DynamoDB — Обзор
DynamoDB позволяет пользователям создавать базы данных, способные хранить и извлекать любой объем данных и обслуживать любой объем трафика. Он автоматически распределяет данные и трафик по серверам для динамического управления запросами каждого клиента, а также поддерживает высокую производительность.
DynamoDB vs. RDBMS
DynamoDB использует модель NoSQL, что означает, что она использует нереляционную систему. В следующей таблице приведены различия между DynamoDB и RDBMS.
| Общие задачи | RDBMS | DynamoDB |
|---|---|---|
| Подключиться к источнику | Он использует постоянное соединение и команды SQL. | Он использует HTTP-запросы и операции API |
| Создать таблицу | Его фундаментальные структуры являются таблицами и должны быть определены. | Он использует только первичные ключи, а не схему при создании. Он использует различные источники данных. |
| Получить информацию о таблице | Вся информация таблицы остается доступной | Раскрываются только первичные ключи. |
| Загрузить данные таблицы | Используются строки из столбцов. | В таблицах используются элементы из атрибутов |
| Читать данные таблицы | Он использует операторы SELECT и операторы фильтрации. | Он использует GetItem, Query и Scan. |
| Управление индексами | Он использует стандартные индексы, созданные с помощью операторов SQL. Модификации к нему происходят автоматически при изменениях таблицы. | Он использует вторичный индекс для достижения той же функции. Требуются спецификации (ключ раздела и ключ сортировки). |
| Изменить данные таблицы | Он использует оператор UPDATE. | Он использует операцию UpdateItem. |
| Удалить данные таблицы | Он использует оператор DELETE. | Он использует операцию DeleteItem. |
| Удалить таблицу | Он использует оператор DROP TABLE. | Он использует операцию DeleteTable. |
преимущества
Два главных преимущества DynamoDB — это масштабируемость и гибкость. Он не требует использования определенного источника данных и структуры, позволяя пользователям работать практически с чем угодно, но единообразно.
Его конструкция также поддерживает широкий спектр использования — от более легких задач и операций до требовательных функциональных возможностей предприятия. Он также позволяет легко использовать несколько языков: Ruby, Java, Python, C #, Erlang, PHP и Perl.
Ограничения
DynamoDB действительно страдает от определенных ограничений, однако эти ограничения не обязательно создают огромные проблемы или препятствуют твердому развитию.
Вы можете просмотреть их из следующих пунктов —
-
Размеры единицы емкости — Единица емкости чтения — это единое согласованное чтение в секунду для элементов размером не более 4 КБ. Емкость записи — это одна запись в секунду для элементов размером не более 1 КБ.
-
Предоставленная пропускная способность мин / макс. — Все таблицы и глобальные вторичные индексы имеют как минимум одну единицу чтения и одну единицу емкости записи. Максимумы зависят от региона. В США ограничение на чтение и запись 40 КБ остается ограниченным на таблицу (80 КБ на учетную запись), а в других регионах ограничение на 10 КБ на таблицу составляет 20 КБ.
-
Предусмотренное увеличение и уменьшение пропускной способности — вы можете увеличивать это так часто, как это необходимо, но снижение остается ограниченным не более четырех раз в день на стол.
-
Размер таблицы и количество для каждой учетной записи — Размеры таблиц не имеют ограничений, но для учетных записей есть ограничение в 256 таблиц, если только вы не запросите более высокий предел
-
Вторичные индексы на таблицу — пять локальных и пять глобальных разрешены.
-
Прогнозируемые атрибуты вторичного индекса на таблицу — DynamoDB допускает 20 атрибутов.
-
Длина ключа ключа и его значения — их минимальная длина составляет 1 байт, а максимальная — 2048 байт, однако DynamoDB не устанавливает ограничений на значения.
-
Длина и значения ключа сортировки — его минимальная длина составляет 1 байт, а максимальная — 1024 байта, без ограничений для значений, если в таблице не используется локальный вторичный индекс.
-
Имена табличных и вторичных индексов. Имена должны содержать не менее 3 символов в длину и не более 255. В них используются следующие символы: AZ, az, 0-9, «_», «-» и «.» ,
-
Имена атрибутов — один символ остается минимальным, а 64 КБ максимальным, за исключением ключей и определенных атрибутов.
-
Зарезервированные слова — DynamoDB не запрещает использование зарезервированных слов в качестве имен.
-
Длина выражения — строки выражения имеют ограничение 4 КБ. Выражения атрибутов имеют ограничение в 255 байтов. Переменные подстановки выражения имеют ограничение в 2 МБ.
Размеры единицы емкости — Единица емкости чтения — это единое согласованное чтение в секунду для элементов размером не более 4 КБ. Емкость записи — это одна запись в секунду для элементов размером не более 1 КБ.
Предоставленная пропускная способность мин / макс. — Все таблицы и глобальные вторичные индексы имеют как минимум одну единицу чтения и одну единицу емкости записи. Максимумы зависят от региона. В США ограничение на чтение и запись 40 КБ остается ограниченным на таблицу (80 КБ на учетную запись), а в других регионах ограничение на 10 КБ на таблицу составляет 20 КБ.
Предусмотренное увеличение и уменьшение пропускной способности — вы можете увеличивать это так часто, как это необходимо, но снижение остается ограниченным не более четырех раз в день на стол.
Размер таблицы и количество для каждой учетной записи — Размеры таблиц не имеют ограничений, но для учетных записей есть ограничение в 256 таблиц, если только вы не запросите более высокий предел
Вторичные индексы на таблицу — пять локальных и пять глобальных разрешены.
Прогнозируемые атрибуты вторичного индекса на таблицу — DynamoDB допускает 20 атрибутов.
Длина ключа ключа и его значения — их минимальная длина составляет 1 байт, а максимальная — 2048 байт, однако DynamoDB не устанавливает ограничений на значения.
Длина и значения ключа сортировки — его минимальная длина составляет 1 байт, а максимальная — 1024 байта, без ограничений для значений, если в таблице не используется локальный вторичный индекс.
Имена табличных и вторичных индексов. Имена должны содержать не менее 3 символов в длину и не более 255. В них используются следующие символы: AZ, az, 0-9, «_», «-» и «.» ,
Имена атрибутов — один символ остается минимальным, а 64 КБ максимальным, за исключением ключей и определенных атрибутов.
Зарезервированные слова — DynamoDB не запрещает использование зарезервированных слов в качестве имен.
Длина выражения — строки выражения имеют ограничение 4 КБ. Выражения атрибутов имеют ограничение в 255 байтов. Переменные подстановки выражения имеют ограничение в 2 МБ.
DynamoDB — Основные понятия
Перед использованием DynamoDB вы должны ознакомиться с его основными компонентами и экосистемой. В экосистеме DynamoDB вы работаете с таблицами, атрибутами и элементами. Таблица содержит наборы элементов, а элементы содержат наборы атрибутов. Атрибут — это фундаментальный элемент данных, не требующий дальнейшей декомпозиции, т. Е. Поле.
Основной ключ
Первичные ключи служат средством уникальной идентификации элементов таблицы, а вторичные индексы обеспечивают гибкость запросов. DynamoDB осуществляет потоковую запись событий, изменяя данные таблицы.
Создание таблицы требует не только задания имени, но и первичного ключа; который идентифицирует элементы таблицы. Нет двух предметов, которые разделяют ключ. DynamoDB использует два типа первичных ключей —
-
Ключ раздела — этот простой первичный ключ состоит из одного атрибута, называемого «ключом раздела». Внутри DynamoDB использует значение ключа в качестве входных данных для хэш-функции для определения хранилища.
-
Ключ раздела и ключ сортировки — этот ключ, известный как «составной первичный ключ», состоит из двух атрибутов.
-
Ключ раздела и
-
Ключ сортировки.
DynamoDB применяет первый атрибут к хеш-функции и сохраняет элементы с одним и тем же ключом разделения; с их порядком, определенным ключом сортировки. Элементы могут разделять ключи разделов, но не сортировать ключи.
-
Ключ раздела — этот простой первичный ключ состоит из одного атрибута, называемого «ключом раздела». Внутри DynamoDB использует значение ключа в качестве входных данных для хэш-функции для определения хранилища.
Ключ раздела и ключ сортировки — этот ключ, известный как «составной первичный ключ», состоит из двух атрибутов.
Ключ раздела и
Ключ сортировки.
DynamoDB применяет первый атрибут к хеш-функции и сохраняет элементы с одним и тем же ключом разделения; с их порядком, определенным ключом сортировки. Элементы могут разделять ключи разделов, но не сортировать ключи.
Атрибуты первичного ключа допускают только скалярные (одиночные) значения; и строковые, числовые или двоичные типы данных. Неключевые атрибуты не имеют этих ограничений.
Вторичные индексы
Эти индексы позволяют запрашивать данные таблицы с помощью альтернативного ключа. Хотя DynamoDB не заставляет их использовать, они оптимизируют запросы.
DynamoDB использует два типа вторичных индексов —
-
Глобальный вторичный индекс — этот индекс обладает ключами секционирования и сортировки, которые могут отличаться от ключей таблицы.
-
Локальный вторичный индекс — этот индекс имеет ключ раздела, идентичный таблице, однако его ключ сортировки отличается.
Глобальный вторичный индекс — этот индекс обладает ключами секционирования и сортировки, которые могут отличаться от ключей таблицы.
Локальный вторичный индекс — этот индекс имеет ключ раздела, идентичный таблице, однако его ключ сортировки отличается.
API
Операции API, предлагаемые DynamoDB, включают в себя операции плоскости управления, плоскости данных (например, создание, чтение, обновление и удаление) и потоков. В операциях плоскости управления вы создаете и управляете таблицами с помощью следующих инструментов:
- CreateTable
- DescribeTable
- ListTables
- UpdateTable
- DeleteTable
В плоскости данных вы выполняете операции CRUD с помощью следующих инструментов:
| Создайте | Читать | Обновить | удалять |
|---|---|---|---|
|
PutItem BatchWriteItem |
GetItem BatchGetItem запрос сканирование |
UpdateItem |
Удалить пункт BatchWriteItem |
PutItem
BatchWriteItem
GetItem
BatchGetItem
запрос
сканирование
Удалить пункт
BatchWriteItem
Потоковые операции управляют таблицей потоков. Вы можете просмотреть следующие инструменты потока —
- ListStreams
- DescribeStream
- GetShardIterator
- GetRecords
Предоставленная пропускная способность
При создании таблицы вы указываете выделенную пропускную способность, которая резервирует ресурсы для чтения и записи. Вы используете единицы мощности для измерения и установки пропускной способности.
Когда приложения превышают установленную пропускную способность, запросы не выполняются. Консоль DynamoDB GUI позволяет отслеживать установленную и используемую пропускную способность для лучшей и динамической подготовки.
Последовательность чтения
DynamoDB использует в конечном итоге согласованные и строго согласованные операции чтения для поддержки потребностей динамических приложений. В конечном итоге согласованные чтения не всегда доставляют текущие данные.
Строго согласованные чтения всегда доставляют текущие данные (за исключением отказа оборудования или проблем с сетью). В конечном итоге непротиворечивые чтения служат настройкой по умолчанию, для изменения которой требуется значение true в параметре ConsistentRead .
Перегородки
DynamoDB использует разделы для хранения данных. Эти распределения памяти для таблиц имеют поддержку SSD и автоматически реплицируются по зонам. DynamoDB управляет всеми задачами раздела, не требуя участия пользователя.
При создании таблицы таблица переходит в состояние CREATING, в котором выделяются разделы. Когда он достигает состояния ACTIVE, вы можете выполнять операции. Система изменяет разделы, когда ее емкость достигает максимума или когда вы меняете пропускную способность.
DynamoDB — Окружающая среда
Среда DynamoDB состоит только из использования вашей учетной записи Amazon Web Services для доступа к консоли графического интерфейса DynamoDB, однако вы также можете выполнить локальную установку.
Перейдите на следующий веб-сайт — https://aws.amazon.com/dynamodb/
Нажмите кнопку «Начало работы с Amazon DynamoDB» или кнопку «Создать учетную запись AWS», если у вас нет учетной записи Amazon Web Services. Простой, управляемый процесс проинформирует вас обо всех связанных с этим сборах и требованиях.
После выполнения всех необходимых шагов процесса у вас будет доступ. Просто войдите в консоль AWS, а затем перейдите к консоли DynamoDB.
Обязательно удалите неиспользованный или ненужный материал, чтобы избежать связанных с этим сборов.
Локальная установка
AWS (Amazon Web Service) предоставляет версию DynamoDB для локальных установок. Он поддерживает создание приложений без веб-службы или подключения. Это также снижает выделенную пропускную способность, хранение данных и плату за передачу, предоставляя локальную базу данных. Это руководство предполагает локальную установку.
Когда вы будете готовы к развертыванию, вы можете внести небольшие изменения в свое приложение, чтобы преобразовать его в использование AWS.
Установочный файл является исполняемым файлом .jar . Он работает в Linux, Unix, Windows и любых других ОС с поддержкой Java. Загрузите файл, используя одну из следующих ссылок —
-
Тарбол — http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.tar.gz
-
Zip-архив — http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.zip
Тарбол — http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.tar.gz
Zip-архив — http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.zip
Примечание. Другие репозитории предлагают файл, но не обязательно последнюю версию. Используйте ссылки выше для получения обновленных файлов установки. Также убедитесь, что у вас установлена Java Runtime Engine (JRE) версии 6.x или более поздней. DynamoDB не может работать с более старыми версиями.
После загрузки соответствующего архива, распакуйте его каталог (DynamoDBLocal.jar) и поместите его в нужное место.
Затем вы можете запустить DynamoDB, открыв командную строку, перейдя в каталог, содержащий DynamoDBLocal.jar, и введя следующую команду:
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDb
Вы также можете остановить DynamoDB, закрыв командную строку, которая использовалась для его запуска.
Рабочая обстановка
Вы можете использовать оболочку JavaScript, консоль с графическим интерфейсом и несколько языков для работы с DynamoDB. Доступные языки: Ruby, Java, Python, C #, Erlang, PHP и Perl.
В этом уроке мы используем примеры консолей Java и GUI для ясности концептуальности и кода. Установите Java IDE, AWS SDK для Java и настройте учетные данные безопасности AWS для Java SDK, чтобы использовать Java.
Преобразование из локального кода в код веб-службы
Когда вы будете готовы к развертыванию, вам нужно будет изменить свой код. Корректировки зависят от языка кода и других факторов. Основное изменение состоит просто в изменении конечной точки с локальной точки на регион AWS. Другие изменения требуют более глубокого анализа вашего приложения.
Локальная установка отличается от веб-службы во многих отношениях, включая, помимо прочего, следующие ключевые отличия:
-
Локальная установка создает таблицы немедленно, но служба занимает гораздо больше времени.
-
Локальная установка игнорирует пропускную способность.
-
Удаление происходит немедленно при локальной установке.
-
Чтение / запись происходят быстро при локальной установке из-за отсутствия сетевых издержек.
Локальная установка создает таблицы немедленно, но служба занимает гораздо больше времени.
Локальная установка игнорирует пропускную способность.
Удаление происходит немедленно при локальной установке.
Чтение / запись происходят быстро при локальной установке из-за отсутствия сетевых издержек.
DynamoDB — Операционные инструменты
DynamoDB предоставляет три варианта выполнения операций: веб-консоль с графическим интерфейсом, оболочка JavaScript и язык программирования по вашему выбору.
В этом руководстве мы сосредоточимся на использовании консоли GUI и языка Java для ясности и концептуального понимания.
Консоль GUI
Консоль с графическим интерфейсом или Консоль управления AWS для Amazon DynamoDB можно найти по следующему адресу — https://console.aws.amazon.com/dynamodb/home.
Позволяет выполнять следующие задачи —
- CRUD
- Просмотр элементов таблицы
- Выполнять запросы к таблицам
- Установить сигналы тревоги для мониторинга емкости таблицы
- Просмотр таблицы показателей в режиме реального времени
- Просмотр таблицы сигналов

Если ваша учетная запись DynamoDB не имеет таблиц, при доступе она поможет вам создать таблицу. Его главный экран предлагает три ярлыка для выполнения общих операций —
- Создать таблицы
- Добавить и запросить таблицы
- Мониторинг и управление таблицами
Оболочка JavaScript
DynamoDB включает в себя интерактивную оболочку JavaScript. Оболочка работает в веб-браузере, и в число рекомендуемых браузеров входят Firefox и Chrome.
Примечание. Использование других браузеров может привести к ошибкам.
Чтобы открыть оболочку, откройте веб-браузер и введите следующий адрес — http: // localhost: 8000 / shell
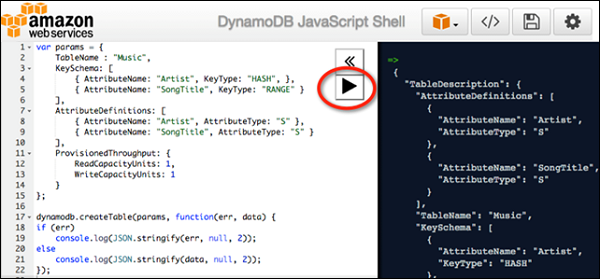
Используйте оболочку, введя JavaScript на левой панели и нажав кнопку «Play» в правом верхнем углу левой панели, чтобы запустить код. Результаты кода отображаются на правой панели.
DynamoDB и Java
Используйте Java с DynamoDB, используя вашу среду разработки Java. Операции подтверждают нормальный синтаксис и структуру Java.
DynamoDB — Типы данных
Типы данных, поддерживаемые DynamoDB, включают в себя типы данных, специфичные для атрибутов, действий и выбранного языка кодирования.
Типы данных атрибута
DynamoDB поддерживает большой набор типов данных для атрибутов таблицы. Каждый тип данных попадает в одну из трех следующих категорий:
-
Скалярный. Эти типы представляют одно значение и включают число, строку, двоичный код, логическое значение и ноль.
-
Документ — эти типы представляют собой сложную структуру, обладающую вложенными атрибутами, и включают списки и карты.
-
Set — эти типы представляют несколько скаляров и включают в себя наборы строк, наборы чисел и двоичные наборы.
Скалярный. Эти типы представляют одно значение и включают число, строку, двоичный код, логическое значение и ноль.
Документ — эти типы представляют собой сложную структуру, обладающую вложенными атрибутами, и включают списки и карты.
Set — эти типы представляют несколько скаляров и включают в себя наборы строк, наборы чисел и двоичные наборы.
Вспомните DynamoDB как базу данных NoSQL без схемы, для которой не нужны определения атрибутов или типов данных при создании таблицы. Для этого требуются только типы данных атрибута первичного ключа в отличие от СУБД, для которых требуются типы данных столбца при создании таблицы.
Скаляры
-
Числа — они ограничены 38 цифрами и могут быть положительными, отрицательными или нулевыми.
-
String — Это Unicode, использующий UTF-8, с минимальной длиной> 0 и максимальной 400 КБ.
-
Двоичные — они хранят любые двоичные данные, например, зашифрованные данные, изображения и сжатый текст. DynamoDB рассматривает свои байты как неподписанные.
-
Boolean — Они хранят истину или ложь.
-
Null — они представляют неизвестное или неопределенное состояние.
Числа — они ограничены 38 цифрами и могут быть положительными, отрицательными или нулевыми.
String — Это Unicode, использующий UTF-8, с минимальной длиной> 0 и максимальной 400 КБ.
Двоичные — они хранят любые двоичные данные, например, зашифрованные данные, изображения и сжатый текст. DynamoDB рассматривает свои байты как неподписанные.
Boolean — Они хранят истину или ложь.
Null — они представляют неизвестное или неопределенное состояние.
Документ
-
Список — хранит коллекции упорядоченных значений и использует квадратные ([…]) скобки.
-
Карта — хранит неупорядоченные коллекции пар имя-значение и использует фигурные ({…}) фигурные скобки.
Список — хранит коллекции упорядоченных значений и использует квадратные ([…]) скобки.
Карта — хранит неупорядоченные коллекции пар имя-значение и использует фигурные ({…}) фигурные скобки.
Задавать
Наборы должны содержать элементы одного типа, будь то число, строка или двоичный файл. Единственные ограничения, установленные для наборов, состоят из ограничения размера элемента в 400 КБ, причем каждый элемент является уникальным.
Типы данных действий
DynamoDB API содержит различные типы данных, используемые действиями. Вы можете просмотреть выбор следующих ключевых типов —
-
AttributeDefinition — представляет таблицу ключей и схему индекса.
-
Емкость — представляет собой объем пропускной способности, потребляемой таблицей или индексом.
-
CreateGlobalSecondaryIndexAction — представляет новый глобальный вторичный индекс, добавленный в таблицу.
-
LocalSecondaryIndex — представляет свойства локального вторичного индекса.
-
ProvisionedThroughput — представляет выделенную пропускную способность для индекса или таблицы.
-
PutRequest — представляет запросы PutItem.
-
TableDescription — представляет свойства таблицы.
AttributeDefinition — представляет таблицу ключей и схему индекса.
Емкость — представляет собой объем пропускной способности, потребляемой таблицей или индексом.
CreateGlobalSecondaryIndexAction — представляет новый глобальный вторичный индекс, добавленный в таблицу.
LocalSecondaryIndex — представляет свойства локального вторичного индекса.
ProvisionedThroughput — представляет выделенную пропускную способность для индекса или таблицы.
PutRequest — представляет запросы PutItem.
TableDescription — представляет свойства таблицы.
Поддерживаемые типы данных Java
DynamoDB обеспечивает поддержку примитивных типов данных, наборов коллекций и произвольных типов для Java.
DynamoDB — Создать таблицу
Создание таблицы обычно состоит из порождения таблицы, присвоения ей имени, установления атрибутов ее первичного ключа и установки типов данных атрибута.
Используйте GUI Console, Java или другой вариант для выполнения этих задач.
Создать таблицу с помощью консоли GUI
Создайте таблицу, открыв консоль по адресу https://console.aws.amazon.com/dynamodb . Затем выберите опцию «Создать таблицу».

В нашем примере создается таблица, заполненная информацией о продукте, с продуктами с уникальными атрибутами, идентифицированными по идентификационному номеру (числовой атрибут). На экране Создать таблицу введите имя таблицы в поле имени таблицы; введите первичный ключ (ID) в поле ключа раздела; и введите «Число» для типа данных.
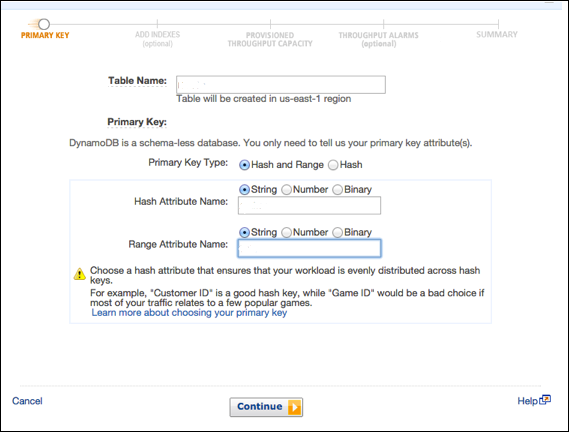
После ввода всей информации выберите Создать .
Создать таблицу с использованием Java
Используйте Java для создания той же таблицы. Его первичный ключ состоит из следующих двух атрибутов:
-
ID — используйте ключ раздела и ScalarAttributeType N , что означает число.
-
Номенклатура — используйте ключ сортировки и ScalarAttributeType S , что означает строку.
ID — используйте ключ раздела и ScalarAttributeType N , что означает число.
Номенклатура — используйте ключ сортировки и ScalarAttributeType S , что означает строку.
Java использует метод createTable для генерации таблицы; и в вызове указываются имя таблицы, атрибуты первичного ключа и типы данных атрибута.
Вы можете просмотреть следующий пример —
import java.util.Arrays; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.model.AttributeDefinition; import com.amazonaws.services.dynamodbv2.model.KeySchemaElement; import com.amazonaws.services.dynamodbv2.model.KeyType; import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput; import com.amazonaws.services.dynamodbv2.model.ScalarAttributeType; public class ProductsCreateTable { public static void main(String[] args) throws Exception { AmazonDynamoDBClient client = new AmazonDynamoDBClient() .withEndpoint("http://localhost:8000"); DynamoDB dynamoDB = new DynamoDB(client); String tableName = "Products"; try { System.out.println("Creating the table, wait..."); Table table = dynamoDB.createTable (tableName, Arrays.asList ( new KeySchemaElement("ID", KeyType.HASH), // the partition key // the sort key new KeySchemaElement("Nomenclature", KeyType.RANGE) ), Arrays.asList ( new AttributeDefinition("ID", ScalarAttributeType.N), new AttributeDefinition("Nomenclature", ScalarAttributeType.S) ), new ProvisionedThroughput(10L, 10L) ); table.waitForActive(); System.out.println("Table created successfully. Status: " + table.getDescription().getTableStatus()); } catch (Exception e) { System.err.println("Cannot create the table: "); System.err.println(e.getMessage()); } } }
В приведенном выше примере обратите внимание на конечную точку: .withEndpoint .
Это указывает на использование локальной установки с использованием localhost. Также обратите внимание на обязательный параметр ProvisionedThroughput , который локальная установка игнорирует.
DynamoDB — таблица загрузки
Загрузка таблицы обычно состоит из создания исходного файла, обеспечения соответствия исходного файла синтаксису, совместимому с DynamoDB, отправки исходного файла в место назначения и последующего подтверждения успешного заполнения.
Используйте консоль графического интерфейса, Java или другой вариант для выполнения задачи.
Загрузить таблицу с помощью консоли GUI
Загрузите данные, используя комбинацию командной строки и консоли. Вы можете загрузить данные несколькими способами, некоторые из которых следующие:
- Консоль
- Командная строка
- Код, а также
- Data Pipeline (функция обсуждается позже в руководстве)
Однако для скорости в этом примере используются как оболочка, так и консоль. Сначала загрузите исходные данные в место назначения со следующим синтаксисом:
aws dynamodb batch-write-item -–request-items file://[filename]
Например —
aws dynamodb batch-write-item -–request-items file://MyProductData.json
Проверьте успешность операции, открыв консоль по адресу —
https://console.aws.amazon.com/dynamodb
Выберите Таблицы на панели навигации и выберите таблицу назначения из списка таблиц.
Выберите вкладку « Элементы », чтобы просмотреть данные, которые вы использовали для заполнения таблицы. Выберите Отмена, чтобы вернуться к списку таблиц.
Загрузить таблицу с помощью Java
Используйте Java, сначала создав исходный файл. Наш исходный файл использует формат JSON. Каждый продукт имеет два атрибута первичного ключа (ID и номенклатура) и карту JSON (Stat) —
[ { "ID" : ... , "Nomenclature" : ... , "Stat" : { ... } }, { "ID" : ... , "Nomenclature" : ... , "Stat" : { ... } }, ... ]
Вы можете просмотреть следующий пример —
{ "ID" : 122, "Nomenclature" : "Particle Blaster 5000", "Stat" : { "Manufacturer" : "XYZ Inc.", "sales" : "1M+", "quantity" : 500, "img_src" : "http://www.xyz.com/manuals/particleblaster5000.jpg", "description" : "A laser cutter used in plastic manufacturing." } }
Следующим шагом является размещение файла в каталоге, используемом вашим приложением.
Java в основном использует методы putItem и path для выполнения загрузки.
Вы можете просмотреть следующий пример кода для обработки файла и его загрузки —
import java.io.File; import java.util.Iterator; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.Table; import com.fasterxml.jackson.core.JsonFactory; import com.fasterxml.jackson.core.JsonParser; import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper import com.fasterxml.jackson.databind.node.ObjectNode; public class ProductsLoadData { public static void main(String[] args) throws Exception { AmazonDynamoDBClient client = new AmazonDynamoDBClient() .withEndpoint("http://localhost:8000"); DynamoDB dynamoDB = new DynamoDB(client); Table table = dynamoDB.getTable("Products"); JsonParser parser = new JsonFactory() .createParser(new File("productinfo.json")); JsonNode rootNode = new ObjectMapper().readTree(parser); Iterator<JsonNode> iter = rootNode.iterator(); ObjectNode currentNode; while (iter.hasNext()) { currentNode = (ObjectNode) iter.next(); int ID = currentNode.path("ID").asInt(); String Nomenclature = currentNode.path("Nomenclature").asText(); try { table.putItem(new Item() .withPrimaryKey("ID", ID, "Nomenclature", Nomenclature) .withJSON("Stat", currentNode.path("Stat").toString())); System.out.println("Successful load: " + ID + " " + Nomenclature); } catch (Exception e) { System.err.println("Cannot add product: " + ID + " " + Nomenclature); System.err.println(e.getMessage()); break; } } parser.close(); } }
DynamoDB — таблица запросов
Для запроса таблицы в первую очередь требуется выбрать таблицу, указать ключ раздела и выполнить запрос; с возможностью использования вторичных индексов и выполнения более глубокой фильтрации с помощью операций сканирования.
Используйте GUI Console, Java или другой вариант для выполнения задачи.
Таблица запросов с использованием консоли GUI
Выполните несколько простых запросов, используя ранее созданные таблицы. Сначала откройте консоль по адресу https://console.aws.amazon.com/dynamodb.
Выберите Таблицы на панели навигации и выберите Ответить из списка таблиц. Затем выберите вкладку « Элементы », чтобы увидеть загруженные данные.
Выберите ссылку на фильтрацию данных («Сканировать: [Таблица] Ответить») под кнопкой « Создать элемент» .
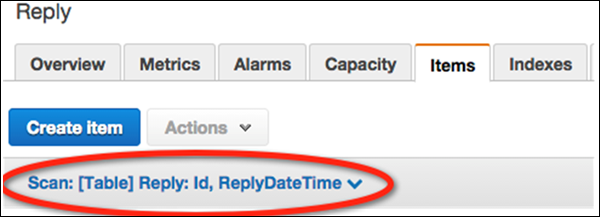
На экране фильтрации выберите Запрос для операции. Введите соответствующее значение ключа раздела и нажмите « Пуск» .
Таблица ответов затем возвращает соответствующие элементы.
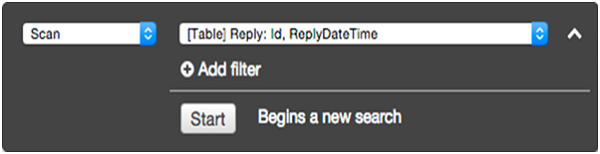
Таблица запросов с использованием Java
Используйте метод запроса в Java для выполнения операций поиска данных. Требуется указать значение ключа раздела, причем ключ сортировки необязателен.
Кодируйте Java-запрос, сначала создав объект querySpec с описанием параметров. Затем передайте объект в метод запроса. Мы используем ключ раздела из предыдущих примеров.
Вы можете просмотреть следующий пример —
import java.util.HashMap; import java.util.Iterator; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.ItemCollection; import com.amazonaws.services.dynamodbv2.document.QueryOutcome; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec; import com.amazonaws.services.dynamodbv2.document.utils.NameMap; public class ProductsQuery { public static void main(String[] args) throws Exception { AmazonDynamoDBClient client = new AmazonDynamoDBClient() .withEndpoint("http://localhost:8000"); DynamoDB dynamoDB = new DynamoDB(client); Table table = dynamoDB.getTable("Products"); HashMap<String, String> nameMap = new HashMap<String, String>(); nameMap.put("#ID", "ID"); HashMap<String, Object> valueMap = new HashMap<String, Object>(); valueMap.put(":xxx", 122); QuerySpec querySpec = new QuerySpec() .withKeyConditionExpression("#ID = :xxx") .withNameMap(new NameMap().with("#ID", "ID")) .withValueMap(valueMap); ItemCollection<QueryOutcome> items = null; Iterator<Item> iterator = null; Item item = null; try { System.out.println("Product with the ID 122"); items = table.query(querySpec); iterator = items.iterator(); while (iterator.hasNext()) { item = iterator.next(); System.out.println(item.getNumber("ID") + ": " + item.getString("Nomenclature")); } } catch (Exception e) { System.err.println("Cannot find products with the ID number 122"); System.err.println(e.getMessage()); } } }
Обратите внимание, что в запросе используется ключ раздела, однако вторичные индексы предоставляют другой вариант для запросов. Их гибкость позволяет запрашивать неключевые атрибуты — тема, которая будет обсуждаться позже в этом руководстве.
Метод сканирования также поддерживает операции поиска, собирая все данные таблицы. Необязательное выражение .withFilterExpression предотвращает появление в результатах элементов вне заданных критериев.
Позже в этом уроке мы подробно обсудим сканирование . Теперь взглянем на следующий пример:
import java.util.Iterator; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.ItemCollection; import com.amazonaws.services.dynamodbv2.document.ScanOutcome; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.spec.ScanSpec; import com.amazonaws.services.dynamodbv2.document.utils.NameMap; import com.amazonaws.services.dynamodbv2.document.utils.ValueMap; public class ProductsScan { public static void main(String[] args) throws Exception { AmazonDynamoDBClient client = new AmazonDynamoDBClient() .withEndpoint("http://localhost:8000"); DynamoDB dynamoDB = new DynamoDB(client); Table table = dynamoDB.getTable("Products"); ScanSpec scanSpec = new ScanSpec() .withProjectionExpression("#ID, Nomenclature , stat.sales") .withFilterExpression("#ID between :start_id and :end_id") .withNameMap(new NameMap().with("#ID", "ID")) .withValueMap(new ValueMap().withNumber(":start_id", 120) .withNumber(":end_id", 129)); try { ItemCollection<ScanOutcome> items = table.scan(scanSpec); Iterator<Item> iter = items.iterator(); while (iter.hasNext()) { Item item = iter.next(); System.out.println(item.toString()); } } catch (Exception e) { System.err.println("Cannot perform a table scan:"); System.err.println(e.getMessage()); } } }
DynamoDB — Удалить таблицу
В этой главе мы обсудим, как мы можем удалить таблицу, а также различные способы удаления таблицы.
Удаление таблицы — это простая операция, требующая чуть больше, чем имя таблицы. Используйте консоль GUI, Java или любую другую опцию для выполнения этой задачи.
Удалить таблицу с помощью консоли GUI
Выполните операцию удаления, сначала получив доступ к консоли по адресу —
https://console.aws.amazon.com/dynamodb .
Выберите « Таблицы» на панели навигации и выберите таблицу, которую нужно удалить, из списка таблиц, как показано на следующем снимке экрана.
Наконец, выберите Удалить таблицу . После выбора Удалить таблицу появляется подтверждение. Ваша таблица будет удалена.
Удалить таблицу с помощью Java
Используйте метод удаления, чтобы удалить таблицу. Ниже приведен пример, чтобы лучше объяснить концепцию.
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Table; public class ProductsDeleteTable { public static void main(String[] args) throws Exception { AmazonDynamoDBClient client = new AmazonDynamoDBClient() .withEndpoint("http://localhost:8000"); DynamoDB dynamoDB = new DynamoDB(client); Table table = dynamoDB.getTable("Products"); try { System.out.println("Performing table delete, wait..."); table.delete(); table.waitForDelete(); System.out.print("Table successfully deleted."); } catch (Exception e) { System.err.println("Cannot perform table delete: "); System.err.println(e.getMessage()); } } }
DynamoDB — API интерфейс
DynamoDB предлагает широкий набор мощных API-инструментов для манипулирования таблицами, чтения и модификации данных.
Amazon рекомендует использовать AWS SDK (например, Java SDK) вместо вызова низкоуровневых API. Библиотеки делают ненужным взаимодействие с низкоуровневыми API. Библиотеки упрощают общие задачи, такие как аутентификация, сериализация и соединения.
Управлять таблицами
DynamoDB предлагает пять низкоуровневых действий для Table Management —
-
CreateTable — это порождает таблицу и включает пропускную способность, установленную пользователем. Требуется установить первичный ключ, будь то составной или простой. Это также позволяет один или несколько вторичных индексов.
-
ListTables — предоставляет список всех таблиц в учетной записи текущего пользователя AWS и привязан к их конечной точке.
-
UpdateTable — изменяет пропускную способность и пропускную способность глобального вторичного индекса.
-
DescribeTable — предоставляет метаданные таблицы; например, состояние, размер и индексы.
-
DeleteTable — это просто стирает таблицу и ее индексы.
CreateTable — это порождает таблицу и включает пропускную способность, установленную пользователем. Требуется установить первичный ключ, будь то составной или простой. Это также позволяет один или несколько вторичных индексов.
ListTables — предоставляет список всех таблиц в учетной записи текущего пользователя AWS и привязан к их конечной точке.
UpdateTable — изменяет пропускную способность и пропускную способность глобального вторичного индекса.
DescribeTable — предоставляет метаданные таблицы; например, состояние, размер и индексы.
DeleteTable — это просто стирает таблицу и ее индексы.
Читать данные
DynamoDB предлагает четыре низкоуровневых действия для чтения данных —
-
GetItem — принимает первичный ключ и возвращает атрибуты связанного элемента. Он допускает изменения в настройках по умолчанию, которые в конечном итоге соответствуют настройкам чтения.
-
BatchGetItem — выполняет несколько запросов GetItem для нескольких элементов через первичные ключи с возможностью выбора одной или нескольких таблиц. Возвращает не более 100 предметов и должно оставаться менее 16 МБ. Это позволяет в конечном итоге согласованные и строго согласованные чтения.
-
Сканирование — считывает все элементы таблицы и выдает в итоге согласованный набор результатов. Вы можете фильтровать результаты по условиям. Он избегает использования индекса и сканирует всю таблицу, поэтому не используйте его для запросов, требующих предсказуемости.
-
Запрос — возвращает один или несколько элементов таблицы или элементов вторичного индекса. Он использует указанное значение для ключа раздела и позволяет использовать операторы сравнения для сужения области действия. Он включает поддержку обоих типов согласованности, и каждый ответ соответствует предельному размеру в 1 МБ.
GetItem — принимает первичный ключ и возвращает атрибуты связанного элемента. Он допускает изменения в настройках по умолчанию, которые в конечном итоге соответствуют настройкам чтения.
BatchGetItem — выполняет несколько запросов GetItem для нескольких элементов через первичные ключи с возможностью выбора одной или нескольких таблиц. Возвращает не более 100 предметов и должно оставаться менее 16 МБ. Это позволяет в конечном итоге согласованные и строго согласованные чтения.
Сканирование — считывает все элементы таблицы и выдает в итоге согласованный набор результатов. Вы можете фильтровать результаты по условиям. Он избегает использования индекса и сканирует всю таблицу, поэтому не используйте его для запросов, требующих предсказуемости.
Запрос — возвращает один или несколько элементов таблицы или элементов вторичного индекса. Он использует указанное значение для ключа раздела и позволяет использовать операторы сравнения для сужения области действия. Он включает поддержку обоих типов согласованности, и каждый ответ соответствует предельному размеру в 1 МБ.
Изменить данные
DynamoDB предлагает четыре низкоуровневых действия для модификации данных —
-
PutItem — создает новый элемент или заменяет существующие. При обнаружении идентичных первичных ключей по умолчанию он заменяет элемент. Условные операторы позволяют работать по умолчанию и заменять элементы только при определенных условиях.
-
BatchWriteItem — выполняет несколько запросов PutItem и DeleteItem, а также несколько таблиц. Если один запрос не выполняется, он не влияет на всю операцию. Его кепка вмещает 25 предметов размером 16 МБ.
-
UpdateItem — изменяет существующие атрибуты элемента и разрешает использование условных операторов для выполнения обновлений только при определенных условиях.
-
DeleteItem — использует первичный ключ для удаления элемента, а также позволяет использовать условные операторы для указания условий для удаления.
PutItem — создает новый элемент или заменяет существующие. При обнаружении идентичных первичных ключей по умолчанию он заменяет элемент. Условные операторы позволяют работать по умолчанию и заменять элементы только при определенных условиях.
BatchWriteItem — выполняет несколько запросов PutItem и DeleteItem, а также несколько таблиц. Если один запрос не выполняется, он не влияет на всю операцию. Его кепка вмещает 25 предметов размером 16 МБ.
UpdateItem — изменяет существующие атрибуты элемента и разрешает использование условных операторов для выполнения обновлений только при определенных условиях.
DeleteItem — использует первичный ключ для удаления элемента, а также позволяет использовать условные операторы для указания условий для удаления.
DynamoDB — Создание предметов
Создание элемента в DynamoDB состоит, главным образом, из спецификации элемента и атрибута и возможности задания условий. Каждый элемент существует в виде набора атрибутов, каждому названному атрибуту присваивается значение определенного типа.
Типы значений включают скаляр, документ или набор. Элементы имеют ограничение размера 400 КБ, с возможностью любого количества атрибутов, способных вписаться в этот предел. Размеры имени и значения (длина в двоичном формате и длина UTF-8) определяют размер элемента. Использование коротких имен атрибутов помогает минимизировать размер элемента.
Примечание. Необходимо указать все атрибуты первичного ключа, причем первичным ключам требуется только ключ раздела; и составные ключи, требующие как раздел, так и ключ сортировки.
Кроме того, помните, что таблицы не имеют предопределенной схемы. Вы можете хранить совершенно разные наборы данных в одной таблице.
Используйте консоль с графическим интерфейсом, Java или другой инструмент для выполнения этой задачи.
Как создать элемент с помощью консоли GUI?
Перейдите к консоли. На панели навигации слева выберите Таблицы . Выберите имя таблицы для использования в качестве места назначения, а затем выберите вкладку « Элементы », как показано на следующем снимке экрана.
Выберите Создать элемент . Экран Create Item предоставляет интерфейс для ввода требуемых значений атрибутов. Любые вторичные индексы также должны быть введены.
Если вам требуется больше атрибутов, выберите меню действий слева от сообщения . Затем выберите « Добавить» и укажите нужный тип данных.
После ввода всей необходимой информации выберите Сохранить, чтобы добавить элемент.
Как использовать Java в создании предметов?
Использование Java в операциях создания элементов состоит из создания экземпляра класса DynamoDB, экземпляра класса Table, экземпляра класса Item и указания первичного ключа и атрибутов создаваемого элемента. Затем добавьте новый элемент с помощью метода putItem.
пример
DynamoDB dynamoDB = new DynamoDB (new AmazonDynamoDBClient( new ProfileCredentialsProvider())); Table table = dynamoDB.getTable("ProductList"); // Spawn a related items list List<Number> RELItems = new ArrayList<Number>(); RELItems.add(123); RELItems.add(456); RELItems.add(789); //Spawn a product picture map Map<String, String> photos = new HashMap<String, String>(); photos.put("Anterior", "http://xyz.com/products/101_front.jpg"); photos.put("Posterior", "http://xyz.com/products/101_back.jpg"); photos.put("Lateral", "http://xyz.com/products/101_LFTside.jpg"); //Spawn a product review map Map<String, List<String>> prodReviews = new HashMap<String, List<String>>(); List<String> fiveStarRVW = new ArrayList<String>(); fiveStarRVW.add("Shocking high performance."); fiveStarRVW.add("Unparalleled in its market."); prodReviews.put("5 Star", fiveStarRVW); List<String> oneStarRVW = new ArrayList<String>(); oneStarRVW.add("The worst offering in its market."); prodReviews.put("1 Star", oneStarRVW); // Generate the item Item item = new Item() .withPrimaryKey("Id", 101) .withString("Nomenclature", "PolyBlaster 101") .withString("Description", "101 description") .withString("Category", "Hybrid Power Polymer Cutter") .withString("Make", "Brand – XYZ") .withNumber("Price", 50000) .withString("ProductCategory", "Laser Cutter") .withBoolean("Availability", true) .withNull("Qty") .withList("ItemsRelated", RELItems) .withMap("Images", photos) .withMap("Reviews", prodReviews); // Add item to the table PutItemOutcome outcome = table.putItem(item);
Вы также можете посмотреть на следующий более крупный пример.
Примечание. В следующем примере может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В следующем примере также используются Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
package com.amazonaws.codesamples.document; import java.io.IOException; import java.util.Arrays; import java.util.HashMap; import java.util.HashSet; import java.util.Map; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome; import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec; import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec; import com.amazonaws.services.dynamodbv2.document.utils.NameMap; import com.amazonaws.services.dynamodbv2.document.utils.ValueMap; import com.amazonaws.services.dynamodbv2.model.ReturnValue; public class CreateItemOpSample { static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient ( new ProfileCredentialsProvider())); static String tblName = "ProductList"; public static void main(String[] args) throws IOException { createItems(); retrieveItem(); // Execute updates updateMultipleAttributes(); updateAddNewAttribute(); updateExistingAttributeConditionally(); // Item deletion deleteItem(); } private static void createItems() { Table table = dynamoDB.getTable(tblName); try { Item item = new Item() .withPrimaryKey("ID", 303) .withString("Nomenclature", "Polymer Blaster 4000") .withStringSet( "Manufacturers", new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc."))) .withNumber("Price", 50000) .withBoolean("InProduction", true) .withString("Category", "Laser Cutter"); table.putItem(item); item = new Item() .withPrimaryKey("ID", 313) .withString("Nomenclature", "Agitatatron 2000") .withStringSet( "Manufacturers", new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc."))) .withNumber("Price", 40000) .withBoolean("InProduction", true) .withString("Category", "Agitator"); table.putItem(item); } catch (Exception e) { System.err.println("Cannot create items."); System.err.println(e.getMessage()); } } }
DynamoDB — Получение предметов
Для извлечения элемента в DynamoDB необходимо использовать GetItem и указать имя таблицы и первичный ключ элемента. Не забудьте включить полный первичный ключ, а не пропускать часть.
Например, опуская ключ сортировки составного ключа.
Поведение GetItem соответствует трем параметрам по умолчанию —
- Это выполняется как в конечном итоге последовательное чтение.
- Он предоставляет все атрибуты.
- Это не детализирует его потребление единицы мощности.
Эти параметры позволяют переопределить поведение GetItem по умолчанию.
Получить предмет
DynamoDB обеспечивает надежность благодаря поддержке нескольких копий элементов на нескольких серверах. Каждая успешная запись создает эти копии, но требует значительного времени для выполнения; смысл в конечном итоге соответствует. Это означает, что вы не можете сразу попытаться прочитать после записи элемента.
Вы можете изменить по умолчанию согласованное чтение GetItem, однако стоимость более актуальных данных остается потреблением большего количества единиц емкости; в частности, в два раза больше. Примечание. DynamoDB обычно обеспечивает согласованность каждой копии в течение секунды.
Вы можете использовать консоль с графическим интерфейсом, Java или другой инструмент для выполнения этой задачи.
Поиск предметов с использованием Java
Использование Java в операциях поиска элементов требует создания экземпляра класса DynamoDB, экземпляра класса таблицы и вызова метода getItem экземпляра таблицы. Затем укажите первичный ключ элемента.
Вы можете просмотреть следующий пример —
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); Table table = dynamoDB.getTable("ProductList"); Item item = table.getItem("IDnum", 109);
В некоторых случаях вам необходимо указать параметры для этой операции.
В следующем примере .withProjectionExpression и GetItemSpec для получения спецификаций поиска —
GetItemSpec spec = new GetItemSpec() .withPrimaryKey("IDnum", 122) .withProjectionExpression("IDnum, EmployeeName, Department") .withConsistentRead(true); Item item = table.getItem(spec); System.out.println(item.toJSONPretty());
Вы также можете рассмотреть следующий большой пример для лучшего понимания.
Примечание. В следующем примере может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В этом примере также используется Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
package com.amazonaws.codesamples.document; import java.io.IOException import java.util.Arrays; import java.util.HashMap; import java.util.HashSet; import java.util.Map; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome; import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec; import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec; import com.amazonaws.services.dynamodbv2.document.utils.NameMap; import com.amazonaws.services.dynamodbv2.document.utils.ValueMap; import com.amazonaws.services.dynamodbv2.model.ReturnValue; public class GetItemOpSample { static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); static String tblName = "ProductList"; public static void main(String[] args) throws IOException { createItems(); retrieveItem(); // Execute updates updateMultipleAttributes(); updateAddNewAttribute(); updateExistingAttributeConditionally(); // Item deletion deleteItem(); } private static void createItems() { Table table = dynamoDB.getTable(tblName); try { Item item = new Item() .withPrimaryKey("ID", 303) .withString("Nomenclature", "Polymer Blaster 4000") .withStringSet( "Manufacturers", new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc."))) .withNumber("Price", 50000) .withBoolean("InProduction", true) .withString("Category", "Laser Cutter"); table.putItem(item); item = new Item() .withPrimaryKey("ID", 313) .withString("Nomenclature", "Agitatatron 2000") .withStringSet( "Manufacturers", new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc."))) .withNumber("Price", 40000) .withBoolean("InProduction", true) .withString("Category", "Agitator"); table.putItem(item); } catch (Exception e) { System.err.println("Cannot create items."); System.err.println(e.getMessage()); } } private static void retrieveItem() { Table table = dynamoDB.getTable(tableName); try { Item item = table.getItem("ID", 303, "ID, Nomenclature, Manufacturers", null); System.out.println("Displaying retrieved items..."); System.out.println(item.toJSONPretty()); } catch (Exception e) { System.err.println("Cannot retrieve items."); System.err.println(e.getMessage()); } } }
DynamoDB — Обновление элементов
Обновление элемента в DynamoDB в основном состоит из указания полного первичного ключа и имени таблицы для элемента. Требуется новое значение для каждого атрибута, который вы изменяете. Операция использует UpdateItem , который изменяет существующие элементы или создает их при обнаружении отсутствующего элемента.
В обновлениях может потребоваться отслеживать изменения, отображая исходные и новые значения до и после операций. UpdateItem использует параметр ReturnValues для достижения этой цели.
Примечание . Операция не сообщает о потреблении единиц мощности, но вы можете использовать параметр ReturnConsumedCapacity .
Используйте консоль GUI, Java или любой другой инструмент для выполнения этой задачи.
Как обновить элементы с помощью инструментов GUI?
Перейдите к консоли. На панели навигации слева выберите Таблицы . Выберите нужную таблицу, а затем перейдите на вкладку « Элементы ».
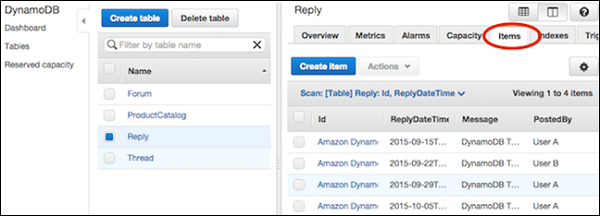
Выберите элемент, который требуется обновить, и выберите Действия | Редактировать
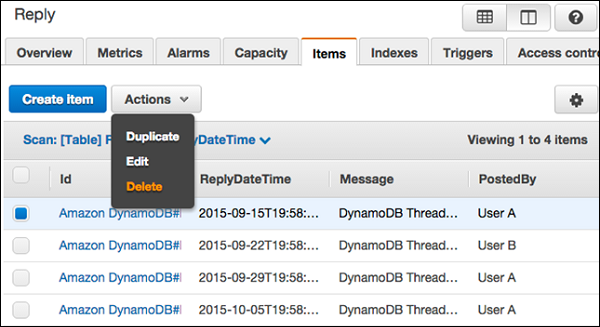
Измените любые атрибуты или значения, необходимые в окне « Редактировать элемент» .
Обновление элементов с помощью Java
Использование Java в операциях обновления элемента требует создания экземпляра класса Table и вызова его метода updateItem . Затем вы указываете первичный ключ элемента и предоставляете подробные модификации атрибутов UpdateExpression .
Ниже приведен пример того же —
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); Table table = dynamoDB.getTable("ProductList"); Map<String, String> expressionAttributeNames = new HashMap<String, String>(); expressionAttributeNames.put("#M", "Make"); expressionAttributeNames.put("#P", "Price expressionAttributeNames.put("#N", "ID"); Map<String, Object> expressionAttributeValues = new HashMap<String, Object>(); expressionAttributeValues.put(":val1", new HashSet<String>(Arrays.asList("Make1","Make2"))); expressionAttributeValues.put(":val2", 1); //Price UpdateItemOutcome outcome = table.updateItem( "internalID", // key attribute name 111, // key attribute value "add #M :val1 set #P = #P - :val2 remove #N", // UpdateExpression expressionAttributeNames, expressionAttributeValues);
Метод updateItem также позволяет указать условия, которые можно увидеть в следующем примере:
Table table = dynamoDB.getTable("ProductList"); Map<String, String> expressionAttributeNames = new HashMap<String, String>(); expressionAttributeNames.put("#P", "Price"); Map<String, Object> expressionAttributeValues = new HashMap<String, Object>(); expressionAttributeValues.put(":val1", 44); // change Price to 44 expressionAttributeValues.put(":val2", 15); // only if currently 15 UpdateItemOutcome outcome = table.updateItem (new PrimaryKey("internalID",111), "set #P = :val1", // Update "#P = :val2", // Condition expressionAttributeNames, expressionAttributeValues);
Обновление элементов с помощью счетчиков
DynamoDB позволяет использовать атомарные счетчики, что означает использование UpdateItem для увеличения / уменьшения значений атрибутов без влияния на другие запросы; Более того, счетчики всегда обновляются.
Ниже приведен пример, который объясняет, как это можно сделать.
Примечание. В следующем примере может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В этом примере также используется Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
package com.amazonaws.codesamples.document; import java.io.IOException; import java.util.Arrays; import java.util.HashMap; import java.util.HashSet; import java.util.Map; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome; import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec; import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec; import com.amazonaws.services.dynamodbv2.document.utils.NameMap; import com.amazonaws.services.dynamodbv2.document.utils.ValueMap; import com.amazonaws.services.dynamodbv2.model.ReturnValue; public class UpdateItemOpSample { static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); static String tblName = "ProductList"; public static void main(String[] args) throws IOException { createItems(); retrieveItem(); // Execute updates updateMultipleAttributes(); updateAddNewAttribute(); updateExistingAttributeConditionally(); // Item deletion deleteItem(); } private static void createItems() { Table table = dynamoDB.getTable(tblName); try { Item item = new Item() .withPrimaryKey("ID", 303) .withString("Nomenclature", "Polymer Blaster 4000") .withStringSet( "Manufacturers", new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc."))) .withNumber("Price", 50000) .withBoolean("InProduction", true) .withString("Category", "Laser Cutter"); table.putItem(item); item = new Item() .withPrimaryKey("ID", 313) .withString("Nomenclature", "Agitatatron 2000") .withStringSet( "Manufacturers", new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc."))) .withNumber("Price", 40000) .withBoolean("InProduction", true) .withString("Category", "Agitator"); table.putItem(item); } catch (Exception e) { System.err.println("Cannot create items."); System.err.println(e.getMessage()); } } private static void updateAddNewAttribute() { Table table = dynamoDB.getTable(tableName); try { Map<String, String> expressionAttributeNames = new HashMap<String, String>(); expressionAttributeNames.put("#na", "NewAttribute"); UpdateItemSpec updateItemSpec = new UpdateItemSpec() .withPrimaryKey("ID", 303) .withUpdateExpression("set #na = :val1") .withNameMap(new NameMap() .with("#na", "NewAttribute")) .withValueMap(new ValueMap() .withString(":val1", "A value")) .withReturnValues(ReturnValue.ALL_NEW); UpdateItemOutcome outcome = table.updateItem(updateItemSpec); // Confirm System.out.println("Displaying updated item..."); System.out.println(outcome.getItem().toJSONPretty()); } catch (Exception e) { System.err.println("Cannot add an attribute in " + tableName); System.err.println(e.getMessage()); } } }
DynamoDB — Удалить элементы
Для удаления элемента в DynamoDB требуется только указать имя таблицы и ключ элемента. Также настоятельно рекомендуется использовать условное выражение, которое будет необходимо, чтобы избежать удаления неправильных элементов.
Как обычно, вы можете использовать консоль с графическим интерфейсом, Java или любой другой необходимый инструмент для выполнения этой задачи.
Удалить элементы с помощью консоли графического интерфейса
Перейдите к консоли. На панели навигации слева выберите Таблицы . Затем выберите имя таблицы и вкладку « Элементы ».
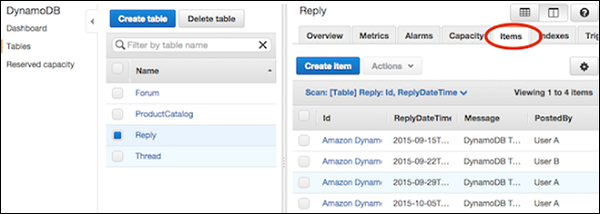
Выберите элементы, которые нужно удалить, и выберите Действия | Удалить
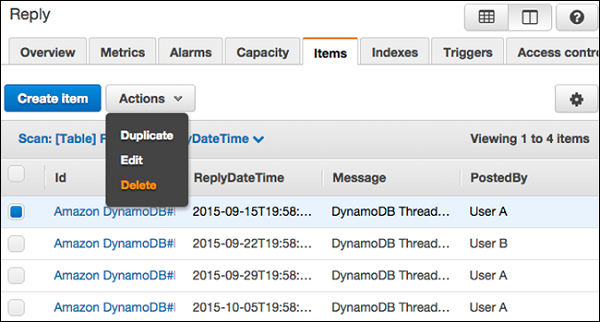
Появится диалоговое окно « Удалить элементы», как показано на следующем скриншоте. Выберите «Удалить» для подтверждения.
Как удалить элементы с помощью Java?
Использование Java в операциях удаления элементов просто включает создание клиентского экземпляра DynamoDB и вызов метода deleteItem с помощью ключа элемента.
Вы можете увидеть следующий пример, где это было подробно объяснено.
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); Table table = dynamoDB.getTable("ProductList"); DeleteItemOutcome outcome = table.deleteItem("IDnum", 151);
Вы также можете указать параметры для защиты от неправильного удаления. Просто используйте ConditionExpression .
Например —
Map<String,Object> expressionAttributeValues = new HashMap<String,Object>(); expressionAttributeValues.put(":val", false); DeleteItemOutcome outcome = table.deleteItem("IDnum",151, "Ship = :val", null, // doesn't use ExpressionAttributeNames expressionAttributeValues);
Ниже приведен более крупный пример для лучшего понимания.
Примечание. В следующем примере может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В этом примере также используется Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
package com.amazonaws.codesamples.document; import java.io.IOException; import java.util.Arrays; import java.util.HashMap; import java.util.HashSet; import java.util.Map; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome; import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec; import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec; import com.amazonaws.services.dynamodbv2.document.utils.NameMap; import com.amazonaws.services.dynamodbv2.document.utils.ValueMap; import com.amazonaws.services.dynamodbv2.model.ReturnValue; public class DeleteItemOpSample { static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); static String tblName = "ProductList"; public static void main(String[] args) throws IOException { createItems(); retrieveItem(); // Execute updates updateMultipleAttributes(); updateAddNewAttribute(); updateExistingAttributeConditionally(); // Item deletion deleteItem(); } private static void createItems() { Table table = dynamoDB.getTable(tblName); try { Item item = new Item() .withPrimaryKey("ID", 303) .withString("Nomenclature", "Polymer Blaster 4000") .withStringSet( "Manufacturers", new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc."))) .withNumber("Price", 50000) .withBoolean("InProduction", true) .withString("Category", "Laser Cutter"); table.putItem(item); item = new Item() .withPrimaryKey("ID", 313) .withString("Nomenclature", "Agitatatron 2000") .withStringSet( "Manufacturers", new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc."))) .withNumber("Price", 40000) .withBoolean("InProduction", true) .withString("Category", "Agitator"); table.putItem(item); } catch (Exception e) { System.err.println("Cannot create items."); System.err.println(e.getMessage()); } } private static void deleteItem() { Table table = dynamoDB.getTable(tableName); try { DeleteItemSpec deleteItemSpec = new DeleteItemSpec() .withPrimaryKey("ID", 303) .withConditionExpression("#ip = :val") .withNameMap(new NameMap() .with("#ip", "InProduction")) .withValueMap(new ValueMap() .withBoolean(":val", false)) .withReturnValues(ReturnValue.ALL_OLD); DeleteItemOutcome outcome = table.deleteItem(deleteItemSpec); // Confirm System.out.println("Displaying deleted item..."); System.out.println(outcome.getItem().toJSONPretty()); } catch (Exception e) { System.err.println("Cannot delete item in " + tableName); System.err.println(e.getMessage()); } } }
DynamoDB — Пакетная запись
Пакетная запись работает с несколькими элементами, создавая или удаляя несколько элементов. Эти операции используют BatchWriteItem , который имеет ограничения не более 16 МБ записей и 25 запросов. Каждый элемент соответствует ограничениям в размере 400 КБ. Пакетная запись также не может выполнять обновления элементов.
Что такое пакетная запись?
Пакетная запись может манипулировать элементами в нескольких таблицах. Вызов операции происходит для каждого отдельного запроса, что означает, что операции не влияют друг на друга, и разрешены гетерогенные миксы; например, один PutItem и три запроса DeleteItem в пакете, при этом сбой запроса PutItem не влияет на другие. Неудачные запросы приводят к тому, что операция возвращает информацию (ключи и данные), относящуюся к каждому неудавшемуся запросу.
Примечание. Если DynamoDB возвращает какие-либо элементы без их обработки, повторите их; однако используйте метод отката, чтобы избежать другого сбоя запроса из-за перегрузки.
DynamoDB отклоняет операцию пакетной записи, когда одно или несколько из следующих утверждений подтверждаются:
-
Запрос превышает предоставленную пропускную способность.
-
Запрос пытается использовать BatchWriteItems для обновления элемента.
-
Запрос выполняет несколько операций над одним элементом.
-
Таблицы запросов не существуют.
-
Атрибуты элемента в запросе не соответствуют цели.
-
Запросы превышают пределы размера.
Запрос превышает предоставленную пропускную способность.
Запрос пытается использовать BatchWriteItems для обновления элемента.
Запрос выполняет несколько операций над одним элементом.
Таблицы запросов не существуют.
Атрибуты элемента в запросе не соответствуют цели.
Запросы превышают пределы размера.
Для пакетной записи требуются определенные параметры RequestItem —
-
Операции удаления требуют ключевых подэлементов DeleteRequest, означающих имя и значение атрибута.
-
Для элементов PutRequest требуется подэлемент Item, означающий карту атрибута и значения атрибута.
Операции удаления требуют ключевых подэлементов DeleteRequest, означающих имя и значение атрибута.
Для элементов PutRequest требуется подэлемент Item, означающий карту атрибута и значения атрибута.
Ответ — Успешная операция приводит к ответу HTTP 200, который указывает такие характеристики, как использованные единицы емкости, показатели обработки таблицы и любые необработанные элементы.
Пакетная запись с Java
Выполните пакетную запись, создав экземпляр класса DynamoDB, экземпляр класса TableWriteItems, описывающий все операции, и вызовите метод batchWriteItem для использования объекта TableWriteItems.
Примечание. Необходимо создать экземпляр TableWriteItems для каждой таблицы в пакетной записи в несколько таблиц. Кроме того, проверьте ваш запрос ответа на любые необработанные запросы.
Вы можете просмотреть следующий пример пакетной записи —
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); TableWriteItems forumTableWriteItems = new TableWriteItems("Forum") .withItemsToPut( new Item() .withPrimaryKey("Title", "XYZ CRM") .withNumber("Threads", 0)); TableWriteItems threadTableWriteItems = new TableWriteItems(Thread) .withItemsToPut( new Item() .withPrimaryKey("ForumTitle","XYZ CRM","Topic","Updates") .withHashAndRangeKeysToDelete("ForumTitle","A partition key value", "Product Line 1", "A sort key value")); BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem ( forumTableWriteItems, threadTableWriteItems);
Следующая программа является еще одним большим примером для лучшего понимания того, как пакет пишет с Java.
Примечание. В следующем примере может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В этом примере также используются Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
package com.amazonaws.codesamples.document; import java.io.IOException; import java.util.Arrays; import java.util.HashSet; import java.util.List; import java.util.Map; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.BatchWriteItemOutcome; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.TableWriteItems; import com.amazonaws.services.dynamodbv2.model.WriteRequest; public class BatchWriteOpSample { static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); static String forumTableName = "Forum"; static String threadTableName = "Thread"; public static void main(String[] args) throws IOException { batchWriteMultiItems(); } private static void batchWriteMultiItems() { try { // Place new item in Forum TableWriteItems forumTableWriteItems = new TableWriteItems(forumTableName) //Forum .withItemsToPut(new Item() .withPrimaryKey("Name", "Amazon RDS") .withNumber("Threads", 0)); // Place one item, delete another in Thread // Specify partition key and range key TableWriteItems threadTableWriteItems = new TableWriteItems(threadTableName) .withItemsToPut(new Item() .withPrimaryKey("ForumName","Product Support","Subject","Support Thread 1") .withString("Message", "New OS Thread 1 message") .withHashAndRangeKeysToDelete("ForumName","Subject", "Polymer Blaster", "Support Thread 100")); System.out.println("Processing request..."); BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem ( forumTableWriteItems, threadTableWriteItems); do { // Confirm no unprocessed items Map<String, List<WriteRequest>> unprocessedItems = outcome.getUnprocessedItems(); if (outcome.getUnprocessedItems().size() == 0) { System.out.println("All items processed."); } else { System.out.println("Gathering unprocessed items..."); outcome = dynamoDB.batchWriteItemUnprocessed(unprocessedItems); } } while (outcome.getUnprocessedItems().size() > 0); } catch (Exception e) { System.err.println("Could not get items: "); e.printStackTrace(System.err); } } }
DynamoDB — Пакетное извлечение
Операции пакетного извлечения возвращают атрибуты одного или нескольких элементов. Эти операции обычно состоят из использования первичного ключа для идентификации желаемого элемента (ов). Операции BatchGetItem подчиняются ограничениям отдельных операций, а также их собственным уникальным ограничениям.
Следующие запросы в операциях пакетного поиска приводят к отклонению:
- Сделайте запрос на более 100 наименований.
- Сделайте запрос, превышающий пропускную способность.
Операции пакетного извлечения выполняют частичную обработку запросов, которые могут превышать пределы.
Например, запрос на извлечение нескольких элементов, достаточно больших по размеру, чтобы превысить пределы, приводит к части обработки запроса и сообщению об ошибке, отмечающему необработанную часть. При возврате необработанных элементов создайте решение для алгоритма отсрочки, чтобы управлять этим, а не регулировать таблицы.
Операции BatchGet в конечном итоге выполняются с согласованным чтением, что требует модификации для строго согласованного чтения. Они также выполняют поиск параллельно.
Примечание — порядок возврата товаров. DynamoDB не сортирует элементы. Это также не указывает на отсутствие запрошенных товаров. Кроме того, эти запросы потребляют единицы мощности.
Для всех операций BatchGet требуются параметры RequestItems, такие как согласованность чтения, имена атрибутов и первичные ключи.
Ответ — Успешная операция приводит к ответу HTTP 200, который указывает такие характеристики, как использованные единицы емкости, показатели обработки таблицы и любые необработанные элементы.
Пакетные загрузки с Java
Использование Java в операциях BatchGet требует создания экземпляра класса DynamoDB, экземпляра класса TableKeysAndAttributes, описывающего список значений первичного ключа для элементов, и передачи объекта TableKeysAndAttributes в метод BatchGetItem .
Ниже приведен пример операции BatchGet:
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient ( new ProfileCredentialsProvider())); TableKeysAndAttributes forumTableKeysAndAttributes = new TableKeysAndAttributes (forumTableName); forumTableKeysAndAttributes.addHashOnlyPrimaryKeys ( "Title", "Updates", "Product Line 1" ); TableKeysAndAttributes threadTableKeysAndAttributes = new TableKeysAndAttributes ( threadTableName); threadTableKeysAndAttributes.addHashAndRangePrimaryKeys ( "ForumTitle", "Topic", "Product Line 1", "P1 Thread 1", "Product Line 1", "P1 Thread 2", "Product Line 2", "P2 Thread 1" ); BatchGetItemOutcome outcome = dynamoDB.batchGetItem ( forumTableKeysAndAttributes, threadTableKeysAndAttributes); for (String tableName : outcome.getTableItems().keySet()) { System.out.println("Table items " + tableName); List<Item> items = outcome.getTableItems().get(tableName); for (Item item : items) { System.out.println(item); } }
Вы можете рассмотреть следующий более крупный пример.
Примечание. В следующей программе может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
Эта программа также использует Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
package com.amazonaws.codesamples.document; import java.io.IOException; import java.util.List; import java.util.Map; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.BatchGetItemOutcome; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.TableKeysAndAttributes; import com.amazonaws.services.dynamodbv2.model.KeysAndAttributes; public class BatchGetOpSample { static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient ( new ProfileCredentialsProvider())); static String forumTableName = "Forum"; static String threadTableName = "Thread"; public static void main(String[] args) throws IOException { retrieveMultipleItemsBatchGet(); } private static void retrieveMultipleItemsBatchGet() { try { TableKeysAndAttributes forumTableKeysAndAttributes = new TableKeysAndAttributes(forumTableName); //Create partition key forumTableKeysAndAttributes.addHashOnlyPrimaryKeys ( "Name", "XYZ Melt-O-tron", "High-Performance Processing" ); TableKeysAndAttributes threadTableKeysAndAttributes = new TableKeysAndAttributes(threadTableName); //Create partition key and sort key threadTableKeysAndAttributes.addHashAndRangePrimaryKeys ( "ForumName", "Subject", "High-Performance Processing", "HP Processing Thread One", "High-Performance Processing", "HP Processing Thread Two", "Melt-O-Tron", "MeltO Thread One" ); System.out.println("Processing..."); BatchGetItemOutcome outcome = dynamoDB.batchGetItem(forumTableKeysAndAttributes, threadTableKeysAndAttributes); Map<String, KeysAndAttributes> unprocessed = null; do { for (String tableName : outcome.getTableItems().keySet()) { System.out.println("Table items for " + tableName); List<Item> items = outcome.getTableItems().get(tableName); for (Item item : items) { System.out.println(item.toJSONPretty()); } } // Confirm no unprocessed items unprocessed = outcome.getUnprocessedKeys(); if (unprocessed.isEmpty()) { System.out.println("All items processed."); } else { System.out.println("Gathering unprocessed items..."); outcome = dynamoDB.batchGetItemUnprocessed(unprocessed); } } while (!unprocessed.isEmpty()); } catch (Exception e) { System.err.println("Could not get items."); System.err.println(e.getMessage()); } } }
DynamoDB — Запрос
Запросы определяют местонахождение предметов или вторичных индексов через первичные ключи. Выполнение запроса требует ключа раздела и определенного значения или ключа и значения сортировки; с возможностью фильтрации сравнений. Поведение запроса по умолчанию состоит в возврате каждого атрибута для элементов, связанных с предоставленным первичным ключом. Однако вы можете указать нужные атрибуты с помощью параметра ProjectionExpression .
Запрос использует параметры KeyConditionExpression для выбора элементов, что требует предоставления имени и значения ключа раздела в форме условия равенства. У вас также есть возможность предоставить дополнительное условие для любых имеющихся ключей сортировки.
Вот несколько примеров ключевых условий сортировки:
| Sr.No | Состояние и описание |
|---|---|
| 1 |
х = у Он принимает значение true, если атрибут x равен y. |
| 2 |
х <у Он оценивается как true, если x меньше y. |
| 3 |
х <= у Он принимает значение true, если x меньше или равно y. |
| 4 |
х> у Он оценивается как истина, если х больше, чем у. |
| 5 |
х> = у Он оценивается как истина, если х больше или равно у. |
| 6 |
х между у и г Он принимает значение true, если x равен и> = y, и <= z. |
х = у
Он принимает значение true, если атрибут x равен y.
х <у
Он оценивается как true, если x меньше y.
х <= у
Он принимает значение true, если x меньше или равно y.
х> у
Он оценивается как истина, если х больше, чем у.
х> = у
Он оценивается как истина, если х больше или равно у.
х между у и г
Он принимает значение true, если x равен и> = y, и <= z.
DynamoDB также поддерживает следующие функции: begin_with (x, substr)
Значение true, если атрибут x начинается с указанной строки.
Следующие условия должны соответствовать определенным требованиям —
-
Имена атрибутов должны начинаться с символа в наборе az или AZ.
-
Второй символ имени атрибута должен находиться в наборе az, AZ или 0-9.
-
Имена атрибутов не могут использовать зарезервированные слова.
Имена атрибутов должны начинаться с символа в наборе az или AZ.
Второй символ имени атрибута должен находиться в наборе az, AZ или 0-9.
Имена атрибутов не могут использовать зарезервированные слова.
Имена атрибутов, не соответствующие указанным выше ограничениям, могут определять заполнитель.
Запрос обрабатывается путем выполнения поиска в порядке ключей сортировки и с использованием любых имеющихся условий и выражений фильтра. Запросы всегда возвращают набор результатов, и при отсутствии совпадений он возвращает пустой.
Результаты всегда возвращаются в порядке ключей сортировки и в порядке типов данных с изменяемым значением по умолчанию в порядке возрастания.
Запросы с Java
Запросы в Java позволяют запрашивать таблицы и вторичные индексы. Они требуют указания ключей разделения и условий равенства с возможностью указать ключи и условия сортировки.
Общие необходимые шаги для запроса в Java включают создание экземпляра класса DynamoDB, экземпляра класса Table для целевой таблицы и вызов метода запроса экземпляра Table для получения объекта запроса.
Ответ на запрос содержит объект ItemCollection, предоставляющий все возвращаемые элементы.
В следующем примере демонстрируются подробные запросы:
DynamoDB dynamoDB = new DynamoDB ( new AmazonDynamoDBClient(new ProfileCredentialsProvider())); Table table = dynamoDB.getTable("Response"); QuerySpec spec = new QuerySpec() .withKeyConditionExpression("ID = :nn") .withValueMap(new ValueMap() .withString(":nn", "Product Line 1#P1 Thread 1")); ItemCollection<QueryOutcome> items = table.query(spec); Iterator<Item> iterator = items.iterator(); Item item = null; while (iterator.hasNext()) { item = iterator.next(); System.out.println(item.toJSONPretty()); }
Метод запроса поддерживает множество необязательных параметров. В следующем примере показано, как использовать эти параметры:
Table table = dynamoDB.getTable("Response"); QuerySpec spec = new QuerySpec() .withKeyConditionExpression("ID = :nn and ResponseTM > :nn_responseTM") .withFilterExpression("Author = :nn_author") .withValueMap(new ValueMap() .withString(":nn", "Product Line 1#P1 Thread 1") .withString(":nn_responseTM", twoWeeksAgoStr) .withString(":nn_author", "Member 123")) .withConsistentRead(true); ItemCollection<QueryOutcome> items = table.query(spec); Iterator<Item> iterator = items.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next().toJSONPretty()); }
Вы также можете рассмотреть следующий более крупный пример.
Примечание. В следующей программе может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В этом примере также используются Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
package com.amazonaws.codesamples.document; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Iterator; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.ItemCollection; import com.amazonaws.services.dynamodbv2.document.Page; import com.amazonaws.services.dynamodbv2.document.QueryOutcome; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec; import com.amazonaws.services.dynamodbv2.document.utils.ValueMap; public class QueryOpSample { static DynamoDB dynamoDB = new DynamoDB( new AmazonDynamoDBClient(new ProfileCredentialsProvider())); static String tableName = "Reply"; public static void main(String[] args) throws Exception { String forumName = "PolyBlaster"; String threadSubject = "PolyBlaster Thread 1"; getThreadReplies(forumName, threadSubject); } private static void getThreadReplies(String forumName, String threadSubject) { Table table = dynamoDB.getTable(tableName); String replyId = forumName + "#" + threadSubject; QuerySpec spec = new QuerySpec() .withKeyConditionExpression("Id = :v_id") .withValueMap(new ValueMap() .withString(":v_id", replyId)); ItemCollection<QueryOutcome> items = table.query(spec); System.out.println("\ngetThreadReplies results:"); Iterator<Item> iterator = items.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next().toJSONPretty()); } } }
DynamoDB — Сканирование
Операции сканирования читают все элементы таблицы или вторичные индексы. Его функция по умолчанию возвращает все атрибуты данных всех элементов в индексе или таблице. Используйте параметр ProjectionExpression в фильтрах атрибутов.
Каждое сканирование возвращает набор результатов, даже если не найдено совпадений, что приводит к пустому набору. Сканирования извлекают не более 1 МБ с возможностью фильтрации данных.
Примечание . Параметры и фильтрация сканирования также применяются к запросам.
Типы операций сканирования
Фильтрация. Операции сканирования обеспечивают тонкую фильтрацию по выражениям фильтра, которые изменяют данные после сканирования или запросов; прежде чем возвращать результаты. В выражениях используются операторы сравнения. Их синтаксис напоминает выражения условий, за исключением ключевых атрибутов, которые выражения фильтра не допускают. Вы не можете использовать раздел или ключ сортировки в выражении фильтра.
Примечание . Ограничение в 1 МБ применяется до любого применения фильтрации.
Характеристики пропускной способности — при сканировании используется пропускная способность, однако при этом основное внимание уделяется размеру элемента, а не возвращаемым данным. Потребление остается неизменным независимо от того, запрашиваете ли вы каждый атрибут или только несколько, и использование или отсутствие выражения фильтра также не влияет на потребление.
Разбиение на страницы — DynamoDB разбивает на страницы результаты, вызывая разделение результатов на определенные страницы. Ограничение в 1 МБ применяется к возвращаемым результатам, и когда вы его превышаете, для сбора остальных данных становится необходимым другое сканирование. Значение LastEvaluatedKey позволяет выполнить это последующее сканирование. Просто примените значение к ExclusiveStartkey . Когда значение LastEvaluatedKey становится нулевым, операция завершила все страницы данных. Однако ненулевое значение не означает автоматически, что остается больше данных. Только нулевое значение указывает на статус.
Параметр предела — параметр предела управляет размером результата. DynamoDB использует его для определения количества элементов для обработки перед возвратом данных и не работает за пределами области действия. Если вы установите значение x, DynamoDB вернет первые x соответствующих элементов.
Значение LastEvaluatedKey также применяется в случаях параметров ограничения, дающих частичные результаты. Используйте его для завершения сканирования.
Счетчик результатов — Ответы на запросы и сканирования также включают информацию, относящуюся к ScannedCount и Count, которые количественно определяют отсканированные / запрошенные элементы и количественно возвращают элементы. Если вы не фильтруете, их значения идентичны. Когда вы превышаете 1 МБ, отсчеты представляют только обработанную часть.
Согласованность — результаты запросов и результаты сканирования в конечном итоге становятся согласованными, однако вы также можете установить строго согласованные чтения. Используйте параметр ConsistentRead, чтобы изменить этот параметр.
Примечание. Согласованные параметры чтения влияют на потребление, используя удвоенные единицы емкости, если настроены на строго согласованные значения.
Производительность. Запросы обеспечивают лучшую производительность, чем сканирование, поскольку при сканировании выполняется обход полной таблицы или вторичного индекса, что приводит к вялому отклику и высокому потреблению пропускной способности. Сканирование лучше всего подходит для небольших таблиц и поиска с меньшим количеством фильтров, однако вы можете разработать скудное сканирование, следуя нескольким рекомендациям, таким как избегание внезапного ускоренного чтения и использование параллельного сканирования.
Запрос находит определенный диапазон ключей, удовлетворяющих заданному условию, при этом производительность определяется количеством извлекаемых данных, а не объемом ключей. Параметры операции и количество совпадений особенно влияют на производительность.
Параллельное сканирование
Операции сканирования выполняют обработку последовательно по умолчанию. Затем они возвращают данные порциями по 1 МБ, что побуждает приложение извлечь следующую порцию. Это приводит к длинному сканированию больших таблиц и индексов.
Эта характеристика также означает, что сканирование может не всегда полностью использовать доступную пропускную способность. DynamoDB распределяет данные таблицы по нескольким разделам; и пропускная способность сканирования остается ограниченной для одного раздела из-за его операции с одним разделом.
Решение этой проблемы заключается в логическом разделении таблиц или индексов на сегменты. Затем «рабочие» параллельно (одновременно) сканируют сегменты. Он использует параметры Segment и TotalSegments, чтобы указать сегменты, сканируемые определенными работниками, и указать общее количество обработанных сегментов.
Рабочий номер
Для достижения максимальной производительности приложения вы должны поэкспериментировать с рабочими значениями (параметр Segment).
Примечание. Параллельное сканирование с большим количеством рабочих влияет на пропускную способность, возможно, потребляя всю пропускную способность. Решите эту проблему с помощью параметра Limit, который вы можете использовать, чтобы не дать одному рабочему использовать всю пропускную способность.
Ниже приведен пример глубокого сканирования.
Примечание. В следующей программе может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В этом примере также используются Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
import java.util.HashMap; import java.util.Iterator; import java.util.Map; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.ItemCollection; import com.amazonaws.services.dynamodbv2.document.ScanOutcome; import com.amazonaws.services.dynamodbv2.document.Table; public class ScanOpSample { static DynamoDB dynamoDB = new DynamoDB( new AmazonDynamoDBClient(new ProfileCredentialsProvider())); static String tableName = "ProductList"; public static void main(String[] args) throws Exception { findProductsUnderOneHun(); //finds products under 100 dollars } private static void findProductsUnderOneHun() { Table table = dynamoDB.getTable(tableName); Map<String, Object> expressionAttributeValues = new HashMap<String, Object>(); expressionAttributeValues.put(":pr", 100); ItemCollection<ScanOutcome> items = table.scan ( "Price < :pr", //FilterExpression "ID, Nomenclature, ProductCategory, Price", //ProjectionExpression null, //No ExpressionAttributeNames expressionAttributeValues); System.out.println("Scanned " + tableName + " to find items under $100."); Iterator<Item> iterator = items.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next().toJSONPretty()); } } }
DynamoDB — Индексы
DynamoDB использует индексы для атрибутов первичного ключа для улучшения доступа. Они ускоряют доступ к приложениям и извлечение данных, а также поддерживают более высокую производительность за счет уменьшения задержки приложений.
Вторичный индекс
Вторичный индекс содержит подмножество атрибутов и альтернативный ключ. Вы используете его с помощью запроса или операции сканирования, которая нацелена на индекс.
Его содержимое включает в себя атрибуты, которые вы проектируете или копируете. При создании вы определяете альтернативный ключ для индекса и любые атрибуты, которые вы хотите проецировать в индекс. Затем DynamoDB выполняет копирование атрибутов в индекс, включая атрибуты первичного ключа, полученные из таблицы. Выполнив эти задачи, вы просто используете запрос / сканирование, как будто выполняете работу с таблицей.
DynamoDB автоматически поддерживает все вторичные индексы. При выполнении операций с элементами, таких как добавление или удаление, обновляются все индексы в целевой таблице.
DynamoDB предлагает два типа вторичных индексов —
-
Глобальный вторичный индекс — этот индекс включает ключ раздела и ключ сортировки, которые могут отличаться от исходной таблицы. Он использует метку «глобальный» из-за способности запросов / сканирований в индексе охватывать все данные таблицы и все разделы.
-
Локальный вторичный индекс — этот индекс разделяет ключ раздела с таблицей, но использует другой ключ сортировки. Его «локальный» характер обусловлен тем, что все его разделы имеют вид таблицы с одинаковым значением ключа раздела.
Глобальный вторичный индекс — этот индекс включает ключ раздела и ключ сортировки, которые могут отличаться от исходной таблицы. Он использует метку «глобальный» из-за способности запросов / сканирований в индексе охватывать все данные таблицы и все разделы.
Локальный вторичный индекс — этот индекс разделяет ключ раздела с таблицей, но использует другой ключ сортировки. Его «локальный» характер обусловлен тем, что все его разделы имеют вид таблицы с одинаковым значением ключа раздела.
Лучший тип используемого индекса зависит от потребностей приложения. Рассмотрим различия между двумя представленными в следующей таблице —
| Качественный | Глобальный вторичный индекс | Локальный вторичный индекс |
|---|---|---|
| Схема ключей | Он использует простой или составной первичный ключ. | Он всегда использует составной первичный ключ. |
| Ключевые атрибуты | Ключ индекса и ключ сортировки могут состоять из атрибутов строки, числа или двоичной таблицы. | Ключ раздела индекса является атрибутом, который используется совместно с ключом раздела таблицы. Ключом сортировки могут быть строковые, числовые или двоичные атрибуты таблицы. |
| Пределы размера на значение ключа раздела | Они не имеют ограничений по размеру. | Это накладывает максимальное ограничение в 10 ГБ на общий размер проиндексированных элементов, связанных со значением ключа раздела. |
| Операции с индексами в Интернете | Вы можете создавать их при создании таблиц, добавлять их в существующие таблицы или удалять существующие. | Вы должны создать их при создании таблицы, но не можете удалить их или добавить в существующие таблицы. |
| Запросы | Это позволяет выполнять запросы, охватывающие всю таблицу и каждый раздел. | Они адресуют отдельные разделы через значение ключа раздела, указанное в запросе. |
| консистенция | Запросы этих индексов предлагают только окончательно согласованный вариант. | Запросы из них предлагают варианты в конечном итоге последовательных или строго последовательных. |
| Пропускная способность | Он включает в себя настройки пропускной способности для чтения и записи. Запросы / сканирования потребляют емкость из индекса, а не из таблицы, что также относится к обновлениям записи в таблицу. | Запросы / сканирования потребляют таблицы для чтения. Таблица записывает обновления локальных индексов и использует единицы емкости таблицы. |
| проекция | Запросы / сканирования могут запрашивать только атрибуты, спроецированные в индекс, без извлечения атрибутов таблицы. | Запросы / проверки могут запрашивать те атрибуты, которые не проецируются; кроме того, автоматические выборки их происходят. |
При создании нескольких таблиц со вторичными индексами делайте это последовательно; то есть составьте таблицу и подождите, пока она достигнет АКТИВНОГО состояния, прежде чем создавать другую и снова ждать. DynamoDB не разрешает одновременное создание.
Каждый вторичный индекс требует определенных спецификаций —
-
Тип — Укажите локальный или глобальный.
-
Имя — использует правила именования, идентичные таблицам.
-
Схема ключей — разрешены только строка верхнего уровня, число или двоичный тип, причем тип индекса определяет другие требования.
-
Атрибуты для проецирования — DynamoDB автоматически проецирует их и допускает любой тип данных.
-
Пропускная способность — укажите емкость чтения / записи для глобальных вторичных индексов.
Тип — Укажите локальный или глобальный.
Имя — использует правила именования, идентичные таблицам.
Схема ключей — разрешены только строка верхнего уровня, число или двоичный тип, причем тип индекса определяет другие требования.
Атрибуты для проецирования — DynamoDB автоматически проецирует их и допускает любой тип данных.
Пропускная способность — укажите емкость чтения / записи для глобальных вторичных индексов.
Предел для индексов остается 5 глобальных и 5 локальных на таблицу.
Вы можете получить доступ к подробной информации об индексах с помощью DescribeTable . Возвращает имя, размер и количество предметов.
Примечание. Эти значения обновляются каждые 6 часов.
В запросах или сканированиях, используемых для доступа к данным индекса, укажите имена таблиц и индексов, требуемые атрибуты для результата и любые условные операторы. DynamoDB предлагает возможность возвращать результаты в порядке возрастания или убывания.
Примечание. При удалении таблицы также удаляются все индексы.
DynamoDB — Глобальные вторичные индексы
Приложения, которым требуются различные типы запросов с разными атрибутами, могут использовать один или несколько глобальных вторичных индексов при выполнении этих подробных запросов.
Например — Система, отслеживающая пользователей, их статус входа в систему и время их входа в систему. Рост предыдущего примера замедляет запросы к своим данным.
Глобальные вторичные индексы ускоряют запросы, организуя выбор атрибутов из таблицы. Они используют первичные ключи при сортировке данных и не требуют атрибутов таблицы ключей или схемы ключей, идентичной таблице.
Все глобальные вторичные индексы должны включать ключ раздела с опцией ключа сортировки. Схема ключа индекса может отличаться от таблицы, а атрибуты ключа индекса могут использовать любые строковые, числовые или двоичные атрибуты таблицы верхнего уровня.
В проекции можно использовать другие атрибуты таблицы, однако запросы не извлекаются из родительских таблиц.
Прогнозы атрибутов
Проекции состоят из набора атрибутов, скопированных из таблицы во вторичный индекс. Проекция всегда происходит с ключом разделения таблицы и ключом сортировки. В запросах проекции предоставляют DynamoDB доступ к любому атрибуту проекции; они по существу существуют как их собственная таблица.
При создании вторичного индекса необходимо указать атрибуты для проекции. DynamoDB предлагает три способа выполнить эту задачу —
-
KEYS_ONLY — Все элементы индекса состоят из значений разделов таблицы и ключей сортировки, а также значений ключей индекса. Это создает наименьший индекс.
-
INCLUDE — включает атрибуты KEYS_ONLY и неключевые атрибуты.
-
ALL — включает все атрибуты исходной таблицы, создавая максимально возможный индекс.
KEYS_ONLY — Все элементы индекса состоят из значений разделов таблицы и ключей сортировки, а также значений ключей индекса. Это создает наименьший индекс.
INCLUDE — включает атрибуты KEYS_ONLY и неключевые атрибуты.
ALL — включает все атрибуты исходной таблицы, создавая максимально возможный индекс.
Обратите внимание на компромиссы при проецировании атрибутов в глобальный вторичный индекс, которые относятся к пропускной способности и стоимости хранения.
Рассмотрим следующие моменты —
-
Если вам нужен только доступ к нескольким атрибутам с низкой задержкой, проецируйте только те, которые вам нужны. Это уменьшает затраты на хранение и запись.
-
Если приложение часто обращается к определенным неключевым атрибутам, спроектируйте их, потому что затраты на хранение бледнеют по сравнению с потреблением сканирования.
-
Вы можете проецировать большие наборы часто используемых атрибутов, однако это приводит к высокой стоимости хранения.
-
Используйте KEYS_ONLY для нечастых запросов к таблицам и частых записей / обновлений. Это контролирует размер, но все же предлагает хорошую производительность по запросам.
Если вам нужен только доступ к нескольким атрибутам с низкой задержкой, проецируйте только те, которые вам нужны. Это уменьшает затраты на хранение и запись.
Если приложение часто обращается к определенным неключевым атрибутам, спроектируйте их, потому что затраты на хранение бледнеют по сравнению с потреблением сканирования.
Вы можете проецировать большие наборы часто используемых атрибутов, однако это приводит к высокой стоимости хранения.
Используйте KEYS_ONLY для нечастых запросов к таблицам и частых записей / обновлений. Это контролирует размер, но все же предлагает хорошую производительность по запросам.
Глобальный вторичный индекс Запросы и сканирование
Вы можете использовать запросы для доступа к одному или нескольким элементам в индексе. Вы должны указать индекс и имя таблицы, желаемые атрибуты и условия; с возможностью возврата результатов в порядке возрастания или убывания.
Вы также можете использовать сканы, чтобы получить все данные индекса. Требуется имя таблицы и индекса. Вы используете выражение фильтра для извлечения определенных данных.
Синхронизация данных таблиц и индексов
DynamoDB автоматически выполняет синхронизацию по индексам с их родительской таблицей. Каждая операция по изменению элементов вызывает асинхронное обновление, однако приложения не записывают в индексы напрямую.
Вам необходимо понять влияние обслуживания DynamoDB на индексы. При создании индекса вы указываете ключевые атрибуты и типы данных, что означает, что при записи эти типы данных должны соответствовать типам данных схемы ключей.
При создании или удалении элемента индексы обновляются в конечном итоге согласованным образом, однако обновления данных распространяются за доли секунды (если не происходит системный сбой какого-либо типа). Вы должны учитывать эту задержку в приложениях.
Вопросы пропускной способности в глобальных вторичных индексах — Несколько глобальных вторичных индексов влияют на пропускную способность. Для создания индекса требуются спецификации единиц емкости, которые существуют отдельно от таблицы, что приводит к тому, что операции потребляют единицы емкости индекса, а не единицы таблицы.
Это может привести к регулированию, если запрос или запись превышает выделенную пропускную способность. Просмотр настроек пропускной способности с помощью DescribeTable .
Емкость чтения — глобальные вторичные индексы обеспечивают возможную согласованность. В запросах DynamoDB выполняет расчеты обеспечения, идентичные тем, которые используются для таблиц, с единственной разницей в использовании размера элемента индекса, а не размера элемента. Предел возвращаемых запросов остается 1 МБ, который включает размер имени атрибута и значения для каждого возвращаемого элемента.
Емкость записи
Когда происходят операции записи, затронутый индекс потребляет единицы записи. Расходы на пропускную способность записи представляют собой сумму единиц емкости записи, потребляемых при записи в таблицу, и единиц, используемых в обновлениях индекса. Успешная операция записи требует достаточной емкости или приводит к дросселированию.
Стоимость записи также остается зависимой от определенных факторов, некоторые из которых следующие:
-
Новые элементы, определяющие индексированные атрибуты, или обновления элементов, определяющие неопределенные индексированные атрибуты, используют одну операцию записи для добавления элемента в индекс.
-
Обновления, изменяющие значение атрибута индексированного ключа, используют две записи для удаления элемента и записи нового.
-
Запись таблицы, инициирующая удаление индексированного атрибута, использует одну запись, чтобы стереть проекцию старого элемента в индексе.
-
Элементы, отсутствующие в индексе до и после операции обновления, не используют записи.
-
Обновления, изменяющие только значение прогнозируемого атрибута в схеме ключа индекса, а не значение атрибута индексированного ключа, используют одну запись для обновления значений прогнозируемых атрибутов в индексе.
Новые элементы, определяющие индексированные атрибуты, или обновления элементов, определяющие неопределенные индексированные атрибуты, используют одну операцию записи для добавления элемента в индекс.
Обновления, изменяющие значение атрибута индексированного ключа, используют две записи для удаления элемента и записи нового.
Запись таблицы, инициирующая удаление индексированного атрибута, использует одну запись, чтобы стереть проекцию старого элемента в индексе.
Элементы, отсутствующие в индексе до и после операции обновления, не используют записи.
Обновления, изменяющие только значение прогнозируемого атрибута в схеме ключа индекса, а не значение атрибута индексированного ключа, используют одну запись для обновления значений прогнозируемых атрибутов в индексе.
Все эти факторы предполагают, что размер элемента не превышает 1 КБ.
Глобальное вторичное хранилище индексов
При записи элемента DynamoDB автоматически копирует правильный набор атрибутов в любые индексы, где атрибуты должны существовать. Это влияет на вашу учетную запись, взимая плату за хранение элементов таблицы и атрибутов. Используемое пространство получается из суммы этих величин:
- Размер байта первичного ключа таблицы
- Размер в байтах атрибута индекса ключа
- Размер в байтах проектируемых атрибутов
- 100 байтов на каждый элемент индекса
Вы можете оценить потребности в хранилище путем оценки среднего размера элемента и умножения на количество элементов таблицы с атрибутами ключа глобального вторичного индекса.
DynamoDB не записывает данные элемента для элемента таблицы с неопределенным атрибутом, определенным как раздел индекса или ключ сортировки.
Глобальный вторичный индекс Crud
Создайте таблицу с глобальными вторичными индексами, используя операцию CreateTable в паре с параметром GlobalSecondaryIndexes . Вы должны указать атрибут, который будет служить ключом индекса, или использовать другой для ключа сортировки индекса. Все атрибуты ключа индекса должны быть строковыми, числовыми или двоичными скалярами. Также необходимо указать параметры пропускной способности, состоящие из ReadCapacityUnits и WriteCapacityUnits .
Используйте UpdateTable, чтобы еще раз добавить глобальные вторичные индексы к существующим таблицам, используя параметр GlobalSecondaryIndexes.
В этой операции вы должны предоставить следующие входные данные —
- Индекс
- Ключевая схема
- Прогнозируемые атрибуты
- Настройки пропускной способности
При добавлении глобального вторичного индекса для больших таблиц может потребоваться значительное время из-за объема элемента, объема прогнозируемых атрибутов, емкости записи и активности записи. Используйте метрики CloudWatch для мониторинга процесса.
Используйте DescribeTable для получения информации о состоянии для глобального вторичного индекса. Возвращает один из четырех IndexStatus для GlobalSecondaryIndexes —
-
СОЗДАНИЕ — указывает этап построения индекса и его недоступность.
-
ACTIVE — указывает на готовность индекса к использованию.
-
ОБНОВЛЕНИЕ — показывает состояние обновления настроек пропускной способности.
-
УДАЛЕНИЕ — указывает на состояние удаления индекса и его постоянную недоступность для использования.
СОЗДАНИЕ — указывает этап построения индекса и его недоступность.
ACTIVE — указывает на готовность индекса к использованию.
ОБНОВЛЕНИЕ — показывает состояние обновления настроек пропускной способности.
УДАЛЕНИЕ — указывает на состояние удаления индекса и его постоянную недоступность для использования.
Обновите настройки пропускной способности глобального вторичного индекса на стадии загрузки / обратной засыпки (атрибуты записи DynamoDB в индекс и отслеживание добавленных / удаленных / обновленных элементов). Используйте UpdateTable для выполнения этой операции.
Вы должны помнить, что вы не можете добавлять / удалять другие индексы на этапе обратной засыпки.
Используйте UpdateTable для удаления глобальных вторичных индексов. Это позволяет удалять только один индекс на одну операцию, однако вы можете выполнять несколько операций одновременно, до пяти. Процесс удаления не влияет на операции чтения / записи родительской таблицы, но вы не можете добавлять / удалять другие индексы, пока операция не завершится.
Использование Java для работы с глобальными вторичными индексами
Создайте таблицу с индексом через CreateTable. Просто создайте экземпляр класса DynamoDB, экземпляр класса CreateTableRequest для запроса информации и передайте объект запроса в метод CreateTable.
Следующая программа является кратким примером —
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient ( new ProfileCredentialsProvider())); // Attributes ArrayList<AttributeDefinition> attributeDefinitions = new ArrayList<AttributeDefinition>(); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("City") .withAttributeType("S")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("Date") .withAttributeType("S")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("Wind") .withAttributeType("N")); // Key schema of the table ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>(); tableKeySchema.add(new KeySchemaElement() .withAttributeName("City") .withKeyType(KeyType.HASH)); //Partition key tableKeySchema.add(new KeySchemaElement() .withAttributeName("Date") .withKeyType(KeyType.RANGE)); //Sort key // Wind index GlobalSecondaryIndex windIndex = new GlobalSecondaryIndex() .withIndexName("WindIndex") .withProvisionedThroughput(new ProvisionedThroughput() .withReadCapacityUnits((long) 10) .withWriteCapacityUnits((long) 1)) .withProjection(new Projection().withProjectionType(ProjectionType.ALL)); ArrayList<KeySchemaElement> indexKeySchema = new ArrayList<KeySchemaElement>(); indexKeySchema.add(new KeySchemaElement() .withAttributeName("Date") .withKeyType(KeyType.HASH)); //Partition key indexKeySchema.add(new KeySchemaElement() .withAttributeName("Wind") .withKeyType(KeyType.RANGE)); //Sort key windIndex.setKeySchema(indexKeySchema); CreateTableRequest createTableRequest = new CreateTableRequest() .withTableName("ClimateInfo") .withProvisionedThroughput(new ProvisionedThroughput() .withReadCapacityUnits((long) 5) .withWriteCapacityUnits((long) 1)) .withAttributeDefinitions(attributeDefinitions) .withKeySchema(tableKeySchema) .withGlobalSecondaryIndexes(windIndex); Table table = dynamoDB.createTable(createTableRequest); System.out.println(table.getDescription());
Получить информацию индекса с DescribeTable . Сначала создайте экземпляр класса DynamoDB. Затем создайте экземпляр класса Table для целевого индекса. Наконец, передайте таблицу методу описания.
Вот короткий пример —
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient ( new ProfileCredentialsProvider())); Table table = dynamoDB.getTable("ClimateInfo"); TableDescription tableDesc = table.describe(); Iterator<GlobalSecondaryIndexDescription> gsiIter = tableDesc.getGlobalSecondaryIndexes().iterator(); while (gsiIter.hasNext()) { GlobalSecondaryIndexDescription gsiDesc = gsiIter.next(); System.out.println("Index data " + gsiDesc.getIndexName() + ":"); Iterator<KeySchemaElement> kse7Iter = gsiDesc.getKeySchema().iterator(); while (kseIter.hasNext()) { KeySchemaElement kse = kseIter.next(); System.out.printf("\t%s: %s\n", kse.getAttributeName(), kse.getKeyType()); } Projection projection = gsiDesc.getProjection(); System.out.println("\tProjection type: " + projection.getProjectionType()); if (projection.getProjectionType().toString().equals("INCLUDE")) { System.out.println("\t\tNon-key projected attributes: " + projection.getNonKeyAttributes()); } }
Используйте Query для выполнения запроса индекса, как с запросом таблицы. Просто создайте экземпляр класса DynamoDB, экземпляр класса Table для целевого индекса, экземпляр класса Index для определенного индекса и передайте объект индекса и запроса в метод запроса.
Взгляните на следующий код, чтобы лучше понять —
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient ( new ProfileCredentialsProvider())); Table table = dynamoDB.getTable("ClimateInfo"); Index index = table.getIndex("WindIndex"); QuerySpec spec = new QuerySpec() .withKeyConditionExpression("#d = :v_date and Wind = :v_wind") .withNameMap(new NameMap() .with("#d", "Date")) .withValueMap(new ValueMap() .withString(":v_date","2016-05-15") .withNumber(":v_wind",0)); ItemCollection<QueryOutcome> items = index.query(spec); Iterator<Item> iter = items.iterator(); while (iter.hasNext()) { System.out.println(iter.next().toJSONPretty()); }
Следующая программа является большим примером для лучшего понимания —
Примечание. В следующей программе может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В этом примере также используются Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
import java.util.ArrayList; import java.util.Iterator; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Index; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.ItemCollection; import com.amazonaws.services.dynamodbv2.document.QueryOutcome; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec; import com.amazonaws.services.dynamodbv2.document.utils.ValueMap; import com.amazonaws.services.dynamodbv2.model.AttributeDefinition; import com.amazonaws.services.dynamodbv2.model.CreateTableRequest; import com.amazonaws.services.dynamodbv2.model.GlobalSecondaryIndex; import com.amazonaws.services.dynamodbv2.model.KeySchemaElement; import com.amazonaws.services.dynamodbv2.model.KeyType; import com.amazonaws.services.dynamodbv2.model.Projection; import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput; public class GlobalSecondaryIndexSample { static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient ( new ProfileCredentialsProvider())); public static String tableName = "Bugs"; public static void main(String[] args) throws Exception { createTable(); queryIndex("CreationDateIndex"); queryIndex("NameIndex"); queryIndex("DueDateIndex"); } public static void createTable() { // Attributes ArrayList<AttributeDefinition> attributeDefinitions = new ArrayList<AttributeDefinition>(); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("BugID") .withAttributeType("S")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("Name") .withAttributeType("S")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("CreationDate") .withAttributeType("S")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("DueDate") .withAttributeType("S")); // Table Key schema ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>(); tableKeySchema.add (new KeySchemaElement() .withAttributeName("BugID") .withKeyType(KeyType.HASH)); //Partition key tableKeySchema.add (new KeySchemaElement() .withAttributeName("Name") .withKeyType(KeyType.RANGE)); //Sort key // Indexes' initial provisioned throughput ProvisionedThroughput ptIndex = new ProvisionedThroughput() .withReadCapacityUnits(1L) .withWriteCapacityUnits(1L); // CreationDateIndex GlobalSecondaryIndex creationDateIndex = new GlobalSecondaryIndex() .withIndexName("CreationDateIndex") .withProvisionedThroughput(ptIndex) .withKeySchema(new KeySchemaElement() .withAttributeName("CreationDate") .withKeyType(KeyType.HASH), //Partition key new KeySchemaElement() .withAttributeName("BugID") .withKeyType(KeyType.RANGE)) //Sort key .withProjection(new Projection() .withProjectionType("INCLUDE") .withNonKeyAttributes("Description", "Status")); // NameIndex GlobalSecondaryIndex nameIndex = new GlobalSecondaryIndex() .withIndexName("NameIndex") .withProvisionedThroughput(ptIndex) .withKeySchema(new KeySchemaElement() .withAttributeName("Name") .withKeyType(KeyType.HASH), //Partition key new KeySchemaElement() .withAttributeName("BugID") .withKeyType(KeyType.RANGE)) //Sort key .withProjection(new Projection() .withProjectionType("KEYS_ONLY")); // DueDateIndex GlobalSecondaryIndex dueDateIndex = new GlobalSecondaryIndex() .withIndexName("DueDateIndex") .withProvisionedThroughput(ptIndex) .withKeySchema(new KeySchemaElement() .withAttributeName("DueDate") .withKeyType(KeyType.HASH)) //Partition key .withProjection(new Projection() .withProjectionType("ALL")); CreateTableRequest createTableRequest = new CreateTableRequest() .withTableName(tableName) .withProvisionedThroughput( new ProvisionedThroughput() .withReadCapacityUnits( (long) 1) .withWriteCapacityUnits( (long) 1)) .withAttributeDefinitions(attributeDefinitions) .withKeySchema(tableKeySchema) .withGlobalSecondaryIndexes(creationDateIndex, nameIndex, dueDateIndex); System.out.println("Creating " + tableName + "..."); dynamoDB.createTable(createTableRequest); // Pause for active table state System.out.println("Waiting for ACTIVE state of " + tableName); try { Table table = dynamoDB.getTable(tableName); table.waitForActive(); } catch (InterruptedException e) { e.printStackTrace(); } } public static void queryIndex(String indexName) { Table table = dynamoDB.getTable(tableName); System.out.println ("\n*****************************************************\n"); System.out.print("Querying index " + indexName + "..."); Index index = table.getIndex(indexName); ItemCollection<QueryOutcome> items = null; QuerySpec querySpec = new QuerySpec(); if (indexName == "CreationDateIndex") { System.out.println("Issues filed on 2016-05-22"); querySpec.withKeyConditionExpression("CreationDate = :v_date and begins_with (BugID, :v_bug)") .withValueMap(new ValueMap() .withString(":v_date","2016-05-22") .withString(":v_bug","A-")); items = index.query(querySpec); } else if (indexName == "NameIndex") { System.out.println("Compile error"); querySpec.withKeyConditionExpression("Name = :v_name and begins_with (BugID, :v_bug)") .withValueMap(new ValueMap() .withString(":v_name","Compile error") .withString(":v_bug","A-")); items = index.query(querySpec); } else if (indexName == "DueDateIndex") { System.out.println("Items due on 2016-10-15"); querySpec.withKeyConditionExpression("DueDate = :v_date") .withValueMap(new ValueMap() .withString(":v_date","2016-10-15")); items = index.query(querySpec); } else { System.out.println("\nInvalid index name"); return; } Iterator<Item> iterator = items.iterator(); System.out.println("Query: getting result..."); while (iterator.hasNext()) { System.out.println(iterator.next().toJSONPretty()); } } }
DynamoDB — локальные вторичные индексы
Некоторые приложения выполняют запросы только с первичным ключом, но в некоторых ситуациях используется альтернативный ключ сортировки. Разрешите вашему приложению выбор путем создания одного или нескольких локальных вторичных индексов.
Сложные требования к доступу к данным, такие как объединение миллионов элементов, делают необходимым выполнение более эффективных запросов / сканирований. Локальные вторичные индексы предоставляют альтернативный ключ сортировки для значения ключа раздела. Они также содержат копии всех или некоторых атрибутов таблицы. Они организуют данные по ключу разделения таблицы, но используют другой ключ сортировки.
Использование локального вторичного индекса устраняет необходимость сканирования всей таблицы и позволяет выполнять простой и быстрый запрос с использованием ключа сортировки.
Все локальные вторичные индексы должны удовлетворять определенным условиям —
- Идентичный ключ раздела и ключ раздела исходной таблицы.
- Ключ сортировки только одного скалярного атрибута.
- Проекция исходного ключа сортировки таблицы, действующего как неключевой атрибут.
Все локальные вторичные индексы автоматически содержат ключи разделов и сортировки из родительских таблиц. В запросах это означает эффективный сбор спроецированных атрибутов, а также поиск не спроецированных атрибутов.
Предел хранилища для локального вторичного индекса остается 10 ГБ на значение ключа раздела, которое включает в себя все элементы таблицы и элементы индекса, совместно использующие значение ключа раздела.
Проецирование атрибута
Некоторые операции требуют избыточного чтения / извлечения из-за сложности. Эти операции могут потреблять значительную пропускную способность. Проекция позволяет избежать дорогостоящей выборки и выполнять сложные запросы, изолируя эти атрибуты. Помните, что проекции состоят из атрибутов, скопированных во вторичный индекс.
При создании вторичного индекса вы указываете проецируемые атрибуты. Вспомните три опции, предоставляемые DynamoDB: KEYS_ONLY, INCLUDE и ALL .
Выбирая определенные атрибуты в проекции, учитывайте связанные с этим компромиссы затрат —
-
Если вы проецируете только небольшой набор необходимых атрибутов, вы значительно сократите затраты на хранение.
-
Если вы проектируете часто используемые неключевые атрибуты, вы компенсируете затраты на сканирование с затратами на хранение.
-
Если вы проецируете большинство или все неключевые атрибуты, это максимизирует гибкость и снижает пропускную способность (без поиска); Однако стоимость хранения возрастает.
-
Если вы проектируете KEYS_ONLY для частых записей / обновлений и нечастых запросов, это минимизирует размер, но поддерживает подготовку запросов.
Если вы проецируете только небольшой набор необходимых атрибутов, вы значительно сократите затраты на хранение.
Если вы проектируете часто используемые неключевые атрибуты, вы компенсируете затраты на сканирование с затратами на хранение.
Если вы проецируете большинство или все неключевые атрибуты, это максимизирует гибкость и снижает пропускную способность (без поиска); Однако стоимость хранения возрастает.
Если вы проектируете KEYS_ONLY для частых записей / обновлений и нечастых запросов, это минимизирует размер, но поддерживает подготовку запросов.
Создание локального вторичного индекса
Используйте параметр LocalSecondaryIndex в CreateTable, чтобы создать один или несколько локальных вторичных индексов. Вы должны указать один неключевой атрибут для ключа сортировки. При создании таблицы вы создаете локальные вторичные индексы. При удалении вы удаляете эти индексы.
Таблицы с локальным вторичным индексом должны соответствовать ограничениям в размере 10 ГБ на значение ключа раздела, но могут хранить любое количество элементов.
Локальный вторичный индекс запросов и сканирования
Операция запроса к локальным вторичным индексам возвращает все элементы с совпадающим значением ключа раздела, когда несколько элементов в индексе совместно используют значения ключа сортировки. Соответствующие элементы не возвращаются в определенном порядке. Запросы для локальных вторичных индексов используют либо возможную, либо строгую согласованность, а строго согласованные чтения обеспечивают получение последних значений.
Операция сканирования возвращает все локальные данные вторичного индекса. При сканировании необходимо указать имя таблицы и индекса и разрешить использование выражения фильтра для отбрасывания данных.
Написание предмета
При создании локального вторичного индекса вы указываете атрибут ключа сортировки и его тип данных. Когда вы пишете элемент, его тип должен соответствовать типу данных схемы ключей, если элемент определяет атрибут ключа индекса.
DynamoDB не предъявляет никаких требований к отношениям «один к одному» для элементов таблицы и элементов локального вторичного индекса. Таблицы с несколькими локальными вторичными индексами имеют более высокие затраты на запись, чем таблицы с меньшими.
Вопросы пропускной способности в локальных вторичных индексах
Потребляемая мощность чтения запроса зависит от характера доступа к данным. В запросах используется либо возможная, либо строгая согласованность, при строго согласованных чтениях используется одна единица по сравнению с половиной единиц в конечном итоге согласованных чтений.
Ограничения результата включают максимальный размер 1 МБ. Размеры результата получаются из суммы соответствующего размера элемента индекса, округленной до ближайших 4 КБ, и размера соответствующего элемента таблицы также округленной до ближайших 4 КБ.
Потребляемая мощность записи остается в пределах выделенных единиц. Рассчитайте общую обеспеченную стоимость, найдя сумму потребленных единиц в записи таблицы и потребленных единиц в обновлении индексов.
Вы также можете рассмотреть ключевые факторы, влияющие на стоимость, некоторые из которых могут быть —
-
Когда вы пишете элемент, определяющий индексированный атрибут, или обновляете элемент, чтобы определить неопределенный индексированный атрибут, происходит одна операция записи.
-
Когда обновление таблицы изменяет значение атрибута индексированного ключа, происходит две записи для удаления, а затем — для добавления элемента.
-
Когда запись вызывает удаление индексированного атрибута, происходит одна запись для удаления проекции старого элемента.
-
Если элемент не существует в индексе до или после обновления, запись не производится.
Когда вы пишете элемент, определяющий индексированный атрибут, или обновляете элемент, чтобы определить неопределенный индексированный атрибут, происходит одна операция записи.
Когда обновление таблицы изменяет значение атрибута индексированного ключа, происходит две записи для удаления, а затем — для добавления элемента.
Когда запись вызывает удаление индексированного атрибута, происходит одна запись для удаления проекции старого элемента.
Если элемент не существует в индексе до или после обновления, запись не производится.
Хранение локального вторичного индекса
При записи элемента таблицы DynamoDB автоматически копирует правильный набор атрибутов в требуемые локальные вторичные индексы. Это заряжает ваш аккаунт. Используемое пространство получается из суммы размера байтов первичного ключа таблицы, размера байта атрибута ключа индекса, любого байта текущего размера проецируемого атрибута и накладных расходов 100 байт для каждого элемента индекса.
Хранение оценки получается путем оценки среднего размера элемента индекса и умножения на количество элемента таблицы.
Использование Java для работы с локальными вторичными индексами
Создайте локальный вторичный индекс, сначала создав экземпляр класса DynamoDB. Затем создайте экземпляр класса CreateTableRequest с необходимой информацией запроса. Наконец, используйте метод createTable.
пример
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); String tableName = "Tools"; CreateTableRequest createTableRequest = new CreateTableRequest().withTableName(tableName); //Provisioned Throughput createTableRequest.setProvisionedThroughput ( new ProvisionedThroughput() .withReadCapacityUnits((long)5) .withWriteCapacityUnits(( long)5)); //Attributes ArrayList<AttributeDefinition> attributeDefinitions = new ArrayList<AttributeDefinition>(); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("Make") .withAttributeType("S")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("Model") .withAttributeType("S")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("Line") .withAttributeType("S")); createTableRequest.setAttributeDefinitions(attributeDefinitions); //Key Schema ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>(); tableKeySchema.add(new KeySchemaElement() .withAttributeName("Make") .withKeyType(KeyType.HASH)); //Partition key tableKeySchema.add(new KeySchemaElement() .withAttributeName("Model") .withKeyType(KeyType.RANGE)); //Sort key createTableRequest.setKeySchema(tableKeySchema); ArrayList<KeySchemaElement> indexKeySchema = new ArrayList<KeySchemaElement>(); indexKeySchema.add(new KeySchemaElement() .withAttributeName("Make") .withKeyType(KeyType.HASH)); //Partition key indexKeySchema.add(new KeySchemaElement() .withAttributeName("Line") .withKeyType(KeyType.RANGE)); //Sort key Projection projection = new Projection() .withProjectionType(ProjectionType.INCLUDE); ArrayList<String> nonKeyAttributes = new ArrayList<String>(); nonKeyAttributes.add("Type"); nonKeyAttributes.add("Year"); projection.setNonKeyAttributes(nonKeyAttributes); LocalSecondaryIndex localSecondaryIndex = new LocalSecondaryIndex() .withIndexName("ModelIndex") .withKeySchema(indexKeySchema) .withProjection(p rojection); ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new ArrayList<LocalSecondaryIndex>(); localSecondaryIndexes.add(localSecondaryIndex); createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes); Table table = dynamoDB.createTable(createTableRequest); System.out.println(table.getDescription());
Получить информацию о локальном вторичном индексе с помощью метода description. Просто создайте экземпляр класса DynamoDB, создайте экземпляр класса Table и передайте таблицу методу description.
пример
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); String tableName = "Tools"; Table table = dynamoDB.getTable(tableName); TableDescription tableDescription = table.describe(); List<LocalSecondaryIndexDescription> localSecondaryIndexes = tableDescription.getLocalSecondaryIndexes(); Iterator<LocalSecondaryIndexDescription> lsiIter = localSecondaryIndexes.iterator(); while (lsiIter.hasNext()) { LocalSecondaryIndexDescription lsiDescription = lsiIter.next(); System.out.println("Index info " + lsiDescription.getIndexName() + ":"); Iterator<KeySchemaElement> kseIter = lsiDescription.getKeySchema().iterator(); while (kseIter.hasNext()) { KeySchemaElement kse = kseIter.next(); System.out.printf("\t%s: %s\n", kse.getAttributeName(), kse.getKeyType()); } Projection projection = lsiDescription.getProjection(); System.out.println("\tProjection type: " + projection.getProjectionType()); if (projection.getProjectionType().toString().equals("INCLUDE")) { System.out.println("\t\tNon-key projected attributes: " + projection.getNonKeyAttributes()); } }
Выполните запрос, выполнив те же действия, что и запрос таблицы. Просто создайте экземпляр класса DynamoDB, экземпляр класса Table, экземпляр класса Index, объект запроса и используйте метод запроса.
пример
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); String tableName = "Tools"; Table table = dynamoDB.getTable(tableName); Index index = table.getIndex("LineIndex"); QuerySpec spec = new QuerySpec() .withKeyConditionExpression("Make = :v_make and Line = :v_line") .withValueMap(new ValueMap() .withString(":v_make", "Depault") .withString(":v_line", "SuperSawz")); ItemCollection<QueryOutcome> items = index.query(spec); Iterator<Item> itemsIter = items.iterator(); while (itemsIter.hasNext()) { Item item = itemsIter.next(); System.out.println(item.toJSONPretty()); }
Вы также можете просмотреть следующий пример.
Примечание. В следующем примере может использоваться ранее созданный источник данных. Прежде чем пытаться выполнить, приобретите вспомогательные библиотеки и создайте необходимые источники данных (таблицы с требуемыми характеристиками или другие ссылочные источники).
В следующем примере также используется Eclipse IDE, файл учетных данных AWS и набор инструментов AWS в Java-проекте Eclipse AWS.
пример
import java.util.ArrayList; import java.util.Iterator; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.document.DynamoDB; import com.amazonaws.services.dynamodbv2.document.Index; import com.amazonaws.services.dynamodbv2.document.Item; import com.amazonaws.services.dynamodbv2.document.ItemCollection; import com.amazonaws.services.dynamodbv2.document.PutItemOutcome; import com.amazonaws.services.dynamodbv2.document.QueryOutcome; import com.amazonaws.services.dynamodbv2.document.Table; import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec; import com.amazonaws.services.dynamodbv2.document.utils.ValueMap; import com.amazonaws.services.dynamodbv2.model.AttributeDefinition; import com.amazonaws.services.dynamodbv2.model.CreateTableRequest; import com.amazonaws.services.dynamodbv2.model.KeySchemaElement; import com.amazonaws.services.dynamodbv2.model.KeyType; import com.amazonaws.services.dynamodbv2.model.LocalSecondaryIndex; import com.amazonaws.services.dynamodbv2.model.Projection; import com.amazonaws.services.dynamodbv2.model.ProjectionType; import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput; import com.amazonaws.services.dynamodbv2.model.ReturnConsumedCapacity; import com.amazonaws.services.dynamodbv2.model.Select; public class LocalSecondaryIndexSample { static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient( new ProfileCredentialsProvider())); public static String tableName = "ProductOrders"; public static void main(String[] args) throws Exception { createTable(); query(null); query("IsOpenIndex"); query("OrderCreationDateIndex"); } public static void createTable() { CreateTableRequest createTableRequest = new CreateTableRequest() .withTableName(tableName) .withProvisionedThroughput(new ProvisionedThroughput() .withReadCapacityUnits((long) 1) .withWriteCapacityUnits((long) 1)); // Table partition and sort keys attributes ArrayList<AttributeDefinition> attributeDefinitions = new ArrayList<AttributeDefinition>(); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("CustomerID") .withAttributeType("S")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("OrderID") .withAttributeType("N")); // Index primary key attributes attributeDefinitions.add(new AttributeDefinition() .withAttributeName("OrderDate") .withAttributeType("N")); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("OpenStatus") .withAttributeType("N")); createTableRequest.setAttributeDefinitions(attributeDefinitions); // Table key schema ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>(); tableKeySchema.add(new KeySchemaElement() .withAttributeName("CustomerID") .withKeyType(KeyType.HASH)); //Partition key tableKeySchema.add(new KeySchemaElement() .withAttributeName("OrderID") .withKeyType(KeyType.RANGE)); //Sort key createTableRequest.setKeySchema(tableKeySchema); ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new ArrayList<LocalSecondaryIndex>(); // OrderDateIndex LocalSecondaryIndex orderDateIndex = new LocalSecondaryIndex() .withIndexName("OrderDateIndex"); // OrderDateIndex key schema ArrayList<KeySchemaElement> indexKeySchema = new ArrayList<KeySchemaElement>(); indexKeySchema.add(new KeySchemaElement() .withAttributeName("CustomerID") .withKeyType(KeyType.HASH)); //Partition key indexKeySchema.add(new KeySchemaElement() .withAttributeName("OrderDate") .withKeyType(KeyType.RANGE)); //Sort key orderDateIndex.setKeySchema(indexKeySchema); // OrderCreationDateIndex projection w/attributes list Projection projection = new Projection() .withProjectionType(ProjectionType.INCLUDE); ArrayList<String> nonKeyAttributes = new ArrayList<String>(); nonKeyAttributes.add("ProdCat"); nonKeyAttributes.add("ProdNomenclature"); projection.setNonKeyAttributes(nonKeyAttributes); orderCreationDateIndex.setProjection(projection); localSecondaryIndexes.add(orderDateIndex); // IsOpenIndex LocalSecondaryIndex isOpenIndex = new LocalSecondaryIndex() .withIndexName("IsOpenIndex"); // OpenStatusIndex key schema indexKeySchema = new ArrayList<KeySchemaElement>(); indexKeySchema.add(new KeySchemaElement() .withAttributeName("CustomerID") .withKeyType(KeyType.HASH)); //Partition key indexKeySchema.add(new KeySchemaElement() .withAttributeName("OpenStatus") .withKeyType(KeyType.RANGE)); //Sort key // OpenStatusIndex projection projection = new Projection() .withProjectionType(ProjectionType.ALL); OpenStatusIndex.setKeySchema(indexKeySchema); OpenStatusIndex.setProjection(projection); localSecondaryIndexes.add(OpenStatusIndex); // Put definitions in CreateTable request createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes); System.out.println("Spawning table " + tableName + "..."); System.out.println(dynamoDB.createTable(createTableRequest)); // Pause for ACTIVE status System.out.println("Waiting for ACTIVE table:" + tableName); try { Table table = dynamoDB.getTable(tableName); table.waitForActive(); } catch (InterruptedException e) { e.printStackTrace(); } } public static void query(String indexName) { Table table = dynamoDB.getTable(tableName); System.out.println("\n*************************************************\n"); System.out.println("Executing query on" + tableName); QuerySpec querySpec = new QuerySpec() .withConsistentRead(true) .withScanIndexForward(true) .withReturnConsumedCapacity(ReturnConsumedCapacity.TOTAL); if (indexName == "OpenStatusIndex") { System.out.println("\nEmploying index: '" + indexName + "' open orders for this customer."); System.out.println( "Returns only user-specified attribute list\n"); Index index = table.getIndex(indexName); querySpec.withKeyConditionExpression("CustomerID = :v_custmid and OpenStatus = :v_openstat") .withValueMap(new ValueMap() .withString(":v_custmid", "jane@sample.com") .withNumber(":v_openstat", 1)); querySpec.withProjectionExpression( "OrderDate, ProdCat, ProdNomenclature, OrderStatus"); ItemCollection<QueryOutcome> items = index.query(querySpec); Iterator<Item> iterator = items.iterator(); System.out.println("Printing query results..."); while (iterator.hasNext()) { System.out.println(iterator.next().toJSONPretty()); } } else if (indexName == "OrderDateIndex") { System.out.println("\nUsing index: '" + indexName + "': this customer's orders placed after 05/22/2016."); System.out.println("Projected attributes are returned\n"); Index index = table.getIndex(indexName); querySpec.withKeyConditionExpression("CustomerID = :v_custmid and OrderDate >= :v_ordrdate") .withValueMap(new ValueMap() .withString(":v_custmid", "jane@sample.com") .withNumber(":v_ordrdate", 20160522)); querySpec.withSelect(Select.ALL_PROJECTED_ATTRIBUTES); ItemCollection<QueryOutcome> items = index.query(querySpec); Iterator<Item> iterator = items.iterator(); System.out.println("Printing query results..."); while (iterator.hasNext()) { System.out.println(iterator.next().toJSONPretty()); } } else { System.out.println("\nNo index: All Jane's orders by OrderID:\n"); querySpec.withKeyConditionExpression("CustomerID = :v_custmid") .withValueMap(new ValueMap() .withString(":v_custmid", "jane@example.com")); ItemCollection<QueryOutcome> items = table.query(querySpec); Iterator<Item> iterator = items.iterator(); System.out.println("Printing query results..."); while (iterator.hasNext()) { System.out.println(iterator.next().toJSONPretty()); } } } }
DynamoDB — Агрегация
DynamoDB не обеспечивает функции агрегирования. Вы должны творчески использовать запросы, сканы, индексы и различные инструменты для выполнения этих задач. Во всем этом пропускная способность запросов / сканирований в этих операциях может быть большой.
У вас также есть возможность использовать библиотеки и другие инструменты для вашего предпочтительного языка кодирования DynamoDB. Убедитесь в их совместимости с DynamoDB перед его использованием.
Рассчитать максимум или минимум
Используйте восходящий / нисходящий порядок хранения результатов, параметр Limit и любые параметры, которые устанавливают порядок, чтобы найти самое высокое и самое низкое значения.
Например —
Map<String, AttributeValue> eaval = new HashMap<>(); eaval.put(":v1", new AttributeValue().withS("hashval")); queryExpression = new DynamoDBQueryExpression<Table>() .withIndexName("yourindexname") .withKeyConditionExpression("HK = :v1") .withExpressionAttributeValues(values) .withScanIndexForward(false); //descending order queryExpression.setLimit(1); QueryResultPage<Lookup> res = dynamoDBMapper.queryPage(Table.class, queryExpression);
Подсчитать количество
Используйте DescribeTable, чтобы получить количество элементов таблицы, однако обратите внимание, что он предоставляет устаревшие данные. Также используйте метод Java getScannedCount .
Используйте LastEvaluatedKey, чтобы обеспечить все результаты.
Например —
ScanRequest scanRequest = new ScanRequest().withTableName(yourtblName); ScanResult yourresult = client.scan(scanRequest); System.out.println("#items:" + yourresult.getScannedCount());
Расчет среднего и суммы
Используйте индексы и запрос / сканирование для извлечения и фильтрации значений перед обработкой. Затем просто оперируйте этими значениями через объект.
DynamoDB — Контроль доступа
DynamoDB использует предоставленные вами учетные данные для аутентификации запросов. Эти учетные данные являются обязательными и должны включать разрешения на доступ к ресурсам AWS. Эти разрешения охватывают практически все аспекты DynamoDB вплоть до второстепенных функций операции или функциональности.
Типы разрешений
В этом разделе мы обсудим различные разрешения и доступ к ресурсам в DynamoDB.
Аутентификация пользователей
При регистрации вы предоставили пароль и адрес электронной почты, которые служат в качестве корневых учетных данных. DynamoDB связывает эти данные с вашей учетной записью AWS и использует их для предоставления полного доступа ко всем ресурсам.
AWS рекомендует использовать свои учетные данные root только для создания учетной записи администратора. Это позволяет создавать учетные записи / пользователей IAM с меньшими правами. Пользователи IAM — это другие учетные записи, созданные с помощью службы IAM. Их разрешения / привилегии доступа включают доступ к защищенным страницам и определенные пользовательские разрешения, такие как изменение таблицы.
Ключи доступа предоставляют еще одну опцию для дополнительных учетных записей и доступа. Используйте их для предоставления доступа, а также во избежание ручного предоставления доступа в определенных ситуациях. Федеративные пользователи предоставляют еще одну возможность, предоставляя доступ через провайдера идентификации.
администрация
Ресурсы AWS остаются в собственности аккаунта. Политики разрешений регулируют разрешения, предоставляемые для порождения или доступа к ресурсам. Администраторы связывают политики разрешений с удостоверениями IAM, то есть с ролями, группами, пользователями и службами. Они также прикрепляют разрешения к ресурсам.
Разрешения указывают пользователей, ресурсы и действия. Обратите внимание, что администраторы — это просто учетные записи с правами администратора.
Операция и ресурсы
Таблицы остаются основными ресурсами в DynamoDB. Подресурсы служат дополнительными ресурсами, например, потоками и индексами. Эти ресурсы используют уникальные имена, некоторые из которых упомянуты в следующей таблице:
| Тип | ARN (название ресурса Amazon) |
|---|---|
| Поток | ARN: AWS: dynamodb: регион: счет-идентификатор: имя таблицы таблицы / / поток / поток метка |
| Индекс | счет-идентификатор:: / / индекс имя-таблицы / имя-таблицы индекса ARN: AWS: dynamodb: регион |
| Таблица | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
Владение
Владелец ресурса определяется как учетная запись AWS, которая породила ресурс, или учетная запись основного объекта, ответственная за проверку подлинности запроса при создании ресурса. Рассмотрим, как это работает в среде DynamoDB —
-
Используя корневые учетные данные для создания таблицы, ваша учетная запись остается владельцем ресурса.
-
При создании пользователя IAM и предоставлении пользователю разрешения на создание таблицы ваша учетная запись остается владельцем ресурса.
-
При создании пользователя IAM и предоставлении пользователю и любому лицу, способному взять на себя роль, разрешения на создание таблицы, ваша учетная запись остается владельцем ресурса.
Используя корневые учетные данные для создания таблицы, ваша учетная запись остается владельцем ресурса.
При создании пользователя IAM и предоставлении пользователю разрешения на создание таблицы ваша учетная запись остается владельцем ресурса.
При создании пользователя IAM и предоставлении пользователю и любому лицу, способному взять на себя роль, разрешения на создание таблицы, ваша учетная запись остается владельцем ресурса.
Управление доступом к ресурсам
Управление доступом в основном требует внимания к политике разрешений, описывающей пользователей и доступ к ресурсам. Вы связываете политики с идентификационными данными или ресурсами IAM. Однако DynamoDB поддерживает только политики IAM / идентификации.
Политики на основе идентификаторов (IAM) позволяют предоставлять привилегии следующими способами:
- Прикрепите разрешения для пользователей или групп.
- Присоедините разрешения к ролям для разрешений между учетными записями.
Другие AWS допускают политики на основе ресурсов. Эти политики разрешают доступ к таким вещам, как корзина S3.
Элементы политики
Политики определяют действия, эффекты, ресурсы и принципы; и дать разрешение на выполнение этих операций.
Примечание. Для операций API могут потребоваться разрешения для нескольких действий.
Присмотритесь к следующим элементам политики —
-
Ресурс — ARN идентифицирует это.
-
Действие — ключевые слова идентифицируют эти операции с ресурсами и разрешают или запрещают.
-
Эффект — он определяет эффект для пользовательского запроса на действие, то есть разрешить или запретить с отказом по умолчанию.
-
Принципал — это идентифицирует пользователя, прикрепленного к политике.
Ресурс — ARN идентифицирует это.
Действие — ключевые слова идентифицируют эти операции с ресурсами и разрешают или запрещают.
Эффект — он определяет эффект для пользовательского запроса на действие, то есть разрешить или запретить с отказом по умолчанию.
Принципал — это идентифицирует пользователя, прикрепленного к политике.
условия
Предоставляя разрешения, вы можете указать условия, когда политики станут активными, например, на определенную дату. Выразите условия с помощью ключей условий, которые включают общесистемные ключи AWS и ключи DynamoDB. Эти ключи подробно обсуждаются позже в руководстве.
Разрешения консоли
Пользователь требует определенных основных разрешений для использования консоли. Они также требуют разрешения для консоли в других стандартных службах —
- CloudWatch
- Конвейер данных
- Управление идентификацией и доступом
- Служба уведомлений
- лямбда
Если политика IAM оказывается слишком ограниченной, пользователь не может эффективно использовать консоль. Кроме того, вам не нужно беспокоиться о правах пользователей для тех, кто только вызывает CLI или API.
Общие правила использования Iam
AWS покрывает обычные операции в разрешениях с помощью автономных политик, управляемых IAM. Они предоставляют ключевые разрешения, позволяющие вам избежать глубокого изучения того, что вы должны предоставить.
Некоторые из них следующие:
-
AmazonDynamoDBReadOnlyAccess — предоставляет доступ только для чтения через консоль.
-
AmazonDynamoDBFullAccess — предоставляет полный доступ через консоль.
-
AmazonDynamoDBFullAccesswithDataPipeline — предоставляет полный доступ через консоль и разрешает экспорт / импорт с помощью Data Pipeline.
AmazonDynamoDBReadOnlyAccess — предоставляет доступ только для чтения через консоль.
AmazonDynamoDBFullAccess — предоставляет полный доступ через консоль.
AmazonDynamoDBFullAccesswithDataPipeline — предоставляет полный доступ через консоль и разрешает экспорт / импорт с помощью Data Pipeline.
Вы также можете создавать собственные политики.
Предоставление привилегий: использование оболочки
Вы можете предоставить разрешения с помощью оболочки Javascript. Следующая программа показывает типичную политику разрешений —
{ "Version": "2016-05-22", "Statement": [ { "Sid": "DescribeQueryScanToolsTable", "Effect": "Deny", "Action": [ "dynamodb:DescribeTable", "dynamodb:Query", "dynamodb:Scan" ], "Resource": "arn:aws:dynamodb:us-west-2:account-id:table/Tools" } ] }
Вы можете просмотреть три примера:
Заблокировать пользователя от выполнения любого табличного действия.
{ "Version": "2016-05-23", "Statement": [ { "Sid": "AllAPIActionsOnTools", "Effect": "Deny", "Action": "dynamodb:*", "Resource": "arn:aws:dynamodb:us-west-2:155556789012:table/Tools" } ] }
Блокировать доступ к таблице и ее индексам.
{ "Version": "2016-05-23", "Statement": [ { "Sid": "AccessAllIndexesOnTools", "Effect": "Deny", "Action": [ "dynamodb:*" ], "Resource": [ "arn:aws:dynamodb:us-west-2:155556789012:table/Tools", "arn:aws:dynamodb:us-west-2:155556789012:table/Tools/index/*" ] } ] }
Заблокировать пользователя от совершения покупки зарезервированной емкости.
{ "Version": "2016-05-23", "Statement": [ { "Sid": "BlockReservedCapacityPurchases", "Effect": "Deny", "Action": "dynamodb:PurchaseReservedCapacityOfferings", "Resource": "arn:aws:dynamodb:us-west-2:155556789012:*" } ] }
Предоставление прав: использование консоли с графическим интерфейсом
Вы также можете использовать консоль GUI для создания политик IAM. Для начала выберите Таблицы на панели навигации. В списке таблиц выберите таблицу назначения и выполните следующие действия.
Шаг 1 — Выберите вкладку Контроль доступа .
Шаг 2 — Выберите поставщика удостоверений, действий и атрибутов политики. Выберите Создать политику после ввода всех настроек.
Шаг 3. Выберите « Прикрепить инструкции к политике» и выполните каждый необходимый шаг, чтобы связать политику с соответствующей ролью IAM.
DynamoDB — API разрешений
DynamoDB API предлагает большой набор действий, для которых требуются разрешения. При настройке разрешений вы должны установить разрешенные действия, разрешенные ресурсы и условия каждого из них.
Вы можете указать действия в поле Действие политики. Укажите значение ресурса в поле «Ресурс» политики. Но убедитесь, что вы используете правильный синтаксис, содержащий префикс Dynamodb:: с операцией API.
Например — Dynamodb: CreateTable
Вы также можете использовать условные ключи для фильтрации разрешений.
Разрешения и действия API
Внимательно рассмотрите действия API и соответствующие разрешения, приведенные в следующей таблице:
| Операция API | Необходимое разрешение |
|---|---|
| BatchGetItem | dynamodb: BatchGetItem |
| BatchWriteItem | dynamodb: BatchWriteItem |
| CreateTable | dynamodb: CreateTable |
| Удалить пункт | dynamodb: DeleteItem |
| DeleteTable | dynamodb: DeleteTable |
| DescribeLimits | dynamodb: DescribeLimits |
| DescribeReservedCapacity | dynamodb: DescribeReservedCapacity |
| DescribeReservedCapacityOfferings | dynamodb: DescribeReservedCapacityOfferings |
| DescribeStream | dynamodb: DescribeStream |
| DescribeTable | dynamodb: DescribeTable |
| GetItem | dynamodb: GetItem |
| GetRecords | dynamodb: GetRecords |
| GetShardIterator | dynamodb: GetShardIterator |
| ListStreams | dynamodb: ListStreams |
| ListTables | dynamodb: ListTables |
| PurchaseReservedCapacityOfferings | dynamodb: PurchaseReservedCapacityOfferings |
| PutItem | dynamodb: PutItem |
| запрос | dynamodb: Запрос |
| сканирование | dynamodb: Scan |
| UpdateItem | dynamodb: UpdateItem |
| UpdateTable | dynamodb: UpdateTable |
Ресурсы
В следующей таблице вы можете просмотреть ресурсы, связанные с каждым разрешенным действием API —
| Операция API | Ресурс |
|---|---|
| BatchGetItem | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| BatchWriteItem | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| CreateTable | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| Удалить пункт | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| DeleteTable | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| DescribeLimits | ARN: AWS: dynamodb: регион: счет-ID: * |
| DescribeReservedCapacity | ARN: AWS: dynamodb: регион: счет-ID: * |
| DescribeReservedCapacityOfferings | ARN: AWS: dynamodb: регион: счет-ID: * |
| DescribeStream | ARN: AWS: dynamodb: регион: счет-идентификатор: имя таблицы таблицы / / поток / поток метка |
| DescribeTable | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| GetItem | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| GetRecords | ARN: AWS: dynamodb: регион: счет-идентификатор: имя таблицы таблицы / / поток / поток метка |
| GetShardIterator | ARN: AWS: dynamodb: регион: счет-идентификатор: имя таблицы таблицы / / поток / поток метка |
| ListStreams | ARN: AWS: dynamodb: регион: счет-идентификатор: таблица / имя-таблицы / поток / * |
| ListTables | * |
| PurchaseReservedCapacityOfferings | ARN: AWS: dynamodb: регион: счет-ID: * |
| PutItem | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| запрос |
ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / или же счет-идентификатор:: / / индекс имя-таблицы / имя-таблицы индекса ARN: AWS: dynamodb: регион |
| сканирование |
ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / или же счет-идентификатор:: / / индекс имя-таблицы / имя-таблицы индекса ARN: AWS: dynamodb: регион |
| UpdateItem | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
| UpdateTable | ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы / |
ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы /
или же
счет-идентификатор:: / / индекс имя-таблицы / имя-таблицы индекса ARN: AWS: dynamodb: регион
ARN: AWS: dynamodb: регион: счет-ID: имя-таблицы таблицы /
или же
счет-идентификатор:: / / индекс имя-таблицы / имя-таблицы индекса ARN: AWS: dynamodb: регион
DynamoDB — Условия
При предоставлении разрешений DynamoDB позволяет указывать для них условия с помощью подробной политики IAM с ключами условий. Это поддерживает такие настройки, как доступ к определенным элементам и атрибутам.
Примечание . DynamoDB не поддерживает теги.
Детальный контроль
Некоторые условия допускают конкретизацию элементов и атрибутов, например предоставление доступа только для чтения к определенным элементам на основе учетной записи пользователя. Реализуйте этот уровень контроля с помощью условных политик IAM, которые управляют учетными данными безопасности. Затем просто примените политику к нужным пользователям, группам и ролям. Федерация веб-идентичности, о которой пойдет речь позже, также предоставляет способ управления доступом пользователей через учетные записи Amazon, Facebook и Google.
Элемент условия политики IAM реализует управление доступом. Вы просто добавляете это в политику. Пример его использования состоит в запрещении или разрешении доступа к элементам и атрибутам таблицы. Элемент condition также может использовать ключи условия для ограничения разрешений.
Вы можете просмотреть следующие два примера ключей условия:
-
dynamicodb: LeadingKeys — запрещает доступ к элементу пользователям без идентификатора, соответствующего значению ключа раздела.
-
dynamicodb: Attributes — запрещает пользователям доступ или работу с атрибутами, не входящими в список.
dynamicodb: LeadingKeys — запрещает доступ к элементу пользователям без идентификатора, соответствующего значению ключа раздела.
dynamicodb: Attributes — запрещает пользователям доступ или работу с атрибутами, не входящими в список.
При оценке политики IAM приводят к истинному или ложному значению. Если какая-либо часть оценивается как ложная, вся политика оценивается как ложная, что приводит к отказу в доступе. Обязательно укажите всю необходимую информацию в условных ключах, чтобы обеспечить пользователям соответствующий доступ.
Предопределенные ключи условия
AWS предлагает набор предопределенных ключей условий, которые применяются ко всем сервисам. Они поддерживают широкий спектр использования и мелкие детали при проверке пользователей и доступа.
Примечание. Чувствительность к регистру в клавишах условий.
Вы можете просмотреть выбор следующих сервисных ключей —
-
dynamicodb: LeadingKey — представляет первый ключевой атрибут таблицы; ключ раздела. Используйте модификатор ForAllValues в условиях.
-
dynamicodb: Select — представляет запрос / запрос на сканирование. Выберите параметр. Он должен иметь значение ALL_ATTRIBUTES, ALL_PROJECTED_ATTRIBUTES, SPECIFIC_ATTRIBUTES или COUNT.
-
dynamicodb: Attributes — представляет список имен атрибутов в запросе или атрибуты, возвращаемые из запроса. Его значения и их функции напоминают параметры действий API, например, BatchGetItem использует AttributesToGet.
-
dynamicodb: ReturnValues — представляет параметр запроса ReturnValues и может использовать следующие значения: ALL_OLD, UPDATED_OLD, ALL_NEW, UPDATED_NEW и NONE.
-
dynamicodb: ReturnConsumedCapacity — представляет параметр запроса ReturnConsumedCapacity и может использовать следующие значения: TOTAL и NONE.
dynamicodb: LeadingKey — представляет первый ключевой атрибут таблицы; ключ раздела. Используйте модификатор ForAllValues в условиях.
dynamicodb: Select — представляет запрос / запрос на сканирование. Выберите параметр. Он должен иметь значение ALL_ATTRIBUTES, ALL_PROJECTED_ATTRIBUTES, SPECIFIC_ATTRIBUTES или COUNT.
dynamicodb: Attributes — представляет список имен атрибутов в запросе или атрибуты, возвращаемые из запроса. Его значения и их функции напоминают параметры действий API, например, BatchGetItem использует AttributesToGet.
dynamicodb: ReturnValues — представляет параметр запроса ReturnValues и может использовать следующие значения: ALL_OLD, UPDATED_OLD, ALL_NEW, UPDATED_NEW и NONE.
dynamicodb: ReturnConsumedCapacity — представляет параметр запроса ReturnConsumedCapacity и может использовать следующие значения: TOTAL и NONE.
DynamoDB — Федерация веб-идентичности
Федерация веб-идентификации позволяет упростить аутентификацию и авторизацию для больших групп пользователей. Вы можете пропустить создание отдельных учетных записей и требовать, чтобы пользователи входили в систему поставщика удостоверений, чтобы получить временные учетные данные или токены. Для управления учетными данными используется служба маркеров безопасности AWS (STS). Приложения используют эти токены для взаимодействия со службами.
Федерация веб-идентификации также поддерживает других поставщиков идентификационных данных, таких как Amazon, Google и Facebook.
Функция. При использовании федерация веб-идентификации сначала вызывает провайдера идентификации для аутентификации пользователя и приложения, а провайдер возвращает токен. Это приводит к тому, что приложение вызывает AWS STS и передает токен для ввода. STS авторизует приложение и предоставляет ему временные учетные данные для доступа, которые позволяют приложению использовать роль IAM и получать доступ к ресурсам на основе политики.
Реализация федерации веб-идентификации
Вы должны выполнить следующие три шага перед использованием —
-
Используйте поддерживаемого стороннего поставщика удостоверений, чтобы зарегистрироваться в качестве разработчика.
-
Зарегистрируйте свое приложение у провайдера, чтобы получить идентификатор приложения.
-
Создайте одну или несколько ролей IAM, включая вложение политики. Вы должны использовать роль для каждого поставщика в приложении.
Используйте поддерживаемого стороннего поставщика удостоверений, чтобы зарегистрироваться в качестве разработчика.
Зарегистрируйте свое приложение у провайдера, чтобы получить идентификатор приложения.
Создайте одну или несколько ролей IAM, включая вложение политики. Вы должны использовать роль для каждого поставщика в приложении.
Предположим, что вы используете одну из своих ролей IAM для использования федерации веб-идентификации. Ваше приложение должно затем выполнить трехэтапный процесс —
- Аутентификация
- Получение учетных данных
- Доступ к ресурсам
На первом этапе ваше приложение использует собственный интерфейс для вызова поставщика, а затем управляет процессом токена.
Затем на втором шаге выполняется управление токенами, и ваше приложение должно отправить запрос AssumeRoleWithWebIdentity в AWS STS. Запрос содержит первый токен, идентификатор приложения поставщика и ARN роли IAM. STS предоставляет учетные данные, срок действия которых истекает через определенный период.
На последнем шаге ваше приложение получает ответ от STS, содержащий информацию о доступе к ресурсам DynamoDB. Он состоит из учетных данных, срока действия, роли и идентификатора роли.
DynamoDB — конвейер данных
Data Pipeline позволяет экспортировать и импортировать данные в / из таблицы, файла или корзины S3. Это, конечно, оказывается полезным для резервного копирования, тестирования и для аналогичных потребностей или сценариев.
В экспорте вы используете консоль Data Pipeline, которая создает новый конвейер и запускает кластер Amazon EMR (Elastic MapReduce) для выполнения экспорта. EMR читает данные из DynamoDB и записывает в цель. Мы подробно обсудим EMR позже в этом уроке.
В операции импорта вы используете консоль Data Pipeline, которая создает конвейер и запускает EMR для выполнения импорта. Он читает данные из источника и записывает в место назначения.
Примечание. Операции по экспорту / импорту несут затраты с учетом используемых услуг, в частности EMR и S3.
Использование конвейера данных
Вы должны указать действие и права доступа к ресурсам при использовании конвейера данных. Вы можете использовать роль или политику IAM для их определения. Пользователи, которые выполняют импорт / экспорт, должны отметить, что им потребуются идентификатор активного ключа доступа и секретный ключ.
Роли IAM для конвейера данных
Для использования конвейера данных необходимы две роли IAM —
-
DataPipelineDefaultRole — содержит все действия, которые вы разрешаете выполнять конвейеру за вас.
-
DataPipelineDefaultResourceRole — здесь есть ресурсы, которые вы разрешаете предоставить конвейеру.
DataPipelineDefaultRole — содержит все действия, которые вы разрешаете выполнять конвейеру за вас.
DataPipelineDefaultResourceRole — здесь есть ресурсы, которые вы разрешаете предоставить конвейеру.
Если вы новичок в Data Pipeline, вы должны породить каждую роль. Все предыдущие пользователи обладают этими ролями из-за существующих ролей.
Используйте консоль IAM для создания ролей IAM для конвейера данных и выполните следующие четыре шага:
Шаг 1. Войдите в консоль IAM, расположенную по адресу https://console.aws.amazon.com/iam/.
Шаг 2 — Выберите Роли на панели инструментов.
Шаг 3 — Выберите « Создать новую роль» . Затем введите DataPipelineDefaultRole в поле « Имя роли» и выберите « Следующий шаг» . В списке « Роли службы AWS» на панели « Тип роли» перейдите к конвейеру данных и выберите « Выбрать» . Выберите « Создать роль» на панели « Обзор» .
Шаг 4 — Выберите « Создать новую роль» .
DynamoDB — Резервное копирование данных
Используйте функцию импорта / экспорта Data Pipeline для выполнения резервного копирования. То, как вы выполняете резервное копирование, зависит от того, используете ли вы консоль с графическим интерфейсом или напрямую используете конвейер данных (API). Либо создайте отдельные конвейеры для каждой таблицы при использовании консоли, либо импортируйте / экспортируйте несколько таблиц в один конвейер при использовании прямой опции.
Экспорт и импорт данных
Вы должны создать корзину Amazon S3 до выполнения экспорта. Вы можете экспортировать из одной или нескольких таблиц.
Выполните следующие четыре шага, чтобы выполнить экспорт —
Шаг 1. Войдите в консоль управления AWS и откройте консоль конвейера данных, расположенную по адресу https://console.aws.amazon.com/datapipeline/.
Шаг 2. Если в регионе AWS нет конвейеров, выберите « Начать сейчас» . Если у вас есть один или несколько, выберите Создать новый конвейер .
Шаг 3 — На странице создания введите имя для вашего конвейера. Выберите Build, используя шаблон для параметра Source. Выберите Экспорт таблицы DynamoDB в S3 из списка. Введите исходную таблицу в поле Имя исходной таблицы DynamoDB .
Введите целевой контейнер S3 в текстовое поле « Выходная папка S3» в следующем формате: s3: // nameOfBucket / region / nameOfFolder. Введите пункт назначения S3 для файла журнала в поле S3 location for logs .
Шаг 4 — Выберите Активировать после ввода всех настроек.
Конвейер может занять несколько минут, чтобы завершить процесс создания. Используйте консоль для контроля ее состояния. Подтвердите успешную обработку с помощью консоли S3, просмотрев экспортированный файл.
Импорт данных
Успешный импорт может произойти, только если выполняются следующие условия: вы создали таблицу назначения, место назначения и источник используют одинаковые имена, а место назначения и источник используют одинаковую схему ключей.
Вы можете использовать заполненную таблицу назначения, однако импорт заменяет элементы данных, разделяющие ключ с исходными элементами, а также добавляет лишние элементы в таблицу. Пункт назначения также может использовать другой регион.
Хотя вы можете экспортировать несколько источников, вы можете импортировать только один для каждой операции. Вы можете выполнить импорт, придерживаясь следующих шагов —
Шаг 1. Войдите в консоль управления AWS и откройте консоль конвейера данных.
Шаг 2 — Если вы собираетесь выполнить межрегиональный импорт, вам следует выбрать регион назначения.
Шаг 3 — Выберите Создать новый конвейер .
Шаг 4 — Введите имя конвейера в поле Имя . Выберите Построить, используя шаблон для параметра «Источник», и в списке шаблонов выберите « Импортировать данные резервной копии DynamoDB из S3» .
Введите местоположение исходного файла в текстовом поле « Папка ввода S3» . Введите имя таблицы назначения в поле Имя таблицы Target DynamoDB . Затем введите местоположение файла журнала в текстовом поле S3 location for logs .
Шаг 5 — Выберите Активировать после ввода всех настроек.
Импорт начинается сразу после создания конвейера. Конвейеру может потребоваться несколько минут для завершения процесса создания.
ошибки
При возникновении ошибок консоль Data Pipeline отображает ERROR в качестве состояния конвейера. Нажав на конвейер с ошибкой, вы попадете на страницу с подробной информацией, которая показывает каждый шаг процесса и момент, когда произошел сбой. Файлы журнала внутри также дают некоторое представление.
Вы можете просмотреть общие причины ошибок следующим образом:
-
Таблица назначения для импорта не существует или не использует схему ключей, идентичную исходной.
-
Контейнер S3 не существует, или у вас нет разрешения на чтение / запись для него.
-
Время истекло.
-
У вас нет необходимых разрешений на экспорт / импорт.
-
Ваш аккаунт AWS достиг лимита ресурсов.
Таблица назначения для импорта не существует или не использует схему ключей, идентичную исходной.
Контейнер S3 не существует, или у вас нет разрешения на чтение / запись для него.
Время истекло.
У вас нет необходимых разрешений на экспорт / импорт.
Ваш аккаунт AWS достиг лимита ресурсов.
DynamoDB — Мониторинг
Amazon предлагает CloudWatch для агрегирования и анализа производительности с помощью консоли CloudWatch, командной строки или API CloudWatch. Вы также можете использовать его для установки будильника и выполнения задач. Он выполняет определенные действия с определенными событиями.
Консоль Cloudwatch
Используйте CloudWatch, открыв Консоль управления, а затем открыв консоль CloudWatch по адресу https://console.aws.amazon.com/cloudwatch/ .
Затем вы можете выполнить следующие шаги —
-
Выберите Метрики на панели навигации.
-
В разделе Метрики DynamoDB на панели «Метрики CloudWatch по категориям» выберите « Метрики таблицы» .
-
Используйте верхнюю панель, чтобы прокрутить ниже и изучить весь список показателей таблицы. Список просмотра содержит параметры метрик.
Выберите Метрики на панели навигации.
В разделе Метрики DynamoDB на панели «Метрики CloudWatch по категориям» выберите « Метрики таблицы» .
Используйте верхнюю панель, чтобы прокрутить ниже и изучить весь список показателей таблицы. Список просмотра содержит параметры метрик.
В интерфейсе результатов можно выбрать / отменить выбор каждой метрики, установив флажок рядом с именем ресурса и метрикой. Тогда вы сможете просматривать графики для каждого элемента.
Интеграция API
Вы можете получить доступ к CloudWatch с запросами. Используйте значения метрик для выполнения действий CloudWatch. Примечание. DynamoDB не отправляет метрики со значением ноль. Он просто пропускает метрики для периодов времени, когда эти метрики остаются при этом значении.
Ниже приведены некоторые из наиболее часто используемых показателей —
-
ConditionalCheckFailedRequests — отслеживает количество неудачных попыток условной записи, например условной записи PutItem. Неудачные записи увеличивают этот показатель на единицу при оценке на false. Также выдает ошибку HTTP 400.
-
ConsumedReadCapacityUnits — количественно определяет единицы емкости, использованные за определенный период времени. Вы можете использовать это, чтобы исследовать отдельную таблицу и индекс потребления.
-
ConsumedWriteCapacityUnits — количественно определяет единицы емкости, использованные за определенный период времени. Вы можете использовать это, чтобы исследовать отдельную таблицу и индекс потребления.
-
ReadThrottleEvents — количественно оценивает запросы, превышающие выделенные единицы емкости в чтениях таблиц / индексов. Он увеличивается на каждом газе, включая пакетные операции с несколькими газами.
-
ReturnedBytes — количественно определяет количество байтов, возвращаемых в операциях поиска в течение определенного периода времени.
-
ReturnedItemCount — количественно оценивает элементы, возвращенные в операциях Query и Scan за определенный период времени. Он касается только возвращенных предметов, а не тех, которые были оценены, как правило, это совершенно разные цифры.
ConditionalCheckFailedRequests — отслеживает количество неудачных попыток условной записи, например условной записи PutItem. Неудачные записи увеличивают этот показатель на единицу при оценке на false. Также выдает ошибку HTTP 400.
ConsumedReadCapacityUnits — количественно определяет единицы емкости, использованные за определенный период времени. Вы можете использовать это, чтобы исследовать отдельную таблицу и индекс потребления.
ConsumedWriteCapacityUnits — количественно определяет единицы емкости, использованные за определенный период времени. Вы можете использовать это, чтобы исследовать отдельную таблицу и индекс потребления.
ReadThrottleEvents — количественно оценивает запросы, превышающие выделенные единицы емкости в чтениях таблиц / индексов. Он увеличивается на каждом газе, включая пакетные операции с несколькими газами.
ReturnedBytes — количественно определяет количество байтов, возвращаемых в операциях поиска в течение определенного периода времени.
ReturnedItemCount — количественно оценивает элементы, возвращенные в операциях Query и Scan за определенный период времени. Он касается только возвращенных предметов, а не тех, которые были оценены, как правило, это совершенно разные цифры.
Примечание. Существует еще много метрик, и большинство из них позволяют вычислять средние, суммы, максимумы, минимумы и счетчики.
DynamoDB — CloudTrail
DynamoDB включает в себя интеграцию CloudTrail. Он захватывает низкоуровневые запросы API от или для DynamoDB в учетной записи и отправляет файлы журнала в указанную корзину S3. Он нацелен на вызовы из консоли или API. Вы можете использовать эти данные, чтобы определить сделанные запросы и их источник, пользователя, метку времени и многое другое.
Когда он включен, он отслеживает действия в файлах журналов, которые включают в себя другие служебные записи. Он поддерживает восемь действий и два потока —
Восемь действий следующие:
- CreateTable
- DeleteTable
- DescribeTable
- ListTables
- UpdateTable
- DescribeReservedCapacity
- DescribeReservedCapacityOfferings
- PurchaseReservedCapacityOfferings
В то время как два потока —
- DescribeStream
- ListStreams
Все журналы содержат информацию об учетных записях, делающих запросы. Вы можете определить подробную информацию, например, отправили ли пользователь root или IAM запрос, или с временными учетными данными, или с федерацией.
Файлы журнала остаются в хранилище на любое время, указанное вами, с настройками архивирования и удаления. По умолчанию создаются зашифрованные журналы. Вы можете установить оповещения для новых журналов. Вы также можете организовать несколько журналов по регионам и учетным записям в одном ведре.
Интерпретация файлов журнала
Каждый файл содержит одну или несколько записей. Каждая запись состоит из нескольких событий формата JSON. Запись представляет запрос и включает в себя связанную информацию; без гарантии заказа.
Вы можете просмотреть следующий пример файла журнала —
{"Records": [ { "eventVersion": "5.05", "userIdentity": { "type": "AssumedRole", "principalId": "AKTTIOSZODNN8SAMPLE:jane", "arn": "arn:aws:sts::155522255533:assumed-role/users/jane", "accountId": "155522255533", "accessKeyId": "AKTTIOSZODNN8SAMPLE", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2016-05-11T19:01:01Z" }, "sessionIssuer": { "type": "Role", "principalId": "AKTTI44ZZ6DHBSAMPLE", "arn": "arn:aws:iam::499955777666:role/admin-role", "accountId": "499955777666", "userName": "jill" } } }, "eventTime": "2016-05-11T14:33:20Z", "eventSource": "dynamodb.amazonaws.com", "eventName": "DeleteTable", "awsRegion": "us-west-2", "sourceIPAddress": "192.0.2.0", "userAgent": "console.aws.amazon.com", "requestParameters": {"tableName": "Tools"}, "responseElements": {"tableDescription": { "tableName": "Tools", "itemCount": 0, "provisionedThroughput": { "writeCapacityUnits": 25, "numberOfDecreasesToday": 0, "readCapacityUnits": 25 }, "tableStatus": "DELETING", "tableSizeBytes": 0 }}, "requestID": "4D89G7D98GF7G8A7DF78FG89AS7GFSO5AEMVJF66Q9ASUAAJG", "eventID": "a954451c-c2fc-4561-8aea-7a30ba1fdf52", "eventType": "AwsApiCall", "apiVersion": "2013-04-22", "recipientAccountId": "155522255533" } ]}
DynamoDB — MapReduce
Amazon Elastic MapReduce (EMR) позволяет вам быстро и эффективно обрабатывать большие данные. EMR запускает Apache Hadoop на экземплярах EC2, но упрощает процесс. Вы используете Apache Hive для запроса карты, чтобы уменьшить потоки заданий через HiveQL , язык запросов, похожий на SQL. Apache Hive служит способом оптимизации запросов и ваших приложений.
Для запуска потока работ можно использовать вкладку EMR консоли управления, интерфейс командной строки EMR, API или SDK. У вас также есть возможность запустить Hive в интерактивном режиме или использовать скрипт.
Операции чтения / записи EMR влияют на потребление пропускной способности, однако в больших запросах он выполняет повторные попытки с защитой алгоритма отката. Кроме того, выполнение EMR одновременно с другими операциями и задачами может привести к регулированию.
Интеграция DynamoDB / EMR не поддерживает двоичные и двоичные атрибуты набора.
DynamoDB / EMR Необходимые условия интеграции
Просмотрите этот контрольный список необходимых элементов перед использованием EMR —
- Аккаунт AWS
- Заполненная таблица под той же учетной записью, используемой в операциях EMR
- Специальная версия Hive с подключением DynamoDB
- Поддержка подключения DynamoDB
- Ведро S3 (опционально)
- Клиент SSH (необязательно)
- Пара ключей EC2 (необязательно)
Настройка улья
Перед использованием EMR создайте пару ключей для запуска Hive в интерактивном режиме. Пара ключей позволяет подключаться к экземплярам EC2 и основным узлам потоков заданий.
Вы можете выполнить это, выполнив следующие шаги —
-
Войдите в консоль управления и откройте консоль EC2, расположенную по адресу https://console.aws.amazon.com/ec2/.
-
Выберите область в верхней правой части консоли. Убедитесь, что регион соответствует региону DynamoDB.
-
На панели навигации выберите Пары ключей .
-
Выберите Создать пару ключей .
-
В поле Имя пары ключей введите имя и выберите Создать .
-
Загрузите полученный файл закрытого ключа, который использует следующий формат: filename.pem.
Войдите в консоль управления и откройте консоль EC2, расположенную по адресу https://console.aws.amazon.com/ec2/.
Выберите область в верхней правой части консоли. Убедитесь, что регион соответствует региону DynamoDB.
На панели навигации выберите Пары ключей .
Выберите Создать пару ключей .
В поле Имя пары ключей введите имя и выберите Создать .
Загрузите полученный файл закрытого ключа, который использует следующий формат: filename.pem.
Примечание. Вы не можете подключиться к экземплярам EC2 без пары ключей.
Улей кластер
Создайте кластер с поддержкой Hive для запуска Hive. Он создает необходимую среду приложений и инфраструктуры для соединения Hive-DynamoDB.
Вы можете выполнить эту задачу, используя следующие шаги —
-
Получите доступ к консоли EMR.
-
Выберите Создать кластер .
-
На экране создания задайте конфигурацию кластера с описательным именем для кластера, выберите « Да» для защиты от прерываний и установите флажок « Включен для ведения журнала», «Назначение S3» для расположения папки S3 журнала и « Включен» для отладки.
-
На экране «Конфигурация программного обеспечения» убедитесь, что в полях находятся: Amazon для распространения Hadoop, последняя версия для версии AMI, версия Hive по умолчанию для приложений, которые будут установлены, Hive, и версия Pig по умолчанию для приложений, которые будут установлены, Pig.
-
На экране «Конфигурация оборудования» убедитесь, что в полях « Запуск в EC2-Classic для сети» нет значения «Нет предпочтений для зоны доступности EC2», по умолчанию для типа экземпляра Master-Amazon EC2, нет проверки для экземпляров «Спотовый запрос», по умолчанию для экземпляра Core-Amazon EC2. Тип: 2 для счетчика, нет проверки для экземпляров спотового запроса, по умолчанию для типа экземпляра Task-Amazon EC2, 0 для счетчика и без проверки для экземпляров спотового запроса.
Получите доступ к консоли EMR.
Выберите Создать кластер .
На экране создания задайте конфигурацию кластера с описательным именем для кластера, выберите « Да» для защиты от прерываний и установите флажок « Включен для ведения журнала», «Назначение S3» для расположения папки S3 журнала и « Включен» для отладки.
На экране «Конфигурация программного обеспечения» убедитесь, что в полях находятся: Amazon для распространения Hadoop, последняя версия для версии AMI, версия Hive по умолчанию для приложений, которые будут установлены, Hive, и версия Pig по умолчанию для приложений, которые будут установлены, Pig.
На экране «Конфигурация оборудования» убедитесь, что в полях « Запуск в EC2-Classic для сети» нет значения «Нет предпочтений для зоны доступности EC2», по умолчанию для типа экземпляра Master-Amazon EC2, нет проверки для экземпляров «Спотовый запрос», по умолчанию для экземпляра Core-Amazon EC2. Тип: 2 для счетчика, нет проверки для экземпляров спотового запроса, по умолчанию для типа экземпляра Task-Amazon EC2, 0 для счетчика и без проверки для экземпляров спотового запроса.
Обязательно установите ограничение, обеспечивающее достаточную емкость для предотвращения сбоя кластера.
-
На экране «Безопасность и доступ» убедитесь, что поля содержат вашу пару ключей в паре ключей EC2, « Нет других пользователей IAM в доступе пользователя IAM» и « Продолжить без ролей в роли IAM».
-
Просмотрите экран Bootstrap Actions, но не изменяйте его.
-
Просмотрите настройки и выберите Create Cluster, когда закончите.
На экране «Безопасность и доступ» убедитесь, что поля содержат вашу пару ключей в паре ключей EC2, « Нет других пользователей IAM в доступе пользователя IAM» и « Продолжить без ролей в роли IAM».
Просмотрите экран Bootstrap Actions, но не изменяйте его.
Просмотрите настройки и выберите Create Cluster, когда закончите.
Сводная панель появляется в начале кластера.
Активировать сессию SSH
Вам необходим активный сеанс SSH для подключения к главному узлу и выполнения операций CLI. Найдите главный узел, выбрав кластер в консоли EMR. Это перечисляет главный узел как Основное публичное DNS-имя .
Установите PuTTY, если у вас его нет. Затем запустите PuTTYgen и выберите Загрузить . Выберите файл PEM и откройте его. PuTTYgen сообщит вам об успешном импорте. Выберите « Сохранить закрытый ключ» для сохранения в формате закрытого ключа PuTTY (PPK) и выберите « Да» для сохранения без пароля. Затем введите имя для клавиши PuTTY, нажмите « Сохранить» и закройте PuTTYgen.
Используйте PuTTY, чтобы установить соединение с главным узлом, сначала запустив PuTTY. Выберите сессию из списка категорий. Введите hadoop @ DNS в поле Имя хоста. Разверните Connection> SSH в списке категорий и выберите Auth . На экране параметров управления выберите « Поиск файла закрытого ключа» для аутентификации. Затем выберите файл с закрытым ключом и откройте его. Выберите Да для всплывающего окна с предупреждением системы безопасности.
При подключении к главному узлу появляется командная строка Hadoop, что означает, что вы можете начать интерактивный сеанс Hive.
Улей Стол
Hive служит инструментом хранилища данных, позволяющим выполнять запросы к кластерам EMR с использованием HiveQL . Предыдущие настройки дают вам рабочее приглашение. Запускайте команды Hive в интерактивном режиме, просто введя «hive», а затем любые нужные вам команды. Смотрите наш урок Hive для получения дополнительной информации о Hive .
DynamoDB — Таблица активности
Потоки DynamoDB позволяют отслеживать и реагировать на изменения элементов таблицы. Используйте эту функцию для создания приложения, которое реагирует на изменения, обновляя информацию из разных источников. Синхронизируйте данные для тысяч пользователей большой многопользовательской системы. Используйте его для отправки уведомлений пользователям об обновлениях. Его применения оказываются разнообразными и существенными. Потоки DynamoDB служат основным инструментом, используемым для достижения этой функциональности.
Потоки захватывают упорядоченные по времени последовательности, содержащие модификации элементов в таблице. Они хранят эти данные максимум 24 часа. Приложения используют их для просмотра оригинальных и измененных элементов практически в реальном времени.
Включенные в таблицу потоки фиксируют все модификации. При любой операции CRUD DynamoDB создает запись потока с атрибутами первичного ключа измененных элементов. Вы можете настроить потоки для дополнительной информации, такой как изображения до и после.
Потоки несут две гарантии —
-
Каждая запись появляется один раз в потоке и
-
Каждая модификация элемента приводит к тому, что записи потока того же порядка, что и модификации.
Каждая запись появляется один раз в потоке и
Каждая модификация элемента приводит к тому, что записи потока того же порядка, что и модификации.
Все потоки обрабатываются в режиме реального времени, чтобы вы могли использовать их для связанных функций в приложениях.
Управление потоками
При создании таблицы вы можете включить поток. Существующие таблицы позволяют отключить поток или изменить настройки. Потоки предлагают функцию асинхронной работы, что означает отсутствие влияния на производительность таблицы.
Используйте консоль управления AWS для простого управления потоками. Сначала перейдите к консоли и выберите « Таблицы» . На вкладке Обзор выберите Управление потоком . Внутри окна выберите информацию, добавляемую в поток при модификации данных таблицы. После ввода всех настроек выберите Включить .
Если вы хотите отключить любые существующие потоки, выберите « Управление потоком» , а затем « Отключить» .
Вы также можете использовать API CreateTable и UpdateTable для включения или изменения потока. Используйте параметр StreamSpecification для настройки потока. StreamEnabled указывает состояние, означающее true для включенного и false для отключенного.
StreamViewType указывает информацию, добавляемую в поток: KEYS_ONLY, NEW_IMAGE, OLD_IMAGE и NEW_AND_OLD_IMAGES.
Потоковое чтение
Чтение и обработка потоков путем подключения к конечной точке и выполнения запросов API. Каждый поток состоит из записей потока, и каждая запись существует как отдельная модификация, которой принадлежит поток. Потоковые записи включают порядковый номер, раскрывающий порядок публикации. Записи принадлежат группам, также известным как осколки. Осколки функционируют как контейнеры для нескольких записей, а также содержат информацию, необходимую для доступа и просмотра записей. Через 24 часа записи автоматически удаляются.
Эти осколки создаются и удаляются по мере необходимости и не длятся долго. Они также автоматически делятся на несколько новых сегментов, обычно в ответ на всплески активности при записи. При отключении потока откройте открытые осколки. Иерархическая связь между шардами означает, что приложения должны определять приоритеты родительских шардов для правильного порядка обработки. Вы можете использовать Kinesis Adapter, чтобы автоматически сделать это.
Примечание . Операции, не приводящие к изменениям, не записывают потоковые записи.
Доступ и обработка записей требует выполнения следующих задач —
- Определите ARN целевого потока.
- Определите осколки потока, содержащего целевые записи.
- Получите доступ к осколку (ам), чтобы получить нужные записи.
Примечание. Должно быть не более 2 процессов, читающих шард одновременно. Если он превышает 2 процесса, то он может задушить источник.
Доступные действия потокового API включают
- ListStreams
- DescribeStream
- GetShardIterator
- GetRecords
Вы можете просмотреть следующий пример чтения потока —
import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import com.amazonaws.auth.profile.ProfileCredentialsProvider; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreamsClient; import com.amazonaws.services.dynamodbv2.model.AttributeAction; import com.amazonaws.services.dynamodbv2.model.AttributeDefinition; import com.amazonaws.services.dynamodbv2.model.AttributeValue; import com.amazonaws.services.dynamodbv2.model.AttributeValueUpdate; import com.amazonaws.services.dynamodbv2.model.CreateTableRequest; import com.amazonaws.services.dynamodbv2.model.DescribeStreamRequest; import com.amazonaws.services.dynamodbv2.model.DescribeStreamResult; import com.amazonaws.services.dynamodbv2.model.DescribeTableResult; import com.amazonaws.services.dynamodbv2.model.GetRecordsRequest; import com.amazonaws.services.dynamodbv2.model.GetRecordsResult; import com.amazonaws.services.dynamodbv2.model.GetShardIteratorRequest; import com.amazonaws.services.dynamodbv2.model.GetShardIteratorResult; import com.amazonaws.services.dynamodbv2.model.KeySchemaElement; import com.amazonaws.services.dynamodbv2.model.KeyType; import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput; import com.amazonaws.services.dynamodbv2.model.Record; import com.amazonaws.services.dynamodbv2.model.Shard; import com.amazonaws.services.dynamodbv2.model.ShardIteratorType; import com.amazonaws.services.dynamodbv2.model.StreamSpecification; import com.amazonaws.services.dynamodbv2.model.StreamViewType; import com.amazonaws.services.dynamodbv2.util.Tables; public class StreamsExample { private static AmazonDynamoDBClient dynamoDBClient = new AmazonDynamoDBClient(new ProfileCredentialsProvider()); private static AmazonDynamoDBStreamsClient streamsClient = new AmazonDynamoDBStreamsClient(new ProfileCredentialsProvider()); public static void main(String args[]) { dynamoDBClient.setEndpoint("InsertDbEndpointHere"); streamsClient.setEndpoint("InsertStreamEndpointHere"); // table creation String tableName = "MyTestingTable"; ArrayList<AttributeDefinition> attributeDefinitions = new ArrayList<AttributeDefinition>(); attributeDefinitions.add(new AttributeDefinition() .withAttributeName("ID") .withAttributeType("N")); ArrayList<KeySchemaElement> keySchema = new ArrayList<KeySchemaElement>(); keySchema.add(new KeySchemaElement() .withAttributeName("ID") .withKeyType(KeyType.HASH)); //Partition key StreamSpecification streamSpecification = new StreamSpecification(); streamSpecification.setStreamEnabled(true); streamSpecification.setStreamViewType(StreamViewType.NEW_AND_OLD_IMAGES); CreateTableRequest createTableRequest = new CreateTableRequest() .withTableName(tableName) .withKeySchema(keySchema) .withAttributeDefinitions(attributeDefinitions) .withProvisionedThroughput(new ProvisionedThroughput() .withReadCapacityUnits(1L) .withWriteCapacityUnits(1L)) .withStreamSpecification(streamSpecification); System.out.println("Executing CreateTable for " + tableName); dynamoDBClient.createTable(createTableRequest); System.out.println("Creating " + tableName); try { Tables.awaitTableToBecomeActive(dynamoDBClient, tableName); } catch (InterruptedException e) { e.printStackTrace(); } // Get the table's stream settings DescribeTableResult describeTableResult = dynamoDBClient.describeTable(tableName); String myStreamArn = describeTableResult.getTable().getLatestStreamArn(); StreamSpecification myStreamSpec = describeTableResult.getTable().getStreamSpecification(); System.out.println("Current stream ARN for " + tableName + ": "+ myStreamArn); System.out.println("Stream enabled: "+ myStreamSpec.getStreamEnabled()); System.out.println("Update view type: "+ myStreamSpec.getStreamViewType()); // Add an item int numChanges = 0; System.out.println("Making some changes to table data"); Map<String, AttributeValue> item = new HashMap<String, AttributeValue>(); item.put("ID", new AttributeValue().withN("222")); item.put("Alert", new AttributeValue().withS("item!")); dynamoDBClient.putItem(tableName, item); numChanges++; // Update the item Map<String, AttributeValue> key = new HashMap<String, AttributeValue>(); key.put("ID", new AttributeValue().withN("222")); Map<String, AttributeValueUpdate> attributeUpdates = new HashMap<String, AttributeValueUpdate>(); attributeUpdates.put("Alert", new AttributeValueUpdate() .withAction(AttributeAction.PUT) .withValue(new AttributeValue().withS("modified item"))); dynamoDBClient.updateItem(tableName, key, attributeUpdates); numChanges++; // Delete the item dynamoDBClient.deleteItem(tableName, key); numChanges++; // Get stream shards DescribeStreamResult describeStreamResult = streamsClient.describeStream(new DescribeStreamRequest() .withStreamArn(myStreamArn)); String streamArn = describeStreamResult.getStreamDescription().getStreamArn(); List<Shard> shards = describeStreamResult.getStreamDescription().getShards(); // Process shards for (Shard shard : shards) { String shardId = shard.getShardId(); System.out.println("Processing " + shardId + " in "+ streamArn); // Get shard iterator GetShardIteratorRequest getShardIteratorRequest = new GetShardIteratorRequest() .withStreamArn(myStreamArn) .withShardId(shardId) .withShardIteratorType(ShardIteratorType.TRIM_HORIZON); GetShardIteratorResult getShardIteratorResult = streamsClient.getShardIterator(getShardIteratorRequest); String nextItr = getShardIteratorResult.getShardIterator(); while (nextItr != null && numChanges > 0) { // Read data records with iterator GetRecordsResult getRecordsResult = streamsClient.getRecords(new GetRecordsRequest(). withShardIterator(nextItr)); List<Record> records = getRecordsResult.getRecords(); System.out.println("Pulling records..."); for (Record record : records) { System.out.println(record); numChanges--; } nextItr = getRecordsResult.getNextShardIterator(); } } } }
DynamoDB — Обработка ошибок
При неудачной обработке запроса DynamoDB выдает ошибку. Каждая ошибка состоит из следующих компонентов: код состояния HTTP, имя исключения и сообщение. Управление ошибками основывается на вашем SDK, который распространяет ошибки, или на вашем собственном коде.
Коды и сообщения
Исключения попадают в разные коды состояния HTTP-заголовка. 4xx и 5xx содержат ошибки, связанные с проблемами запросов и AWS.
Ниже перечислены некоторые исключения в категории HTTP 4xx.
-
AccessDeniedException — клиент не смог правильно подписать запрос.
-
ConditionalCheckFailedException — условие, оцененное как ложное.
-
IncompleteSignatureException — запрос включал неполную подпись.
AccessDeniedException — клиент не смог правильно подписать запрос.
ConditionalCheckFailedException — условие, оцененное как ложное.
IncompleteSignatureException — запрос включал неполную подпись.
Исключения в категории HTTP 5xx следующие:
- Внутренняя ошибка сервера
- Сервис недоступен
Повторные попытки и алгоритмы возврата
Ошибки происходят из различных источников, таких как серверы, коммутаторы, балансировщики нагрузки и другие элементы структур и систем. Общие решения состоят из простых повторных попыток, что обеспечивает надежность. Все SDK включают эту логику автоматически, и вы можете установить параметры повтора в соответствии с потребностями вашего приложения.
Например — Java предлагает значение maxErrorRetry, чтобы остановить повторные попытки.
Amazon рекомендует использовать решение для отсрочки в дополнение к повторным попыткам, чтобы контролировать поток. Это состоит из постепенно увеличивающихся периодов ожидания между повторными попытками и, в конечном счете, остановки после довольно короткого периода. Примечание. SDK выполняют автоматические повторные попытки, но не экспоненциальный откат.
Следующая программа является примером отката повторной попытки —
public enum Results { SUCCESS, NOT_READY, THROTTLED, SERVER_ERROR } public static void DoAndWaitExample() { try { // asynchronous operation. long token = asyncOperation(); int retries = 0; boolean retry = false; do { long waitTime = Math.min(getWaitTime(retries), MAX_WAIT_INTERVAL); System.out.print(waitTime + "\n"); // Pause for result Thread.sleep(waitTime); // Get result Results result = getAsyncOperationResult(token); if (Results.SUCCESS == result) { retry = false; } else if (Results.NOT_READY == result) { retry = true; } else if (Results.THROTTLED == result) { retry = true; } else if (Results.SERVER_ERROR == result) { retry = true; } else { // stop on other error retry = false; } } while (retry && (retries++ < MAX_RETRIES)); } catch (Exception ex) { } } public static long getWaitTime(int retryCount) { long waitTime = ((long) Math.pow(3, retryCount) * 100L); return waitTime; }
DynamoDB — лучшие практики
Определенные практики оптимизируют код, предотвращают ошибки и минимизируют стоимость пропускной способности при работе с различными источниками и элементами.
Ниже приведены некоторые из наиболее важных и часто используемых передовых практик в DynamoDB.
таблицы
Распределение таблиц означает, что наилучшие подходы равномерно распределяют операции чтения / записи по всем элементам таблицы.
Цель для единого доступа к данным на элементах таблицы. Оптимальное использование пропускной способности зависит от выбора первичного ключа и моделей рабочей нагрузки элемента. Распределите рабочую нагрузку равномерно по значениям ключей секционирования. Избегайте таких вещей, как небольшое количество интенсивно используемых значений ключей секционирования. Выберите лучший выбор, например, большое количество различных значений ключа раздела.
Получить понимание поведения раздела. Оценка разделов, автоматически распределяемых DynamoDB.
DynamoDB предлагает использование пакетной пропускной способности, которая резервирует неиспользованную пропускную способность для «всплесков» мощности. Избегайте интенсивного использования этой опции, потому что пакеты быстро потребляют большое количество пропускной способности; кроме того, он не является надежным ресурсом.
При загрузке распространяйте данные для достижения лучшей производительности. Реализуйте это, загружая на все выделенные серверы одновременно.
Кэширование часто используемых элементов для разгрузки операций чтения в кеш, а не в базу данных.
Предметы
Дросселирование, производительность, размер и стоимость доступа остаются самыми большими проблемами с предметами. Выберите один-ко-многим столам. Удалите атрибуты и разделите таблицы, чтобы соответствовать шаблонам доступа. Вы можете значительно повысить эффективность с помощью этого простого подхода.
Сжатие больших значений до их сохранения. Используйте стандартные инструменты сжатия. Используйте альтернативное хранилище для больших значений атрибутов, таких как S3. Вы можете сохранить объект в S3, а идентификатор в элементе.
Распределите большие атрибуты по нескольким предметам через кусочки виртуальных предметов. Это позволяет обойти ограничения размера элемента.
Запросы и сканы
Запросы и сканирование в основном страдают от проблем с пропускной способностью. Избегайте посылок, которые обычно являются результатом таких вещей, как переключение на строго согласованное чтение. Используйте параллельное сканирование с низким уровнем ресурсов (например, фоновая функция без регулирования). Кроме того, используйте их только с большими таблицами, а ситуации, когда вы не используете полностью пропускную способность или операции сканирования, предлагают низкую производительность.
Местные вторичные индексы
Индексы представляют проблемы в области пропускной способности и затрат на хранение, а также эффективности запросов. Избегайте индексации, если вы часто не запрашиваете атрибуты. В прогнозах выбирайте мудро, потому что они раздувают индексы. Выберите только те, которые интенсивно используются.
Используйте разреженные индексы, то есть индексы, в которых ключи сортировки отображаются не во всех элементах таблицы. Они полезны для запросов по атрибутам, отсутствующим в большинстве элементов таблицы.
Обратите внимание на расширение коллекции элементов (все элементы таблицы и их индексы). Операции добавления / обновления приводят к росту как таблиц, так и индексов, и 10 ГБ остаются ограничением для коллекций.
Глобальные вторичные индексы
Индексы представляют проблемы в области пропускной способности и затрат на хранение, а также эффективности запросов. Выберите распределение ключевых атрибутов, которое, как и чтение / запись в таблицах, обеспечивает равномерность рабочей нагрузки. Выберите атрибуты, которые равномерно распределяют данные. Также используйте разреженные индексы.
Используйте глобальные вторичные индексы для быстрого поиска в запросах, запрашивающих скромный объем данных.