Кластеризация — это процедура организации элементов или элементов данной коллекции в группы на основе сходства между элементами. Например, приложения, связанные с публикацией новостей в Интернете, группируют свои новостные статьи с помощью кластеризации.
Приложения кластеризации
-
Кластеризация широко используется во многих приложениях, таких как исследование рынка, распознавание образов, анализ данных и обработка изображений.
-
Кластеризация может помочь маркетологам обнаружить отдельные группы на основе своих клиентов. И они могут охарактеризовать свои группы клиентов на основе моделей покупок.
-
В области биологии его можно использовать для выведения таксономий растений и животных, классификации генов с аналогичной функциональностью и получения информации о структурах, присущих популяциям.
-
Кластеризация помогает в идентификации областей схожего землепользования в базе данных наблюдения Земли.
-
Кластеризация также помогает в классификации документов в Интернете для обнаружения информации.
-
Кластеризация используется в таких приложениях, как обнаружение мошенничества с кредитными картами.
-
Как функция интеллектуального анализа данных, Cluster Analysis служит инструментом, позволяющим получить представление о распределении данных для наблюдения за характеристиками каждого кластера.
Кластеризация широко используется во многих приложениях, таких как исследование рынка, распознавание образов, анализ данных и обработка изображений.
Кластеризация может помочь маркетологам обнаружить отдельные группы на основе своих клиентов. И они могут охарактеризовать свои группы клиентов на основе моделей покупок.
В области биологии его можно использовать для выведения таксономий растений и животных, классификации генов с аналогичной функциональностью и получения информации о структурах, присущих популяциям.
Кластеризация помогает в идентификации областей схожего землепользования в базе данных наблюдения Земли.
Кластеризация также помогает в классификации документов в Интернете для обнаружения информации.
Кластеризация используется в таких приложениях, как обнаружение мошенничества с кредитными картами.
Как функция интеллектуального анализа данных, Cluster Analysis служит инструментом, позволяющим получить представление о распределении данных для наблюдения за характеристиками каждого кластера.
Используя Mahout, мы можем кластеризовать данный набор данных. Необходимые шаги следующие:
-
Алгоритм Вам необходимо выбрать подходящий алгоритм кластеризации для группировки элементов кластера.
-
Сходство и различие Необходимо иметь правило для проверки сходства между вновь обнаруженными элементами и элементами в группах.
-
Условие остановки Условие остановки требуется для определения точки, где кластеризация не требуется.
Алгоритм Вам необходимо выбрать подходящий алгоритм кластеризации для группировки элементов кластера.
Сходство и различие Необходимо иметь правило для проверки сходства между вновь обнаруженными элементами и элементами в группах.
Условие остановки Условие остановки требуется для определения точки, где кластеризация не требуется.
Процедура кластеризации
Для кластеризации данных вам необходимо:
-
Запустите сервер Hadoop. Создайте необходимые каталоги для хранения файлов в файловой системе Hadoop. (Создайте каталоги для входного файла, файла последовательности и кластерного вывода в случае навеса).
-
Скопируйте входной файл в файловую систему Hadoop из файловой системы Unix.
-
Подготовьте файл последовательности из входных данных.
-
Запустите любой из доступных алгоритмов кластеризации.
-
Получить кластерные данные.
Запустите сервер Hadoop. Создайте необходимые каталоги для хранения файлов в файловой системе Hadoop. (Создайте каталоги для входного файла, файла последовательности и кластерного вывода в случае навеса).
Скопируйте входной файл в файловую систему Hadoop из файловой системы Unix.
Подготовьте файл последовательности из входных данных.
Запустите любой из доступных алгоритмов кластеризации.
Получить кластерные данные.
Запуск Hadoop
Mahout работает с Hadoop, поэтому убедитесь, что сервер Hadoop запущен и работает.
$ cd HADOOP_HOME/bin $ start-all.sh
Подготовка каталогов входных файлов
Создайте каталоги в файловой системе Hadoop для хранения входного файла, файлов последовательности и кластерных данных с помощью следующей команды:
$ hadoop fs -p mkdir /mahout_data $ hadoop fs -p mkdir /clustered_data $ hadoop fs -p mkdir /mahout_seq
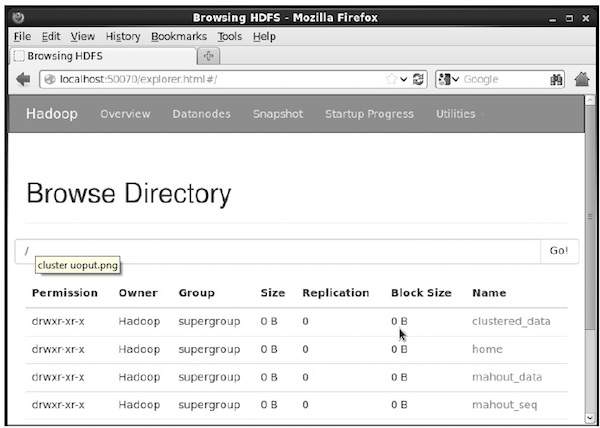
Вы можете проверить, создан ли каталог, используя веб-интерфейс hadoop по следующему URL-адресу — http: // localhost: 50070 /
Это дает вам вывод, как показано ниже:
Копирование входного файла в HDFS
Теперь скопируйте файл входных данных из файловой системы Linux в каталог mahout_data в файловой системе Hadoop, как показано ниже. Предположим, что ваш входной файл mydata.txt и он находится в каталоге / home / Hadoop / data /.
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/
Подготовка файла последовательности
Mahout предоставляет вам утилиту для преобразования указанного входного файла в формат файла последовательности. Эта утилита требует двух параметров.
- Каталог входного файла, в котором находятся исходные данные.
- Каталог выходного файла, в котором должны храниться кластерные данные.
Ниже приведена подсказка для утилиты mahout seqdirectory .
Шаг 1: Перейдите в домашний каталог Mahout. Вы можете получить помощь утилиты, как показано ниже:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help Job-Specific Options: --input (-i) input Path to job input directory. --output (-o) output The directory pathname for output. --overwrite (-ow) If present, overwrite the output directory
Создайте файл последовательности с помощью утилиты, используя следующий синтаксис:
mahout seqdirectory -i <input file path> -o <output directory>
пример
mahout seqdirectory -i hdfs://localhost:9000/mahout_seq/ -o hdfs://localhost:9000/clustered_data/
Алгоритмы кластеризации
Mahout поддерживает два основных алгоритма кластеризации, а именно:
- Кластеризация навеса
- K-означает кластеризацию
Кластеризация навеса
Кластеризация навеса — это простая и быстрая техника, используемая Mahout для кластеризации. Объекты будут рассматриваться как точки в простом пространстве. Этот метод часто используется в качестве начального шага в других методах кластеризации, таких как кластеризация k-средних. Вы можете запустить задание Canopy, используя следующий синтаксис:
mahout canopy -i <input vectors directory> -o <output directory> -t1 <threshold value 1> -t2 <threshold value 2>
Для задания Canopy требуется каталог входного файла с файлом последовательности и выходной каталог, в котором должны храниться кластерные данные.
пример
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq -o hdfs://localhost:9000/clustered_data -t1 20 -t2 30
Вы получите кластерные данные, сгенерированные в заданном выходном каталоге.
K-означает кластеризацию
Кластеризация K-средних является важным алгоритмом кластеризации. Алгоритм кластеризации k в k-средних представляет количество кластеров, на которые необходимо разделить данные. Например, значение k, указанное для этого алгоритма, выбрано равным 3, алгоритм собирается разделить данные на 3 кластера.
Каждый объект будет представлен как вектор в пространстве. Первоначально k точек будет выбираться алгоритмом случайным образом и обрабатываться как центры, каждый объект, ближайший к каждому центру, группируется. Существует несколько алгоритмов измерения расстояния, и пользователь должен выбрать нужный.
Создание векторных файлов
-
В отличие от алгоритма Canopy, алгоритм k-средних требует ввода векторных файлов, поэтому вы должны создавать векторные файлы.
-
Чтобы сгенерировать векторные файлы из формата файла последовательности, Mahout предоставляет утилиту seq2parse .
В отличие от алгоритма Canopy, алгоритм k-средних требует ввода векторных файлов, поэтому вы должны создавать векторные файлы.
Чтобы сгенерировать векторные файлы из формата файла последовательности, Mahout предоставляет утилиту seq2parse .
Ниже приведены некоторые параметры утилиты seq2parse . Создайте векторные файлы, используя эти параметры.
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
После создания векторов перейдите к алгоритму k-средних. Синтаксис для запуска задания k-means выглядит следующим образом:
mahout kmeans -i <input vectors directory> -c <input clusters directory> -o <output working directory> -dm <Distance Measure technique> -x <maximum number of iterations> -k <number of initial clusters>
Для задания кластеризации K-означает, что требуется каталог входных векторов, каталог выходных кластеров, мера расстояния, максимальное количество итераций, которое необходимо выполнить, и целочисленное значение, представляющее количество кластеров, на которые следует разделить входные данные.