Что такое PyTorch?
PyTorch — основанная на Torch библиотека машинного обучения для Python. Это похоже на NumPy, но с мощной поддержкой графического процессора. Он был разработан AI Research Group из Facebook в 2016 году. PyTorch предлагает динамический вычислительный график, который позволяет изменять график на ходу с помощью автограда. Pytorch также быстрее в некоторых случаях, чем другие фреймворки, но вы обсудите это позже в другом разделе.
Преимущества и слабость PyTorch
преимущества
- Простая библиотека
Код PyTorch прост. Это легко понять, и вы используете библиотеку мгновенно. Например, взгляните на фрагмент кода ниже:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = torch.nn.Linear(1, 1)
def forward(self, x):
x = self.layer(x)
return x
Как и выше, вы можете легко определить модель сети и быстро понять код без особого обучения.
- Динамический вычислительный граф

Источник изображения: изучение глубокого обучения с помощью PyTorch
Pytorch предлагает динамический вычислительный граф (DAG). Вычислительные графы — это способ выражения математических выражений в моделях или теориях графов, таких как узлы и ребра. Узел выполнит математическую операцию, а ребро — это Тензор, который будет подан в узлы и будет содержать выходные данные узла в Тензор.
DAG — это граф, который имеет произвольную форму и способен выполнять операции между различными входными графами. На каждой итерации создается новый граф. Таким образом, можно иметь такую же структуру графа или создать новый граф с другой операцией, или мы можем назвать его динамическим графом.
- Лучшая производительность
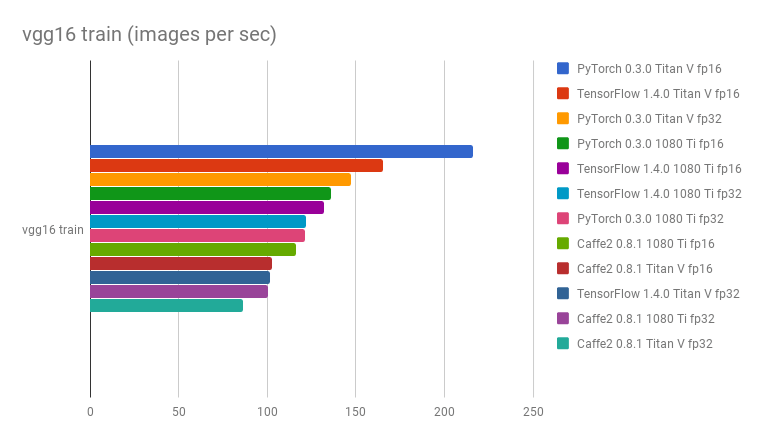
Сообщества и исследователи, оценивают и сравнивают структуры, чтобы увидеть, какая из них быстрее. Тест репозитория GitHub по фреймворкам глубокого обучения и графическим процессорам показал, что PyTorch работает быстрее, чем другие фреймворки, с точки зрения изображений, обрабатываемых в секунду.
Как вы можете видеть ниже, графики сравнения с vgg16 и resnet152
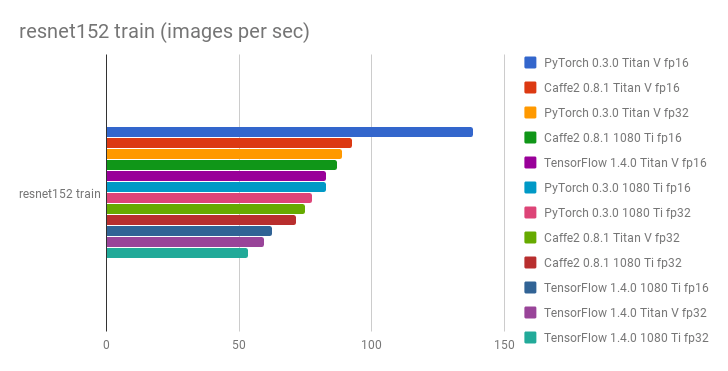
- Родной питон
PyTorch больше основан на Python. Например, если вы хотите обучить модель, вы можете использовать собственный поток управления, такой как циклы и рекурсии, без необходимости добавлять дополнительные специальные переменные или сеансы, чтобы иметь возможность их запускать. Это очень полезно для тренировочного процесса.
Pytorch также реализует императивное программирование, и оно определенно более гибкое. Таким образом, можно распечатать значение тензора в середине вычислительного процесса.
Слабость
PyTorch еще не официально готов, потому что он все еще перерабатывается в версию 1. Таким образом, для достижения стабильной версии необходимы дальнейшие разработки и исследования.
PyTorch Vs. TensorFlow

Самая популярная структура глубокого обучения — Tensorflow . Разработанный Google Brain Team, это самый распространенный инструмент глубокого обучения.
PyTorch против Tensorflow
| параметры | PyTorch | Tensorflow |
| Определение модели | Модель определена в подклассе и предлагает простой в использовании пакет | Модель определяется многими, и вам нужно понять синтаксис |
| Поддержка GPU | да | да |
| Тип графика | динамический | статический |
| инструменты | Нет инструмента визуализации | Вы можете использовать инструмент визуализации Tensorboard |
| сообщество | Сообщество все еще растет | Большие активные сообщества |
Установка PyTorch
Linux
Это просто установить в Linux. Вы можете использовать виртуальную среду или установить ее напрямую с правами root. Введите эту команду в терминале
pip3 install --upgrade torch torchvision
AWS Sagemaker
Sagemaker — это одна из платформ в веб-службе Amazon, которая предлагает мощный механизм машинного обучения с предустановленными конфигурациями глубокого обучения, позволяющими ученым или разработчикам данных создавать, обучать и развертывать модели в любом масштабе.
Сначала откройте консоль Amazon Sagemaker и нажмите «Создать экземпляр ноутбука» и заполните все данные для своего ноутбука.

Следующий шаг, нажмите Открыть, чтобы запустить экземпляр вашего ноутбука.

Наконец, в Jupyter, нажмите New и выберите conda_pytorch_p36, и вы готовы использовать экземпляр вашего ноутбука с установленным Pytorch.
Основы PyTorch Framework
Давайте изучим основные понятия PyTorch, прежде чем мы углубимся. PyTorch использует Tensor для каждой переменной, аналогичной ndarray numpy, но с поддержкой вычислений на GPU. Здесь мы объясним модель сети, функцию потерь, Backprop и Optimizer.
Модель сети
Сеть может быть построена путем создания подкласса torch.nn. Есть 2 основные части,
- Первая часть — определить параметры и слои, которые вы будете использовать.
- Вторая часть — это основная задача, называемая прямым процессом, который будет принимать входные данные и прогнозировать выходные данные.
Import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(3, 20, 5)
self.conv2 = nn.Conv2d(20, 40, 5)
self.fc1 = nn.Linear(320, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
return F.log_softmax(x)
net = Model()
Как вы можете видеть выше, вы создаете класс nn.Module с именем Model. Он содержит 2 слоя Conv2d и линейный слой. Первый слой conv2d принимает входное значение 3 и выходную форму 20. Второй слой принимает входное значение 20 и будет формировать выходную форму 40. Последний слой представляет собой полностью связанный слой в форме 320 и будет производить выход 10.
Процесс пересылки будет принимать ввод X и передавать его на слой conv1 и выполнять функцию ReLU,
Точно так же это также будет питать слой conv2. После этого x будет преобразован в (-1, 320) и передан в финальный слой FC. Перед отправкой вывода вы будете использовать функцию активации softmax.
Обратный процесс автоматически определяется autograd, поэтому вам нужно только определить прямой процесс.
Функция потери
Функция потерь используется для измерения того, насколько хорошо модель прогнозирования способна прогнозировать ожидаемые результаты. PyTorch уже имеет много стандартных функций потерь в модуле torch.nn. Например, вы можете использовать кросс-энтропийную потерю для решения задачи классификации нескольких классов. Легко определить функцию потерь и вычислить потери:
loss_fn = nn.CrossEntropyLoss() #training process loss = loss_fn(out, target)
С PyTorch легко рассчитать собственную функцию расчета потерь.
Backprop
Чтобы выполнить обратное распространение, вы просто вызываете los.backward (). Ошибка будет вычислена, но не забудьте очистить существующий градиент с помощью zero_grad ()
net.zero_grad() # to clear the existing gradient loss.backward() # to perform backpropragation
оптимизатор
Torch.optim предоставляет общие алгоритмы оптимизации. Вы можете определить оптимизатор с простым шагом:
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01, momentum=0.9)
Необходимо передать параметры сетевой модели и скорость обучения, чтобы на каждой итерации параметры обновлялись после процесса backprop.
Простая регрессия с PyTorch
Шаг 1) Создание нашей сетевой модели
Наша сетевая модель представляет собой простой линейный слой с формой ввода и вывода 1.
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = torch.nn.Linear(1, 1)
def forward(self, x):
x = self.layer(x)
return x
net = Net()
print(net)
И сетевой выход должен быть таким
Net( (hidden): Linear(in_features=1, out_features=1, bias=True) )
Шаг 2) Тестовые данные
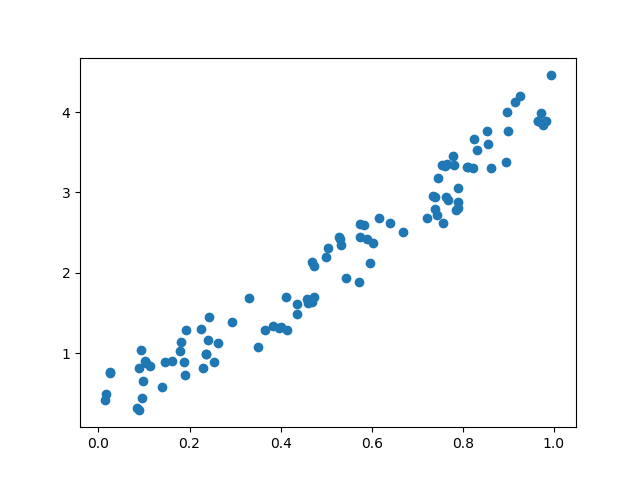
Прежде чем начать тренировочный процесс, вам необходимо знать наши данные. Вы делаете случайную функцию для проверки нашей модели. Y = x 3 sin (x) + 3x + 0.8 ранд (100)
# Visualize our data import matplotlib.pyplot as plt import numpy as np x = np.random.rand(100) y = np.sin(x) * np.power(x,3) + 3*x + np.random.rand(100)*0.8 plt.scatter(x, y) plt.show()
Вот график рассеяния нашей функции:
Перед тем, как вы начнете процесс обучения, вам нужно преобразовать массив numpy в переменные, поддерживаемые Torch и autograd.
# convert numpy array to tensor in shape of input size x = torch.from_numpy(x.reshape(-1,1)).float() y = torch.from_numpy(y.reshape(-1,1)).float() print(x, y)
Шаг 3) Оптимизатор и потеря
Затем вы должны определить Оптимизатор и функцию потерь для нашего тренировочного процесса.
# Define Optimizer and Loss Function optimizer = torch.optim.SGD(net.parameters(), lr=0.2) loss_func = torch.nn.MSELoss()
Шаг 4) Обучение
Теперь давайте начнем наш тренировочный процесс. С эпохой 250 вы будете перебирать наши данные, чтобы найти лучшее значение для наших гиперпараметров.
inputs = Variable(x)
outputs = Variable(y)
for i in range(250):
prediction = net(inputs)
loss = loss_func(prediction, outputs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 10 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'})
plt.pause(0.1)
plt.show()
Шаг 5) Результат
Как вы можете видеть ниже, вы успешно выполнили регрессию с помощью нейронной сети. Фактически, на каждой итерации красная линия на графике будет обновляться и менять свое положение в соответствии с данными. Но на этой картинке вы показываете только конечный результат

Классификация изображений с помощью PyTorch
Одним из популярных методов изучения основ глубокого обучения является набор данных MNIST. Это «Hello World» в глубоком обучении. Набор данных содержит рукописные числа от 0 до 9 с общим количеством 60000 обучающих образцов и 10000 тестовых образцов, которые уже помечены размером 28×28 пикселей.

Шаг 1) Предварительная обработка данных
Прежде чем начать тренировочный процесс, вам необходимо разобраться в данных. На первом этапе вы загрузите набор данных с помощью модуля torchvision. Torchvision загрузит набор данных и преобразует изображения в соответствии с требованиями сети, такими как форма и нормализация изображений.
import torch
import torchvision
import numpy as np
from torchvision import datasets, models, transforms
# This is used to transform the images to Tensor and normalize it
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
training = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(training, batch_size=4,
shuffle=True, num_workers=2)
testing = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(testing, batch_size=4,
shuffle=False, num_workers=2)
classes = ('0', '1', '2', '3',
'4', '5', '6', '7', '8', '9')
import matplotlib.pyplot as plt
import numpy as np
#create an iterator for train_loader
# get random training images
data_iterator = iter(train_loader)
images, labels = data_iterator.next()
#plot 4 images to visualize the data
rows = 2
columns = 2
fig=plt.figure()
for i in range(4):
fig.add_subplot(rows, columns, i+1)
plt.title(classes[labels[i]])
img = images[i] / 2 + 0.5 # this is for unnormalize the image
img = torchvision.transforms.ToPILImage()(img)
plt.imshow(img)
plt.show()
Функция преобразования преобразует изображения в тензор и нормализует значение. Функция torchvision.transforms.MNIST, загрузит набор данных (если он недоступен) в каталог, при необходимости установит набор данных для обучения и выполнит процесс преобразования.
Чтобы визуализировать набор данных, вы используете data_iterator для получения следующего пакета изображений и меток. Вы используете matplot для построения этих изображений и их соответствующей метки. Как вы можете видеть ниже наши изображения и их этикетки.
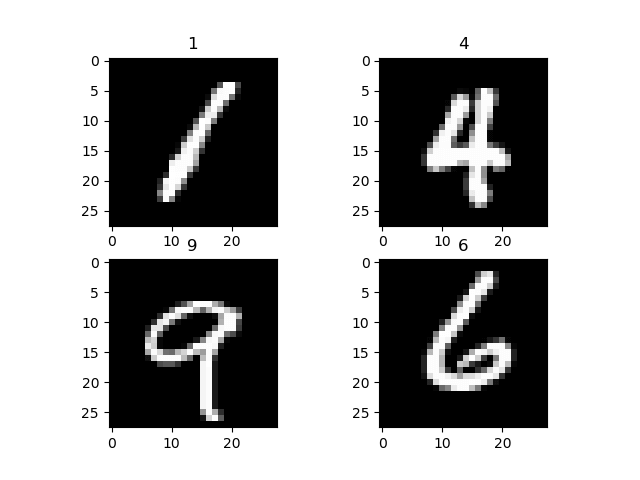
Шаг 2) Настройка сетевой модели
Теперь вы сделаете простую нейронную сеть для классификации изображений. Здесь мы представляем вам еще один способ создания модели сети в PyTorch. Мы будем использовать nn.Sequential для создания модели последовательности вместо создания подкласса nn.Module.
import torch.nn as nn
# flatten the tensor into
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)
#sequential based model
seq_model = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Dropout2d(),
nn.Conv2d(10, 20, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
Flatten(),
nn.Linear(320, 50),
nn.ReLU(),
nn.Linear(50, 10),
nn.Softmax(),
)
net = seq_model
print(net)
Вот вывод нашей сетевой модели
Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (2): ReLU() (3): Dropout2d(p=0.5) (4): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)) (5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (6): ReLU() (7): Flatten() (8): Linear(in_features=320, out_features=50, bias=True) (9): ReLU() (10): Linear(in_features=50, out_features=10, bias=True) (11): Softmax() )
Сеть Объяснение
- Последовательность состоит в том, что первый слой представляет собой слой Conv2D с формой ввода 1 и формой вывода 10 с размером ядра 5
- Далее у вас есть слой MaxPool2D
- Функция активации ReLU
- слой Dropout для сброса значений низкой вероятности.
- Затем второй Conv2d с входной формой 10 из последнего слоя и выходной формой 20 с размером ядра 5
- Следующий слой MaxPool2d
- Функция активации ReLU.
- После этого вы сгладите тензор, прежде чем подать его в линейный слой.
- Linear Layer отобразит наш вывод на второй Linear layer с функцией активации softmax
Шаг 3) Обучаем модель
Перед началом тренировочного процесса необходимо настроить критерий и функцию оптимизатора. Для критерия вы будете использовать CrossEntropyLoss. Для Оптимизатора вы будете использовать SGD со скоростью обучения 0,001 и импульсом 0,9.
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Прямой процесс примет входную форму и передаст ее первому слою conv2d. Затем он будет передан в maxpool2d и, наконец, введен в функцию активации ReLU. Тот же процесс будет происходить во втором слое conv2d. После этого вход будет преобразован в (-1,320) и передан в слой fc, чтобы предсказать результат.
Теперь вы начнете тренировочный процесс. Вы будете перебирать наш набор данных 2 раза или с периодом 2 и распечатывать текущие потери в каждой партии 2000.
for epoch in range(2):
#set the running loss at each epoch to zero
running_loss = 0.0
# we will enumerate the train loader with starting index of 0
# for each iteration (i) and the data (tuple of input and labels)
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# clear the gradient
optimizer.zero_grad()
#feed the input and acquire the output from network
outputs = net(inputs)
#calculating the predicted and the expected loss
loss = criterion(outputs, labels)
#compute the gradient
loss.backward()
#update the parameters
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 1000 == 0:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0
В каждую эпоху перечислитель получит следующий кортеж ввода и соответствующие метки. Прежде чем мы передадим входные данные в нашу сетевую модель, нам нужно очистить предыдущий градиент. Это необходимо, потому что после обратного процесса (обратного распространения) градиент будет накапливаться, а не заменяться. Затем мы рассчитаем потери от прогнозируемой выработки от ожидаемой выработки. После этого мы сделаем обратное распространение для вычисления градиента и, наконец, обновим параметры.
Вот результат тренировочного процесса
[1, 1] loss: 0.002 [1, 1001] loss: 2.302 [1, 2001] loss: 2.295 [1, 3001] loss: 2.204 [1, 4001] loss: 1.930 [1, 5001] loss: 1.791 [1, 6001] loss: 1.756 [1, 7001] loss: 1.744 [1, 8001] loss: 1.696 [1, 9001] loss: 1.650 [1, 10001] loss: 1.640 [1, 11001] loss: 1.631 [1, 12001] loss: 1.631 [1, 13001] loss: 1.624 [1, 14001] loss: 1.616 [2, 1] loss: 0.001 [2, 1001] loss: 1.604 [2, 2001] loss: 1.607 [2, 3001] loss: 1.602 [2, 4001] loss: 1.596 [2, 5001] loss: 1.608 [2, 6001] loss: 1.589 [2, 7001] loss: 1.610 [2, 8001] loss: 1.596 [2, 9001] loss: 1.598 [2, 10001] loss: 1.603 [2, 11001] loss: 1.596 [2, 12001] loss: 1.587 [2, 13001] loss: 1.596 [2, 14001] loss: 1.603
Шаг 4) Проверьте модель
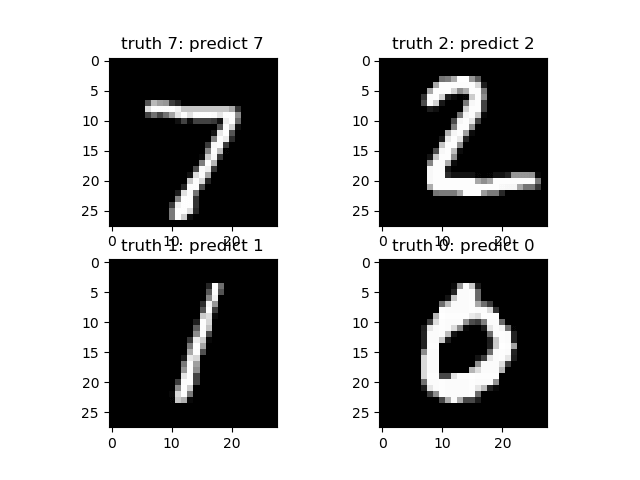
После того, как вы обучите нашу модель, вам нужно протестировать или оценить другие наборы изображений. Мы будем использовать итератор для test_loader, и он сгенерирует пакет изображений и меток, которые будут переданы обученной модели. Прогнозируемый результат будет отображаться и сравниваться с ожидаемым результатом.
#make an iterator from test_loader
#Get a batch of training images
test_iterator = iter(test_loader)
images, labels = test_iterator.next()
results = net(images)
_, predicted = torch.max(results, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
fig2 = plt.figure()
for i in range(4):
fig2.add_subplot(rows, columns, i+1)
plt.title('truth ' + classes[labels[i]] + ': predict ' + classes[predicted[i]])
img = images[i] / 2 + 0.5 # this is to unnormalize the image
img = torchvision.transforms.ToPILImage()(img)
plt.imshow(img)
plt.show()