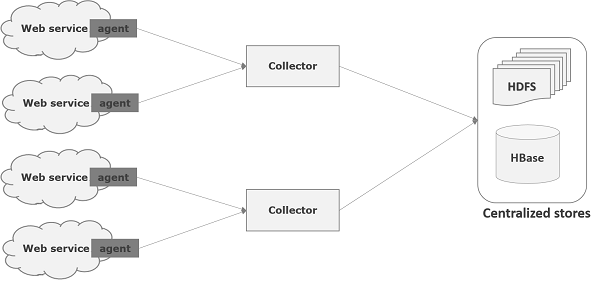
Flume — это инфраструктура, которая используется для перемещения данных журнала в HDFS. Обычно события и данные журнала генерируются серверами журналов, и на этих серверах работают агенты Flume. Эти агенты получают данные от генераторов данных.
Данные в этих агентах будут собираться промежуточным узлом, известным как Collector . Как и у агентов, в Flume может быть несколько сборщиков.
Наконец, данные со всех этих сборщиков будут объединены и отправлены в централизованное хранилище, такое как HBase или HDFS. Следующая диаграмма объясняет поток данных в Flume.
Multi-hop Flow
Внутри Flume может быть несколько агентов, и до достижения конечного пункта назначения событие может проходить через более одного агента. Это известно как многопролетный поток .
Поток распада
Поток данных из одного источника в несколько каналов известен как поток разветвления . Это двух типов —
-
Репликация — поток данных, в котором данные будут реплицироваться во всех настроенных каналах.
-
Мультиплексирование — поток данных, в котором данные будут отправлены на выбранный канал, который упоминается в заголовке события.
Репликация — поток данных, в котором данные будут реплицироваться во всех настроенных каналах.
Мультиплексирование — поток данных, в котором данные будут отправлены на выбранный канал, который упоминается в заголовке события.
Поток вентилятора
Поток данных, в котором данные будут передаваться из многих источников в один канал, называется потоком данных .
Обработка ошибок
В Flume для каждого события выполняются две транзакции: одна у отправителя и одна у получателя. Отправитель отправляет события получателю. Вскоре после получения данных получатель совершает собственную транзакцию и отправляет «полученный» сигнал отправителю. После получения сигнала отправитель совершает свою транзакцию. (Отправитель не будет совершать транзакцию, пока не получит сигнал от получателя.)