Виртуальная машина Java — Введение
JVM является спецификацией и может иметь различные реализации, если они соответствуют спецификациям. Спецификации можно найти по ссылке ниже — https://docs.oracle.com
У Oracle есть своя собственная реализация JVM (называемая JVM HotSpot), у IBM — своя (например, JVM J9).
Операции, определенные внутри спецификации, приведены ниже (источник — спецификации Oracle JVM, см. Ссылку выше) —
- Формат файла ‘class’
- Типы данных
- Примитивные типы и значения
- Типы ссылок и значения
- Области данных времени выполнения
- Рамки
- Представление объектов
- Арифметика с плавающей точкой
- Специальные методы
- Исключения
- Сводка инструкций
- Библиотеки классов
- Публичный дизайн, частная реализация
JVM — это виртуальная машина, абстрактный компьютер, который имеет свой собственный ISA, собственную память, стек, кучу и т. Д. Он работает в операционной системе хоста и предъявляет ему требования к ресурсам.
Виртуальная машина Java — Архитектура
Архитектура HotSpot JVM 3 показана ниже —
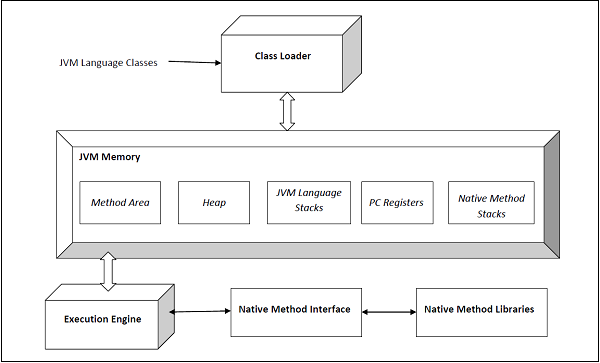
Механизм выполнения состоит из сборщика мусора и JIT-компилятора. JVM поставляется в двух вариантах — клиент и сервер . Оба они используют один и тот же код времени выполнения, но отличаются тем, какой JIT используется. Мы узнаем больше об этом позже. Пользователь может контролировать, какой вариант использовать, указав флаги JVM -client или -server . Серверная JVM была разработана для долго работающих Java-приложений на серверах.
JVM поставляется в 32-битной и 64-битной версиях. Пользователь может указать, какую версию использовать, используя -d32 или -d64 в аргументах виртуальной машины. 32-битная версия может адресовать только до 4 ГБ памяти. С критическими приложениями, поддерживающими большие наборы данных в памяти, версия 64b отвечает этой потребности.
Виртуальная машина Java — загрузчик классов
JVM динамически управляет процессом загрузки, связывания и инициализации классов и интерфейсов. В процессе загрузки JVM находит двоичное представление класса и создает его.
В процессе связывания загруженные классы объединяются в состояние времени выполнения JVM, чтобы их можно было выполнить на этапе инициализации . JVM в основном использует таблицу символов, хранящуюся в постоянном пуле времени выполнения, для процесса связывания. Инициализация состоит из фактического выполнения связанных классов .
Типы погрузчиков
Загрузчик классов BootStrap находится на вершине иерархии загрузчиков классов. Он загружает стандартные классы JDK в каталог lib JRE.
Загрузчик класса Extension находится в середине иерархии загрузчика классов и является непосредственным потомком загрузчика классов начальной загрузки и загружает классы в каталог lib \ ext JRE.
Загрузчик классов приложений находится в нижней части иерархии загрузчиков классов и является непосредственным потомком загрузчика классов приложений. Он загружает файлы jar и классы, указанные в переменной CLVSPATH ENV .
соединение
Процесс связывания состоит из следующих трех шагов —
Проверка — это выполняется с помощью верификатора байт-кода, чтобы убедиться, что сгенерированные файлы .class (байт-код) действительны. Если нет, выдается ошибка, и процесс компоновки останавливается.
Подготовка — память выделяется для всех статических переменных класса, и они инициализируются со значениями по умолчанию.
Решение. Все символические ссылки в памяти заменяются исходными ссылками. Для этого используется таблица символов в постоянной памяти времени выполнения области метода класса.
инициализация
Это последний этап процесса загрузки классов. Статическим переменным присваиваются исходные значения и выполняются статические блоки.
Виртуальная машина Java — области данных времени выполнения
Спецификация JVM определяет определенные области данных времени выполнения, которые необходимы во время выполнения программы. Некоторые из них создаются во время запуска JVM. Другие являются локальными для потоков и создаются только при создании потока (и уничтожаются при разрушении потока). Они перечислены ниже —
ПК (счетчик программ) Регистрация
Он является локальным для каждого потока и содержит адрес инструкции JVM, которую поток выполняет в данный момент.
стек
Он является локальным для каждого потока и сохраняет параметры, локальные переменные и адреса возврата во время вызовов метода. Ошибка StackOverflow может возникнуть, если поток требует больше места в стеке, чем это разрешено. Если стек динамически расширяемый, он все равно может выбросить OutOfMemoryError.
отвал
Он распределяется между всеми потоками и содержит объекты, метаданные классов, массивы и т. Д., Которые создаются во время выполнения. Он создается при запуске JVM и уничтожается при выключении JVM. Вы можете контролировать объем кучи, требуемой вашей JVM от ОС, используя определенные флаги (подробнее об этом позже). Необходимо соблюдать осторожность, чтобы не потребовать слишком мало или слишком много памяти, поскольку это имеет важные последствия для производительности. Кроме того, GC управляет этим пространством и постоянно удаляет мертвые объекты, чтобы освободить пространство.
Область метода
Эта область выполнения является общей для всех потоков и создается при запуске JVM. Он хранит структуры для каждого класса, такие как пул констант (подробнее об этом позже), код для конструкторов и методов, данные методов и т. Д. JLS не определяет, нужно ли собирать эту область, и, следовательно, реализации JVM может игнорировать GC. Кроме того, это может или не может расширяться в соответствии с потребностями приложения. JLS не требует ничего в отношении этого.
Постоянный пул времени выполнения
JVM поддерживает структуру данных для каждого класса / типа, которая действует как таблица символов (одна из ее многочисленных ролей) при связывании загруженных классов.
Стеки родного метода
Когда поток вызывает собственный метод, он входит в новый мир, в котором структуры и ограничения безопасности виртуальной машины Java больше не ограничивают его свободу. Собственный метод может, вероятно, получить доступ к областям данных времени выполнения виртуальной машины (это зависит от интерфейса нативного метода), но также может делать все что угодно.
Вывоз мусора
JVM управляет всем жизненным циклом объектов в Java. Как только объект создан, разработчику больше не нужно беспокоиться об этом. В случае, если объект становится мертвым (то есть, на него больше нет ссылок), он извлекается из кучи GC, используя один из многих алгоритмов — последовательный GC, CMS, G1 и т. Д.
Во время процесса GC объекты перемещаются в память. Следовательно, эти объекты не могут быть использованы во время процесса. Все приложение должно быть остановлено на время процесса. Такие паузы называются паузами «останови мир» и являются огромными накладными расходами. Алгоритмы GC направлены в первую очередь на сокращение этого времени. Мы обсудим это очень подробно в следующих главах.
Благодаря GC, утечки памяти очень редки в Java, но они могут произойти. В следующих главах мы увидим, как создать утечку памяти в Java.
Виртуальная машина Java — JIT-компилятор
В этой главе мы узнаем о JIT-компиляторе и разнице между компилируемыми и интерпретируемыми языками.
Скомпилированные и интерпретированные языки
Такие языки, как C, C ++ и FORTRAN, являются скомпилированными языками. Их код поставляется в виде двоичного кода, предназначенного для базовой машины. Это означает, что высокоуровневый код компилируется в двоичный код одновременно статическим компилятором, написанным специально для базовой архитектуры. Созданный двоичный файл не будет работать на любой другой архитектуре.
С другой стороны, интерпретируемые языки, такие как Python и Perl, могут работать на любой машине, если у них есть действительный интерпретатор. Он переходит построчно к высокоуровневому коду, преобразуя его в двоичный код.
Интерпретируемый код обычно медленнее, чем скомпилированный код. Например, рассмотрим цикл. Интерпретируемый преобразует соответствующий код для каждой итерации цикла. С другой стороны, скомпилированный код сделает перевод только одним. Кроме того, поскольку интерпретаторы видят только одну строку за раз, они не могут выполнить какой-либо значимый код, например, изменить порядок выполнения операторов, таких как компиляторы.
Мы рассмотрим пример такой оптимизации ниже —
Добавление двух чисел, хранящихся в памяти . Поскольку доступ к памяти может занимать несколько циклов ЦП, хороший компилятор выдаст инструкции для извлечения данных из памяти и выполнения сложения только при наличии данных. Он не будет ждать, а пока выполнит другие инструкции. С другой стороны, никакая такая оптимизация была бы невозможна во время интерпретации, поскольку интерпретатор не знает весь код в любой момент времени.
Но тогда интерпретируемые языки могут работать на любой машине, у которой есть действительный интерпретатор этого языка.
Java компилируется или интерпретируется?
Ява пыталась найти золотую середину. Поскольку JVM находится между компилятором javac и базовым оборудованием, компилятор javac (или любой другой компилятор) компилирует код Java в байт-код, который понимается JVM для конкретной платформы. Затем JVM компилирует байт-код в двоичном формате, используя компиляцию JIT (Just-in-time) по мере выполнения кода.
HotSpots
В типичной программе часто выполняется только небольшая часть кода, и часто именно этот код существенно влияет на производительность всего приложения. Такие разделы кода называются HotSpots .
Если какой-то раздел кода выполняется только один раз, то его компиляция была бы пустой тратой усилий, и вместо этого было бы быстрее интерпретировать байт-код. Но если этот раздел является горячим разделом и выполняется несколько раз, JVM скомпилирует его. Например, если метод вызывается несколько раз, дополнительные циклы, которые потребуются для компиляции кода, будут компенсированы более быстрым генерируемым двоичным файлом.
Кроме того, чем больше JVM запускает конкретный метод или цикл, тем больше информации она собирает для проведения различных оптимизаций, чтобы генерировать более быстрый двоичный файл.
Давайте рассмотрим следующий код —
for(int i = 0 ; I <= 100; i++) { System.out.println(obj1.equals(obj2)); //two objects }
Если этот код интерпретируется, интерпретатор будет выводить для каждой итерации, что классы obj1. Это связано с тем, что у каждого класса в Java есть метод .equals (), который расширен от класса Object и может быть переопределен. Таким образом, даже если obj1 является строкой для каждой итерации, вывод все равно будет выполнен.
С другой стороны, в действительности JVM заметит, что для каждой итерации obj1 имеет класс String и, следовательно, будет генерировать код, соответствующий методу .equals () класса String. Таким образом, поиск не потребуется, и скомпилированный код будет выполняться быстрее.
Такое поведение возможно только тогда, когда JVM знает, как ведет себя код. Таким образом, он ждет, прежде чем скомпилировать определенные разделы кода.
Ниже приведен еще один пример —
int sum = 7; for(int i = 0 ; i <= 100; i++) { sum += i; }
Интерпретатор для каждого цикла извлекает из памяти значение «sum», добавляет к нему «I» и сохраняет его в памяти. Доступ к памяти является дорогостоящей операцией и обычно занимает несколько циклов ЦП. Поскольку этот код запускается несколько раз, это HotSpot. JIT скомпилирует этот код и выполнит следующую оптимизацию.
Локальная копия «sum» будет храниться в регистре, специфичном для конкретного потока. Все операции будут выполнены со значением в регистре, и когда цикл завершится, значение будет записано обратно в память.
Что если другие переменные также обращаются к переменной? Поскольку обновления выполняются в локальной копии переменной каким-либо другим потоком, они увидят устаревшее значение. В таких случаях необходима синхронизация потоков. Самым базовым примитивом синхронизации было бы объявление ‘sum’ как volatile. Теперь, прежде чем получить доступ к переменной, поток сбрасывает свои локальные регистры и извлекает значение из памяти. После доступа к нему значение сразу записывается в память.
Ниже приведены некоторые общие оптимизации, которые выполняются компиляторами JIT.
- Метод встраивания
- Устранение мертвого кода
- Эвристика для оптимизации сайтов вызовов
- Постоянное складывание
Виртуальная машина Java — уровни компиляции
JVM поддерживает пять уровней компиляции —
- переводчик
- C1 с полной оптимизацией (без профилирования)
- C1 с счетчиками вызовов и задних кромок (легкое профилирование)
- С1 с полным профилированием
- C2 (использует данные профилирования из предыдущих шагов)
Используйте -Xint, если вы хотите отключить все JIT-компиляторы и использовать только интерпретатор.
Клиент против сервера JIT
Используйте -client и -server для активации соответствующих режимов.
Клиентский компилятор (C1) начинает компилировать код раньше, чем серверный компилятор (C2). Таким образом, к тому времени, когда C2 начал компиляцию, C1 уже скомпилировал части кода.
Но пока он ждет, C2 профилирует код, чтобы узнать о нем больше, чем C1. Следовательно, время ожидания, если смещение по оптимизации может быть использовано для создания гораздо более быстрого двоичного файла. С точки зрения пользователя, компромисс между временем запуска программы и временем, затраченным на ее запуск. Если время запуска является премиальным, то следует использовать C1. Если ожидается, что приложение будет работать в течение длительного времени (типично для приложений, развернутых на серверах), лучше использовать C2, поскольку он генерирует гораздо более быстрый код, который значительно компенсирует любое дополнительное время запуска.
Для таких программ, как IDE (NetBeans, Eclipse) и других программ с графическим интерфейсом, время запуска является критическим. Для запуска NetBeans может потребоваться минута или больше. Сотни классов компилируются при запуске таких программ, как NetBeans. В таких случаях компилятор C1 является лучшим выбором.
Обратите внимание, что существует две версии C1 — 32b и 64b . С2 приходит только в 64б .
Многоуровневая компиляция
В более старых версиях Java пользователь мог выбрать один из следующих параметров:
- Переводчик (-Xint)
- C1 (-клиент)
- C2 (-сервер)
Он появился в Java 7. Он использует компилятор C1 для запуска и, когда код нагревается, переключается на C2. Его можно активировать с помощью следующих параметров JVM: -XX: + TieredCompilation. Значением по умолчанию является false в Java 7 и true в Java 8 .
Из пяти уровней компиляции ярусная компиляция использует 1 -> 4 -> 5 .
Виртуальная машина Java — 32b против 64b
На 32-битной машине может быть установлена только 32-битная версия JVM. На 64-битной машине у пользователя есть выбор между 32-битной и 64-битной версиями. Но в этом есть определенные нюансы, которые могут повлиять на работу наших Java-приложений.
Если приложение Java использует менее 4 ГБ памяти, мы должны использовать 32-разрядную JVM даже на 64-разрядных компьютерах. Это связано с тем, что ссылки на память в этом случае были бы только 32b, и манипулирование ими было бы дешевле, чем манипулирование адресами 64b. В этом случае 64-битная JVM будет работать хуже, даже если мы используем OOPS (обычные объектные указатели). Используя OOPS, JVM может использовать 32-битные адреса в 64-битной JVM. Однако манипулирование ими будет медленнее, чем реальные ссылки 32b, поскольку базовые нативные ссылки будут по-прежнему 64b.
Если наше приложение будет использовать больше памяти 4G, нам придется использовать версию 64b, поскольку ссылки 32b могут адресовать не более 4G памяти. Мы можем установить обе версии на одном компьютере и переключаться между ними с помощью переменной PATH.
Виртуальная машина Java — оптимизация JIT
В этой главе мы узнаем об оптимизации JIT.
Метод Встраивания
В этой технике оптимизации компилятор решает заменить ваши вызовы функций на тело функции. Ниже приведен пример для того же —
int sum3; static int add(int a, int b) { return a + b; } public static void main(String…args) { sum3 = add(5,7) + add(4,2); } //after method inlining public static void main(String…args) { sum3 = 5+ 7 + 4 + 2; }
Используя эту технику, компилятор избавляет машину от накладных расходов при выполнении каких-либо вызовов функций (для этого необходимо перенести и перенести параметры в стек). Таким образом, сгенерированный код работает быстрее.
Встраивание метода может быть сделано только для не виртуальных функций (функций, которые не переопределяются). Подумайте, что произойдет, если метод add был переопределен в подклассе, а тип объекта, содержащего этот метод, неизвестен до времени выполнения. В этом случае компилятор не будет знать, какой метод встроить. Но если бы метод был помечен как ‘final’, то компилятор легко знал бы, что он может быть встроенным, потому что он не может быть переопределен каким-либо подклассом. Обратите внимание, что вовсе не гарантируется, что последний метод всегда будет встроен.
Недоступный и мертвый код
Недоступный код — это код, который не может быть достигнут ни одним из возможных потоков выполнения. Мы рассмотрим следующий пример —
void foo() { if (a) return; else return; foobar(a,b); //unreachable code, compile time error }
Мертвый код также является недостижимым кодом, но компилятор выдает ошибку в этом случае. Вместо этого мы просто получаем предупреждение. Каждый блок кода, такой как конструкторы, функции, try, catch, если, while и т. Д., Имеют свои собственные правила для недоступного кода, определенного в JLS (Спецификация языка Java).
Постоянное складывание
Чтобы понять концепцию постоянного сворачивания, см. Пример ниже.
final int num = 5; int b = num * 6; //compile-time constant, num never changes //compiler would assign b a value of 30.
Виртуальная машина Java — Сборка мусора
Жизненный цикл объекта Java управляется JVM. Как только объект создан программистом, нам не нужно беспокоиться об оставшейся части его жизненного цикла. JVM автоматически найдет те объекты, которые больше не используются, и освободит их память из кучи.
Сборка мусора — это основная операция, которую выполняет JVM, и ее настройка для наших нужд может значительно повысить производительность нашего приложения. Существуют различные алгоритмы сборки мусора, которые предоставляются современными JVM. Нам нужно знать о потребностях нашего приложения, чтобы решить, какой алгоритм использовать.
Вы не можете освобождать объект программно в Java, как вы можете делать в не-GC языках, таких как C и C ++. Таким образом, вы не можете иметь висячие ссылки в Java. Однако у вас могут быть нулевые ссылки (ссылки, которые относятся к области памяти, где JVM никогда не будет хранить объекты). Всякий раз, когда используется нулевая ссылка, JVM генерирует исключение NullPointerException.
Обратите внимание, что, хотя GC редко обнаруживает утечки памяти в программах Java, они случаются. Мы создадим утечку памяти в конце этой главы.
Следующие GC используются в современных JVM
- Серийный коллектор
- Пропускной коллектор
- CMS коллектор
- Коллектор G1
Каждый из вышеперечисленных алгоритмов выполняет одну и ту же задачу — находит объекты, которые больше не используются, и освобождает память, которую они занимают в куче. Один из наивных подходов к этому — подсчитать количество ссылок, которые есть у каждого объекта, и освободить его, как только число ссылок станет равным 0 (это также называется подсчетом ссылок). Почему это наивно? Рассмотрим круговой связанный список. Каждый из его узлов будет иметь ссылку на него, но на весь объект нигде нет ссылок, и в идеале его следует освободить.
JVM не только освобождает память, но и объединяет небольшие блоки памяти в большие. Это сделано для предотвращения фрагментации памяти.
Проще говоря, типичный алгоритм GC выполняет следующие действия:
- Нахождение неиспользованных предметов
- Освобождая память, которую они занимают в куче
- Объединение фрагментов
GC должен остановить потоки приложения во время его работы. Это потому, что он перемещает объекты во время работы, и, следовательно, эти объекты не могут быть использованы. Такие остановки называются «паузами остановки мира», а минимизация частоты и продолжительности этих пауз — это то, к чему мы стремимся при настройке нашего GC.
Объединение памяти
Простая демонстрация объединения памяти показана ниже
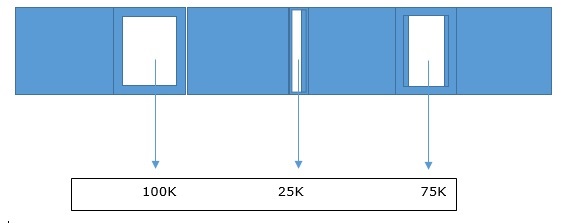
Затененная часть — это объекты, которые необходимо освободить. Даже после того, как все пространство будет освобождено, мы можем выделить только объект с максимальным размером = 75 КБ. Это даже после того, как у нас есть 200 КБ свободного места, как показано ниже

Виртуальная машина Java — GC поколения
Большинство JVM делят кучу на три поколения — молодое поколение (YG), старое поколение (OG) и постоянное поколение (также называемое постоянным поколением) . Каковы причины такого мышления?
Эмпирические исследования показали, что большинство созданных объектов имеют очень короткую продолжительность жизни —
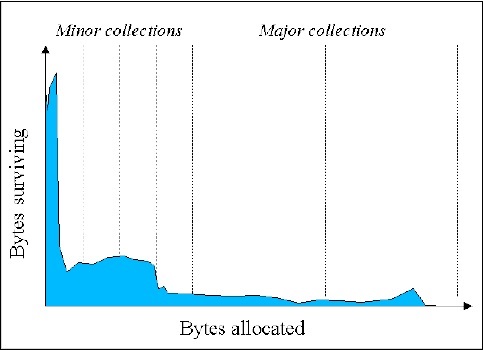
Источник
Как вы можете видеть, чем больше объектов распределяется со временем, тем больше число оставшихся байтов становится меньше (в общем). Java-объекты имеют высокий уровень смертности.
Мы рассмотрим простой пример. Класс String в Java является неизменным. Это означает, что каждый раз, когда вам нужно изменить содержимое объекта String, вы должны создать новый объект в целом. Предположим, вы вносите изменения в строку 1000 раз в цикле, как показано в приведенном ниже коде —
String str = “G11 GC”;
for(int i = 0 ; i < 1000; i++) {
str = str + String.valueOf(i);
}
В каждом цикле мы создаем новый строковый объект, и строка, созданная во время предыдущей итерации, становится бесполезной (то есть на нее не ссылаются никакие ссылки). Время жизни этого объекта составило всего одну итерацию — они будут собраны GC в кратчайшие сроки. Такие недолговечные объекты хранятся в районе кучи молодого поколения. Процесс сбора предметов у молодого поколения называется второстепенной сборкой мусора, и он всегда вызывает паузу «мир-мир».
По мере того, как молодое поколение заполняется, GC выполняет незначительную сборку мусора. Мертвые объекты отбрасываются, а живые объекты переносятся в старое поколение. Потоки приложений останавливаются во время этого процесса.
Здесь мы видим преимущества, которые предлагает дизайн такого поколения. Молодое поколение — лишь малая часть кучи и быстро заполняется. Но обработка занимает намного меньше времени, чем обработка всей кучи. Таким образом, паузы «стоп-мир» в этом случае намного короче, хотя и чаще. Мы всегда должны стремиться к более коротким паузам, чем к более длинным, хотя они могут быть более частыми. Мы обсудим это подробно в следующих разделах этого руководства.
Молодое поколение делится на два пространства — райское и выжившее . Объекты, которые выжили во время сбора рая, перемещаются в пространство выживших, а те, кто выживает в пространстве выживших, переносятся в старое поколение. Молодое поколение уплотняется, пока его собирают.
Когда объекты перемещаются в старое поколение, оно со временем заполняется, и его необходимо собирать и уплотнять. Различные алгоритмы используют разные подходы к этому. Некоторые из них останавливают потоки приложения (что приводит к длительной паузе «остановка мира», поскольку старое поколение довольно велико по сравнению с молодым поколением), в то время как некоторые из них делают это одновременно с продолжением работы потоков приложения. Этот процесс называется полным GC. Два таких коллектора — CMS и G1 .
Давайте теперь проанализируем эти алгоритмы подробно.
Serial GC
это GC по умолчанию на компьютерах клиентского класса (однопроцессорные машины или 32-битная JVM, Windows). Как правило, GC сильно многопоточные, но последовательные GC нет. У него есть один поток для обработки кучи, и он останавливает потоки приложения всякий раз, когда он выполняет вспомогательный или основной сборщик мусора. Мы можем дать команду JVM использовать этот GC, указав флаг: -XX: + UseSerialGC . Если мы хотим использовать другой алгоритм, укажите имя алгоритма. Обратите внимание, что старое поколение полностью уплотняется во время крупного GC.
Пропускная способность GC
Этот GC используется по умолчанию на 64-битных виртуальных машинах и многопроцессорных компьютерах. В отличие от последовательного GC, он использует несколько потоков для обработки молодого и старого поколения. Из-за этого GC также называют параллельным коллектором . Мы можем дать команду нашей JVM использовать этот сборщик, используя флаг: -XX: + UseParallelOldGC или -XX: + UseParallelGC (для JDK 8 и выше). Потоки приложения останавливаются во время основной или вспомогательной сборки мусора. Как и серийный сборщик, он полностью уплотняет молодое поколение во время крупного ГХ.
Пропускная способность GC собирает YG и OG. Когда эден заполнен, коллектор выбрасывает из него живые объекты либо в OG, либо в одно из пространств выживших (SS0 и SS1 на диаграмме ниже). Мертвые объекты отбрасываются, чтобы освободить занимаемое ими пространство.
Перед ГК ЮГ

После GC из YG

Во время полного GC коллектор пропускной способности очищает весь YG, SS0 и SS1. После операции OG содержит только живые объекты. Следует отметить, что оба вышеперечисленных коллектора останавливают потоки приложения при обработке кучи. Это означает длительные паузы «остановленного мира» во время крупного GC. Следующие два алгоритма направлены на их устранение за счет увеличения аппаратных ресурсов —
CMS Collector
Это означает «одновременный разметка». Его функция заключается в том, что он использует некоторые фоновые потоки для периодического сканирования старого поколения и избавляется от мертвых объектов. Но во время небольшого GC потоки приложения останавливаются. Однако паузы довольно маленькие. Это делает CMS сборщиком с низкой паузой.
Этому сборщику требуется дополнительное время ЦП для сканирования кучи во время работы потоков приложения. Кроме того, фоновые потоки просто собирают кучу и не выполняют никакого сжатия. Они могут привести к фрагментации кучи. Поскольку это продолжается, через определенный момент времени CMS остановит все потоки приложения и сожмет кучу, используя один поток. Используйте следующие аргументы JVM, чтобы сообщить JVM об использовании сборщика CMS:
«XX: + UseConcMarkSweepGC -XX: + UseParNewGC» в качестве аргументов JVM, указывающих использовать коллектор CMS.
До GC

После GC

Обратите внимание, что сбор выполняется одновременно.
G1 GC
Этот алгоритм работает путем разделения кучи на несколько областей. Как и коллектор CMS, он останавливает потоки приложения при выполнении вспомогательного GC и использует фоновые потоки для обработки старого поколения, сохраняя при этом потоки приложения. Поскольку оно делит старое поколение на регионы, оно продолжает их уплотнять, перемещая объекты из одного региона в другой. Следовательно, фрагментация минимальна. Вы можете использовать флаг: XX: + UseG1GC, чтобы сообщить вашей JVM об использовании этого алгоритма. Как и CMS, ему также нужно больше процессорного времени для обработки кучи и одновременной работы потоков приложений.
Этот алгоритм был разработан для обработки больших куч (> 4G), которые разделены на несколько различных областей. Некоторые из этих регионов составляют молодое поколение, а остальные — старое. YG очищается с использованием традиционно — все потоки приложения останавливаются и все объекты, которые все еще живы для старого поколения или пространства выживших.
Обратите внимание, что все алгоритмы GC разделяют кучу на YG и OG и используют STWP для очистки YG. Этот процесс обычно очень быстрый.
Виртуальная машина Java — настройка GC
В последней главе мы узнали о различных поколениях Gcs. В этой главе мы обсудим, как настроить GC.
Размер кучи
Размер кучи является важным фактором производительности наших Java-приложений. Если он слишком мал, он будет часто заполняться и, как следствие, GC должен будет часто собирать его. С другой стороны, если мы просто увеличим размер кучи, хотя ее нужно собирать реже, длина пауз увеличится.
Кроме того, увеличение размера кучи имеет серьезные последствия для базовой ОС. Используя подкачку страниц, ОС заставляет наши прикладные программы видеть намного больше памяти, чем фактически доступно. Операционная система управляет этим путем использования некоторого пространства подкачки на диске, копируя в него неактивные части программ. Когда эти части нужны, ОС копирует их обратно с диска в память.
Предположим, что у машины 8 ГБ памяти, а JVM видит 16 ГБ виртуальной памяти, JVM не знает, что на самом деле в системе доступно только 8 ГБ. Он просто запросит 16G у ОС и, как только получит эту память, продолжит ее использовать. Операционная система должна будет обмениваться большим количеством данных, и это является огромным снижением производительности системы.
И затем наступают паузы, которые будут происходить во время полного GC такой виртуальной памяти. Поскольку сборщик мусора и сборщик мусора будут обрабатывать всю кучу, ему придется много ждать, пока виртуальная память будет выгружена с диска. В случае одновременного сборщика фоновые потоки должны будут много ждать, пока данные будут скопированы из пространства подкачки в память.
Таким образом, здесь возникает вопрос о том, как мы должны определить оптимальный размер кучи. Первое правило — никогда не запрашивать у ОС больше памяти, чем есть на самом деле. Это полностью предотвратит проблему частой замены. Если на машине установлено и работает несколько JVM, то общий запрос памяти для всех из них меньше, чем фактический объем ОЗУ в системе.
Вы можете контролировать размер запроса памяти JVM, используя два флага:
-
-XmsN — контролирует начальную запрошенную память.
-
-XmxN — управляет максимальным объемом памяти, который может быть запрошен.
-XmsN — контролирует начальную запрошенную память.
-XmxN — управляет максимальным объемом памяти, который может быть запрошен.
Значения по умолчанию обоих этих флагов зависят от базовой ОС. Например, для 64-битных JVM, работающих на MacOS, -XmsN = 64M и -XmxN = минимум 1G или 1/4 от общей физической памяти.
Обратите внимание, что JVM может автоматически настраиваться между двумя значениями. Например, если он замечает, что происходит слишком много GC, он будет продолжать увеличивать объем памяти, пока он находится ниже -XmxN и желаемые цели производительности достигнуты.
Если вы точно знаете, сколько памяти требуется вашему приложению, вы можете установить -XmsN = -XmxN. В этом случае JVM не нужно вычислять «оптимальное» значение кучи, и, следовательно, процесс GC становится немного более эффективным.
Размеры поколения
Вы можете решить, какую часть кучи вы хотите выделить для YG, и какую часть вы хотите выделить для OG. Оба эти значения влияют на производительность наших приложений следующим образом.
Если размер YG очень большой, то он будет собираться реже. Это приведет к тому, что меньшее количество объектов будет переведено в OG. С другой стороны, если вы слишком сильно увеличите размер OG, то сбор и сжатие займет слишком много времени, и это приведет к длительным паузам STW. Таким образом, пользователь должен найти баланс между этими двумя значениями.
Ниже приведены флаги, которые вы можете использовать для установки этих значений —
-
-XX: NewRatio = N: отношение YG к OG (значение по умолчанию = 2)
-
-XX: NewSize = N: начальный размер YG
-
-XX: MaxNewSize = N: максимальный размер YG
-
-XmnN: установить NewSize и MaxNewSize на одно и то же значение, используя этот флаг
-XX: NewRatio = N: отношение YG к OG (значение по умолчанию = 2)
-XX: NewSize = N: начальный размер YG
-XX: MaxNewSize = N: максимальный размер YG
-XmnN: установить NewSize и MaxNewSize на одно и то же значение, используя этот флаг
Первоначальный размер YG определяется значением NewRatio по заданной формуле —
(общий размер кучи) / (newRatio + 1)
Поскольку начальное значение newRatio равно 2, в приведенной выше формуле начальное значение YG составляет 1/3 от общего размера кучи. Вы всегда можете переопределить это значение, явно указав размер YG с помощью флага NewSize. Этот флаг не имеет никакого значения по умолчанию, и если он не установлен явно, размер YG будет рассчитываться по формуле выше.
Permagen и Metaspace
Permagen и metaspace являются областями кучи, где JVM хранит метаданные классов. Пространство называется «permagen» в Java 7, а в Java 8 оно называется «metaspace». Эта информация используется компилятором и средой выполнения.
Вы можете контролировать размер пермагена, используя следующие флаги: -XX: PermSize = N и -XX: MaxPermSize = N. Размер Metaspace можно контролировать с помощью: -XX: Metaspace- Size = N и -XX: MaxMetaspaceSize = N.
Существуют некоторые различия в управлении permagen и metaspace, когда значения флага не установлены. По умолчанию оба имеют начальный размер по умолчанию. Но хотя метапространство может занимать столько кучи, сколько необходимо, permagen может занимать не более начальных значений по умолчанию. Например, 64-битная виртуальная машина Java имеет 82M пространства кучи в качестве максимального размера пермагена.
Обратите внимание, что, поскольку метапространство может занимать неограниченное количество памяти, если не указано иное, может быть ошибка нехватки памяти. Полный GC происходит всякий раз, когда размеры этих регионов изменяются. Следовательно, во время запуска, если загружается много классов, метапространство может продолжать изменять размер, каждый раз получая полный GC. Таким образом, запуск больших приложений занимает много времени в случае, если начальный размер метапространства слишком мал. Хорошей идеей является увеличение начального размера, так как это сокращает время запуска.
Хотя permagen и metaspace содержат метаданные класса, они не являются постоянными, и пространство восстанавливается GC, как в случае объектов. Это обычно в случае серверных приложений. Всякий раз, когда вы делаете новое развертывание на сервере, старые метаданные должны быть очищены, так как новым загрузчикам классов теперь потребуется место. Это пространство освобождается GC.
Виртуальная машина Java — утечка памяти в Java
Мы обсудим концепцию утечки памяти в Java в этой главе.
Следующий код создает утечку памяти в Java —
void queryDB() { try{ Connection conn = ConnectionFactory.getConnection(); PreparedStatement ps = conn.preparedStatement("query"); // executes a SQL ResultSet rs = ps.executeQuery(); while(rs.hasNext()) { //process the record } } catch(SQLException sqlEx) { //print stack trace } }
В приведенном выше коде при выходе из метода мы не закрыли объект подключения. Таким образом, физическое соединение остается открытым до запуска GC и видит объект соединения как недостижимый. Теперь он вызовет последний метод для объекта подключения, однако он может быть не реализован. Следовательно, объект не будет мусором в этом цикле.
То же самое будет происходить в следующем, пока удаленный сервер не увидит, что соединение было открыто в течение длительного времени, и принудительно прервет его. Таким образом, объект без ссылки остается в памяти в течение длительного времени, что создает утечку.