
Теперь вам нужно указать свойства областей кэша. EHCache имеет свой собственный файл конфигурации, ehcache.xml , который должен находиться в CLASSPATH приложения. Конфигурация кэша в ehcache.xml для класса Employee может выглядеть так:
<diskStore path="java.io.tmpdir"/> <defaultCache maxElementsInMemory = "1000" eternal = "false" timeToIdleSeconds = "120" timeToLiveSeconds = "120" overflowToDisk = "true" /> <cache name = "Employee" maxElementsInMemory = "500" eternal = "true" timeToIdleSeconds = "0" timeToLiveSeconds = "0" overflowToDisk = "false" />
Вот и все, теперь у нас включено кэширование второго уровня для класса Employee, а Hibernate теперь обращается к кэшу второго уровня, когда вы переходите к Employee или когда вы загружаете Employee по идентификатору.
Вы должны проанализировать все свои классы и выбрать подходящую стратегию кэширования для каждого из классов. Иногда кэширование второго уровня может снизить производительность приложения. Поэтому рекомендуется сначала провести сравнительный анализ вашего приложения, не включая кэширование, а затем включите хорошо подходящее кэширование и проверьте производительность. Если кэширование не улучшает производительность системы, то нет смысла включать любой тип кэширования.
Кэш на уровне запросов
Чтобы использовать кэш запросов, сначала необходимо активировать его, используя свойство hibernate.cache.use_query_cache = «true» в файле конфигурации. Установив для этого свойства значение true, вы заставляете Hibernate создавать необходимые кеши в памяти для хранения наборов запросов и идентификаторов.
Далее, чтобы использовать кеш запросов, вы используете метод setCacheable (Boolean) класса Query. Например —
Session session = SessionFactory.openSession();
Query query = session.createQuery("FROM EMPLOYEE");
query.setCacheable(true);
List users = query.list();
SessionFactory.closeSession();
Hibernate также поддерживает очень тонкую поддержку кэша благодаря концепции области кэша. Регион кеша является частью кеша, которому дано имя.
Session session = SessionFactory.openSession();
Query query = session.createQuery("FROM EMPLOYEE");
query.setCacheable(true);
query.setCacheRegion("employee");
List users = query.list();
SessionFactory.closeSession();
Этот код использует метод, чтобы сообщить Hibernate хранить и искать запрос в области кэша сотрудников.
Hibernate — Пакетная обработка
Рассмотрим ситуацию, когда вам нужно загрузить большое количество записей в вашу базу данных с помощью Hibernate. Ниже приведен фрагмент кода для достижения этой цели с помощью Hibernate —
Session session = SessionFactory.openSession();
Transaction tx = session.beginTransaction();
for ( int i=0; i<100000; i++ ) {
Employee employee = new Employee(.....);
session.save(employee);
}
tx.commit();
session.close();
По умолчанию Hibernate будет кэшировать все сохраненные объекты в кэше на уровне сеанса, и в конечном итоге ваше приложение будет сброшено с OutOfMemoryException где-то около 50 000-й строки. Вы можете решить эту проблему, если вы используете пакетную обработку с Hibernate.
Чтобы использовать функцию пакетной обработки, сначала установите hibernate.jdbc.batch_size в качестве размера пакета равным 20 или 50, в зависимости от размера объекта. Это сообщит Hibernate контейнеру, что каждые X строк должны быть вставлены в пакетном режиме. Чтобы реализовать это в вашем коде, нам нужно будет сделать небольшое изменение следующим образом:
Session session = SessionFactory.openSession();
Transaction tx = session.beginTransaction();
for ( int i=0; i<100000; i++ ) {
Employee employee = new Employee(.....);
session.save(employee);
if( i % 50 == 0 ) { // Same as the JDBC batch size
//flush a batch of inserts and release memory:
session.flush();
session.clear();
}
}
tx.commit();
session.close();
Приведенный выше код будет нормально работать для операции INSERT, но если вы захотите выполнить операцию UPDATE, вы можете добиться с помощью следующего кода:
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
ScrollableResults employeeCursor = session.createQuery("FROM EMPLOYEE").scroll();
int count = 0;
while ( employeeCursor.next() ) {
Employee employee = (Employee) employeeCursor.get(0);
employee.updateEmployee();
seession.update(employee);
if ( ++count % 50 == 0 ) {
session.flush();
session.clear();
}
}
tx.commit();
session.close();
Пример пакетной обработки
Давайте изменим файл конфигурации, добавив свойство hibernate.jdbc.batch_size —
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-configuration SYSTEM
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name = "hibernate.dialect">
org.hibernate.dialect.MySQLDialect
</property>
<property name = "hibernate.connection.driver_class">
com.mysql.jdbc.Driver
</property>
<!-- Assume students is the database name -->
<property name = "hibernate.connection.url">
jdbc:mysql://localhost/test
</property>
<property name = "hibernate.connection.username">
root
</property>
<property name = "hibernate.connection.password">
root123
</property>
<property name = "hibernate.jdbc.batch_size">
50
</property>
<!-- List of XML mapping files -->
<mapping resource = "Employee.hbm.xml"/>
</session-factory>
</hibernate-configuration>
Рассмотрим следующий класс сотрудников POJO —
public class Employee {
private int id;
private String firstName;
private String lastName;
private int salary;
public Employee() {}
public Employee(String fname, String lname, int salary) {
this.firstName = fname;
this.lastName = lname;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}
Давайте создадим следующую таблицу EMPLOYEE для хранения объектов Employee —
create table EMPLOYEE ( id INT NOT NULL auto_increment, first_name VARCHAR(20) default NULL, last_name VARCHAR(20) default NULL, salary INT default NULL, PRIMARY KEY (id) );
Ниже будет файл сопоставления для сопоставления объектов Employee с таблицей EMPLOYEE —
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name = "Employee" table = "EMPLOYEE">
<meta attribute = "class-description">
This class contains the employee detail.
</meta>
<id name = "id" type = "int" column = "id">
<generator class="native"/>
</id>
<property name = "firstName" column = "first_name" type = "string"/>
<property name = "lastName" column = "last_name" type = "string"/>
<property name = "salary" column = "salary" type = "int"/>
</class>
</hibernate-mapping>
Наконец, мы создадим наш класс приложения с методом main () для запуска приложения, в котором мы будем использовать методы flush () и clear (), доступные в объекте Session, чтобы Hibernate продолжал записывать эти записи в базу данных, а не кэшировать их в объем памяти.
import java.util.*;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.Transaction;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class ManageEmployee {
private static SessionFactory factory;
public static void main(String[] args) {
try {
factory = new Configuration().configure().buildSessionFactory();
} catch (Throwable ex) {
System.err.println("Failed to create sessionFactory object." + ex);
throw new ExceptionInInitializerError(ex);
}
ManageEmployee ME = new ManageEmployee();
/* Add employee records in batches */
ME.addEmployees( );
}
/* Method to create employee records in batches */
public void addEmployees( ){
Session session = factory.openSession();
Transaction tx = null;
Integer employeeID = null;
try {
tx = session.beginTransaction();
for ( int i=0; i<100000; i++ ) {
String fname = "First Name " + i;
String lname = "Last Name " + i;
Integer salary = i;
Employee employee = new Employee(fname, lname, salary);
session.save(employee);
if( i % 50 == 0 ) {
session.flush();
session.clear();
}
}
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
return ;
}
}
Компиляция и выполнение
Вот шаги для компиляции и запуска вышеупомянутого приложения. Убедитесь, что вы правильно установили PATH и CLASSPATH, прежде чем приступить к компиляции и выполнению.
-
Создайте файл конфигурации hibernate.cfg.xml, как описано выше.
-
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
-
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
-
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
-
Выполните двоичный файл ManageEmployee, чтобы запустить программу, которая создаст 100000 записей в таблице EMPLOYEE.
Создайте файл конфигурации hibernate.cfg.xml, как описано выше.
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
Выполните двоичный файл ManageEmployee, чтобы запустить программу, которая создаст 100000 записей в таблице EMPLOYEE.
Hibernate — Перехватчики
Как вы узнали, что в Hibernate объект будет создан и сохранен. Как только объект был изменен, он должен быть сохранен обратно в базу данных. Этот процесс продолжается до следующего раза, когда объект понадобится, и он будет загружен из постоянного хранилища.
Таким образом, объект проходит через различные этапы своего жизненного цикла, и интерфейс перехватчика предоставляет методы, которые можно вызывать на различных этапах для выполнения некоторых необходимых задач. Эти методы являются обратными вызовами от сеанса к приложению, позволяя приложению проверять и / или манипулировать свойствами постоянного объекта перед его сохранением, обновлением, удалением или загрузкой. Ниже приведен список всех методов, доступных в интерфейсе Interceptor.
| Sr.No. | Метод и описание |
|---|---|
| 1 |
findDirty () Этот метод вызывается, когда метод flush () вызывается для объекта Session. |
| 2 |
экземпляр () Этот метод вызывается, когда создается экземпляр постоянного класса. |
| 3 |
isUnsaved () Этот метод вызывается, когда объект передается методу saveOrUpdate () / |
| 4 |
OnDelete () Этот метод вызывается перед удалением объекта. |
| 5 |
onFlushDirty () Этот метод вызывается, когда Hibernate обнаруживает, что объект загрязнен (то есть был изменен) во время сброса, т.е. операции обновления. |
| 6 |
в процессе() Этот метод вызывается до инициализации объекта. |
| 7 |
OnSave () Этот метод вызывается перед сохранением объекта. |
| 8 |
postFlush () Этот метод вызывается после сброса и обновления объекта в памяти. |
| 9 |
промывочная () Этот метод вызывается перед сбросом. |
findDirty ()
Этот метод вызывается, когда метод flush () вызывается для объекта Session.
экземпляр ()
Этот метод вызывается, когда создается экземпляр постоянного класса.
isUnsaved ()
Этот метод вызывается, когда объект передается методу saveOrUpdate () /
OnDelete ()
Этот метод вызывается перед удалением объекта.
onFlushDirty ()
Этот метод вызывается, когда Hibernate обнаруживает, что объект загрязнен (то есть был изменен) во время сброса, т.е. операции обновления.
в процессе()
Этот метод вызывается до инициализации объекта.
OnSave ()
Этот метод вызывается перед сохранением объекта.
postFlush ()
Этот метод вызывается после сброса и обновления объекта в памяти.
промывочная ()
Этот метод вызывается перед сбросом.
Hibernate Interceptor дает нам полный контроль над тем, как объект будет выглядеть как для приложения, так и для базы данных.
Как использовать перехватчики?
Чтобы создать перехватчик, вы можете либо напрямую реализовать класс Interceptor, либо расширить класс EmptyInterceptor . Далее будут простые шаги по использованию функциональности Hibernate Interceptor.
Создать перехватчики
Мы расширим EmptyInterceptor в нашем примере, где метод Interceptor будет вызываться автоматически при создании и обновлении объекта Employee . Вы можете реализовать больше методов в соответствии с вашими требованиями.
import java.io.Serializable;
import java.util.Date;
import java.util.Iterator;
import org.hibernate.EmptyInterceptor;
import org.hibernate.Transaction;
import org.hibernate.type.Type;
public class MyInterceptor extends EmptyInterceptor {
private int updates;
private int creates;
private int loads;
public void onDelete(Object entity, Serializable id,
Object[] state, String[] propertyNames, Type[] types) {
// do nothing
}
// This method is called when Employee object gets updated.
public boolean onFlushDirty(Object entity, Serializable id,
Object[] currentState, Object[] previousState, String[] propertyNames,
Type[] types) {
if ( entity instanceof Employee ) {
System.out.println("Update Operation");
return true;
}
return false;
}
public boolean onLoad(Object entity, Serializable id,
Object[] state, String[] propertyNames, Type[] types) {
// do nothing
return true;
}
// This method is called when Employee object gets created.
public boolean onSave(Object entity, Serializable id,
Object[] state, String[] propertyNames, Type[] types) {
if ( entity instanceof Employee ) {
System.out.println("Create Operation");
return true;
}
return false;
}
//called before commit into database
public void preFlush(Iterator iterator) {
System.out.println("preFlush");
}
//called after committed into database
public void postFlush(Iterator iterator) {
System.out.println("postFlush");
}
}
Создать классы POJO
Теперь давайте немного изменим наш первый пример, в котором мы использовали таблицу EMPLOYEE и класс Employee для игры —
public class Employee {
private int id;
private String firstName;
private String lastName;
private int salary;
public Employee() {}
public Employee(String fname, String lname, int salary) {
this.firstName = fname;
this.lastName = lname;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId( int id ) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName( String first_name ) {
this.firstName = first_name;
}
public String getLastName() {
return lastName;
}
public void setLastName( String last_name ) {
this.lastName = last_name;
}
public int getSalary() {
return salary;
}
public void setSalary( int salary ) {
this.salary = salary;
}
}
Создать таблицы базы данных
Вторым шагом будет создание таблиц в вашей базе данных. Там будет одна таблица, соответствующая каждому объекту, вы готовы предоставить постоянство. Рассмотрим объекты, описанные выше, которые необходимо сохранить и извлечь в следующую таблицу RDBMS —
create table EMPLOYEE ( id INT NOT NULL auto_increment, first_name VARCHAR(20) default NULL, last_name VARCHAR(20) default NULL, salary INT default NULL, PRIMARY KEY (id) );
Создать файл конфигурации сопоставления
На этом этапе создается файл сопоставления, который инструктирует Hibernate — как сопоставить определенный класс или классы с таблицами базы данных.
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name = "Employee" table = "EMPLOYEE">
<meta attribute = "class-description">
This class contains the employee detail.
</meta>
<id name = "id" type = "int" column = "id">
<generator class="native"/>
</id>
<property name = "firstName" column = "first_name" type = "string"/>
<property name = "lastName" column = "last_name" type = "string"/>
<property name = "salary" column = "salary" type = "int"/>
</class>
</hibernate-mapping>
Создать класс приложения
Наконец, мы создадим наш класс приложения с методом main () для запуска приложения. Здесь следует отметить, что при создании объекта сеанса мы использовали наш класс Interceptor в качестве аргумента.
import java.util.List;
import java.util.Date;
import java.util.Iterator;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.Transaction;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class ManageEmployee {
private static SessionFactory factory;
public static void main(String[] args) {
try {
factory = new Configuration().configure().buildSessionFactory();
} catch (Throwable ex) {
System.err.println("Failed to create sessionFactory object." + ex);
throw new ExceptionInInitializerError(ex);
}
ManageEmployee ME = new ManageEmployee();
/* Add few employee records in database */
Integer empID1 = ME.addEmployee("Zara", "Ali", 1000);
Integer empID2 = ME.addEmployee("Daisy", "Das", 5000);
Integer empID3 = ME.addEmployee("John", "Paul", 10000);
/* List down all the employees */
ME.listEmployees();
/* Update employee's records */
ME.updateEmployee(empID1, 5000);
/* Delete an employee from the database */
ME.deleteEmployee(empID2);
/* List down new list of the employees */
ME.listEmployees();
}
/* Method to CREATE an employee in the database */
public Integer addEmployee(String fname, String lname, int salary){
Session session = factory.openSession( new MyInterceptor() );
Transaction tx = null;
Integer employeeID = null;
try {
tx = session.beginTransaction();
Employee employee = new Employee(fname, lname, salary);
employeeID = (Integer) session.save(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
return employeeID;
}
/* Method to READ all the employees */
public void listEmployees( ){
Session session = factory.openSession( new MyInterceptor() );
Transaction tx = null;
try {
tx = session.beginTransaction();
List employees = session.createQuery("FROM Employee").list();
for (Iterator iterator = employees.iterator(); iterator.hasNext();){
Employee employee = (Employee) iterator.next();
System.out.print("First Name: " + employee.getFirstName());
System.out.print(" Last Name: " + employee.getLastName());
System.out.println(" Salary: " + employee.getSalary());
}
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to UPDATE salary for an employee */
public void updateEmployee(Integer EmployeeID, int salary ){
Session session = factory.openSession( new MyInterceptor() );
Transaction tx = null;
try {
tx = session.beginTransaction();
Employee employee = (Employee)session.get(Employee.class, EmployeeID);
employee.setSalary( salary );
session.update(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
/* Method to DELETE an employee from the records */
public void deleteEmployee(Integer EmployeeID){
Session session = factory.openSession( new MyInterceptor() );
Transaction tx = null;
try {
tx = session.beginTransaction();
Employee employee = (Employee)session.get(Employee.class, EmployeeID);
session.delete(employee);
tx.commit();
} catch (HibernateException e) {
if (tx!=null) tx.rollback();
e.printStackTrace();
} finally {
session.close();
}
}
}
Компиляция и выполнение
Вот шаги для компиляции и запуска вышеупомянутого приложения. Убедитесь, что вы правильно установили PATH и CLASSPATH, прежде чем приступить к компиляции и выполнению.
-
Создайте файл конфигурации hibernate.cfg.xml, как описано в главе о конфигурации.
-
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
-
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
-
Создайте исходный файл MyInterceptor.java, как показано выше, и скомпилируйте его.
-
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
-
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Создайте файл конфигурации hibernate.cfg.xml, как описано в главе о конфигурации.
Создайте файл сопоставления Employee.hbm.xml, как показано выше.
Создайте исходный файл Employee.java, как показано выше, и скомпилируйте его.
Создайте исходный файл MyInterceptor.java, как показано выше, и скомпилируйте его.
Создайте исходный файл ManageEmployee.java, как показано выше, и скомпилируйте его.
Выполните двоичный файл ManageEmployee, чтобы запустить программу.
Вы получите следующий результат, и записи будут созданы в таблице EMPLOYEE.
$java ManageEmployee .......VARIOUS LOG MESSAGES WILL DISPLAY HERE........ Create Operation preFlush postFlush Create Operation preFlush postFlush Create Operation preFlush postFlush First Name: Zara Last Name: Ali Salary: 1000 First Name: Daisy Last Name: Das Salary: 5000 First Name: John Last Name: Paul Salary: 10000 preFlush postFlush preFlush Update Operation postFlush preFlush postFlush First Name: Zara Last Name: Ali Salary: 5000 First Name: John Last Name: Paul Salary: 10000 preFlush postFlush
Если вы проверите свою таблицу EMPLOYEE, она должна иметь следующие записи: