В предыдущей главе вы узнали, как создавать таблицы в Tajo. В этой главе рассказывается об операторе SQL в Tajo.
Создать таблицу Заявление
Прежде чем перейти к созданию таблицы, создайте текстовый файл «Students.csv» в пути к каталогу установки Tajo следующим образом:
students.csv
| Я бы | название | Адрес | Возраст | Метки |
|---|---|---|---|---|
| 1 | Адам | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Старая улица | 13 | 95 |
| 3 | боб | 10 Cross Street | 12 | 80 |
| 4 | Дэвид | 15 Экспресс Авеню | 12 | 85 |
| 5 | Эша | 20 Garden Street | 13 | 50 |
| 6 | Ганга | 25 Северная улица | 12 | 55 |
| 7 | Джек | 2 Park Street | 12 | 60 |
| 8 | Лииной | 24 Южная улица | 12 | 70 |
| 9 | Мэри | 5 Вест Стрит | 12 | 75 |
| 10 | Питер | 16 Парк Авеню | 12 | 95 |
После того, как файл был создан, перейдите к терминалу и запустите сервер Tajo и оболочку один за другим.
Создать базу данных
Создайте новую базу данных, используя следующую команду —
запрос
default> create database sampledb; OK
Подключитесь к базе данных «sampledb», которая сейчас создается.
default> \c sampledb You are now connected to database "sampledb" as user “user1”.
Затем создайте таблицу в «sampledb» следующим образом:
запрос
sampledb> create external table mytable(id int,name text,address text,age int,mark int) using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;
Результат
Приведенный выше запрос приведет к следующему результату.
OK
Здесь создается внешняя таблица. Теперь вам просто нужно указать местоположение файла. Если вам нужно назначить таблицу из hdfs, используйте hdfs вместо файла.
Затем файл «student.csv» содержит значения, разделенные запятыми. Поле text.delimiter назначается с помощью ‘,’.
Вы успешно создали «mytable» в «sampledb».
Показать таблицу
Чтобы показать таблицы в Tajo, используйте следующий запрос.
запрос
sampledb> \d mytable sampledb> \d mytable
Результат
Приведенный выше запрос приведет к следующему результату.
table name: sampledb.mytable table uri: file:/Users/workspace/Tajo/students.csv store type: TEXT number of rows: unknown volume: 261 B Options: 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'text.delimiter' = ',' schema: id INT4 name TEXT address TEXT age INT4 mark INT4
Список таблиц
Чтобы получить все записи в таблице, введите следующий запрос —
запрос
sampledb> select * from mytable;
Результат
Приведенный выше запрос приведет к следующему результату.
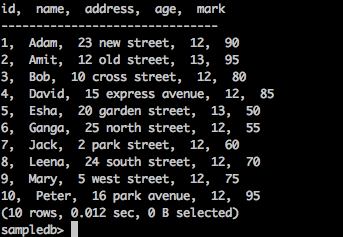
Вставить таблицу
Тахо использует следующий синтаксис для вставки записей в таблицу.
Синтаксис
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;
Оператор вставки Тахо похож на оператор INSERT INTO SELECT в SQL.
запрос
Давайте создадим таблицу для перезаписи данных таблицы существующей таблицы.
sampledb> create table test(sno int,name text,addr text,age int,mark int); OK sampledb> \d
Результат
Приведенный выше запрос приведет к следующему результату.
mytable test
Вставить записи
Чтобы вставить записи в «тестовую» таблицу, введите следующий запрос.
запрос
sampledb> insert overwrite into test select * from mytable;
Результат
Приведенный выше запрос приведет к следующему результату.
Progress: 100%, response time: 0.518 sec
Здесь записи «mytable» перезаписывают таблицу «test». Если вы не хотите создавать таблицу «test», сразу же назначьте физический путь, как указано в альтернативной опции для запроса вставки.
Получить записи
Используйте следующий запрос, чтобы перечислить все записи в «тестовой» таблице:
запрос
sampledb> select * from test;
Результат
Приведенный выше запрос приведет к следующему результату.
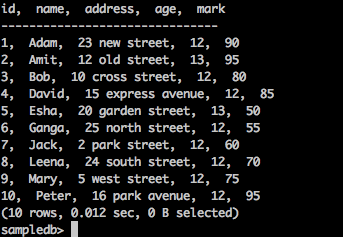
Этот оператор используется для добавления, удаления или изменения столбцов существующей таблицы.
Чтобы переименовать таблицу, используйте следующий синтаксис —
Alter table table1 RENAME TO table2;
запрос
sampledb> alter table test rename to students;
Результат
Приведенный выше запрос приведет к следующему результату.
OK
Чтобы проверить измененное имя таблицы, используйте следующий запрос.
sampledb> \d mytable students
Теперь таблица «тест» заменена на таблицу «студенты».
Добавить столбец
Чтобы вставить новый столбец в таблицу «студентов», введите следующий синтаксис —
Alter table <table_name> ADD COLUMN <column_name> <data_type>
запрос
sampledb> alter table students add column grade text;
Результат
Приведенный выше запрос приведет к следующему результату.
OK
Установить свойство
Это свойство используется для изменения свойства таблицы.
запрос
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD', 'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ; OK
Здесь назначаются тип сжатия и свойства кодека.
Чтобы изменить свойство текстового разделителя, используйте следующее —
запрос
ALTER TABLE students SET PROPERTY ‘text.delimiter'=','; OK
Результат
Приведенный выше запрос приведет к следующему результату.
sampledb> \d students table name: sampledb.students table uri: file:/tmp/tajo-user1/warehouse/sampledb/students store type: TEXT number of rows: 10 volume: 228 B Options: 'compression.type' = 'RECORD' 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec' 'text.delimiter' = ',' schema: id INT4 name TEXT addr TEXT age INT4 mark INT4 grade TEXT
Приведенный выше результат показывает, что свойства таблицы изменяются с помощью свойства «SET».
Выберите заявление
Оператор SELECT используется для выбора данных из базы данных.
Синтаксис для оператора Select следующий:
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...] [FROM <table reference> [[AS] <table alias name>] [, ...]] [WHERE <condition>] [GROUP BY <expression> [, ...]] [HAVING <condition>] [ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]
Где пункт
Предложение Where используется для фильтрации записей из таблицы.
запрос
sampledb> select * from mytable where id > 5;
Результат
Приведенный выше запрос приведет к следующему результату.
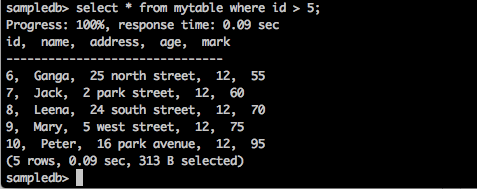
Запрос возвращает записи тех студентов, чей идентификатор больше 5.
запрос
sampledb> select * from mytable where name = ‘Peter’;
Результат
Приведенный выше запрос приведет к следующему результату.
Progress: 100%, response time: 0.117 sec id, name, address, age ------------------------------- 10, Peter, 16 park avenue , 12
Результат фильтрует только записи Питера.
Отличительная оговорка
Столбец таблицы может содержать повторяющиеся значения. Ключевое слово DISTINCT может использоваться для возврата только различных (разных) значений.
Синтаксис
SELECT DISTINCT column1,column2 FROM table_name;
запрос
sampledb> select distinct age from mytable;
Результат
Приведенный выше запрос приведет к следующему результату.
Progress: 100%, response time: 0.216 sec age ------------------------------- 13 12
Запрос возвращает отчетливый возраст студентов из mytable .
Группа по пункту
Предложение GROUP BY используется в сотрудничестве с оператором SELECT для объединения идентичных данных в группы.
Синтаксис
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;
запрос
select age,sum(mark) as sumofmarks from mytable group by age;
Результат
Приведенный выше запрос приведет к следующему результату.
age, sumofmarks ------------------------------- 13, 145 12, 610
Здесь столбец «mytable» имеет два типа возрастов — 12 и 13. Теперь запрос группирует записи по возрасту и выдает сумму оценок для соответствующих возрастов учащихся.
Имея пункт
Предложение HAVING позволяет указать условия, которые фильтруют, какие групповые результаты появляются в окончательных результатах. Предложение WHERE помещает условия в выбранные столбцы, тогда как предложение HAVING помещает условия в группы, созданные предложением GROUP BY.
Синтаксис
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]
запрос
sampledb> select age from mytable group by age having sum(mark) > 200;
Результат
Приведенный выше запрос приведет к следующему результату.
age ------------------------------- 12
Запрос группирует записи по возрасту и возвращает возраст, когда сумма результата условия (отметка)> 200.
Заказать по пункту
Предложение ORDER BY используется для сортировки данных в порядке возрастания или убывания на основе одного или нескольких столбцов. По умолчанию база данных Tajo сортирует результаты запроса в порядке возрастания.
Синтаксис
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
запрос
sampledb> select * from mytable where mark > 60 order by name desc;
Результат
Приведенный выше запрос приведет к следующему результату.
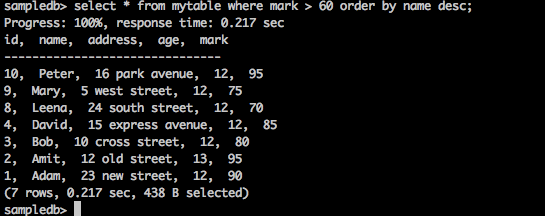
Запрос возвращает имена тех учеников в порядке убывания, оценки которых превышают 60.
Создать указатель
Оператор CREATE INDEX используется для создания индексов в таблицах. Индекс используется для быстрого поиска данных. Текущая версия поддерживает индекс только для простых текстовых форматов, хранящихся в HDFS.
Синтаксис
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }
запрос
create index student_index on mytable(id);
Результат
Приведенный выше запрос приведет к следующему результату.
id ———————————————
Чтобы просмотреть назначенный индекс для столбца, введите следующий запрос.
default> \d mytable table name: default.mytable table uri: file:/Users/deiva/workspace/Tajo/students.csv store type: TEXT number of rows: unknown volume: 307 B Options: 'timezone' = 'Asia/Kolkata' 'text.null' = '\\N' 'text.delimiter' = ',' schema: id INT4 name TEXT address TEXT age INT4 mark INT4 Indexes: "student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )
Здесь метод TWO_LEVEL_BIN_TREE используется по умолчанию в Тахо.
Выписка со стола
Оператор удаления таблицы используется для удаления таблицы из базы данных.
Синтаксис
drop table table name;
запрос
sampledb> drop table mytable;
Чтобы проверить, была ли таблица удалена из таблицы, введите следующий запрос.
sampledb> \d mytable;
Результат
Приведенный выше запрос приведет к следующему результату.
ERROR: relation 'mytable' does not exist
Вы также можете проверить запрос с помощью команды «\ d», чтобы вывести список доступных таблиц Tajo.