Zookeeper — Обзор
ZooKeeper — это распределенный сервис координации для управления большим количеством хостов. Координация и управление сервисом в распределенной среде — сложный процесс. ZooKeeper решает эту проблему благодаря своей простой архитектуре и API. ZooKeeper позволяет разработчикам сосредоточиться на основной логике приложения, не беспокоясь о распределенной природе приложения.
Фреймворк ZooKeeper изначально был создан в «Yahoo!» для простого и надежного доступа к их приложениям. Позже Apache ZooKeeper стал стандартом для организованного сервиса, используемого Hadoop, HBase и другими распределенными средами. Например, Apache HBase использует ZooKeeper для отслеживания состояния распределенных данных.
Прежде чем двигаться дальше, важно, чтобы мы знали кое-что о распределенных приложениях. Итак, давайте начнем обсуждение с краткого обзора распределенных приложений.
Распределенное приложение
Распределенное приложение может работать в нескольких системах в сети в одно и то же время (одновременно), координируя свои действия для быстрого и эффективного выполнения определенной задачи. Как правило, сложные и трудоемкие задачи, которые могут выполняться часами нераспределенным приложением (работающим в одной системе), могут быть выполнены за несколько минут распределенным приложением с использованием вычислительных возможностей всей задействованной системы.
Время выполнения задачи может быть дополнительно сокращено путем настройки распределенного приложения для работы в большем количестве систем. Группа систем, в которой работает распределенное приложение, называется кластером, а каждая машина, работающая в кластере, называется узлом .
Распределенное приложение состоит из двух частей: серверного и клиентского приложения. Серверные приложения фактически распределены и имеют общий интерфейс, так что клиенты могут подключаться к любому серверу в кластере и получать тот же результат. Клиентские приложения — это инструменты для взаимодействия с распределенным приложением.
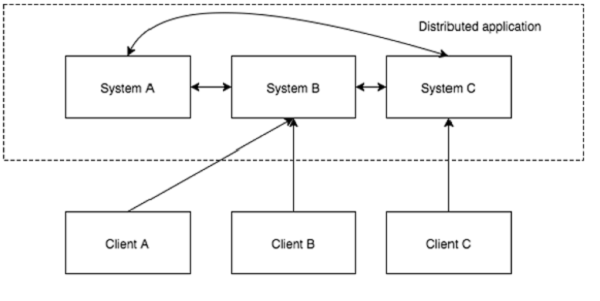
Преимущества распределенных приложений
-
Надежность. Отказ одной или нескольких систем не приводит к отказу всей системы.
-
Масштабируемость. Производительность можно увеличивать по мере необходимости, добавляя больше компьютеров с незначительными изменениями в конфигурации приложения без простоев.
-
Прозрачность — скрывает сложность системы и показывает себя как единое целое / приложение.
Надежность. Отказ одной или нескольких систем не приводит к отказу всей системы.
Масштабируемость. Производительность можно увеличивать по мере необходимости, добавляя больше компьютеров с незначительными изменениями в конфигурации приложения без простоев.
Прозрачность — скрывает сложность системы и показывает себя как единое целое / приложение.
Проблемы распределенных приложений
-
Состояние гонки — две или более машины пытаются выполнить определенную задачу, которая фактически должна выполняться только одной машиной в любой момент времени. Например, общие ресурсы должны быть изменены только одной машиной в любой момент времени.
-
Тупик — две или более операций, ожидающих друг друга до бесконечности.
-
Несоответствие — Частичный сбой данных.
Состояние гонки — две или более машины пытаются выполнить определенную задачу, которая фактически должна выполняться только одной машиной в любой момент времени. Например, общие ресурсы должны быть изменены только одной машиной в любой момент времени.
Тупик — две или более операций, ожидающих друг друга до бесконечности.
Несоответствие — Частичный сбой данных.
Для чего нужен Apache ZooKeeper?
Apache ZooKeeper — это сервис, используемый кластером (группой узлов) для координации между собой и поддержки общих данных с помощью надежных методов синхронизации. ZooKeeper сам по себе является распределенным приложением, предоставляющим сервисы для написания распределенного приложения.
Общие услуги, предоставляемые ZooKeeper, следующие:
-
Служба именования — идентификация узлов в кластере по имени. Это похоже на DNS, но для узлов.
-
Управление конфигурацией — самая свежая и актуальная информация о конфигурации системы для присоединяющегося узла.
-
Управление кластером — присоединение / выход узла в кластере и статус узла в режиме реального времени.
-
Выбор лидера — Выбор узла в качестве лидера для целей координации.
-
Служба блокировки и синхронизации — блокировка данных при их изменении. Этот механизм помогает вам в автоматическом восстановлении после сбоя при подключении других распределенных приложений, таких как Apache HBase.
-
Высоконадежный реестр данных — доступность данных, даже когда один или несколько узлов не работают.
Служба именования — идентификация узлов в кластере по имени. Это похоже на DNS, но для узлов.
Управление конфигурацией — самая свежая и актуальная информация о конфигурации системы для присоединяющегося узла.
Управление кластером — присоединение / выход узла в кластере и статус узла в режиме реального времени.
Выбор лидера — Выбор узла в качестве лидера для целей координации.
Служба блокировки и синхронизации — блокировка данных при их изменении. Этот механизм помогает вам в автоматическом восстановлении после сбоя при подключении других распределенных приложений, таких как Apache HBase.
Высоконадежный реестр данных — доступность данных, даже когда один или несколько узлов не работают.
Распределенные приложения предлагают много преимуществ, но они также бросают несколько сложных и сложных задач. Платформа ZooKeeper предоставляет полный механизм для преодоления всех проблем. Состояние гонки и взаимоблокировка обрабатываются с использованием подхода безопасной синхронизации . Другим главным недостатком является несогласованность данных, которую ZooKeeper решает с атомарностью .
Преимущества ZooKeeper
Вот преимущества использования ZooKeeper —
-
Простой распределенный процесс координации
-
Синхронизация — взаимное исключение и взаимодействие между процессами сервера. Этот процесс помогает в Apache HBase для управления конфигурацией.
-
Заказанные сообщения
-
Сериализация — кодирование данных в соответствии с определенными правилами. Убедитесь, что ваше приложение работает последовательно. Этот подход можно использовать в MapReduce для координации очереди для выполнения запущенных потоков.
-
надежность
-
Атомарность. Передача данных либо завершается успешно, либо завершается неудачей полностью, но никакая транзакция не является частичной
Простой распределенный процесс координации
Синхронизация — взаимное исключение и взаимодействие между процессами сервера. Этот процесс помогает в Apache HBase для управления конфигурацией.
Заказанные сообщения
Сериализация — кодирование данных в соответствии с определенными правилами. Убедитесь, что ваше приложение работает последовательно. Этот подход можно использовать в MapReduce для координации очереди для выполнения запущенных потоков.
надежность
Атомарность. Передача данных либо завершается успешно, либо завершается неудачей полностью, но никакая транзакция не является частичной
Zookeeper — Основы
Прежде чем углубляться в работу ZooKeeper, давайте взглянем на фундаментальные концепции ZooKeeper. Мы обсудим следующие темы в этой главе —
- Архитектура
- Иерархическое пространство имен
- сессия
- Часы
Архитектура ZooKeeper
Посмотрите на следующую диаграмму. Он изображает «клиент-серверную архитектуру» ZooKeeper.
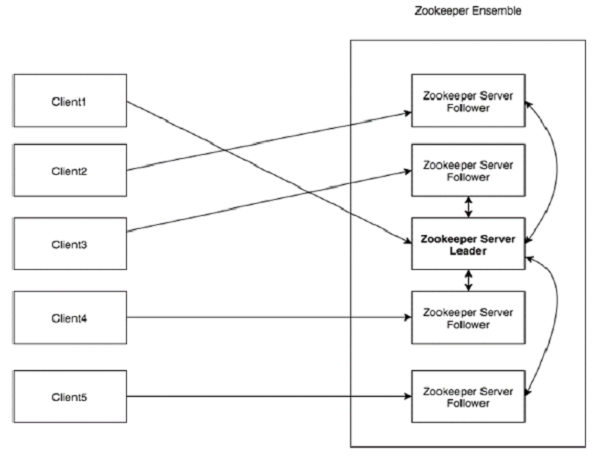
Каждый из компонентов, являющихся частью архитектуры ZooKeeper, описан в следующей таблице.
| Часть | Описание |
|---|---|
| клиент |
Клиенты, один из узлов нашего распределенного кластера приложений, получают доступ к информации с сервера. В течение определенного промежутка времени каждый клиент отправляет сообщение на сервер, чтобы сервер знал, что клиент жив. Точно так же сервер отправляет подтверждение, когда клиент соединяется. Если нет ответа от подключенного сервера, клиент автоматически перенаправляет сообщение на другой сервер. |
| сервер | Сервер, один из узлов нашего ансамбля ZooKeeper, предоставляет все услуги клиентам. Дает подтверждение клиенту, чтобы сообщить, что сервер жив. |
| Ансамбль | Группа серверов ZooKeeper. Минимальное количество узлов, необходимое для формирования ансамбля, составляет 3. |
| лидер | Узел сервера, который выполняет автоматическое восстановление в случае сбоя любого из подключенных узлов. Лидеры избираются при запуске сервиса. |
| толкатель | Серверный узел, который следует инструкции лидера. |
Клиенты, один из узлов нашего распределенного кластера приложений, получают доступ к информации с сервера. В течение определенного промежутка времени каждый клиент отправляет сообщение на сервер, чтобы сервер знал, что клиент жив.
Точно так же сервер отправляет подтверждение, когда клиент соединяется. Если нет ответа от подключенного сервера, клиент автоматически перенаправляет сообщение на другой сервер.
Иерархическое пространство имен
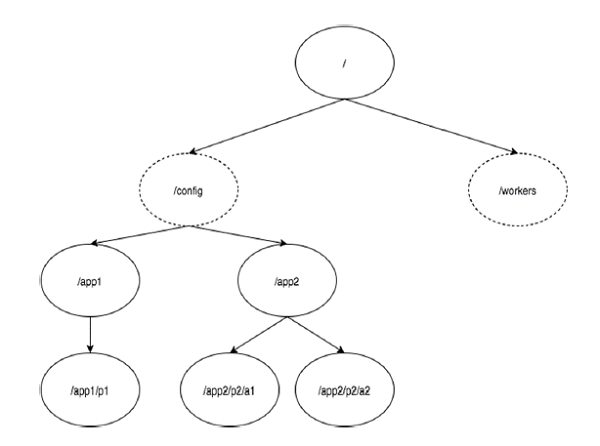
Следующая диаграмма изображает древовидную структуру файловой системы ZooKeeper, используемой для представления памяти. Узел ZooKeeper называется znode . Каждый znode идентифицируется по имени и разделяется последовательностью пути (/).
-
На диаграмме сначала у вас есть корневой узел, разделенный символом «/». Под root у вас есть два логических пространства имен config и рабочие .
-
Пространство имен config используется для централизованного управления конфигурацией, а пространство имен рабочих используется для именования.
-
В пространстве имен config каждый znode может хранить до 1 МБ данных. Это похоже на файловую систему UNIX за исключением того, что родительский znode также может хранить данные. Основное назначение этой структуры — хранить синхронизированные данные и описывать метаданные znode. Эта структура называется моделью данных ZooKeeper .
На диаграмме сначала у вас есть корневой узел, разделенный символом «/». Под root у вас есть два логических пространства имен config и рабочие .
Пространство имен config используется для централизованного управления конфигурацией, а пространство имен рабочих используется для именования.
В пространстве имен config каждый znode может хранить до 1 МБ данных. Это похоже на файловую систему UNIX за исключением того, что родительский znode также может хранить данные. Основное назначение этой структуры — хранить синхронизированные данные и описывать метаданные znode. Эта структура называется моделью данных ZooKeeper .
Каждый узел в модели данных ZooKeeper поддерживает структуру статистики . Статистика просто предоставляет метаданные znode. Он состоит из номера версии, списка управления действиями (ACL), отметки времени и длины данных.
-
Номер версии — у каждого znode есть номер версии, что означает, что каждый раз, когда данные, связанные с znode, изменяются, его соответствующий номер версии также увеличивается. Использование номера версии важно, когда несколько клиентов zookeeper пытаются выполнить операции на одном и том же znode.
-
Список управления действиями (ACL) — ACL — это механизм аутентификации для доступа к znode. Он управляет всеми операциями чтения и записи znode.
-
Timestamp — Timestamp представляет время, прошедшее с момента создания и модификации znode. Обычно он представлен в миллисекундах. ZooKeeper идентифицирует каждое изменение в znodes из «ID транзакции» (zxid). Zxid уникален и поддерживает время для каждой транзакции, так что вы можете легко определить время, прошедшее от одного запроса к другому.
-
Длина данных — общий объем данных, хранящихся в znode, является длиной данных. Вы можете хранить максимум 1 МБ данных.
Номер версии — у каждого znode есть номер версии, что означает, что каждый раз, когда данные, связанные с znode, изменяются, его соответствующий номер версии также увеличивается. Использование номера версии важно, когда несколько клиентов zookeeper пытаются выполнить операции на одном и том же znode.
Список управления действиями (ACL) — ACL — это механизм аутентификации для доступа к znode. Он управляет всеми операциями чтения и записи znode.
Timestamp — Timestamp представляет время, прошедшее с момента создания и модификации znode. Обычно он представлен в миллисекундах. ZooKeeper идентифицирует каждое изменение в znodes из «ID транзакции» (zxid). Zxid уникален и поддерживает время для каждой транзакции, так что вы можете легко определить время, прошедшее от одного запроса к другому.
Длина данных — общий объем данных, хранящихся в znode, является длиной данных. Вы можете хранить максимум 1 МБ данных.
Типы Знодес
Znodes подразделяются на постоянство, последовательность и эфемерность.
-
Постоянство znode — Постоянство znode живо даже после того, как клиент, который создал этот конкретный znode, был отключен. По умолчанию все узлы являются постоянными, если не указано иное.
-
Ephemeral znode — эфемерные znode активны, пока клиент не жив. Когда клиент отключается от ансамбля ZooKeeper, тогда эфемерные узлы удаляются автоматически. По этой причине только эфемерные узлы не могут иметь детей дальше. Если эфемерный znode удален, то следующий подходящий узел займет свою позицию. Эфемерные зводы играют важную роль в выборах лидера.
-
Последовательный узел — Последовательный узел может быть постоянным или эфемерным. Когда новый znode создается как последовательный znode, ZooKeeper устанавливает путь znode, прикрепляя 10-значный порядковый номер к исходному имени. Например, если znode с путем / myapp создается как последовательный znode, ZooKeeper изменит путь на / myapp0000000001 и установит следующий порядковый номер как 0000000002. Если два последовательных znode создаются одновременно, то ZooKeeper никогда не использует один и тот же номер для каждый зноде. Последовательные узлы играют важную роль в блокировке и синхронизации.
Постоянство znode — Постоянство znode живо даже после того, как клиент, который создал этот конкретный znode, был отключен. По умолчанию все узлы являются постоянными, если не указано иное.
Ephemeral znode — эфемерные znode активны, пока клиент не жив. Когда клиент отключается от ансамбля ZooKeeper, тогда эфемерные узлы удаляются автоматически. По этой причине только эфемерные узлы не могут иметь детей дальше. Если эфемерный znode удален, то следующий подходящий узел займет свою позицию. Эфемерные зводы играют важную роль в выборах лидера.
Последовательный узел — Последовательный узел может быть постоянным или эфемерным. Когда новый znode создается как последовательный znode, ZooKeeper устанавливает путь znode, прикрепляя 10-значный порядковый номер к исходному имени. Например, если znode с путем / myapp создается как последовательный znode, ZooKeeper изменит путь на / myapp0000000001 и установит следующий порядковый номер как 0000000002. Если два последовательных znode создаются одновременно, то ZooKeeper никогда не использует один и тот же номер для каждый зноде. Последовательные узлы играют важную роль в блокировке и синхронизации.
сессии
Сессии очень важны для работы ZooKeeper. Запросы в сеансе выполняются в порядке FIFO. Как только клиент подключится к серверу, сеанс будет установлен, и клиенту будет назначен идентификатор сеанса .
Клиент отправляет тактовые импульсы через определенный промежуток времени, чтобы поддерживать сеанс в силе. Если ансамбль ZooKeeper не получает тактовые импульсы от клиента в течение периода, превышающего период (время ожидания сеанса), указанный при запуске службы, он решает, что клиент умер.
Тайм-ауты сессии обычно представлены в миллисекундах. Когда сеанс заканчивается по какой-либо причине, эфемерные узлы, созданные во время этого сеанса, также удаляются.
Часы
Часы — это простой механизм, позволяющий клиенту получать уведомления об изменениях в ансамбле ZooKeeper. Клиенты могут устанавливать часы при чтении определенного узла. Наблюдатели отправляют уведомление зарегистрированному клиенту для любого изменения znode (на котором клиент регистрируется).
Изменения Znode — это изменение данных, связанных с Znode, или изменения в дочерних узлах Znode. Часы срабатывают только один раз. Если клиент снова хочет получить уведомление, его необходимо выполнить с помощью другой операции чтения. Когда сеанс соединения истекает, клиент будет отключен от сервера, и связанные наблюдения также будут удалены.
Zookeeper — Рабочий процесс
После запуска ансамбля ZooKeeper он будет ожидать подключения клиентов. Клиенты будут подключаться к одному из узлов в ансамбле ZooKeeper. Это может быть лидер или последователь узла. Как только клиент подключен, узел назначает идентификатор сеанса конкретному клиенту и отправляет подтверждение клиенту. Если клиент не получает подтверждение, он просто пытается подключиться к другому узлу в ансамбле ZooKeeper. После подключения к узлу клиент будет регулярно отправлять тактовые импульсы на узел, чтобы убедиться, что соединение не потеряно.
-
Если клиент хочет прочитать определенный znode, он отправляет запрос на чтение узлу с путем znode, и узел возвращает запрошенный znode, получая его из своей собственной базы данных. По этой причине чтение происходит быстро в ансамбле ZooKeeper.
-
Если клиент хочет сохранить данные в ансамбле ZooKeeper , он отправляет путь znode и данные на сервер. Подключенный сервер перенаправит запрос лидеру, а затем лидер повторно отправит запрос на запись всем подписчикам. Если только большинство узлов ответят успешно, запрос на запись будет выполнен успешно, и успешный код возврата будет отправлен клиенту. В противном случае запрос на запись не будет выполнен. Строгое большинство узлов называется Кворумом .
Если клиент хочет прочитать определенный znode, он отправляет запрос на чтение узлу с путем znode, и узел возвращает запрошенный znode, получая его из своей собственной базы данных. По этой причине чтение происходит быстро в ансамбле ZooKeeper.
Если клиент хочет сохранить данные в ансамбле ZooKeeper , он отправляет путь znode и данные на сервер. Подключенный сервер перенаправит запрос лидеру, а затем лидер повторно отправит запрос на запись всем подписчикам. Если только большинство узлов ответят успешно, запрос на запись будет выполнен успешно, и успешный код возврата будет отправлен клиенту. В противном случае запрос на запись не будет выполнен. Строгое большинство узлов называется Кворумом .
Узлы в ансамбле ZooKeeper
Давайте проанализируем эффект наличия разного количества узлов в ансамбле ZooKeeper.
-
Если у нас есть один узел , то ансамбль ZooKeeper дает сбой при сбое этого узла. Это способствует «единой точке отказа» и не рекомендуется в производственной среде.
-
Если у нас есть два узла и один узел выходит из строя, у нас также нет большинства, так как один из двух не является большинством.
-
Если у нас есть три узла и один узел выходит из строя, у нас есть большинство и так, это минимальное требование. Для ансамбля ZooKeeper обязательно иметь как минимум три узла в рабочей среде.
-
Если у нас четыре узла и два узла вышли из строя, он снова выходит из строя, и это похоже на наличие трех узлов. Дополнительный узел не служит какой-либо цели, поэтому лучше добавлять узлы в нечетные числа, например, 3, 5, 7.
Если у нас есть один узел , то ансамбль ZooKeeper дает сбой при сбое этого узла. Это способствует «единой точке отказа» и не рекомендуется в производственной среде.
Если у нас есть два узла и один узел выходит из строя, у нас также нет большинства, так как один из двух не является большинством.
Если у нас есть три узла и один узел выходит из строя, у нас есть большинство и так, это минимальное требование. Для ансамбля ZooKeeper обязательно иметь как минимум три узла в рабочей среде.
Если у нас четыре узла и два узла вышли из строя, он снова выходит из строя, и это похоже на наличие трех узлов. Дополнительный узел не служит какой-либо цели, поэтому лучше добавлять узлы в нечетные числа, например, 3, 5, 7.
Мы знаем, что процесс записи стоит дороже, чем процесс чтения в ансамбле ZooKeeper, поскольку все узлы должны записывать одни и те же данные в свою базу данных. Таким образом, лучше иметь меньшее количество узлов (3, 5 или 7), чем большое количество узлов для сбалансированной среды.
На следующей диаграмме изображен ZooKeeper WorkFlow, а в следующей таблице поясняются его различные компоненты.
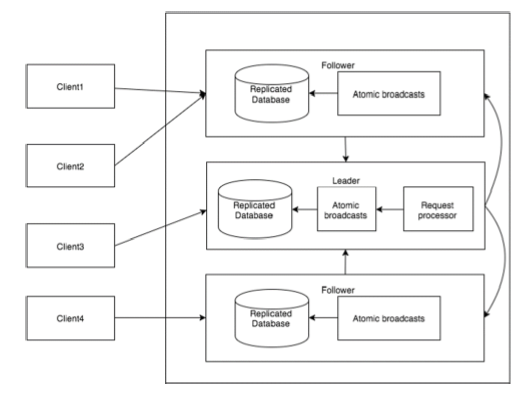
| Составная часть | Описание |
|---|---|
| Написать | Процесс записи обрабатывается ведущим узлом. Руководитель направляет запрос на запись всем узлам и ждет ответов от узлов. Если ответит половина узлов, процесс записи завершен. |
| Читать | Чтения выполняются внутри определенного подключенного узла, поэтому нет необходимости взаимодействовать с кластером. |
| Реплицированная база данных | Используется для хранения данных в zookeeper. Каждый znode имеет свою собственную базу данных, и каждый znode каждый раз имеет одни и те же данные с помощью согласованности. |
| лидер | Лидер — это Znode, который отвечает за обработку запросов на запись. |
| толкатель | Последователи получают запросы на запись от клиентов и отправляют их руководителю znode. |
| Обработчик запросов | Присутствует только в ведущем узле. Он управляет запросами на запись от узла-подписчика. |
| Атомные трансляции | Отвечает за передачу изменений от узла-лидера на узлы-последователи. |
Zookeeper — Лидер Выборы
Давайте проанализируем, как лидерный узел может быть выбран в ансамбле ZooKeeper. Учтите, что в кластере N узлов. Процесс выбора лидера выглядит следующим образом —
-
Все узлы создают последовательный, эфемерный znode с одинаковым путем, / app / leader_election / guid_ .
-
Ансамбль ZooKeeper добавит к пути 10-значный порядковый номер, а созданный znode будет / app / leader_election / guid_0000000001, / app / leader_election / guid_0000000002 и т. Д.
-
Для данного экземпляра узел, который создает наименьшее число в znode, становится лидером, а все остальные узлы являются последователями.
-
Каждый следящий узел наблюдает за узлом, имеющим следующий наименьший номер. Например, узел, который создает znode / app / leader_election / guid_0000000008, будет наблюдать за znode / app / leader_election / guid_0000000007, а узел, который создает znode / app / leader_election / guid_0000000007, будет смотреть znode / app / leader_election / guid_000000000.
-
Если лидер отключается, то соответствующий ему znode / app / leader_electionN удаляется.
-
Следующий в очереди следящий узел получит уведомление от наблюдателя об удалении лидера.
-
Следующий в строке следящий узел проверит, есть ли другие узлы с наименьшим номером. Если нет, то он возьмет на себя роль лидера. В противном случае он находит узел, который создал znode с наименьшим номером в качестве лидера.
-
Точно так же все другие узлы-последователи выбирают узел, который создал znode с наименьшим числом в качестве лидера.
Все узлы создают последовательный, эфемерный znode с одинаковым путем, / app / leader_election / guid_ .
Ансамбль ZooKeeper добавит к пути 10-значный порядковый номер, а созданный znode будет / app / leader_election / guid_0000000001, / app / leader_election / guid_0000000002 и т. Д.
Для данного экземпляра узел, который создает наименьшее число в znode, становится лидером, а все остальные узлы являются последователями.
Каждый следящий узел наблюдает за узлом, имеющим следующий наименьший номер. Например, узел, который создает znode / app / leader_election / guid_0000000008, будет наблюдать за znode / app / leader_election / guid_0000000007, а узел, который создает znode / app / leader_election / guid_0000000007, будет смотреть znode / app / leader_election / guid_000000000.
Если лидер отключается, то соответствующий ему znode / app / leader_electionN удаляется.
Следующий в очереди следящий узел получит уведомление от наблюдателя об удалении лидера.
Следующий в строке следящий узел проверит, есть ли другие узлы с наименьшим номером. Если нет, то он возьмет на себя роль лидера. В противном случае он находит узел, который создал znode с наименьшим номером в качестве лидера.
Точно так же все другие узлы-последователи выбирают узел, который создал znode с наименьшим числом в качестве лидера.
Выбор лидера — это сложный процесс, когда он делается с нуля. Но сервис ZooKeeper делает это очень просто. Давайте перейдем к установке ZooKeeper для целей разработки в следующей главе.
Zookeeper — Установка
Перед установкой ZooKeeper убедитесь, что ваша система работает в любой из следующих операционных систем:
-
Любая из ОС Linux — поддерживает разработку и развертывание. Это предпочтительно для демонстрационных приложений.
-
ОС Windows — поддерживает только разработку.
-
Mac OS — поддерживает только разработку.
Любая из ОС Linux — поддерживает разработку и развертывание. Это предпочтительно для демонстрационных приложений.
ОС Windows — поддерживает только разработку.
Mac OS — поддерживает только разработку.
Сервер ZooKeeper создан на Java и работает на JVM. Вам нужно использовать JDK 6 или выше.
Теперь, следуйте инструкциям ниже, чтобы установить ZooKeeper Framework на свой компьютер.
Шаг 1. Проверка установки Java
Мы считаем, что в вашей системе уже установлена среда Java. Просто проверьте это с помощью следующей команды.
$ java -version
Если на вашем компьютере установлена Java, вы можете увидеть версию установленной Java. В противном случае выполните простые шаги, приведенные ниже, чтобы установить последнюю версию Java.
Шаг 1.1: Загрузите JDK
Загрузите последнюю версию JDK, перейдя по следующей ссылке и загрузите последнюю версию. Джава
Последняя версия (при написании этого руководства) — JDK 8u 60, а файл — «jdk-8u60-linuxx64.tar.gz». Пожалуйста, загрузите файл на свой компьютер.
Шаг 1.2: Извлеките файлы
Как правило, файлы загружаются в папку загрузок . Проверьте это и распакуйте настройку tar, используя следующие команды.
$ cd /go/to/download/path $ tar -zxf jdk-8u60-linux-x64.gz
Шаг 1.3: Перейдите в каталог opt
Чтобы сделать Java доступным для всех пользователей, переместите извлеченный контент Java в папку «/ usr / local / java».
$ su password: (type password of root user) $ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/
Шаг 1.4: Установить путь
Чтобы установить переменные path и JAVA_HOME, добавьте следующие команды в файл ~ / .bashrc.
export JAVA_HOME = /usr/jdk/jdk-1.8.0_60 export PATH=$PATH:$JAVA_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 1.5: альтернативы Java
Используйте следующую команду, чтобы изменить альтернативы Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
Шаг 1.6
Проверьте установку Java с помощью команды проверки (java -version), описанной в шаге 1.
Шаг 2: Установка ZooKeeper Framework
Шаг 2.1: Загрузите ZooKeeper
Чтобы установить ZooKeeper Framework на свой компьютер, перейдите по следующей ссылке и загрузите последнюю версию ZooKeeper. http://zookeeper.apache.org/releases.html
На данный момент последняя версия ZooKeeper — 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Шаг 2.2: Извлеките файл tar
Распакуйте файл tar, используя следующие команды:
$ cd opt/ $ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6 $ mkdir data
Шаг 2.3: Создайте файл конфигурации
Откройте файл конфигурации с именем conf / zoo.cfg с помощью команды vi conf / zoo.cfg и всех следующих параметров, чтобы установить в качестве отправной точки.
$ vi conf/zoo.cfg tickTime = 2000 dataDir = /path/to/zookeeper/data clientPort = 2181 initLimit = 5 syncLimit = 2
Как только файл конфигурации был успешно сохранен, вернитесь в терминал снова. Теперь вы можете запустить сервер zookeeper.
Шаг 2.4: Запустите сервер ZooKeeper
Выполните следующую команду —
$ bin/zkServer.sh start
После выполнения этой команды вы получите ответ:
$ JMX enabled by default $ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED
Шаг 2.5: Запустите CLI
Введите следующую команду —
$ bin/zkCli.sh
После ввода вышеуказанной команды вы будете подключены к серверу ZooKeeper и получите следующий ответ.
Connecting to localhost:2181 ................ ................ ................ Welcome to ZooKeeper! ................ ................ WATCHER:: WatchedEvent state:SyncConnected type: None path:null [zk: localhost:2181(CONNECTED) 0]
Стоп ZooKeeper Сервер
После подключения сервера и выполнения всех операций вы можете остановить сервер zookeeper с помощью следующей команды.
$ bin/zkServer.sh stop
Zookeeper — CLI
Интерфейс командной строки ZooKeeper (CLI) используется для взаимодействия с ансамблем ZooKeeper в целях разработки. Это полезно для отладки и обхода различных опций.
Для выполнения операций ZooKeeper CLI сначала включите сервер ZooKeeper ( «bin / zkServer.sh start» ), а затем клиент ZooKeeper ( «bin / zkCli.sh» ). После запуска клиента вы можете выполнить следующую операцию:
- Создайте znodes
- Получить данные
- Следите за изменениями
- Установить данные
- Создавайте детей Знода
- Список детей знода
- Проверить состояние
- Удалить / Удалить узел
Теперь давайте рассмотрим приведенную выше команду одну за другой с примером.
Создать Znodes
Создайте znode с указанным путем. Аргумент flag указывает, будет ли созданный znode эфемерным, постоянным или последовательным. По умолчанию все узлы являются постоянными.
-
Эфемерные узлы (флаг: e) будут автоматически удалены по истечении сеанса или при отключении клиента.
-
Последовательный znode гарантирует, что путь znode будет уникальным.
-
Ансамбль ZooKeeper добавит порядковый номер вместе с 10-значным заполнением к пути znode. Например, znode path / myapp будет преобразован в / myapp0000000001, а следующий порядковый номер будет / myapp0000000002 . Если флаги не указаны, то znode считается постоянным .
Эфемерные узлы (флаг: e) будут автоматически удалены по истечении сеанса или при отключении клиента.
Последовательный znode гарантирует, что путь znode будет уникальным.
Ансамбль ZooKeeper добавит порядковый номер вместе с 10-значным заполнением к пути znode. Например, znode path / myapp будет преобразован в / myapp0000000001, а следующий порядковый номер будет / myapp0000000002 . Если флаги не указаны, то znode считается постоянным .
Синтаксис
create /path /data
Образец
create /FirstZnode “Myfirstzookeeper-app”
Выход
[zk: localhost:2181(CONNECTED) 0] create /FirstZnode “Myfirstzookeeper-app” Created /FirstZnode
Чтобы создать последовательный znode , добавьте флаг -s, как показано ниже.
Синтаксис
create -s /path /data
Образец
create -s /FirstZnode second-data
Выход
[zk: localhost:2181(CONNECTED) 2] create -s /FirstZnode “second-data” Created /FirstZnode0000000023
Чтобы создать Ephemeral Znode , добавьте флаг -e, как показано ниже.
Синтаксис
create -e /path /data
Образец
create -e /SecondZnode “Ephemeral-data”
Выход
[zk: localhost:2181(CONNECTED) 2] create -e /SecondZnode “Ephemeral-data” Created /SecondZnode
Помните, что когда клиентское соединение потеряно, эфемерный znode будет удален. Вы можете попробовать это, выйдя из ZooKeeper CLI и затем снова открыв CLI.
Получить данные
Он возвращает связанные данные znode и метаданные указанного znode. Вы получите информацию, например, когда данные были изменены в последний раз, где они были изменены, а также информацию о данных. Этот CLI также используется, чтобы назначить часы, чтобы показать уведомление о данных.
Синтаксис
get /path
Образец
get /FirstZnode
Выход
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode “Myfirstzookeeper-app” cZxid = 0x7f ctime = Tue Sep 29 16:15:47 IST 2015 mZxid = 0x7f mtime = Tue Sep 29 16:15:47 IST 2015 pZxid = 0x7f cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 22 numChildren = 0
Чтобы получить доступ к последовательному znode, вы должны ввести полный путь к znode.
Образец
get /FirstZnode0000000023
Выход
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode0000000023 “Second-data” cZxid = 0x80 ctime = Tue Sep 29 16:25:47 IST 2015 mZxid = 0x80 mtime = Tue Sep 29 16:25:47 IST 2015 pZxid = 0x80 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 13 numChildren = 0
Часы
Наблюдения показывают уведомление, когда указанные дочерние данные znode или znode изменяются. Вы можете установить часы только в команде get .
Синтаксис
get /path [watch] 1
Образец
get /FirstZnode 1
Выход
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode 1 “Myfirstzookeeper-app” cZxid = 0x7f ctime = Tue Sep 29 16:15:47 IST 2015 mZxid = 0x7f mtime = Tue Sep 29 16:15:47 IST 2015 pZxid = 0x7f cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 22 numChildren = 0
Вывод похож на обычную команду get , но он будет ждать изменений znode в фоновом режиме. <Начните здесь>
Установить данные
Установите данные указанного znode. Когда вы закончите эту операцию установки, вы можете проверить данные с помощью команды get CLI.
Синтаксис
set /path /data
Образец
set /SecondZnode Data-updated
Выход
[zk: localhost:2181(CONNECTED) 1] get /SecondZnode “Data-updated” cZxid = 0x82 ctime = Tue Sep 29 16:29:50 IST 2015 mZxid = 0x83 mtime = Tue Sep 29 16:29:50 IST 2015 pZxid = 0x82 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x15018b47db00000 dataLength = 14 numChildren = 0
Если вы определили опцию watch в команде get (как в предыдущей команде), то результат будет похож, как показано ниже —
Выход
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode “Mysecondzookeeper-app” WATCHER: : WatchedEvent state:SyncConnected type:NodeDataChanged path:/FirstZnode cZxid = 0x7f ctime = Tue Sep 29 16:15:47 IST 2015 mZxid = 0x84 mtime = Tue Sep 29 17:14:47 IST 2015 pZxid = 0x7f cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 23 numChildren = 0
Создать Детей / Подзнание
Создание детей похоже на создание новых узлов. Единственное отличие состоит в том, что путь дочернего znode будет также иметь родительский путь.
Синтаксис
create /parent/path/subnode/path /data
Образец
create /FirstZnode/Child1 firstchildren
Выход
[zk: localhost:2181(CONNECTED) 16] create /FirstZnode/Child1 “firstchildren” created /FirstZnode/Child1 [zk: localhost:2181(CONNECTED) 17] create /FirstZnode/Child2 “secondchildren” created /FirstZnode/Child2
Список детей
Эта команда используется для отображения и отображения дочерних элементов znode.
Синтаксис
ls /path
Образец
ls /MyFirstZnode
Выход
[zk: localhost:2181(CONNECTED) 2] ls /MyFirstZnode [mysecondsubnode, myfirstsubnode]
Проверить состояние
Статус описывает метаданные указанного узла. Он содержит такие сведения, как метка времени, номер версии, ACL, длина данных и дочерний узел.
Синтаксис
stat /path
Образец
stat /FirstZnode
Выход
[zk: localhost:2181(CONNECTED) 1] stat /FirstZnode cZxid = 0x7f ctime = Tue Sep 29 16:15:47 IST 2015 mZxid = 0x7f mtime = Tue Sep 29 17:14:24 IST 2015 pZxid = 0x7f cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 23 numChildren = 0
Удалить Znode
Удаляет указанный znode и рекурсивно все его дочерние элементы. Это произойдет, только если такой znode доступен.
Синтаксис
rmr /path
Образец
rmr /FirstZnode
Выход
[zk: localhost:2181(CONNECTED) 10] rmr /FirstZnode [zk: localhost:2181(CONNECTED) 11] get /FirstZnode Node does not exist: /FirstZnode
Команда удаления (удаления / пути) аналогична команде удаления , за исключением того, что она работает только на узлах без дочерних элементов.
Zookeeper — API
ZooKeeper имеет официальную привязку API для Java и C. Сообщество ZooKeeper предоставляет неофициальный API для большинства языков (.NET, python и т. Д.). Используя API ZooKeeper, приложение может подключаться, взаимодействовать, манипулировать данными, координировать и, наконец, отключаться от ансамбля ZooKeeper.
ZooKeeper API имеет богатый набор функций, позволяющих получить все функциональные возможности ансамбля ZooKeeper простым и безопасным способом. ZooKeeper API предоставляет как синхронные, так и асинхронные методы.
Ансамбль ZooKeeper и API ZooKeeper полностью дополняют друг друга во всех аспектах, и это приносит большую пользу разработчикам. Давайте обсудим связывание Java в этой главе.
Основы API ZooKeeper
Приложение, взаимодействующее с ансамблем ZooKeeper, называется клиентом ZooKeeper или просто клиентом .
Znode является основным компонентом ансамбля ZooKeeper, а ZooKeeper API предоставляет небольшой набор методов для управления всеми деталями znode с ансамблем ZooKeeper.
Клиент должен следовать приведенным ниже инструкциям, чтобы иметь четкое и понятное взаимодействие с ансамблем ZooKeeper.
-
Подключитесь к ансамблю ZooKeeper. Ансамбль ZooKeeper назначает идентификатор сеанса для клиента.
-
Периодически отправлять тактовые импульсы на сервер. В противном случае у ансамбля ZooKeeper истекает идентификатор сессии, и клиенту необходимо повторно подключиться.
-
Получить / установить znodes, пока активен идентификатор сеанса.
-
Отключитесь от ансамбля ZooKeeper, как только все задачи будут выполнены. Если клиент неактивен в течение длительного времени, ансамбль ZooKeeper автоматически отключит его.
Подключитесь к ансамблю ZooKeeper. Ансамбль ZooKeeper назначает идентификатор сеанса для клиента.
Периодически отправлять тактовые импульсы на сервер. В противном случае у ансамбля ZooKeeper истекает идентификатор сессии, и клиенту необходимо повторно подключиться.
Получить / установить znodes, пока активен идентификатор сеанса.
Отключитесь от ансамбля ZooKeeper, как только все задачи будут выполнены. Если клиент неактивен в течение длительного времени, ансамбль ZooKeeper автоматически отключит его.
Java Binding
Давайте разберемся с наиболее важным набором API ZooKeeper в этой главе. Центральная часть API ZooKeeper — это класс ZooKeeper . Он предоставляет опции для подключения ансамбля ZooKeeper в своем конструкторе и имеет следующие методы:
-
подключиться — подключиться к ансамблю ZooKeeper
-
создать — создать znode
-
существует — проверьте, существует ли znode и его информация
-
getData — получить данные с определенного узла
-
setData — установить данные в определенном znode
-
getChildren — получить все подузлы, доступные в определенном znode
-
delete — получить определенный znode и всех его потомков
-
закрыть — закрыть соединение
подключиться — подключиться к ансамблю ZooKeeper
создать — создать znode
существует — проверьте, существует ли znode и его информация
getData — получить данные с определенного узла
setData — установить данные в определенном znode
getChildren — получить все подузлы, доступные в определенном znode
delete — получить определенный znode и всех его потомков
закрыть — закрыть соединение
Подключение к ансамблю ZooKeeper
Класс ZooKeeper обеспечивает функциональность соединения через его конструктор. Подпись конструктора выглядит следующим образом —
ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher)
Куда,
-
connectionString — хост ансамбля ZooKeeper.
-
sessionTimeout — время ожидания сеанса в миллисекундах.
-
watcher — объект, реализующий интерфейс «Watcher». Ансамбль ZooKeeper возвращает статус соединения через объект-наблюдатель.
connectionString — хост ансамбля ZooKeeper.
sessionTimeout — время ожидания сеанса в миллисекундах.
watcher — объект, реализующий интерфейс «Watcher». Ансамбль ZooKeeper возвращает статус соединения через объект-наблюдатель.
Давайте создадим новый вспомогательный класс ZooKeeperConnection и добавим метод connect . Метод connect создает объект ZooKeeper, подключается к ансамблю ZooKeeper и затем возвращает объект.
Здесь CountDownLatch используется для остановки (ожидания) основного процесса, пока клиент не соединится с ансамблем ZooKeeper.
Ансамбль ZooKeeper отвечает за состояние соединения посредством обратного вызова Watcher . Обратный вызов Watcher будет вызван, как только клиент соединится с ансамблем ZooKeeper, а обратный вызов Watcher вызовет метод countDown CountDownLatch, чтобы снять блокировку, ожидая в основном процессе.
Вот полный код для соединения с ансамблем ZooKeeper.
Кодирование: ZooKeeperConnection.java
// import java classes import java.io.IOException; import java.util.concurrent.CountDownLatch; // import zookeeper classes import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.Watcher.Event.KeeperState; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.AsyncCallback.StatCallback; import org.apache.zookeeper.KeeperException.Code; import org.apache.zookeeper.data.Stat; public class ZooKeeperConnection { // declare zookeeper instance to access ZooKeeper ensemble private ZooKeeper zoo; final CountDownLatch connectedSignal = new CountDownLatch(1); // Method to connect zookeeper ensemble. public ZooKeeper connect(String host) throws IOException,InterruptedException { zoo = new ZooKeeper(host,5000,new Watcher() { public void process(WatchedEvent we) { if (we.getState() == KeeperState.SyncConnected) { connectedSignal.countDown(); } } }); connectedSignal.await(); return zoo; } // Method to disconnect from zookeeper server public void close() throws InterruptedException { zoo.close(); } }
Сохраните приведенный выше код, и он будет использован в следующем разделе для соединения ансамбля ZooKeeper.
Создать Znode
Класс ZooKeeper предоставляет метод create для создания нового znode в ансамбле ZooKeeper. Сигнатура метода создания выглядит следующим образом:
create(String path, byte[] data, List<ACL> acl, CreateMode createMode)
Куда,
-
путь — Зноде путь. Например, / myapp1, / myapp2, / myapp1 / mydata1, myapp2 / mydata1 / myanothersubdata
-
data — данные для хранения по указанному пути znode
-
acl — список контроля доступа создаваемого узла. ZooKeeper API предоставляет статический интерфейс ZooDefs.Ids для получения некоторых основных списков acl. Например, ZooDefs.Ids.OPEN_ACL_UNSAFE возвращает список acl для открытых узлов.
-
createMode — тип узла, эфемерный, последовательный или оба. Это перечисление .
путь — Зноде путь. Например, / myapp1, / myapp2, / myapp1 / mydata1, myapp2 / mydata1 / myanothersubdata
data — данные для хранения по указанному пути znode
acl — список контроля доступа создаваемого узла. ZooKeeper API предоставляет статический интерфейс ZooDefs.Ids для получения некоторых основных списков acl. Например, ZooDefs.Ids.OPEN_ACL_UNSAFE возвращает список acl для открытых узлов.
createMode — тип узла, эфемерный, последовательный или оба. Это перечисление .
Давайте создадим новое Java-приложение для проверки функциональности создания API ZooKeeper. Создайте файл ZKCreate.java . В методе main создайте объект типа ZooKeeperConnection и вызовите метод connect для подключения к ансамблю ZooKeeper.
Метод connect возвращает объект ZooKeeper zk . Теперь вызовите метод create объекта zk с пользовательским путем и данными .
Полный программный код для создания znode выглядит следующим образом:
Кодирование: ZKCreate.java
import java.io.IOException; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.Watcher.Event.KeeperState; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.CreateMode; import org.apache.zookeeper.ZooDefs; public class ZKCreate { // create static instance for zookeeper class. private static ZooKeeper zk; // create static instance for ZooKeeperConnection class. private static ZooKeeperConnection conn; // Method to create znode in zookeeper ensemble public static void create(String path, byte[] data) throws KeeperException,InterruptedException { zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } public static void main(String[] args) { // znode path String path = "/MyFirstZnode"; // Assign path to znode // data in byte array byte[] data = "My first zookeeper app”.getBytes(); // Declare data try { conn = new ZooKeeperConnection(); zk = conn.connect("localhost"); create(path, data); // Create the data to the specified path conn.close(); } catch (Exception e) { System.out.println(e.getMessage()); //Catch error message } } }
После того как приложение скомпилировано и выполнено, в ансамбле ZooKeeper будет создан znode с указанными данными. Вы можете проверить это, используя ZooKeeper CLI zkCli.sh .
cd /path/to/zookeeper bin/zkCli.sh >>> get /MyFirstZnode
Exists — Проверить существование Znode
Класс ZooKeeper предоставляет метод существующие для проверки существования znode. Возвращает метаданные znode, если указанный znode существует. Подпись существующего метода выглядит следующим образом:
exists(String path, boolean watcher)
Куда,
-
путь — Зноде путь
-
watcher — логическое значение, указывающее, смотреть ли указанный узел или нет
путь — Зноде путь
watcher — логическое значение, указывающее, смотреть ли указанный узел или нет
Давайте создадим новое Java-приложение для проверки «существующих» функциональных возможностей API ZooKeeper. Создайте файл «ZKExists.java» . В основном методе создайте объект ZooKeeper «zk», используя объект «ZooKeeperConnection» . Затем вызовите «существующий» метод объекта «zk» с пользовательским «путем» . Полный список выглядит следующим образом —
Кодирование: ZKExists.java
import java.io.IOException; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.Watcher.Event.KeeperState; import org.apache.zookeeper.data.Stat; public class ZKExists { private static ZooKeeper zk; private static ZooKeeperConnection conn; // Method to check existence of znode and its status, if znode is available. public static Stat znode_exists(String path) throws KeeperException,InterruptedException { return zk.exists(path, true); } public static void main(String[] args) throws InterruptedException,KeeperException { String path = "/MyFirstZnode"; // Assign znode to the specified path try { conn = new ZooKeeperConnection(); zk = conn.connect("localhost"); Stat stat = znode_exists(path); // Stat checks the path of the znode if(stat != null) { System.out.println("Node exists and the node version is " + stat.getVersion()); } else { System.out.println("Node does not exists"); } } catch(Exception e) { System.out.println(e.getMessage()); // Catches error messages } } }
Как только приложение скомпилировано и выполнено, вы получите следующий вывод.
Node exists and the node version is 1.
Метод getData
Класс ZooKeeper предоставляет метод getData для получения данных, прикрепленных в указанном znode, и его статуса. Подпись метода getData выглядит следующим образом:
getData(String path, Watcher watcher, Stat stat)
Куда,
-
путь — Зноде путь.
-
watcher — функция обратного вызова типа Watcher . Ансамбль ZooKeeper уведомит через обратный вызов Watcher об изменении данных указанного znode. Это разовое уведомление.
-
stat — возвращает метаданные znode.
путь — Зноде путь.
watcher — функция обратного вызова типа Watcher . Ансамбль ZooKeeper уведомит через обратный вызов Watcher об изменении данных указанного znode. Это разовое уведомление.
stat — возвращает метаданные znode.
Давайте создадим новое приложение Java, чтобы понять функциональность getData API ZooKeeper. Создайте файл ZKGetData.java . В методе main создайте объект ZooKeeper zk, используя объект ZooKeeperConnection . Затем вызовите метод getData объекта zk с пользовательским путем.
Вот полный код программы для получения данных с указанного узла —
Кодирование: ZKGetData.java
import java.io.IOException; import java.util.concurrent.CountDownLatch; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.Watcher.Event.KeeperState; import org.apache.zookeeper.data.Stat; public class ZKGetData { private static ZooKeeper zk; private static ZooKeeperConnection conn; public static Stat znode_exists(String path) throws KeeperException,InterruptedException { return zk.exists(path,true); } public static void main(String[] args) throws InterruptedException, KeeperException { String path = "/MyFirstZnode"; final CountDownLatch connectedSignal = new CountDownLatch(1); try { conn = new ZooKeeperConnection(); zk = conn.connect("localhost"); Stat stat = znode_exists(path); if(stat != null) { byte[] b = zk.getData(path, new Watcher() { public void process(WatchedEvent we) { if (we.getType() == Event.EventType.None) { switch(we.getState()) { case Expired: connectedSignal.countDown(); break; } } else { String path = "/MyFirstZnode"; try { byte[] bn = zk.getData(path, false, null); String data = new String(bn, "UTF-8"); System.out.println(data); connectedSignal.countDown(); } catch(Exception ex) { System.out.println(ex.getMessage()); } } } }, null); String data = new String(b, "UTF-8"); System.out.println(data); connectedSignal.await(); } else { System.out.println("Node does not exists"); } } catch(Exception e) { System.out.println(e.getMessage()); } } }
Как только приложение скомпилировано и выполнено, вы получите следующий вывод
My first zookeeper app
И приложение будет ждать дальнейшего уведомления от ансамбля ZooKeeper. Измените данные указанного znode, используя ZooKeeper CLI zkCli.sh .
cd /path/to/zookeeper bin/zkCli.sh >>> set /MyFirstZnode Hello
Теперь приложение напечатает следующий вывод и завершит работу.
Hello
Метод setData
Класс ZooKeeper предоставляет метод setData для изменения данных, вложенных в указанный znode. Подпись метода setData следующая:
setData(String path, byte[] data, int version)
Куда,
-
путь — Зноде путь
-
data — данные для хранения по указанному пути znode.
-
версия — текущая версия znode. ZooKeeper обновляет номер версии znode всякий раз, когда данные изменяются.
путь — Зноде путь
data — данные для хранения по указанному пути znode.
версия — текущая версия znode. ZooKeeper обновляет номер версии znode всякий раз, когда данные изменяются.
Давайте теперь создадим новое Java-приложение, чтобы понять функциональность setData API ZooKeeper. Создайте файл ZKSetData.java . В методе main создайте объект ZooKeeper zk, используя объект ZooKeeperConnection . Затем вызовите метод setData объекта zk с указанным путем, новыми данными и версией узла.
Вот полный код программы для изменения данных, прикрепленных к указанному znode.
Код: ZKSetData.java
import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.Watcher.Event.KeeperState; import java.io.IOException; public class ZKSetData { private static ZooKeeper zk; private static ZooKeeperConnection conn; // Method to update the data in a znode. Similar to getData but without watcher. public static void update(String path, byte[] data) throws KeeperException,InterruptedException { zk.setData(path, data, zk.exists(path,true).getVersion()); } public static void main(String[] args) throws InterruptedException,KeeperException { String path= "/MyFirstZnode"; byte[] data = "Success".getBytes(); //Assign data which is to be updated. try { conn = new ZooKeeperConnection(); zk = conn.connect("localhost"); update(path, data); // Update znode data to the specified path } catch(Exception e) { System.out.println(e.getMessage()); } } }
После того, как приложение скомпилировано и выполнено, данные указанного znode будут изменены, и их можно проверить с помощью ZooKeeper CLI, zkCli.sh .
cd /path/to/zookeeper bin/zkCli.sh >>> get /MyFirstZnode
getChildrenMethod
Класс ZooKeeper предоставляет метод getChildren для получения всех подузлов конкретного узла. Подпись метода getChildren следующая:
getChildren(String path, Watcher watcher)
Куда,
-
путь — Зноде путь.
-
watcher — функция обратного вызова типа «Watcher». Ансамбль ZooKeeper уведомит, когда указанный znode будет удален или дочерний элемент под znode будет создан / удален. Это разовое уведомление.
путь — Зноде путь.
watcher — функция обратного вызова типа «Watcher». Ансамбль ZooKeeper уведомит, когда указанный znode будет удален или дочерний элемент под znode будет создан / удален. Это разовое уведомление.
Кодирование: ZKGetChildren.java
import java.io.IOException; import java.util.*; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.Watcher.Event.KeeperState; import org.apache.zookeeper.data.Stat; public class ZKGetChildren { private static ZooKeeper zk; private static ZooKeeperConnection conn; // Method to check existence of znode and its status, if znode is available. public static Stat znode_exists(String path) throws KeeperException,InterruptedException { return zk.exists(path,true); } public static void main(String[] args) throws InterruptedException,KeeperException { String path = "/MyFirstZnode"; // Assign path to the znode try { conn = new ZooKeeperConnection(); zk = conn.connect("localhost"); Stat stat = znode_exists(path); // Stat checks the path if(stat!= null) { //“getChildren” method- get all the children of znode.It has two args, path and watch List <String> children = zk.getChildren(path, false); for(int i = 0; i < children.size(); i++) System.out.println(children.get(i)); //Print children's } else { System.out.println("Node does not exists"); } } catch(Exception e) { System.out.println(e.getMessage()); } } }
Перед запуском программы, давайте создадим два подузла для / MyFirstZnode, используя ZooKeeper CLI, zkCli.sh .
cd /path/to/zookeeper bin/zkCli.sh >>> create /MyFirstZnode/myfirstsubnode Hi >>> create /MyFirstZnode/mysecondsubmode Hi
Теперь, скомпилировав и запустив программу, вы получите созданные выше znodes.
myfirstsubnode mysecondsubnode
Удалить Znode
Класс ZooKeeper предоставляет метод delete для удаления указанного znode. Подпись метода удаления выглядит следующим образом:
delete(String path, int version)
Куда,
-
путь — Зноде путь.
-
версия — текущая версия znode.
путь — Зноде путь.
версия — текущая версия znode.
Давайте создадим новое приложение Java, чтобы понять функциональность удаления API ZooKeeper. Создайте файл ZKDelete.java . В методе main создайте объект ZooKeeper zk, используя объект ZooKeeperConnection . Затем вызовите метод удаления объекта zk с указанным путем и версией узла.
Полный код программы для удаления znode выглядит следующим образом:
Кодирование: ZKDelete.java
import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.KeeperException; public class ZKDelete { private static ZooKeeper zk; private static ZooKeeperConnection conn; // Method to check existence of znode and its status, if znode is available. public static void delete(String path) throws KeeperException,InterruptedException { zk.delete(path,zk.exists(path,true).getVersion()); } public static void main(String[] args) throws InterruptedException,KeeperException { String path = "/MyFirstZnode"; //Assign path to the znode try { conn = new ZooKeeperConnection(); zk = conn.connect("localhost"); delete(path); //delete the node with the specified path } catch(Exception e) { System.out.println(e.getMessage()); // catches error messages } } }
Zookeeper — Приложения
Zookeeper предоставляет гибкую координационную инфраструктуру для распределенной среды. Платформа ZooKeeper поддерживает многие из лучших на сегодняшний день промышленных приложений. Мы обсудим некоторые из наиболее заметных применений ZooKeeper в этой главе.
Yahoo!
Фреймворк ZooKeeper изначально был создан в Yahoo! Хорошо спроектированное распределенное приложение должно отвечать таким требованиям, как прозрачность данных, лучшая производительность, надежность, централизованная конфигурация и координация. Таким образом, они разработали платформу ZooKeeper для удовлетворения этих требований.
Apache Hadoop
Apache Hadoop является движущей силой роста индустрии больших данных. Hadoop использует ZooKeeper для управления конфигурацией и координации. Давайте рассмотрим сценарий, чтобы понять роль ZooKeeper в Hadoop.
Предположим, что кластер Hadoop соединяет 100 или более обычных серверов . Следовательно, существует необходимость в услугах по координации и наименованию. Поскольку в расчет вовлечено большое количество узлов, каждый узел должен синхронизироваться друг с другом, знать, где получить доступ к службам, и знать, как их следует настраивать. На данный момент кластерам Hadoop требуются межузловые сервисы. ZooKeeper предоставляет средства для межузловой синхронизации и обеспечивает сериализацию и синхронизацию задач в проектах Hadoop.
Несколько серверов ZooKeeper поддерживают большие кластеры Hadoop. Каждый клиентский компьютер связывается с одним из серверов ZooKeeper для получения и обновления информации о синхронизации. Некоторые из примеров в реальном времени —
-
Проект «Геном человека» — проект «Геном человека» содержит терабайты данных. Среду Hadoop MapReduce можно использовать для анализа набора данных и поиска интересных фактов для развития человека.
-
Здравоохранение — больницы могут хранить, извлекать и анализировать огромные наборы медицинских карт пациентов, которые обычно находятся в терабайтах.
Проект «Геном человека» — проект «Геном человека» содержит терабайты данных. Среду Hadoop MapReduce можно использовать для анализа набора данных и поиска интересных фактов для развития человека.
Здравоохранение — больницы могут хранить, извлекать и анализировать огромные наборы медицинских карт пациентов, которые обычно находятся в терабайтах.
Apache HBase
Apache HBase — это распределенная база данных NoSQL с открытым исходным кодом, используемая для доступа в режиме реального времени для чтения / записи больших наборов данных и работающая поверх HDFS. HBase следует архитектуре ведущий-ведомый, где ведущий HBase управляет всеми ведомыми. Рабы называются серверами региона .
Установка распределенного приложения HBase зависит от работающего кластера ZooKeeper. Apache HBase использует ZooKeeper для отслеживания состояния распределенных данных на главных и региональных серверах с помощью централизованного управления конфигурацией и механизмов распределенного мьютекса . Вот несколько примеров использования HBase —
-
Телеком — Телекоммуникационная индустрия хранит миллиарды записей о мобильных вызовах (около 30 ТБ / месяц), и доступ к этим записям в реальном времени становится огромной задачей. HBase может использоваться для простой и эффективной обработки всех записей в режиме реального времени.
-
Социальная сеть — Подобно индустрии телекоммуникаций, такие сайты, как Twitter, LinkedIn и Facebook, получают огромные объемы данных через сообщения, созданные пользователями. HBase можно использовать для поиска последних тенденций и других интересных фактов.
Телеком — Телекоммуникационная индустрия хранит миллиарды записей о мобильных вызовах (около 30 ТБ / месяц), и доступ к этим записям в реальном времени становится огромной задачей. HBase может использоваться для простой и эффективной обработки всех записей в режиме реального времени.
Социальная сеть — Подобно индустрии телекоммуникаций, такие сайты, как Twitter, LinkedIn и Facebook, получают огромные объемы данных через сообщения, созданные пользователями. HBase можно использовать для поиска последних тенденций и других интересных фактов.
Apache Solr
Apache Solr — это быстрая поисковая платформа с открытым исходным кодом, написанная на Java. Это невероятно быстрый, отказоустойчивый распределенный поисковик. Созданный на основе Lucene , это высокопроизводительный, полнофункциональный механизм поиска текста.
Solr широко использует все функции ZooKeeper, такие как управление конфигурацией, выбор лидера, управление узлами, блокировка и синхронизация данных.
Solr состоит из двух частей: индексация и поиск . Индексирование — это процесс хранения данных в надлежащем формате, чтобы их можно было искать позже. Solr использует ZooKeeper как для индексации данных на нескольких узлах, так и для поиска на нескольких узлах. ZooKeeper предоставляет следующие функции —
-
Добавить / удалить узлы по мере необходимости
-
Репликация данных между узлами с последующей минимизацией потери данных
-
Обмен данными между несколькими узлами и последующий поиск по нескольким узлам для более быстрых результатов поиска
Добавить / удалить узлы по мере необходимости
Репликация данных между узлами с последующей минимизацией потери данных
Обмен данными между несколькими узлами и последующий поиск по нескольким узлам для более быстрых результатов поиска
Некоторые примеры использования Apache Solr включают электронную коммерцию, поиск работы и т. Д.