OpenNLP — Обзор
НЛП представляет собой набор инструментов, используемых для получения значимой и полезной информации из источников на естественном языке, таких как веб-страницы и текстовые документы.
Что такое Open NLP?
Apache OpenNLP — это библиотека Java с открытым исходным кодом, которая используется для обработки текста на естественном языке. С помощью этой библиотеки вы можете создать эффективный сервис обработки текста.
OpenNLP предоставляет такие сервисы, как токенизация, сегментация предложений, тегирование части речи, выделение именованных объектов, разбиение на фрагменты, анализ и разрешение сопутствующих ссылок и т. Д.
Особенности OpenNLP
Ниже приведены заметные особенности OpenNLP —
-
Распознавание именованных объектов (NER) — Open NLP поддерживает NER, используя который вы можете извлекать имена местоположений, людей и вещей даже при обработке запросов.
-
Подведение итогов — используя функцию подведения итогов , вы можете суммировать абзацы, статьи, документы или их коллекции в НЛП.
-
Поиск — в OpenNLP заданная строка поиска или ее синонимы могут быть идентифицированы в данном тексте, даже если данное слово изменено или написано с ошибкой.
-
Пометка (POS) — Пометка в НЛП используется для разделения текста на различные грамматические элементы для дальнейшего анализа.
-
Перевод — в НЛП Перевод помогает в переводе с одного языка на другой.
-
Группировка информации — эта опция в НЛП группирует текстовую информацию в содержании документа, как части речи.
-
Генерация естественного языка — используется для генерирования информации из базы данных и автоматизации информационных отчетов, таких как анализ погоды или медицинские отчеты.
-
Анализ обратной связи. Как следует из названия, НЛП собирает различные виды отзывов людей о продуктах, чтобы проанализировать, насколько продукт успешен в завоевании их сердец.
-
Распознавание речи. Хотя анализ человеческой речи затруднен, в НЛП есть некоторые встроенные функции для этого требования.
Распознавание именованных объектов (NER) — Open NLP поддерживает NER, используя который вы можете извлекать имена местоположений, людей и вещей даже при обработке запросов.
Подведение итогов — используя функцию подведения итогов , вы можете суммировать абзацы, статьи, документы или их коллекции в НЛП.
Поиск — в OpenNLP заданная строка поиска или ее синонимы могут быть идентифицированы в данном тексте, даже если данное слово изменено или написано с ошибкой.
Пометка (POS) — Пометка в НЛП используется для разделения текста на различные грамматические элементы для дальнейшего анализа.
Перевод — в НЛП Перевод помогает в переводе с одного языка на другой.
Группировка информации — эта опция в НЛП группирует текстовую информацию в содержании документа, как части речи.
Генерация естественного языка — используется для генерирования информации из базы данных и автоматизации информационных отчетов, таких как анализ погоды или медицинские отчеты.
Анализ обратной связи. Как следует из названия, НЛП собирает различные виды отзывов людей о продуктах, чтобы проанализировать, насколько продукт успешен в завоевании их сердец.
Распознавание речи. Хотя анализ человеческой речи затруднен, в НЛП есть некоторые встроенные функции для этого требования.
Open NLP API
Библиотека Apache OpenNLP предоставляет классы и интерфейсы для выполнения различных задач обработки естественного языка, таких как обнаружение предложений, токенизация, поиск имени, маркировка частей речи, разбиение предложения на части, анализ, сопоставление ссылок и категоризация документов.
В дополнение к этим задачам мы также можем обучать и оценивать наши собственные модели для любой из этих задач.
OpenNLP CLI
В дополнение к библиотеке, OpenNLP также предоставляет интерфейс командной строки (CLI), где мы можем обучать и оценивать модели. Мы обсудим эту тему подробно в последней главе этого урока.
Открытые модели НЛП
Для выполнения различных задач НЛП, OpenNLP предоставляет набор предопределенных моделей. В этот набор входят модели для разных языков.
Скачивание моделей
Вы можете выполнить приведенные ниже шаги, чтобы загрузить предопределенные модели, предоставляемые OpenNLP.
Шаг 1 — Откройте страницу индекса моделей OpenNLP, перейдя по следующей ссылке — http://opennlp.sourceforge.net/models-1.5/ .
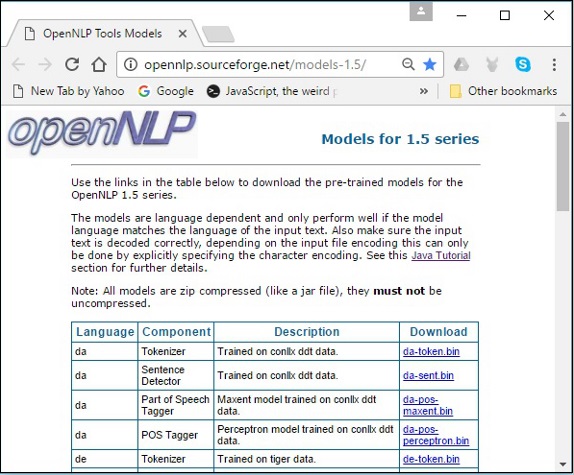
Шаг 2 — Посетив данную ссылку, вы увидите список компонентов на разных языках и ссылки для их загрузки. Здесь вы можете получить список всех предопределенных моделей, предоставляемых OpenNLP.
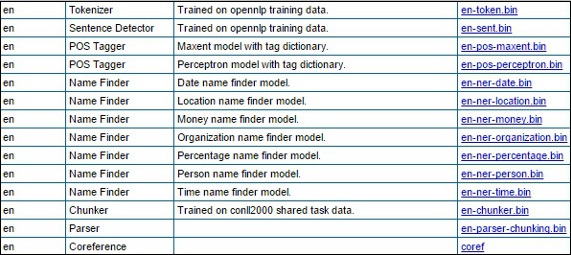
Загрузите все эти модели в папку C: / OpenNLP_models /> , нажав на соответствующие ссылки. Все эти модели зависят от языка, и при их использовании необходимо убедиться, что язык модели соответствует языку входного текста.
История OpenNLP
-
В 2010 году OpenNLP вступила в инкубационный период Apache.
-
В 2011 году был выпущен инкубатор Apache OpenNLP 1.5.2, и в том же году он стал проектом Apache верхнего уровня.
-
В 2015 году был выпущен OpenNLP 1.6.0.
В 2010 году OpenNLP вступила в инкубационный период Apache.
В 2011 году был выпущен инкубатор Apache OpenNLP 1.5.2, и в том же году он стал проектом Apache верхнего уровня.
В 2015 году был выпущен OpenNLP 1.6.0.
OpenNLP — Окружающая среда
В этой главе мы обсудим, как вы можете настроить среду OpenNLP в вашей системе. Начнем с процесса установки.
Установка OpenNLP
Ниже приведены шаги для загрузки библиотеки Apache OpenNLP в вашу систему.
Шаг 1 — Откройте домашнюю страницу Apache OpenNLP , перейдя по следующей ссылке — https://opennlp.apache.org/ .
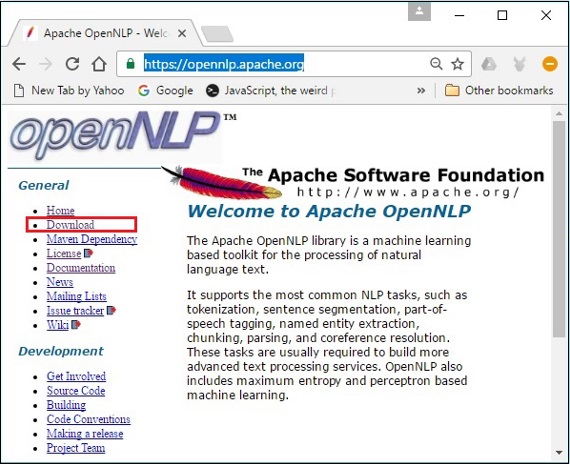
Шаг 2 — Теперь нажмите на ссылку « Загрузки» . При нажатии вы попадете на страницу, где можно найти различные зеркала, которые перенаправят вас в каталог распространения Apache Software Foundation.
Шаг 3 — На этой странице вы можете найти ссылки для загрузки различных дистрибутивов Apache. Просмотрите их, найдите дистрибутив OpenNLP и щелкните по нему.
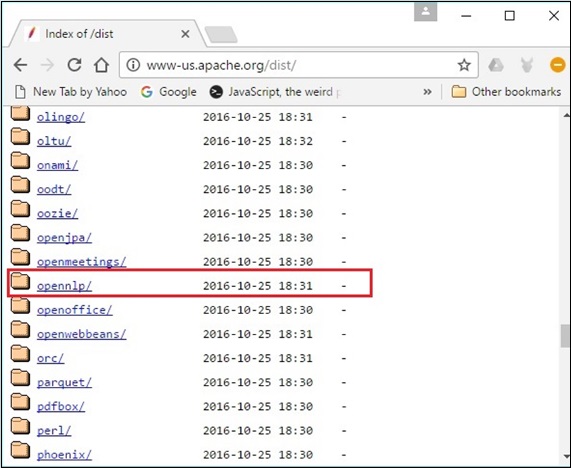
Шаг 4 — При нажатии вы будете перенаправлены в каталог, где вы можете увидеть индекс дистрибутива OpenNLP, как показано ниже.
Нажмите на последнюю версию из доступных дистрибутивов.
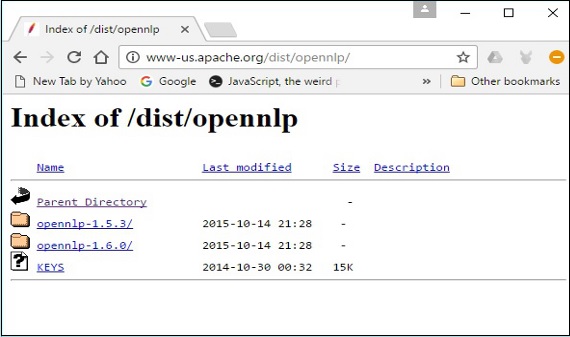
Шаг 5 — Каждый дистрибутив предоставляет исходные и двоичные файлы библиотеки OpenNLP в различных форматах. Загрузите исходные и двоичные файлы, apache-opennlp-1.6.0-bin.zip и apache-opennlp1.6.0-src.zip (для Windows).
Установка пути к классам
После загрузки библиотеки OpenNLP вам необходимо установить ее путь к каталогу bin . Предположим, что вы загрузили библиотеку OpenNLP на диск E вашей системы.
Теперь, следуйте инструкциям ниже:
Шаг 1 — Щелкните правой кнопкой мыши «Мой компьютер» и выберите «Свойства».
Шаг 2 — Нажмите кнопку «Переменные среды» на вкладке «Дополнительно».
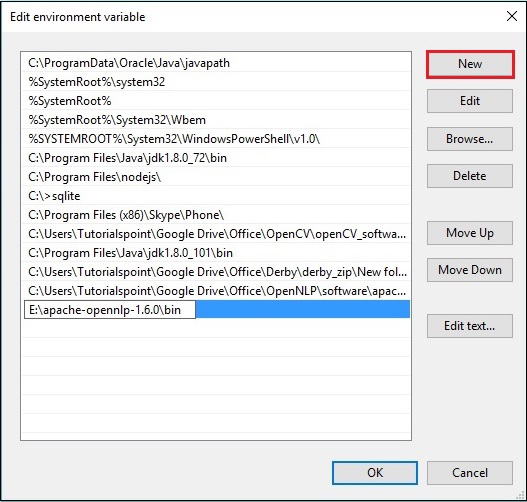
Шаг 3 — Выберите переменную пути и нажмите кнопку « Изменить» , как показано на следующем снимке экрана.
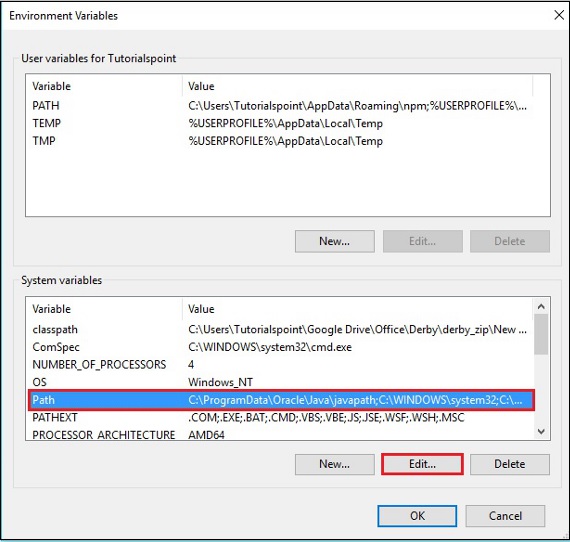
Шаг 4 — В окне «Изменить переменную среды» нажмите кнопку « Создать» и добавьте путь к каталогу OpenNLP E: \ apache-opennlp-1.6.0 \ bin и нажмите кнопку « ОК» , как показано на следующем снимке экрана.
Установка Затмения
Вы можете установить среду Eclipse для библиотеки OpenNLP, указав путь сборки для файлов JAR или используя pom.xml .
Установка пути сборки для файлов JAR
Следуйте инструкциям ниже, чтобы установить OpenNLP в Eclipse —
Шаг 1. Убедитесь, что в вашей системе установлена среда Eclipse.
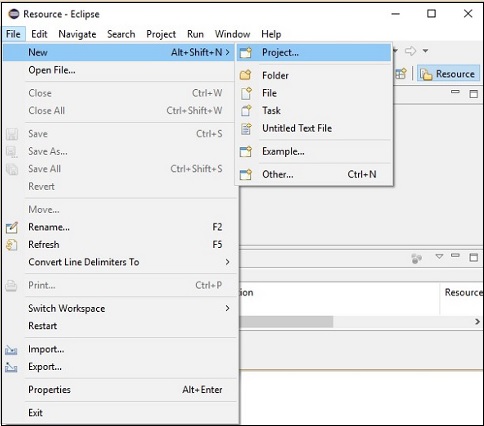
Шаг 2 — Откройте Eclipse. Нажмите Файл → Создать → Открыть новый проект, как показано ниже.
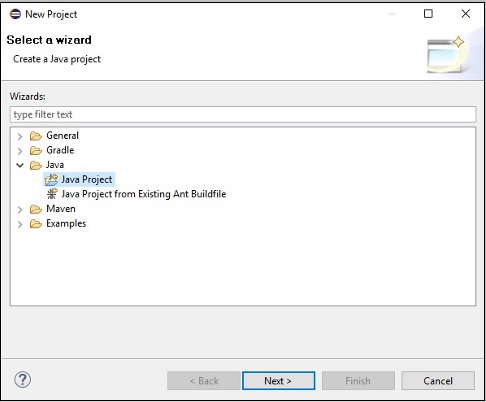
Шаг 3 — Вы получите мастер нового проекта . В этом мастере выберите проект Java и нажмите кнопку « Далее» .
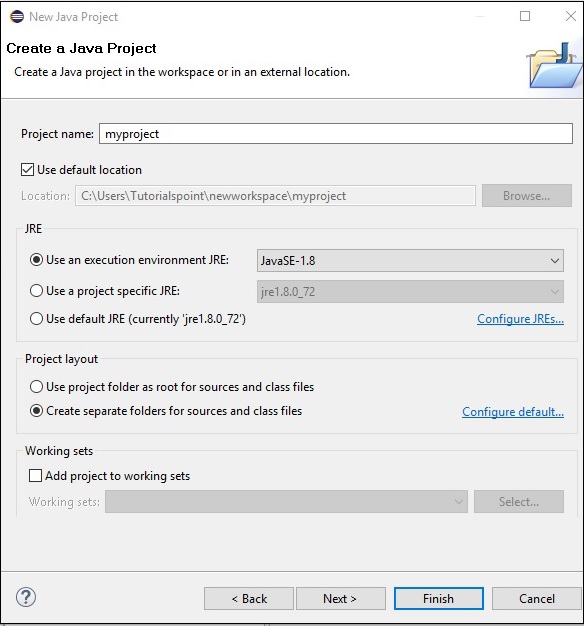
Шаг 4 — Далее вы получите мастер New Java Project . Здесь вам нужно создать новый проект и нажать кнопку « Далее» , как показано ниже.
Шаг 5 — После создания нового проекта щелкните его правой кнопкой мыши, выберите « Путь сборки» и нажмите « Настроить путь сборки» .
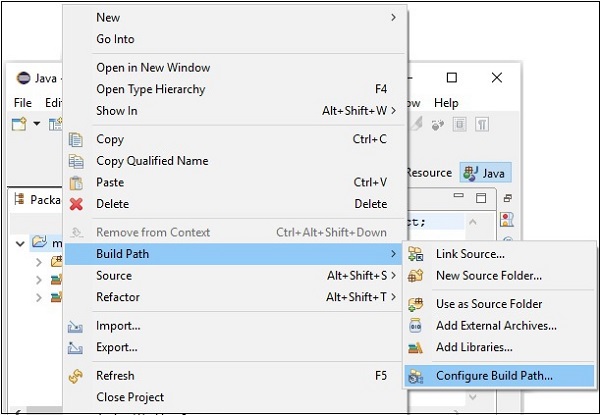
Шаг 6 — Далее вы получите мастер Java Build Path . Здесь нажмите кнопку Add External JARs , как показано ниже.
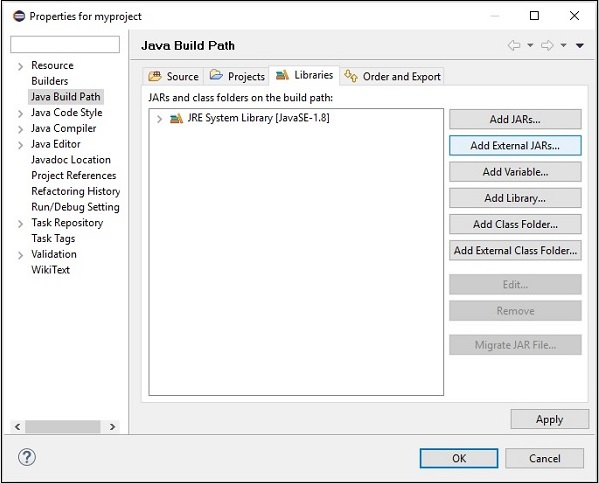
Шаг 7 — Выберите файлы jar opennlp-tools-1.6.0.jar и opennlp-uima-1.6.0.jar, расположенные в папке lib папки apache-opennlp-1.6.0 .
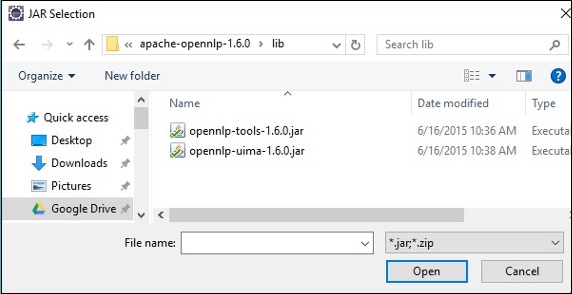
При нажатии кнопки « Открыть» на приведенном выше экране выбранные файлы будут добавлены в вашу библиотеку.
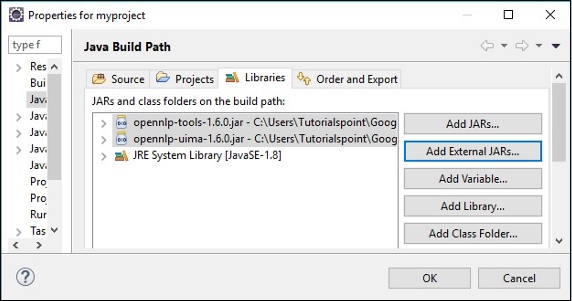
Нажав OK , вы успешно добавите необходимые файлы JAR в текущий проект и сможете проверить эти добавленные библиотеки, развернув ссылочные библиотеки, как показано ниже.
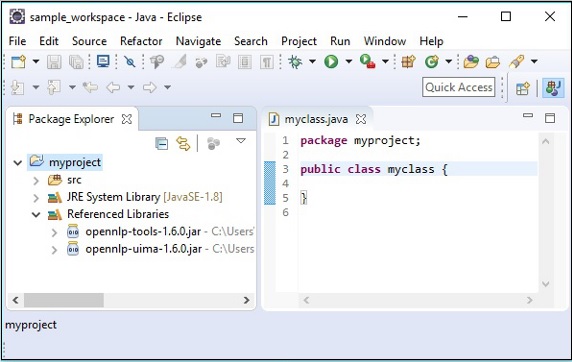
Использование pom.xml
Преобразуйте проект в проект Maven и добавьте следующий код в его файл pom.xml .
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>myproject</groupId> <artifactId>myproject</artifactId> <version>0.0.1-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>org.apache.opennlp</groupId> <artifactId>opennlp-tools</artifactId> <version>1.6.0</version> </dependency> <dependency> <groupId>org.apache.opennlp</groupId> <artifactId>opennlp-uima</artifactId> <version>1.6.0</version> </dependency> </dependencies> </project>
OpenNLP — ссылочный API
В этой главе мы обсудим классы и методы, которые мы будем использовать в последующих главах этого урока.
Обнаружение приговора
Класс SentenceModel
Этот класс представляет предопределенную модель, которая используется для обнаружения предложений в заданном необработанном тексте. Этот класс принадлежит пакету opennlp.tools.sentdetect .
Конструктор этого класса принимает объект InputStream файла модели детектора предложений (en-sent.bin).
SentenceDetectorME class
Этот класс принадлежит пакету opennlp.tools.sentdetect и содержит методы для разбиения необработанного текста на предложения. Этот класс использует модель максимальной энтропии для оценки символов конца предложения в строке, чтобы определить, означают ли они конец предложения.
Ниже приведены важные методы этого класса.
| S.No | Методы и описание |
|---|---|
| 1 |
sentDetect () Этот метод используется для обнаружения предложений в необработанном тексте, переданном ему. Он принимает переменную String в качестве параметра и возвращает массив String, который содержит предложения из заданного необработанного текста. |
| 2 |
sentPosDetect () Этот метод используется для определения позиций предложений в данном тексте. Этот метод принимает строковую переменную, представляющую предложение, и возвращает массив объектов типа Span . Класс с именем Span пакета opennlp.tools.util используется для хранения начального и конечного целого числа наборов. |
| 3 |
getSentenceProbabilities () Этот метод возвращает вероятности, связанные с самыми последними вызовами метода sentDetect () . |
sentDetect ()
Этот метод используется для обнаружения предложений в необработанном тексте, переданном ему. Он принимает переменную String в качестве параметра и возвращает массив String, который содержит предложения из заданного необработанного текста.
sentPosDetect ()
Этот метод используется для определения позиций предложений в данном тексте. Этот метод принимает строковую переменную, представляющую предложение, и возвращает массив объектов типа Span .
Класс с именем Span пакета opennlp.tools.util используется для хранения начального и конечного целого числа наборов.
getSentenceProbabilities ()
Этот метод возвращает вероятности, связанные с самыми последними вызовами метода sentDetect () .
лексемизацию
Класс TokenizerModel
Этот класс представляет предопределенную модель, которая используется для токенизации данного предложения. Этот класс принадлежит пакету opennlp.tools.tokenizer .
Конструктор этого класса принимает объект InputStream файла модели токенизатора (entoken.bin).
Классы
Для выполнения токенизации библиотека OpenNLP предоставляет три основных класса. Все три класса реализуют интерфейс под названием Tokenizer .
| S.No | Классы и описание |
|---|---|
| 1 |
SimpleTokenizer Этот класс маркирует заданный необработанный текст, используя классы символов. |
| 2 |
WhitespaceTokenizer Этот класс использует пробелы для токенизации заданного текста. |
| 3 |
TokenizerME Этот класс преобразует необработанный текст в отдельные токены. Он использует максимальную энтропию для принятия своих решений. |
SimpleTokenizer
Этот класс маркирует заданный необработанный текст, используя классы символов.
WhitespaceTokenizer
Этот класс использует пробелы для токенизации заданного текста.
TokenizerME
Этот класс преобразует необработанный текст в отдельные токены. Он использует максимальную энтропию для принятия своих решений.
Эти классы содержат следующие методы.
| S.No | Методы и описание |
|---|---|
| 1 |
токенизировать () Этот метод используется для токенизации необработанного текста. Этот метод принимает переменную String в качестве параметра и возвращает массив строк (токенов). |
| 2 |
sentPosDetect () Этот метод используется для получения позиций или диапазонов токенов. Он принимает предложение (или) необработанный текст в виде строки и возвращает массив объектов типа Span . |
токенизировать ()
Этот метод используется для токенизации необработанного текста. Этот метод принимает переменную String в качестве параметра и возвращает массив строк (токенов).
sentPosDetect ()
Этот метод используется для получения позиций или диапазонов токенов. Он принимает предложение (или) необработанный текст в виде строки и возвращает массив объектов типа Span .
В дополнение к вышеупомянутым двум методам класс TokenizerME имеет метод getTokenProbabilities () .
| S.No | Методы и описание |
|---|---|
| 1 |
getTokenProbabilities () Этот метод используется для получения вероятностей, связанных с самыми последними вызовами метода tokenizePos () . |
getTokenProbabilities ()
Этот метод используется для получения вероятностей, связанных с самыми последними вызовами метода tokenizePos () .
NameEntityRecognition
Класс TokenNameFinderModel
Этот класс представляет предопределенную модель, которая используется для поиска именованных сущностей в данном предложении. Этот класс принадлежит пакету opennlp.tools.namefind .
Конструктор этого класса принимает объект InputStream файла модели искателя имен (enner-person.bin).
NameFinderME класс
Класс принадлежит пакету opennlp.tools.namefind и содержит методы для выполнения задач NER. Этот класс использует модель максимальной энтропии для поиска именованных объектов в заданном необработанном тексте.
| S.No | Методы и описание |
|---|---|
| 1 |
находить() Этот метод используется для обнаружения имен в необработанном тексте. Он принимает переменную String, представляющую необработанный текст в качестве параметра, и возвращает массив объектов типа Span. |
| 2 |
Probs () Этот метод используется для получения вероятностей последней декодированной последовательности. |
находить()
Этот метод используется для обнаружения имен в необработанном тексте. Он принимает переменную String, представляющую необработанный текст в качестве параметра, и возвращает массив объектов типа Span.
Probs ()
Этот метод используется для получения вероятностей последней декодированной последовательности.
Нахождение частей речи
POSModel класс
Этот класс представляет предопределенную модель, которая используется для маркировки частей речи данного предложения. Этот класс принадлежит пакету opennlp.tools.postag .
Конструктор этого класса принимает объект InputStream файла модели pos-tagger (enpos-maxent.bin).
POSTaggerME класс
Этот класс принадлежит пакету opennlp.tools.postag и используется для прогнозирования частей речи данного необработанного текста. Он использует максимальную энтропию для принятия своих решений.
| S.No | Методы и описание |
|---|---|
| 1 |
тег() Этот метод используется для назначения предложения токенов POS-тегов. Этот метод принимает массив токенов (String) в качестве параметра и возвращает теги (массив). |
| 2 |
getSentenceProbabilities () Этот метод используется для получения вероятностей для каждого тега недавно помеченного предложения. |
тег()
Этот метод используется для назначения предложения токенов POS-тегов. Этот метод принимает массив токенов (String) в качестве параметра и возвращает теги (массив).
getSentenceProbabilities ()
Этот метод используется для получения вероятностей для каждого тега недавно помеченного предложения.
Разбор предложения
Класс ParserModel
Этот класс представляет предопределенную модель, которая используется для анализа данного предложения. Этот класс принадлежит пакету opennlp.tools.parser .
Конструктор этого класса принимает объект InputStream файла модели анализатора (en-parserchunking.bin).
Parser Factory класс
Этот класс принадлежит пакету opennlp.tools.parser и используется для создания анализаторов.
| S.No | Методы и описание |
|---|---|
| 1 |
Создайте() Это статический метод, и он используется для создания объекта парсера. Этот метод принимает объект Filestream файла модели анализатора. |
Создайте()
Это статический метод, и он используется для создания объекта парсера. Этот метод принимает объект Filestream файла модели анализатора.
Класс ParserTool
Этот класс принадлежит пакету opennlp.tools.cmdline.parser и используется для анализа содержимого.
| S.No | Методы и описание |
|---|---|
| 1 |
parseLine () Этот метод класса ParserTool используется для анализа необработанного текста в OpenNLP. Этот метод принимает —
|
parseLine ()
Этот метод класса ParserTool используется для анализа необработанного текста в OpenNLP. Этот метод принимает —
лязг
Класс ChunkerModel
Этот класс представляет предопределенную модель, которая используется для разделения предложения на более мелкие фрагменты. Этот класс принадлежит пакету opennlp.tools.chunker .
Конструктор этого класса принимает объект InputStream файла модели чанкера (enchunker.bin).
ChunkerME класс
Этот класс принадлежит пакету с именем opennlp.tools.chunker и используется для разделения данного предложения на более мелкие куски.
| S.No | Методы и описание |
|---|---|
| 1 |
Кусок () Этот метод используется для разделения данного предложения на более мелкие куски. Он принимает в качестве параметров токены предложения и теги P art O f S peech. |
| 2 |
Probs () Этот метод возвращает вероятности последней декодированной последовательности. |
Кусок ()
Этот метод используется для разделения данного предложения на более мелкие куски. Он принимает в качестве параметров токены предложения и теги P art O f S peech.
Probs ()
Этот метод возвращает вероятности последней декодированной последовательности.
OpenNLP — обнаружение приговора
При обработке естественного языка решение о начале и конце предложений является одной из проблем, требующих решения. Этот процесс известен как S entence Boundary D isambiguation (SBD) или просто разрыв предложения.
Методы, которые мы используем для обнаружения предложений в данном тексте, зависят от языка текста.
Обнаружение предложения с использованием Java
Мы можем обнаружить предложения в данном тексте на языке Java, используя регулярные выражения и набор простых правил.
Например, давайте предположим, что точка, знак вопроса или восклицательный знак заканчивают предложение в данном тексте, а затем мы можем разделить предложение с помощью метода split () класса String . Здесь мы должны передать регулярное выражение в формате String.
Ниже приводится программа, которая определяет предложения в данном тексте с использованием регулярных выражений Java (метод split) . Сохраните эту программу в файле с именем SentenceDetection_RE.java .
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды.
javac SentenceDetection_RE.java java SentenceDetection_RE
При выполнении вышеупомянутая программа создает документ PDF, отображающий следующее сообщение.
Hi How are you Welcome to Tutorialspoint We provide free tutorials on various technologies
Обнаружение предложения с использованием OpenNLP
Для обнаружения предложений OpenNLP использует предопределенную модель, файл с именем en-sent.bin . Эта предопределенная модель обучена обнаружению предложений в заданном необработанном тексте.
Пакет opennlp.tools.sentdetect содержит классы и интерфейсы, которые используются для выполнения задачи обнаружения предложений.
Чтобы обнаружить предложение с использованием библиотеки OpenNLP, вам необходимо —
-
Загрузите модель en-sent.bin, используя класс SentenceModel
-
Создание экземпляра класса SentenceDetectorME .
-
Определите предложения, используя метод sentDetect () этого класса.
Загрузите модель en-sent.bin, используя класс SentenceModel
Создание экземпляра класса SentenceDetectorME .
Определите предложения, используя метод sentDetect () этого класса.
Ниже приведены шаги, которые необходимо выполнить, чтобы написать программу, которая обнаружит предложения из заданного необработанного текста.
Шаг 1: Загрузка модели
Модель для определения предложения представлена классом с именем SentenceModel , который принадлежит пакету opennlp.tools.sentdetect .
Чтобы загрузить модель определения предложения —
-
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
-
Создайте экземпляр класса SentenceModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода:
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
Создайте экземпляр класса SentenceModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода:
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);
Шаг 2: создание класса SentenceDetectorME
Класс SentenceDetectorME пакета opennlp.tools.sentdetect содержит методы для разделения необработанного текста на предложения. Этот класс использует модель максимальной энтропии для оценки символов конца предложения в строке, чтобы определить, означают ли они конец предложения.
Создайте экземпляр этого класса и передайте объект модели, созданный на предыдущем шаге, как показано ниже.
//Instantiating the SentenceDetectorME class SentenceDetectorME detector = new SentenceDetectorME(model);
Шаг 3: Определение предложения
Метод sentDetect () класса SentenceDetectorME используется для обнаружения предложений в необработанном тексте, переданном ему. Этот метод принимает строковую переменную в качестве параметра.
Вызовите этот метод, передав формат строки предложения этому методу.
//Detecting the sentence String sentences[] = detector.sentDetect(sentence);
пример
Ниже приводится программа, которая обнаруживает предложения в заданном необработанном тексте. Сохраните эту программу в файле с именем SentenceDetectionME.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac SentenceDetectorME.java java SentenceDetectorME
При выполнении вышеупомянутая программа читает данную строку и обнаруживает предложения в ней и отображает следующий вывод.
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
Выявление положений приговоров
Мы также можем определить позиции предложений, используя метод sentPosDetect () класса SentenceDetectorME .
Ниже приведены шаги, которые необходимо выполнить, чтобы написать программу, которая определяет позиции предложений из заданного необработанного текста.
Шаг 1: Загрузка модели
Модель для определения предложения представлена классом с именем SentenceModel , который принадлежит пакету opennlp.tools.sentdetect .
Чтобы загрузить модель определения предложения —
-
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
-
Создайте экземпляр класса SentenceModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода.
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
Создайте экземпляр класса SentenceModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода.
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
Шаг 2: создание класса SentenceDetectorME
Класс SentenceDetectorME пакета opennlp.tools.sentdetect содержит методы для разделения необработанного текста на предложения. Этот класс использует модель максимальной энтропии для оценки символов конца предложения в строке, чтобы определить, означают ли они конец предложения.
Создайте экземпляр этого класса и передайте объект модели, созданный на предыдущем шаге.
//Instantiating the SentenceDetectorME class SentenceDetectorME detector = new SentenceDetectorME(model);
Шаг 3: Определение позиции предложения
Метод sentPosDetect () класса SentenceDetectorME используется для определения позиций предложений в необработанном тексте, переданном ему. Этот метод принимает строковую переменную в качестве параметра.
Вызовите этот метод, передав формат строки предложения в качестве параметра этому методу.
//Detecting the position of the sentences in the paragraph Span[] spans = detector.sentPosDetect(sentence);
Шаг 4: Печать интервалов предложений
Метод sentPosDetect () класса SentenceDetectorME возвращает массив объектов типа Span . Класс с именем Span пакета opennlp.tools.util используется для хранения начального и конечного целого числа наборов.
Вы можете сохранить диапазоны, возвращенные методом sentPosDetect (), в массиве Span и распечатать их, как показано в следующем блоке кода.
//Printing the sentences and their spans of a sentence for (Span span : spans) System.out.println(paragraph.substring(span);
пример
Ниже приводится программа, которая обнаруживает предложения в заданном необработанном тексте. Сохраните эту программу в файле с именем SentenceDetectionME.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac SentencePosDetection.java java SentencePosDetection
При выполнении вышеупомянутая программа читает данную строку и обнаруживает предложения в ней и отображает следующий вывод.
[0..16) [17..43) [44..93)
Предложения вместе с их позициями
Метод substring () класса String принимает смещения начала и конца и возвращает соответствующую строку. Мы можем использовать этот метод для печати предложений и их интервалов (позиций), как показано в следующем блоке кода.
for (Span span : spans) System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
Ниже приведена программа для определения предложений по заданному необработанному тексту и отображения их вместе с их позициями. Сохраните эту программу в файле с именем SentencesAndPosDetection.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac SentencesAndPosDetection.java java SentencesAndPosDetection
При выполнении вышеупомянутая программа считывает данную строку и определяет предложения вместе с их позициями и отображает следующий вывод.
Hi. How are you? [0..16) Welcome to Tutorialspoint. [17..43) We provide free tutorials on various technologies [44..93)
Определение вероятности приговора
Метод getSentenceProbabilities () класса SentenceDetectorME возвращает вероятности, связанные с самыми последними вызовами метода sentDetect ().
//Getting the probabilities of the last decoded sequence double[] probs = detector.getSentenceProbabilities();
Ниже приведена программа для печати вероятностей, связанных с вызовами метода sentDetect (). Сохраните эту программу в файле с именем SentenceDetectionMEProbs.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac SentenceDetectionMEProbs.java java SentenceDetectionMEProbs
При выполнении вышеупомянутая программа считывает данную строку и определяет предложения и печатает их. Кроме того, он также возвращает вероятности, связанные с самыми последними вызовами метода sentDetect (), как показано ниже.
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies 0.9240246995179983 0.9957680129995953 1.0
OpenNLP — токенизация
Процесс разбиения данного предложения на более мелкие части (токены) известен как токенизация . В общем, данный необработанный текст маркируется на основе набора разделителей (в основном, пробелов).
Токенизация используется в таких задачах, как проверка орфографии, обработка запросов, определение частей речи, обнаружение предложений, классификация документов и т. Д.
Токенизация с использованием OpenNLP
Пакет opennlp.tools.tokenize содержит классы и интерфейсы, которые используются для выполнения токенизации.
Чтобы разбить данные предложения на более простые фрагменты, библиотека OpenNLP предоставляет три разных класса:
-
SimpleTokenizer — этот класс маркирует заданный необработанный текст с использованием классов символов.
-
WhitespaceTokenizer — этот класс использует пробелы для токенизации заданного текста.
-
TokenizerME — этот класс преобразует необработанный текст в отдельные токены. Он использует максимальную энтропию для принятия своих решений.
SimpleTokenizer — этот класс маркирует заданный необработанный текст с использованием классов символов.
WhitespaceTokenizer — этот класс использует пробелы для токенизации заданного текста.
TokenizerME — этот класс преобразует необработанный текст в отдельные токены. Он использует максимальную энтропию для принятия своих решений.
SimpleTokenizer
Чтобы токенизировать предложение с помощью класса SimpleTokenizer , вам необходимо:
-
Создайте объект соответствующего класса.
-
Токенизируйте предложение, используя метод tokenize () .
-
Распечатайте жетоны.
Создайте объект соответствующего класса.
Токенизируйте предложение, используя метод tokenize () .
Распечатайте жетоны.
Ниже приведены шаги, которые необходимо выполнить, чтобы написать программу, которая использует токен для данного необработанного текста.
Шаг 1 — Создание соответствующего класса
В обоих классах нет доступных конструкторов для их создания. Поэтому нам нужно создавать объекты этих классов, используя статическую переменную INSTANCE .
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
Шаг 2 — Токенизация предложений
Оба этих класса содержат метод tokenize () . Этот метод принимает необработанный текст в формате String. При вызове он маркирует данную строку и возвращает массив строк (токенов).
Токенизируйте предложение, используя метод tokenizer (), как показано ниже.
//Tokenizing the given sentence String tokens[] = tokenizer.tokenize(sentence);
Шаг 3 — Распечатать токены
После токенизации предложения вы можете распечатать токены, используя цикл for , как показано ниже.
//Printing the tokens for(String token : tokens) System.out.println(token);
пример
Ниже приведена программа, которая токенизирует данное предложение с использованием класса SimpleTokenizer. Сохраните эту программу в файле с именем SimpleTokenizerExample.java .
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac SimpleTokenizerExample.java java SimpleTokenizerExample
При выполнении вышеупомянутая программа читает данную строку (необработанный текст), токенизирует ее и отображает следующий вывод:
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologies
WhitespaceTokenizer
Чтобы токенизировать предложение с помощью класса WhitespaceTokenizer, вам необходимо:
-
Создайте объект соответствующего класса.
-
Токенизируйте предложение, используя метод tokenize () .
-
Распечатайте жетоны.
Создайте объект соответствующего класса.
Токенизируйте предложение, используя метод tokenize () .
Распечатайте жетоны.
Ниже приведены шаги, которые необходимо выполнить, чтобы написать программу, которая использует токен для данного необработанного текста.
Шаг 1 — Создание соответствующего класса
В обоих классах нет доступных конструкторов для их создания. Поэтому нам нужно создавать объекты этих классов, используя статическую переменную INSTANCE .
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;
Шаг 2 — Токенизация предложений
Оба этих класса содержат метод tokenize () . Этот метод принимает необработанный текст в формате String. При вызове он маркирует данную строку и возвращает массив строк (токенов).
Токенизируйте предложение, используя метод tokenizer (), как показано ниже.
//Tokenizing the given sentence String tokens[] = tokenizer.tokenize(sentence);
Шаг 3 — Распечатать токены
После токенизации предложения вы можете распечатать токены, используя цикл for , как показано ниже.
//Printing the tokens for(String token : tokens) System.out.println(token);
пример
Ниже приведена программа, которая токенизирует данное предложение с использованием класса WhitespaceTokenizer. Сохраните эту программу в файле с именем WhitespaceTokenizerExample.java .
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac WhitespaceTokenizerExample.java java WhitespaceTokenizerExample
При выполнении вышеупомянутая программа считывает данную строку (необработанный текст), маркирует ее и отображает следующий вывод.
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologies
TokenizerME класс
OpenNLP также использует предопределенную модель, файл с именем de-token.bin, для токенизации предложений. Он обучен токенизации предложений в заданном необработанном тексте.
Класс TokenizerME пакета opennlp.tools.tokenizer используется для загрузки этой модели и токенизации заданного необработанного текста с использованием библиотеки OpenNLP. Для этого вам нужно —
-
Загрузите модель en-token.bin, используя класс TokenizerModel .
-
Создайте класс TokenizerME .
-
Токенизируйте предложения, используя метод tokenize () этого класса.
Загрузите модель en-token.bin, используя класс TokenizerModel .
Создайте класс TokenizerME .
Токенизируйте предложения, используя метод tokenize () этого класса.
Ниже приведены шаги, которые необходимо выполнить для написания программы, которая токенизирует предложения из заданного необработанного текста с использованием класса TokenizerME .
Шаг 1 — Загрузка модели
Модель для токенизации представлена классом с именем TokenizerModel , который принадлежит пакету opennlp.tools.tokenize .
Чтобы загрузить модель токенизатора —
-
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
-
Создайте экземпляр класса TokenizerModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода.
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
Создайте экземпляр класса TokenizerModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода.
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
Шаг 2 — Создание класса TokenizerME
Класс TokenizerME пакета opennlp.tools.tokenize содержит методы для разбиения необработанного текста на более мелкие части (токены). Он использует максимальную энтропию для принятия своих решений.
Создайте экземпляр этого класса и передайте объект модели, созданный на предыдущем шаге, как показано ниже.
//Instantiating the TokenizerME class TokenizerME tokenizer = new TokenizerME(tokenModel);
Шаг 3 — Токенизация предложения
Метод tokenize () класса TokenizerME используется для токенизации необработанного текста, передаваемого ему. Этот метод принимает переменную String в качестве параметра и возвращает массив строк (токенов).
Вызовите этот метод, передав формат строки предложения этому методу следующим образом.
//Tokenizing the given raw text String tokens[] = tokenizer.tokenize(paragraph);
пример
Ниже приведена программа, которая токенизирует данный необработанный текст. Сохраните эту программу в файле с именем TokenizerMEExample.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac TokenizerMEExample.java java TokenizerMEExample
При выполнении вышеупомянутая программа читает данную строку и обнаруживает предложения в ней и отображает следующий вывод:
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologie
Получение позиций токенов
Мы также можем получить позиции или диапазоны токенов, используя метод tokenizePos () . Это метод интерфейса Tokenizer пакета opennlp.tools.tokenize . Поскольку все (три) класса Tokenizer реализуют этот интерфейс, вы можете найти этот метод во всех них.
Этот метод принимает предложение или необработанный текст в виде строки и возвращает массив объектов типа Span .
Вы можете получить позиции токенов, используя метод tokenizePos () , как показано ниже:
//Retrieving the tokens tokenizer.tokenizePos(sentence);
Печать позиций (пролетов)
Класс с именем Span пакета opennlp.tools.util используется для хранения начального и конечного целого числа наборов.
Вы можете сохранить диапазоны, возвращаемые методом tokenizePos (), в массиве Span и распечатать их, как показано в следующем блоке кода.
//Retrieving the tokens Span[] tokens = tokenizer.tokenizePos(sentence); //Printing the spans of tokens for( Span token : tokens) System.out.println(token);
Печать токенов и их позиций вместе
Метод substring () класса String принимает смещения начала и конца и возвращает соответствующую строку. Мы можем использовать этот метод для печати токенов и их диапазонов (позиций) вместе, как показано в следующем блоке кода.
//Printing the spans of tokens for(Span token : tokens) System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
Пример (SimpleTokenizer)
Ниже приведена программа, которая извлекает области маркеров необработанного текста с использованием класса SimpleTokenizer . Он также печатает токены вместе с их позициями. Сохраните эту программу в файле с именем SimpleTokenizerSpans.java .
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac SimpleTokenizerSpans.java java SimpleTokenizerSpans
При выполнении вышеупомянутая программа читает данную строку (необработанный текст), токенизирует ее и отображает следующий вывод:
[0..2) Hi [2..3) . [4..7) How [8..11) are [12..15) you [15..16) ? [17..24) Welcome [25..27) to [28..42) Tutorialspoint [42..43) . [44..46) We [47..54) provide [55..59) free [60..69) tutorials [70..72) on [73..80) various [81..93) technologies
Пример (WhitespaceTokenizer)
Ниже приведена программа, которая извлекает области маркеров необработанного текста с использованием класса WhitespaceTokenizer . Он также печатает токены вместе с их позициями. Сохраните эту программу в файле с именем WhitespaceTokenizerSpans.java .
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды
javac WhitespaceTokenizerSpans.java java WhitespaceTokenizerSpans
При выполнении вышеупомянутая программа считывает данную строку (необработанный текст), маркирует ее и отображает следующий вывод.
[0..3) Hi. [4..7) How [8..11) are [12..16) you? [17..24) Welcome [25..27) to [28..43) Tutorialspoint. [44..46) We [47..54) provide [55..59) free [60..69) tutorials [70..72) on [73..80) various [81..93) technologies
Пример (TokenizerME)
Ниже приведена программа, которая извлекает области маркеров необработанного текста с использованием класса TokenizerME . Он также печатает токены вместе с их позициями. Сохраните эту программу в файле с именем TokenizerMESpans.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac TokenizerMESpans.java java TokenizerMESpans
При выполнении вышеупомянутая программа читает данную строку (необработанный текст), токенизирует ее и отображает следующий вывод:
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint
Вероятность токенизатора
Метод getTokenProbabilities () класса TokenizerME используется для получения вероятностей, связанных с самыми последними вызовами метода tokenizePos ().
//Getting the probabilities of the recent calls to tokenizePos() method double[] probs = detector.getSentenceProbabilities();
Ниже приведена программа для печати вероятностей, связанных с вызовами метода tokenizePos (). Сохраните эту программу в файле с именем TokenizerMEProbs.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac TokenizerMEProbs.java java TokenizerMEProbs
При выполнении вышеупомянутая программа читает заданную строку и маркирует предложения и печатает их. Кроме того, он также возвращает вероятности, связанные с самыми последними вызовами метода tokenizerPos ().
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
OpenNLP — Признание названных лиц
Процесс поиска имен, людей, мест и других объектов из заданного текста известен как N-N Entity R ecognition (NER). В этой главе мы обсудим, как выполнить NER через программу Java с использованием библиотеки OpenNLP.
Распознавание именованных объектов с использованием открытого NLP
Для выполнения различных задач NER OpenNLP использует различные предопределенные модели, а именно: en-nerdate.bn, en-ner-location.bin, en-ner-organization.bin, en-ner-person.bin и en-ner-time. бен. Все эти файлы являются предопределенными моделями, которые обучены обнаруживать соответствующие объекты в заданном необработанном тексте.
Пакет opennlp.tools.namefind содержит классы и интерфейсы, которые используются для выполнения задачи NER. Для выполнения задачи NER с использованием библиотеки OpenNLP вам необходимо:
-
Загрузите соответствующую модель, используя класс TokenNameFinderModel .
-
Создайте экземпляр класса NameFinder .
-
Найдите имена и напечатайте их.
Загрузите соответствующую модель, используя класс TokenNameFinderModel .
Создайте экземпляр класса NameFinder .
Найдите имена и напечатайте их.
Ниже приведены шаги, которые необходимо выполнить для написания программы, которая обнаруживает имена сущностей из заданного необработанного текста.
Шаг 1: Загрузка модели
Модель для определения предложения представлена классом с именем TokenNameFinderModel , который принадлежит пакету opennlp.tools.namefind .
Чтобы загрузить модель NER —
-
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь соответствующей модели NER в формате String ее конструктору).
-
Создайте экземпляр класса TokenNameFinderModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода.
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь соответствующей модели NER в формате String ее конструктору).
Создайте экземпляр класса TokenNameFinderModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода.
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
Шаг 2: Создание класса NameFinderME
Класс NameFinderME пакета opennlp.tools.namefind содержит методы для выполнения задач NER. Этот класс использует модель максимальной энтропии для поиска именованных объектов в заданном необработанном тексте.
Создайте экземпляр этого класса и передайте объект модели, созданный на предыдущем шаге, как показано ниже —
//Instantiating the NameFinderME class NameFinderME nameFinder = new NameFinderME(model);
Шаг 3: Поиск имен в предложении
Метод find () класса NameFinderME используется для обнаружения имен в необработанном тексте, переданном ему. Этот метод принимает строковую переменную в качестве параметра.
Вызовите этот метод, передав формат строки предложения этому методу.
//Finding the names in the sentence Span nameSpans[] = nameFinder.find(sentence);
Шаг 4: Печать диапазонов имен в предложении
Метод find () класса NameFinderME возвращает массив объектов типа Span. Класс с именем Span пакета opennlp.tools.util используется для хранения начального и конечного целого числа наборов.
Вы можете сохранить диапазоны, возвращенные методом find (), в массиве Span и распечатать их, как показано в следующем блоке кода.
//Printing the sentences and their spans of a sentence for (Span span : spans) System.out.println(paragraph.substring(span);
Пример NER
Ниже приводится программа, которая читает данное предложение и распознает промежутки имен людей в нем. Сохраните эту программу в файле с именем NameFinderME_Example.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac NameFinderME_Example.java java NameFinderME_Example
При выполнении вышеупомянутая программа читает данную строку (необработанный текст), обнаруживает имена людей в ней и отображает их позиции (промежутки), как показано ниже.
[0..1) person [2..3) person
Имена вместе с их позициями
Метод substring () класса String принимает смещения начала и конца и возвращает соответствующую строку. Мы можем использовать этот метод для печати имен и их интервалов (позиций), как показано в следующем блоке кода.
for(Span s: nameSpans) System.out.println(s.toString()+" "+tokens[s.getStart()]);
Ниже приведена программа для определения имен из заданного необработанного текста и отображения их вместе с их позициями. Сохраните эту программу в файле с именем NameFinderSentences.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac NameFinderSentences.java java NameFinderSentences
При выполнении вышеупомянутая программа читает данную строку (необработанный текст), обнаруживает имена людей в ней и отображает их позиции (промежутки), как показано ниже.
[0..1) person Mike
Поиск названий места
Загружая различные модели, вы можете обнаружить различные именованные объекты. Ниже приведена Java-программа, которая загружает модель en-ner-location.bin и определяет имена местоположений в данном предложении. Сохраните эту программу в файле с именем LocationFinder.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac LocationFinder.java java LocationFinder
При выполнении вышеупомянутая программа читает данную строку (необработанный текст), обнаруживает имена людей в ней и отображает их позиции (промежутки), как показано ниже.
[4..5) location Hyderabad
NameFinder Вероятность
Метод probs () класса NameFinderME используется для получения вероятностей последней декодированной последовательности.
double[] probs = nameFinder.probs();
Ниже приводится программа для печати вероятностей. Сохраните эту программу в файле с именем TokenizerMEProbs.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac TokenizerMEProbs.java java TokenizerMEProbs
При выполнении вышеупомянутая программа читает данную строку, маркирует предложения и печатает их. Кроме того, он также возвращает вероятности последней декодированной последовательности, как показано ниже.
[0..5) Hello [6..10) John [11..14) how [15..18) are [19..22) you [23..30) welcome [31..33) to [34..48) Tutorialspoint 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
OpenNLP — поиск частей речи
Используя OpenNLP, вы также можете обнаружить части речи данного предложения и распечатать их. Вместо полного названия частей речи OpenNLP использует краткие формы каждой части речи. В следующей таблице указаны различные части речей, обнаруженных OpenNLP, и их значения.
| Части речи | Значение частей речи |
|---|---|
| Н.Н. | Существительное, единственное или массовое |
| DT | детерминанта |
| VB | Глагол, базовая форма |
| ВБД | Глагол прошедшего времени |
| VBZ | Глагол, от третьего лица единственное настоящее |
| В | Предлог или подчиняющее соединение |
| ННП | Имя собственное, единственное число |
| К | в |
| JJ | Имя прилагательное |
Пометка частей речи
Чтобы пометить части речи предложения, OpenNLP использует модель, файл с именем en-posmaxent.bin . Это предопределенная модель, которая обучается маркировать части речи данного необработанного текста.
Класс POSTaggerME пакета opennlp.tools.postag используется для загрузки этой модели и маркировки частей речи данного необработанного текста с использованием библиотеки OpenNLP. Для этого вам нужно —
-
Загрузите модель en-pos-maxent.bin, используя класс POSModel .
-
Создайте класс POSTaggerME .
-
Токенизируйте предложение.
-
Сгенерируйте теги, используя метод tag () .
-
Распечатайте токены и теги, используя класс POSSample .
Загрузите модель en-pos-maxent.bin, используя класс POSModel .
Создайте класс POSTaggerME .
Токенизируйте предложение.
Сгенерируйте теги, используя метод tag () .
Распечатайте токены и теги, используя класс POSSample .
Ниже приведены шаги, которые необходимо выполнить для написания программы, которая помечает части речи в заданном необработанном тексте с использованием класса POSTaggerME .
Шаг 1: Загрузите модель
Модель для маркировки POS представлена классом с именем POSModel , который принадлежит пакету opennlp.tools.postag .
Чтобы загрузить модель токенизатора —
-
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
-
Создайте экземпляр класса POSModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода:
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
Создайте экземпляр класса POSModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода:
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
Шаг 2: Создание класса POSTaggerME
Класс POSTaggerME пакета opennlp.tools.postag используется для прогнозирования частей речи данного необработанного текста. Он использует максимальную энтропию для принятия своих решений.
Создайте экземпляр этого класса и передайте объект модели, созданный на предыдущем шаге, как показано ниже —
//Instantiating POSTaggerME class POSTaggerME tagger = new POSTaggerME(model);
Шаг 3: Маркировка предложения
Метод tokenize () класса whitespaceTokenizer используется для токенизации необработанного текста, переданного ему. Этот метод принимает переменную String в качестве параметра и возвращает массив строк (токенов).
Создайте экземпляр класса whitespaceTokenizer и вызовите этот метод, передав формат String предложения этому методу.
//Tokenizing the sentence using WhitespaceTokenizer class WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE; String[] tokens = whitespaceTokenizer.tokenize(sentence);
Шаг 4: Генерация тегов
Метод tag () класса whitespaceTokenizer назначает POS-теги предложению токенов. Этот метод принимает массив токенов (String) в качестве параметра и возвращает тег (массив).
Вызвать метод tag () , передав ему токены, сгенерированные в предыдущем шаге.
//Generating tags String[] tags = tagger.tag(tokens);
Шаг 5: Печать токенов и тегов
Класс POSSample представляет предложение с тегом POS. Для создания экземпляра этого класса нам потребуется массив токенов (текста) и массив тегов.
Метод toString () этого класса возвращает теговое предложение. Создайте экземпляр этого класса, передав токены и массивы тегов, созданные на предыдущих шагах, и вызовите его метод toString () , как показано в следующем блоке кода.
//Instantiating the POSSample class POSSample sample = new POSSample(tokens, tags); System.out.println(sample.toString());
пример
Ниже приводится программа, которая помечает части речи в заданном необработанном тексте. Сохраните эту программу в файле с именем PosTaggerExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac PosTaggerExample.java java PosTaggerExample
При выполнении вышеупомянутая программа читает заданный текст и обнаруживает части речи этих предложений и отображает их, как показано ниже.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
POS Tagger Performance
Ниже приводится программа, которая помечает части речи данного необработанного текста. Он также контролирует производительность и отображает производительность тегера. Сохраните эту программу в файле с именем PosTagger_Performance.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac PosTaggerExample.java java PosTaggerExample
При выполнении вышеупомянутая программа читает заданный текст и отмечает части речи этих предложений и отображает их. Кроме того, он также отслеживает производительность тега POS и отображает его.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB Average: 0.0 sent/s Total: 1 sent Runtime: 0.0s
POS Tagger Вероятность
Метод probs () класса POSTaggerME используется для определения вероятностей каждого тега недавно помеченного предложения.
//Getting the probabilities of the recent calls to tokenizePos() method double[] probs = detector.getSentenceProbabilities();
Ниже приводится программа, которая отображает вероятности для каждого тега последнего тегированного предложения. Сохраните эту программу в файле с именем PosTaggerProbs.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac TokenizerMEProbs.java java TokenizerMEProbs
При выполнении вышеупомянутая программа читает заданный необработанный текст, отмечает части речи каждого токена в нем и отображает их. Кроме того, он также отображает вероятности для каждой части речи в данном предложении, как показано ниже.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB 0.6416834779738033 0.42983612874819177 0.8584513635863117 0.4394784478206072
OpenNLP — Разбор предложений
Используя OpenNLP API, вы можете анализировать данные предложения. В этой главе мы обсудим, как анализировать необработанный текст с помощью OpenNLP API.
Разбор необработанного текста с использованием библиотеки OpenNLP
Чтобы обнаружить предложения, OpenNLP использует предопределенную модель, файл с именем en-parserchunking.bin . Это предопределенная модель, которая обучается анализировать данный необработанный текст.
Класс Parser пакета opennlp.tools.Parser используется для хранения компонентов анализа, а класс ParserTool пакета opennlp.tools.cmdline.parser используется для анализа содержимого.
Ниже приведены шаги, которые необходимо выполнить для написания программы, которая анализирует данный необработанный текст с использованием класса ParserTool .
Шаг 1: Загрузка модели
Модель для анализа текста представлена классом с именем ParserModel , который принадлежит пакету opennlp.tools.parser .
Чтобы загрузить модель токенизатора —
-
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
-
Создайте экземпляр класса ParserModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода.
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
Создайте экземпляр класса ParserModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода.
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
Шаг 2: Создание объекта класса Parser
Класс Parser пакета opennlp.tools.parser представляет структуру данных для хранения компонентов анализа. Вы можете создать объект этого класса, используя статический метод create () класса ParserFactory .
Вызовите метод create () ParserFactory , передав объект модели, созданный на предыдущем шаге, как показано ниже —
//Creating a parser Parser parser = ParserFactory.create(model);
Шаг 3: Разбор предложения
Метод parseLine () класса ParserTool используется для анализа необработанного текста в OpenNLP. Этот метод принимает —
-
строковая переменная, представляющая текст для анализа.
-
объект парсера.
-
целое число, представляющее количество разборов, которые должны быть выполнены.
строковая переменная, представляющая текст для анализа.
объект парсера.
целое число, представляющее количество разборов, которые должны быть выполнены.
Вызовите этот метод, передав предложение следующим параметрам: объект разбора, созданный на предыдущих шагах, и целое число, представляющее требуемое количество разборов, которые необходимо выполнить.
//Parsing the sentence String sentence = "Tutorialspoint is the largest tutorial library."; Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
пример
Ниже приводится программа, которая анализирует данный необработанный текст. Сохраните эту программу в файле с именем ParserExample.java .
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac ParserExample.java java ParserExample
При выполнении вышеуказанная программа считывает заданный необработанный текст, анализирует его и отображает следующий вывод:
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN tutorial) (NN library.)))))
OpenNLP — Чанкинг Предложения
Разделение предложения на части означает разделение / разделение предложения на части слов, такие как группы слов и группы глаголов.
Разделение предложения с помощью OpenNLP
Чтобы обнаружить предложения, OpenNLP использует модель, файл с именем en-chunker.bin . Это предопределенная модель, которая обучается разбивать предложения в заданном необработанном тексте.
Пакет opennlp.tools.chunker содержит классы и интерфейсы, которые используются для поиска нерекурсивных синтаксических аннотаций, таких как фрагменты имен существительных.
Вы можете разделить предложение на части, используя метод chunk () класса ChunkerME . Этот метод принимает токены предложения и POS-теги в качестве параметров. Поэтому, прежде чем начинать процесс разбиения на фрагменты, прежде всего вам необходимо токенизировать предложение и генерировать POS-теги его частей.
Чтобы разделить предложение на части с помощью библиотеки OpenNLP, вам необходимо:
-
Токенизируйте предложение.
-
Создать POS-теги для него.
-
Загрузите модель en-chunker.bin, используя класс ChunkerModel
-
Создайте класс ChunkerME .
-
Разделите предложения, используя метод chunk () этого класса.
Токенизируйте предложение.
Создать POS-теги для него.
Загрузите модель en-chunker.bin, используя класс ChunkerModel
Создайте класс ChunkerME .
Разделите предложения, используя метод chunk () этого класса.
Ниже приведены шаги, которые необходимо выполнить, чтобы написать программу для фрагментов предложений из заданного необработанного текста.
Шаг 1: Маркировка предложения
Токенизируйте предложения, используя метод tokenize () класса whitespaceTokenizer , как показано в следующем блоке кода.
//Tokenizing the sentence String sentence = "Hi welcome to Tutorialspoint"; WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE; String[] tokens = whitespaceTokenizer.tokenize(sentence);
Шаг 2: Генерация POS-тегов
Сгенерируйте POS-теги предложения, используя метод tag () класса POSTaggerME , как показано в следующем блоке кода.
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
Шаг 3: Загрузка модели
Модель разбиения предложения представлена классом с именем ChunkerModel , который принадлежит пакету opennlp.tools.chunker .
Чтобы загрузить модель определения предложения —
-
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
-
Создайте экземпляр класса ChunkerModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода:
Создайте объект InputStream модели (создайте экземпляр FileInputStream и передайте путь модели в формате String ее конструктору).
Создайте экземпляр класса ChunkerModel и передайте InputStream (объект) модели в качестве параметра ее конструктору, как показано в следующем блоке кода:
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
Шаг 4: Создание класса chunkerME
Класс chunkerME пакета opennlp.tools.chunker содержит методы для разделения предложений. Это основанный на максимальной энтропии чанкер.
Создайте экземпляр этого класса и передайте объект модели, созданный на предыдущем шаге.
//Instantiate the ChunkerME class ChunkerME chunkerME = new ChunkerME(chunkerModel);
Шаг 5: Разделение предложения
Метод chunk () класса ChunkerME используется для разбиения предложений в необработанном тексте, переданном ему. Этот метод принимает два строковых массива, представляющих токены и теги, в качестве параметров.
Вызовите этот метод, передав в качестве параметров массив токенов и массив тегов, созданный на предыдущих шагах.
//Generating the chunks String result[] = chunkerME.chunk(tokens, tags);
пример
Ниже приведена программа для разбиения предложений в заданном необработанном тексте. Сохраните эту программу в файле с именем ChunkerExample.java .
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующую команду —
javac ChunkerExample.java java ChunkerExample
При выполнении вышеупомянутая программа считывает данную строку и разбивает на нее предложения и отображает их, как показано ниже.
Loading POS Tagger model ... done (1.040s) B-NP I-NP B-VP I-VP
Обнаружение позиций токенов
Мы также можем определить позиции или промежутки блоков, используя метод chunkAsSpans () класса ChunkerME . Этот метод возвращает массив объектов типа Span. Класс с именем Span пакета opennlp.tools.util используется для хранения начального и конечного целого числа наборов.
Вы можете сохранить диапазоны, возвращенные методом chunkAsSpans (), в массиве Span и распечатать их, как показано в следующем блоке кода.
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
пример
Ниже приводится программа, которая обнаруживает предложения в заданном необработанном тексте. Сохраните эту программу в файле с именем ChunkerSpansEample.java .
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac ChunkerSpansEample.java java ChunkerSpansEample
При выполнении вышеупомянутая программа считывает данную строку и охватывает фрагменты в ней и отображает следующий вывод:
Loading POS Tagger model ... done (1.059s) [0..2) NP [2..4) VP
Определение вероятности чункера
Метод probs () класса ChunkerME возвращает вероятности последней декодированной последовательности.
//Getting the probabilities of the last decoded sequence double[] probs = chunkerME.probs();
Ниже приведена программа для печати вероятностей последней декодированной последовательности блоком . Сохраните эту программу в файле с именем ChunkerProbsExample.java .
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}
Скомпилируйте и выполните сохраненный файл Java из командной строки, используя следующие команды:
javac ChunkerProbsExample.java java ChunkerProbsExample
При выполнении вышеупомянутая программа считывает данную строку, разбивает ее на части и печатает вероятности последней декодированной последовательности.
0.9592746040797778 0.6883933131241501 0.8830563473996004 0.8951150529746051
OpenNLP — интерфейс командной строки
OpenNLP предоставляет интерфейс командной строки (CLI) для выполнения различных операций через командную строку. В этой главе мы возьмем несколько примеров, чтобы показать, как мы можем использовать интерфейс командной строки OpenNLP.