Apache Storm считывает необработанный поток данных в реальном времени с одного конца и пропускает их через последовательность небольших блоков обработки и выводит обработанную / полезную информацию на другом конце.
Следующая диаграмма изображает основную концепцию Apache Storm.
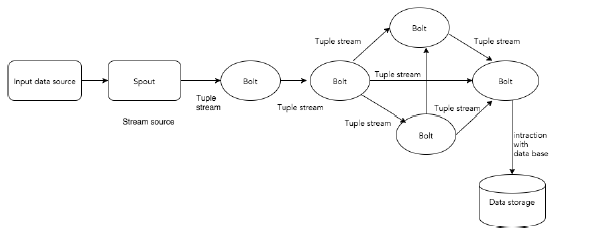
Давайте теперь подробнее рассмотрим компоненты Apache Storm —
| Компоненты | Описание |
|---|---|
| Кортеж | Кортеж является основной структурой данных в Storm. Это список упорядоченных элементов. По умолчанию кортеж поддерживает все типы данных. Обычно он моделируется как набор значений, разделенных запятыми, и передается в кластер Storm. |
| Поток | Поток — это неупорядоченная последовательность кортежей. |
| Смерчи | Источник потока. Как правило, Storm принимает входные данные из необработанных источников данных, таких как Twitter Streaming API, очередь Apache Kafka, очередь Kestrel и т. Д. В противном случае вы можете написать носители для чтения данных из источников данных. «ISpout» является основным интерфейсом для реализации spouts. Некоторыми из определенных интерфейсов являются IRichSpout, BaseRichSpout, KafkaSpout и т. Д. |
| Болты | Болты являются логическими единицами обработки. Носики передают данные в процесс обработки болтов и болтов и создают новый выходной поток. Болты могут выполнять операции фильтрации, агрегации, объединения, взаимодействия с источниками данных и базами данных. Болт получает данные и испускает один или несколько болтов. «IBolt» является основным интерфейсом для реализации болтов. Некоторые из распространенных интерфейсов — IRichBolt, IBasicBolt и т. Д. |
Давайте рассмотрим пример «анализа Twitter» в реальном времени и посмотрим, как его можно смоделировать в Apache Storm. Следующая диаграмма изображает структуру.
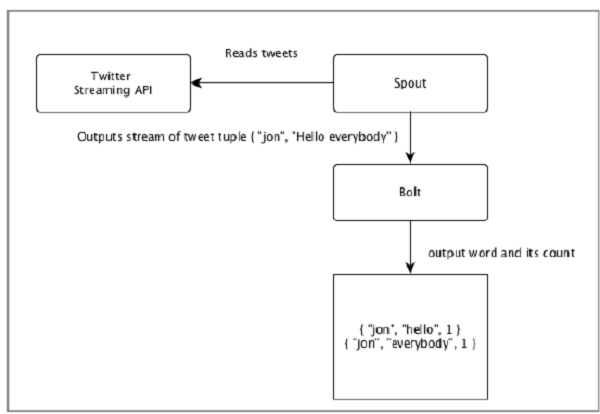
Входные данные для «Twitter Analysis» поступают из Twitter Streaming API. Spout будет читать твиты пользователей, используя Twitter Streaming API, и выводить их как поток кортежей. Один кортеж из носика будет иметь имя пользователя в твиттере и один твит в качестве значений, разделенных запятыми. Затем этот поток кортежей будет перенаправлен на Болт, и Болт разделит твит на отдельные слова, вычислит количество слов и сохранит информацию в сконфигурированном источнике данных. Теперь мы можем легко получить результат, запросив источник данных.
Топология
Изливы и болты соединены вместе и образуют топологию. Логика приложения реального времени задается внутри топологии Storm. Проще говоря, топология — это ориентированный граф, где вершины — это вычисления, а ребра — поток данных.
Простая топология начинается с носиков. Носик испускает данные на один или несколько болтов. Болт представляет узел в топологии, имеющий наименьшую логику обработки, и вывод болта может быть передан в другой болт в качестве ввода.
Storm постоянно поддерживает топологию, пока вы не уничтожите топологию. Основная задача Apache Storm — запускать топологию и одновременно запускать любое количество топологий.
Задачи
Теперь у вас есть общее представление о носиках и болтах. Они представляют собой наименьшую логическую единицу топологии, и топология строится с использованием одного излива и набора болтов. Они должны быть выполнены правильно в определенном порядке для успешной работы топологии. Выполнение каждой струи и удара Storm называется «Задачами». Говоря простыми словами, задание — это либо выполнение излива, либо засов. В каждый момент времени каждый излив и болт может иметь несколько экземпляров, работающих в нескольких отдельных потоках.
Рабочие
Топология работает распределенным образом на нескольких рабочих узлах. Storm равномерно распределяет задачи по всем рабочим узлам. Роль рабочего узла заключается в том, чтобы прослушивать задания и запускать или останавливать процессы при каждом поступлении нового задания.
Группировка потоков
Поток данных течет от носика к болту или от одного болта к другому болту. Группировка потоков управляет маршрутизацией кортежей в топологии и помогает нам понять поток кортежей в топологии. Есть четыре встроенных группировки, как описано ниже.
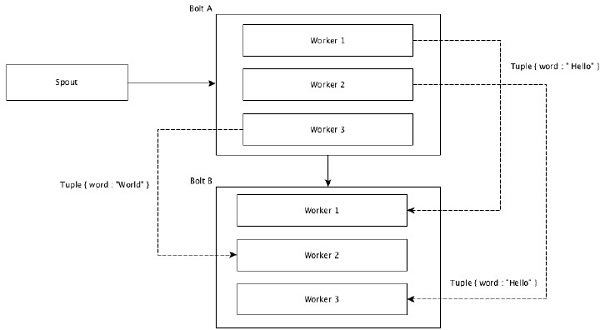
Shuffle Grouping
В случайном порядке одинаковое количество кортежей распределяется случайным образом по всем рабочим, выполняющим болты. Следующая диаграмма изображает структуру.
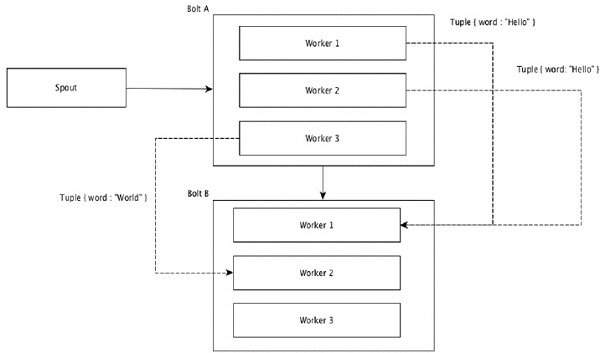
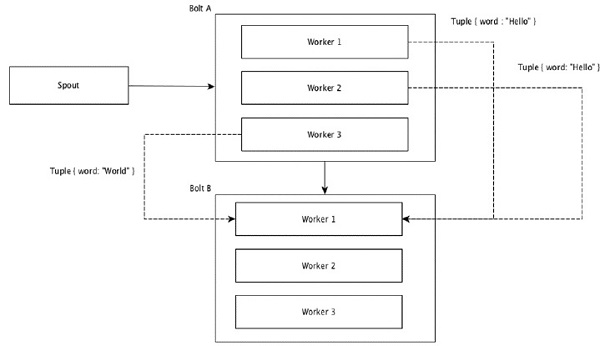
Группировка полей
Поля с одинаковыми значениями в кортежах сгруппированы, а оставшиеся кортежи хранятся снаружи. Затем кортежи с одинаковыми значениями поля отправляются тому же рабочему, выполняющему болты. Например, если поток сгруппирован по полю «word», то кортежи с одинаковой строкой «Hello» будут перемещены к одному и тому же работнику. На следующей диаграмме показано, как работает группировка полей.
Глобальная группировка
Все потоки можно сгруппировать и направить на один болт. Эта группировка отправляет кортежи, сгенерированные всеми экземплярами источника, одному целевому экземпляру (в частности, выберите работника с самым низким ID).
Все группировки
Вся группировка отправляет одну копию каждого кортежа всем экземплярам приемного болта. Этот вид группировки используется для отправки сигналов на болты. Вся группировка полезна для операций объединения.